
 pangkalan data
tutorial mysql
Bagaimana untuk memindahkan sistem tanpa sensor SQL Server ke MySQL
pangkalan data
tutorial mysql
Bagaimana untuk memindahkan sistem tanpa sensor SQL Server ke MySQL
Bagaimana untuk memindahkan sistem tanpa sensor SQL Server ke MySQL

1. Gambaran Keseluruhan Seni Bina
Melalui analisis kesesakan sistem sedia ada, kami mendapati bahawa kecacatan teras tertumpu pada cache data pesanan bertaburan, yang membawa kepada ketidakkonsistenan di semua hujung data. Setiap aplikasi pesanan disambungkan terus ke pangkalan data, yang menjadikannya berskala. Melalui amalan, kami menulis middleware untuk mengabstrak dan menyatukan lapisan akses data, dan membina cache pesanan berdasarkan cermin seni bina penempatan pangkalan data untuk mengurus data panas secara seragam, menyelesaikan perbezaan antara hujung yang berbeza.
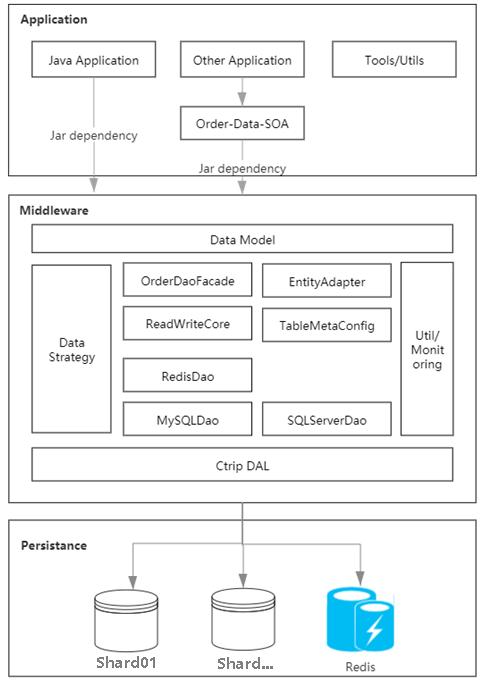
Rajah 1.1 Gambar rajah seni bina sistem storan
2. Senario aplikasi
1 >
Kelajuan daripada penyerahan pesanan kepada keterlihatan pada setiap hujung ialah salah satu penunjuk teras perkhidmatan storan Kami telah mengoptimumkan pautan utama rantaian data, meliputi penyegerakan pesanan baharu, tolakan mesej masa nyata, pembinaan indeks pertanyaan, dan pengarkiban luar talian platform data Tunggu pautan utama untuk memastikan kelajuan ketibaan data dalam sistem besar adalah dalam masa 3 saat, iaitu, pengguna boleh melompat ke senarai Jenama Saya serta-merta selepas membuat pesanan. Apabila pengguna baharu membuat pesanan, perkhidmatan penyegerakan berfungsi sebagai pintu masuk pautan data untuk menulis data pesanan pengguna ke dalam perpustakaan pesanan melalui perisian tengah pada masa ini, perisian tengah juga melengkapkan pembinaan pesanan cache; Apabila pesanan Selepas melengkapkan pembinaan gelagat pergudangan dan data tempat liputan, mesej pesanan dibuang dan dikeluarkan ke setiap subsistem dalam masa nyata Apabila pesanan baharu dimasukkan pergudangan, indeks ES butiran pesanan segera dibina untuk menyediakan sokongan mendapatkan semula untuk pihak ketiga Akhir sekali, platform data T+1 melaksanakan pengarkiban data harian untuk digunakan oleh pelbagai perniagaan luar talian seperti BI; .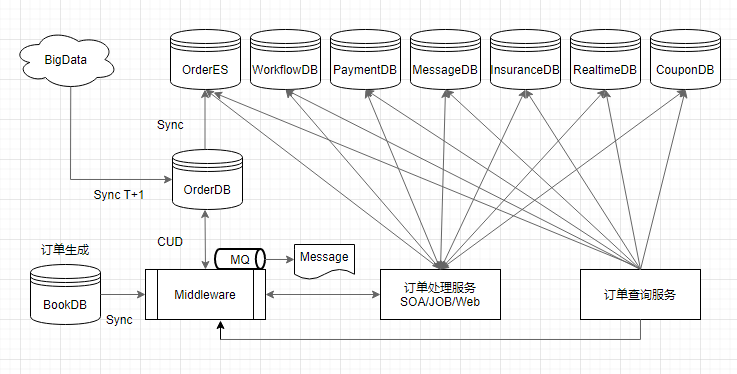
- Pertanyaan dalam talian terutamanya berdasarkan caching pesanan Sebaik sahaja pesanan diserahkan, cache hotspot dibina untuk melegakan tekanan pertanyaan, dan ia boleh sah untuk masa yang lama mengikut tempoh. parameter masa yang dikonfigurasikan.
- Dalam senario pertanyaan bukan dalam talian, push mesej masa nyata digunakan dan dihantar dalam mod T+1 digabungkan dengan gudang data Hive Mesej pesanan diakses di mana-mana sahaja data pesanan jangka panjang diperlukan (seperti laporan masa nyata) Dikira dalam masa nyata. Apabila menjalankan analisis data berskala besar, BI luar talian akan menggunakan jadual Hive dan melakukan penyegerakan data melalui akses frekuensi rendah daripada pangkalan data semasa tempoh puncak rendah pada awal pagi setiap hari.
Selepas analisis data, sistem pesanan biasanya membaca lebih banyak dan menulis kurang Untuk berkongsi data pertanyaan panas dan mengurangkan beban DB, cara yang berkesan adalah dengan memperkenalkan cache, seperti yang ditunjukkan dalam Rajah 3.1 cache ditanya terlebih dahulu, jika terdapat data cache, hasilnya akan dikembalikan secara langsung jika tiada hit dalam cache, DB akan ditanya, dan data hasil DB akan disahkan mengikut dasar konfigurasi berlalu, data DB akan ditulis ke cache untuk kegunaan pertanyaan berikutnya, jika tidak, ia tidak akan ditulis ke cache , dan akhirnya mengembalikan hasil pertanyaan DB.

Rajah 3.1 Reka bentuk asas cache pesanan
Mengenai overhed perkakasan selepas memperkenalkan komponen cache baharu, ia boleh dikurangkan dengan menumpu sumber perkakasan asal yang berselerak setiap aplikasi. Jumlah kos, tetapi pengurusan berpusat juga akan membawa cabaran kebolehgunaan dan isu ketekalan data, jadi adalah perlu untuk menjalankan sepenuhnya penilaian kapasiti, anggaran trafik dan analisis nilai jadual cache sistem sedia ada. Hanya cache jadual data panas dengan volum akses tinggi Melalui reka bentuk struktur cache yang sesuai, pemampatan data dan strategi penghapusan cache, kami boleh memaksimumkan kadar hit cache dan membuat pertukaran yang baik antara kapasiti cache, kos perkakasan dan ketersediaan.
