

Apakah perbezaan antara on, in, as, dan where dalam Mysql?

Perbezaan antara Mysql on, in, as, dan where
Jawapan: Di mana keadaan pertanyaan, on digunakan semasa menyambung secara dalaman dan luaran, seperti yang digunakan sebagai alias, dalam pertanyaan sama ada nilai tertentu adalah dalam keadaan tertentu
Cipta 2 jadual: pelajar, skor
pelajar:
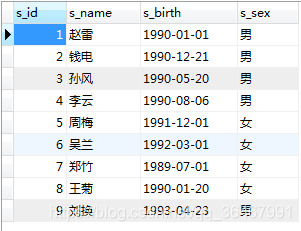
skor :
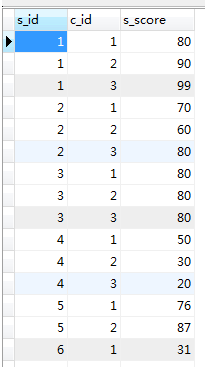
di mana
SELECT * FROM student WHERE s_sex='男'
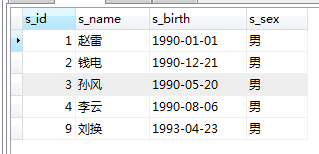
Contohnya: pada
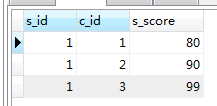
SELECT * FROM student LEFT JOIN score on student.s_id=score.s_id;
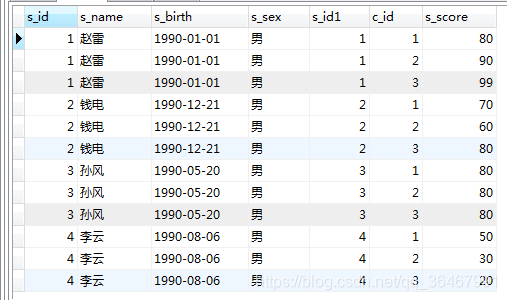
pada dan di mana kombinasi:
SELECT * FROM student LEFT JOIN score on student.s_id=score.s_id WHERE s_name='赵雷'
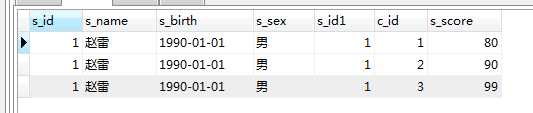
Contohnya : dalam
SELECT * FROM score WHERE s_id in (SELECT s_id FROM student WHERE s_name='赵雷')
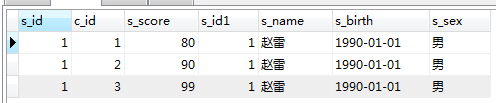
sebagai
select * from score as a LEFT JOIN student as b on a.s_id=b.s_id where s_name='赵雷'
Penyelesaian masalah pernyataan MySQL
1. Masalah penapisan data gabungan kiri
Keadaan selepas on hanya boleh menapis jadual di sebelah kanan gabungan kiri Jika jadual kiri tidak boleh sepadan dengan data jadual kanan, nol akan dipaparkan pada kedudukan jadual kanan asal Data jadual di sebelah kiri gabungan kiri tidak akan dikekang Hidup Selepas syarat terakhir ditambahkan ke tempat, semua data akan ditapis.
2. Masalah penapisan berulang dan penggunaan data yang sama
with <name> as()
Anda boleh menggunakan sebagai untuk menjana jadual sementara dalam mysql,
with arc as(
select id,arc.title,update_time,is_top,cId,pid,name_id from article arc where is_del = 0
)
select * from arcselect * from (
select cId,title,content(
select count(*)+1 from arc a1 where (a1.cId = a2.cId) and a1.updateTime > a2.updateTime
)updateTimeSort from arc a2
) a3
where updateTimeSort <= 3 order by cId,updateTime desc4、业务逻辑书写位置问题
接触sql多了会发现,sql其实能帮我们解决一定的业务问题,明显的有sql的存储过程和方法,对sql语句的批量处理其实在一定程度上帮我们解决一定的业务问题,但缺点也很明显,当新手接触这个项目时他很难搞清楚某个功能到底是如何实现的,不利于维护。
一般来说我们解决业务是在server层,有时会使用sql解决一些问题,但很少,在sever处理受制于计算机硬件,在数据库处理受制于数据库性能,相比之下,计算机硬件更易于扩展,因此还是不推荐大量使用sql解决问题的。
例如上个问题:根据某个字段排序取每个类别最后三条数据或前三条数据问题,虽然问题基本解决但让存在一些 ‘bug’,例如排序时会产生1、2、3、3、4这种排序,这是因为同个类别内有两条数据更新时间重复了,那我们直观想法(还是要看个人经验值)应该是,既然问题出在数据库,那应该在数据库查询的时候就解决这个问题,但事实上,让数据库去解决并不好解决,数据库的强项在于各种搜索算法,不在于逻辑处理,因此我们就要转移到server层处理,会有不少人陷于这个坑,花费大量时间去找办法让数据库去处理这类问题,但其实就算数据库处理得了,它也不一定有server层处理的效率高,当然如果是为了学习更多东西,这些时间也是值得花的,但是这种解题思路还是要改变下的。将1、2、3、3、4问题交给server处理也就是利用java等高级语言处理这种问题,相信熟用这些语言的开发者解决这些问题都是小case了。
5、查找另一表内和本表相关字段的数量
先复习下知识:用过count函数的人都清楚一旦使用count这类聚合函数,不做其他处理数据就会归为一行数据,但很多时候我们并不期望这样的结果,以此就要想些办法能用聚合函数,也能获取很多数据,我常用的是利用group by分组。
