

Bagaimana untuk mengoptimumkan pernyataan gabungan dalam MySQL

Simple Nested-Loop Join
Mari kita lihat cara mysql berfungsi semasa melakukan operasi gabungan. Apakah kaedah gabungan biasa?
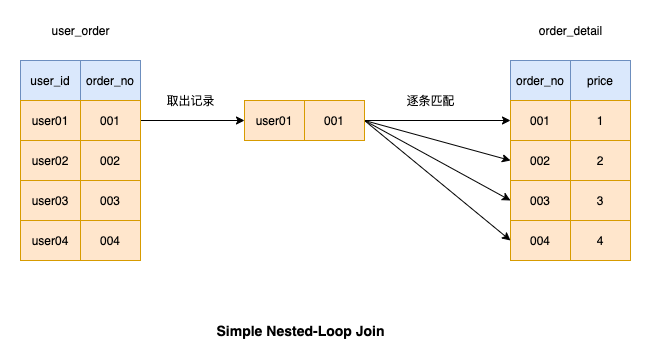
Seperti yang ditunjukkan dalam rajah, apabila kita melakukan operasi sambungan, jadual di sebelah kiri ialah jadual pemandu, dan jadual di sebelah kanan ialah jadual dipandu
Simple Nested-Loop Join Operasi gabungan ini adalah untuk mengambil rekod daripada jadual pemanduan dan kemudian memadankan rekod jadual dipandu satu demi satu Jika keadaannya sepadan , hasilnya akan dikembalikan. Kemudian, teruskan padankan rekod seterusnya dalam jadual pemacu sehingga semua data dalam jadual pemacu telah dipadankan
Kerana mengambil data dari jadual pemacu setiap kali memakan masa, MySQL tidak gunakan algoritma ini Untuk melaksanakan operasi cantum
Block Nested-Loop Join
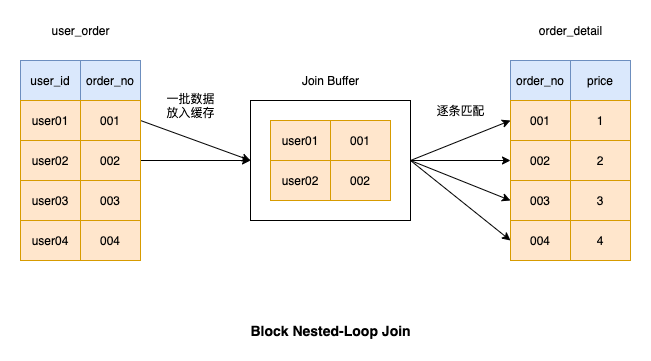
Untuk mengelakkan pengambilan data yang memakan masa daripada pemandu jadual setiap kali, kita boleh menambah kumpulan Data diambil dari jadual pemacu sekali gus dan dipadankan dalam ingatan. Selepas kumpulan data ini dipadankan, kumpulan data diambil dari jadual pemacu dan diletakkan dalam memori sehingga semua data dalam jadual pemacu dipadankan
Pendapatan semula data kelompok boleh mengurangkan banyak operasi IO, jadi kecekapan pelaksanaan adalah agak tinggi Operasi sambungan jenis ini juga digunakan oleh MySQL
Dengan cara ini, memori ini mempunyai nama yang betul dalam MySQ, dipanggil join buffer saiz penimbal gabungan
show variables like '%join_buffer%'

Alih keluar jadual jadual_tunggal yang kami gunakan sebelum ini, buat 2 jadual berdasarkan jadual jadual_tunggal, masukkan rekod rawak 1w ke dalam setiap jadual
CREATE TABLE single_table (
id INT NOT NULL AUTO_INCREMENT,
key1 VARCHAR(100),
key2 INT,
key3 VARCHAR(100),
key_part1 VARCHAR(100),
key_part2 VARCHAR(100),
key_part3 VARCHAR(100),
common_field VARCHAR(100),
PRIMARY KEY (id),
KEY idx_key1 (key1),
UNIQUE KEY idx_key2 (key2),
KEY idx_key3 (key3),
KEY idx_key_part(key_part1, key_part2, key_part3)
) Engine=InnoDB CHARSET=utf8;
create table t1 like single_table;
create table t2 like single_table;Jika anda menggunakan pernyataan join secara langsung, pengoptimuman MySQL Pelayan boleh memilih jadual t1 atau t2 sebagai jadual pemacu, yang akan menjejaskan proses kami menganalisis pernyataan sql, jadi kami menggunakan straight_join untuk membenarkan mysql menggunakan kaedah sambungan tetap untuk melaksanakan pertanyaan
select * from t1 straight_join t2 on (t1.common_field = t2.common_field)
Masa berjalan ialah 0.035s

