

Bagaimana untuk mencipta indeks MySql

1. Indeks pepohon B+
Seperti namanya, indeks yang strukturnya ialah pepohon B+ ialah indeks pepohon B+ Dalam keadaan biasa, indeks konvensional yang dibuat dalam enjin InnoDb adalah semua struktur B+.
Indeks pokok B+ ialah yang berikut.
1.1. Indeks berkelompok/indeks berkelompok
Apabila mentakrifkan kunci primer, indeks yang dilampirkan secara automatik pada kunci primer ialah indeks berkelompok, juga dikenali sebagai indeks berkelompok.
Dalam Mysql, komponen digunakan untuk membina struktur pokok B+ Seperti yang ditunjukkan dalam rajah, setiap nod daun sepadan dengan kunci utama dan data lain yang berkaitan.
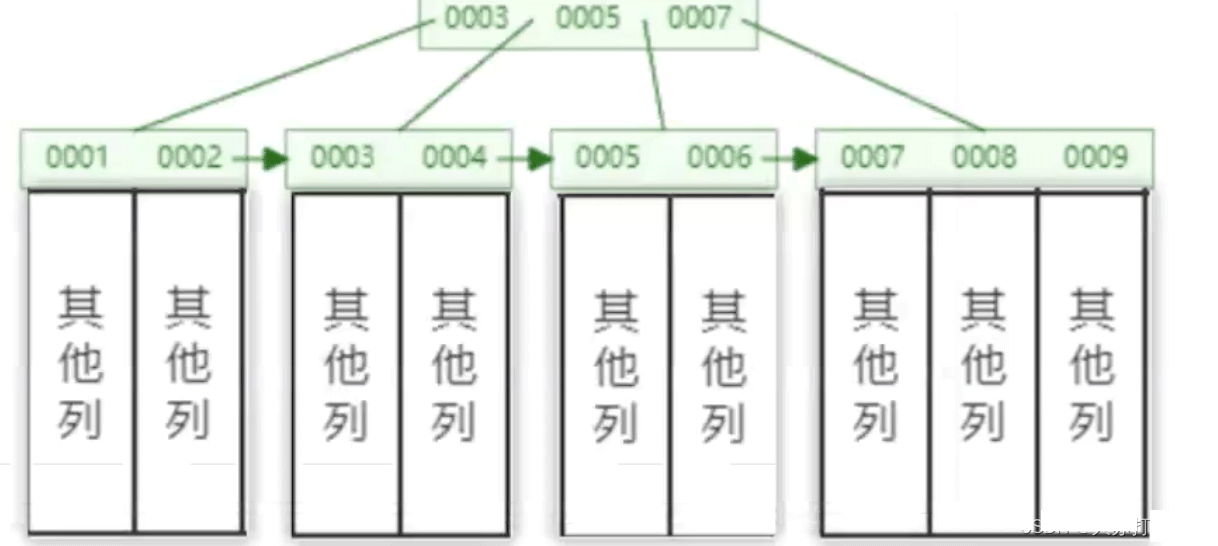
Jika kami tidak mentakrifkan kunci utama apabila kami mencipta jadual, Mysql akan secara automatik mencipta kunci utama dan indeks yang sepadan ialah rowId
1.2. Indeks tambahan/indeks sekunder
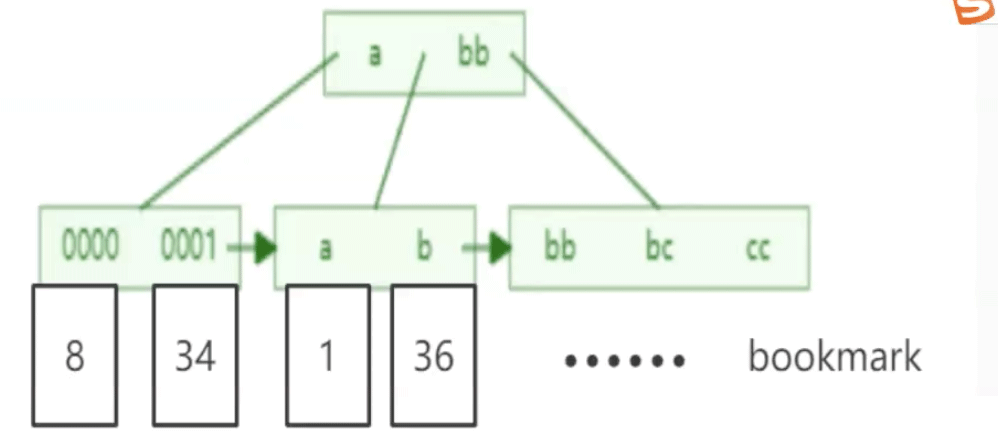
Indeks tambahan, juga dipanggil indeks sekunder, merujuk kepada indeks yang dibuat untuk lajur bukan kunci utama. Begitu juga, Mysql akan mencipta pokok B+ untuk indeks ini Selain nilai lajur, nod daun pokok hanya mengandungi nilai kunci utama baris di mana lajur itu terletak melalui indeks lajur Kemudian maklumat kunci utama dalam nod daun dicari dari indeks kunci utama, dan akhirnya seluruh baris data diperoleh.