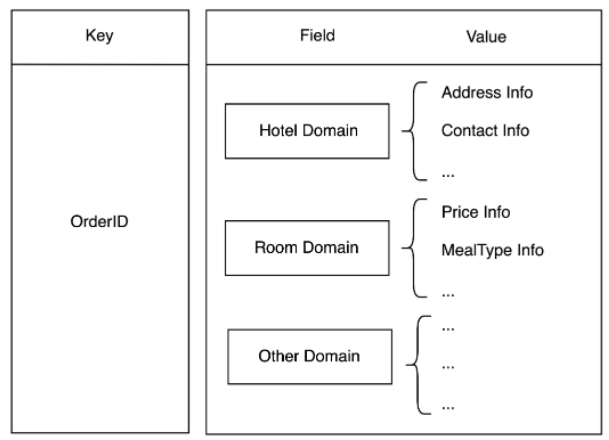
Reka bentuk cache tradisional ialah satu rekod jadual pangkalan data sepadan dengan satu data cache. Dalam sistem pesanan, adalah sangat biasa untuk menanyakan beberapa jadual untuk satu pesanan Jika reka bentuk tradisional diguna pakai, bilangan akses Redis dalam pertanyaan pengguna meningkat dengan bilangan jadual ini mempunyai rangkaian IO yang besar. memakan masa yang lama. Apabila mengambil stok data trafik dimensi jadual, kami mendapati bahawa sesetengah jadual sering ditanya bersama-sama dan kurang daripada 30% daripada jadual mempunyai lebih daripada 90% trafik pertanyaan Dari segi perniagaan, mereka boleh dibahagikan kepada yang sama model domain abstrak, dan kemudian disimpan berdasarkan struktur cincang, seperti Rajah 3.2 menggunakan nombor pesanan sebagai kunci, nama medan sebagai medan dan data medan sebagai nilai.
Dengan cara ini, tidak kira ia adalah satu jadual atau pertanyaan berbilang jadual, setiap pesanan hanya perlu mengakses Redis sekali, yang bukan sahaja mengurangkan kunci, tetapi juga mengurangkan bilangan pertanyaan berbilang jadual dan meningkatkan prestasi. Pada masa yang sama, nilai dimampatkan berdasarkan protostuff, yang juga mengurangkan ruang penyimpanan Redis dan overhed trafik rangkaian seterusnya.

Rajah 3.2 Penerangan ringkas tentang struktur storan berasaskan domain
2 Proses migrasi tanpa rugi
Cara mencapai migrasi panas tanpa rugi ialah keseluruhan projek Tempat yang paling mencabar. Kerja persediaan kami adalah untuk menyelesaikan pembangunan perisian tengah terlebih dahulu, dengan tujuan mengasingkan pangkalan data dan aplikasi lapisan perniagaan, supaya reka bentuk proses dapat dijalankan. Kedua, lapisan Dao abstrak melaksanakan domainisasi, dan lapisan domain data menyediakan perkhidmatan data kepada aplikasi Di bawah domain, dua pangkalan data, SQLServer dan MySQL, disesuaikan dan dibungkus secara seragam. Berdasarkan ini, migrasi haba tanpa kehilangan boleh dilaksanakan untuk reka bentuk proses berikut.
Pangkalan data dwi SQLServer dan MySQL berada dalam talian, melaksanakan penulisan berganda, SQLServer penulisan utama dan MySQL penulisan sekunder segerak Jika operasi SQLServer gagal, keseluruhan operasi gagal dan transaksi penulisan berganda adalah berguling ke belakang.
Tambah kerja penyegerakan antara SQLServer dan MySQL untuk menanyakan data yang diubah dalam tetingkap masa terkini SQLServer dalam masa nyata untuk mengesahkan konsistensi entri dalam MySQL memastikan penulisan berganda Ini amat berguna apabila terdapat ketidakkonsistenan yang tidak dijangka antara kedua-dua pihak dalam tempoh ini, terutamanya apabila masih terdapat akses terus kepada aplikasi SQL Server.
Perisian tengah direka bentuk dengan sistem konfigurasi yang menyokong mana-mana dimensi pertanyaan utama Ia boleh mengarahkan sumber data dengan tepat ke SQLServer atau MySQL mengikut konfigurasi, dan boleh mengawal sama ada untuk memuatkannya ke dalam cache pesanan selepas membaca . Tetapan awal adalah untuk memuatkan sumber data SQLServer sahaja untuk mengelakkan lompatan data cache yang disebabkan oleh ketidakkonsistenan data antara kedua-dua pangkalan data. Pada peringkat awal, skala kelabu boleh disediakan dan sebilangan kecil jadual bukan teras boleh disambungkan terus ke MySQL untuk pengesahan bagi memastikan kebolehpercayaan. Setelah jangkaan ketekalan data lewat dicapai, cache pesanan boleh dimuatkan pada pangkalan data yang ditentukan sesuka hati.
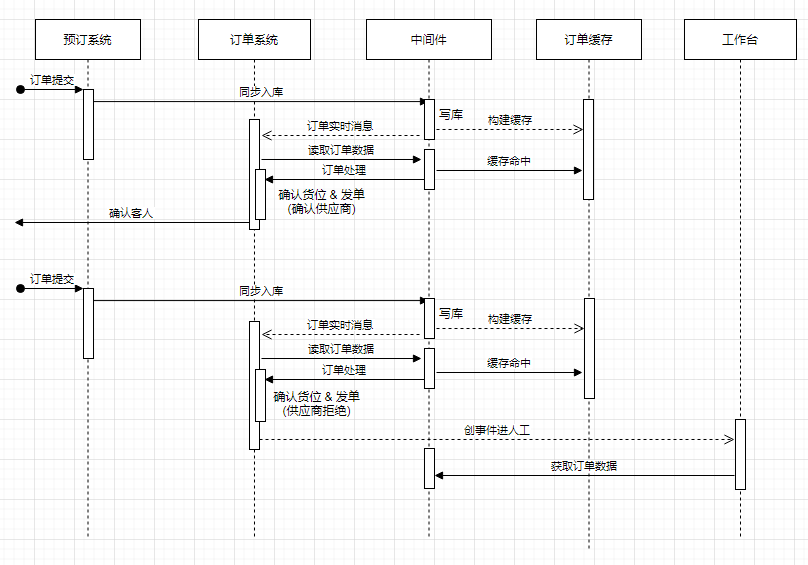
Selepas memastikan ketekalan data semasa membuat pertanyaan data, dasar trafik menyokong penulisan tunggal ke pangkalan data mengikut mana-mana dimensi yang boleh dikawal dalam Rajah 3.3. Dalam projek sebenar, tulisan tunggal dilaksanakan terutamanya dalam dimensi jadual Apabila jadual tertentu dikonfigurasikan dengan MySQL tulis tunggal, semua tingkah laku CRUD yang melibatkan jadual diarahkan ke MySQL, termasuk sumber beban cache.
