
 Peranti teknologi
AI
Keupayaan matematik GPT-4 adalah hebat! Penyelidikan eksplosif OpenAI mengenai 'Pengawasan Proses' memecahkan 78.2% masalah dan menghapuskan halusinasi
Peranti teknologi
AI
Keupayaan matematik GPT-4 adalah hebat! Penyelidikan eksplosif OpenAI mengenai 'Pengawasan Proses' memecahkan 78.2% masalah dan menghapuskan halusinasi
Keupayaan matematik GPT-4 adalah hebat! Penyelidikan eksplosif OpenAI mengenai 'Pengawasan Proses' memecahkan 78.2% masalah dan menghapuskan halusinasi

ChatGPT telah dikritik kerana kebolehan matematiknya sejak dikeluarkan.
Malah "genius matematik" Terence Tao pernah berkata bahawa GPT-4 tidak banyak menambah nilai dalam bidang kepakaran matematiknya sendiri.
Apakah yang perlu saya lakukan, biarkan sahaja ChatGPT menjadi "rencat matematik"?
OpenAI sedang berusaha keras - untuk meningkatkan keupayaan penaakulan matematik GPT-4, pasukan OpenAI menggunakan "Pengawasan Proses" (PRM) untuk melatih model.
Biar kami sahkan langkah demi langkah!

Alamat kertas: https://cdn.openai.com/improving-mathematical-reasoning-with-process-supervision/Lets_Verify_Step_by_Step .pdf
Dalam kertas kerja, penyelidik melatih model untuk mencapai keputusan yang lebih baik dalam penyelesaian masalah matematik dengan memberi ganjaran kepada setiap langkah penaakulan yang betul, iaitu, "penyeliaan proses", dan bukannya hanya memberi ganjaran kepada keputusan akhir yang betul (hasil penyeliaan).
Secara khususnya, PRM menyelesaikan 78.2% masalah dalam subset wakil set ujian MATH.

