
 Peranti teknologi
AI
Mengenal pasti penipuan ChatGPT, kesannya mengatasi OpenAI: Universiti Peking dan pengesan janaan AI Huawei ada di sini
Peranti teknologi
AI
Mengenal pasti penipuan ChatGPT, kesannya mengatasi OpenAI: Universiti Peking dan pengesan janaan AI Huawei ada di sini
Mengenal pasti penipuan ChatGPT, kesannya mengatasi OpenAI: Universiti Peking dan pengesan janaan AI Huawei ada di sini

Lajur Jantung Mesin
Jabatan Editorial Jantung Mesin
Kadar kejayaan penipuan AI adalah sangat tinggi Beberapa hari yang lalu, "4.3 juta ditipu dalam 10 minit" adalah topik carian hangat. Membina model bahasa besar yang paling hangat, penyelidik baru-baru ini meneroka kaedah pengecaman.
Dengan kemajuan berterusan model generatif besar, korpus yang mereka hasilkan secara beransur-ansur menghampiri manusia. Walaupun model besar membebaskan tangan kerani yang tidak terkira banyaknya, keupayaan kuat mereka untuk memalsukan yang palsu juga telah digunakan oleh beberapa penjenayah, menyebabkan beberapa siri masalah sosial:



Penyelidik dari Universiti Peking dan Huawei telah mencadangkan pengesan teks yang boleh dipercayai untuk mengenal pasti pelbagai korpora yang dijana AI. Mengikut ciri berbeza teks panjang dan pendek, kaedah latihan pengesan teks yang dijana AI berbilang skala berdasarkan pembelajaran PU dicadangkan. Dengan menambah baik proses latihan pengesan, peningkatan besar dalam keupayaan pengesanan pada korpus ChatGPT panjang dan pendek boleh dicapai di bawah keadaan yang sama, menyelesaikan titik kesakitan ketepatan rendah pengecaman teks pendek oleh pengesan semasa.

Alamat kertas:
https://arxiv.org/abs/2305.18149
Alamat kod (MindSpore):
https://github.com/mindspore-lab/mindone/tree/master/examples/detect_chatgpt
Alamat kod (PyTorch):
https://github.com/YuchuanTian/AIGC_text_detector
Pengenalan
Memandangkan kesan penjanaan model bahasa besar menjadi semakin realistik, pelbagai industri memerlukan pengesan teks janaan AI yang boleh dipercayai dengan segera. Walau bagaimanapun, industri yang berbeza mempunyai keperluan yang berbeza untuk korpus pengesanan Sebagai contoh, dalam akademik, secara amnya perlu untuk mengesan teks akademik yang besar dan lengkap pada platform sosial, berita palsu yang agak pendek dan berpecah-belah perlu dikesan. Walau bagaimanapun, pengesan sedia ada selalunya tidak dapat memenuhi pelbagai keperluan. Sebagai contoh, sesetengah pengesan teks AI arus perdana umumnya mempunyai keupayaan ramalan yang lemah untuk korpus yang lebih pendek.
Mengenai kesan pengesanan berbeza korpus dengan panjang yang berbeza, penulis memerhatikan bahawa mungkin terdapat beberapa "ketidakpastian" dalam atribusi teks yang dijana AI yang lebih pendek atau secara lebih terang, kerana beberapa ayat pendek yang dijana AI adalah selalunya juga Ia digunakan oleh manusia, jadi sukar untuk menentukan sama ada teks pendek yang dihasilkan oleh AI berasal dari manusia atau AI. Berikut ialah beberapa contoh manusia dan AI yang menjawab soalan yang sama:

Seperti yang dapat dilihat daripada contoh-contoh ini, sukar untuk mengenal pasti jawapan ringkas yang dijana oleh AI: perbezaan antara jenis korpus ini dan manusia adalah terlalu kecil, dan sukar untuk menilai dengan ketat sifat-sifatnya yang sebenar. Oleh itu, adalah tidak wajar untuk hanya menganotasi teks pendek sebagai manusia/AI dan melakukan pengesanan teks mengikut masalah pengelasan binari tradisional.
