

Model kuota Duxiaoman berdasarkan inferens sebab akibat kontrafaktual


1. Paradigma penyelidikan inferens sebab-akibat
Paradigma penyelidikan pada masa ini mempunyai dua hala tuju penyelidikan:
- Model Struktur Mutiara Judea
- Rangka kerja output yang berpotensi
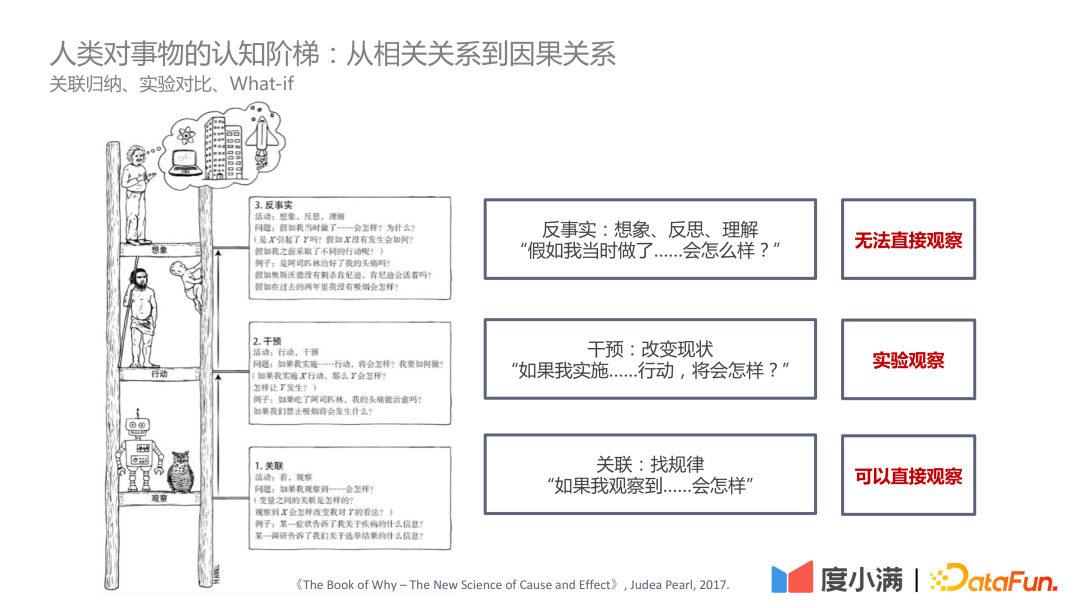
Dalam "The Book of Why – The New Science of Cause and Effect" oleh Judea Pearl Dalam buku ini, tangga kognitif diletakkan sebagai tiga peringkat:
- Tahap pertama - korelasi: ketahui peraturan melalui korelasi, anda boleh terus Pemerhatian; >
- Tahap kedua - campur tangan: Jika status quo diubah, apakah tindakan yang perlu dilaksanakan dan apakah kesimpulan yang perlu dibuat boleh diperhatikan melalui eksperimen; > Tahap ketiga - Counterfactual: Disebabkan masalah seperti undang-undang dan peraturan, adalah mustahil untuk memerhati secara langsung melalui andaian kontrafaktual, apa yang akan berlaku jika tindakan itu dilaksanakan dan bagaimana untuk nilaikan ATE dan CATE adalah masalah yang lebih sukar.
Pertama, mari kita jelaskan empat cara untuk menjana korelasi: 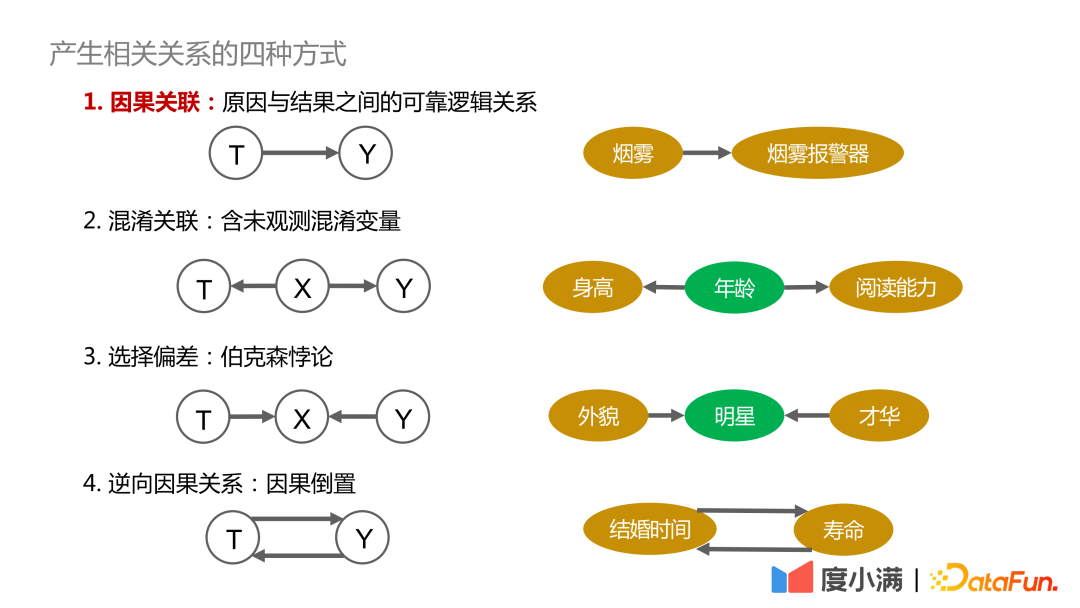
: Terdapat hubungan yang boleh dipercayai, boleh dikesan dan bergantung secara positif antara sebab dan akibat, seperti penggera asap dan asap yang mempunyai hubungan sebab akibat
2 Korelasi keliru: Mengandungi pembolehubah mengelirukan yang tidak boleh diperhatikan secara langsung, seperti sama ada ketinggian dan keupayaan membaca boleh dikaitkan, yang memerlukan untuk dikawal Umur pembolehubah adalah serupa, dengan itu membuat kesimpulan yang sah;
3 Berkson's Paradox, sebagai contoh, jika anda meneroka hubungan antara penampilan dan bakat, jika anda hanya memerhatikannya di kalangan selebriti, anda mungkin membuat kesimpulan bahawa penampilan dan bakat tidak boleh mempunyai kedua-duanya. Jika diperhatikan di kalangan semua manusia, tidak ada hubungan sebab akibat antara rupa dan bakat.4. Punca terbalik
: Itulah penyongsangan sebab dan akibat semakin lama manusia berkahwin, semakin lama umurnya. Tetapi sebaliknya, kita tidak boleh berkata: Jika anda ingin hidup lebih lama, anda mesti berkahwin awal.Bagaimana faktor yang mengelirukan mempengaruhi hasil pemerhatian, berikut adalah dua kes untuk menggambarkan:
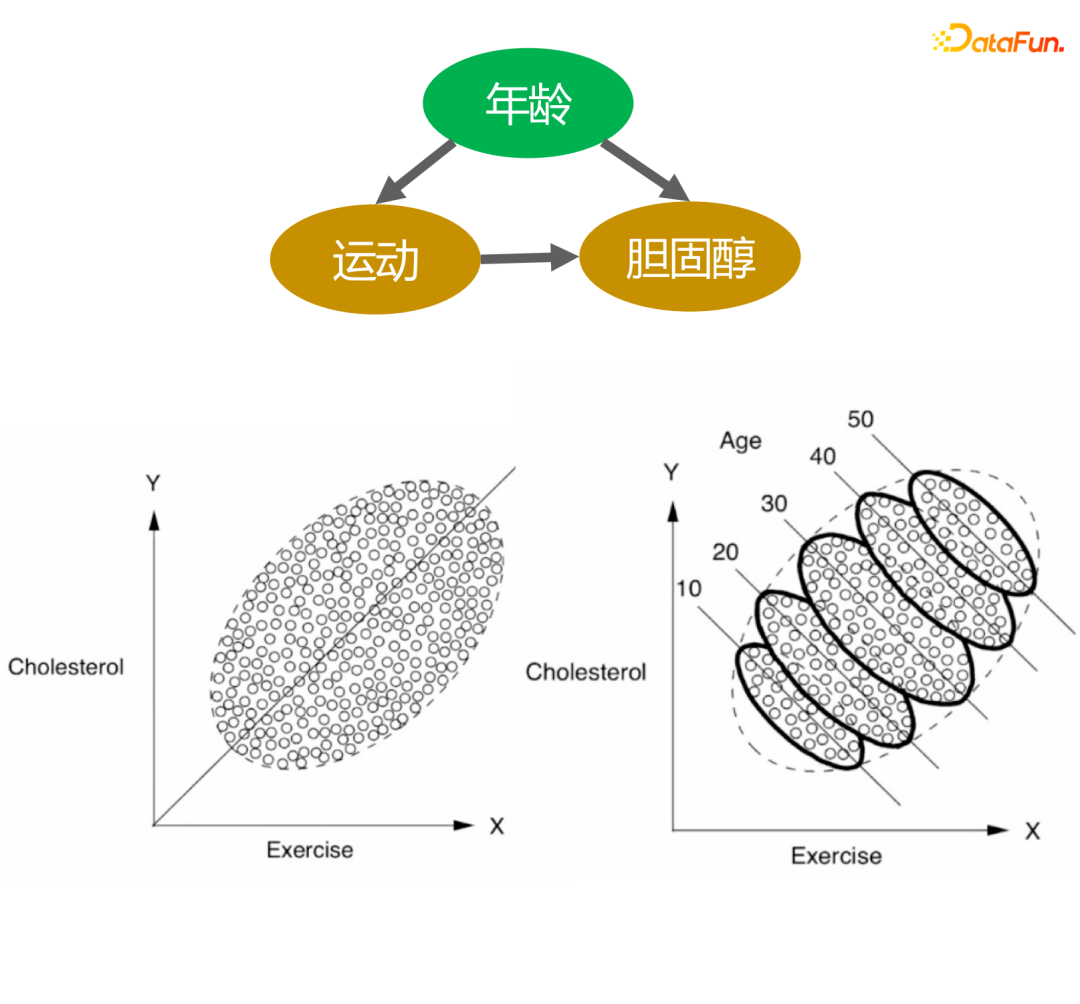
Gambar di atas menerangkan hubungan antara isipadu senaman dan tahap kolesterol. Dari gambar di sebelah kiri, kita boleh membuat kesimpulan bahawa lebih banyak jumlah senaman, semakin tinggi tahap kolesterol. Walau bagaimanapun, apabila stratifikasi umur ditambah, di bawah stratifikasi umur yang sama, semakin banyak jumlah senaman, semakin rendah tahap kolesterol. Di samping itu, apabila usia kita meningkat, paras kolesterol secara beransur-ansur meningkat, jadi kesimpulan ini konsisten dengan pengetahuan kita.
