

Model bahasa berskala besar (LLM) mengubah jangkaan pengguna dalam setiap industri. Walau bagaimanapun, membina produk AI generatif yang berpusat pada pertuturan manusia masih sukar kerana fail audio menimbulkan cabaran kepada model bahasa yang besar.
Cabaran utama dalam menggunakan LLM pada fail audio ialah LLM dihadkan oleh tetingkap konteksnya. Sebelum fail audio boleh dimasukkan ke dalam LLM, ia perlu ditukar kepada teks. Semakin panjang fail audio, semakin besar cabaran kejuruteraan untuk memintas had tetingkap konteks LLM. Tetapi dalam senario kerja, kami sering memerlukan LLM untuk membantu kami memproses fail suara yang sangat panjang, seperti mengekstrak kandungan teras daripada rakaman mesyuarat selama beberapa jam atau mencari jawapan kepada soalan tertentu daripada temu bual...
Baru-baru ini, syarikat AI pengecaman pertuturan AssemblyAI melancarkan model baharu yang dipanggil LeMUR. Sama seperti ChatGPT memproses berpuluh-puluh halaman teks PDF, LeMUR boleh menyalin dan memproses sehingga 10 jam rakaman, dan kemudian membantu pengguna meringkaskan kandungan teras ucapan dan menjawab soalan yang dimasukkan oleh pengguna.

Alamat percubaan: https://www.assemblyai.com/playground/v2/source
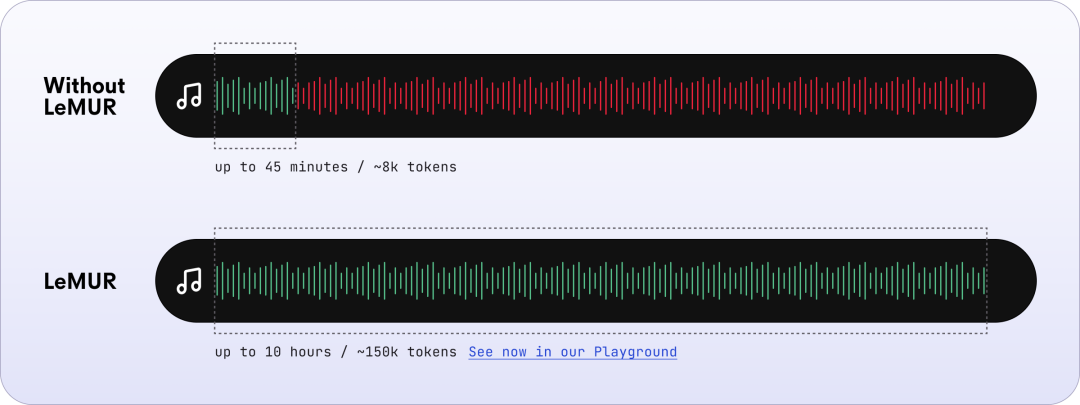
LeMUR ialah singkatan daripada Memanfaatkan Model Bahasa Besar untuk Memahami Pertuturan yang Diiktiraf Ia merupakan rangka kerja baharu untuk menggunakan LLM yang berkuasa pada pertuturan yang ditranskripsi. Dengan hanya satu baris kod (melalui Python SDK AssemblyAI), LeMUR boleh memproses transkripsi kandungan audio sehingga 10 jam dengan cepat, dengan berkesan menukarkannya kepada kira-kira 150,000 token. Sebaliknya, LLM vanila di luar rak hanya boleh menampung sehingga 8K, atau kira-kira 45 minit audio yang ditranskripsi dalam kekangan tetingkap konteksnya.