Tindakan mencari kunci primer melalui indeks sekunder dan kemudian mendapatkan seluruh baris data daripada kunci primer dipanggil pulangan jadual.
1.3 Indeks gabungan/indeks gabungan
1.3.1 Apakah itu indeks gabungan
Indeks pengagregatan boleh dikatakan. indeks sekunder keadaan istimewa. Secara amnya, indeks sekunder hanya menambah indeks pada satu lajur bukan kunci utama, manakala indeks agregat menambah indeks pada berbilang lajur sekaligus.
Indeks sekunder am dicipta seperti ini:
CREATE INDEX order_name_index on t_order(order_name);
Indeks komposit dicipta seperti ini:
CREATE INDEX order_name_and_order_type_index on t_order(order_name, order_type);
Untuk indeks kompaun, MySQL juga akan mencipta pokok B+, tetapi kerana ia adalah indeks pada berbilang lajur, peraturan pengisihan pokok B+ adalah istimewa dan mengikut prinsip paling kiri. Apakah prinsip paling kiri akan dibincangkan di bawah. Selepas
, nod daun mengandungi berbilang maklumat Satu ialah nilai setiap lajur yang digunakan sebagai indeks, dan satu lagi ialah nilai kunci utama.
1.3.2 Prinsip paling kiri
Apa yang dipanggil prinsip paling kiri ialah apabila pepohon B+ ditakrifkan mengikut indeks, nama lajur dalam pernyataan yang ditentukan diisih dari kiri ke betul.
Sebagai contoh, penyataan definisi adalah seperti berikut:
CREATE INDEX joint_index on t_order(order_name, order_type, submit_time);
Peraturan pengisihan ialah mengisih order_name dahulu, jika order_name sama, kemudian mengisih order_type, dan akhirnya submit_time.
Kemudian apabila kita bertanya, mengikut definisi, susunan lajur adalah dari kiri ke kanan Klausa where atau order by dan klausa lain harus cuba bermula dengan order_name dahulu, dan. seterusnya.
Sebagai contoh, kami telah mentakrifkan indeks komposit yang terdiri daripada tiga lajur di atas Apabila membuat pertanyaan atau mengisih, cuba dahulu order_name, kemudian order_type, dan akhirnya submit_time. Sebab
select * from t_order where order_name = 'order1' and order_type = 1 and submit_time = str_to_date('2022-08-02 00:52:26', '%Y-%m-%d %T')
adalah mudah, kerana peraturan pengisihan indeks bersama adalah untuk mengisih order_name dahulu, jika order_name adalah sama, kemudian mengisih order_type, dan akhirnya submit_time. Jadi hanya jika peraturan ini diikuti semasa pengisihan pertanyaan, bolehkah kita menggunakan indeks.
Jika kita tidak mematuhi sepenuhnya prinsip paling kiri, sebagai contoh, isihan pertanyaan hanya mengisih dua lajur, mengabaikan yang tengah order by order_name, submit_time. Pada masa ini, Mysql akan mempunyai pemprosesan pintar, dan ia akan menilai sama ada lebih pantas untuk menggunakan indeks atau tidak untuk menggunakan indeks.
1.3.3. Pengoptimuman pertanyaan indeks bersama
Cuba gunakan lajur yang membentuk indeks bersama dan pastikan susunannya. Susunan lajur boleh dilihat dengan menanyakan indeks. Semak medan yang dikembalikan oleh sql_in_index
show index from t_order;

Cuba untuk hanya mengembalikan lajur dan kunci utama yang membentuk indeks bersama.
