

Terlalu sedikit indeks akan mengakibatkan kecekapan pertanyaan yang rendah akan menjejaskan prestasi program, dan penggunaan indeks harus konsisten dengan keadaan sebenar.
Indeks yang disokong oleh Innodb termasuk:
Carian teks penuh, menggunakan indeks terbalik
Indeks cincang, adaptif, tiada campur tangan manusia , dibuat berdasarkan halaman indeks berkelompok dalam kumpulan penimbal, dan keseluruhan jadual tidak akan dicincang, jadi penciptaan indeks adalah sangat pantas.
Indeks pokok B+, indeks dalam erti kata tradisional, kini merupakan indeks yang paling berkesan dan biasa digunakan dalam pangkalan data hubungan.
Pokok B+ tidak dapat mengesan rekod baris tertentu pada jadual, tetapi mengembalikan halaman tempat rekod baris terletak, akhirnya, berdasarkan maklumat slot dalam memori dan rekod baris pengepala seterusnya rekod maklumat untuk kedudukan yang tepat.
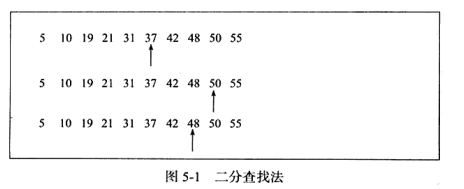
Carian binari hanya boleh digunakan untuk mencari set data linear tersusun, mengambil median setiap kali , kecil ke hadapan, besar ke belakang. Kerumitan masa mencari nombor 48 dalam tatasusunan tertib ialah log N, seperti yang ditunjukkan dalam rajah di bawah.
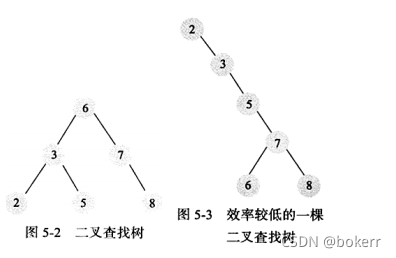
Pokok carian binari merujuk kepada, Dalam binari pokok, ia berpuas hati bahawa: nod anak kiri mana-mana nod adalah lebih kecil daripada dirinya sendiri, dan nod anak kanan mana-mana nod adalah lebih besar daripada dirinya sendiri, ia adalah pokok carian binari.
Pokok binari biasa tidak dapat menjamin masa akses O(logN), kerana dalam kes yang melampau, ia juga boleh merosot menjadi senarai terpaut.
Apabila satu set data tersusun dibina untuk membina pokok binari, maka senarai terpaut diperolehi Pada masa ini, kerumitan masa menjadi: O(N)
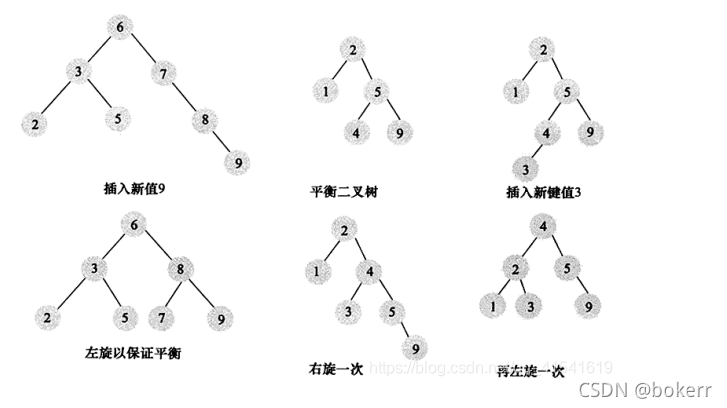
Pokok B+ ialah pokok carian seimbang yang direka khas untuk cakera atau peranti tambahan akses langsung yang lain Dalam pepohon B+, semua nod rekod disimpan secara berurutan dalam daun lapisan yang sama mengikut saiz. nilai kunci. Nod dipautkan oleh setiap penunjuk nod daun.1. Definisi lengkap pokok B+Pokok B+ tertib M perlu memenuhi sifat berikut: Semua takrifan berikut berkenaan pembahagian dua nombor , jika ia tidak boleh dibahagi, bundarkan ia bukannya membuang tempat perpuluhan. (Kecuali untuk menyimpulkan ketaksamaan dalam kes) 1) Item data mesti wujud pada nod daun 2) Nod bukan daun menyimpan kata kunci M-1 untuk menunjukkan arah carian yang saya wakili; Kata kunci terkecil dalam subpohon i + 1 nod bukan daun; 3) Pokok B+ sama ada hanya mempunyai satu nod daun sebagai nod akar (tanpa sebarang nod anak, bilangan nodnya mesti tergolong dalam set: {2~M}; 🎜>
