

Untuk pembangun bahagian belakang, satu SQl boleh digunakan untuk melaksanakan antara muka pertanyaan senarai Jika syarat pertanyaan adalah rumit dan reka bentuk pangkalan data jadual tidak munasabah, pertanyaan ini akan menjadi sukar untuk anda gunakan Redis untuk melaksanakan antara muka.
Yang berikut bermula dengan contoh Ini adalah keadaan carian tapak web beli-belah Jika anda diminta untuk melaksanakan antara muka carian sedemikian, bagaimana anda akan melaksanakannya
Sudah tentu anda berkata dengan bantuan enjin carian, seperti Elasticsearch dan seumpamanya, anda pasti boleh melakukannya. Tetapi apa yang saya ingin katakan di sini ialah, bagaimana jika anda ingin melaksanakannya sendiri

Seperti yang anda lihat dari gambar di atas, carian terbahagi kepada 6 kategori kesemuanya? , dan dalam setiap kategori Terbahagi kepada pelbagai subkategori.
Dalam kes ini, proses penapisan mengambil persilangan pelbagai kategori utama syarat dan mempertimbangkan pemilihan tunggal, pilihan berbilang dan penyesuaian dalam setiap subkategori untuk mengeluarkan set hasil yang memenuhi syarat.
Baiklah, setelah syaratnya jelas, mari kita mula melaksanakannya.
Pelaksanaan 1
Yang pertama muncul ialah pelajar A. Beliau adalah "pakar" dalam menulis SQL. Little A berkata dengan yakin: "Bukankah ia hanya antara muka pertanyaan? Terdapat banyak syarat, tetapi dengan pengalaman SQL saya yang kaya, ini tidak menjadi masalah untuk saya." (mengambil MySQL sebagai contoh di sini):
select ... from table_1 left join table_2 left join table_3 left join (select ... from table_x where ...) tmp_1 ... where ... order by ... limit m,n
Kod telah dijalankan dalam persekitaran ujian, dan hasilnya kelihatan sepadan, jadi saya bersedia untuk mengeluarkannya terlebih dahulu. Dengan prapelancaran ini, masalah mula timbul.
Pra-keluaran bertujuan untuk menjadikan persekitaran dalam talian serealistik mungkin, jadi jumlah data secara semula jadi jauh lebih besar daripada ujian. Jadi untuk SQL yang begitu kompleks, kecekapan pelaksanaannya boleh dibayangkan. Rakan sekelas ujian menaip semula kod Little A dengan tegas.
Pelaksanaan 2Merumuskan pengajaran yang dipelajari daripada kegagalan Little A, Little B mula mengoptimumkan SQL Pertama, ia melepasi kata kunci explain untuk analisis prestasi SQL. Indeks ditambah di mana-mana indeks ditambah.
Pisah SQL yang kompleks kepada berbilang SQL pada masa yang sama dan hasil pengiraan dikira dalam memori program.
Kod pseudo adalah seperti berikut:
$result_1 = query('select ... from table_1 where ...');
$result_2 = query('select ... from table_2 where ...');
$result_3 = query('select ... from table_3 where ...');
...
$result = array_intersect($result_1, $result_2, $result_3, ...);Penyelesaian ini jelas lebih baik daripada yang pertama dari segi prestasi, tetapi semasa penerimaan fungsi, pengurus produk masih merasakan bahawa kelajuan pertanyaan adalah tidak cukup pantas.
Little B sendiri juga tahu bahawa setiap pertanyaan akan menanyakan pangkalan data beberapa kali, dan atas beberapa sebab sejarah, pertanyaan satu jadual tidak boleh dilakukan di bawah beberapa syarat, jadi masa menunggu untuk pertanyaan tidak dapat dielakkan.
Pelaksanaan 3Little C melihat ruang untuk pengoptimuman daripada penyelesaian di atas. Dia mendapati bahawa Little B tidak mempunyai masalah dengan pemikirannya Dia membahagikan keadaan kompleks, mengira set hasil setiap sub-dimensi, dan akhirnya meringkaskan dan menggabungkan semua set subhasil untuk mendapatkan hasil akhir yang diinginkan.