Ini sepatutnya mudah difahami, kerana nod daun pokok B+ indeks bersama hanya mengandungi kunci utama dan nilai lajur yang membentuk indeks bersama Jika medan yang dikembalikan hanyalah lajur ini , maka pertanyaan dalam pepohon B+ selesai. Jika anda ingin mengembalikan lajur lain, anda perlu mencari dalam indeks kunci utama dan melakukan operasi pemulangan jadual.
2. Indeks hash
Pangkalan data umum menggunakan indeks pepohon B+ untuk menanyakan data, tetapi apabila pangkalan data digunakan untuk satu tempoh masa, InnoDB akan merekodkan beberapa data panas yang digunakan dengan lebih kerap, dan kemudian untuk data Panas ini menetapkan indeks struktur cincang, yang merupakan senario aplikasi indeks cincang.
Indeks ini didayakan secara lalai bermula dari Mysql 5.7.
2.1. Semak kadar hit dan maklumat lain indeks cincang
Gunakan pernyataan:
show engine innodb status;

di mana statusTerdapat banyak maklumat, termasuk situasi indeks cincang. Mari salin maklumat ke dalam editor dan lihatnya. Bahagian ini ialah maklumat indeks cincang.
------------------------------------- INSERT BUFFER AND ADAPTIVE HASH INDEX ------------------------------------- Ibuf: size 1, free list len 0, seg size 2, 0 merges merged operations: insert 0, delete mark 0, delete 0 discarded operations: insert 0, delete mark 0, delete 0 Hash table size 34679, node heap has 0 buffer(s) Hash table size 34679, node heap has 0 buffer(s) Hash table size 34679, node heap has 5 buffer(s) Hash table size 34679, node heap has 0 buffer(s) Hash table size 34679, node heap has 1 buffer(s) Hash table size 34679, node heap has 0 buffer(s) Hash table size 34679, node heap has 1 buffer(s) Hash table size 34679, node heap has 1 buffer(s) -- 哈希索引的命中率,可根据这个来决定是否使用哈希索引 0.00 hash searches/s, 0.00 non-hash searches/s ---
3、索引的创建策略
3.1、 单列索引的策略
3.1.1、列的类型占用的空间越小,越适合作为索引
因为B+树也是占用空间的,所以在固定空间中,如果列的类型占用的空间越小,那我们一次就能读取更多的B+树节点,这样自然就加快了效率。
3.1.2、根据列的值的离散性
离散性是指数据的值重复的程度高不高,假如有N条数据的话,那离散性就可以用数值表示,范围是1/N 到 1。
比如说某个列在数据库中有下面几条数据(1, 2, 3, 4, 5, 5, 3),其中5和3都有重复,去重后应该是(1, 2, 3, 4, 5)。我们将去重后的条数除以总条数就得到离散性。这里是5/7。列中重复数据较多时,对应的数值较小,而重复数据较少时,数值相应较大。
