

Apakah situasi di mana MySQL menyebabkan kegagalan indeks?

1. Kerja penyediaan
Pertama sediakan dua meja untuk demonstrasi:
CREATE TABLE `student_info` ( `id` int NOT NULL AUTO_INCREMENT, `student_id` int NOT NULL, `name` varchar(20) DEFAULT NULL, `course_id` int NOT NULL, `class_id` int DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=1000001 DEFAULT CHARSET=utf8;
CREATE TABLE `course` ( `id` int NOT NULL AUTO_INCREMENT, `course_id` int NOT NULL, `course_name` varchar(40) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=101 DEFAULT CHARSET=utf8;
#准备数据 select count(*) from student_info;#1000000 select count(*) from course; #100
2 1. Utamakan penggunaan indeks bersama
Pernyataan SQL berikut tidak mempunyai indeks:
#平均耗时291毫秒 select * from student_info where name='123' and course_id=1 and class_id=1;
Kami mengoptimumkan kecekapan pertanyaannya dengan mencipta indeks Terdapat beberapa pilihan:
①Buat indeks biasa:#建立普通索引
create index idx_name on student_info(name);
#平均耗时25毫秒,查看explain执行计划,使用到的是idx_name索引查询
select * from student_info where name='MOKiKb' and course_id=1 and class_id=1;
#name,course_id组成的联合索引
create index idx_name_courseId on student_info(name,course_id);
#该查询语句一般使用的是联合索引,而不是普通索引,具体看优化器决策
#平均耗时20ms
select * from student_info where name='zhangsan' and course_id=1 and class_id=1;
 Anda dapat melihat bahawa
Anda dapat melihat bahawa
berbanding, ini juga sepatutnya Ianya mudah difahami, dengan syarat prinsip padanan paling kiri bagi indeks sendi dipatuhi . Jika anda mencipta indeks bersama yang terdiri daripada nama, course_id, class_id, maka pernyataan sql di atas akan menggunakan indeks bersama ini dengan key_len yang lebih panjang seperti yang diharapkan (tanpa diduga, pengoptimum boleh memilih penyelesaian lain yang lebih baik, Jika ia lebih cepat).
Kelajuan indeks bersama tidak semestinya lebih baik daripada indeks biasaContohnya, jika syarat pertama menapis semua rekod, maka tidak perlu menggunakan yang berikutnya indeks.
2. Prinsip pemadanan paling kiri
#删除前例创建的索引,新创建三个字段的联合索引,name-course_id-cass_id create index idx_name_cou_cls on student_info(name,course_id,class_id);
#关联字段的索引比较完整
explain select * from student_info where name='11111' and course_id=10068 and class_id=10154;
 Setiap keadaan medan sepadan dengan indeks kesatuan, jadi pernyataan SQL ini mengikut peraturan awalan paling kiri. Penggunaan indeks bersama membolehkan carian pantas dan mengelakkan pertanyaan tambahan, jadi ini adalah situasi yang optimum.
Setiap keadaan medan sepadan dengan indeks kesatuan, jadi pernyataan SQL ini mengikut peraturan awalan paling kiri. Penggunaan indeks bersama membolehkan carian pantas dan mengelakkan pertanyaan tambahan, jadi ini adalah situasi yang optimum.
explain select * from student_info where name='11111' and course_id=10068;
 Keadaan pernyataan sql tidak mengandungi semua indeks bersama syarat, tetapi memadamkan separuh kanan Indeks yang digunakan oleh pernyataan ini masih merupakan pertanyaan yang berkaitan, tetapi hanya sebahagian daripadanya digunakan Dengan melihat key_len, kita boleh mengetahui bahawa 5 bait ini tidak sesuai dengan class_id membuktikan class_id tidak berkuat kuasa (ia tidak di mana, jadi sudah tentu ia tidak digunakan).
Keadaan pernyataan sql tidak mengandungi semua indeks bersama syarat, tetapi memadamkan separuh kanan Indeks yang digunakan oleh pernyataan ini masih merupakan pertanyaan yang berkaitan, tetapi hanya sebahagian daripadanya digunakan Dengan melihat key_len, kita boleh mengetahui bahawa 5 bait ini tidak sesuai dengan class_id membuktikan class_id tidak berkuat kuasa (ia tidak di mana, jadi sudah tentu ia tidak digunakan).