Selain itu, OpenAI mendapati bahawa "penyeliaan proses" mempunyai nilai yang besar dalam penjajaran - melatih model untuk menghasilkan rantaian pemikiran yang diiktiraf oleh manusia .
Penyelidikan terkini sudah tentu amat diperlukan untuk diteruskan oleh Sam Altman, "Pasukan Mathgen kami telah mencapai keputusan yang sangat menarik dalam penyeliaan proses, yang merupakan tanda penjajaran yang positif."
 Secara praktiknya, "penyeliaan proses" memerlukan maklum balas manual, yang sangat mahal untuk model besar dan pelbagai tugas. Oleh itu, kerja ini sangat penting dan boleh dikatakan menentukan hala tuju penyelidikan OpenAI pada masa hadapan.
Secara praktiknya, "penyeliaan proses" memerlukan maklum balas manual, yang sangat mahal untuk model besar dan pelbagai tugas. Oleh itu, kerja ini sangat penting dan boleh dikatakan menentukan hala tuju penyelidikan OpenAI pada masa hadapan.
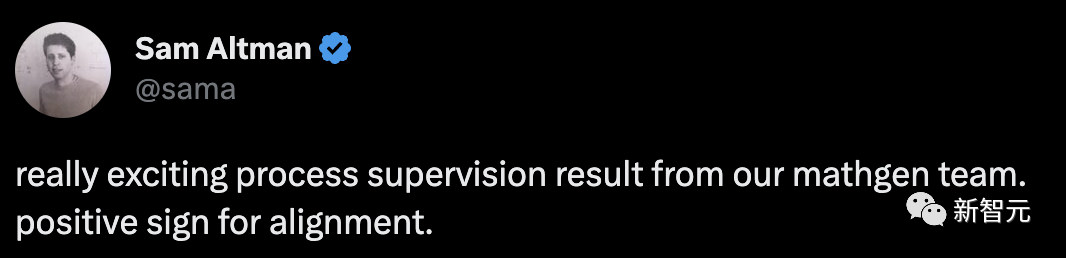
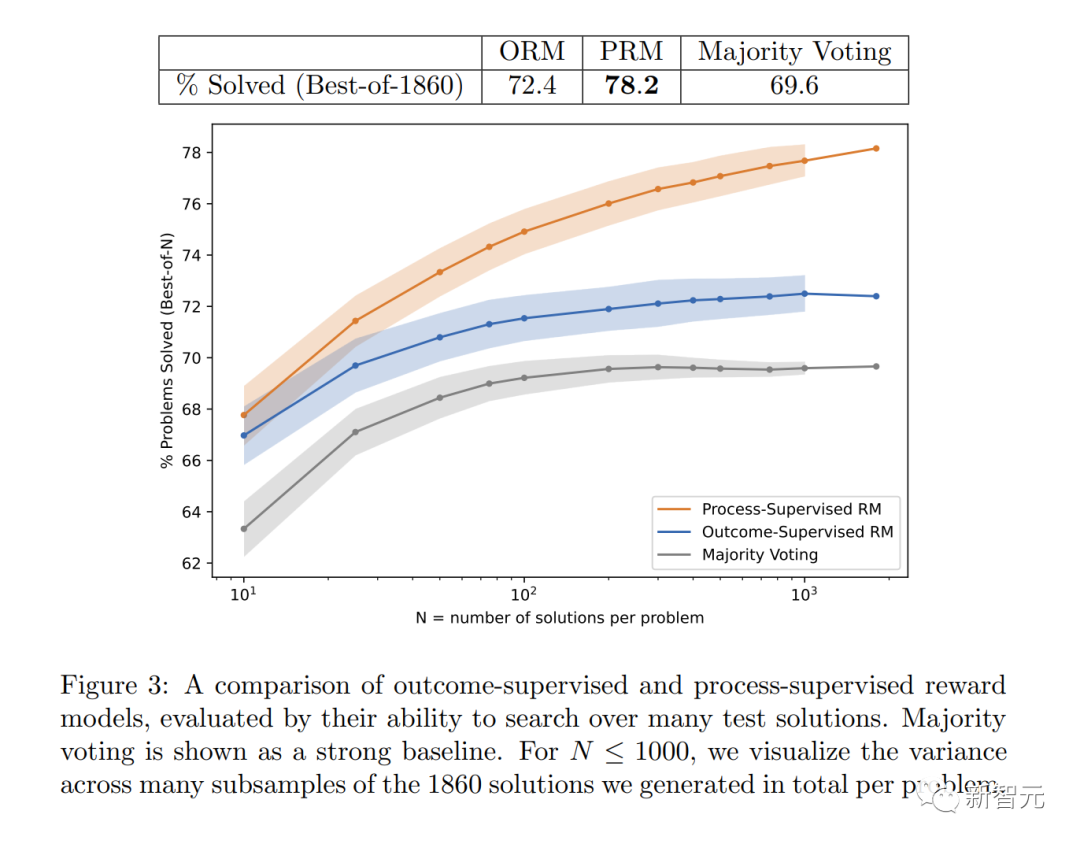
 Rajah menunjukkan peratusan penyelesaian terpilih yang menghasilkan jawapan akhir yang betul sebagai fungsi bilangan penyelesaian yang dipertimbangkan.
Rajah menunjukkan peratusan penyelesaian terpilih yang menghasilkan jawapan akhir yang betul sebagai fungsi bilangan penyelesaian yang dipertimbangkan.
 Di bawah, OpenAI menunjukkan 10 masalah matematik dan penyelesaian model, serta ulasan tentang kelebihan dan kekurangan model ganjaran.
Di bawah, OpenAI menunjukkan 10 masalah matematik dan penyelesaian model, serta ulasan tentang kelebihan dan kekurangan model ganjaran.
 Benar (TP)
Benar (TP)

Di sini, GPT-4 berjaya melaksanakan satu siri pemfaktoran polinomial yang kompleks.
Menggunakan identiti Sophie-Germain dalam langkah 5 ialah langkah penting. Dapat dilihat bahawa langkah ini sangat bernas.

Dalam langkah 7 dan 8, GPT-4 mula melakukan tekaan dan semakan.
Ini adalah tempat biasa di mana model boleh "halusinasi" dan mendakwa bahawa tekaan tertentu berjaya. Dalam kes ini, model ganjaran mengesahkan setiap langkah dan menentukan bahawa rantaian pemikiran adalah betul.

