

Bagaimanakah ChatGPT mengeluarkan perkataan demi perkataan?


Apabila ChatGPT menjawab soalan, ia muncul perkataan demi perkataan, memberikan orang perasaan bahawa mereka sedang berfikir secara serius.
Kandungan asas perbualan ini ialah:
S: Bagaimanakah model generatif bahasa besar berfungsi
Jawapan: Model penjanaan bahasa berskala besar (seperti GPT-3) ialah model rangkaian saraf berdasarkan teknologi pembelajaran mendalam. Model-model ini sering menggunakan seni bina yang dipanggil "Transformer", yang telah mencapai kejayaan besar dalam bidang pemprosesan bahasa semula jadi.Berikut ialah gambaran keseluruhan cara model penjanaan bahasa besar berfungsi:
. .. Tinggalkan perenggan...
Jana teks: Setelah model dilatih, ia boleh digunakan untuk menjana teks. Memandangkan teks atau gesaan awal, model menjana perkataan seterusnya berdasarkan taburan kebarangkalian yang telah dipelajari, kemudian menggunakan perkataan yang dijana sebagai input dan terus menjana perkataan seterusnya, dan seterusnya sehingga panjang teks yang diingini dicapai atau dijana Penamatan simbol.
... Tinggalkan perenggan...
Model Bahasa Besar, Besar Model Bahasa, dirujuk sebagai LLM.
Dari perspektif model, LLM menjana token setiap kali ia melakukan inferens sehingga had panjang teks dicapai atau penamat dijana.