Contoh kedua ialah senario kredit. Dapat dilihat daripada statistik sejarah bahawa semakin tinggi had yang diberikan (jumlah wang yang boleh dipinjam), semakin rendah kadar tertunggak. Walau bagaimanapun, dalam bidang kewangan, kelayakan kredit peminjam akan dinilai berdasarkan kad Anya Jika kelayakan kredit lebih baik, platform akan memberikan had yang lebih tinggi dan kadar tertunggak keseluruhan akan menjadi sangat rendah. Walau bagaimanapun, percubaan rawak tempatan menunjukkan bahawa bagi orang yang mempunyai kelayakan kredit yang sama, akan ada sesetengah orang yang keluk penghijrahan had kreditnya berubah secara perlahan, dan akan ada juga beberapa orang yang risiko penghijrahan had kreditnya lebih tinggi, iaitu selepas had kredit meningkat, peningkatan risiko akan lebih besar. Dua kes di atas menggambarkan bahawa jika faktor pengacau diabaikan dalam pemodelan, kesimpulan yang salah atau bertentangan mungkin diperoleh. Untuk kes sampel RCT, jika anda ingin menilai penunjuk ATE, anda boleh menggunakan penolakan kumpulan atau DID (perbezaan dalam perbezaan). Jika anda ingin menilai penunjuk CATE, anda boleh menggunakan pemodelan peningkatan. Kaedah biasa termasuk meta-learner, pembelajaran mesin berganda, hutan sebab-akibat, dsb. Terdapat tiga andaian yang perlu diberi perhatian di sini: SUTVA, Unconfoundedness dan Positiviti. Andaian terasnya ialah tiada faktor pengacau yang tidak diperhatikan. Untuk kes sampel pemerhatian sahaja, hubungan sebab akibat antara rawatan->hasil tidak boleh diperolehi secara langsung Kita perlu menggunakan cara yang diperlukan untuk memotong pintu belakang daripada kovariat kepada laluan rawatan. Kaedah biasa ialah kaedah pembolehubah instrumental dan pembelajaran perwakilan kontrafaktual. Kaedah pembolehubah instrumental perlu mengupas butiran perniagaan tertentu dan melukis rajah sebab dan akibat pembolehubah perniagaan. Pembelajaran perwakilan kontrafaktual bergantung pada pembelajaran mesin matang untuk memadankan sampel dengan kovariat yang serupa untuk penilaian kausal. Seterusnya, kami akan memperkenalkan evolusi rangka kerja inferens sebab musabab, dan cara beralih kepada pembelajaran perwakilan sebab akibat langkah demi langkah. Model Peningkatan Biasa termasuk: Slearner, Tlearner, Xlearner. di mana Slearner menganggap pembolehubah campur sebagai ciri satu dimensi. Perlu diingatkan bahawa dalam model pokok biasa, rawatan mudah dikalahkan, menyebabkan anggaran kesan rawatan yang lebih kecil. Tlearner mendiskrisikan rawatan, memodelkan pembolehubah campur dalam kumpulan, membina model ramalan untuk setiap rawatan, dan kemudian membuat perbezaannya. Adalah penting untuk ambil perhatian bahawa saiz sampel yang lebih kecil membawa kepada anggaran varians yang lebih tinggi. Pemodelan silang kumpulan pelajar X, kumpulan eksperimen dan kumpulan kawalan dikira silang dan dilatih secara berasingan. Kaedah ini menggabungkan kelebihan S/T-learner, tetapi kelemahannya ialah ia memperkenalkan ralat struktur model yang lebih tinggi dan meningkatkan kesukaran pelarasan parameter. Perbandingan tiga model: 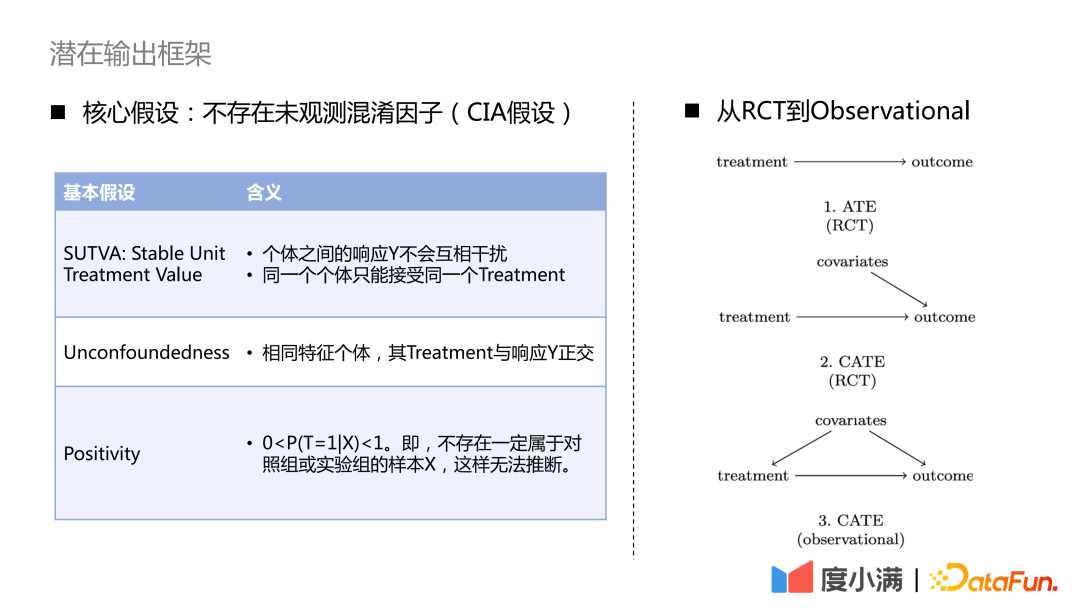
Bagaimana untuk beralih daripada sampel rawak RCT kepada pemodelan sebab akibat sampel pemerhatian?
