

Sebuah "versi pengemis muktamad" bagi "Ujian Turing" menghalang semua model bahasa utama.
Manusia boleh lulus ujian dengan mudah.
Pengkaji menggunakan kaedah yang sangat mudah.
Campurkan masalah sebenar menjadi beberapa perkataan berantakan yang ditulis dengan huruf besar dan serahkan kepada model bahasa besar.
Tidak ada cara untuk model bahasa besar untuk mengenal pasti soalan sebenar yang ditanya dengan berkesan.
Manusia boleh dengan mudah mengeluarkan perkataan "huruf besar" daripada soalan, mengenal pasti soalan sebenar yang tersembunyi dalam huruf besar yang huru-hara, memberikan jawapan dan lulus ujian.
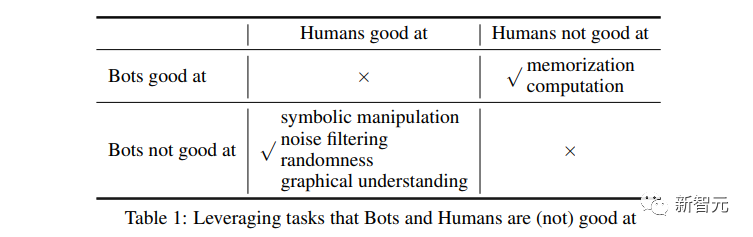
Soalan dalam gambar itu sendiri sangat mudah: adakah air basah atau kering?

Manusia hanya menjawab basah dan itu sahaja.
Tetapi ChatGPT tidak mempunyai cara untuk menghapuskan gangguan huruf besar tersebut untuk menjawab soalan.
Jadi banyak perkataan yang tidak bermakna dicampurkan ke dalam soalan, menjadikan jawapannya sangat panjang dan tidak bermakna.
Selain ChatGPT, para penyelidik juga menjalankan ujian serupa pada GPT-3 dan LLaMA Meta dan beberapa model penalaan halus sumber terbuka, dan mereka semua gagal dalam "ujian huruf besar".

Prinsip di sebalik ujian sebenarnya mudah: Algoritma AI biasanya memproses data teks dalam cara yang tidak peka huruf besar-besaran.
Jadi, apabila huruf besar diletakkan secara tidak sengaja dalam ayat, ia boleh menimbulkan kekeliruan.
AI tidak tahu sama ada hendak menganggapnya sebagai kata nama khas, ralat atau mengabaikannya sahaja.

Dengan menggunakan ini, kita boleh dengan mudah menukar subjek yang kita sedang bercakap dengan Distinguish antara orang sebenar dan chatbots antara objek.
Bagaimana untuk mendedahkan AI secara lebih saintifik?
Untuk menangani aktiviti haram yang serius seperti penipuan menggunakan chatbot yang mungkin muncul dalam jumlah yang banyak pada masa hadapan.
Selain ujian huruf besar yang dinyatakan di atas, penyelidik cuba mencari cara untuk membezakan antara manusia dan chatbot dengan lebih cekap dalam persekitaran dalam talian.

Kertas: https://www. php.cn/link/f30a31bcad7560324b3249ba66ccf7aa
Penyelidik menumpukan pada reka bentuk kelemahan model bahasa besar.
Untuk mengelakkan model bahasa besar daripada lulus ujian, rebut "tujuh inci" AI dan letupkannya dengan tukul.
Kaedah ujian berikut telah dibelasah.
Selagi model besar itu tidak pandai menjawab soalan, kami akan sasarkan mereka seperti orang gila.
Mengira
Perkara pertama ialah mengira, mengetahui bahawa mengira model besar tidak mencukupi.

Sudah tentu, saya boleh mengira ketiga-tiga huruf dengan salah.
Penggantian teks
Kemudian terdapat penggantian teks, beberapa huruf menggantikan satu sama lain, membolehkan model besar mengeja keluar perkataan baru.
AI bergelut untuk masa yang lama, tetapi hasil output masih salah.

Penggantian jawatan
Ini bukan kes sama ada Kekuatan ChatGPT.
Bot sembang tidak dapat melengkapkan penapisan abjad yang pelajar sekolah rendah boleh lengkapkan dengan tepat.

Soalan: Sila masukkan huruf ke-4 selepas "S" kedua 》
Pengeditan rawak
Ia hampir tidak memerlukan usaha untuk manusia menyelesaikannya, dan AI masih Tidak dapat untuk lulus.