如果一个列的数据的重复性越低,那么这个列就越适合加索引。
因为索引是需要起到筛选的作用。比如我们有个where条件是where id = 1,如果数据重复性较高,那可能根据索引会返回100条数据,然后我们在根据其他where条件在100条数据中再筛选。
如果数据重复性较低,那可能就只返回1条数据,那之后的运算量明显小得多。
所以一个列的数据离散性越高,那这个列越适合添加索引。
我们可以用下面的语句得到某个列的离散性程度。
select count(distinct id)/count(*) form t_table;
3.1.3、前缀索引
前缀索引和后缀索引:
有些列的值比较长,比如一些备注日志信息也会记录在数据库当中,这类信息的长度往往比较长,如果我们需要对这类列加索引,那索引并不是索引字符串的全部长度。这时候我们就可以建立前缀索引,即对字符串的前面几位建立索引。
所以前缀索引就是建立范围更小索引,选择一个好前缀位数就能有一个更好的查询效率。
不过有一些缺点,就是这类索引无法应用到order by和group语句上。
Mysql没有后缀索引,如果非要实现后缀索引,那在数据存储时我们应该将数据反转,这样就能用前缀索引达到后缀索引的效果。后缀索引的一个经典应用就是邮箱,快速查询某种类型的邮箱。
选择前缀索引的位数:
这里的逻辑和列的离散性类似,我们需要看看字符串的前面几位的子字符串的离散性如何。比如对于下面的表,内容是电影票的相关信息,我们需要对order_note建立前缀索引。
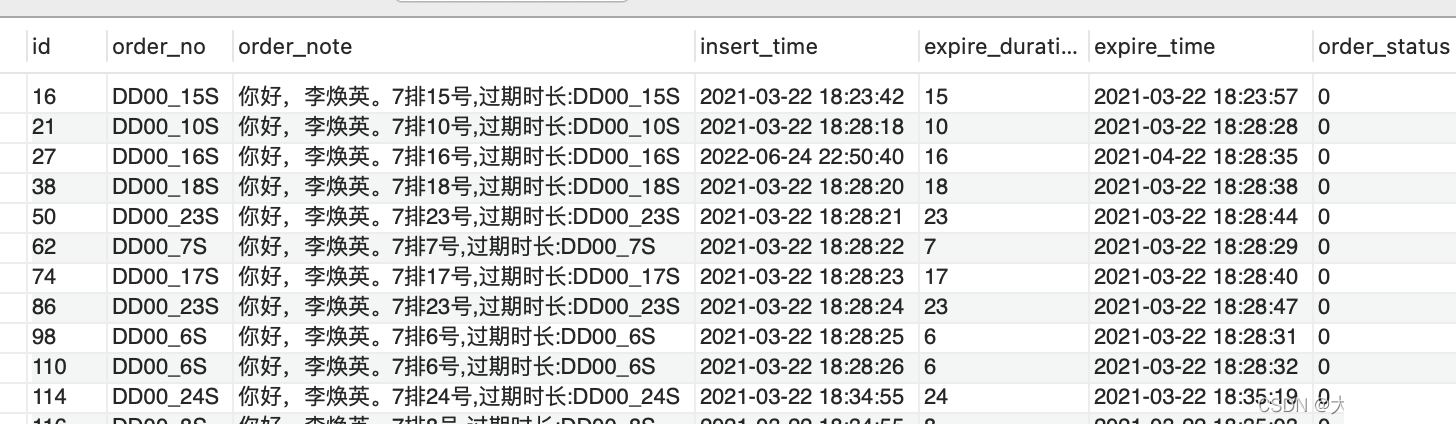
来比较一下各个位的子字符串的离散性。
SELECT COUNT(DISTINCT LEFT(order_note,3))/COUNT(*) AS sel3, COUNT(DISTINCT LEFT(order_note,4))/COUNT(*)AS sel4, COUNT(DISTINCT LEFT(order_note,5))/COUNT(*) AS sel5, COUNT(DISTINCT LEFT(order_note, 6))/COUNT(*) As sel6, COUNT(DISTINCT LEFT(order_note, 7))/COUNT(*) As sel7, COUNT(DISTINCT LEFT(order_note, 8))/COUNT(*) As sel8, COUNT(DISTINCT LEFT(order_note, 9))/COUNT(*) As sel9, COUNT(DISTINCT LEFT(order_note, 10))/COUNT(*) As sel10, COUNT(DISTINCT LEFT(order_note, 11))/COUNT(*) As sel11, COUNT(DISTINCT LEFT(order_note, 12))/COUNT(*) As sel12, COUNT(DISTINCT LEFT(order_note, 13))/COUNT(*) As sel13, COUNT(DISTINCT LEFT(order_note, 14))/COUNT(*) As sel14, COUNT(DISTINCT LEFT(order_note, 15))/COUNT(*) As sel15, COUNT(DISTINCT order_note)/COUNT(*) As total FROM order_exp;

可以看出,前面几位的子字符串的离散程度较低,后面sel13开始就比较高,那我们可以根据实际情况,建立13~15位的前缀索引。
建立前缀索引SQL语句:
alter table order_exp add key(order_note(13));
3.1.2、只为搜索、排序和分组的列建索引
这个理由很简单,不解释了。
3.2、 多列索引的策略
3.2.1、离散性最高的列放前面
原因很简单,查询时根据定义复合索引时的列的顺序来查询的,离散性高的列放在前面的话,就能更早的将更多的数据排除在外。
3.2.2、三星索引
三星索引是一种策略。有三种条件,满足一条则索引获得一颗星,三颗星则是很好的索引。
三条策略分别是
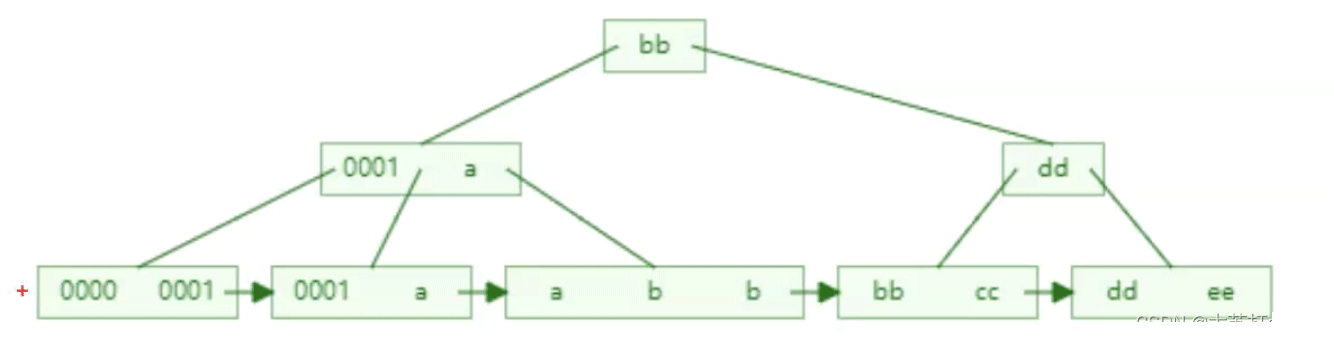
索引将相关记录放在一起。
意思是查询需要的数据在索引树的叶子节点中连续或者足够靠近。举个例子,下面是某个索引的B+树。查询所需数据仅在叶节点的前两个范围内,即0000至a。这很明显,后面的片我们就没必要再去查询了,这无疑增加了效率。当所需数据分布在每个片上时,查询次数就会显著增加。
所以查询需要的数据在叶子节点上越连续,越窄就越好。
索引中的数据顺序与查找中的数据排序一致。