2 Evolusi rangka kerja inferens penyebab
1
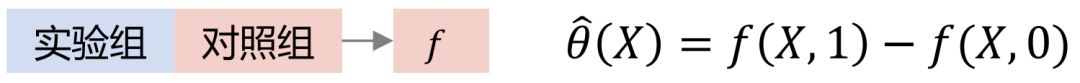
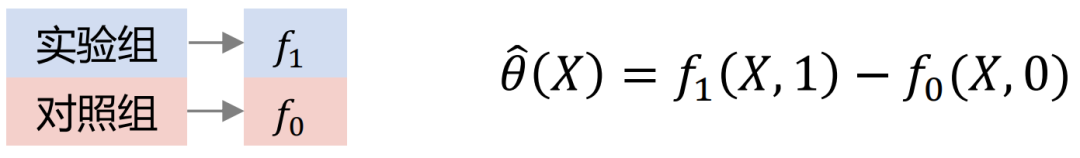
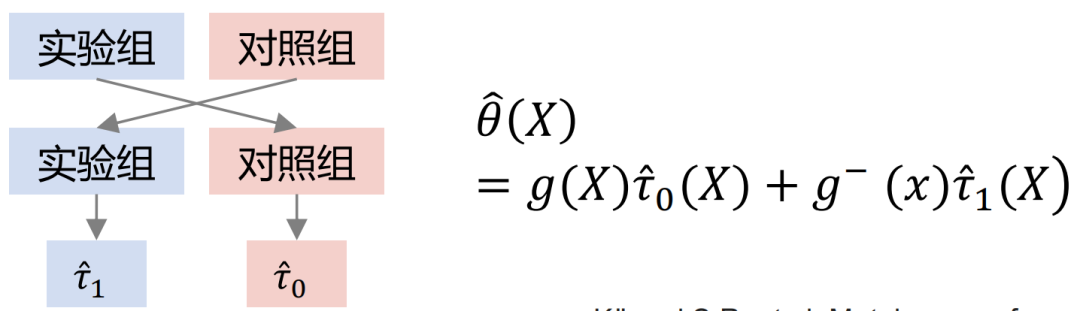
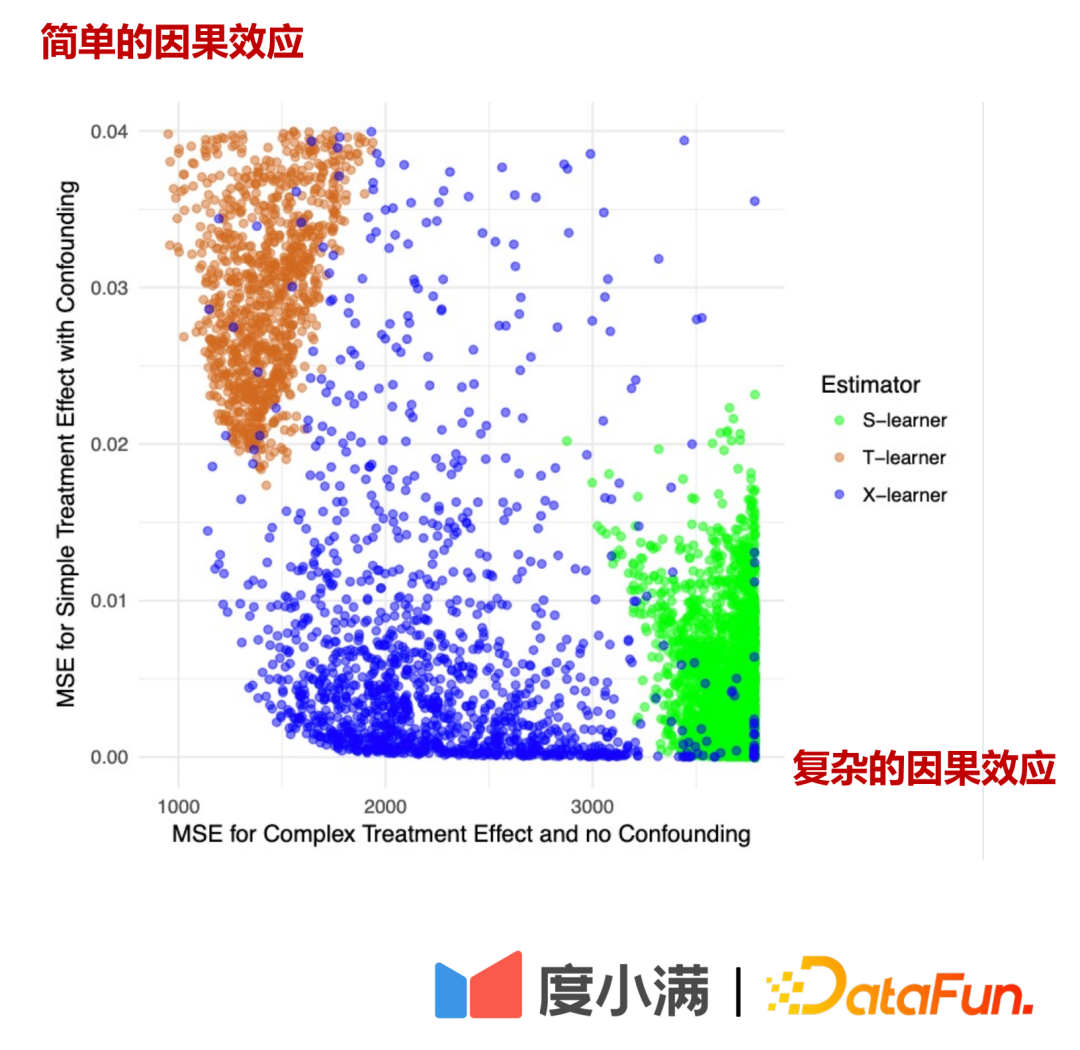
Dalam rajah di atas, paksi mendatar ialah kesan sebab yang kompleks dan ralat anggaran MSE Paksi menegak ialah kesan sebab yang mudah paksi mewakili dua bahagian masing-masing. Hijau mewakili taburan ralat Slearner, coklat mewakili taburan ralat Tlearner, dan biru mewakili taburan ralat Xlearner.
Di bawah keadaan sampel rawak, Xlearner adalah lebih baik untuk kedua-dua anggaran kesan sebab musabab yang kompleks dan anggaran kesan sebab musabab mudah Slearner menunjukkan prestasi yang agak lemah untuk anggaran kesan sebab musabab yang kompleks, dan lebih baik untuk anggaran kesan sebab musabab mudah. Tlearner adalah bertentangan dengan Slearner.
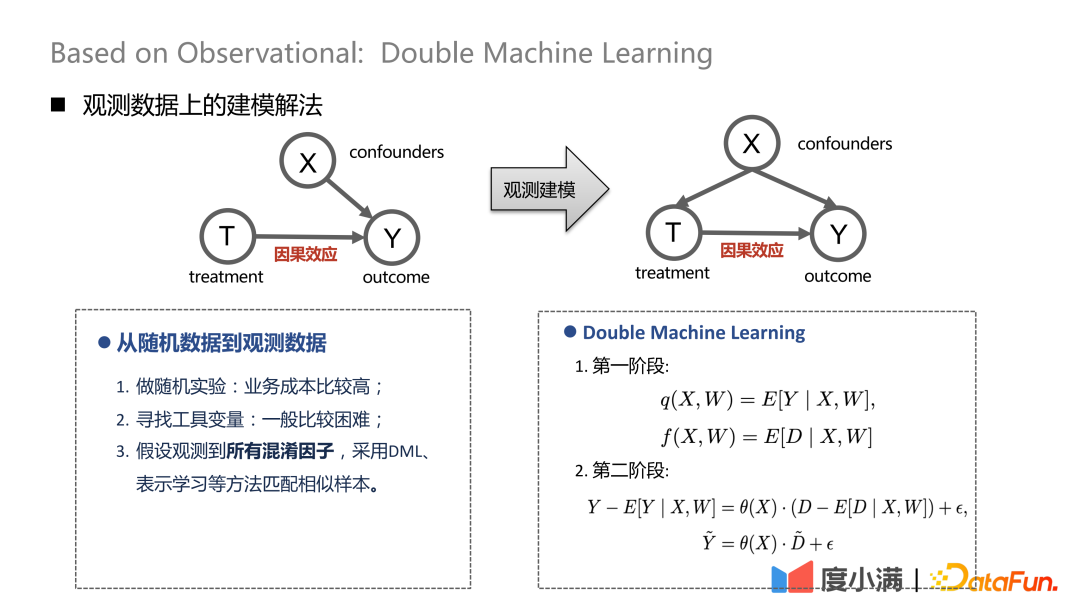
Jika terdapat sampel rawak, anak panah dari X ke T boleh dialih keluar. Selepas beralih kepada pemodelan pemerhatian, anak panah dari X ke T tidak boleh dialih keluar Rawatan dan hasil akan dipengaruhi oleh pengali pada masa yang sama, beberapa pemprosesan depolarisasi boleh dilakukan. Sebagai contoh, kaedah DML (Double Machine Learning) melaksanakan pemodelan dua peringkat. Pada peringkat pertama, X di sini ialah ciri perwakilan pengguna sendiri, seperti umur, jantina, dsb. Pembolehubah yang mengelirukan boleh termasuk, sebagai contoh, usaha sejarah untuk menyaring kumpulan orang tertentu. Pada peringkat kedua, ralat dalam hasil pengiraan peringkat sebelumnya dimodelkan, berikut adalah anggaran CATE.
Terdapat tiga kaedah pemprosesan daripada data rawak kepada data pemerhatian:
(1 ) Lakukan eksperimen rawak, tetapi kos perniagaan adalah tinggi; 🎜 > (3) Dengan mengandaikan bahawa semua faktor yang mengelirukan diperhatikan, gunakan DML, pembelajaran perwakilan dan kaedah lain untuk memadankan sampel yang serupa.
2. Pembelajaran perwakilan sebab
Idea teras pembelajaran kontrafaktual Ia adalah untuk mengimbangi pengedaran ciri di bawah rawatan yang berbeza.
Terdapat dua soalan teras:
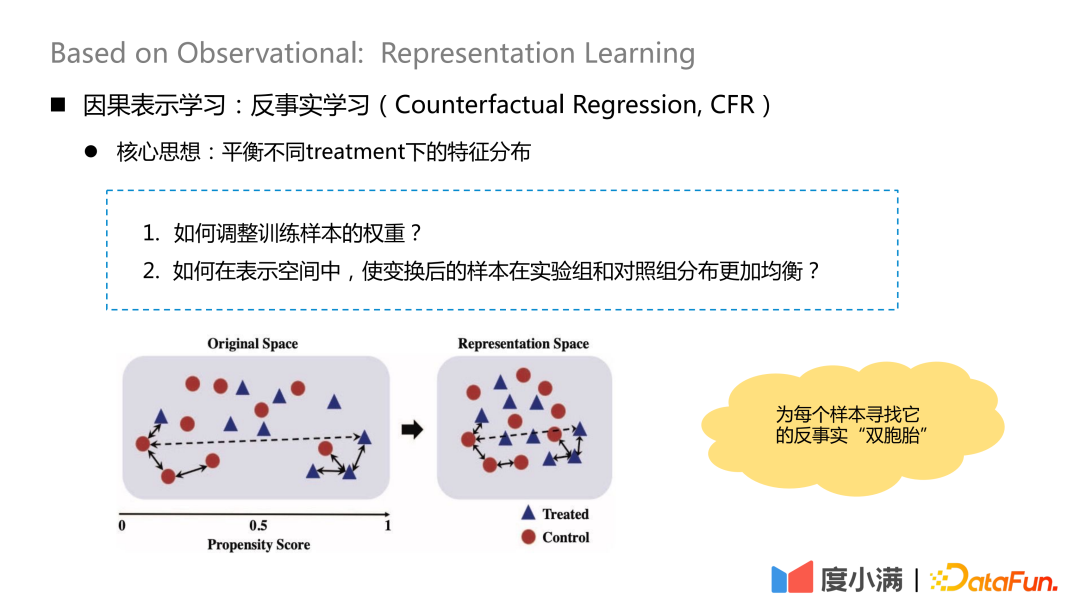
1. Bagaimana untuk menyesuaikan berat sampel latihan?
2. Bagaimanakah cara untuk menjadikan sampel yang diubah menjadi lebih sekata dalam kumpulan eksperimen dan kumpulan kawalan dalam ruang perwakilan?