Pelan pelaksanaan adalah seperti berikut

Menggunakan penimbal sertai dilihat dalam lajur Tambahan, menunjukkan bahawa operasi sambungan adalah berdasarkan Sekat Bersarang -Loop Join Algoritma
Index Nested-Loop Join
Selepas memahami algoritma Block Nested-Loop Join, anda dapat melihat bahawa setiap rekod dalam jadual pemacu akan Memadankan semua rekod dalam jadual didorong adalah sangat memakan masa Bolehkah kecekapan pemadanan dalam jadual didorong dapat dipertingkatkan ?
Saya rasa anda juga telah memikirkan algoritma ini, iaitu menambah indeks pada lajur yang disambungkan oleh jadual yang didorong, supaya proses pemadanan sangat pantas, seperti yang ditunjukkan dalam rajah
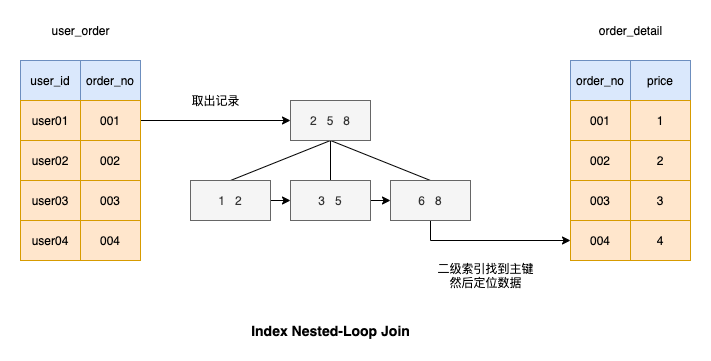
Mari kita lihat betapa pantasnya melakukan pertanyaan berdasarkan gabungan berdasarkan lajur indeks?
select * from t1 straight_join t2 on (t1.id = t2.id)
Masa pelaksanaan ialah 0.001 saat dapat dilihat bahawa ia lebih daripada satu tahap lebih cepat daripada bergabung berdasarkan lajur biasa

Pelan pelaksanaan. adalah seperti berikut

Bukan semua lajur rekod jadual pemacu akan dimasukkan ke dalam penimbal gabungan Hanya lajur dalam senarai pertanyaan dan lajur dalam penapis syarat akan dimasukkan ke dalam penimbal gabungan, jadi Kami tidak mahu menggunakan * sebagai senarai pertanyaan, kami hanya perlu meletakkan lajur yang kami minati dalam senarai pertanyaan, supaya lebih banyak rekod boleh diletakkan dalam penimbal gabungan
Bagaimana untuk memilih meja pemandu?
Sekarang kita tahu pelaksanaan khusus gabungan, mari kita bincangkan tentang soalan biasa, iaitu, bagaimana untuk memilih jadual pemacu?
Jika ia adalah algoritma Block Nested-Loop Join:
Apabila penimbal sambung cukup besar, tidak kira siapa yang memandu jadual
Apabila penimbal gabungan tidak cukup besar, anda harus memilih jadual kecil sebagai jadual pemacu (jadual kecil mempunyai kurang data dan bilangan kali ia dimasukkan ke dalam cantuman penimbal adalah kecil, yang mengurangkan bilangan imbasan jadual)
Jika ia adalah algoritma Index Nested-Loop Join
Andaikan bahawa bilangan baris dalam jadual pemacu ialah M, jadi M baris jadual pemacu perlu diimbas
setiap kali dari Apabila mendapatkan baris data daripada jadual dipacu, anda perlu mencari indeks a dahulu, dan kemudian cari indeks kunci utama. Bilangan baris dalam jadual didorong ialah N. Anggaran kerumitan mencari pokok setiap kali ialah logaritma asas 2 N, jadi kerumitan masa mencari baris pada jadual didorong ialah 2&rendah; l o g 2 N 2*log2^N 2&rendah;log2N
Setiap baris data dalam jadual pemacu mesti dicari sekali dalam jadual didorong Anggaran kerumitan keseluruhan proses pelaksanaan ialah M + M & paling rendah 2 & paling rendah; log2N
Jelas sekali M mempunyai kesan yang lebih besar pada bilangan baris yang diimbas, jadi meja kecil harus digunakan sebagai meja pemanduan. Sudah tentu, premis kesimpulan ini ialah indeks jadual didorong boleh digunakan
Ringkasnya, kita boleh menggunakan jadual kecil sebagai jadual pemanduan
Apabila pernyataan gabungan dilaksanakan dengan perlahan, kita boleh mengoptimumkannya melalui kaedah berikut
Apabila melakukan operasi sambungan, anda boleh menggunakan indeks jadual dipandu
meja kecil sebagai meja pemanduan
Tingkatkan saiz penimbal gabungan
Jangan gunakan * sebagai senarai pertanyaan, hanya kembalikan lajur yang diperlukan
Atas ialah kandungan terperinci Bagaimana untuk mengoptimumkan pernyataan gabungan dalam MySQL. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1375
1375
 52
52