Jadi dia tiba-tiba terfikir sama ada dia boleh cache set hasil setiap sub-dimensi terlebih dahulu Ini akan membolehkan dia untuk terus mengambil subset yang dikehendaki semasa membuat pertanyaan, tanpa perlu menyemak pangkalan data untuk pengiraan setiap kali.
Di sini Little C menggunakan Redis untuk menyimpan data cache Sebab utama untuk menggunakannya ialah ia menyediakan pelbagai struktur data, dan sangat mudah untuk melaksanakan operasi persilangan dan kesatuan pada set dalam Redis.
Pelan khusus adalah seperti yang ditunjukkan dalam rajah:
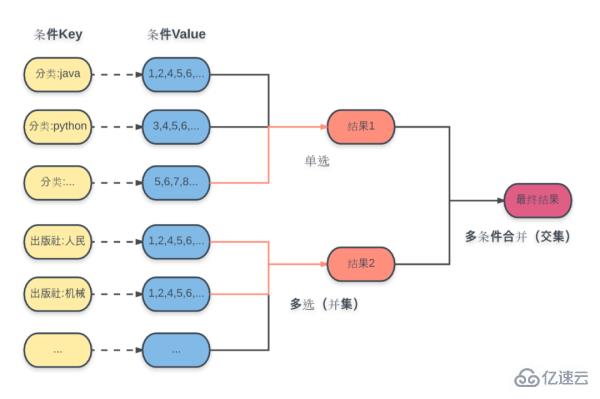 Untuk setiap syarat di sini, ID set hasil yang dikira disimpan dalam Kunci yang sepadan terlebih dahulu dan dipilih. Struktur data ialah satu set (Set).
Untuk setiap syarat di sini, ID set hasil yang dikira disimpan dalam Kunci yang sepadan terlebih dahulu dan dipilih. Struktur data ialah satu set (Set).
Operasi pertanyaan termasuk:
Jadi kaedah Nilai-Kunci bagi keadaan menyeluruh yang dinyatakan di atas adalah tidak mungkin. Di sini, kami menggunakan struktur data set pesanan Redis (Set Diisih) untuk melaksanakan
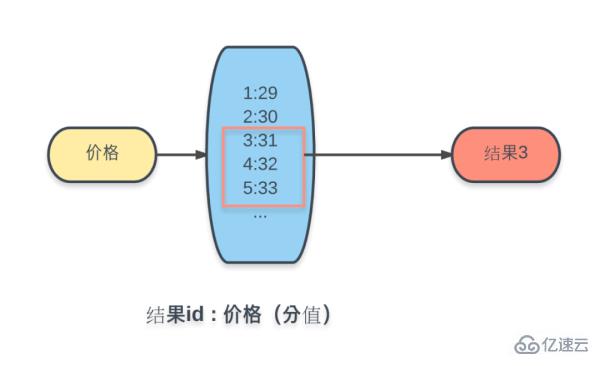 Tambah semua produk pada set pesanan yang kuncinya ialah harga , nilainya ialah ID produk, dan skor yang sepadan dengan setiap nilai ialah nilai harga produk.
Tambah semua produk pada set pesanan yang kuncinya ialah harga , nilainya ialah ID produk, dan skor yang sepadan dengan setiap nilai ialah nilai harga produk.
Dengan cara ini, anda boleh menggunakan perintah ZRANGEBYSCORE untuk mendapatkan set hasil yang sepadan berdasarkan julat skor (harga) dalam set Redis yang dipesan.
Pada ketika ini, pengoptimuman Pelan 3 telah selesai, dan pertanyaan dan pengiraan data telah diasingkan melalui caching.
Dalam setiap carian, anda hanya perlu mencari Redis beberapa kali untuk mendapatkan hasilnya. Kelajuan pertanyaan memenuhi keperluan penerimaan.
Sambungan①Paging
Anda mungkin telah menemui kecacatan fungsi yang serius di sini. . Ya, mari kita lihat dengan segera cara Redis melaksanakan paging.