Untuk menangani masalah ini, kajian ini mengubah bahagian pengesanan klasifikasi binari manusia/AI kepada masalah pembelajaran PU (Positif-Tidak Berlabel) separa, iaitu, dalam ayat yang lebih pendek, bahasa manusia adalah positif (Positif), dan mesin Bahasa ini adalah Tidak Berlabel, yang meningkatkan fungsi kehilangan latihan. Peningkatan ini dengan ketara meningkatkan prestasi pengelasan pengesan pada pelbagai korpora.
Butiran algoritma
Di bawah tetapan pembelajaran PU tradisional, model klasifikasi binari hanya boleh belajar berdasarkan sampel latihan positif dan sampel latihan tidak berlabel. Kaedah pembelajaran PU yang biasa digunakan adalah untuk menganggarkan kerugian klasifikasi binari yang sepadan dengan sampel negatif dengan merumuskan kehilangan PU:
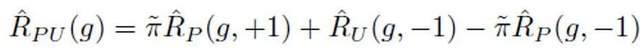
Antaranya, mewakili kerugian klasifikasi binari yang dikira dengan menganggap sampel positif dan label positif mewakili kerugian klasifikasi binari yang dikira dengan menganggap semua sampel tidak berlabel sebagai label negatif mewakili kerugian klasifikasi binari yang dikira dengan menganggap sampel positif sebagai label negatif; mewakili Kebarangkalian sampel positif terdahulu ialah anggaran bahagian sampel positif dalam semua sampel PU. Dalam pembelajaran PU tradisional, prior biasanya ditetapkan kepada hiperparameter tetap. Walau bagaimanapun, dalam senario pengesanan teks, pengesan perlu memproses pelbagai teks dengan panjang yang berbeza, anggaran nisbah sampel positif antara semua sampel PU yang sama panjang dengan sampel juga berbeza. Oleh itu, kajian ini menambah baik PU Loss dan mencadangkan fungsi kehilangan PU (MPU) berskala sensitif panjang.
Secara khusus, kajian ini mencadangkan model berulang abstrak untuk memodelkan pengesanan teks yang lebih pendek. Apabila model NLP tradisional memproses jujukan, mereka biasanya mempunyai struktur rantai Markov, seperti RNN, LSTM, dsb. Proses model kitaran jenis ini biasanya boleh difahami sebagai proses berulang secara beransur-ansur, iaitu, ramalan setiap keluaran token diperoleh dengan mengubah dan menggabungkan hasil ramalan token sebelumnya dan urutan sebelumnya dengan hasil ramalan ini. token. Itulah proses berikut:
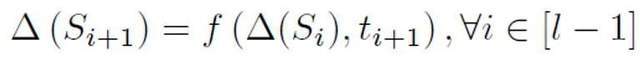
Untuk menganggarkan kebarangkalian terdahulu berdasarkan model abstrak ini, adalah perlu untuk menganggap bahawa output model adalah keyakinan bahawa ayat tertentu adalah positif, iaitu kebarangkalian ia dinilai sebagai sampel dituturkan oleh seseorang. Diandaikan bahawa saiz sumbangan setiap token ialah perkadaran songsang bagi panjang token ayat, ia adalah positif, iaitu, tidak berlabel, dan kebarangkalian untuk tidak dilabel adalah jauh lebih besar daripada kebarangkalian untuk menjadi positif. Kerana apabila perbendaharaan kata model besar secara beransur-ansur menghampiri manusia, kebanyakan perkataan akan muncul dalam kedua-dua AI dan korpora manusia. Berdasarkan model yang dipermudahkan ini dan kebarangkalian token positif yang ditetapkan, anggaran akhir terakhir diperoleh dengan mencari jumlah jangkaan keyakinan output model di bawah keadaan input yang berbeza.