Begitu juga, jika anda memadam medan course_id di mana, indeks bersama masih akan berkuat kuasa, tetapi key_len akan dikurangkan.
③Situasi hilang dalam indeks bersama:#联合索引中间的字段未使用,而左边和右边的都存在
explain select * from student_info where name='11111' and class_id=10154;;
 Pernyataan sql di atas masih menggunakan indeks bersama, tetapi key_lennya Ia telah menjadi lebih kecil. Hanya medan nama yang menggunakan indeks Walaupun medan class_id berada dalam indeks bersama, ia adalah GG kerana ia tidak mematuhi prinsip padanan paling kiri.
Pernyataan sql di atas masih menggunakan indeks bersama, tetapi key_lennya Ia telah menjadi lebih kecil. Hanya medan nama yang menggunakan indeks Walaupun medan class_id berada dalam indeks bersama, ia adalah GG kerana ia tidak mematuhi prinsip padanan paling kiri.
Aliran pelaksanaan keseluruhan pernyataan sql ialah: mula-mula cari semua rekod dengan nama 11111 dalam pepohon B indeks bersama, dan kemudian tapis rekod dengan class_id selain 10154 dalam teks penuh. Dengan satu lagi langkah carian teks penuh, prestasi akan menjadi lebih teruk daripada dalam ① dan ②.
④Situasi apabila bahagian paling kiri indeks sendi hilang:explain select * from student_info where class_id=10154 and course_id=10068;
 Situasi ini adalah kes khas dari sebelumnya situasi, yang terakhir dalam indeks bersama Medan di sebelah kiri tidak ditemui, jadi walaupun terdapat bahagian lain, semuanya tidak sah, dan carian teks penuh digunakan.
Situasi ini adalah kes khas dari sebelumnya situasi, yang terakhir dalam indeks bersama Medan di sebelah kiri tidak ditemui, jadi walaupun terdapat bahagian lain, semuanya tidak sah, dan carian teks penuh digunakan.
Nota: Apabila membuat indeks bersama, susunan medan ditetapkan, dan padanan paling kiri dibandingkan mengikut susunan ini tetapi dalam pernyataan pertanyaan, susunan medan dalam keadaan di mana adalah pilihan Mengubah bermakna bahawa tidak perlu mengikut susunan medan indeks yang berkaitan, selagi terdapat satu dalam keadaan di mana.
3. Indeks lajur di sebelah kanan keadaan julat tidak sah
mengambil alih indeks bersama di atas dan menggunakan pertanyaan sql berikut:
#key_len=> name:63,course_id:5,class_id:5 explain select * from student_info where name='11111' and course_id>1 and class_id=1;
 key_len hanya 68, yang bermaksud class_id tidak digunakan dalam indeks yang berkaitan Walaupun ia mematuhi prinsip padanan paling kiri, simbol
key_len hanya 68, yang bermaksud class_id tidak digunakan dalam indeks yang berkaitan Walaupun ia mematuhi prinsip padanan paling kiri, simbol
. Tetapi jika anda menggunakan tanda >=:
#不是>、<,而是>=、<= explain select * from student_info where name='11111' and course_id>=20 and course_id<=40 and class_id=1;
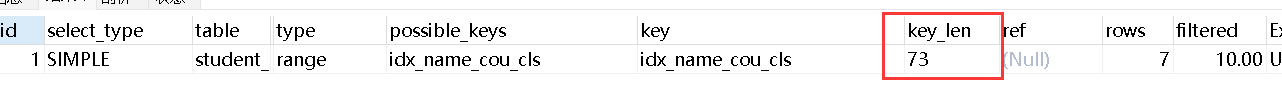 Indeks di sebelah kanan tidak sah, key_len ialah 73, dan indeks semua medan digunakan.
Indeks di sebelah kanan tidak sah, key_len ialah 73, dan indeks semua medan digunakan.