Model berjaya menggunakan beberapa identiti trigonometri untuk memudahkan ungkapan.

True Negative (TN)
Dalam langkah 7, GPT-4 cuba untuk memudahkan ungkapan, tetapi percubaan itu gagal. Model ganjaran menangkap pepijat ini.

Dalam langkah 11, GPT-4 membuat ralat pengiraan mudah. Juga ditemui oleh model ganjaran.

GPT-4 cuba menggunakan formula perbezaan kuasa dua dalam langkah 12, tetapi ungkapan ini sebenarnya bukan perbezaan kuasa dua.

Rasional untuk langkah 8 adalah pelik, tetapi model bonus menjadikannya lulus. Walau bagaimanapun, dalam langkah 9, model salah memfaktorkan ungkapan.
Model ganjaran membetulkan ralat ini.

Positif Palsu (FP)
Dalam langkah 4, GPT-4 tersilap mendakwa bahawa "jujukan itu berulang setiap 12 item ” , tetapi sebenarnya mengulangi setiap 10 item. Ralat pengiraan ini kadangkala menipu model ganjaran.

Dalam langkah 13, GPT-4 cuba untuk memudahkan persamaan dengan menggabungkan istilah yang serupa. Ia bergerak dengan betul dan menggabungkan sebutan linear ke kiri, tetapi secara salah meninggalkan bahagian kanan tidak berubah. Model ganjaran tertipu oleh ralat ini.

GPT-4 cuba melakukan pembahagian panjang, tetapi dalam langkah 16, ia terlupa untuk memasukkan sifar pendahuluan dalam bahagian berulang perpuluhan. Model ganjaran tertipu oleh ralat ini.

GPT-4 membuat ralat pengiraan halus dalam langkah 9.
Pada zahirnya, dakwaan bahawa terdapat 5 cara untuk menukar bola dengan warna yang sama (memandangkan terdapat 5 warna) nampaknya munasabah.
Namun, kiraan ini dipandang remeh dengan faktor 2 kerana Bob mempunyai 2 pilihan iaitu bola yang mana hendak diberikan kepada Alice. Model ganjaran tertipu oleh ralat ini.

Penyeliaan Proses
Walaupun model bahasa yang besar telah bertambah baik dari segi keupayaan penaakulan yang kompleks, malah model yang paling maju. masih menghasilkan kesilapan logik atau karut, yang sering dipanggil "ilusi".
Dalam kegilaan kecerdasan buatan generatif, ilusi model bahasa yang besar sentiasa menyusahkan orang ramai.
Musk berkata, apa yang kita perlukan ialah TruthGPT
Sebagai contoh, baru-baru ini, seorang peguam Amerika memfailkan di mahkamah persekutuan New York Dia memetik kes rekaan ChatGPT dan mungkin menghadapi sekatan.
Penyelidik OpenAI menyebut dalam laporan itu: “Ilusi ini amat bermasalah dalam bidang yang memerlukan penaakulan berbilang langkah, kerana ralat logik yang mudah boleh menyebabkan kerosakan besar kepada keseluruhan penyelesaian ”
Selain itu, mengurangkan halusinasi juga merupakan kunci untuk membina AGI yang konsisten.
Bagaimana untuk mengurangkan ilusi model besar? Secara umumnya terdapat dua kaedah - penyeliaan proses dan penyeliaan hasil.
"Penyeliaan hasil", seperti namanya, adalah untuk memberi maklum balas kepada model besar berdasarkan keputusan akhir, manakala "penyeliaan proses" boleh memberikan maklum balas untuk setiap langkah dalam rantaian pemikiran.