Untuk mengurangkan kerumitan penggunaan LLM pada fail audio yang ditranskripsi, saluran paip LeMUR terutamanya merangkumi segmentasi pintar, pangkalan data Vektor yang pantas dan beberapa langkah penaakulan (seperti gesaan rantaian pemikiran dan penilaian kendiri), seperti yang ditunjukkan di bawah:
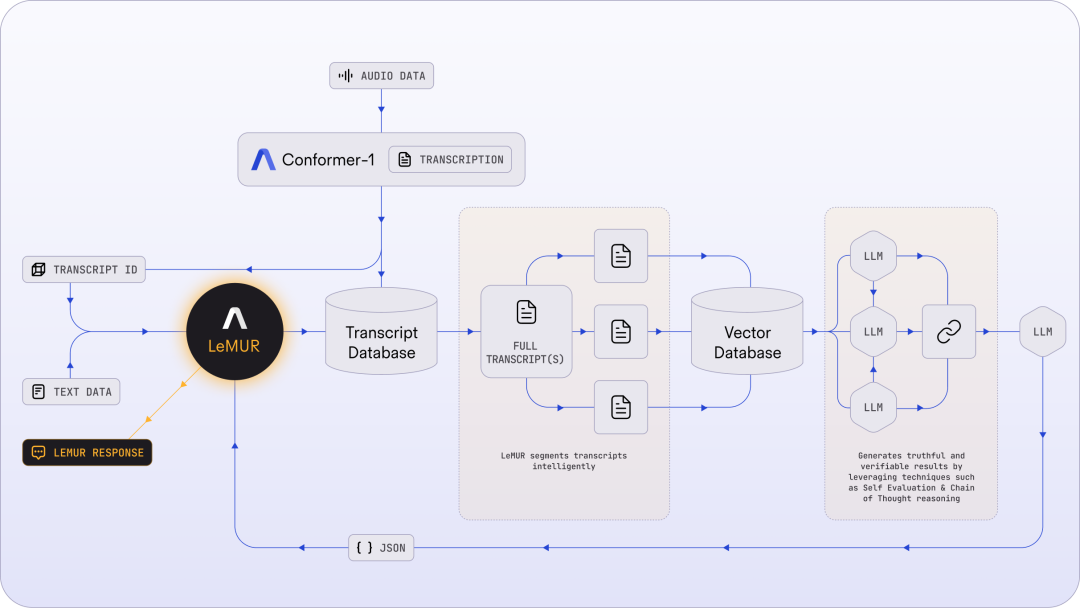
Rajah 1: Seni bina LeMUR membolehkan pengguna menghantar fail transkrip audio yang panjang dan/atau berbilang ke LLM dengan satu panggilan API.
Pada masa hadapan, LeMUR dijangka akan digunakan secara meluas dalam perkhidmatan pelanggan dan bidang lain.

LeMUR membuka beberapa kemungkinan baharu yang menakjubkan yang saya tidak fikir mungkin berlaku hanya beberapa tahun yang lalu. Rasanya benar-benar menakjubkan untuk dapat dengan mudah mengeluarkan cerapan berharga seperti menentukan tindakan terbaik dan hasil panggilan yang arif seperti jualan, janji temu atau tujuan panggilan. —Ryan Johnson, ketua pegawai produk di CallRail, sebuah syarikat teknologi perkhidmatan penjejakan panggilan dan analitik
Gunakan LLM pada berbilang teks audio
LeMUR membenarkan pengguna mendapatkan pemprosesan LLM berbilang fail audio sekaligus Maklum balas dan ke atas hingga 10 jam hasil transkripsi suara, panjang token teks yang ditukar boleh mencapai 150K.
