
 Peranti teknologi
AI
Pemahaman dunia terbuka tentang awan titik 3D, klasifikasi, perolehan semula, sari kata dan penjanaan imej
Peranti teknologi
AI
Pemahaman dunia terbuka tentang awan titik 3D, klasifikasi, perolehan semula, sari kata dan penjanaan imej
Pemahaman dunia terbuka tentang awan titik 3D, klasifikasi, perolehan semula, sari kata dan penjanaan imej

Masukkan bentuk tiga dimensi kerusi goyang dan kuda Apa yang anda boleh dapat?


Kereta kayu ditambah kuda? Dapatkan kereta dan kuda elektrik; Dapatkan perahu layar pisang ditambah dengan kerusi geladak? Dapatkan kerusi telur.
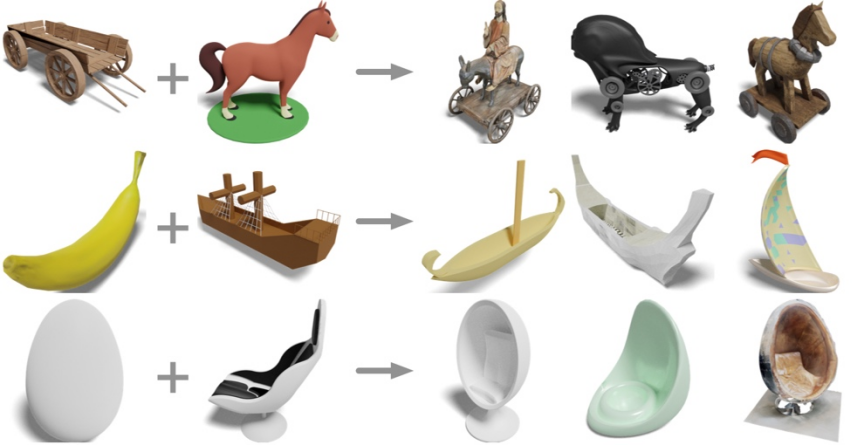
Penyelidik dari UCSD, Universiti Shanghai Jiao Tong dan pasukan Qualcomm telah mencadangkan model perwakilan tiga dimensi terkini OpenShape, membolehkan anda memahami dunia terbuka bentuk tiga dimensi.
- Alamat kertas: https://arxiv.org/pdf/2305.10764.pdf
- Laman utama projek: https://colin97.github.io/OpenShape/
- Demo interaktif: https://huggingface.co/spaces/OpenShape/openshape-demo
- Alamat kod:https://github.com/Colin97/OpenShape_code
Dengan mempelajari pengekod asli awan titik 3D pada data berbilang modal (awan titik - teks - imej), OpenShape membina ruang perwakilan bentuk 3D dan menjajarkannya dengan ruang teks dan imej CLIP. Terima kasih kepada pra-latihan 3D berskala besar dan pelbagai, OpenShape mencapai pemahaman dunia terbuka tentang bentuk 3D buat kali pertama, menyokong klasifikasi bentuk 3D tangkapan sifar, pengambilan bentuk 3D berbilang mod (input awan teks/imej/titik), dan sari kata awan titik 3D Tugas silang modal seperti penjanaan imej dan penjanaan imej berasaskan awan titik 3D.
Klasifikasi tangkapan sifar bentuk 3D
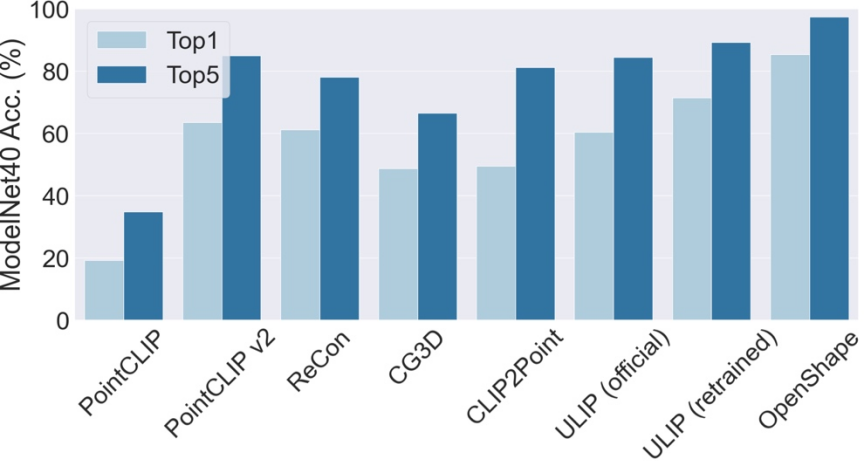
OpenShape menyokong klasifikasi bentuk 3D tangkapan sifar. Tanpa latihan tambahan atau penalaan halus, OpenShape mencapai ketepatan top1 sebanyak 85.3% pada penanda aras ModelNet40 yang biasa digunakan (termasuk 40 kategori biasa), mengatasi kaedah sifar pukulan sedia ada sebanyak 24 mata peratusan dan mencapai prestasi yang setanding dengan beberapa kaedah yang diselia sepenuhnya untuk kali pertama.