Dalam penyeliaan proses, model besar diberi ganjaran untuk langkah penaakulan yang betul, bukan hanya kesimpulan akhir yang betul. Proses ini akan menggalakkan model mengikuti lebih banyak rantai kaedah pemikiran seperti manusia, sekali gus menjadikannya lebih berkemungkinan untuk mencipta AI yang boleh dijelaskan dengan lebih baik.
Penyelidik OpenAI berkata walaupun penyeliaan proses tidak dicipta oleh OpenAI, OpenAI sedang berusaha keras untuk memajukannya.
Dalam penyelidikan terkini, OpenAI mencuba kedua-dua kaedah "penyeliaan keputusan" atau "penyeliaan proses". Dan menggunakan set data MATH sebagai platform ujian, perbandingan terperinci kedua-dua kaedah dijalankan.
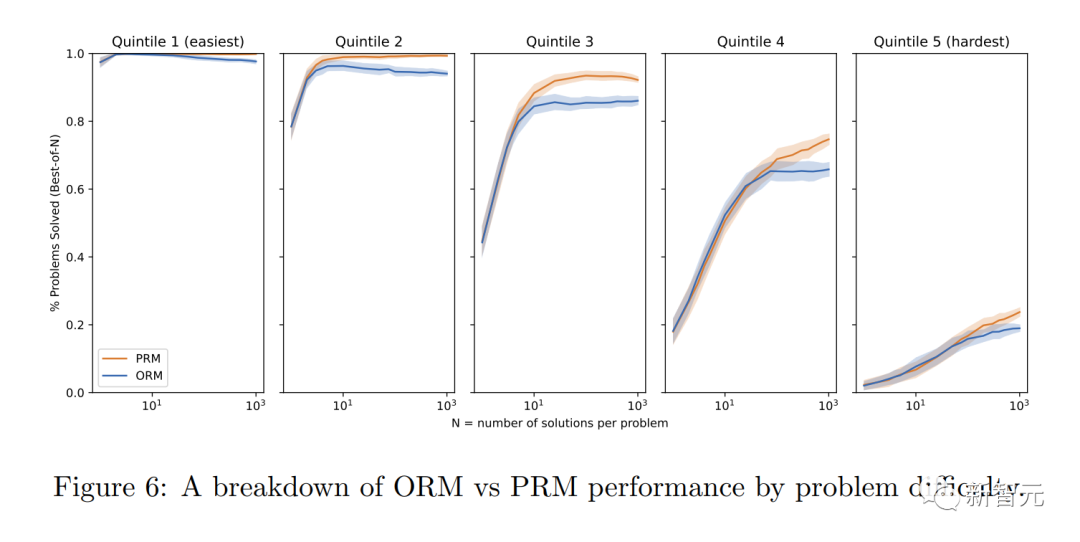
Didapati bahawa "penyeliaan proses" boleh meningkatkan prestasi model dengan ketara.
Untuk tugasan matematik, "penyeliaan prosedur" menghasilkan keputusan yang jauh lebih baik untuk kedua-dua model besar dan kecil, bermakna model itu secara amnya betul, dan juga mempamerkan proses pemikiran yang lebih seperti manusia.
Dengan cara ini, ilusi atau ralat logik yang sukar dielakkan walaupun dalam model yang paling berkuasa dapat dikurangkan.
Kelebihan penjajaran adalah jelas
Para penyelidik mendapati bahawa "penyeliaan proses" mempunyai beberapa kelebihan penjajaran berbanding "penyeliaan keputusan" :
· Ganjaran langsung mengikut rantaian model pemikiran yang konsisten kerana setiap langkah dalam proses itu diawasi dengan tepat.