Idea penting ialah mencari "kembar" kontrafak bagi setiap sampel selepas pemetaan transformasi. Selepas pemetaan, taburan X dalam kumpulan rawatan dan kumpulan kawalan adalah agak serupa.
Semakin banyak karya yang mewakili adalah kertas kerja yang diterbitkan pada TKDE 2022, yang memperkenalkan DeR-CFR Some work, bahagian ini sebenarnya adalah lelaran model DR-CRF, menggunakan kaedah bebas model untuk memisahkan pembolehubah yang diperhatikan.
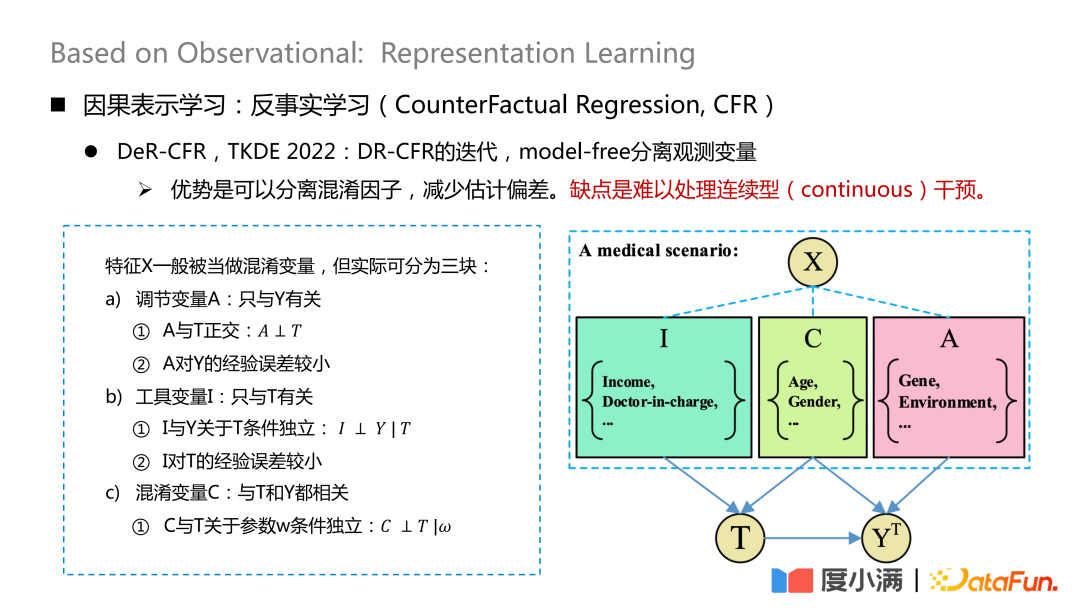 Bahagikan pembolehubah X kepada tiga bahagian: pembolehubah pelarasan A, pembolehubah instrumental I dan pembolehubah pengeliru C. Kemudian I, C, dan A digunakan untuk melaraskan berat X di bawah rawatan yang berbeza untuk mencapai tujuan pemodelan kausal pada data yang diperhatikan.
Bahagikan pembolehubah X kepada tiga bahagian: pembolehubah pelarasan A, pembolehubah instrumental I dan pembolehubah pengeliru C. Kemudian I, C, dan A digunakan untuk melaraskan berat X di bawah rawatan yang berbeza untuk mencapai tujuan pemodelan kausal pada data yang diperhatikan.
Kelebihan kaedah ini ialah ia boleh memisahkan faktor yang mengelirukan dan mengurangkan bias anggaran. Kelemahannya ialah sukar untuk mengendalikan campur tangan berterusan.
Inti rangkaian ini ialah cara mengasingkan tiga jenis pembolehubah A/I/C. Pembolehubah pelarasan A hanya berkaitan dengan Y, dan ia perlu dipastikan bahawa A dan T adalah ortogon, dan ralat empirikal A hingga Y adalah kecil pembolehubah instrumental I hanya berkaitan dengan T, dan ia perlu memenuhi kebebasan bersyarat I dan Y berkenaan dengan T, dan pengalaman I berkenaan dengan T Ralat adalah kecil; pembolehubah kekeliruan C berkaitan dengan kedua-dua T dan Y, dan w ialah berat rangkaian berat, adalah perlu untuk memastikan bahawa C dan T adalah bebas bersyarat berkenaan dengan w. Keortogonan di sini boleh dicapai melalui formula jarak am, seperti jarak logloss atau mse Euclidean dan kekangan lain.
Bagaimana untuk menangani campur tangan berterusan, terdapat juga beberapa kertas kerja baharu dalam bidang ini VCNet yang diterbitkan pada ICLR2021 menyediakan kaedah anggaran untuk campur tangan berterusan. Kelemahannya ialah sukar untuk memohon terus kepada data pemerhatian (senario CFR). Peta X hingga Z. Z terutamanya mengandungi pembolehubah I dan pembolehubah C dalam penguraian X yang dinyatakan sebelum ini, yang akan lebih berguna untuk rawatan. Pembolehubah penyumbang diekstrak daripada X. Di sini, rawatan berterusan dibahagikan kepada ketua segmentasi/ramalan B, setiap fungsi berterusan ditukar kepada fungsi linear bersegmen, dan kehilangan log ralat empirikal diminimumkan, yang digunakan untuk belajar Kemudian gunakan Z dan θ(t) yang telah anda pelajari untuk belajar. 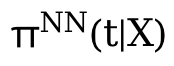
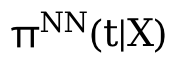
3. Model Kuota Counterfaktual Mono-CFR
Akhir sekali, mari perkenalkan kontrafaktual Du Xiaoman Model kredit fakta terutamanya menyelesaikan masalah anggaran counterfaktual rawatan berterusan pada data pemerhatian.
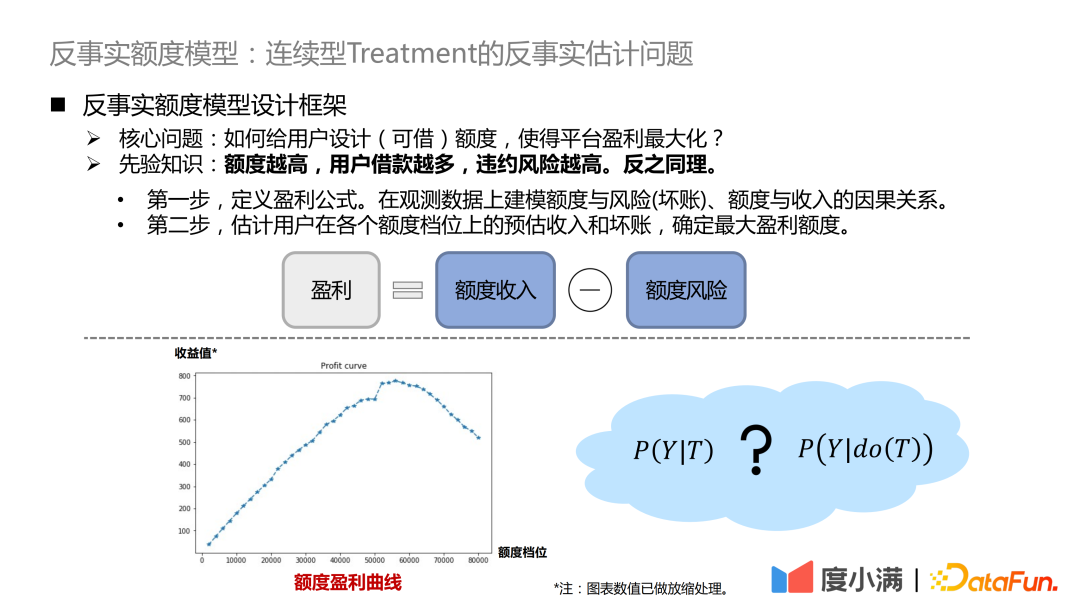
Persoalan terasnya ialah, bagaimana untuk mereka bentuk kuota (boleh dipinjam) untuk pengguna memaksimumkan keuntungan platform? Pengetahuan a priori di sini ialah semakin tinggi had, semakin ramai pengguna meminjam dan semakin tinggi risiko lalai. Begitu juga sebaliknya.
- Langkah pertama ialah menentukan formula keuntungan. Untung = pendapatan kuota - risiko kuota. Formulanya kelihatan mudah, tetapi sebenarnya terdapat banyak butiran untuk disesuaikan. Dengan cara ini, masalah diubah menjadi pemodelan hubungan sebab akibat antara jumlah dan risiko (hutang lapuk), dan jumlah serta pendapatan pada data pemerhatian.
- Langkah kedua ialah menganggarkan anggaran pendapatan dan hutang lapuk pengguna pada setiap tahap kuota, dan menentukan jumlah keuntungan maksimum.
Kami menjangkakan setiap pengguna mempunyai keluk keuntungan seperti yang ditunjukkan dalam rajah di atas, dan songsang nilai keuntungan pada tahap kuota yang berbeza.