Ketepatan top3 dan top5 OpenShape pada ModelNet40 masing-masing mencapai 96.5% dan 98.0%.
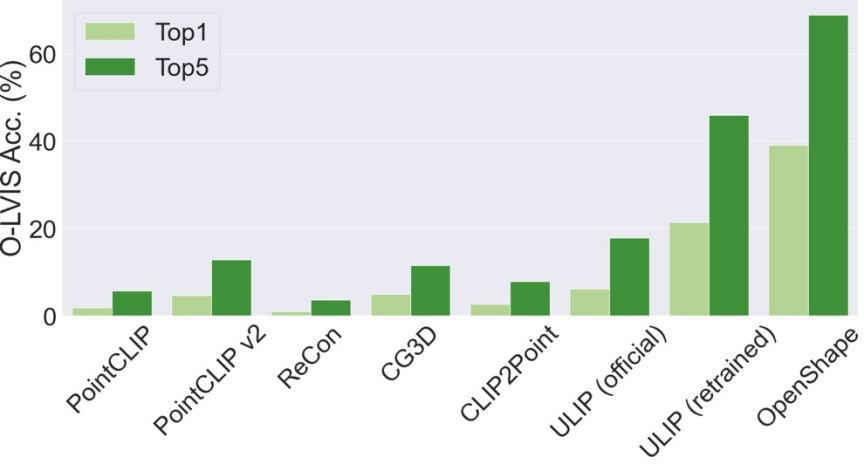
Tidak seperti kaedah sedia ada yang terhad terutamanya kepada beberapa kategori objek biasa, OpenShape dapat mengklasifikasikan pelbagai kategori dunia terbuka. Pada penanda aras Objaverse-LVIS (mengandungi 1156 kategori objek), OpenShape mencapai ketepatan top1 sebanyak 46.8%, jauh melebihi ketepatan tertinggi hanya 6.2% daripada kaedah tangkapan sifar sedia ada. Keputusan ini menunjukkan bahawa OpenShape mempunyai keupayaan untuk mengenali bentuk 3D dengan berkesan di dunia terbuka.
Pendapatan semula bentuk 3D berbilang mod
Dengan perwakilan multimodal OpenShape, pengguna boleh melakukan pengambilan semula bentuk 3D pada imej, teks atau input awan titik. Kaji perolehan semula bentuk 3D daripada set data bersepadu dengan mengira persamaan kosinus antara perwakilan input dan perwakilan bentuk 3D dan mencari kNN.

Pendapatan semula bentuk tiga dimensi input imej
Imej di atas menunjukkan imej input dan dua bentuk 3D yang diambil semula.

Pendapatan semula bentuk 3D input teks
Imej di atas menunjukkan teks input dan bentuk 3D yang diambil. OpenShape mempelajari pelbagai konsep visual dan semantik, membolehkan subkategori halus (dua baris pertama) dan kawalan atribut (dua baris terakhir, seperti warna, bentuk, gaya dan gabungannya).

Pendapatan semula bentuk 3D input awan titik 3D
Imej di atas menunjukkan input awan titik 3D dan dua bentuk 3D yang diambil.

Input dua kali pengambilan bentuk tiga dimensi
Rajah di atas mengambil dua bentuk 3D sebagai input dan menggunakan perwakilan OpenShape mereka untuk mendapatkan semula bentuk 3D yang paling hampir dengan kedua-dua input pada masa yang sama. Bentuk yang diambil dengan bijak menggabungkan elemen semantik dan geometri daripada kedua-dua bentuk input.