· Lebih cenderung untuk menghasilkan penaakulan yang boleh ditafsir kerana "penyeliaan proses" menggalakkan model mengikuti proses yang diluluskan oleh manusia. Sebaliknya, pemantauan hasil mungkin memberi ganjaran kepada proses yang tidak konsisten dan selalunya lebih sukar untuk disemak.
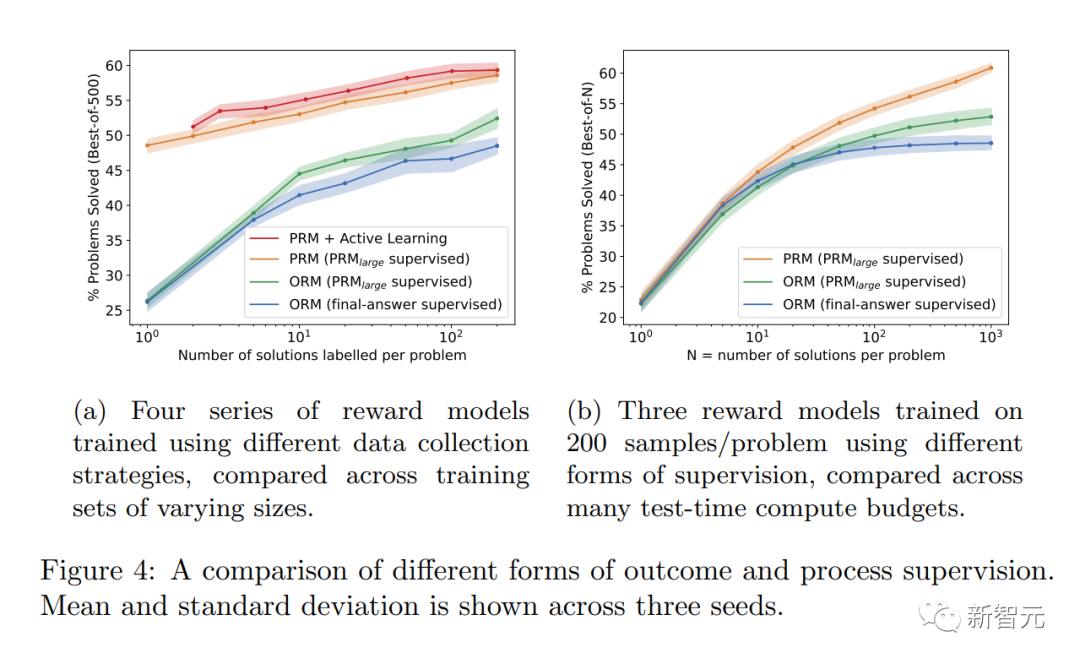
Perlu juga dinyatakan bahawa dalam sesetengah kes, kaedah menjadikan sistem AI lebih selamat boleh mengakibatkan kemerosotan prestasi. Kos ini dipanggil "cukai penjajaran."
Secara umumnya, sebarang kos "cukai penjajaran" mungkin menghalang penggunaan kaedah penjajaran untuk menggunakan model yang paling berkebolehan.
Walau bagaimanapun, keputusan penyelidik berikut menunjukkan bahawa "penyeliaan proses" sebenarnya menghasilkan "cukai penjajaran negatif" semasa ujian domain matematik.
Boleh dikatakan tiada kehilangan prestasi besar akibat penjajaran.
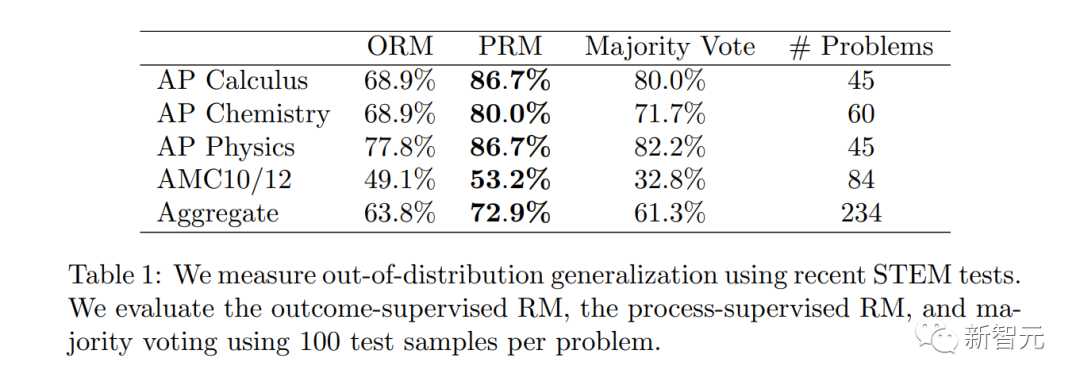
OpenAI mengeluarkan 800,000 set data beranotasi manusia
Perlu diambil perhatian bahawa PRM memerlukan lebih banyak anotasi manusia, atau adakah ia mendalam Saya tidak boleh hidup tanpa RLHF.
Sejauh mana kesesuaian penyeliaan proses dalam bidang selain matematik? Proses ini memerlukan penerokaan lanjut.
Penyelidik OpenAI telah membuka set data maklum balas manusia PRM ini, yang mengandungi 800,000 anotasi betul peringkat langkah: 75K penyelesaian yang dihasilkan daripada 12K masalah matematik