Akhirnya, pesanan pesanan yang dihantar secara luaran disatukan melalui perisian tengah Semua mesej dihantar berdasarkan operasi CUD perisian tengah dan tiada kaitan dengan pangkalan data fizikal , sumber data mesej adalah telus dan boleh dipautkan di atas Semua operasi proses dan pautan data kekal konsisten.
Rajah 3.3 Pengenalan kepada proses operasi
3. Sambungan gudang data
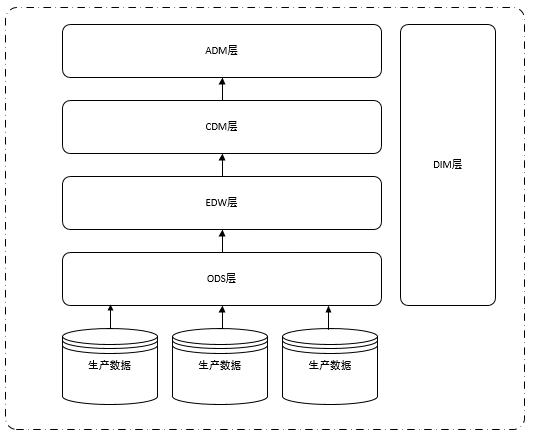
Untuk memudahkan pemahaman data pengeluaran kepada data Perpindahan data lapisan ODS gudang adalah telus kepada pengguna hiliran Berikut ialah pengenalan ringkas kepada sistem hierarki gudang data konvensional. Biasanya gudang data terbahagi kepada lima lapisan: ODS (lapisan data asal), DIM (dimensi), EDW (gudang data perusahaan), CDM (lapisan model biasa), ADM (lapisan model aplikasi),
Seperti yang ditunjukkan di bawah:

Rajah 3.4 Struktur hierarki gudang data
Seperti yang dapat dilihat daripada Rajah 3.4, setiap lapisan gudang data bergantung pada data lapisan ODS Agar tidak menjejaskan semua aplikasi platform data, kita hanya perlu menggantikan perpustakaan pesanan asal Sumber data lapisan ODS boleh dipindahkan daripada SQLServer ke perpustakaan MySQL.
Ia boleh dilihat secara intuitif dari gambar bahawa migrasi hanya perlu menukar sumber data Ia tidak terlalu menyusahkan, tetapi untuk memastikan kualiti data, kami telah melakukan banyak pra-kerja, seperti sebagai: DBA menyegerakkan data pengeluaran kepada pengeluaran terlebih dahulu pangkalan data MySQL, penyegerakan masa nyata data MySQL, pengesahan ketekalan data pada kedua-dua belah pengeluaran, penyegerakan data sisi MySQL ke lapisan ODS, pengesahan ketekalan data lapisan ODS dan data kerja penyegerakan lapisan ODS asal. penukaran sumber, dsb.
Antaranya, semakan konsistensi data pada kedua-dua belah pengeluaran dan semakan konsistensi data pada lapisan ODS gudang data adalah yang paling kompleks dan memakan masa yang paling lama Anda mesti memastikan bahawa setiap jadual dan medan mesti konsisten sebelum menukar sumber data. Walau bagaimanapun, dalam operasi sebenar, ia tidak boleh konsisten sepenuhnya. Mengikut situasi sebenar, mengendalikan jenis masa, ketepatan nilai titik terapung dan tempat perpuluhan dengan betul, dsb.
Berikut ialah pengenalan kepada proses keseluruhan:
Pertama sekali, untuk pengesahan ketekalan data dalam talian, kami membangunkan kerja penyegerakan dalam talian untuk membandingkan data SQLServer dengan MySQL data , apabila ketidakkonsistenan ditemui, data MySQL dikemas kini berdasarkan data SQLServer untuk memastikan konsistensi data pada kedua-dua belah pihak.
Kedua, untuk pengesahan ketekalan data luar talian, kami bekerjasama dengan rakan sekerja gudang data untuk menyegerakkan data sisi MySQL ke lapisan ODS (gunakan nama pangkalan data untuk membezakan sama ada ia adalah jadual SQLServer atau MySQL), dan menggabungkan tugas yang dijadualkan dengan Tugas-tugas di bahagian SQL Server hendaklah sekonsisten mungkin dalam masa. Selepas data di kedua-dua belah pihak disediakan, kami membangunkan penjana skrip pengesahan data luar talian Berdasarkan metadata gudang data, kerja penyegerakan telah dijana untuk setiap jadual dan digunakan ke platform penjadualan.
Tugas penyegerakan akan bergantung pada data penyegerakan lapisan ODS pada kedua-dua belah pihak Selepas penyegerakan data T+1 selesai, pengesahan ketekalan akan dilakukan, nombor pesanan yang tidak konsisten akan direkodkan dalam jadual butiran yang tidak konsisten. jumlah data yang tidak konsisten akan dikira. Kemudian kami membuat laporan pada platform pelaporan layan diri dan menghantar statistik harian jadual tidak konsisten dan jumlah ketidakkonsistenan ke peti mel Kami menyelesaikan masalah jadual tidak konsisten setiap hari untuk mencari masalah, melaraskan strategi perbandingan dan mengemas kini kerja perbandingan . Proses umum adalah seperti berikut:
Rajah 3.5 Proses pengesahan ketekalan keseluruhan
Akhir sekali, apabila data dalam talian dan luar talian beransur-ansur menjadi konsisten, kami akan Data sumber SQLServer asal yang disegerakkan kepada kerja lapisan ODS telah ditukar kepada MySQL. Sesetengah pelajar di sini mungkin mempunyai soalan: Mengapa tidak menggunakan terus jadual dalam lapisan ODS pada bahagian MySQL? Sebabnya, mengikut statistik, terdapat beribu-ribu pekerjaan yang bergantung pada jadual lapisan ODS asal Jika tugas bergantung itu ditukar ke jadual ODS sisi MySQL, beban kerja pengubahsuaian akan menjadi sangat berat, jadi kami terus menukar ODS asal. sumber data penyegerakan lapisan ke dalam MySQL.
Dalam operasi sebenar, pemotongan sumber data tidak boleh dilakukan secara serentak Kami melakukannya dalam tiga kelompok Kami mula-mula mencari sedozen jadual yang kurang penting sebagai kumpulan pertama, kami menjalankannya selama dua minggu mengumpul Maklum Balas mengenai isu data hiliran. Kumpulan pertama sampel berjaya dianalisis dua minggu kemudian, dan kami tidak menerima masalah data dalam laporan hiliran, yang membuktikan kebolehpercayaan kualiti data sampel. Kemudian bahagikan ratusan meja yang tinggal kepada dua kelompok mengikut kepentingannya dan teruskan memotong sehingga ia selesai.