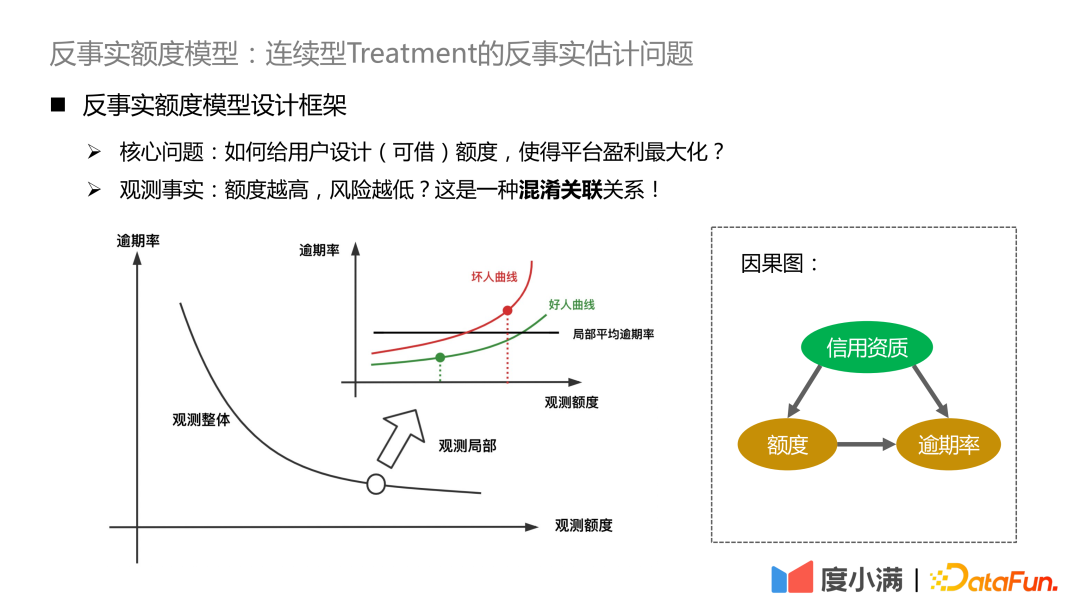
Jika anda melihat dalam data pemerhatian bahawa semakin tinggi jumlah, semakin rendah risiko, pada asasnya disebabkan oleh kewujudan daripada faktor yang mengelirukan. Faktor yang mengelirukan dalam senario kami ialah kelayakan kredit. Bagi orang yang mempunyai kelayakan kredit yang baik, platform akan memberikan had yang lebih tinggi, dan sebaliknya, platform akan memberikan had yang lebih rendah. Risiko mutlak orang yang mempunyai kelayakan kredit yang cemerlang masih jauh lebih rendah daripada orang yang mempunyai kelayakan kredit yang rendah. Jika anda meningkatkan kelayakan kredit anda, anda akan melihat bahawa peningkatan dalam had akan membawa peningkatan dalam risiko, dan had yang tinggi akan melebihi kesolvenan pengguna sendiri.
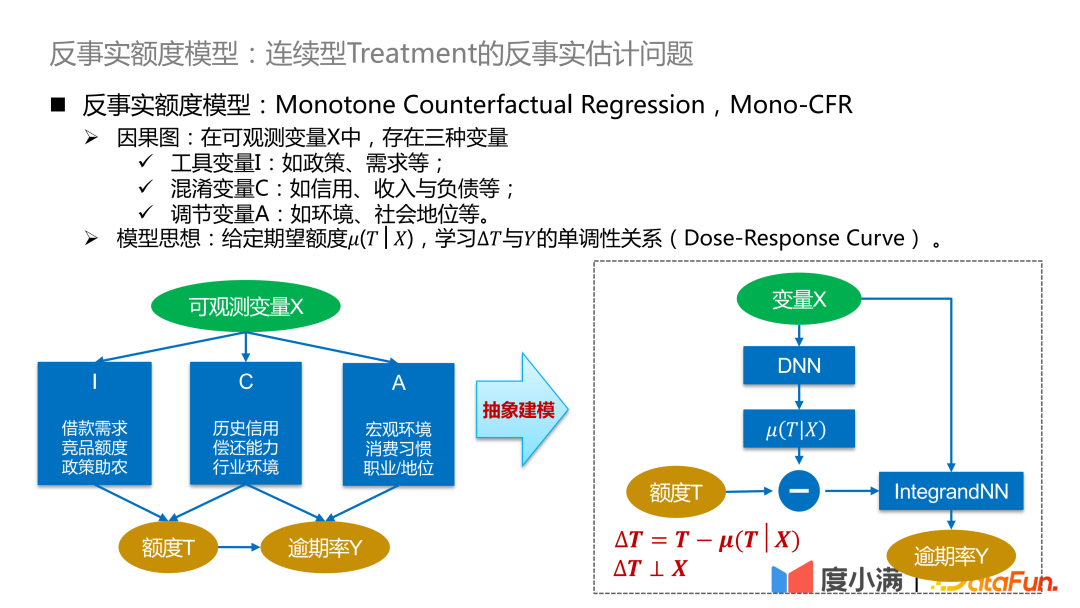
Kami mula memperkenalkan rangka kerja model kuota kontrafaktual. Antara pembolehubah yang boleh diperhatikan .
- Pembolehubah instrumental I: Seperti dasar, permintaan, dsb., yang akan menjejaskan strategi kuota sejarah, tetapi tidak akan menjejaskan kebarangkalian tertunggak.
- Pembolehubah yang mengelirukan C: seperti kredit, pendapatan dan liabiliti, dsb., yang pada masa yang sama menjejaskan pelarasan had dan kebarangkalian tertunggak orang itu.
- Melaraskan pembolehubah A: seperti persekitaran, status sosial, dsb., akan menjejaskan kadar tertunggak.
Idea model: memandangkan jumlah yang dijangkakan μ(T|X), pelajari perhubungan monotonik antara ΔT dan Y (Keluk Tindak Balas Dos) . Jumlah yang dijangkakan boleh difahami sebagai jumlah kecenderungan kesinambungan yang dipelajari oleh model, supaya hubungan antara pembolehubah yang mengelirukan C dan jumlah T boleh diputuskan dan ditukar kepada pembelajaran hubungan sebab akibat antara ΔT dan Y, supaya dapat membandingkan taburan daripada Y di bawah ΔT Pencirian yang baik.
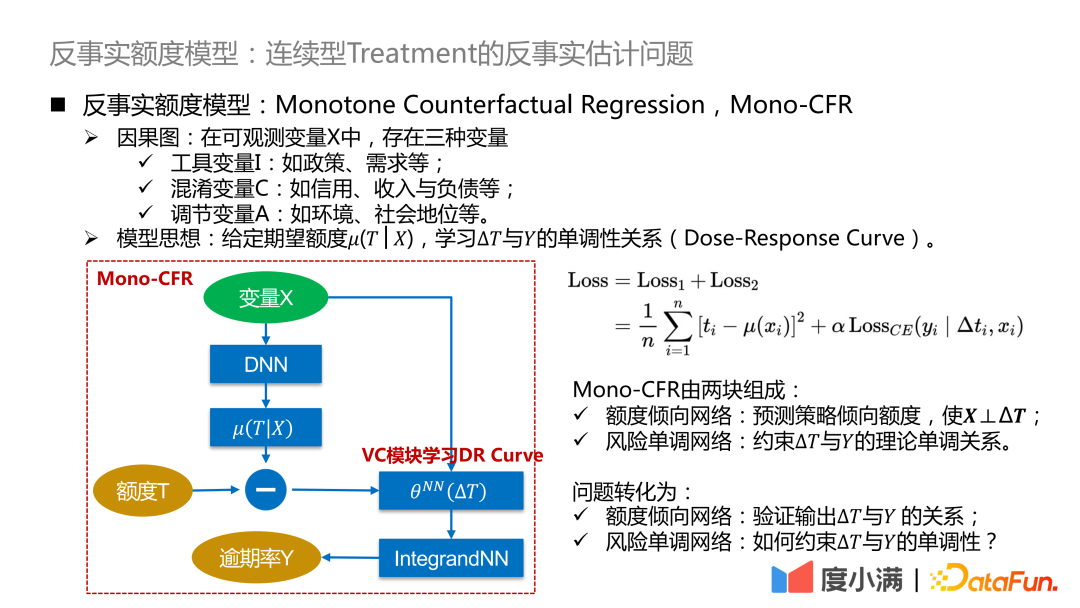
Di sini kami memperhalusi lagi rangka kerja abstrak di atas : Tukar ΔT kepada model pekali pembolehubah dan kemudian sambungkannya ke rangkaian IntegrandNN Ralat latihan dibahagikan kepada dua bahagian:
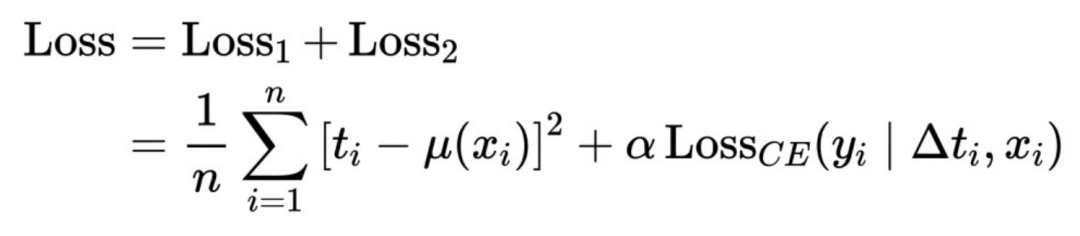
.
α di sini ialah hiperparameter yang mengukur kepentingan risiko.
Mono-CFR terdiri daripada dua bahagian:
- Rangkaian kecenderungan kuota : Ramalkan jumlah kecenderungan strategik supaya X⊥ΔT.
Fungsi 1: Menyaring pembolehubah dalam X yang paling berkaitan dengan T dan meminimumkan ralat empirikal.
Fungsi 2: Menambatkan sampel anggaran pada strategi sejarah.
- Rangkaian monotonik risiko: Hubungan monotonik teoritis antara kekangan ΔT dan Y.
Fungsi 1: Gunakan kekangan monotonik bebas kepada pembolehubah pekali lemah.
Fungsi 2: Mengurangkan bias anggaran.
Masalah diubah menjadi:
- Rangkaian kecenderungan kuota: Pengesahan output Δ Hubungan antara T dan Y.
- Rangkaian monotoni berisiko: Bagaimana untuk mengekang kemonotonan ΔT dan Y?