Dari perspektif pelayan, token yang dijana perlu dikembalikan kepada penyemak imbas satu demi satu melalui protokol HTTPS.
Dalam mod Pelayan-Pelanggan, kaedah interaksi konvensional ialah pelanggan menghantar permintaan dan menerima respons. Jelas sekali, ini tidak dapat memenuhi senario ChatGPT membalas soalan.
Kedua, kita mungkin memikirkan websocket, yang bergantung pada HTTP untuk melaksanakan jabat tangan dan dinaik taraf kepada WebSocket. Walau bagaimanapun, WebSocket memerlukan kedua-dua pelanggan dan pelayan untuk terus menduduki soket, dan kos di bahagian pelayan agak tinggi.
CtGPT menggunakan kompromi: acara yang dihantar oleh pelayan (pendek kata SSE kami boleh menemui ini daripada dokumentasi API OpenAI:
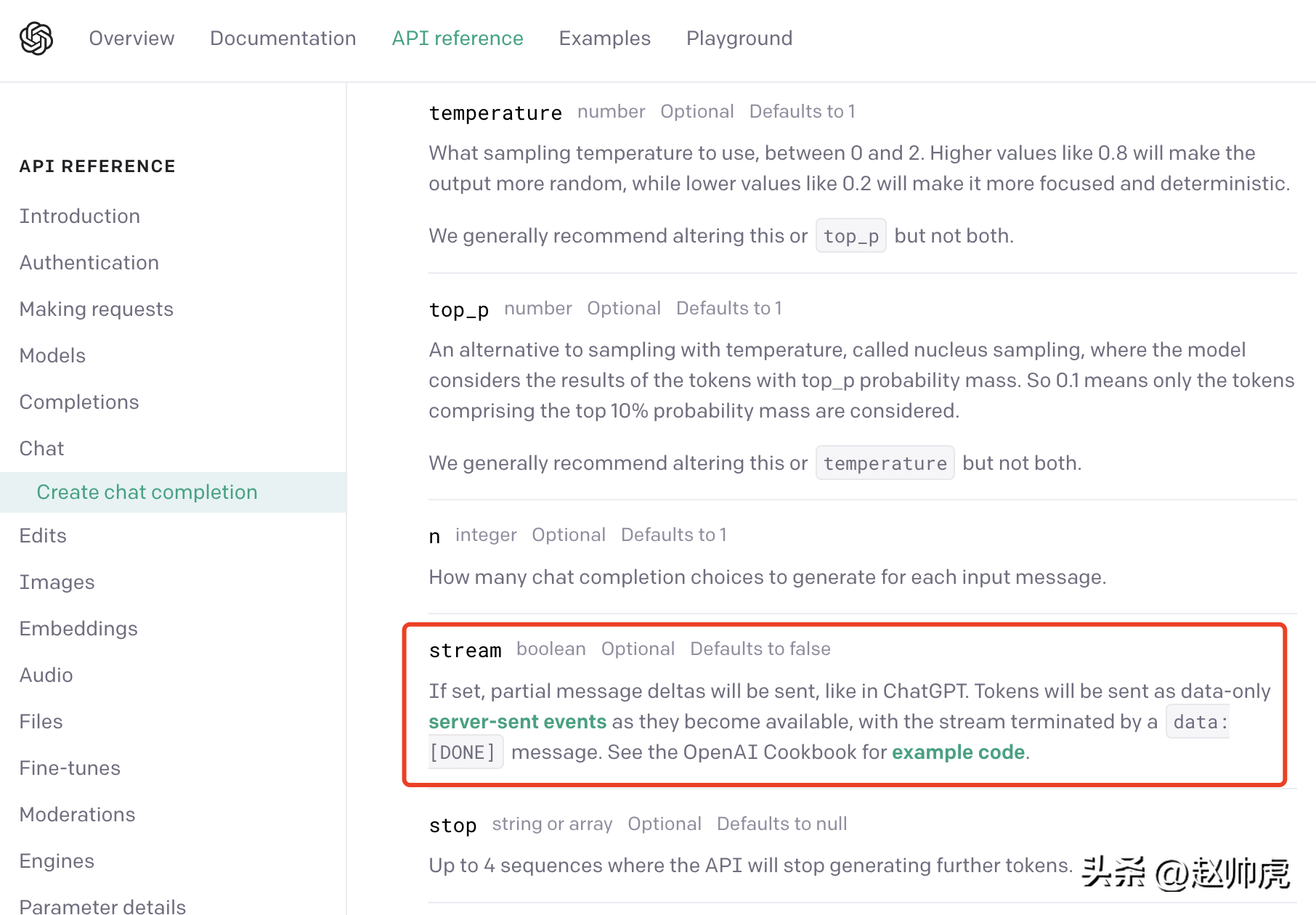
Dalam mod SSE, pelanggan hanya perlu menghantar permintaan kepada pelayan sekali sahaja, dan pelayan boleh meneruskan output sehingga penghujung diperlukan. Keseluruhan proses interaksi ditunjukkan dalam rajah di bawah:
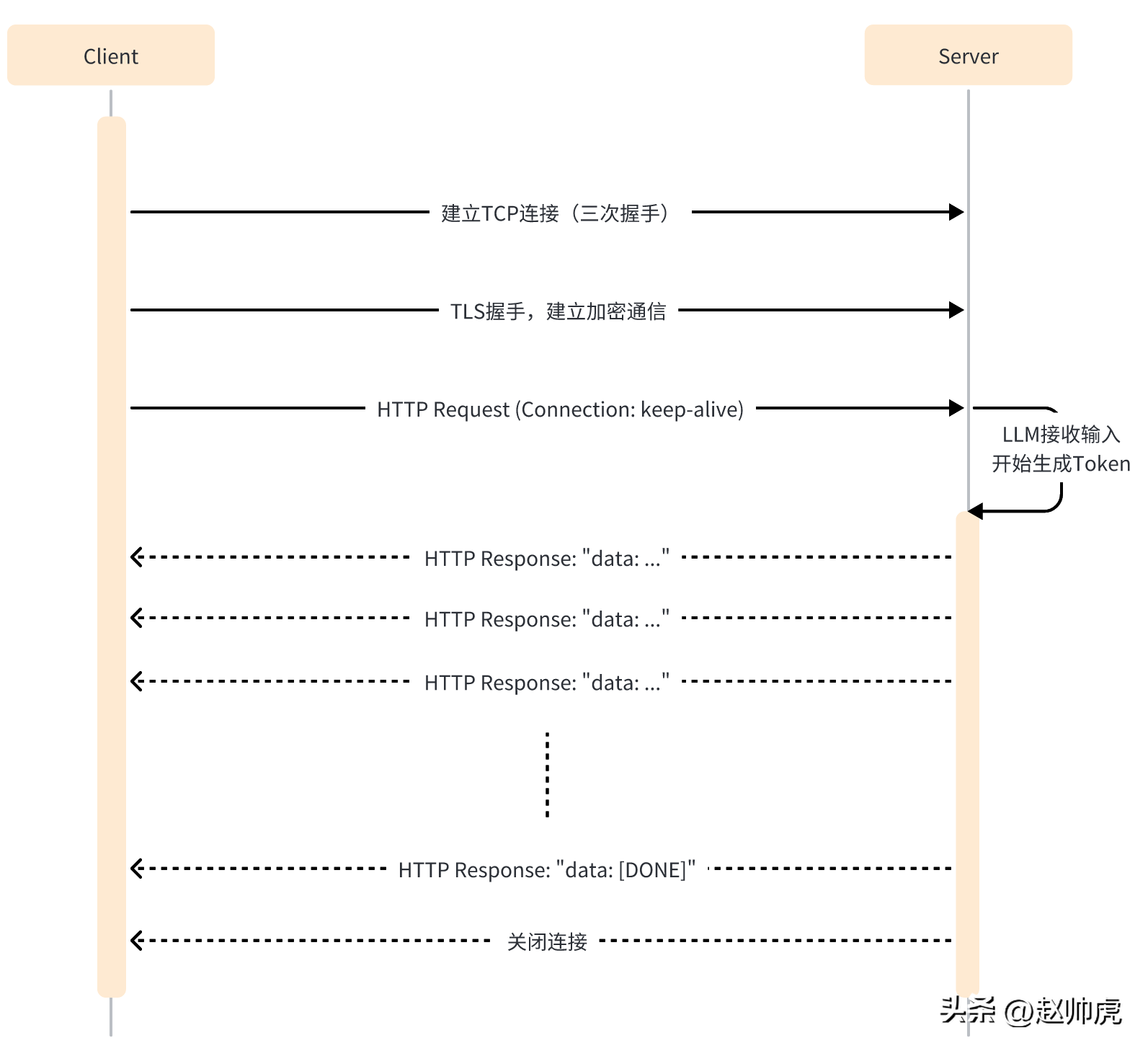
SSE masih menggunakan HTTP sebagai protokol penghantaran lapisan aplikasi, menggunakan sepenuhnya sambungan HTTP yang panjang keupayaan untuk melaksanakan keupayaan Push sebelah pelayan.
Dari peringkat kod, perbezaan antara mod SSE dan satu permintaan HTTP ialah:
- Keep perlu dihidupkan di sisi klien -alive memastikan sambungan tidak akan tamat masa.
- Pengepala respons HTTP mengandungi Content-Type=text/event-stream, Cache-Cnotallow=no-cache, dsb.
- Ibu tindak balas HTTP secara amnya ialah struktur seperti "data: ...".
- Respon HTTP mungkin mengandungi beberapa data kosong untuk mengelakkan tamat masa sambungan.
Ambil API ChatGPT sebagai contoh Apabila menghantar permintaan, menetapkan parameter strim kepada benar membolehkan ciri SSE, tetapi anda perlu memberi sedikit perhatian dalam SDK yang. membaca data.
Dalam mod biasa, selepas mendapat http.Response, gunakan ioutil.ReadAll untuk membaca data berikut:
func main() {payload := strings.NewReader(`{"model": "gpt-3.5-turbo","messages": [{"role": "user", "content": "大语言生成式模型是如何工作的"}],"max_tokens": 1024,"temperature": 1,"top_p": 1,"n": 1,"stream": false}`)client := &http.Client{}req, _ := http.NewRequest("POST", "https://api.openai.com/v1/chat/completions", payload)req.Header.Add("Content-Type", "application/json")req.Header.Add("Authorization", "Bearer <openai-token>")resp, err := client.Do(req)if err != nil {fmt.Println(err)return}defer resp.Body.Close()body, _ := ioutil.ReadAll(resp.Body)fmt.Println(string(body))}</openai-token>mengambil masa kira-kira 20s+ untuk dilaksanakan dan mendapat hasil yang lengkap:
{"id": "chatcmpl-7KklTf9mag5tyBXLEqM3PWQn4jlfD","object": "chat.completion","created": 1685180679,"model": "gpt-3.5-turbo-0301","usage": {"prompt_tokens": 21,"completion_tokens": 358,"total_tokens": 379},"choices": [{"message": {"role": "assistant","content": "大语言生成式模型通常采用神经网络来实现,具体工作流程如下:\n\n1. 数据预处理:将语料库中的文本数据进行预处理,包括分词、删除停用词(如“的”、“了”等常用词汇)、去重等操作,以减少冗余信息。\n\n2. 模型训练:采用递归神经网络(RNN)、长短期记忆网络(LSTM)或变种的Transformers等模型进行训练,这些模型都具有一定的记忆能力,可以学习到语言的一定规律,并预测下一个可能出现的词语。\n\n3. 模型应用:当模型完成训练后,可以将其应用于实际的生成任务中。模型接收一个输入文本串,并预测下一个可能出现的词语,直到达到一定长度或遇到结束符号为止。\n\n4. 根据生成结果对模型进行调优:生成的结果需要进行评估,如计算生成文本与语料库文本的相似度、流畅度等指标,以此来调优模型,提高其生成质量。\n\n总体而言,大语言生成式模型通过对语言的规律学习,从而生成高质量的文本。"},"finish_reason": "stop","index": 0}]}Jika kami menetapkan strim kepada benar tanpa membuat sebarang pengubahsuaian, jumlah permintaan menggunakan 28s+, yang mana mencerminkan Untuk banyak mesej strim:
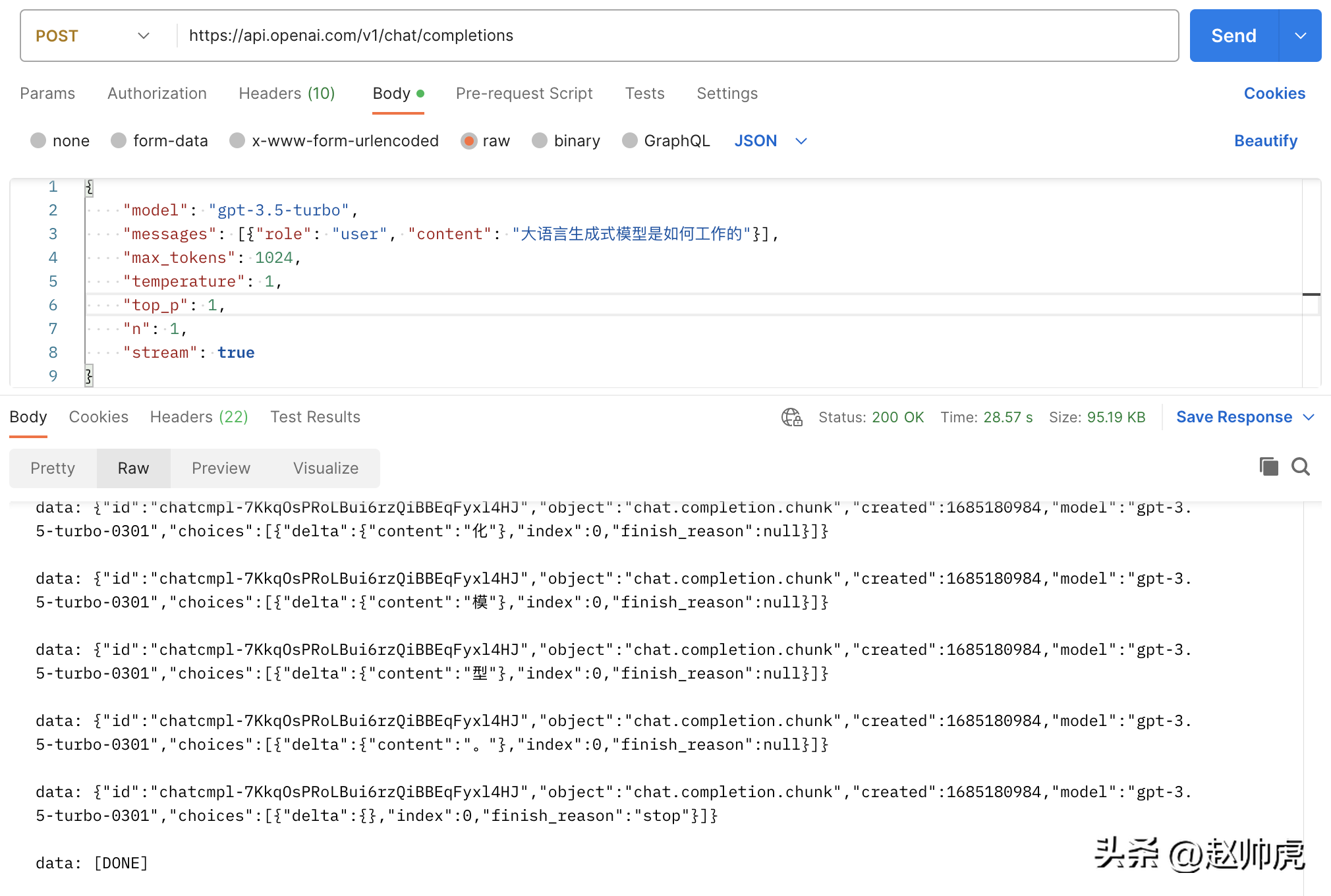
Gambar di atas ialah gambar Posmen yang memanggil api chatgpt, menggunakan mod ioutil.ReadAll. Untuk melaksanakan pembacaan aliran, kita boleh membaca http.Response.Body dalam segmen. Inilah sebabnya mengapa ini berfungsi:
- http.Response.Body adalah jenis io.ReaderCloser , lapisan bawah bergantung pada sambungan HTTP dan menyokong pembacaan strim.