4) Kecuali akar, bilangan nod anak semua nod bukan daun mesti memenuhi bahawa ia tergolong dalam set: { M/2, M };
5) Semua daun berada pada kedalaman yang sama, dan item data nod daun ialah Nombor mesti tergolong dalam set: { L/2, L }; > Anggapkan bahawa jumlah panjang semua medan tidak melebihi 500 bait, dengan kunci utama 50 bait Contohnya, simulasikan terbitan pepohon B+, termasuk ruang yang diduduki oleh rekod baris itu sendiri
Adalah diketahui bahawa semua rekod baris akan menggunakan beberapa bait untuk merekodkan maklumat baris: seperti medan panjang berubah-ubah, pengepala rekod baris, ID urus niaga, penuding balik, dsb.
create table context( id varchar(50) primary key, name varchar(50) not null, description varchar(360) );
Nod daun mewakili halaman data, dan pilihan nilai M dan L berkait rapat dengannya. Andaikan saiz halaman data ialah: P/bait (mengambil MySQL yang dibincangkan dalam artikel ini sebagai contoh, saiz halaman data ialah 16K, iaitu 16384 bait)
Pada nod bukan daun: kunci pokok B+ ialah kunci utama Dalam contoh ini, diandaikan bahawa kunci utama ialah 50 bait, dan kunci pepohon B+ tertib-M ialah M -1 , menduduki: 50 * (M - 1) bait ruang; , dengan mengandaikan bahawa setiap penuding cawangan menduduki 4 bait storan, kemudian nod daun bukan In, jumlah penggunaan ruang ialah: 50 * (M - 1) + 4 * M = 54M - 50 bait.
Apabila menggunakan MySQL, dan dengan mengandaikan kunci utama ialah 50 bait, ketaksamaan diwujudkan: 54M - 50 <= P, di mana P = 16384, maka penyelesaian untuk M ialah: M <= 302, pesanan M Nilai pilihan maksimum adalah lebih kurang: 302 di sini kita boleh memilih maksimum 302 pesanan B+ pokok.
Pada nod daun, kapasiti maksimum setiap baris yang ditakrifkan dalam jadual yang diketahui ialah: 500 bait Pada masa ini, ungkapan berikut ditetapkan: L * 500 <= 16384 ditetapkan daripada L ialah :L <= 32;
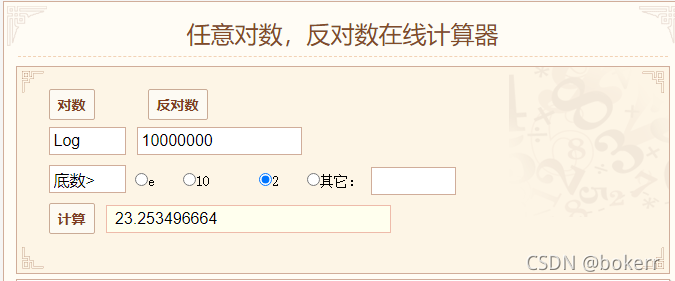
Seperti yang ditunjukkan di bawah, terdapat data 5000W pada masa ini dan ketinggian pokok lebih besar daripada 3, bermakna kita hanya memerlukan sehingga 4 IO cakera untuk mencari data.