Pada ketika ini, kami telah menyelesaikan pemindahan pangkalan data pesanan daripada SQLServer ke MySQL pada lapisan gudang data.
4. Isu teras yang diperhalusi
Malah, tidak kira betapa teliti analisis dan reka bentuk, ia tidak dapat dielakkan untuk menghadapi pelbagai cabaran semasa proses pelaksanaan. Kami telah merumuskan beberapa masalah klasik Walaupun masalah besar dan kecil ini akhirnya diselesaikan melalui cara teknikal dan matlamat telah dicapai, saya percaya bahawa anda pembaca mesti mempunyai penyelesaian yang lebih baik.
1. Cara memantau migrasi trafik SQLServer & MySQL
Sistem pesanan melibatkan sejumlah besar aplikasi dan jadual, satu aplikasi sepadan dengan 1 hingga n jadual sepadan dengan 1 hingga n aplikasi adalah perhubungan banyak-ke-banyak biasa. Seperti yang ditunjukkan dalam Rajah 4.1, untuk aplikasi lapisan atas, beralih daripada satu pangkalan data SQLServer ke pangkalan data MySQL yang lain, proses asas dibahagikan kepada sekurang-kurangnya langkah berikut mengikut bab proses operasi:
Dari SQLServer Penulisan tunggal menjadi SQLServer dan MySQL dwi-tulisan
Dari SQLServer bacaan tunggal kepada MySQL bacaan tunggal
Daripada dwi- menulis SQLServer dan MySQL menjadi Hanya tulis MySQL
SQLServer Luar Talian

Rajah 4.1 Gambar rajah hubungan antara aplikasi, pangkalan data dan jadual
Mengganti sistem pangkalan data dalam persekitaran pengeluaran adalah seperti menukar tayar di lebuh raya tanpa henti Ia perlu mengekalkan kelajuan asal dan tidak sensitif kepada pengguna, jika tidak, akibatnya tidak dapat dibayangkan.
Penulisan dua kali, bacaan tunggal dan proses penulisan tunggal dalam proses pensuisan saling berkait dan bergantung pada satu sama lain langkah demi langkah Sebagai kaedah pemantauan reka bentuk sokongan, adalah perlu untuk mengesahkan bahawa operasi sebelumnya mencapai kesan yang diharapkan sebelum meneruskan yang seterusnya. Jika anda melangkau atau meneruskan ke langkah seterusnya secara terburu-buru tanpa menukar dengan bersih, sebagai contoh, jika anda mula membaca data MySQL sebelum penulisan dua kali benar-benar konsisten, anda mungkin tidak menemui data ini atau mencari data kotor! Maka adalah perlu untuk memantau bacaan dan penulisan setiap operasi CRUD, dan mencapai kawalan pembahagian trafik visual 360 darjah tanpa titik buta semasa proses penghijrahan Apa yang anda lihat ialah apa yang anda perolehi. Kaedah khusus adalah seperti berikut:
Semua aplikasi disambungkan ke middleware, dan CRUD dikawal oleh middleware untuk membaca dan menulis DB dan jadual yang mana mengikut konfigurasi
Maklumat terperinci bagi setiap operasi baca dan tulis ditulis kepada ES dan dipaparkan secara visual pada Kibana dan Grafana, dan melalui DBTrace, anda boleh mengetahui DB mana setiap SQL dilaksanakan pada
Langkah demi langkah konfigurasikan DB dwi-tulis mengikut tahap aplikasi, bandingkan, membaiki dan merekodkan perbezaan DB pada kedua-dua belah dalam masa nyata melalui kerja penyegerakan, dan kemudian sahkan ketidakkonsistenan akhir dalam dwi-tulis melalui T+1 luar talian, dan seterusnya sehingga dwi-tulisan adalah konsisten; pemantauan dan DBTrace, ia disahkan bahawa tiada bacaan SQLServer sama sekali, yang bermaksud bahawa bacaan tunggal MySQL selesai Dengan mengambil kira keadaan kunci utama yang ditambah secara automatik, kami menggunakan kaedah menulis ke SQL Server dalam kelompok mengikut. kepada dimensi jadual, sehingga semua jadual ditulis kepada MySQL sahaja.
Ringkasnya, penyelesaian asas adalah menggunakan perisian tengah untuk berfungsi sebagai saluran paip untuk semua aplikasi yang disambungkan, memerhatikan pengedaran trafik dengan memaparkan gelagat lapisan aplikasi dalam masa nyata dan menggabungkannya dengan pangkalan data syarikat Alat visualisasi Trace mengesahkan bahawa gelagat penukaran trafik aplikasi adalah konsisten dengan QPS sebenar dan turun naik beban pangkalan data untuk menyelia tugas migrasi.
2. Bagaimana untuk menyelesaikan masalah konsistensi DB semasa penulisan berganda
Pangkalan data pesanan hotel mempunyai sejarah kira-kira dua puluh tahun, terkumpul selama bertahun-tahun, dan bergantung secara langsung atau tidak langsung oleh berbilang pasukan merentasi jabatan dan dalam hotel Memesan pangkalan data SQLServer, jika anda ingin menukar kepada MySQL, anda mesti terlebih dahulu menyelesaikan masalah konsistensi dwi-tulis Ketidakkonsistenan terutamanya ditunjukkan dalam dua perkara berikut:
Dwi-tulis sebenarnya hanya menulis SQLServer sahaja, MySQL terlepas
Double-tulis ke SQLServer dan MySQL berjaya . berlaku, data MySQL mungkin tidak konsisten dengan SQLServer.
Mengenai jaminan ketekalan data tulis dua kali, kami menggunakan kerja penyegerakan untuk menjajarkan data SQL Server dan tarik data DB pada kedua-dua belah untuk perbandingan berdasarkan masa kemas kini terakhir . Jika ia tidak konsisten, Baiki data MySQL dan tulis maklumat yang tidak konsisten kepada ES untuk penyelesaian masalah punca punca.
Tetapi juga kerana pengenalan pekerjaan tambahan untuk mengendalikan data MySQL, masalah baru telah timbul, iaitu, apabila menulis dua kali ganda jadual, kerana masa berganda, kerja mendapati bahawa SQLServer mempunyai data tetapi MySQL mempunyai tidak, jadi ia segera Memperbaiki data MySQL yang menyebabkan kegagalan penulisan berganda. Oleh itu, apabila bahagian tulis dua kali gagal, mekanisme Failover ditambah untuk mencetuskan pusingan baharu perbandingan dan kerja pembaikan dengan melontar mesej sehingga data DB pada kedua-dua belah adalah konsisten sepenuhnya.