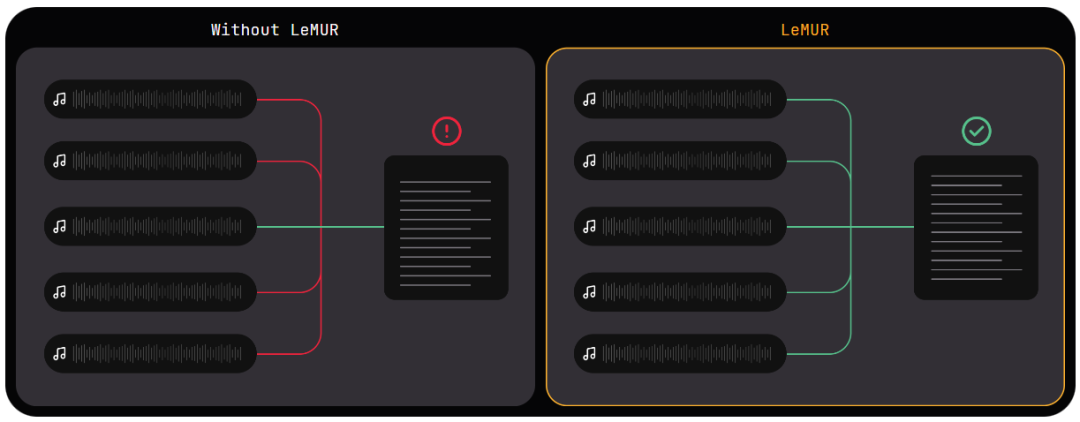
Keluaran yang boleh dipercayai dan selamat
Kerana LeMUR termasuk langkah keselamatan dan penapis kandungan, ia akan memberikan pengguna respons daripada LLM yang kurang berkemungkinan menjana bahasa yang berbahaya atau berat sebelah.
boleh menambah konteks
dalam penaakulan Apabila digunakan, ia membenarkan penggabungan maklumat kontekstual tambahan yang LLM boleh memanfaatkan untuk memberikan hasil yang diperibadikan dan lebih tepat apabila menjana output.
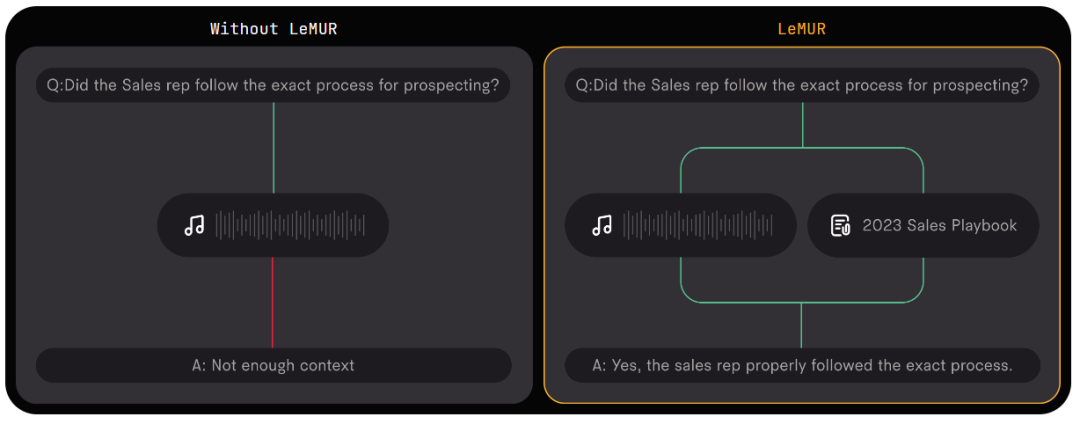
Modular, penyepaduan pantas
LeMUR sentiasa mengembalikan data berstruktur dalam bentuk JSON yang boleh diproses. Pengguna boleh menyesuaikan lagi format output LeMUR untuk memastikan bahawa respons yang diberikan oleh LLM adalah dalam format yang dijangkakan oleh bahagian logik perniagaan mereka yang seterusnya (cth. menukar jawapan kepada nilai Boolean). Dalam proses ini, pengguna tidak perlu lagi menulis kod khusus untuk memproses output LLM.
Menurut pautan ujian yang disediakan oleh AssemblyAI, Heart of the Machine menguji LeMUR.
Antara muka LeMUR menyokong dua kaedah input fail: memuat naik fail audio dan video atau menampal pautan web.