Penjanaan teks dan imej berasaskan bentuk 3D
Memandangkan perwakilan bentuk 3D OpenShape diselaraskan dengan ruang perwakilan imej dan teks CLIP, ia boleh digunakan dengan banyak model Terbitan daripada CLIP digabungkan untuk menyokong pelbagai aplikasi rentas modal.

Penjanaan sari kata awan titik 3D
Dengan menggabungkan dengan model sari kata imej siap pakai (ClipCap), OpenShape melaksanakan penjanaan sari kata untuk awan titik 3D.

Penjanaan imej berdasarkan awan titik 3D
Dengan menggabungkan dengan model penyebaran teks-ke-imej siap sedia (Stable unCLIP), OpenShape melaksanakan penjanaan imej berdasarkan awan titik 3D (menyokong pembayang teks pilihan).

Lebih banyak contoh penjanaan imej berdasarkan awan titik 3D
Butiran latihan
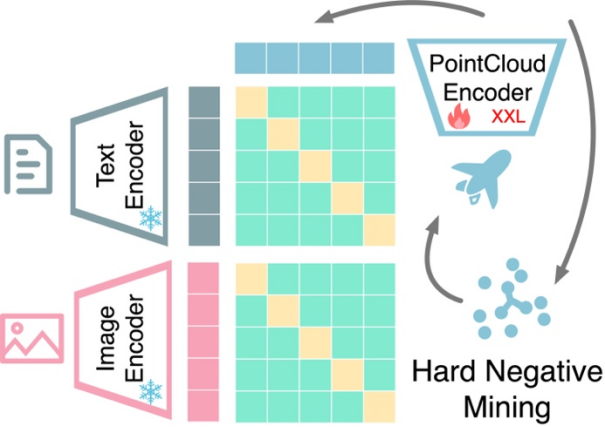
Penjajaran perwakilan berbilang mod berdasarkan pembelajaran kontrastif: OpenShape melatih pengekod asli 3D yang akan Awan titik 3D digunakan sebagai input untuk mengekstrak perwakilan bentuk 3D. Berikutan kerja sebelumnya, kami mengeksploitasi pembelajaran kontrastif multimodal untuk diselaraskan dengan ruang perwakilan imej dan teks CLIP. Tidak seperti kerja sebelumnya, OpenShape bertujuan untuk mempelajari ruang perwakilan bersama yang lebih umum dan boleh skala. Fokus penyelidikan adalah terutamanya untuk mengembangkan skala pembelajaran perwakilan 3D dan menangani cabaran yang sepadan, supaya benar-benar merealisasikan pemahaman bentuk 3D dalam dunia terbuka.
Mengintegrasikan berbilang set data bentuk 3D: Memandangkan skala dan kepelbagaian data latihan memainkan peranan penting dalam mempelajari perwakilan bentuk 3D berskala besar, kajian itu menyepadukan empat Latihan pada yang terbesar pada masa ini yang tersedia untuk umum Set data 3D. Seperti yang ditunjukkan dalam rajah di bawah, data latihan yang dikaji mengandungi 876,000 bentuk latihan. Antara empat set data, ShapeNetCore, 3D-FUTURE dan ABO mengandungi bentuk 3D yang disahkan manusia berkualiti tinggi, tetapi hanya meliputi bilangan bentuk yang terhad dan berpuluh-puluh kategori. Set data Objaverse ialah set data 3D yang dikeluarkan baru-baru ini yang mengandungi lebih banyak bentuk 3D dan merangkumi kelas objek yang lebih pelbagai. Walau bagaimanapun, bentuk dalam Objaverse kebanyakannya dimuat naik oleh pengguna Internet dan belum disahkan secara manual Oleh itu, kualitinya tidak sekata dan pengedarannya sangat tidak sekata, memerlukan pemprosesan selanjutnya.

Penapisan dan pengayaan teks: Kajian ditemui hanya antara bentuk 3D dan imej 2D Mengaplikasikan pembelajaran kontrastif tidak mencukupi untuk memacu penjajaran bentuk 3D dan ruang teks, walaupun apabila dilatih pada set data berskala besar. Penyelidikan membuat spekulasi bahawa ini adalah disebabkan oleh jurang domain yang wujud dalam bahasa CLIP dan ruang perwakilan imej. Oleh itu, penyelidikan perlu menjajarkan bentuk 3D dengan teks secara eksplisit. Walau bagaimanapun, anotasi teks daripada set data 3D asal sering menghadapi masalah seperti kandungan hilang, salah atau kasar dan tunggal. Untuk tujuan ini, kertas kerja ini mencadangkan tiga strategi untuk menapis dan memperkayakan teks untuk meningkatkan kualiti anotasi teks: penapisan teks menggunakan GPT-4, penjanaan sari kata dan mendapatkan semula imej pemaparan 2D model 3D.