Walaupun mekanisme mesej Job dan Failover yang disegerakkan boleh menjadikan data konsisten pada akhirnya, terdapat selang tahap kedua selepas semua data di kedua-dua belah pihak tidak konsisten, dan untuk pelbagai senario bagi banyak aplikasi, ia tidak dapat dielakkan bahawa akan ada peninggalan dan penulisan tunggal SQLServer. Tulisan yang terlepas ini kepada MySQL tidak boleh ditemui melalui DBTrace kerana ia tidak dapat ditentukan bahawa operasi CUD hanya ditulis kepada SQLServer dan bukan kepada MySQL. Jadi adakah cara untuk mengetahui senario kehilangan MySQL terlebih dahulu Kami telah mengetahui satu perkara, iaitu menukar rentetan sambungan pangkalan data, menggunakan rentetan sambungan baharu untuk aplikasi yang disambungkan ke perisian tengah, dan kemudian mengetahui semua operasi menggunakan rentetan sambungan lama SQLServer boleh mengesan trafik yang terlepas MySQL dengan tepat.
Akhirnya, kami secara beransur-ansur mengurangkan kadar ketidakkonsistenan DB tulis dua kali daripada 2/100,000 kepada hampir 0. Mengapakah ia hampir? dibincangkan secara terperinci dalam kandungan seterusnya.
3. Mengendalikan masalah luar penyegerakan data yang disebabkan oleh pengenalan caching pesanan
Selepas cache diperkenalkan, ia melibatkan penulisan atau pengemaskinian amalan biasa dalam industri seperti berikut:
Tulis ke DB dahulu dan kemudian cache
Tulis cache dahulu dan kemudian tulis DB
-
Padam Cache pertama dan kemudian tulis DB
Tulis DB dahulu dan kemudian padam cache
Tidak lagi membandingkan kelebihan dan kekurangan pelbagai kaedah, ia boleh digunakan dalam pelaksanaan tertentu Cache padam dua kali atau cache padam dua kali tertunda. Kami mengguna pakai skema penulisan kepada DB terlebih dahulu dan kemudian memadamkan cache Untuk jadual sensitif data, pemadaman dua kali tertunda akan dilakukan Kerja penyegerakan latar belakang secara kerap membandingkan, membaiki dan merekodkan perbezaan antara data pangkalan data dan data Redis. Walaupun reka bentuk boleh memastikan prestasi akhir, tetapi masih terdapat banyak ketidakkonsistenan data pada peringkat awal. Terutamanya dicerminkan dalam aspek berikut:
Terdapat senario di mana aplikasi tidak disambungkan ke perisian tengah dan cache tidak dipadamkan selepas menjalankan operasi CUD pada DB
-
Kelewatan pemadaman cache selepas menulis DB mengakibatkan membaca data cache yang kotor, seperti rangkaian tidak boleh dipercayai, GC, dsb. menyebabkan kelewatan dalam memadamkan cache; >
Kegagalan untuk memadamkan cache selepas menulis DB mengakibatkan membaca Caching data kotor, seperti semasa penukaran tuan-hamba Redis, hanya boleh dibaca tetapi tidak ditulis.
Untuk menyelesaikan masalah ketekalan cache, seperti yang ditunjukkan dalam Rajah 4.2, kami menambah penguncian optimistik dan penanda pembinaan CUD pada cache dan DB asal untuk mengehadkan pemuatan serentak data di bawah kesesuaian cache yang menimpa satu sama lain, dan persepsi bahawa operasi CUD sedang dilakukan pada data yang sedang diperiksa. Mekanisme pemenang penulis terakhir berdasarkan penguncian optimistik boleh digunakan untuk merealisasikan trafik Pertanyaan untuk menyambung terus ke DB dan menyelesaikan masalah persaingan apabila kedua-dua senario ini tidak selesai. Pada akhirnya, kadar ketidakkonsistenan cache kami dikawal daripada 2 bahagian per juta kepada 3 bahagian setiap 10 juta.

Rajah 4.2 Penyelesaian ketekalan cache
Rajah 4.2 Apabila pertanyaan terlepas cache, atau pada masa ini terdapat kunci optimistik atau tanda pembinaan untuk data, apabila Tanya DB yang disambungkan secara langsung dan lepaskan fungsi pemuatan automatik data cache sehingga transaksi yang berkaitan selesai.
4. Bagaimana untuk menentukur data pesanan stok pada satu masa
Pada permulaan projek, kami membuat penyediaan satu kali data N tahun terakhir untuk MySQL, yang menghasilkan dalam data berikut yang tidak boleh ditentukur semasa peringkat penulisan dua kali Data dua senario:
Oleh kerana pangkalan data pesanan pengeluaran dipratetap untuk mengekalkan hampir N tahun data, tugas yang bertanggungjawab. untuk membersihkan sandaran telah wujud selama N tahun sebelum MySQL disambungkan kepada perisian tengah ini tidak boleh ditimpa oleh dasar dan dibersihkan.
Memerlukan masa yang lama untuk menggunakan semua perisian tengah yang bersambung Data mungkin tidak konsisten sebelum penulisan dua perisian tengah yang bersambung dan berganda -tulis semua jadual Data dibaiki sekali gus.
Untuk perkara pertama, kami membangunkan kerja pembersihan data MySQL Memandangkan pangkalan data pesanan mempunyai berbilang serpihan, jumlah bilangan utas teras ditetapkan secara dalaman dalam kerja berdasarkan bilangan sebenar. setiap serpihan secara berasingan Bertanggungjawab untuk membersihkan jadual yang ditetapkan dalam Shard yang sepadan, dan menjalankan berbilang pelayan secara selari untuk mengagihkan tugas untuk pembersihan Melalui kawalan kelajuan, kecekapan dipastikan tanpa menjejaskan beban pangkalan data pengeluaran.
Mengenai perkara kedua, selepas semua perisian tengah antara muka aplikasi dan semua jadual ditulis dua kali, data pesanan sedia ada dibaiki dengan melaraskan cap masa mula imbasan kerja penyegerakan dalam talian. Apabila membaiki, perhatian khusus harus diberikan kepada fakta bahawa data yang diimbas mesti diproses dalam kepingan mengikut tempoh masa untuk mengelakkan terlalu banyak data daripada dimuatkan, menyebabkan CPU pelayan pangkalan data pesanan menjadi terlalu tinggi.
5. Beberapa perbezaan dalam ciri pangkalan data
Jika kita ingin melakukan migrasi langsung pangkalan data dalam sistem yang besar, kita mesti mempunyai pemahaman yang mendalam tentang persamaan dan perbezaan antara pangkalan data yang berbeza untuk berkesan Menyelesaikan masalah. Walaupun MySQL dan SQL Server adalah pangkalan data hubungan yang popular dan kedua-duanya menyokong pertanyaan SQL standard, masih terdapat beberapa perbezaan dalam butiran. Mari kita lihat dengan lebih dekat masalah yang dihadapi semasa penghijrahan.