Input rangkaian kecenderungan jumlah sebenar adalah seperti berikut:
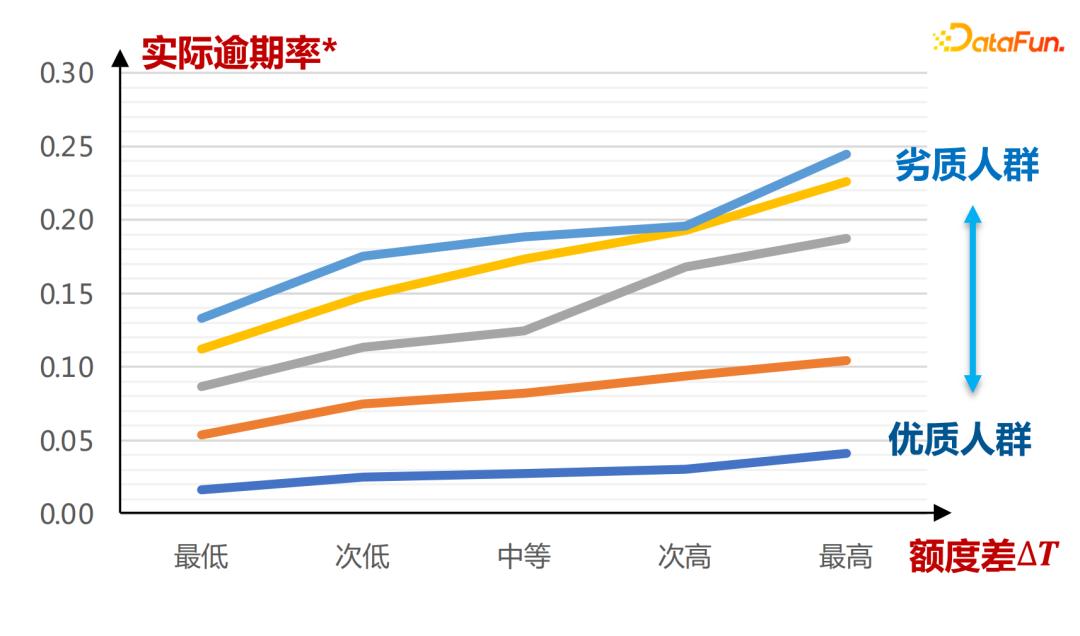
Paksi mendatar ialah kumpulan yang ditakrifkan oleh skor kad A Ia boleh dilihat bahawa di bawah kuota kecenderungan yang berbeza μ(T|X), perbezaan kuota ΔT dan tertunggak. kadar Y menunjukkan perhubungan yang semakin monotonik Semakin teruk perbezaan kredit ΔT perubahan keluk bagi kumpulan yang lebih miskin, semakin curam keluk perubahan kadar tertunggak sebenar, dan kecerunan keseluruhan keluk lebih besar. Kesimpulan di sini dibuat sepenuhnya melalui pembelajaran data sejarah.
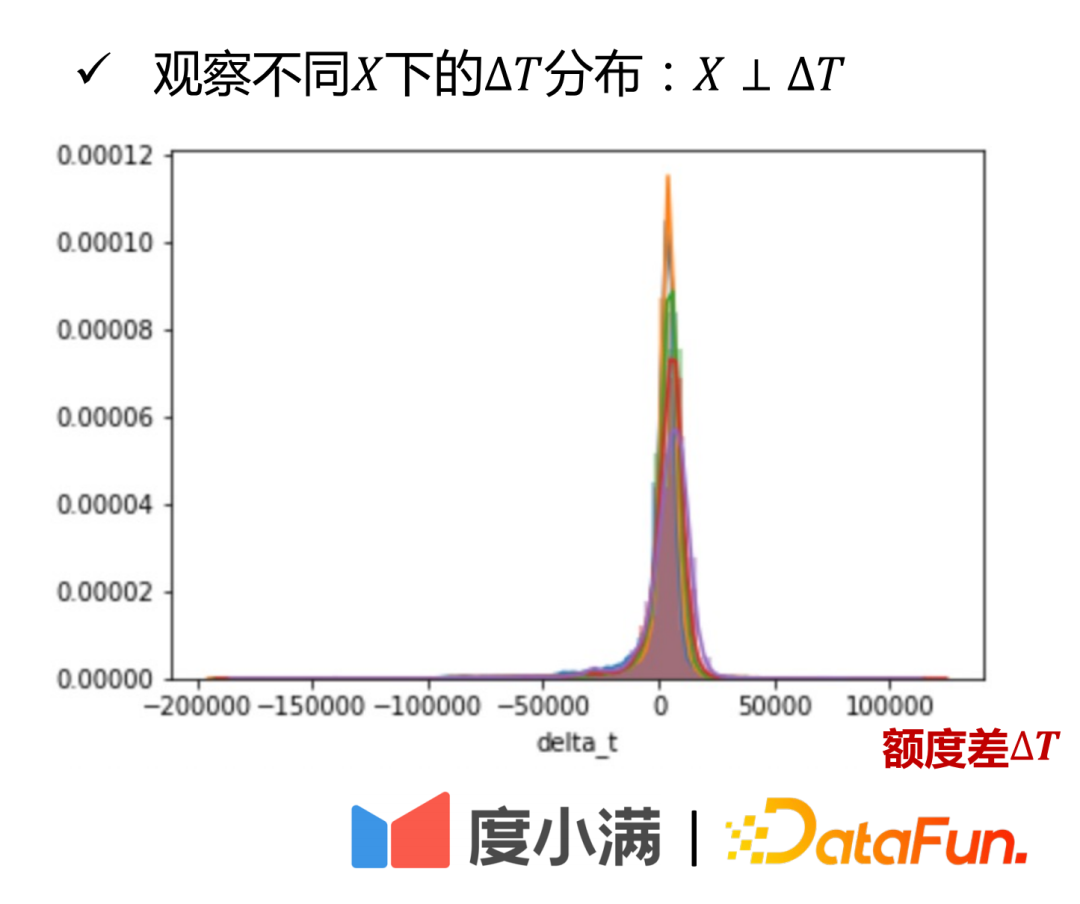
Ia boleh dilihat daripada rajah taburan X dan ΔT: kelayakan berbeza Perbezaan amaun ΔT antara kumpulan orang (dibezakan dengan warna yang berbeza dalam rajah) diagihkan sama rata dalam selang yang sama Ini dijelaskan dari perspektif praktikal.
Dari perspektif teori, ia juga boleh dibuktikan dengan teliti.
Bahagian kedua ialah pelaksanaan rangkaian monotonik risiko:

Ungkapan matematik bagi fungsi ELU+1 di sini ialah:
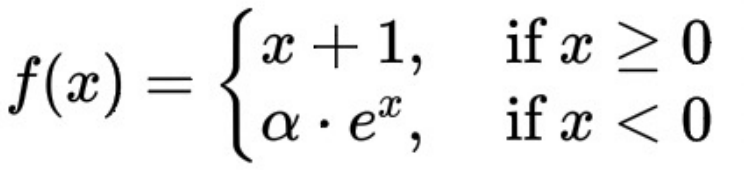
ΔT dan kadar tertunggak menunjukkan arah aliran meningkat secara monoton, yang dijamin oleh terbitan fungsi ELU+1 sentiasa lebih besar daripada atau sama dengan 0.
Seterusnya, terangkan bagaimana rangkaian monotonik risiko boleh belajar dengan lebih tepat untuk pembolehubah pekali lemah:
Andaikan terdapat formula sedemikian:
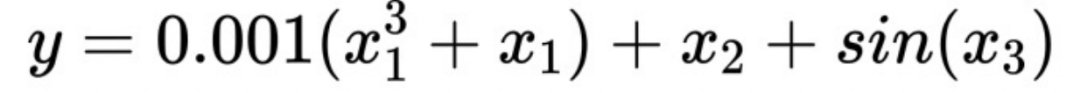
Anda boleh lihat di sini bahawa x1 ialah pembolehubah pekali lemah Apabila x1 Selepas mengenakan kekangan monotonisitas, anggaran tindak balas Y adalah lebih tepat. Tanpa kekangan yang berasingan sedemikian, kepentingan x1 akan ditenggelami oleh x2, mengakibatkan peningkatan berat sebelah model.