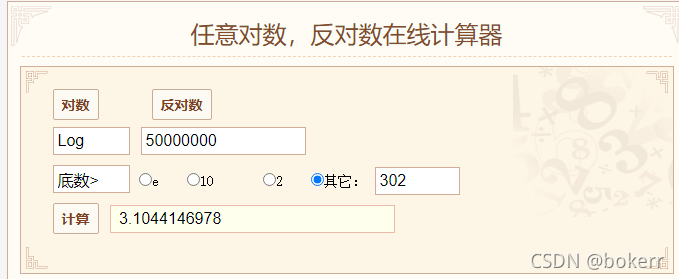 Rujuk rajah di bawah, batas masa terburuk bagi pokok binari seimbang ialah: 1.44 * logN = 25.58 * 1.44 = 36.83; iaitu, jika data 5000W menggunakan pokok binari yang seimbang, had masa yang paling teruk bagi pokok Dalam kes yang paling teruk, akan terdapat lebih daripada 36 masa IO cakera, dan sekurang-kurangnya 26 masa IO cakera.
Rujuk rajah di bawah, batas masa terburuk bagi pokok binari seimbang ialah: 1.44 * logN = 25.58 * 1.44 = 36.83; iaitu, jika data 5000W menggunakan pokok binari yang seimbang, had masa yang paling teruk bagi pokok Dalam kes yang paling teruk, akan terdapat lebih daripada 36 masa IO cakera, dan sekurang-kurangnya 26 masa IO cakera.
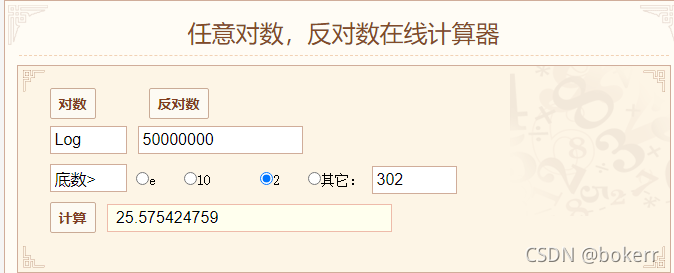 Gambar menunjukkan pokok B+ biasa 5 urutan (M = 5), di mana setiap nod mempunyai maksimum 5 nilai (L = 5); L tidak Mesti sama, seperti dalam analisis di atas: M dan L bergantung kepada keadaan sebenar.
Gambar menunjukkan pokok B+ biasa 5 urutan (M = 5), di mana setiap nod mempunyai maksimum 5 nilai (L = 5); L tidak Mesti sama, seperti dalam analisis di atas: M dan L bergantung kepada keadaan sebenar.
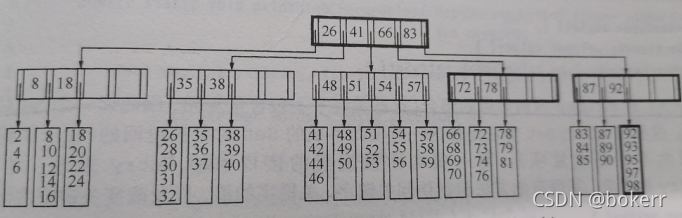 Hahaha, melukis gambar terlalu menyusahkan Saya menganalisis foto dari buku "Data Structure and Algorithm" dan ia juga secerdik saya.
Hahaha, melukis gambar terlalu menyusahkan Saya menganalisis foto dari buku "Data Structure and Algorithm" dan ia juga secerdik saya.
Di sini kita hanya bercakap tentang definisi pepohon B+ dan butiran pemilihan parameter Penyisipan pepohon B+ dan pemadaman pepohon B+ tidak dibincangkan secara terperinci.
4. Indeks pokok B+
1. Indeks berkelompok
2. Indeks tambahan
Setiap jadual boleh mempunyai berbilang indeks tambahan
Kelemahan bantu indeks ialah ia mestilah diskret Indeks berkelompok mendapat data baris yang lengkap, walaupun penanda halaman yang disimpan dalam indeks sekunder telah ditemui.