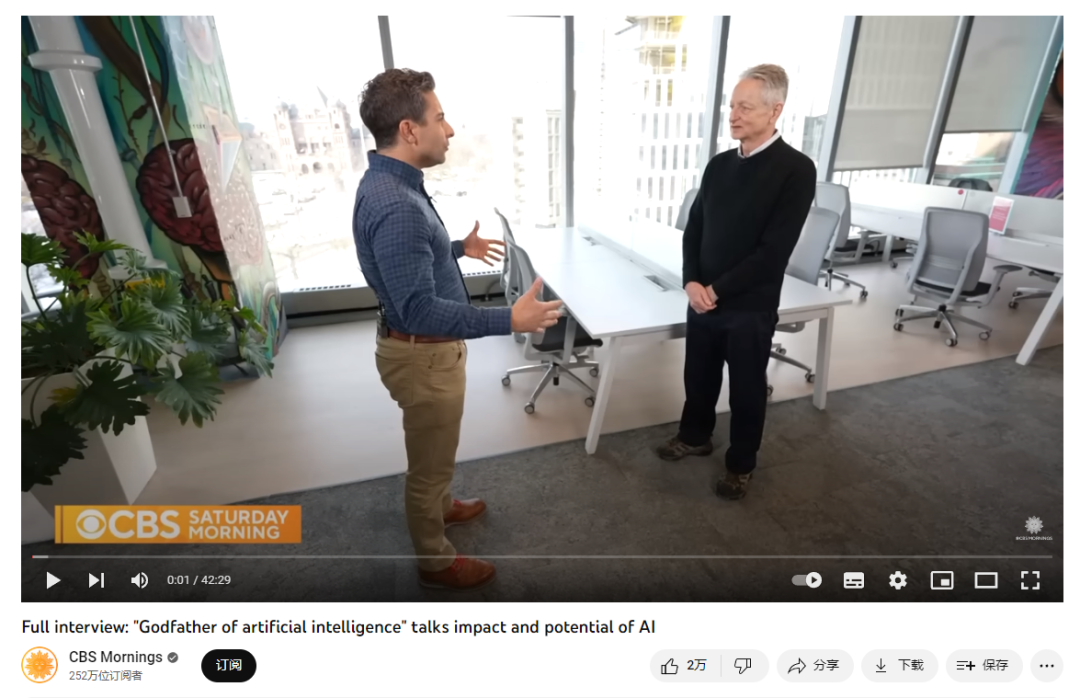
Kami menggunakan data temu bual terkini Hinton sebagai input untuk menguji prestasi LeMUR.
Selepas memuat naik, sistem menggesa kami untuk menunggu seketika kerana ia perlu menukar pertuturan kepada teks terlebih dahulu.
Antara muka selepas transkripsi adalah seperti berikut:
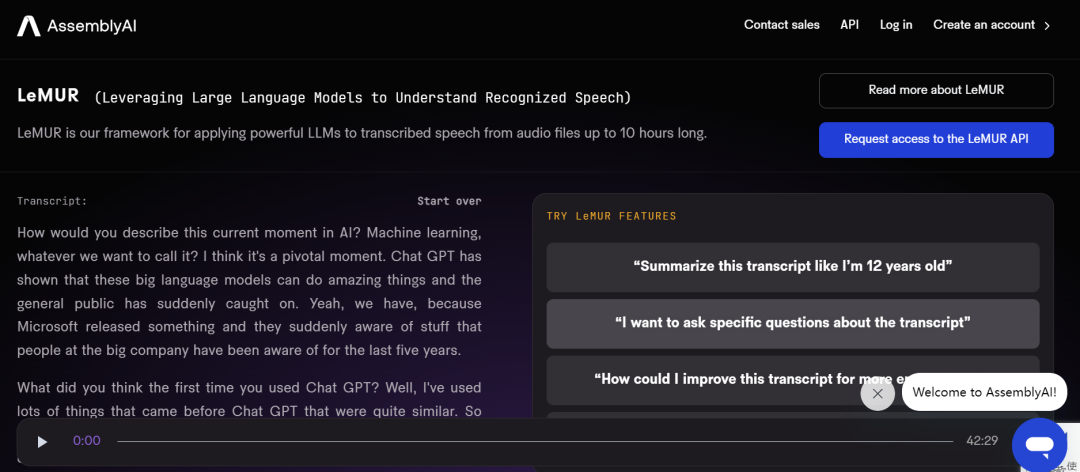