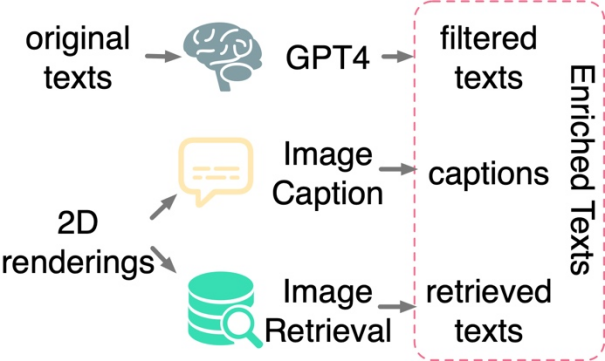
Kajian itu mencadangkan tiga strategi untuk Penapis secara automatik dan memperkayakan teks bising dalam set data mentah.
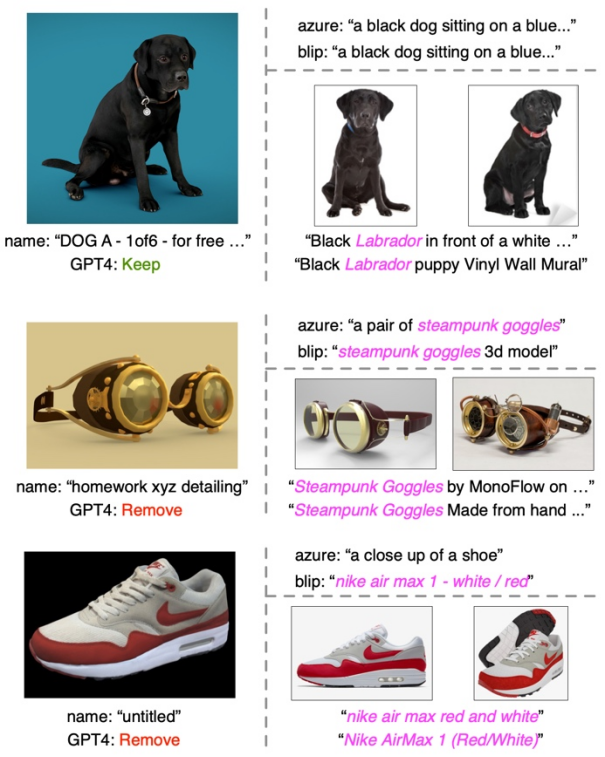
Contoh penapisan dan pengayaan teks
Dalam setiap contoh, bahagian kiri menunjukkan lakaran kecil, nama bentuk asal dan hasil yang ditapis GPT-4. Bahagian kanan atas menunjukkan kapsyen imej daripada dua model kapsyen, manakala bahagian kanan bawah menunjukkan imej yang diambil dan teks yang sepadan dengannya.
Kembangkan rangkaian tulang belakang tiga dimensi. Memandangkan kerja sebelumnya pada pembelajaran awan titik 3D menyasarkan set data 3D berskala kecil seperti ShapeNet, rangkaian tulang belakang ini mungkin tidak boleh digunakan secara langsung untuk latihan 3D berskala besar kami dan skala rangkaian tulang belakang perlu dikembangkan dengan sewajarnya. Kajian mendapati bahawa rangkaian tulang belakang 3D yang berbeza mempamerkan gelagat dan kebolehskalaan yang berbeza apabila dilatih pada set data dengan saiz yang berbeza. Antaranya, PointBERT berdasarkan Transformer dan SparseConv berdasarkan lilitan tiga dimensi menunjukkan prestasi dan kebolehskalaan yang lebih berkuasa, jadi mereka dipilih sebagai rangkaian tulang belakang tiga dimensi.