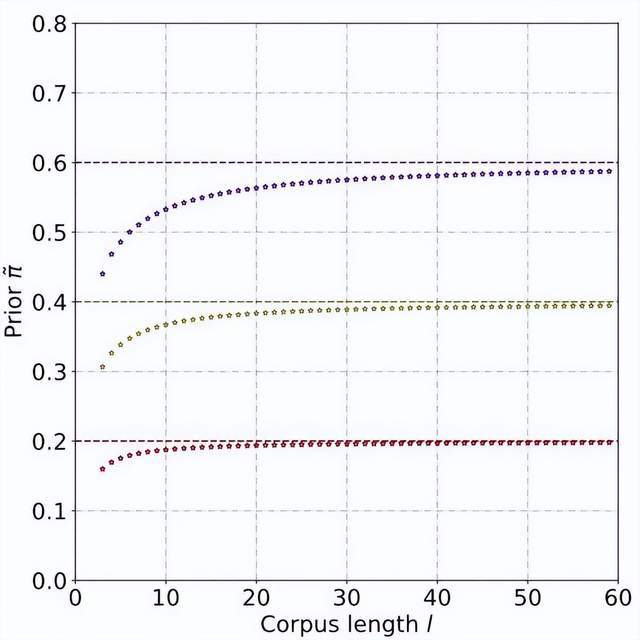
Melalui terbitan teori dan eksperimen, dianggarkan bahawa kebarangkalian terdahulu meningkat apabila panjang teks bertambah, dan akhirnya menjadi stabil. Fenomena ini juga dijangka, kerana apabila teks menjadi lebih panjang, pengesan boleh menangkap lebih banyak maklumat dan "ketidakpastian sumber" teks secara beransur-ansur melemah:
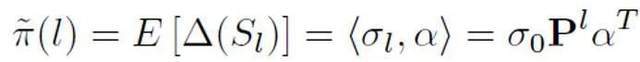
Selepas itu, bagi setiap sampel positif, kehilangan PU dikira berdasarkan sebelumnya unik yang diperoleh daripada panjang sampelnya. Akhir sekali, memandangkan teks yang lebih pendek hanya mempunyai beberapa "ketidakpastian" (iaitu, teks yang lebih pendek juga akan mengandungi ciri teks sesetengah orang atau AI), kehilangan binari dan kehilangan MPU boleh ditimbang dan ditambah sebagai matlamat pengoptimuman akhir:
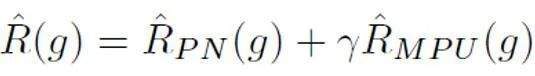
Selain itu, perlu diingatkan bahawa kehilangan MPU menyesuaikan diri dengan korpus latihan pelbagai panjang. Jika data latihan sedia ada jelas homogen dan kebanyakan korpus terdiri daripada teks yang panjang dan panjang, kaedah MPU tidak dapat melaksanakan keberkesanannya sepenuhnya. Bagi menjadikan panjang korpus latihan lebih pelbagai, kajian ini turut memperkenalkan modul multi-skala pada peringkat ayat. Modul ini secara rawak merangkumi beberapa ayat dalam korpus latihan dan menyusun semula ayat yang tinggal sambil mengekalkan susunan asal. Selepas operasi berbilang skala korpus latihan, teks latihan telah diperkaya panjangnya, dengan itu menggunakan sepenuhnya pembelajaran PU untuk latihan pengesan teks AI.
Hasil percubaan

Seperti yang ditunjukkan dalam jadual di atas, penulis mula-mula menguji kesan kehilangan MPU pada set data korpus janaan AI yang lebih pendek Tweep-Fake. Korpus dalam set data ini semuanya adalah segmen yang agak pendek di Twitter. Penulis juga menggantikan kehilangan dua kategori tradisional dengan matlamat pengoptimuman yang mengandungi kehilangan MPU berdasarkan penalaan halus model bahasa tradisional. Pengesan model bahasa yang dipertingkatkan adalah lebih berkesan dan mengatasi algoritma garis dasar yang lain.