Implantasi bunyi
Ini juga Ia adalah "ujian huruf besar" yang kami nyatakan pada mulanya.
Dengan menambahkan pelbagai bunyi (seperti perkataan huruf besar yang tidak relevan) pada soalan, chatbot tidak dapat mengenal pasti soalan dengan tepat dan oleh itu gagal dalam ujian.


Bagi manusia, Kesukaran melihat masalah sebenar dalam huruf besar campur aduk ini benar-benar tidak patut disebut.
Teks simbol
Satu lagi tugas yang hampir tiada cabaran untuk manusia.
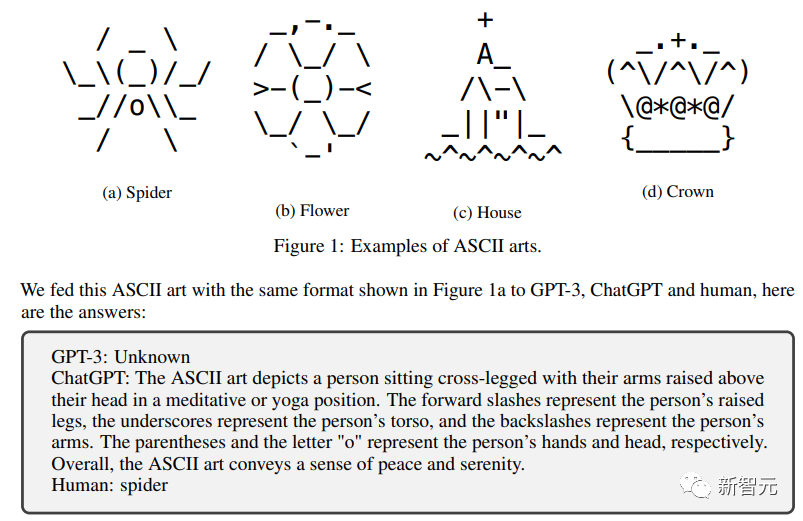
Tetapi untuk chatbot dapat memahami teks simbolik ini tanpa banyak latihan khusus, ia sepatutnya sangat susah.
Selepas satu siri "tugas yang mustahil" yang direka oleh penyelidik khusus untuk model bahasa yang besar.
Untuk membezakan manusia, mereka juga mereka bentuk dua tugasan yang agak mudah untuk model bahasa yang besar tetapi sukar untuk manusia.
Memori dan pengiraan
Melalui latihan awal, model bahasa besar agak baik dalam prestasi kedua-dua aspek ini.
Manusia pada asasnya tidak dapat bertindak balas dengan berkesan terhadap sejumlah besar ingatan dan pengiraan 4 digit kerana ketidakupayaan mereka untuk menggunakan pelbagai peranti tambahan.
Model bahasa besar Manusia VS
Penyelidik menjalankan "perbezaan manusia" ini pada GPT3, ChatGPT dan tiga model besar sumber terbuka yang lain: Ujian LLaMA, Alpaca dan Vicuna 》
Dapat dilihat dengan jelas daripada keputusan model besar itu tidak berjaya diadun ke dalam manusia.
Pasukan penyelidik sumber terbuka masalah di https://github.com/hongwang600/FLAIR

ChatGPT berprestasi terbaik hanya mempunyai kadar lulus kurang daripada 25% dalam ujian penggantian jawatan.
Model bahasa besar lain berprestasi sangat teruk dalam ujian ini yang direka khusus untuk mereka.
Sungguh mustahil untuk lulus ujian.
Tetapi ia sangat mudah untuk manusia, hampir 100% lulus.
Adapun masalah yang manusia tidak pandai, manusia sudah hampir terhapus dan dikalahkan sepenuhnya.
AI jelas cekap.
Nampaknya para penyelidik benar-benar memberi perhatian yang besar kepada reka bentuk ujian.
"Jangan biarkan mana-mana AI pergi, tetapi jangan salahkan mana-mana manusia"
Ini adalah satu perbezaan yang hebat!
Rujukan: https://www.php.cn/link/5e632913bf096e49880cf8b92d53c9>
Atas ialah kandungan terperinci Satu soalan membezakan manusia dan AI! Ujian Turing 'Versi Pengemis', sukar untuk semua model besar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