Di sebelah kanan halaman, kita boleh meminta LeMUR meringkaskan temu bual atau menjawab soalan. LeMUR pada asasnya menyelesaikan tugas dengan mudah:
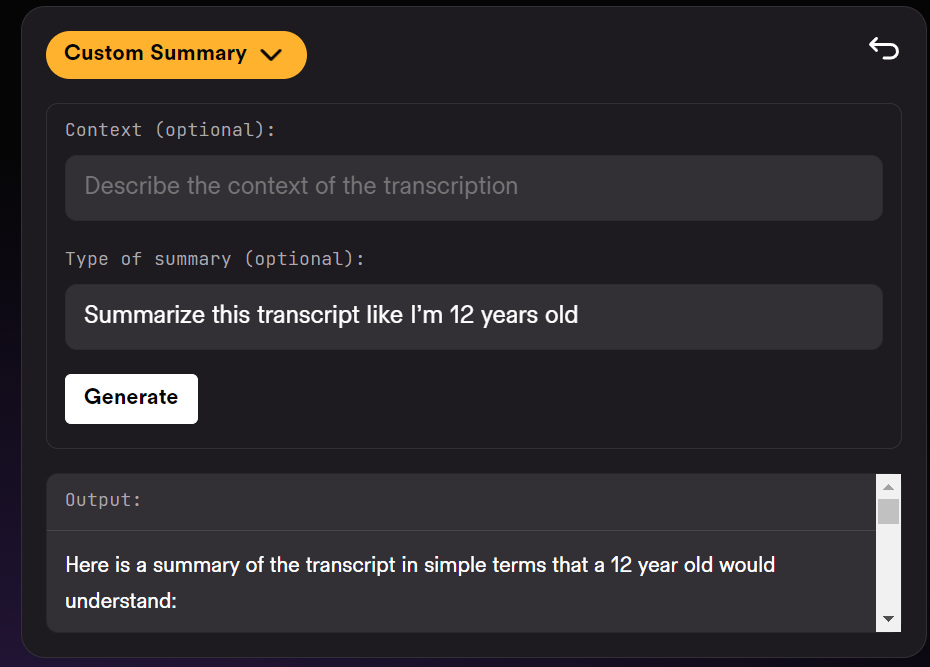
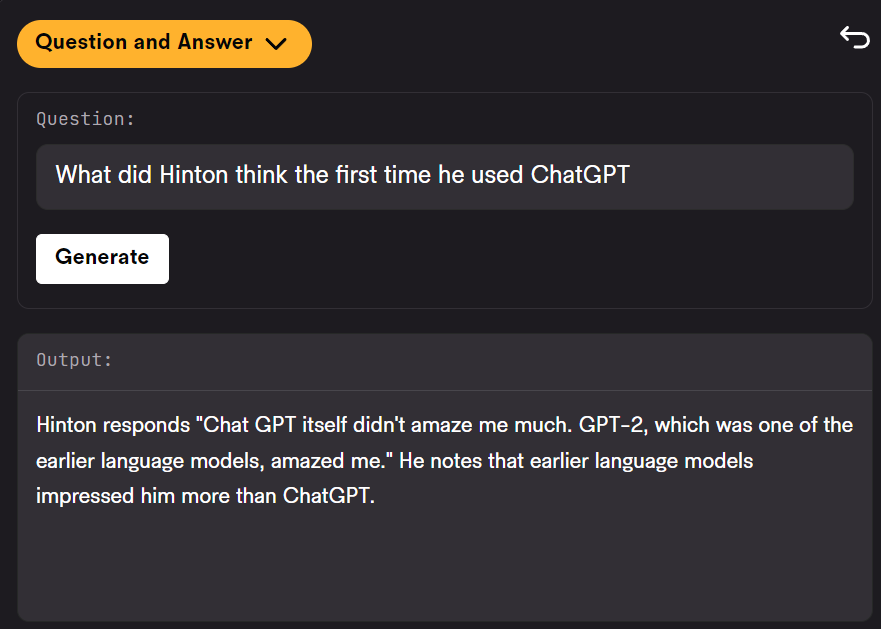
Jika suara yang ingin anda proses ialah ucapan atau balasan perkhidmatan pelanggan, anda juga boleh meminta LeMUR untuk cadangan penambahbaikan.