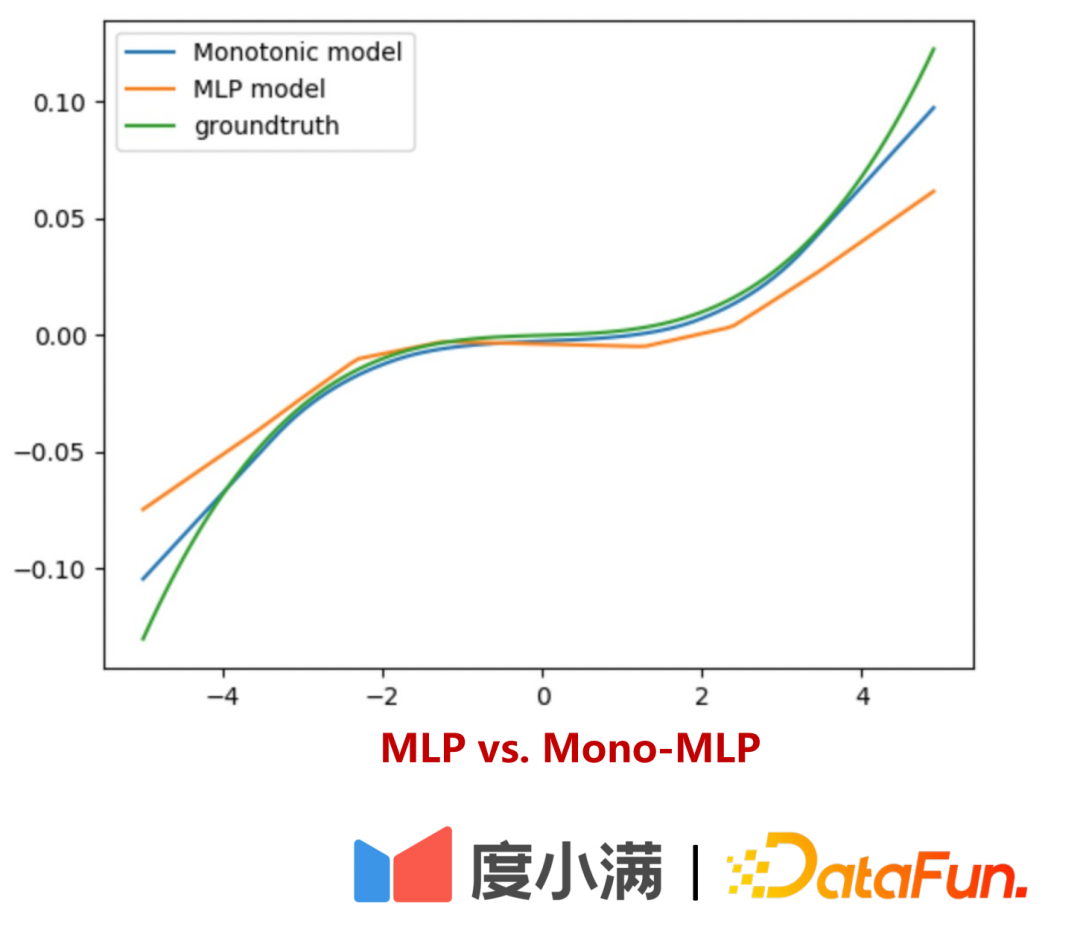
Bagaimana untuk menilai keluk anggaran risiko kuota luar talian?
dibahagikan kepada dua bahagian:
- Bahagian Pertama: Pengesahan Boleh Ditafsir
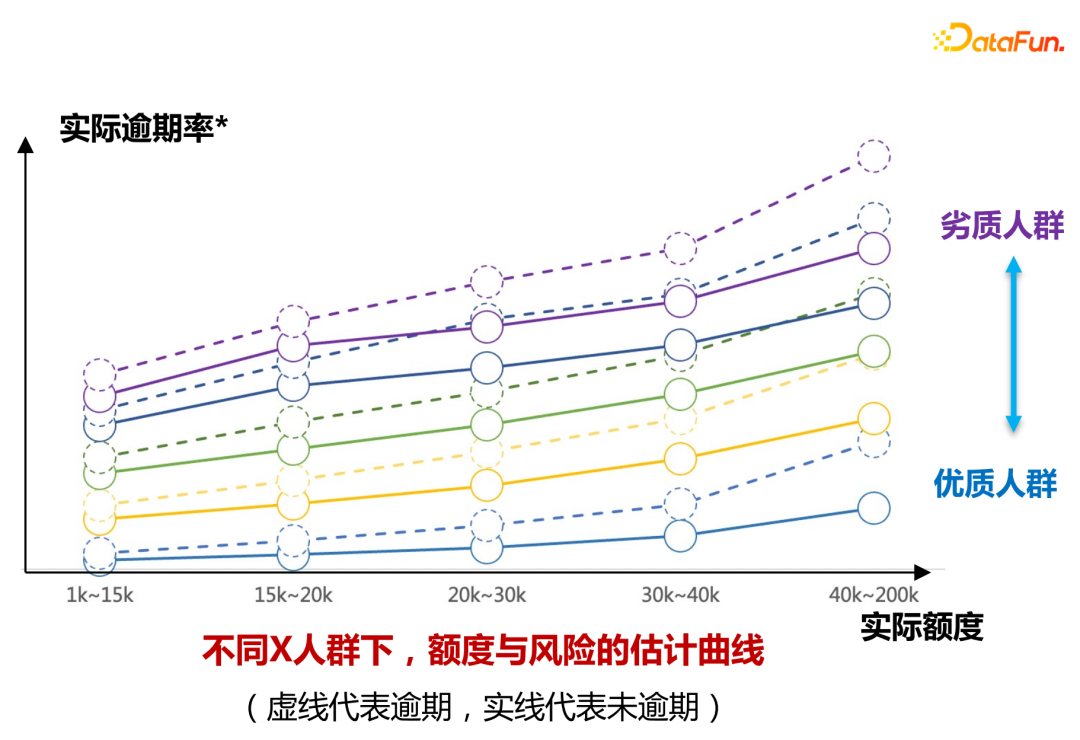
Bagi orang yang mempunyai kelayakan yang berbeza, lukis seperti yang ditunjukkan dalam gambar di atas Berdasarkan keluk perubahan risiko had, model boleh mempelajari perbezaan antara had sebenar dan kadar tertunggak bagi tahap orang yang berbeza dengan kelayakan yang berbeza (ditandakan dengan warna yang berbeza dalam rajah).
- Bahagian 2: Menggunakan eksperimen aliran kecil untuk mengesahkan, sisihan risiko di bawah julat peningkatan kuota yang berbeza boleh diperoleh melalui binning uplift.
Kesimpulan percubaan dalam talian:
Di bawah syarat bahawa kuota meningkat sebanyak 30%, jumlah pengguna tertunggak berkurangan lebih daripada 20%, peminjaman meningkat sebanyak 30%, dan keuntungan meningkat lebih daripada 30%.
Jangkaan model masa hadapan:
Pembolehubah instrumental dan pelarasan adalah bebas model Pembolehubah adalah dipisahkan dengan lebih jelas, membolehkan model menunjukkan prestasi yang lebih baik pada pemindahan risiko pada populasi yang lebih rendah.
Dalam senario perniagaan sebenar, proses lelaran evolusi model Du Xiaoman adalah seperti berikut:
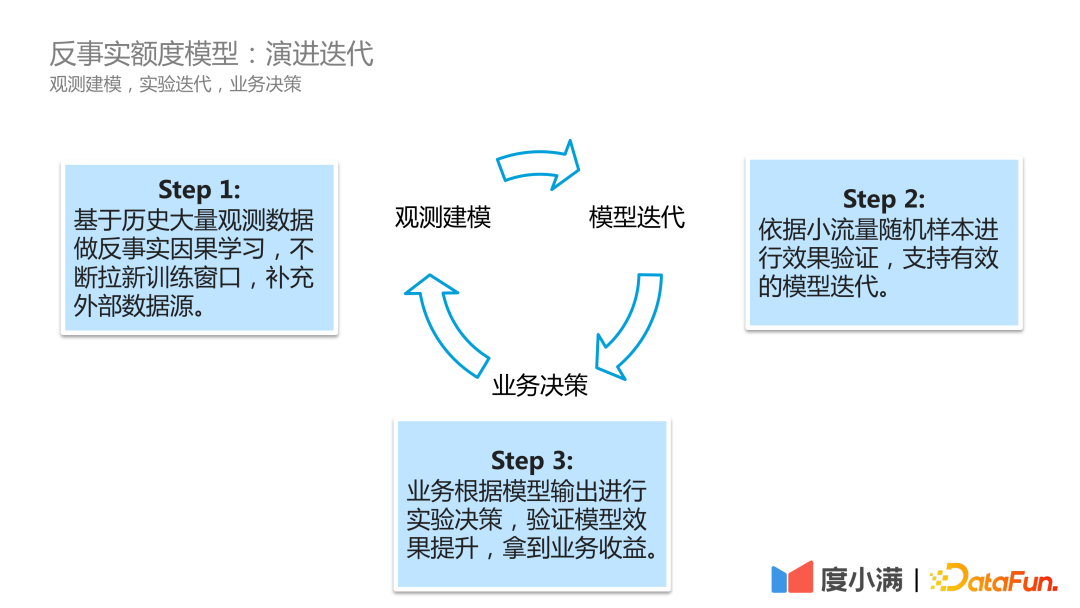
Langkah pertama ialah pemodelan pemerhatian, terus menatal data pemerhatian sejarah, melakukan pembelajaran sebab-akibat yang berlawanan, dan sentiasa membuka tingkap latihan baharu, ditambah oleh sumber data luaran.
Langkah kedua ialah lelaran model Kesannya disahkan berdasarkan sampel rawak trafik kecil untuk menyokong lelaran model yang berkesan.
Langkah ketiga ialah membuat keputusan perniagaan. Perniagaan membuat keputusan percubaan berdasarkan output model untuk mengesahkan peningkatan kesan model dan mendapatkan faedah perniagaan.