5. Mengenai nilai Cardinality
1. Definisi kardinaliti
2. Kemas kini Cardinality
1. Indeks bersama
create table t ( a int, b int, primary key (a), key idx_ab (a, b) )engine=innodb;
Dalam jadual di atas, tetapkan kunci primer bersama idx_ab, dan struktur storannya adalah seperti berikut:
如上图所述,键值有序,需要注意的是,如下SQL可以使用该索引:
select * from t where a = ? and b = ? select * from t where a = ?
如下sql 不能使用该索引;查看示例图中联合索引叶子节点存放的数据我们可以发现:两个叶子节点上,关于字段b的存放显然不是有序的。
select * from t where b = ?
联合索引本身还有一个好处,辅助索引本身已经对第二个键值进行了排序,如下语句可以避免多一次的排序。
select b from t where a = ? order by b desc
辅助索引中已经对 b 列进行了排序,所以此时使用辅助索引更高效。
Innodb 支持覆盖索引(covering index,或称为索引覆盖),即从辅助索引中就可以得到结果,而不需要查询聚集索引中的记录。由于辅助索引不包含完整的行记录,从而比聚集索引小很多,可以极大地减少IO操作。
再形如:select count(*) from table name where b <= ? and b >= ? 的sql,如果有满足条件的辅助索引,它会优先使用辅助索引因为辅助索引体积远远小于聚集索引。
某些情况下,通过EXPLAIN指令会发现一些SQL,并没有选择使用满足条件的辅助索引去查数据,而是直接选择了全表扫描(聚集索引),这种情况一般发生于 范围查找、join链接操作等情况下。
当发生此类查找时,一般是查找一个较大范围内的数据,当范围较大时同样意味着大量的数据需要再进行一次书签访问去获取完整数据,已知顺序读取速度大于离散读取速度,所以此时不会使用辅助索引,而是直接查聚集索引(整表扫描)。一般情况下,当访问数据超过表中数据总数的20%时,索引覆盖不再适用,而需要进行全表扫描。)
create table t ( a int, b int, primary key (a,b), key idx_a (a) )engine=innodb;
如上定义表,a和b两列构成联合索引,列a上有独立的辅助索引,对于语句:
select * from t where a >= 3 and a<= 1000000;
按理说,该语句是可以选择使用辅助索引 idx_a 进行查找的,但是通过执行 explain 发现该语句发生了全表扫描(聚集索引),而不是使用辅助索引: idx_a。
索引提示指MySQL支持在SQL中显式的告诉优化器使用哪个索引。
当优化器选择索引错误,可以手动指定索引。[极小概率事件]
当索引太多时,优化器选择索引的操作时间开销大,此时可以手动指定索引。
使用索引提示的前提是我们自己要对sql的执行非常了解,非常明确该操作能带来更好的效率。
MySQL5.6版本开始支持Multi-Range Read (MRR) 优化,它的目的是减少磁盘的离散读,将离散的访问优化为相对有序的访问,它使用于 range ref eq_ref 类型的查询。
1).MRR优化有如下好处:
它使得数据访问变得较为顺序,当根据辅助索引查询时,会将查询结果按照主键排序后,再去聚集索引进行书签查询。
减少缓冲池中页被替换的次数;
批量处理对键值的查询操作;
2).对于 JOIN 和 范围查询,Innodb 中MRR的工作方式为:
将通过辅助索引查询到的数据放到一个缓存中,此时这些数据是按照辅助索引键值排序的;
将缓存中的数据按照主键顺序排序;
根据主键顺序访问实际数据文件;
想象一下,在缓冲池不够大的情况下进行大范围数据查询,会导致数据页频繁被从LRU列表中移除。如果被查询的辅助索引不是按主键排序的,可能会多次发生如下的情况:一个页在同一次查询中被剔出LRU列表后又再次被加载出来。
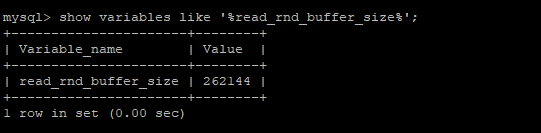
配置项:read_rnd_buffer_size 用来配置上述描述的键值缓冲区大小,默认为256K;当发生溢出时,执行器只对已经缓存的数据进行排序。
3).对于范围查询:MMR还支持对键值的拆分,将范围查询拆分为键值对进行批量的数据查询.