回归问题,现有(现不讨论表是否合理)文章表(id,title,content)有文章id,标题,文章内容三个字段,点赞收藏表(id,arc_id,fav,like)有表id,文章id,收藏字段(0未收藏,1收藏),点赞字段(0未点赞,1点赞),现要查询文章表内每篇文章的点赞收藏数,sql语句:
select art.title,art.content, count(case afl.fav when 1 then 1 end) as collectNum, count(case afl.like when 1 then 1 end) as likeNum from article art left join article_favor_like afl on afl.arc_id = art.id group by afl.arc_id //这是关键
如果没有group by afl.arc_id 后果就是,查出来一行数据,数据还牛头不对马嘴,但通过对文章收藏表中的文章id进行分组就可以针对每个文章id查询数据,这样left join时右表就有每个文章id对相应的收藏数与点赞数,而不是表内所有点赞数和收藏数,最终数据也是我们所需的。
6、关于union的使用
例子:
select id,title,content,1 isArc from arc union select id,name,content,0 isArc from news
使用union进行的是上下整合
被联合的数据列数要求一致
列数相同,数据类型不同会自动进行数据类型转换
联合后的列的名字由联合中第一次出现的列名为依据,即使后续被联合数据有自己的列名也不会使用,在例子中最终列名为:id,title,content,name等列名不会使用,因此使用union一般配合别名使用统一结果。
有时候会区分数据是哪个表的,可以通过附加额外的字段来区别,就像例子中的isArc字段,news表中的isArc可以不写,原因也就是第4条,最终列名由第一次出现的列名决定,后续数据列名有没有都可以。
7、limit的巧用
limit一般用于分页,功能是获取指定区间内的数据,因此我们也可以用它来减少数据库的查询,例子:
select * from arc where id = 12 limit 1
数据库查询由索引还好,没有索引是要遍历数据库的,有些数据经由条件筛选在逻辑上应该是唯一的,使用limit 1可以使数据库查询到该数据时不再搜索,减少数据库搜索次数,但这种方法仅是一种技巧,想大幅度优化sql还要另想办法。
8、update ignore和insert ignore的使用
//标题是唯一索引,'新标题'存在则更新操作不执行 update ignore arc set title = '新标题' //标题是唯一索引,'标题1号'存在则插入操作不执行 insert ignore into arc values(null,'标题1号','文章内容')
有这种需求,数据存在时不执行任何操作,不存在则更新或插入,一个办法是使用ingore,它会忽略数据库报错,而数据库执行原子操作时报错是会回滚的,因此只要我们给数据加上主键或唯一索引,当被更新字段或插入字段与原有数据冲突时会报错,但因为ingore会忽视这种报错,后端也就不会报错,sql也未执行,达到了目的,有人会对报错敏感,其实也没什么,报错也是在检查数据是发现不合理之处给的一个提醒或警告,对数据库无害的。
9、mysql存在更新,不存在则插入
区别于上面那个需求,这个是当插入的数据存在时更新数据,不再是不做任何操作,例子:
//本例子中title不是唯一索引,id是主键 insert into arc values(1,'标题1号','文章内容') on duplicate key update title='标题1号' //若要更新多个字段使用','隔开,例:title='标题1号',content='文章内容'
在例子中,当id为1的数据存在时,更新标题和内容,不存在则插入,如果执行更新操作,未设置新值的字段保持原来的值。
还有一个REPLACE INTO也可以达到这种效果,区别在于,REPLACE INTO更新时是先删除后插入会破坏原有索引,id为3的数据更新时会删除插入id为4的数据,未更新新值的字段设置为默认值或null。
无论是两个中的哪种方式判断数据是否存在的依据都是主键和唯一索引。
Atas ialah kandungan terperinci Apakah perbezaan antara on, in, as, dan where dalam Mysql?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
MySQL adalah sistem pengurusan pangkalan data sumber terbuka. 1) Buat Pangkalan Data dan Jadual: Gunakan perintah Createdatabase dan Createtable. 2) Operasi Asas: Masukkan, Kemas kini, Padam dan Pilih. 3) Operasi lanjutan: Sertai, subquery dan pemprosesan transaksi. 4) Kemahiran Debugging: Semak sintaks, jenis data dan keizinan. 5) Cadangan Pengoptimuman: Gunakan indeks, elakkan pilih* dan gunakan transaksi.
 Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Anda boleh membuka phpmyadmin melalui langkah -langkah berikut: 1. Log masuk ke panel kawalan laman web; 2. Cari dan klik ikon phpmyadmin; 3. Masukkan kelayakan MySQL; 4. Klik "Login".
 MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL adalah sistem pengurusan pangkalan data relasi sumber terbuka, terutamanya digunakan untuk menyimpan dan mengambil data dengan cepat dan boleh dipercayai. Prinsip kerjanya termasuk permintaan pelanggan, resolusi pertanyaan, pelaksanaan pertanyaan dan hasil pulangan. Contoh penggunaan termasuk membuat jadual, memasukkan dan menanyakan data, dan ciri -ciri canggih seperti Operasi Join. Kesalahan umum melibatkan sintaks SQL, jenis data, dan keizinan, dan cadangan pengoptimuman termasuk penggunaan indeks, pertanyaan yang dioptimumkan, dan pembahagian jadual.
 Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
MySQL dipilih untuk prestasi, kebolehpercayaan, kemudahan penggunaan, dan sokongan komuniti. 1.MYSQL Menyediakan fungsi penyimpanan dan pengambilan data yang cekap, menyokong pelbagai jenis data dan operasi pertanyaan lanjutan. 2. Mengamalkan seni bina pelanggan-pelayan dan enjin penyimpanan berganda untuk menyokong urus niaga dan pengoptimuman pertanyaan. 3. Mudah digunakan, menyokong pelbagai sistem operasi dan bahasa pengaturcaraan. 4. Mempunyai sokongan komuniti yang kuat dan menyediakan sumber dan penyelesaian yang kaya.
 Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Redis menggunakan satu seni bina berulir untuk memberikan prestasi tinggi, kesederhanaan, dan konsistensi. Ia menggunakan I/O multiplexing, gelung acara, I/O yang tidak menyekat, dan memori bersama untuk meningkatkan keserasian, tetapi dengan batasan batasan konkurensi, satu titik kegagalan, dan tidak sesuai untuk beban kerja yang berintensifkan.
 MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL adalah kemahiran penting untuk pemaju. 1.MYSQL adalah sistem pengurusan pangkalan data sumber terbuka, dan SQL adalah bahasa standard yang digunakan untuk mengurus dan mengendalikan pangkalan data. 2.MYSQL menyokong pelbagai enjin penyimpanan melalui penyimpanan data yang cekap dan fungsi pengambilan semula, dan SQL melengkapkan operasi data yang kompleks melalui pernyataan mudah. 3. Contoh penggunaan termasuk pertanyaan asas dan pertanyaan lanjutan, seperti penapisan dan penyortiran mengikut keadaan. 4. Kesilapan umum termasuk kesilapan sintaks dan isu -isu prestasi, yang boleh dioptimumkan dengan memeriksa penyataan SQL dan menggunakan perintah menjelaskan. 5. Teknik pengoptimuman prestasi termasuk menggunakan indeks, mengelakkan pengimbasan jadual penuh, mengoptimumkan operasi menyertai dan meningkatkan kebolehbacaan kod.
 Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Kedudukan MySQL dalam pangkalan data dan pengaturcaraan sangat penting. Ia adalah sistem pengurusan pangkalan data sumber terbuka yang digunakan secara meluas dalam pelbagai senario aplikasi. 1) MySQL menyediakan fungsi penyimpanan data, organisasi dan pengambilan data yang cekap, sistem sokongan web, mudah alih dan perusahaan. 2) Ia menggunakan seni bina pelanggan-pelayan, menyokong pelbagai enjin penyimpanan dan pengoptimuman indeks. 3) Penggunaan asas termasuk membuat jadual dan memasukkan data, dan penggunaan lanjutan melibatkan pelbagai meja dan pertanyaan kompleks. 4) Soalan -soalan yang sering ditanya seperti kesilapan sintaks SQL dan isu -isu prestasi boleh disahpepijat melalui arahan jelas dan log pertanyaan perlahan. 5) Kaedah pengoptimuman prestasi termasuk penggunaan indeks rasional, pertanyaan yang dioptimumkan dan penggunaan cache. Amalan terbaik termasuk menggunakan urus niaga dan preparedStatemen
 Cara Memulihkan Data Selepas SQL Memadam Barisan
Apr 09, 2025 pm 12:21 PM
Cara Memulihkan Data Selepas SQL Memadam Barisan
Apr 09, 2025 pm 12:21 PM
Memulihkan baris yang dipadam secara langsung dari pangkalan data biasanya mustahil melainkan ada mekanisme sandaran atau transaksi. Titik Utama: Rollback Transaksi: Jalankan balik balik sebelum urus niaga komited untuk memulihkan data. Sandaran: Sandaran biasa pangkalan data boleh digunakan untuk memulihkan data dengan cepat. Snapshot Pangkalan Data: Anda boleh membuat salinan bacaan pangkalan data dan memulihkan data selepas data dipadam secara tidak sengaja. Gunakan Pernyataan Padam dengan berhati -hati: Periksa syarat -syarat dengan teliti untuk mengelakkan data yang tidak sengaja memadamkan. Gunakan klausa WHERE: Secara jelas menentukan data yang akan dipadam. Gunakan Persekitaran Ujian: Ujian Sebelum Melaksanakan Operasi Padam.