Paging terutamanya melibatkan pengisihan, mari kita ambil masa penciptaan sebagai contoh. Seperti yang ditunjukkan dalam rajah:
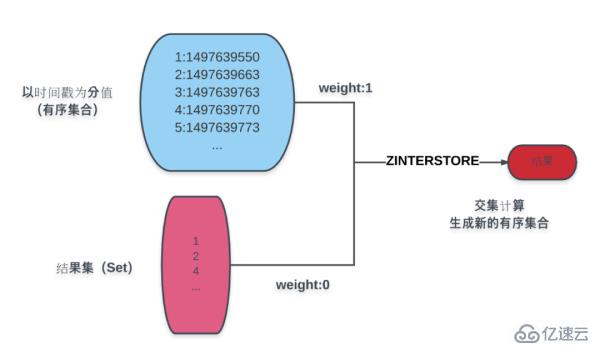
Bahagian biru dalam rajah ialah koleksi tertib produk berdasarkan masa penciptaan Hasil yang ditetapkan di bawah biru ialah pengiraan bersyarat hasilnya, melalui arahan ZINTERSTORE, berat set hasil ditetapkan kepada 0, hasil masa produk ialah 1, dan set hasil yang diperoleh dengan mengambil persimpangan diberikan kepada set skor masa penciptaan yang tersusun baharu.
Operasi pada set hasil baharu boleh mendapatkan setiap data yang diperlukan untuk halaman:
Jumlah halaman ialah: perintah ZCOUNT.
Kandungan halaman semasa: arahan ZRANGE.
Jika disusun mengikut urutan terbalik: arahan ZREVRANGE.
②Kemas kini data
Berkenaan isu kemas kini data indeks, terdapat dua cara untuk meneruskan. Satu adalah untuk mencetuskan operasi kemas kini dengan segera melalui pengubahsuaian data produk, dan satu lagi adalah untuk melaksanakan kemas kini kelompok melalui skrip yang dijadualkan.
Apa yang perlu diperhatikan di sini ialah mengenai kemas kini kandungan indeks, jika anda memadamkan Kunci secara ganas, kemudian tetapkan semula Kunci.
Oleh kerana kedua-dua operasi dalam Redis tidak akan dilakukan secara atom, mungkin terdapat jurang kosong di antaranya. Adalah disyorkan untuk mengalih keluar elemen tidak sah dalam koleksi dan menambah elemen baharu.
③Pengoptimuman Prestasi
Redis ialah operasi peringkat memori, jadi satu pertanyaan akan menjadi sangat pantas. Walau bagaimanapun, jika berbilang operasi Redis dilakukan dalam pelaksanaan kami, berbilang masa sambungan Redis mungkin penggunaan masa yang tidak perlu.
Dengan menggunakan arahan MULTI, mulakan transaksi, letakkan berbilang operasi Redis ke dalam satu transaksi, dan akhirnya lakukan pelaksanaan atom melalui EXEC.
Nota: Transaksi yang dipanggil di sini hanya melaksanakan berbilang operasi dalam satu sambungan Jika kegagalan berlaku semasa pelaksanaan, ia tidak akan ditarik balik.
Ringkasan
Ini hanyalah demo ringkas menggunakan Redis untuk mengoptimumkan carian pertanyaan Berbanding dengan enjin carian sumber terbuka sedia ada, ia lebih ringan dan memerlukan pembelajaran yang lebih sedikit lebih rendah.
Kedua, beberapa ideanya serupa dengan enjin carian sumber terbuka Jika analisis perkataan ditambah, fungsi yang serupa dengan perolehan teks penuh juga boleh dicapai.
Atas ialah kandungan terperinci Cara menggunakan Redis untuk melaksanakan antara muka carian. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Perisian pangkalan data yang biasa digunakan
Perisian pangkalan data yang biasa digunakan
 Apakah pangkalan data dalam memori?
Apakah pangkalan data dalam memori?
 Yang manakah mempunyai kelajuan bacaan yang lebih pantas, mongodb atau redis?
Yang manakah mempunyai kelajuan bacaan yang lebih pantas, mongodb atau redis?
 Cara menggunakan redis sebagai pelayan cache
Cara menggunakan redis sebagai pelayan cache
 Bagaimana redis menyelesaikan ketekalan data
Bagaimana redis menyelesaikan ketekalan data
 Bagaimanakah mysql dan redis memastikan konsistensi penulisan dua kali?
Bagaimanakah mysql dan redis memastikan konsistensi penulisan dua kali?
 Apakah data yang biasanya disimpan oleh redis cache?
Apakah data yang biasanya disimpan oleh redis cache?
 Apakah 8 jenis data redis
Apakah 8 jenis data redis








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