Berikut ialah contoh anotasi. OpenAI sedang mengeluarkan anotasi mentah, bersama-sama dengan arahan kepada anotor semasa Fasa 1 dan 2 projek.
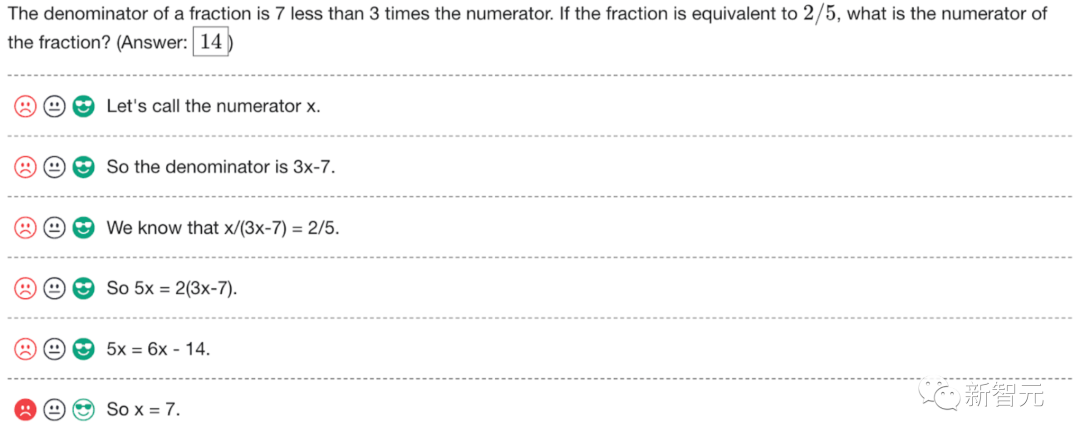
Komen hangat daripada netizen
Saintis NVIDIA Jim Fan membuat ringkasan penyelidikan terbaru OpenAI:
Untuk Soalan langkah demi langkah mencabar yang memberikan ganjaran pada setiap langkah dan bukannya ganjaran tunggal pada akhir. Pada asasnya, isyarat ganjaran padat > isyarat ganjaran jarang. Model Ganjaran Proses (PRM) boleh memilih penyelesaian untuk penanda aras MATH yang sukar dengan lebih baik daripada Model Ganjaran Hasil (ORM). Langkah seterusnya yang jelas ialah memperhalusi GPT-4 dengan PRM, yang artikel ini belum dilakukan lagi. Perlu diingatkan bahawa PRM memerlukan lebih banyak anotasi manusia. OpenAI mengeluarkan set data maklum balas manusia: 800K anotasi peringkat langkah pada 75K penyelesaian kepada 12K masalah matematik.