create table t ( a integer, b integer, primary key (a), key idx_ab (a, b) )engine=innodb;
select * from t where a = 50 and b>= 100 and b<= 20000
由于存在辅助索引 idx_ab,上述sql语句的条件可以拆分为键值对集合:{( 50 , 100 ),( 50 , 101 ),......,( 50 , 20000 )},这样就将范围查询优化为对键值对的查询;否则会进行范围查询,将 b ∈ {100,20000} 的所有数据都取出。
Multi-Range Read 是否启用,由如下参数中的,mrr 和 mrr_cost_based 标记进行控制,mrr标记是 MRR优化的开关。若前者设置为on,后者设置为off表示当满足条件时总是使用MRR优化;若前者设置为 on,后者也设置 on 表示通过 cost base 方式判断是否需要 MRR优化。

Pengoptimuman ICP juga disokong bermula dari MySQL 5.6 Ia adalah kaedah pengoptimuman untuk pertanyaan berdasarkan indeksnya menyokong jenis pertanyaan Optimize: julat, ref, eq_ref, ref_or_null.
Apabila ICP dilumpuhkan, lapisan enjin storan akan melintasi indeks untuk mencari rekod baris yang lengkap kemudian mengembalikannya ke lapisan pangkalan data (lapisan Pelayan), dan kemudian melaksanakan di mana keadaan untuk penapis baris data ini.
Apabila ICP didayakan, jika keadaan di mana boleh menggunakan indeks, MySQL akan meletakkan bahagian operasi penapisan ini ke dalam lapisan enjin storan menapis melalui indeks dan mengambil keluar keseluruhan data yang memenuhi data baris mana dan kembali. Menggunakan ICP boleh mengurangkan kekerapan lapisan enjin storan mengakses rekod baris, dan pada masa yang sama mengurangkan bilangan kali lapisan pangkalan data (lapisan Pelayan) mesti mengakses enjin storan.
[Prasyarat untuk menggunakan penapis ini ialah: keadaan penapis mestilah julat yang boleh diliputi oleh indeks]
Tekan Turun Keadaan Indeks prinsip kerja Seperti berikut:
1) Apabila ICP tidak digunakan
(1) Apabila enjin storan membaca baris seterusnya, ia membaca rekod baris yang berkaitan dari nod daun indeks tambahan , dan kemudian menggunakan rujukan kunci utama rekod dalam penanda halaman dikembalikan ke lapisan pangkalan data (Lapisan pelayan) untuk menanyakan rekod baris yang lengkap.
(2) Lapisan pangkalan data melakukan penapisan keadaan pada rekod baris lengkap Jika data baris memenuhi syarat di mana, ia akan digunakan, jika tidak, ia akan dibuang.
(3) Lakukan langkah 1 sehingga semua data yang memenuhi syarat dibaca.
2) Cara melakukan imbasan indeks apabila menggunakan ICP
(1) Enjin storan membaca data daripada indeks satu demi satu...
(2) Storan Apabila enjin membaca data daripada indeks, ia menggunakan keadaan where untuk menapis berdasarkan kunci indeks Jika rekod baris tidak memenuhi syarat, enjin storan akan memproses sekeping data seterusnya (kembali ke langkah sebelumnya. ). Hanya apabila syarat pertanyaan dipenuhi, data lengkap akan dibaca daripada indeks berkelompok.
(3) Akhir sekali, lapisan enjin storan akan mengembalikan semua rekod baris lengkap yang memenuhi syarat pertanyaan ke lapisan pangkalan data.
(4) Jika lapisan pangkalan data terus digunakan, syarat pertanyaan selepas itu tidak diliputi oleh indeks akan ditapis.
Atas ialah kandungan terperinci Contoh analisis indeks dan algoritma enjin storan Mysql Innodb. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