1) Masalah kunci kenaikan automatik
Untuk mengelakkan risiko pembaikan data yang lebih besar disebabkan oleh nombor siri kenaikan automatik yang tidak konsisten, ia harus dipastikan bahawa dua pangkalan data berkongsi nombor siri kenaikan automatik yang sama. Oleh itu, setiap orang tidak boleh dibenarkan melakukan operasi kenaikan automatik. Oleh itu, apabila data ditulis dua kali, kami menulis id kenaikan automatik yang dijana oleh SQLServer kembali ke lajur kenaikan automatik MySQL Apabila data ditulis kepada MySQL sahaja, MySQL digunakan untuk menjana nilai id kenaikan automatik.
2) Isu ketepatan tarikh
Untuk memastikan ketekalan data selepas penulisan dua kali, pengesahan ketekalan mesti dilakukan pada data di kedua-dua belah, jenisnya ialah Tarikh, DateTime, Timestamp Disebabkan oleh ketepatan storan medan yang tidak konsisten, pemprosesan khas diperlukan semasa perbandingan, dan nilai dipintas kepada saat untuk perbandingan.
3) Masalah medan XML
SQL Server menyokong jenis data XML, tetapi MySQL 5.7 tidak menyokong jenis XML. Selepas menggunakan varchar(4000) sebaliknya, saya menghadapi kes di mana penulisan data MySQL gagal, tetapi kerja penyegerakan boleh menulis data SQLServer kembali ke MySQL seperti biasa. Selepas analisis, program akan menulis rentetan XML yang tidak dimampatkan semasa menulis Jenis XML SQLServer akan memampatkan dan menyimpannya secara automatik, tetapi MySQL tidak akan menyebabkan operasi tulis dengan panjang melebihi 4000 akan gagal, dan panjang selepas pemampatan SQLServer. adalah kurang daripada 4000. , dan boleh menulis semula ke MySQL seperti biasa. Untuk tujuan ini, kami mencadangkan langkah balas, termasuk memampatkan dan mengesahkan panjang sebelum menulis, memintas medan tidak penting sebelum menyimpannya, mengoptimumkan struktur penyimpanan medan penting atau menukar jenis medan.
Berikut menyenaraikan beberapa perkara biasa yang perlu diberi perhatian semasa proses penghijrahan.

5. Amalan Amaran Awal
Amalan amaran awal kami tidak terhad kepada keperluan pemantauan semasa kemajuan projek Cara mengimbas data secara berkala dalam berpuluh bilion data Keabnormalan secara bertulis, semakan kadar ketekalan data tulis dua kali semasa menyiapkan projek, cara memantau masa nyata dan memberi amaran awal kepada aliran biasa jumlah penulisan pesanan pada setiap pecahan perpustakaan pesanan, dan cara kerap terima/sahkan ketersediaan tinggi keseluruhan sistem akan dibincangkan dalam halaman berikut.
1. Berpuluh-puluh bilion amaran pengesahan perbezaan data
Untuk memenuhi keperluan pemindahan data pesanan SQLServer ke pangkalan data MySQL, kualiti data adalah syarat yang diperlukan untuk pemindahan data keperluan, ia tidak akan telus, jadi mereka bentuk pelan pengesahan yang munasabah adalah berkaitan dengan kemajuan migrasi. Untuk pengesahan data, kami membahagikannya kepada dua jenis: dalam talian dan luar talian:
Pengesahan data dalam talian dan amaran awal
Semasa pemindahan, kami menggunakan kerja penyegerakan untuk mengira data yang tidak konsisten, kemudian menulis jadual dan medan yang tidak konsisten ke dalam ElasticSearch, dan kemudian menggunakan Kibana untuk mencipta papan pemuka pemantauan jumlah data yang tidak konsisten dan perkadaran jadual yang tidak konsisten , melalui papan pemuka pemantauan, kami boleh memantau dalam masa nyata jadual yang mempunyai ketidakkonsistenan data yang tinggi, dan kemudian menggunakan alat DBA untuk mengetahui aplikasi yang telah melakukan operasi CUD pada jadual berdasarkan nama jadual, dan seterusnya. cari aplikasi dan kod yang terlepas perisian tengah.
Dalam operasi sebenar, kami menemui sejumlah besar aplikasi yang tidak disambungkan ke perisian tengah dan mengubahnya Memandangkan semakin banyak aplikasi disambungkan ke perisian tengah, konsistensi data bertambah baik daripada papan pemuka pemantauan jumlah ketidakkonsistenan yang dilihat juga perlahan-lahan berkurangan. Walau bagaimanapun, konsistensi tidak pernah dikurangkan kepada sifar Sebabnya disebabkan oleh penyelarasan aplikasi dan kerja penyegerakan Ini juga merupakan masalah yang paling menyusahkan.
Mungkin sesetengah pelajar tertanya-tanya, sejak menulis dua kali, mengapa tidak menghentikan kerja penyegerakan? Sebabnya ialah SQL Server adalah kaedah penulisan utama dan julat CUD yang diliputi oleh middleware digunakan sebagai penanda aras Selain tidak menjamin kejayaan 100% dalam menulis data ke MySQL, tidak ada jaminan bahawa jumlah data dalam. dua pangkalan data adalah sama, jadi kerja yang konsisten diperlukan. Walaupun data tidak boleh konsisten sepenuhnya, ketidakkonsistenan boleh dikurangkan lagi melalui pemprosesan serentak.
Pendekatan kami adalah untuk menetapkan garis stabil 5 saat apabila membandingkan kerja konsisten (iaitu, data dalam masa 5 saat daripada masa semasa dianggap sebagai data tidak stabil Jika cap masa data pesanan tidak berada dalam stabil). baris, Apabila membandingkan di luar garisan stabil, data pesanan akan dikira semula sama ada ia berada dalam talian stabil Jika disahkan bahawa semua data berada di luar garisan stabil, operasi perbandingan akan dilakukan terbengkalai dan penentukuran ketekalan akan dilakukan dalam jadual seterusnya.
Pengesahan data luar talian dan amaran awal
Penghijrahan pangkalan data pesanan melibatkan ratusan jadual dan sejumlah besar data luar talian. Jumlah data berkaitan pesanan dalam hanya satu tahun mencecah berbilion-bilion, yang membawa cabaran besar kepada pemeriksaan data luar talian. Kami menulis penjana skrip ketekalan data untuk menjana skrip perbandingan untuk setiap jadual dan menggunakan ia ke platform penjadualan Skrip perbandingan bergantung pada kerja penyegerakan pada kedua-dua bahagian huluan SQLServer dan MySQL Selepas kerja huluan dilaksanakan, data perbandingan dilakukan secara automatik untuk membandingkan data tidak konsisten Nombor pesanan ditulis ke dalam jadual terperinci, dan jumlah ketidakkonsistenan dikira berdasarkan jadual terperinci, yang dikeluarkan dalam bentuk laporan harian dengan ketidakkonsistenan data yang tinggi diperiksa dan diselesaikan setiap hari.