 Hubungan antara pengguna dan pangkalan data MySQL
Apr 08, 2025 pm 07:15 PM
Hubungan antara pengguna dan pangkalan data MySQL
Apr 08, 2025 pm 07:15 PM
Dalam pangkalan data MySQL, hubungan antara pengguna dan pangkalan data ditakrifkan oleh kebenaran dan jadual. Pengguna mempunyai nama pengguna dan kata laluan untuk mengakses pangkalan data. Kebenaran diberikan melalui perintah geran, sementara jadual dibuat oleh perintah membuat jadual. Untuk mewujudkan hubungan antara pengguna dan pangkalan data, anda perlu membuat pangkalan data, membuat pengguna, dan kemudian memberikan kebenaran.
 Adakah Mysql perlu membayar
Apr 08, 2025 pm 05:36 PM
Adakah Mysql perlu membayar
Apr 08, 2025 pm 05:36 PM
MySQL mempunyai versi komuniti percuma dan versi perusahaan berbayar. Versi komuniti boleh digunakan dan diubahsuai secara percuma, tetapi sokongannya terhad dan sesuai untuk aplikasi dengan keperluan kestabilan yang rendah dan keupayaan teknikal yang kuat. Edisi Enterprise menyediakan sokongan komersil yang komprehensif untuk aplikasi yang memerlukan pangkalan data yang stabil, boleh dipercayai, berprestasi tinggi dan bersedia membayar sokongan. Faktor yang dipertimbangkan apabila memilih versi termasuk kritikal aplikasi, belanjawan, dan kemahiran teknikal. Tidak ada pilihan yang sempurna, hanya pilihan yang paling sesuai, dan anda perlu memilih dengan teliti mengikut keadaan tertentu.
 Integrasi RDS MySQL dengan Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Integrasi RDS MySQL dengan Redshift Zero ETL
Apr 08, 2025 pm 07:06 PM
Penyederhanaan Integrasi Data: AmazonRDSMYSQL dan Integrasi Data Integrasi Zero ETL Redshift adalah di tengah-tengah organisasi yang didorong oleh data. Proses tradisional ETL (ekstrak, menukar, beban) adalah kompleks dan memakan masa, terutamanya apabila mengintegrasikan pangkalan data (seperti Amazonrdsmysql) dengan gudang data (seperti redshift). Walau bagaimanapun, AWS menyediakan penyelesaian integrasi ETL sifar yang telah mengubah keadaan ini sepenuhnya, menyediakan penyelesaian yang mudah, hampir-sebenar untuk penghijrahan data dari RDSMYSQL ke redshift. Artikel ini akan menyelam ke integrasi RDSMYSQL Zero ETL dengan redshift, menjelaskan bagaimana ia berfungsi dan kelebihan yang dibawa kepada jurutera dan pemaju data.
 Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Bagaimana untuk mengoptimumkan prestasi MySQL untuk aplikasi beban tinggi?
Apr 08, 2025 pm 06:03 PM
Panduan Pengoptimuman Prestasi Pangkalan Data MySQL Dalam aplikasi yang berintensifkan sumber, pangkalan data MySQL memainkan peranan penting dan bertanggungjawab untuk menguruskan urus niaga besar-besaran. Walau bagaimanapun, apabila skala aplikasi berkembang, kemunculan prestasi pangkalan data sering menjadi kekangan. Artikel ini akan meneroka satu siri strategi pengoptimuman prestasi MySQL yang berkesan untuk memastikan aplikasi anda tetap cekap dan responsif di bawah beban tinggi. Kami akan menggabungkan kes-kes sebenar untuk menerangkan teknologi utama yang mendalam seperti pengindeksan, pengoptimuman pertanyaan, reka bentuk pangkalan data dan caching. 1. Reka bentuk seni bina pangkalan data dan seni bina pangkalan data yang dioptimumkan adalah asas pengoptimuman prestasi MySQL. Berikut adalah beberapa prinsip teras: Memilih jenis data yang betul dan memilih jenis data terkecil yang memenuhi keperluan bukan sahaja dapat menjimatkan ruang penyimpanan, tetapi juga meningkatkan kelajuan pemprosesan data.