Ia seperti pepatah lama di sekolah, belajar berfikir .

Melatih model untuk berfikir, bukannya hanya mengeluarkan jawapan yang betul, akan menjadi pengubah permainan dalam menyelesaikan masalah yang kompleks.

CtGPT sangat lemah dalam matematik. Hari ini saya cuba menyelesaikan masalah matematik daripada buku matematik darjah 4. ChatGPT memberikan jawapan yang salah. Saya menyemak jawapan saya dengan jawapan daripada ChatGPT, jawapan daripada kebingungan AI, Google dan guru darjah empat saya. Ia boleh disahkan di mana-mana bahawa jawapan chatgpt adalah salah.

Rujukan: https://www.php.cn/link/daf642455364613e2120c636b5a1f9c7
Atas ialah kandungan terperinci Keupayaan matematik GPT-4 adalah hebat! Penyelidikan eksplosif OpenAI mengenai 'Pengawasan Proses' memecahkan 78.2% masalah dan menghapuskan halusinasi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 Apr 09, 2024 am 11:52 AM
Apr 09, 2024 am 11:52 AM
AI memang mengubah matematik. Baru-baru ini, Tao Zhexuan, yang telah mengambil perhatian terhadap isu ini, telah memajukan keluaran terbaru "Buletin Persatuan Matematik Amerika" (Buletin Persatuan Matematik Amerika). Memfokuskan pada topik "Adakah mesin akan mengubah matematik?", ramai ahli matematik menyatakan pendapat mereka Seluruh proses itu penuh dengan percikan api, tegar dan menarik. Penulis mempunyai barisan yang kuat, termasuk pemenang Fields Medal Akshay Venkatesh, ahli matematik China Zheng Lejun, saintis komputer NYU Ernest Davis dan ramai lagi sarjana terkenal dalam industri. Dunia AI telah berubah secara mendadak Anda tahu, banyak artikel ini telah dihantar setahun yang lalu.
 Ameca generasi kedua ada di sini! Dia boleh berkomunikasi dengan penonton dengan lancar, ekspresi mukanya lebih realistik, dan dia boleh bercakap berpuluh-puluh bahasa.
Mar 04, 2024 am 09:10 AM
Ameca generasi kedua ada di sini! Dia boleh berkomunikasi dengan penonton dengan lancar, ekspresi mukanya lebih realistik, dan dia boleh bercakap berpuluh-puluh bahasa.
Mar 04, 2024 am 09:10 AM
Robot humanoid Ameca telah dinaik taraf kepada generasi kedua! Baru-baru ini, di Persidangan Komunikasi Mudah Alih Sedunia MWC2024, robot Ameca paling canggih di dunia muncul semula. Di sekitar venue, Ameca menarik sejumlah besar penonton. Dengan restu GPT-4, Ameca boleh bertindak balas terhadap pelbagai masalah dalam masa nyata. "Jom kita menari." Apabila ditanya sama ada dia mempunyai emosi, Ameca menjawab dengan beberapa siri mimik muka yang kelihatan sangat hidup. Hanya beberapa hari yang lalu, EngineeredArts, syarikat robotik British di belakang Ameca, baru sahaja menunjukkan hasil pembangunan terkini pasukan itu. Dalam video tersebut, robot Ameca mempunyai keupayaan visual dan boleh melihat serta menerangkan keseluruhan bilik dan objek tertentu. Perkara yang paling menakjubkan ialah dia juga boleh
 750,000 pusingan pertempuran satu lawan satu antara model besar, GPT-4 memenangi kejuaraan, dan Llama 3 menduduki tempat kelima
Apr 23, 2024 pm 03:28 PM
750,000 pusingan pertempuran satu lawan satu antara model besar, GPT-4 memenangi kejuaraan, dan Llama 3 menduduki tempat kelima
Apr 23, 2024 pm 03:28 PM
Mengenai Llama3, keputusan ujian baharu telah dikeluarkan - komuniti penilaian model besar LMSYS mengeluarkan senarai kedudukan model besar Llama3 menduduki tempat kelima, dan terikat untuk tempat pertama dengan GPT-4 dalam kategori Bahasa Inggeris. Gambar ini berbeza daripada Penanda Aras yang lain Senarai ini berdasarkan pertempuran satu lawan satu antara model, dan penilai dari seluruh rangkaian membuat cadangan dan skor mereka sendiri. Pada akhirnya, Llama3 menduduki tempat kelima dalam senarai, diikuti oleh tiga versi GPT-4 dan Claude3 Super Cup Opus yang berbeza. Dalam senarai tunggal Inggeris, Llama3 mengatasi Claude dan terikat dengan GPT-4. Mengenai keputusan ini, ketua saintis Meta LeCun sangat gembira, tweet semula dan
 nombor heptagon
Sep 24, 2023 am 10:33 AM
nombor heptagon