Kami biasanya sentiasa menyelesaikan masalah dan menyelesaikan ketidakkonsistenan, termasuk menyelesaikan isu dalam skrip perbandingan dan menyemak kualiti data luar talian. Pengesahan setiap medan dalam setiap jadual data luar talian adalah sangat rumit Kami menulis fungsi UDF untuk perbandingan medan baru. Jadual di kedua-dua belah Apabila melakukan gabungan luar penuh, rekod dengan kunci primer yang sama atau kunci utama logik juga harus menjana medan baharu Selagi ia berbeza, ia akan dianggap sebagai data yang tidak konsisten. Di sini kita harus memberi perhatian kepada pemintasan medan tarikh, ketepatan data dan pemprosesan perpuluhan dengan sifar pada penghujungnya.
Selepas lebih daripada tiga bulan bekerja keras, kami telah mengenal pasti semua aplikasi yang tidak disambungkan ke middleware, dan telah menyambungkan semua operasi CUD mereka kepada middleware Selepas menghidupkan dwi penulisan, konsistensi dalam talian dan data luar talian telah bertambah baik secara beransur-ansur, mencapai matlamat pemindahan data.
2. ALL Shard jumlah pemantauan jumlah pesanan masa nyata
Setiap syarikat amat diperlukan untuk memantau jumlah pesanan Ctrip mempunyai platform amaran awal bersatu, yang terutamanya memantau pelbagai penggera pesanan , termasuk hotel , tiket penerbangan, wayarles, kereta api berkelajuan tinggi dan percutian. Sistem ini mempunyai fungsi carian dan paparan bebas berdasarkan kaedah dalam talian/luar talian, domestik/antarabangsa dan pembayaran, dan makluman untuk semua jenis pesanan.
Semasa pemindahan data pesanan daripada SQL Server ke MySQL, kami menyusun hampir dua ratus strategi amaran awal yang bergantung pada pangkalan data pesanan Rakan sekerja yang berkaitan yang bertanggungjawab untuk memantau membuat salinan strategi amaran awal Sumber data SQL Server dan disambungkan ke sumber data MySQL . Selepas semua penggera pemantauan dengan MySQL sebagai sumber data ditambah, dayakan strategi penggera Apabila jumlah pesanan tidak normal, NOC akan menerima dua pemberitahuan, satu daripada penggera data SQLServer dan satu daripada penggera MySQL bermakna Pengesahan skala kelabu diluluskan. Jika tidak, ia gagal dan masalah pemantauan MySQL perlu disiasat.
Selepas tempoh pengesahan skala kelabu, data penggera pada kedua-dua belah adalah konsisten Memandangkan jadual data SQLServer di luar talian (iaitu, data MySQL ditulis secara bersendirian), strategi amaran awal menggunakan SQLServer sebagai sumber data. juga pergi ke luar talian dalam masa.
3. Operasi Praktikal "Wandering Earth"
Untuk memastikan keselamatan sistem dan meningkatkan keupayaan untuk bertindak balas terhadap kecemasan, latihan dan ujian tekanan yang diperlukan mesti dijalankan. Untuk tujuan ini, kami telah membangunkan pelan kecemasan yang lengkap dan kerap menganjurkan latihan kecemasan - The Wandering Earth. Item gerudi termasuk pemutus litar aplikasi teras/bukan teras, pemutus litar DB, pemutus litar Redis, tembok api teras, suis suis kecemasan, dsb.
Ambil caching sebagai contoh Untuk memastikan ketersediaan perkhidmatan cache yang tinggi, kami akan offline beberapa nod atau mesin atau bahkan memotong keseluruhan perkhidmatan Redis semasa latihan untuk mensimulasikan runtuhan cache, pecahan cache dan. senario lain. Mengikut rancangan, sebelum menggabungkan, kami akan memotong akses Redis aplikasi terlebih dahulu, mengurangkan beban Redis secara beransur-ansur, dan kemudian menggabungkan Redis untuk menguji sama ada setiap sistem aplikasi boleh beroperasi secara normal tanpa Redis.
Dalam latihan pertama, apabila Redis diputuskan, bilangan ralat aplikasi meningkat dengan mendadak, jadi kami dengan tegas menghentikan gerudi dan berguling semula sambil mencari punca masalah. Memandangkan operasi Redis bagi sesetengah aplikasi tidak diurus secara seragam dan tidak dikawal oleh perisian tengah, apabila Redis ditiup, aplikasi serta-merta menjadi tidak normal. Sebagai tindak balas kepada situasi ini, selepas analisis, di satu pihak, kami menyambungkan port capaian cache pesanan aplikasi pelaporan ralat ke middleware Sebaliknya, kami mengukuhkan pergantungan yang lemah antara middleware dan Redis, menyokong satu klik memutuskan sambungan operasi Redis, dan menambah baik pelbagai pemantauan Metrik. Dalam latihan kedua, pemutus litar Redis berjaya dan semua sistem perniagaan berjalan seperti biasa dengan akses trafik penuh ke MySQL. Dalam latihan Wandering Earth terbaharu, selepas pusingan suntikan kerosakan seperti penyekatan rangkaian bilik komputer dan penyekatan aplikasi bukan teras, sistem kami mencapai hasil yang dijangkakan dengan sangat baik.
Dengan cara ini, dalam latih tubi demi latih tubi, kami menemui masalah, meringkaskan pengalaman, mengoptimumkan sistem, menambah baik rancangan kecemasan, langkah demi langkah meningkatkan keupayaan sistem untuk menghadapi kegagalan mengejut, dan memastikan kesinambungan perniagaan dan integriti data seks. Menyediakan sokongan data asas untuk melindungi keseluruhan sistem pesanan hotel.
6. Perancangan masa depan
1 Pesan konsol kawalan manual cache
Walaupun kami mempunyai papan pemantauan yang lengkap dan sistem amaran awal, untuk perkara seperti latihan pemutus litar, kerosakan automatik latihan, kegagalan dan penyelenggaraan perkakasan, serta masalah yang tidak dapat diramalkan terlebih dahulu, jika pembangun teras gagal bertindak balas terhadap operasi di tapak tepat pada masanya, sistem tidak boleh dimusnahkan sepenuhnya secara autonomi, yang boleh menyebabkan beberapa kemerosotan prestasi, seperti peningkatan tindak balas masa, dsb. Pada masa hadapan, kami bercadang untuk menambah papan pemuka kawalan manual Selepas kebenaran, NOC atau TS boleh dibenarkan untuk melaksanakan operasi yang disasarkan. , atau berdasarkan tempoh masa ketidaktersediaan yang dirancang oleh Redis Menetapkan masa pemotongan lebih awal boleh memastikan kebolehkawalan sistem pada tahap yang terbaik.