 Cara Mengisi Nama Pengguna dan Kata Laluan MySQL
Apr 08, 2025 pm 07:09 PM
Cara Mengisi Nama Pengguna dan Kata Laluan MySQL
Apr 08, 2025 pm 07:09 PM
Untuk mengisi nama pengguna dan kata laluan MySQL: 1. Tentukan nama pengguna dan kata laluan; 2. Sambungkan ke pangkalan data; 3. Gunakan nama pengguna dan kata laluan untuk melaksanakan pertanyaan dan arahan.
 Pengoptimuman pertanyaan di MySQL adalah penting untuk meningkatkan prestasi pangkalan data, terutama ketika berurusan dengan set data yang besar
Apr 08, 2025 pm 07:12 PM
Pengoptimuman pertanyaan di MySQL adalah penting untuk meningkatkan prestasi pangkalan data, terutama ketika berurusan dengan set data yang besar
Apr 08, 2025 pm 07:12 PM
1. Gunakan indeks yang betul untuk mempercepatkan pengambilan data dengan mengurangkan jumlah data yang diimbas memilih*frommployeesWherElast_name = 'Smith'; Jika anda melihat lajur jadual beberapa kali, buat indeks untuk lajur tersebut. Jika anda atau aplikasi anda memerlukan data dari pelbagai lajur mengikut kriteria, buat indeks komposit 2. Elakkan pilih * Hanya lajur yang diperlukan, jika anda memilih semua lajur yang tidak diingini, ini hanya akan memakan lebih banyak pelayan dan menyebabkan pelayan melambatkan pada masa yang tinggi atau kekerapan misalnya, jadual anda
 Cara menyalin dan tampal mysql
Apr 08, 2025 pm 07:18 PM
Cara menyalin dan tampal mysql
Apr 08, 2025 pm 07:18 PM
Salin dan tampal di MySQL termasuk langkah -langkah berikut: Pilih data, salin dengan Ctrl C (Windows) atau Cmd C (Mac); Klik kanan di lokasi sasaran, pilih Paste atau gunakan Ctrl V (Windows) atau CMD V (MAC); Data yang disalin dimasukkan ke dalam lokasi sasaran, atau menggantikan data sedia ada (bergantung kepada sama ada data sudah ada di lokasi sasaran).
 Memahami sifat asid: tiang pangkalan data yang boleh dipercayai
Apr 08, 2025 pm 06:33 PM
Memahami sifat asid: tiang pangkalan data yang boleh dipercayai
Apr 08, 2025 pm 06:33 PM
Penjelasan terperinci mengenai atribut asid asid pangkalan data adalah satu set peraturan untuk memastikan kebolehpercayaan dan konsistensi urus niaga pangkalan data. Mereka menentukan bagaimana sistem pangkalan data mengendalikan urus niaga, dan memastikan integriti dan ketepatan data walaupun dalam hal kemalangan sistem, gangguan kuasa, atau pelbagai pengguna akses serentak. Gambaran keseluruhan atribut asid Atomicity: Transaksi dianggap sebagai unit yang tidak dapat dipisahkan. Mana -mana bahagian gagal, keseluruhan transaksi dilancarkan kembali, dan pangkalan data tidak mengekalkan sebarang perubahan. Sebagai contoh, jika pemindahan bank ditolak dari satu akaun tetapi tidak meningkat kepada yang lain, keseluruhan operasi dibatalkan. Begintransaction; UpdateAcCountSsetBalance = Balance-100Wh