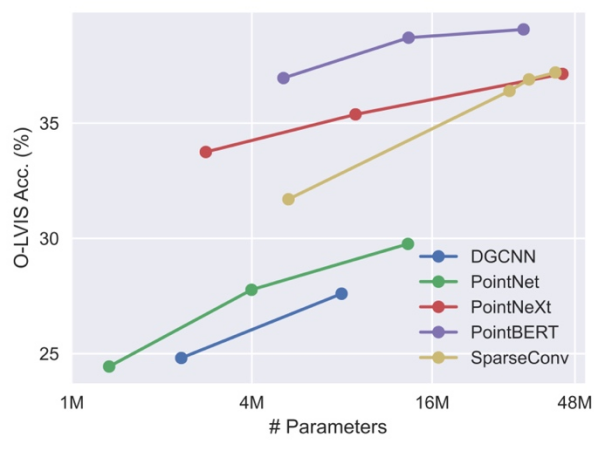
Apabila menskalakan saiz model tulang belakang 3D pada set data bersepadu, Prestasi dan perbandingan skalabiliti.
Contoh Perlombongan Negatif Sukar: Dataset ensemble kajian ini menunjukkan ketidakseimbangan kelas yang tinggi. Beberapa kategori biasa, seperti seni bina, mungkin merangkumi puluhan ribu bentuk, manakala banyak kategori lain, seperti walrus dan dompet, kurang diwakili dengan hanya beberapa dozen atau lebih sedikit bentuk. Oleh itu, apabila kelompok dibina secara rawak untuk pembelajaran kontrastif, bentuk daripada dua kategori yang mudah dikelirukan (cth., epal dan ceri) tidak mungkin muncul dalam kelompok yang sama untuk dikontraskan. Untuk tujuan ini, kertas kerja ini mencadangkan strategi perlombongan contoh negatif yang sukar di luar talian untuk meningkatkan kecekapan dan prestasi latihan.
Selamat mencuba demo interaktif di HuggingFace.
Atas ialah kandungan terperinci Pemahaman dunia terbuka tentang awan titik 3D, klasifikasi, perolehan semula, sari kata dan penjanaan imej. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Cara Melaksanakan Penyortiran Fail oleh Debian Readdir
Apr 13, 2025 am 09:06 AM
Cara Melaksanakan Penyortiran Fail oleh Debian Readdir
Apr 13, 2025 am 09:06 AM
Dalam sistem Debian, fungsi Readdir digunakan untuk membaca kandungan direktori, tetapi urutan yang dikembalikannya tidak ditentukan sebelumnya. Untuk menyusun fail dalam direktori, anda perlu membaca semua fail terlebih dahulu, dan kemudian menyusunnya menggunakan fungsi QSORT. Kod berikut menunjukkan cara menyusun fail direktori menggunakan ReadDir dan QSORT dalam sistem Debian:#termasuk#termasuk#termasuk#termasuk // fungsi perbandingan adat, yang digunakan untuk qSortintCompare (Constvoid*A, Constvoid*b) {Returnstrcmp (*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(*(
 Cara Mengoptimumkan Prestasi Debian Readdir
Apr 13, 2025 am 08:48 AM
Cara Mengoptimumkan Prestasi Debian Readdir
Apr 13, 2025 am 08:48 AM
Dalam sistem Debian, panggilan sistem Readdir digunakan untuk membaca kandungan direktori. Jika prestasinya tidak baik, cuba strategi pengoptimuman berikut: Memudahkan bilangan fail direktori: Split direktori besar ke dalam pelbagai direktori kecil sebanyak mungkin, mengurangkan bilangan item yang diproses setiap panggilan readdir. Dayakan Caching Kandungan Direktori: Bina mekanisme cache, kemas kini cache secara teratur atau apabila kandungan direktori berubah, dan mengurangkan panggilan kerap ke Readdir. Cafh memori (seperti memcached atau redis) atau cache tempatan (seperti fail atau pangkalan data) boleh dipertimbangkan. Mengamalkan struktur data yang cekap: Sekiranya anda melaksanakan traversal direktori sendiri, pilih struktur data yang lebih cekap (seperti jadual hash dan bukannya carian linear) untuk menyimpan dan mengakses maklumat direktori
 Cara Menetapkan Tahap Log Debian Apache
Apr 13, 2025 am 08:33 AM
Cara Menetapkan Tahap Log Debian Apache
Apr 13, 2025 am 08:33 AM
Artikel ini menerangkan cara menyesuaikan tahap pembalakan pelayan Apacheweb dalam sistem Debian. Dengan mengubah suai fail konfigurasi, anda boleh mengawal tahap maklumat log yang direkodkan oleh Apache. Kaedah 1: Ubah suai fail konfigurasi utama untuk mencari fail konfigurasi: Fail konfigurasi apache2.x biasanya terletak di direktori/etc/apache2/direktori. Nama fail mungkin apache2.conf atau httpd.conf, bergantung pada kaedah pemasangan anda. Edit Fail Konfigurasi: Buka Fail Konfigurasi dengan Kebenaran Root Menggunakan Editor Teks (seperti Nano): Sudonano/ETC/APACHE2/APACHE2.CONF
 Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Bagaimana Debian Readdir Bersepadu Dengan Alat Lain
Apr 13, 2025 am 09:42 AM
Fungsi Readdir dalam sistem Debian adalah panggilan sistem yang digunakan untuk membaca kandungan direktori dan sering digunakan dalam pengaturcaraan C. Artikel ini akan menerangkan cara mengintegrasikan Readdir dengan alat lain untuk meningkatkan fungsinya. Kaedah 1: Menggabungkan Program Bahasa C dan Pipeline Pertama, tulis program C untuk memanggil fungsi Readdir dan output hasilnya:#termasuk#termasuk#includeintMain (intargc, char*argv []) {dir*dir; structdirent*entry; if (argc! = 2) {
 Bagaimana Debian OpenSSL Menghalang Serangan Man-dalam-Middle
Apr 13, 2025 am 10:30 AM
Bagaimana Debian OpenSSL Menghalang Serangan Man-dalam-Middle
Apr 13, 2025 am 10:30 AM
Dalam sistem Debian, OpenSSL adalah perpustakaan penting untuk pengurusan penyulitan, penyahsulitan dan sijil. Untuk mengelakkan serangan lelaki-dalam-pertengahan (MITM), langkah-langkah berikut boleh diambil: Gunakan HTTPS: Pastikan semua permintaan rangkaian menggunakan protokol HTTPS dan bukannya HTTP. HTTPS menggunakan TLS (Protokol Keselamatan Lapisan Pengangkutan) untuk menyulitkan data komunikasi untuk memastikan data tidak dicuri atau diganggu semasa penghantaran. Sahkan Sijil Pelayan: Sahkan secara manual Sijil Pelayan pada klien untuk memastikan ia boleh dipercayai. Pelayan boleh disahkan secara manual melalui kaedah perwakilan urlSession
 Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Mengkonfigurasi firewall pelayan Mail Debian adalah langkah penting dalam memastikan keselamatan pelayan. Berikut adalah beberapa kaedah konfigurasi firewall yang biasa digunakan, termasuk penggunaan iptables dan firewalld. Gunakan iptables untuk mengkonfigurasi firewall untuk memasang iptables (jika belum dipasang): sudoapt-getupdateudoapt-getinstalliplesview peraturan iptables semasa: konfigurasi sudoiptable-l
 Cara Belajar Debian Syslog
Apr 13, 2025 am 11:51 AM
Cara Belajar Debian Syslog
Apr 13, 2025 am 11:51 AM
Panduan ini akan membimbing anda untuk belajar cara menggunakan syslog dalam sistem Debian. SYSLOG adalah perkhidmatan utama dalam sistem Linux untuk sistem pembalakan dan mesej log aplikasi. Ia membantu pentadbir memantau dan menganalisis aktiviti sistem untuk mengenal pasti dan menyelesaikan masalah dengan cepat. 1. Pengetahuan asas syslog Fungsi teras syslog termasuk: mengumpul dan menguruskan mesej log secara terpusat; menyokong pelbagai format output log dan lokasi sasaran (seperti fail atau rangkaian); Menyediakan fungsi tontonan log dan penapisan masa nyata. 2. Pasang dan konfigurasikan syslog (menggunakan rsyslog) Sistem Debian menggunakan rsyslog secara lalai. Anda boleh memasangnya dengan arahan berikut: sudoaptupdatesud
 Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Langkah -langkah untuk memasang sijil SSL pada pelayan mel Debian adalah seperti berikut: 1. Pasang OpenSSL Toolkit terlebih dahulu, pastikan bahawa OpenSSL Toolkit telah dipasang pada sistem anda. Jika tidak dipasang, anda boleh menggunakan arahan berikut untuk memasang: sudoapt-getupdateudoapt-getinstallopenssl2. Menjana permintaan kunci dan sijil peribadi seterusnya, gunakan OpenSSL untuk menjana kunci peribadi RSA 2048-bit dan permintaan sijil (CSR): Membuka