- Data yang dikembalikan oleh SSE dipecahkan oleh aksara baris baharu n
Jadi kaedah pembetulan adalah untuk lulus bufio .NewReader(resp.Body)Balut dan baca dalam gelung untuk Kod adalah seperti berikut:
// stream event 结构体定义type ChatCompletionRspChoiceItem struct {Deltamap[string]string `json:"delta,omitempty"` // 只有 content 字段Indexint `json:"index,omitempty"`Logprobs *int`json:"logprobs,omitempty"`FinishReason string`json:"finish_reason,omitempty"`}type ChatCompletionRsp struct {IDstring`json:"id"`Objectstring`json:"object"`Created int `json:"created"` // unix secondModel string`json:"model"`Choices []ChatCompletionRspChoiceItem `json:"choices"`}func main() {payload := strings.NewReader(`{"model": "gpt-3.5-turbo","messages": [{"role": "user", "content": "大语言生成式模型是如何工作的"}],"max_tokens": 1024,"temperature": 1,"top_p": 1,"n": 1,"stream": true}`)client := &http.Client{}req, _ := http.NewRequest("POST", "https://api.openai.com/v1/chat/completions", payload)req.Header.Add("Content-Type", "application/json")req.Header.Add("Authorization", "Bearer "+apiKey)req.Header.Set("Accept", "text/event-stream")req.Header.Set("Cache-Control", "no-cache")req.Header.Set("Connection", "keep-alive")resp, err := client.Do(req)if err != nil {fmt.Println(err)return}defer resp.Body.Close()reader := bufio.NewReader(resp.Body)for {line, err := reader.ReadBytes('\n')if err != nil {if err == io.EOF {// 忽略 EOF 错误break} else {if netErr, ok := err.(net.Error); ok && netErr.Timeout() {fmt.Printf("[PostStream] fails to read response body, timeout\n")} else {fmt.Printf("[PostStream] fails to read response body, err=%s\n", err)}}break}line = bytes.TrimSuffix(line, []byte{'\n'})line = bytes.TrimPrefix(line, []byte("data: "))if bytes.Equal(line, []byte("[DONE]")) {break} else if len(line) > 0 {var chatCompletionRsp ChatCompletionRspif err := json.Unmarshal(line, &chatCompletionRsp); err == nil {fmt.Printf(chatCompletionRsp.Choices[0].Delta["content"])} else {fmt.Printf("\ninvalid line=%s\n", line)}}}fmt.Println("the end")}Selepas membaca bahagian klien, mari kita lihat bahagian pelayan. Sekarang kami cuba mengejek pelayan chatgpt dan mengembalikan sekeping teks verbatim. Dua perkara terlibat di sini:
- Pengepala Respons perlu menetapkan Sambungan untuk kekal hidup dan Jenis Kandungan kepada strim teks/acara.
- Selepas menulis respons, ia perlu disiram kepada pelanggan.