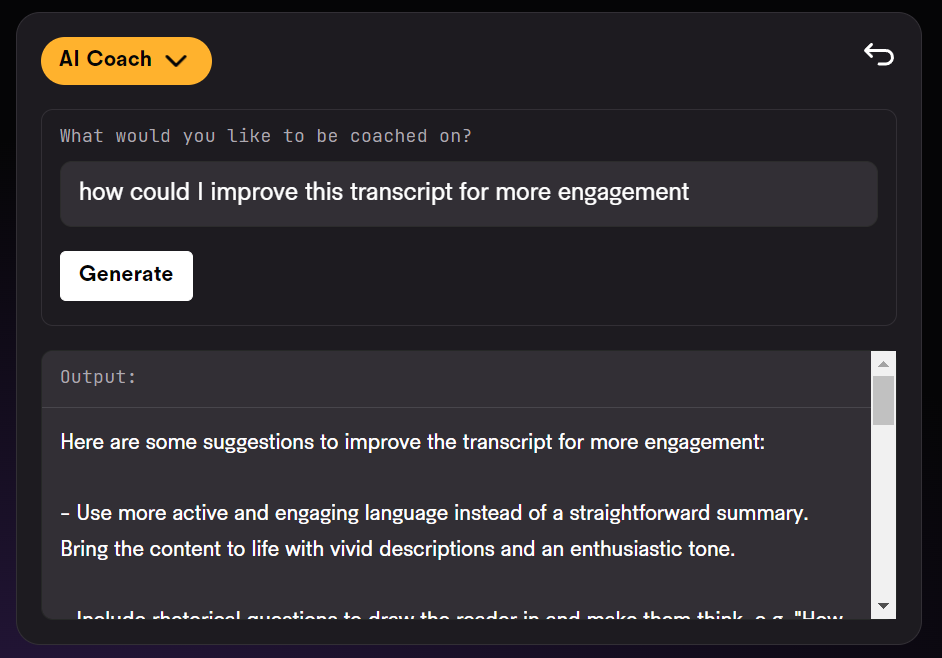
Namun, LeMUR nampaknya masih belum menyokong bahasa Cina. Pembaca yang berminat boleh mencubanya.
Atas ialah kandungan terperinci ChatGPT yang boleh memahami pertuturan ada di sini: 10 jam rakaman dilemparkan, tanya apa sahaja yang anda mahu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk mempertahankan pelayan awan daripada serangan DDoS
Bagaimana untuk mempertahankan pelayan awan daripada serangan DDoS
 Apakah pengecam Python?
Apakah pengecam Python?
 Penggunaan kompaun
Penggunaan kompaun
 Penyelesaian tamat masa permintaan pelayan
Penyelesaian tamat masa permintaan pelayan
 Fungsi wizard pemacu Windows
Fungsi wizard pemacu Windows
 Belajar sendiri untuk pemula dalam bahasa C dengan asas sifar
Belajar sendiri untuk pemula dalam bahasa C dengan asas sifar
 Penggunaan parseInt dalam Java
Penggunaan parseInt dalam Java
 Bagaimana untuk memadam sepenuhnya mongodb jika pemasangan gagal
Bagaimana untuk memadam sepenuhnya mongodb jika pemasangan gagal








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