2. Penurunan taraf automatik perisian tengah
Memandangkan ia boleh dikawal secara manual, kami juga mempertimbangkan untuk memantau beberapa penunjuk teras pada masa hadapan Contohnya, semasa penukaran master-slave Redis, situasi biasa adalah pada tahap kedua, kami juga mengalami situasi di mana beberapa Redis tidak boleh ditulis selama lebih daripada 10 saat, kami boleh memantau jumlah data kotor yang tidak konsisten antara cache dan pangkalan data beberapa strategi dengan memantau ambang masa tindak balas yang tidak normal apabila Redis gagal, supaya Perisian tengah secara automatik menurunkan taraf dan memotong hos yang rosak ini untuk memastikan kestabilan asas perkhidmatan, dan kemudian secara beransur-ansur cuba pulih selepas mengesan penunjuk kelompok stabil.
3. Akses Middleware ke Service Mesh
Pasukan pesanan semasa menggunakan middleware dalam bentuk JAR middleware melindungi perbezaan asas dalam pangkalan data dan mengendalikan Redis untuk mencapai fungsi yang lebih kompleks. secara semula jadi mempunyai keupayaan untuk mengakses Service Mesh Selepas akses, peningkatan asas akan menjadi lebih cepat dan kurang mengganggu, panggilan akan menjadi lebih ringan, integrasi grid dengan rangka kerja akan menjadi lebih baik, dan awan akan menjadi lebih mudah, yang boleh menyokong lebih baik. Strategi pengantarabangsaan Ctrip.
Atas ialah kandungan terperinci Bagaimana untuk memindahkan sistem tanpa sensor SQL Server ke MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
MySQL adalah sistem pengurusan pangkalan data sumber terbuka. 1) Buat Pangkalan Data dan Jadual: Gunakan perintah Createdatabase dan Createtable. 2) Operasi Asas: Masukkan, Kemas kini, Padam dan Pilih. 3) Operasi lanjutan: Sertai, subquery dan pemprosesan transaksi. 4) Kemahiran Debugging: Semak sintaks, jenis data dan keizinan. 5) Cadangan Pengoptimuman: Gunakan indeks, elakkan pilih* dan gunakan transaksi.
 Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Anda boleh membuka phpmyadmin melalui langkah -langkah berikut: 1. Log masuk ke panel kawalan laman web; 2. Cari dan klik ikon phpmyadmin; 3. Masukkan kelayakan MySQL; 4. Klik "Login".
 MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL adalah sistem pengurusan pangkalan data relasi sumber terbuka, terutamanya digunakan untuk menyimpan dan mengambil data dengan cepat dan boleh dipercayai. Prinsip kerjanya termasuk permintaan pelanggan, resolusi pertanyaan, pelaksanaan pertanyaan dan hasil pulangan. Contoh penggunaan termasuk membuat jadual, memasukkan dan menanyakan data, dan ciri -ciri canggih seperti Operasi Join. Kesalahan umum melibatkan sintaks SQL, jenis data, dan keizinan, dan cadangan pengoptimuman termasuk penggunaan indeks, pertanyaan yang dioptimumkan, dan pembahagian jadual.
 Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
MySQL dipilih untuk prestasi, kebolehpercayaan, kemudahan penggunaan, dan sokongan komuniti. 1.MYSQL Menyediakan fungsi penyimpanan dan pengambilan data yang cekap, menyokong pelbagai jenis data dan operasi pertanyaan lanjutan. 2. Mengamalkan seni bina pelanggan-pelayan dan enjin penyimpanan berganda untuk menyokong urus niaga dan pengoptimuman pertanyaan. 3. Mudah digunakan, menyokong pelbagai sistem operasi dan bahasa pengaturcaraan. 4. Mempunyai sokongan komuniti yang kuat dan menyediakan sumber dan penyelesaian yang kaya.
 Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Redis menggunakan satu seni bina berulir untuk memberikan prestasi tinggi, kesederhanaan, dan konsistensi. Ia menggunakan I/O multiplexing, gelung acara, I/O yang tidak menyekat, dan memori bersama untuk meningkatkan keserasian, tetapi dengan batasan batasan konkurensi, satu titik kegagalan, dan tidak sesuai untuk beban kerja yang berintensifkan.
 Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Kedudukan MySQL dalam pangkalan data dan pengaturcaraan sangat penting. Ia adalah sistem pengurusan pangkalan data sumber terbuka yang digunakan secara meluas dalam pelbagai senario aplikasi. 1) MySQL menyediakan fungsi penyimpanan data, organisasi dan pengambilan data yang cekap, sistem sokongan web, mudah alih dan perusahaan. 2) Ia menggunakan seni bina pelanggan-pelayan, menyokong pelbagai enjin penyimpanan dan pengoptimuman indeks. 3) Penggunaan asas termasuk membuat jadual dan memasukkan data, dan penggunaan lanjutan melibatkan pelbagai meja dan pertanyaan kompleks. 4) Soalan -soalan yang sering ditanya seperti kesilapan sintaks SQL dan isu -isu prestasi boleh disahpepijat melalui arahan jelas dan log pertanyaan perlahan. 5) Kaedah pengoptimuman prestasi termasuk penggunaan indeks rasional, pertanyaan yang dioptimumkan dan penggunaan cache. Amalan terbaik termasuk menggunakan urus niaga dan preparedStatemen
 MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL adalah kemahiran penting untuk pemaju. 1.MYSQL adalah sistem pengurusan pangkalan data sumber terbuka, dan SQL adalah bahasa standard yang digunakan untuk mengurus dan mengendalikan pangkalan data. 2.MYSQL menyokong pelbagai enjin penyimpanan melalui penyimpanan data yang cekap dan fungsi pengambilan semula, dan SQL melengkapkan operasi data yang kompleks melalui pernyataan mudah. 3. Contoh penggunaan termasuk pertanyaan asas dan pertanyaan lanjutan, seperti penapisan dan penyortiran mengikut keadaan. 4. Kesilapan umum termasuk kesilapan sintaks dan isu -isu prestasi, yang boleh dioptimumkan dengan memeriksa penyataan SQL dan menggunakan perintah menjelaskan. 5. Teknik pengoptimuman prestasi termasuk menggunakan indeks, mengelakkan pengimbasan jadual penuh, mengoptimumkan operasi menyertai dan meningkatkan kebolehbacaan kod.
 Cara Membina Pangkalan Data SQL
Apr 09, 2025 pm 04:24 PM
Cara Membina Pangkalan Data SQL
Apr 09, 2025 pm 04:24 PM
Membina pangkalan data SQL melibatkan 10 langkah: memilih DBMS; memasang DBMS; mewujudkan pangkalan data; mewujudkan jadual; memasukkan data; mengambil data; mengemas kini data; memadam data; menguruskan pengguna; Menyandarkan pangkalan data.