这容易理解,讲解联合索引中说过,B+树的排序顺序和索引中的数据一样,所以查询时的where的数据顺序越贴近索引中的顺序,就越能更好地利用B+树。
索引的列包含查询中的所有列。
这个可以避免回文操作,不多解释。
三星索引的权重:
一般来说第三个策略权重占到50%,之后是第一个策略27%, 第二个策略23%。
三星索引实例:
CREATE TABLE customer ( cno INT, lname VARCHAR (10), fname VARCHAR (10), sex INT, weight INT, city VARCHAR (10) ); CREATE INDEX idx_cust ON customer (city, lname, fname, cno);
我们创建以上的索引,那么对于下面的查询语句,这个索引就是三星索引。
select cno,fname from customer where lname='xx' and city ='yy' order by fname;
首先,查询条件中有lname=’xx’ and city =’yy’,这条件让我们这需要在lname=’xx’ and city =’yy’的那一片B+树的叶子节点中查询,让我们的查询变窄了很多,并且这部分的数据是连续的,因为B+树是先根据city排序,再根据lname查询。
另外,因为已经锁定lname=’xx’ and city =’yy’,所以这部分的数据是根据fname和cno排序。查询语句正好是根据`fname```排序,所以第二点也满足。
最后是查询的结果都包含正在索引中,不会有回文,第三点也满足,所以这个索引是三星索引。
Atas ialah kandungan terperinci Bagaimana untuk mencipta indeks MySql. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
MySQL adalah sistem pengurusan pangkalan data sumber terbuka. 1) Buat Pangkalan Data dan Jadual: Gunakan perintah Createdatabase dan Createtable. 2) Operasi Asas: Masukkan, Kemas kini, Padam dan Pilih. 3) Operasi lanjutan: Sertai, subquery dan pemprosesan transaksi. 4) Kemahiran Debugging: Semak sintaks, jenis data dan keizinan. 5) Cadangan Pengoptimuman: Gunakan indeks, elakkan pilih* dan gunakan transaksi.
 Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Anda boleh membuka phpmyadmin melalui langkah -langkah berikut: 1. Log masuk ke panel kawalan laman web; 2. Cari dan klik ikon phpmyadmin; 3. Masukkan kelayakan MySQL; 4. Klik "Login".
 MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL adalah sistem pengurusan pangkalan data relasi sumber terbuka, terutamanya digunakan untuk menyimpan dan mengambil data dengan cepat dan boleh dipercayai. Prinsip kerjanya termasuk permintaan pelanggan, resolusi pertanyaan, pelaksanaan pertanyaan dan hasil pulangan. Contoh penggunaan termasuk membuat jadual, memasukkan dan menanyakan data, dan ciri -ciri canggih seperti Operasi Join. Kesalahan umum melibatkan sintaks SQL, jenis data, dan keizinan, dan cadangan pengoptimuman termasuk penggunaan indeks, pertanyaan yang dioptimumkan, dan pembahagian jadual.
 Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
MySQL dipilih untuk prestasi, kebolehpercayaan, kemudahan penggunaan, dan sokongan komuniti. 1.MYSQL Menyediakan fungsi penyimpanan dan pengambilan data yang cekap, menyokong pelbagai jenis data dan operasi pertanyaan lanjutan. 2. Mengamalkan seni bina pelanggan-pelayan dan enjin penyimpanan berganda untuk menyokong urus niaga dan pengoptimuman pertanyaan. 3. Mudah digunakan, menyokong pelbagai sistem operasi dan bahasa pengaturcaraan. 4. Mempunyai sokongan komuniti yang kuat dan menyediakan sumber dan penyelesaian yang kaya.
 Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Redis menggunakan satu seni bina berulir untuk memberikan prestasi tinggi, kesederhanaan, dan konsistensi. Ia menggunakan I/O multiplexing, gelung acara, I/O yang tidak menyekat, dan memori bersama untuk meningkatkan keserasian, tetapi dengan batasan batasan konkurensi, satu titik kegagalan, dan tidak sesuai untuk beban kerja yang berintensifkan.
 MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL adalah kemahiran penting untuk pemaju. 1.MYSQL adalah sistem pengurusan pangkalan data sumber terbuka, dan SQL adalah bahasa standard yang digunakan untuk mengurus dan mengendalikan pangkalan data. 2.MYSQL menyokong pelbagai enjin penyimpanan melalui penyimpanan data yang cekap dan fungsi pengambilan semula, dan SQL melengkapkan operasi data yang kompleks melalui pernyataan mudah. 3. Contoh penggunaan termasuk pertanyaan asas dan pertanyaan lanjutan, seperti penapisan dan penyortiran mengikut keadaan. 4. Kesilapan umum termasuk kesilapan sintaks dan isu -isu prestasi, yang boleh dioptimumkan dengan memeriksa penyataan SQL dan menggunakan perintah menjelaskan. 5. Teknik pengoptimuman prestasi termasuk menggunakan indeks, mengelakkan pengimbasan jadual penuh, mengoptimumkan operasi menyertai dan meningkatkan kebolehbacaan kod.
 Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Kedudukan MySQL dalam pangkalan data dan pengaturcaraan sangat penting. Ia adalah sistem pengurusan pangkalan data sumber terbuka yang digunakan secara meluas dalam pelbagai senario aplikasi. 1) MySQL menyediakan fungsi penyimpanan data, organisasi dan pengambilan data yang cekap, sistem sokongan web, mudah alih dan perusahaan. 2) Ia menggunakan seni bina pelanggan-pelayan, menyokong pelbagai enjin penyimpanan dan pengoptimuman indeks. 3) Penggunaan asas termasuk membuat jadual dan memasukkan data, dan penggunaan lanjutan melibatkan pelbagai meja dan pertanyaan kompleks. 4) Soalan -soalan yang sering ditanya seperti kesilapan sintaks SQL dan isu -isu prestasi boleh disahpepijat melalui arahan jelas dan log pertanyaan perlahan. 5) Kaedah pengoptimuman prestasi termasuk penggunaan indeks rasional, pertanyaan yang dioptimumkan dan penggunaan cache. Amalan terbaik termasuk menggunakan urus niaga dan preparedStatemen
 Cara Memulihkan Data Selepas SQL Memadam Barisan
Apr 09, 2025 pm 12:21 PM
Cara Memulihkan Data Selepas SQL Memadam Barisan
Apr 09, 2025 pm 12:21 PM
Memulihkan baris yang dipadam secara langsung dari pangkalan data biasanya mustahil melainkan ada mekanisme sandaran atau transaksi. Titik Utama: Rollback Transaksi: Jalankan balik balik sebelum urus niaga komited untuk memulihkan data. Sandaran: Sandaran biasa pangkalan data boleh digunakan untuk memulihkan data dengan cepat. Snapshot Pangkalan Data: Anda boleh membuat salinan bacaan pangkalan data dan memulihkan data selepas data dipadam secara tidak sengaja. Gunakan Pernyataan Padam dengan berhati -hati: Periksa syarat -syarat dengan teliti untuk mengelakkan data yang tidak sengaja memadamkan. Gunakan klausa WHERE: Secara jelas menentukan data yang akan dipadam. Gunakan Persekitaran Ujian: Ujian Sebelum Melaksanakan Operasi Padam.