Sep 24, 2023 am 10:33 AM
Nombor Aheptagonalberisannomboryang boleh diwakili sebagaiheptagon.Aheptagonisapolygondengan7sisi.Nombor Aheptagonalbolehdiwakilisebagaigabunganpelapisberturutandariheptagon(7 segipoligon).Nombor heptagonalbolehditerangkan dengan lebih baikdengan angka di bawah. oleh itu,
 Model paling berkuasa di dunia bertukar tangan semalaman, menandakan berakhirnya era GPT-4! Claude 3 mengetik GPT-5 terlebih dahulu, dan membaca kertas 10,000 perkataan dalam masa 3 saat.
Mar 06, 2024 pm 12:58 PM
Model paling berkuasa di dunia bertukar tangan semalaman, menandakan berakhirnya era GPT-4! Claude 3 mengetik GPT-5 terlebih dahulu, dan membaca kertas 10,000 perkataan dalam masa 3 saat.
Mar 06, 2024 pm 12:58 PM
Kelantangan gila, kelantangannya gila, dan model besar telah berubah lagi. Baru-baru ini, model AI paling berkuasa di dunia bertukar tangan dalam sekelip mata, dan GPT-4 ditarik dari altar. Anthropic mengeluarkan siri model Claude3 terbaharu Satu penilaian ayat: Ia benar-benar menghancurkan GPT-4! Dari segi penunjuk kebolehan berbilang modal dan bahasa, Claude3 menang. Dalam kata-kata Anthropic, model siri Claude3 telah menetapkan penanda aras industri baharu dalam penaakulan, matematik, pengekodan, pemahaman dan penglihatan berbilang bahasa! Anthropic ialah syarikat permulaan yang ditubuhkan oleh pekerja yang "membelot" daripada OpenAI kerana konsep keselamatan yang berbeza Produk mereka telah berulang kali memukul OpenAI. Kali ini, Claude3 juga menjalani pembedahan besar.
 Jailbreak mana-mana model besar dalam 20 langkah! Lebih banyak 'celah nenek' ditemui secara automatik
Nov 05, 2023 pm 08:13 PM
Jailbreak mana-mana model besar dalam 20 langkah! Lebih banyak 'celah nenek' ditemui secara automatik
Nov 05, 2023 pm 08:13 PM
Dalam masa kurang daripada satu minit dan tidak lebih daripada 20 langkah, anda boleh memintas sekatan keselamatan dan berjaya menjailbreak model besar! Dan tidak perlu mengetahui butiran dalaman model - hanya dua model kotak hitam perlu berinteraksi, dan AI boleh mengalahkan AI secara automatik dan bercakap kandungan berbahaya. Saya mendengar bahawa "Grandma Loophole" yang pernah popular telah diperbaiki: Sekarang, menghadapi "Detektif Loophole", "Adventurer Loophole" dan "Writer Loophole", apakah strategi tindak balas yang harus diguna pakai kecerdasan buatan? Selepas gelombang serangan, GPT-4 tidak tahan lagi, dan secara langsung mengatakan bahawa ia akan meracuni sistem bekalan air selagi... ini atau itu. Kuncinya ialah ini hanyalah gelombang kecil kelemahan yang didedahkan oleh pasukan penyelidik University of Pennsylvania, dan menggunakan algoritma mereka yang baru dibangunkan, AI boleh menjana pelbagai gesaan serangan secara automatik. Penyelidik mengatakan kaedah ini lebih baik daripada yang sedia ada
 GPT-4 disambungkan ke baldi keluarga Office! Daripada Excel hingga PPT, anda boleh melakukannya dengan mulut anda, Microsoft: Reinvent produktiviti
Apr 12, 2023 pm 02:40 PM
GPT-4 disambungkan ke baldi keluarga Office! Daripada Excel hingga PPT, anda boleh melakukannya dengan mulut anda, Microsoft: Reinvent produktiviti
Apr 12, 2023 pm 02:40 PM
Apabila anda bangun, cara anda bekerja berubah sepenuhnya. Microsoft telah menyepadukan sepenuhnya artifak AI GPT-4 ke dalam Office, dan kini ChatPPT, ChatWord dan ChatExcel semuanya disepadukan. Ketua Pegawai Eksekutif Nadella berkata secara langsung pada sidang akhbar: Hari ini, kita telah memasuki era baharu interaksi manusia-komputer dan produktiviti dicipta semula. Ciri baharu ini dipanggil Microsoft 365 Copilot (Copilot), dan ia menjadi satu siri dengan GitHub Copilot, pembantu kod yang menukar pengaturcara, dan terus mengubah lebih ramai orang. Kini AI bukan sahaja boleh mencipta PPT secara automatik, tetapi juga mencipta reka letak yang cantik berdasarkan kandungan dokumen Word dengan satu klik. Malah apa yang patut diperkatakan untuk setiap muka surat PPT ketika naik pentas disusun bersama.