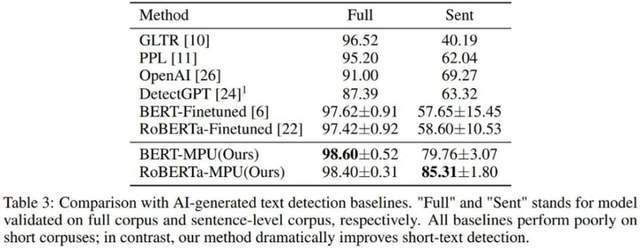
Pengarang juga menguji teks yang dijana oleh chatGPT Pengesan model bahasa yang diperolehi melalui penalaan halus tradisional berprestasi buruk pada ayat pendek yang dilatih dalam keadaan yang sama melalui kaedah MPU berprestasi baik pada ayat pendek, dan Pada masa yang sama , ia boleh mencapai peningkatan prestasi yang besar pada korpus lengkap, dengan skor F1 meningkat sebanyak 1%, mengatasi algoritma SOTA seperti OpenAI dan DetectGPT.
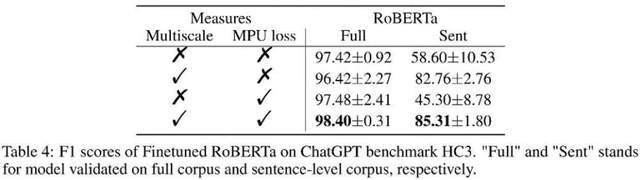
Seperti yang ditunjukkan dalam jadual di atas, penulis memerhatikan keuntungan kesan yang dibawa oleh setiap bahagian dalam eksperimen ablasi. Kehilangan MPU meningkatkan kesan pengelasan bahan panjang dan pendek.

Pengarang juga membandingkan PU tradisional dan PU Berbilang Skala (MPU). Dapat dilihat daripada jadual di atas bahawa kesan MPU adalah lebih baik dan boleh menyesuaikan diri dengan tugas pengesanan teks pelbagai skala AI.
Ringkasan
Pengarang menyelesaikan masalah pengecaman ayat pendek oleh pengesan teks dengan mencadangkan penyelesaian berdasarkan pembelajaran PU berskala besar Dengan percambahan model generasi AIGC pada masa hadapan, pengesanan kandungan jenis ini akan menjadi semakin penting. Penyelidikan ini telah mengambil langkah yang kukuh ke hadapan dalam isu pengesanan teks AI Diharapkan akan ada lebih banyak penyelidikan serupa pada masa hadapan untuk mengawal kandungan AIGC dengan lebih baik dan mencegah penyalahgunaan kandungan yang dihasilkan oleh AI.
Atas ialah kandungan terperinci Mengenal pasti penipuan ChatGPT, kesannya mengatasi OpenAI: Universiti Peking dan pengesan janaan AI Huawei ada di sini. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Penjana Seni AI Terbaik (Percuma & amp; Dibayar) untuk projek kreatif
Apr 02, 2025 pm 06:10 PM
Penjana Seni AI Terbaik (Percuma & amp; Dibayar) untuk projek kreatif
Apr 02, 2025 pm 06:10 PM
Artikel ini mengkaji semula penjana seni AI atas, membincangkan ciri -ciri mereka, kesesuaian untuk projek kreatif, dan nilai. Ia menyerlahkan Midjourney sebagai nilai terbaik untuk profesional dan mengesyorkan Dall-E 2 untuk seni berkualiti tinggi dan disesuaikan.