结论:为了充分利用索引,我们有时候可以将>、<等价转为>=、<=的形式,或者将可能会有<、>的条件的字段尽量放在关联索引靠后的位置。
4.计算、函数导致索引失效
#删除前面的索引,新创建name字段的索引,方便演示 create index idx_name on student_info(name);
现有一个需求,找出name为li开头的学生信息:
#使用到了索引 explain select * from student_info where name like 'li%'; #未使用索引,花费时间更久 explain select * from student_info where LEFT(name,2)='li';
上面的两条sql语句都可以满足需求,然而第一条语句用了索引,第二条没有,一点点的改变真是天差地别。
结论:字段使用函数会让优化器无从下手,B树中的值和函数的结果可能不搭边,所以不会使用索引,即索引失效。字段能不用就不用函数。
类似:
#也不会使用索引 explain select * from student_info where name+''='lisi';
类似的对字段的运算也会导致索引失效。
5.类型转换导致索引失效
#不会使用name的索引 explain select * from student_info where name=123; #使用到索引 explain select * from student_info where name='123';
如上,name字段是VARCAHR类型的,但是比较的值是INT类型的,name的值会被隐式的转换为INT类型再比较,中间相当于有一个将字符串转为INT类型的函数。
6.不等于(!= 或者<>)索引失效
#创建索引 create index idx_name on student_info(name); #索引失效 explain select * from student_info where name<>'zhangsan'; explain select * from student_info where name!='zhangsan';
不等于的情况是不会使用索引的。因为!=代表着要进行全文的查找,用不上索引。
7.is null可以使用索引,is not null无法使用索引
#可以使用索引 explain select * from student_info where name is null; #索引失效 explain select * from student_info where name is not null;
和前一个规则类似的,!=null。同理not like也无法使用索引。
最好在设计表时设置NOT NULL约束,比如将INT类型的默认值设为0,将字符串默认值设为''。
8.like以%开头,索引失效
#使用到了索引 explain select * from student_info where name like 'li%'; #索引失效 explain select * from student_info where name like '%li';
只要以%开头就无法使用索引,因为如果以%开头,在B树排序的数据中并不好找。
9.OR前后存在非索引的列,索引失效
#创建好索引 create index idx_name on student_info(name); create index idx_courseId on student_info(course_id);
如果or前后都是索引:
#使用索引 explain select * from student_info where name like 'li%' or course_id=200;

如果其中一个没有索引:
explain select * from student_info where name like 'li%' or class_id=1;

那么索引就失效了,假设还是使用索引,那就变成了先通过索引查,然后再根据没有的索引的字段进行全表查询,这种方式还不如直接全表查询来的快。
10.字符集不统一
字符集如果不同,会存在隐式的转换,索引也会失效,所有应该使用相同的字符集,防止这种情况发生。
三、建议
对于单列索引,尽量选择针对当前query过滤性更好的索引
在选择组合索引时,query过滤性最好的字段应该越靠前越好
在选择组合索引时,尽量选择能包含当前query中where子句中更多字段的索引
在选择组合索引时,如果某个字段可能出现范围查询,尽量将它往后放
Atas ialah kandungan terperinci Apakah situasi di mana MySQL menyebabkan kegagalan indeks?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1389
1389
 52
52

 Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Anda boleh membuka phpmyadmin melalui langkah -langkah berikut: 1. Log masuk ke panel kawalan laman web; 2. Cari dan klik ikon phpmyadmin; 3. Masukkan kelayakan MySQL; 4. Klik "Login".
 MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL: Pengenalan kepada pangkalan data paling popular di dunia
Apr 12, 2025 am 12:18 AM
MySQL adalah sistem pengurusan pangkalan data relasi sumber terbuka, terutamanya digunakan untuk menyimpan dan mengambil data dengan cepat dan boleh dipercayai. Prinsip kerjanya termasuk permintaan pelanggan, resolusi pertanyaan, pelaksanaan pertanyaan dan hasil pulangan. Contoh penggunaan termasuk membuat jadual, memasukkan dan menanyakan data, dan ciri -ciri canggih seperti Operasi Join. Kesalahan umum melibatkan sintaks SQL, jenis data, dan keizinan, dan cadangan pengoptimuman termasuk penggunaan indeks, pertanyaan yang dioptimumkan, dan pembahagian jadual.
 Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Cara menggunakan redis berulir tunggal
Apr 10, 2025 pm 07:12 PM
Redis menggunakan satu seni bina berulir untuk memberikan prestasi tinggi, kesederhanaan, dan konsistensi. Ia menggunakan I/O multiplexing, gelung acara, I/O yang tidak menyekat, dan memori bersama untuk meningkatkan keserasian, tetapi dengan batasan batasan konkurensi, satu titik kegagalan, dan tidak sesuai untuk beban kerja yang berintensifkan.
 Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
Mengapa menggunakan mysql? Faedah dan kelebihan
Apr 12, 2025 am 12:17 AM
MySQL dipilih untuk prestasi, kebolehpercayaan, kemudahan penggunaan, dan sokongan komuniti. 1.MYSQL Menyediakan fungsi penyimpanan dan pengambilan data yang cekap, menyokong pelbagai jenis data dan operasi pertanyaan lanjutan. 2. Mengamalkan seni bina pelanggan-pelayan dan enjin penyimpanan berganda untuk menyokong urus niaga dan pengoptimuman pertanyaan. 3. Mudah digunakan, menyokong pelbagai sistem operasi dan bahasa pengaturcaraan. 4. Mempunyai sokongan komuniti yang kuat dan menyediakan sumber dan penyelesaian yang kaya.
 Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Tempat Mysql: Pangkalan Data dan Pengaturcaraan
Apr 13, 2025 am 12:18 AM
Kedudukan MySQL dalam pangkalan data dan pengaturcaraan sangat penting. Ia adalah sistem pengurusan pangkalan data sumber terbuka yang digunakan secara meluas dalam pelbagai senario aplikasi. 1) MySQL menyediakan fungsi penyimpanan data, organisasi dan pengambilan data yang cekap, sistem sokongan web, mudah alih dan perusahaan. 2) Ia menggunakan seni bina pelanggan-pelayan, menyokong pelbagai enjin penyimpanan dan pengoptimuman indeks. 3) Penggunaan asas termasuk membuat jadual dan memasukkan data, dan penggunaan lanjutan melibatkan pelbagai meja dan pertanyaan kompleks. 4) Soalan -soalan yang sering ditanya seperti kesilapan sintaks SQL dan isu -isu prestasi boleh disahpepijat melalui arahan jelas dan log pertanyaan perlahan. 5) Kaedah pengoptimuman prestasi termasuk penggunaan indeks rasional, pertanyaan yang dioptimumkan dan penggunaan cache. Amalan terbaik termasuk menggunakan urus niaga dan preparedStatemen
 Pantau titisan redis dengan perkhidmatan pengeksport redis
Apr 10, 2025 pm 01:36 PM
Pantau titisan redis dengan perkhidmatan pengeksport redis
Apr 10, 2025 pm 01:36 PM
Pemantauan yang berkesan terhadap pangkalan data REDIS adalah penting untuk mengekalkan prestasi yang optimum, mengenal pasti kemungkinan kesesakan, dan memastikan kebolehpercayaan sistem keseluruhan. Perkhidmatan Pengeksport Redis adalah utiliti yang kuat yang direka untuk memantau pangkalan data REDIS menggunakan Prometheus. Tutorial ini akan membimbing anda melalui persediaan lengkap dan konfigurasi perkhidmatan pengeksport REDIS, memastikan anda membina penyelesaian pemantauan dengan lancar. Dengan mengkaji tutorial ini, anda akan mencapai tetapan pemantauan operasi sepenuhnya
 Cara Melihat Ralat Pangkalan Data SQL
Apr 10, 2025 pm 12:09 PM
Cara Melihat Ralat Pangkalan Data SQL
Apr 10, 2025 pm 12:09 PM
Kaedah untuk melihat ralat pangkalan data SQL adalah: 1. Lihat mesej ralat secara langsung; 2. Gunakan kesilapan menunjukkan dan menunjukkan perintah amaran; 3. Akses log ralat; 4. Gunakan kod ralat untuk mencari punca kesilapan; 5. Semak sambungan pangkalan data dan sintaks pertanyaan; 6. Gunakan alat debugging.
 Cara menyambung ke pangkalan data Apache
Apr 13, 2025 pm 01:03 PM
Cara menyambung ke pangkalan data Apache
Apr 13, 2025 pm 01:03 PM
Apache menyambung ke pangkalan data memerlukan langkah -langkah berikut: Pasang pemacu pangkalan data. Konfigurasikan fail web.xml untuk membuat kolam sambungan. Buat sumber data JDBC dan tentukan tetapan sambungan. Gunakan API JDBC untuk mengakses pangkalan data dari kod Java, termasuk mendapatkan sambungan, membuat kenyataan, parameter mengikat, melaksanakan pertanyaan atau kemas kini, dan hasil pemprosesan.