Kodnya adalah seperti berikut:
func streamHandler(w http.ResponseWriter, req *http.Request) {w.Header().Set("Connection", "keep-alive")w.Header().Set("Content-Type", "text/event-stream")w.Header().Set("Cache-Control", "no-cache")var chatCompletionRsp ChatCompletionRsprunes := []rune(`大语言生成式模型通常使用深度学习技术,例如循环神经网络(RNN)或变压器(Transformer)来建模语言的概率分布。这些模型接收前面的词汇序列,并利用其内部神经网络结构预测下一个词汇的概率分布。然后,模型将概率最高的词汇作为生成的下一个词汇,并递归地生成一个词汇序列,直到到达最大长度或遇到一个终止符号。在训练过程中,模型通过最大化生成的文本样本的概率分布来学习有效的参数。为了避免模型产生过于平凡的、重复的、无意义的语言,我们通常会引入一些技巧,如dropout、序列扰动等。大语言生成模型的重要应用包括文本生成、问答系统、机器翻译、对话建模、摘要生成、文本分类等。`)for _, r := range runes {chatCompletionRsp.Choices = []ChatCompletionRspChoiceItem{{Delta: map[string]string{"content": string(r)}},}bs, _ := json.Marshal(chatCompletionRsp)line := fmt.Sprintf("data: %s\n", bs)fmt.Fprintf(w, line)if f, ok := w.(http.Flusher); ok {f.Flush()}time.Sleep(time.Millisecond * 100)}fmt.Fprintf(w, "data: [DONE]\n")}func main() {http.HandleFunc("/stream", streamHandler)http.ListenAndServe(":8088", nil)}Dalam senario sebenar, data yang akan dikembalikan datang daripada perkhidmatan atau fungsi lain panggilan. Jika Masa pemulangan panggilan perkhidmatan atau fungsi ini tidak stabil, yang mungkin menyebabkan pelanggan tidak menerima mesej untuk masa yang lama, jadi kaedah pemprosesan umum ialah:
- Panggilan kepada pihak ketiga dibuat dalam goroutine.
- Buat pemasa mengikut masa. Tandakan dan hantar mesej kosong kepada pelanggan.
- Buat saluran tamat masa untuk mengelakkan masa respons terlalu lama.
Untuk membaca data daripada saluran yang berbeza, pilih ialah kata kunci yang bagus, seperti kod demo ini:
// 声明一个 event channel// 声明一个 time.Tick channel// 声明一个 timeout channelselect {case ev := <h2 id="Ringkasan">Ringkasan </h2> <p style="text-align: justify;"><span style="color: #333333;">Proses menjana dan bertindak balas kepada keseluruhan hasil model bahasa yang besar agak panjang, tetapi respons yang dijana oleh token adalah agak pantas ChatGPT menggabungkan sepenuhnya ciri ini dengan teknologi SSE untuk muncul perkataan demi perkataan . Reply telah mencapai peningkatan kualitatif dalam pengalaman pengguna. </span></p><p style="text-align: justify;"><span style="color: #333333;">Melihat model generatif, sama ada LLAMA/Little Alpaca (tidak tersedia secara komersial) atau Stable Diffusion/Midjourney. Apabila menyediakan perkhidmatan dalam talian, teknologi SSE boleh digunakan untuk meningkatkan pengalaman pengguna dan menjimatkan sumber pelayan. </span></p>Atas ialah kandungan terperinci Bagaimanakah ChatGPT mengeluarkan perkataan demi perkataan?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Panduan langkah demi langkah untuk menggunakan Groq Llama 3 70B secara tempatan
Jun 10, 2024 am 09:16 AM
Panduan langkah demi langkah untuk menggunakan Groq Llama 3 70B secara tempatan
Jun 10, 2024 am 09:16 AM
Penterjemah |. Tinjauan Bugatti |. Chonglou Artikel ini menerangkan cara menggunakan enjin inferens GroqLPU untuk menjana respons sangat pantas dalam JanAI dan VSCode. Semua orang sedang berusaha membina model bahasa besar (LLM) yang lebih baik, seperti Groq yang memfokuskan pada bahagian infrastruktur AI. Sambutan pantas daripada model besar ini adalah kunci untuk memastikan model besar ini bertindak balas dengan lebih cepat. Tutorial ini akan memperkenalkan enjin parsing GroqLPU dan cara mengaksesnya secara setempat pada komputer riba anda menggunakan API dan JanAI. Artikel ini juga akan menyepadukannya ke dalam VSCode untuk membantu kami menjana kod, kod refactor, memasukkan dokumentasi dan menjana unit ujian. Artikel ini akan mencipta pembantu pengaturcaraan kecerdasan buatan kami sendiri secara percuma. Pengenalan kepada enjin inferens GroqLPU Groq
 Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Tujuh Soalan Temuduga Teknikal GenAI & LLM yang Cool
Jun 07, 2024 am 10:06 AM
Untuk mengetahui lebih lanjut tentang AIGC, sila layari: 51CTOAI.x Komuniti https://www.51cto.com/aigc/Translator|Jingyan Reviewer|Chonglou berbeza daripada bank soalan tradisional yang boleh dilihat di mana-mana sahaja di Internet memerlukan pemikiran di luar kotak. Model Bahasa Besar (LLM) semakin penting dalam bidang sains data, kecerdasan buatan generatif (GenAI) dan kecerdasan buatan. Algoritma kompleks ini meningkatkan kemahiran manusia dan memacu kecekapan dan inovasi dalam banyak industri, menjadi kunci kepada syarikat untuk kekal berdaya saing. LLM mempunyai pelbagai aplikasi Ia boleh digunakan dalam bidang seperti pemprosesan bahasa semula jadi, penjanaan teks, pengecaman pertuturan dan sistem pengesyoran. Dengan belajar daripada sejumlah besar data, LLM dapat menjana teks
 Model besar juga sangat berkuasa dalam ramalan siri masa! Pasukan China mengaktifkan keupayaan baharu LLM dan mencapai SOTA melebihi model tradisional
Apr 11, 2024 am 09:43 AM
Model besar juga sangat berkuasa dalam ramalan siri masa! Pasukan China mengaktifkan keupayaan baharu LLM dan mencapai SOTA melebihi model tradisional
Apr 11, 2024 am 09:43 AM
Potensi model bahasa besar dirangsang - ramalan siri masa berketepatan tinggi boleh dicapai tanpa melatih model bahasa besar, mengatasi semua model siri masa tradisional. Monash University, Ant dan IBM Research bersama-sama membangunkan rangka kerja umum yang berjaya mempromosikan keupayaan model bahasa besar untuk memproses data jujukan merentas modaliti. Rangka kerja telah menjadi inovasi teknologi yang penting. Ramalan siri masa bermanfaat untuk membuat keputusan dalam sistem kompleks biasa seperti bandar, tenaga, pengangkutan, penderiaan jauh, dsb. Sejak itu, model besar dijangka merevolusikan perlombongan data siri masa/spatiotemporal. Pasukan penyelidikan rangka kerja pengaturcaraan semula model bahasa besar am mencadangkan rangka kerja umum untuk menggunakan model bahasa besar dengan mudah untuk ramalan siri masa umum tanpa sebarang latihan. Dua teknologi utama dicadangkan terutamanya: pengaturcaraan semula input masa; Masa-
 Sebarkan model bahasa besar secara setempat dalam OpenHarmony
Jun 07, 2024 am 10:02 AM
Sebarkan model bahasa besar secara setempat dalam OpenHarmony
Jun 07, 2024 am 10:02 AM
Artikel ini akan membuka sumber hasil "Pengedaran Tempatan Model Bahasa Besar dalam OpenHarmony" yang ditunjukkan pada Persidangan Teknologi OpenHarmony ke-2 alamat sumber terbuka: https://gitee.com/openharmony-sig/tpc_c_cplusplus/blob/master/thirdparty/. InferLLM/docs/ hap_integrate.md. Idea dan langkah pelaksanaan adalah untuk memindahkan rangka kerja inferens model LLM ringan InferLLM kepada sistem standard OpenHarmony dan menyusun produk binari yang boleh dijalankan pada OpenHarmony. InferLLM ialah L yang mudah dan cekap
 Hongmeng Smart Travel S9 dan persidangan pelancaran produk baharu senario penuh, beberapa produk baharu blockbuster dikeluarkan bersama-sama
Aug 08, 2024 am 07:02 AM
Hongmeng Smart Travel S9 dan persidangan pelancaran produk baharu senario penuh, beberapa produk baharu blockbuster dikeluarkan bersama-sama
Aug 08, 2024 am 07:02 AM
Petang ini, Hongmeng Zhixing secara rasmi mengalu-alukan jenama baharu dan kereta baharu. Pada 6 Ogos, Huawei mengadakan persidangan pelancaran produk baharu Hongmeng Smart Xingxing S9 dan senario penuh Huawei, membawakan sedan perdana pintar panoramik Xiangjie S9, M7Pro dan Huawei novaFlip baharu, MatePad Pro 12.2 inci, MatePad Air baharu, Huawei Bisheng With banyak produk pintar semua senario baharu termasuk pencetak laser siri X1, FreeBuds6i, WATCHFIT3 dan skrin pintar S5Pro, daripada perjalanan pintar, pejabat pintar kepada pakaian pintar, Huawei terus membina ekosistem pintar senario penuh untuk membawa pengguna pengalaman pintar Internet Segala-galanya. Hongmeng Zhixing: Pemerkasaan mendalam untuk menggalakkan peningkatan industri kereta pintar Huawei berganding bahu dengan rakan industri automotif China untuk menyediakan