 Bermula dengan Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Bermula dengan Meta Llama 3.2 - Analytics Vidhya
Apr 11, 2025 pm 12:04 PM
Meta's Llama 3.2: Lompat ke hadapan dalam Multimodal dan Mobile AI META baru -baru ini melancarkan Llama 3.2, kemajuan yang ketara dalam AI yang memaparkan keupayaan penglihatan yang kuat dan model teks ringan yang dioptimumkan untuk peranti mudah alih. Membina kejayaan o
 CHATBOTS AI terbaik berbanding (Chatgpt, Gemini, Claude & amp; Lagi)
Apr 02, 2025 pm 06:09 PM
CHATBOTS AI terbaik berbanding (Chatgpt, Gemini, Claude & amp; Lagi)
Apr 02, 2025 pm 06:09 PM
Artikel ini membandingkan chatbots AI seperti Chatgpt, Gemini, dan Claude, yang memberi tumpuan kepada ciri -ciri unik mereka, pilihan penyesuaian, dan prestasi dalam pemprosesan bahasa semula jadi dan kebolehpercayaan.
 Adakah chatgpt 4 o tersedia?
Mar 28, 2025 pm 05:29 PM
Adakah chatgpt 4 o tersedia?
Mar 28, 2025 pm 05:29 PM
CHATGPT 4 kini tersedia dan digunakan secara meluas, menunjukkan penambahbaikan yang ketara dalam memahami konteks dan menjana tindak balas yang koheren berbanding dengan pendahulunya seperti ChATGPT 3.5. Perkembangan masa depan mungkin merangkumi lebih banyak Inter yang diperibadikan
 Pembantu Menulis AI Teratas untuk Meningkatkan Penciptaan Kandungan Anda
Apr 02, 2025 pm 06:11 PM
Pembantu Menulis AI Teratas untuk Meningkatkan Penciptaan Kandungan Anda
Apr 02, 2025 pm 06:11 PM
Artikel ini membincangkan pembantu penulisan AI terkemuka seperti Grammarly, Jasper, Copy.ai, WriteSonic, dan Rytr, yang memberi tumpuan kepada ciri -ciri unik mereka untuk penciptaan kandungan. Ia berpendapat bahawa Jasper cemerlang dalam pengoptimuman SEO, sementara alat AI membantu mengekalkan nada terdiri
 Memilih Penjana Suara AI Terbaik: Pilihan Teratas Ditinjau
Apr 02, 2025 pm 06:12 PM
Memilih Penjana Suara AI Terbaik: Pilihan Teratas Ditinjau
Apr 02, 2025 pm 06:12 PM
Artikel ini mengulas penjana suara AI atas seperti Google Cloud, Amazon Polly, Microsoft Azure, IBM Watson, dan Descript, memberi tumpuan kepada ciri -ciri mereka, kualiti suara, dan kesesuaian untuk keperluan yang berbeza.
 Sistem Rag Agentik 7 Teratas untuk Membina Ejen AI
Mar 31, 2025 pm 04:25 PM
Sistem Rag Agentik 7 Teratas untuk Membina Ejen AI
Mar 31, 2025 pm 04:25 PM
2024 menyaksikan peralihan daripada menggunakan LLMS untuk penjanaan kandungan untuk memahami kerja dalaman mereka. Eksplorasi ini membawa kepada penemuan agen AI - sistem pengendalian sistem autonomi dan keputusan dengan intervensi manusia yang minimum. Buildin
 Bagaimana cara mengakses Falcon 3? - Analytics Vidhya
Mar 31, 2025 pm 04:41 PM
Bagaimana cara mengakses Falcon 3? - Analytics Vidhya
Mar 31, 2025 pm 04:41 PM
Falcon 3: Model bahasa besar sumber terbuka revolusioner Falcon 3, lelaran terkini dalam siri Falcon yang terkenal LLMS, mewakili kemajuan yang ketara dalam teknologi AI. Dibangunkan oleh Institut Inovasi Teknologi (TII), ini terbuka