Atas ialah kandungan terperinci Model kuota Duxiaoman berdasarkan inferens sebab akibat kontrafaktual. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Ringkasan idea teknikal utama dan kaedah inferens sebab musabab
Apr 12, 2023 am 08:10 AM
Ringkasan idea teknikal utama dan kaedah inferens sebab musabab
Apr 12, 2023 am 08:10 AM
Pengenalan: Inferens sebab merupakan cabang penting dalam sains data Ia memainkan peranan penting dalam lelaran produk, algoritma dan penilaian strategi insentif dalam Internet dan industri Ia menggabungkan data, eksperimen atau model ekonometrik untuk mengira kesan perubahan baharu faedah adalah asas untuk membuat keputusan. Walau bagaimanapun, inferens sebab-akibat bukanlah perkara yang mudah. Pertama sekali, dalam kehidupan seharian, orang sering mengelirukan korelasi dan sebab. Korelasi selalunya bermaksud bahawa dua pembolehubah mempunyai kecenderungan untuk meningkat atau menurun pada masa yang sama, tetapi sebab musabab bermaksud bahawa kita ingin tahu apa yang akan berlaku apabila kita menukar pembolehubah, atau kita menjangkakan untuk mendapatkan hasil kontrafaktual, jika kita melakukannya dalam masa lalu Jika kita mengambil tindakan yang berbeza, adakah akan ada perubahan pada masa hadapan? Kesukarannya, walau bagaimanapun, adalah selalunya data kontrafaktual
 Model kuota Duxiaoman berdasarkan inferens sebab akibat kontrafaktual
Jun 03, 2023 pm 10:16 PM
Model kuota Duxiaoman berdasarkan inferens sebab akibat kontrafaktual
Jun 03, 2023 pm 10:16 PM
1. Paradigma penyelidikan inferens sebab-sebab Paradigma penyelidikan pada masa ini mempunyai dua hala tuju penyelidikan utama: rangka kerja keluaran yang berpotensi Model Struktur Mutiara Judea Dalam buku "The Book of Why-The New Science of Cause and Effect", tangga kognitif diletakkan sebagai tiga peringkat: peringkat pertama - persatuan : Ketahui peraturan melalui korelasi, yang boleh diperhatikan secara langsung tahap kedua - campur tangan: jika status quo diubah, apakah tindakan yang perlu dilaksanakan dan apakah kesimpulan yang perlu dibuat, boleh; diperhatikan melalui eksperimen; peringkat ketiga - kontrafaktual: disebabkan oleh Isu seperti undang-undang dan peraturan tidak boleh dipatuhi secara langsung secara eksperimen, dan andaian kontrafaktual dibuat tentang apa yang akan berlaku jika tindakan itu telah dilaksanakan, seperti
 Sistem pengesyor berdasarkan inferens sebab musabab: semakan dan prospek
Apr 12, 2024 am 09:01 AM
Sistem pengesyor berdasarkan inferens sebab musabab: semakan dan prospek
Apr 12, 2024 am 09:01 AM
Tema perkongsian ini adalah sistem pengesyoran berdasarkan inferens sebab Kami menyemak kerja berkaitan masa lalu dan mencadangkan prospek masa depan ke arah ini. Mengapakah kita perlu menggunakan teknik inferens sebab dalam sistem pengesyor? Kerja penyelidikan sedia ada menggunakan inferens sebab-sebab untuk menyelesaikan tiga jenis masalah (lihat kertas TOIS2023 Gaoe et al. Inferens Sebab-sebab dalam Sistem Pengesyor: ASurvey dan Arah Masa Depan): Pertama, terdapat pelbagai bias (BIAS) dalam sistem pengesyoran, dan inferens penyebab ialah cara yang berkesan untuk mengalih keluar Alat ini kerana berat sebelah. Sistem pengesyor mungkin menghadapi cabaran dalam menangani kekurangan data dan ketidakupayaan untuk menganggarkan kesan penyebab dengan tepat. untuk menyelesaikan
 Fokus padanya! ! Analisis dua rangka kerja algoritma utama untuk inferens sebab
Jun 04, 2024 pm 04:45 PM
Fokus padanya! ! Analisis dua rangka kerja algoritma utama untuk inferens sebab
Jun 04, 2024 pm 04:45 PM
1. Tugas utama rangka kerja keseluruhan boleh dibahagikan kepada tiga kategori. Yang pertama ialah penemuan struktur sebab akibat, iaitu mengenal pasti hubungan sebab akibat antara pembolehubah daripada data. Yang kedua ialah anggaran kesan sebab akibat, iaitu membuat kesimpulan daripada data tahap pengaruh satu pembolehubah ke atas pembolehubah yang lain. Perlu diingat bahawa impak ini tidak merujuk kepada sifat relatif, tetapi kepada bagaimana nilai atau taburan pembolehubah lain berubah apabila satu pembolehubah diintervensi. Langkah terakhir ialah membetulkan bias, kerana dalam banyak tugas, pelbagai faktor boleh menyebabkan pengedaran sampel pembangunan dan sampel aplikasi berbeza. Dalam kes ini, inferens sebab boleh membantu kami membetulkan bias. Fungsi ini sesuai untuk pelbagai senario, yang paling tipikal ialah senario membuat keputusan. Melalui inferens kausal, kami dapat memahami cara pengguna yang berbeza bertindak balas terhadap gelagat membuat keputusan kami. Kedua, dalam industri
 Aplikasi teknologi cadangan sebab dalam pemasaran dan kebolehjelasan
May 18, 2023 pm 01:58 PM
Aplikasi teknologi cadangan sebab dalam pemasaran dan kebolehjelasan
May 18, 2023 pm 01:58 PM
1. Ramalan sensitiviti keuntungan Uplifit Berkenaan keuntungan Peningkatan, masalah perniagaan umum boleh diringkaskan sebagai: di kalangan kumpulan orang yang ditentukan, pemasar akan ingin mengetahui berapa banyak tindakan pemasaran baharu yang boleh dibawa oleh T=1 berbanding dengan tindakan pemasaran asal T= 0. Berapakah purata faedah (angkat, ATE, AverageTreatmentEffect). Semua orang akan memberi perhatian sama ada tindakan pemasaran baharu itu lebih berkesan daripada tindakan asal. Dalam senario insurans, tindakan pemasaran terutamanya merujuk kepada pengesyoran insurans, seperti copywriting dan produk yang didedahkan pada modul pengesyoran Matlamatnya adalah untuk mencari kumpulan yang mendapat keuntungan paling banyak disebabkan oleh tindakan pemasaran di bawah pelbagai tindakan dan kekangan pemasaran, dan untuk. Lakukan penghantaran disasarkan (AudienceTargeting). Mari buat perbandingan dahulu
 Amalan inferens sebab dalam pengesyoran video pendek Kuaishou
Feb 05, 2024 pm 06:20 PM
Amalan inferens sebab dalam pengesyoran video pendek Kuaishou
Feb 05, 2024 pm 06:20 PM
1. Senario pengesyoran video pendek lajur tunggal Kuaishou 1. Mengenai Kuaishou* Data diambil dari suku kedua 2023. Kuaishou ialah aplikasi komuniti siaran langsung dan video pendek yang popular. Ia telah mencapai rekod MAU dan DAU Baharu yang mengagumkan. Konsep teras Kuaishou adalah untuk membolehkan semua orang menjadi pencipta dan penyebar kandungan dengan memerhati dan berkongsi kehidupan orang biasa. Dalam aplikasi Kuaishou, adegan video pendek terbahagi terutamanya kepada dua bentuk: lajur tunggal dan lajur berganda. Pada masa ini, trafik satu lajur adalah agak besar, dan pengguna boleh menyemak imbas kandungan video secara mendalam dengan meluncur ke atas dan ke bawah. Pembentangan dua lajur adalah serupa dengan aliran maklumat Pengguna perlu memilih yang mereka minati daripada beberapa kandungan yang muncul pada skrin dan klik untuk menonton. Algoritma pengesyoran ialah teras ekosistem perniagaan Kuaishou dan penting untuk pengedaran trafik.
 Bagaimana untuk menggunakan data dengan lebih baik dalam inferens sebab-akibat?
Apr 11, 2023 pm 07:43 PM
Bagaimana untuk menggunakan data dengan lebih baik dalam inferens sebab-akibat?
Apr 11, 2023 pm 07:43 PM
Pengenalan: Tajuk perkongsian ini ialah "Bagaimana untuk menggunakan data dengan lebih baik dalam inferens sebab musabab?" ", yang terutamanya memperkenalkan kerja terbaru pasukan berkaitan dengan kertas kerja yang diterbitkan mengenai sebab dan akibat. Laporan ini memperkenalkan cara kami boleh menggunakan lebih banyak data untuk membuat inferens sebab dari dua aspek Satu ialah menggunakan data kawalan sejarah untuk secara jelas mengurangkan bias kekeliruan, dan satu lagi ialah inferens sebab di bawah gabungan data berbilang sumber. Jadual kandungan teks penuh: Pembetulan latar belakang inferens sebab akibat Gabungan data penyebab GBCT dalam aplikasi perniagaan semut 1. Latar belakang inferens sebab Masalah ramalan pembelajaran mesin yang biasa ditetapkan dalam sistem yang sama Contohnya, pengagihan bebas dan serupa biasanya diandaikan. seperti meramalkan perokok masalah ramalan seperti kebarangkalian mendapat kanser paru-paru dan klasifikasi gambar. Persoalan sebab dan akibat adalah berkenaan dengan mekanisme di sebalik data soalan lazim seperti
 Adakah penipuan AI adalah kadar kejayaan 100%? Model palsu anti-deep Du Xiaoman 'mengalahkan sihir dengan sihir'
May 30, 2023 pm 09:46 PM
Adakah penipuan AI adalah kadar kejayaan 100%? Model palsu anti-deep Du Xiaoman 'mengalahkan sihir dengan sihir'
May 30, 2023 pm 09:46 PM
2023-05-2610:22:19 Pengarang: Song Junyi Baru-baru ini, topik #AIFraud Kadar Kejayaan Hampir 100%# menjadi carian hangat di Weibo. Video perubahan wajah AI telah menipu wakil sah sebuah syarikat teknologi di Fujian daripada 4.3 juta yuan dalam masa 10 minit. Penipuan berkaitan AI juga berlaku di luar negara E-mel dengan video CEO Google yang dilampirkan menyebabkan ramai penulis blog YouTube memuat turun fail yang mengandungi virus berbahaya. Kedua-dua insiden penipuan melibatkan teknologi deepfake. Ini adalah kaedah mengubah wajah yang telah wujud selama 6 tahun Pada masa kini, ledakan teknologi AIGC telah memudahkan dan memudahkan untuk mencipta video palsu yang sukar dikenal pasti. Untuk industri kewangan di mana pengecaman muka digunakan secara meluas,