 Rangsang keupayaan penaakulan spatial model bahasa besar: petua visualisasi berfikir
Apr 11, 2024 pm 03:10 PM
Rangsang keupayaan penaakulan spatial model bahasa besar: petua visualisasi berfikir
Apr 11, 2024 pm 03:10 PM
Model bahasa besar (LLM) menunjukkan prestasi yang mengagumkan dalam pemahaman bahasa dan pelbagai tugas penaakulan. Walau bagaimanapun, peranan mereka dalam penaakulan spatial, aspek utama kognisi manusia, masih belum dipelajari. Manusia mempunyai keupayaan untuk mencipta imej mental objek ghaib dan tindakan melalui proses yang dikenali sebagai mata minda, membolehkan untuk membayangkan dunia ghaib. Diilhamkan oleh keupayaan kognitif ini, penyelidik mencadangkan "Visualization of Thought" (VoT). VoT bertujuan untuk membimbing penaakulan spatial LLM dengan menggambarkan tanda penaakulan mereka, dengan itu membimbing langkah penaakulan seterusnya. Penyelidik menggunakan VoT untuk tugas penaakulan spatial berbilang hop, termasuk navigasi bahasa semula jadi, penglihatan
 Merumuskan 374 karya berkaitan, pasukan Tao Dacheng, bersama-sama dengan Universiti Hong Kong dan UMD, mengeluarkan ulasan terbaru tentang penyulingan pengetahuan LLM
Mar 18, 2024 pm 07:49 PM
Merumuskan 374 karya berkaitan, pasukan Tao Dacheng, bersama-sama dengan Universiti Hong Kong dan UMD, mengeluarkan ulasan terbaru tentang penyulingan pengetahuan LLM
Mar 18, 2024 pm 07:49 PM
Model Bahasa Besar (LLM) telah berkembang pesat dalam dua tahun yang lalu, dan beberapa model dan produk yang fenomenal telah muncul, seperti GPT-4, Gemini, Claude, dll., tetapi kebanyakannya adalah sumber tertutup. Terdapat jurang yang besar antara kebanyakan LLM sumber terbuka yang kini boleh diakses oleh komuniti penyelidikan dan LLM sumber tertutup Oleh itu, meningkatkan keupayaan LLM sumber terbuka dan model kecil lain untuk mengurangkan jurang antara mereka dan model besar sumber tertutup telah menjadi tempat tumpuan penyelidikan. dalam padang ini. Keupayaan berkuasa LLM, terutamanya LLM sumber tertutup, membolehkan penyelidik saintifik dan pengamal industri menggunakan output dan pengetahuan model besar ini apabila melatih model mereka sendiri. Proses ini pada asasnya adalah penyulingan pengetahuan (Knowledge, Dist
 OWASP mengeluarkan senarai semak keselamatan dan tadbir urus rangkaian model bahasa besar
Apr 17, 2024 pm 07:31 PM
OWASP mengeluarkan senarai semak keselamatan dan tadbir urus rangkaian model bahasa besar
Apr 17, 2024 pm 07:31 PM
Risiko terbesar yang dihadapi oleh teknologi kecerdasan buatan pada masa ini ialah pembangunan dan kelajuan aplikasi model bahasa besar (LLM) dan teknologi kecerdasan buatan generatif telah jauh melebihi kelajuan keselamatan dan tadbir urus. Penggunaan AI generatif dan produk model bahasa besar daripada syarikat seperti OpenAI, Anthropic, Google dan Microsoft berkembang dengan pesat. Pada masa yang sama, penyelesaian model bahasa besar sumber terbuka juga berkembang pesat komuniti kecerdasan buatan sumber terbuka seperti HuggingFace telah menyediakan sejumlah besar model sumber terbuka, set data dan aplikasi AI. Untuk menggalakkan pembangunan kecerdasan buatan, organisasi industri seperti OWASP, OpenSSF dan CISA sedang giat membangun dan menyediakan aset utama untuk keselamatan dan tadbir urus kecerdasan buatan, seperti OWASPAIExchange,
