

Kebanyakan pelayan MySQL telah mendayakan caching pertanyaan. Ini adalah salah satu cara yang paling berkesan untuk meningkatkan prestasi, dan ia dikendalikan oleh enjin pangkalan data MySQL. Apabila banyak pertanyaan yang sama dilaksanakan berbilang kali, hasil pertanyaan akan diletakkan dalam cache, supaya pertanyaan serupa berikutnya tidak perlu mengendalikan jadual tetapi mengakses terus hasil cache.
Masalah utama di sini ialah bagi pengaturcara, perkara ini mudah terlepas pandang. Kerana beberapa pernyataan pertanyaan kami akan menyebabkan MySQL tidak menggunakan cache . Sila lihat contoh berikut:

Perbezaan antara dua pernyataan SQL di atas ialah
CURDATE(), cache pertanyaan MySQL tidak berfungsi untuk fungsi ini . Oleh itu, fungsi SQL sepertiNOW()danRAND()atau fungsi lain yang serupa tidak akan mendayakan caching pertanyaan, kerana pulangan fungsi ini tidak menentu. Jadi, apa yang anda perlukan ialah menggantikan fungsi MySQL dengan pembolehubah untuk membolehkan caching.
Menggunakan kata kunci
EXPLAINboleh memberitahu anda bagaimana MySQL memproses pernyataan SQL anda . Ini boleh membantu anda menganalisis kesesakan prestasi penyata pertanyaan atau struktur jadual anda. Hasil pertanyaanEXPLAINjuga akan memberitahu anda cara kunci utama indeks anda digunakan, cara jadual data anda dicari dan diisih...dsb., dsb.
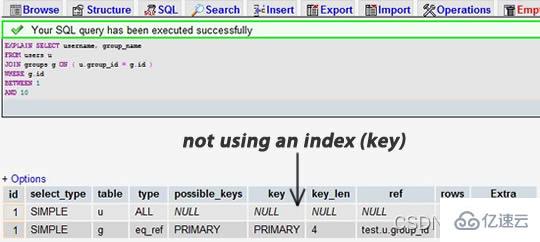
Pilih salah satu penyataSELECTanda (disyorkan untuk memilih yang paling kompleks dengan berbilang sambungan jadual) dan tambahkan kata kunciEXPLAINke hadapan. Anda boleh menggunakanphpmyadminuntuk melakukan ini. Kemudian, anda akan melihat satu borang. Dalam contoh di bawah, kami terlupa untuk menambah indeksgroup_iddan mempunyai gabungan jadual:
Selepas kami menambah indeks pada medan group_id: 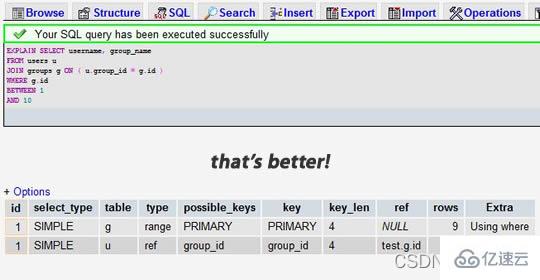
Kita dapat melihat bahawa hasil sebelumnya menunjukkan bahawa 7883 baris telah dicari, manakala yang terakhir hanya mencari 9 dan 16 baris daripada dua jadual. Melihat pada lajur baris membolehkan kami mencari isu prestasi yang berpotensi.
Apabila anda menanyakan jadual, anda sudah tahu bahawa hanya akan ada satu hasil, tetapi kerana anda mungkin perlu
fetchKursor, atau anda mungkin menyemak bilangan rekod yang dikembalikan.
Dalam kes ini, menambahLIMIT 1boleh meningkatkan prestasi. Dengan cara ini, enjin pangkalan data MySQL akan berhenti mencari selepas mencari sekeping data, dan bukannya terus mencari sekeping data seterusnya yang sepadan dengan rekod.
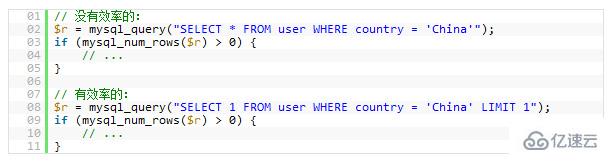
Contoh berikut hanyalah untuk mengetahui sama ada terdapat pengguna "China" Jelas sekali, yang terakhir akan lebih cekap daripada yang pertama. (Sila ambil perhatian bahawa yang pertama ialahSelect *dan yang kedua ialahSelect 1)
Indeks tidak semestinya untuk kunci utama atau satu-satunya medan. Jika terdapat medan dalam jadual anda yang anda akan sentiasa gunakan untuk mencari, maka sila buat indeks untuknya
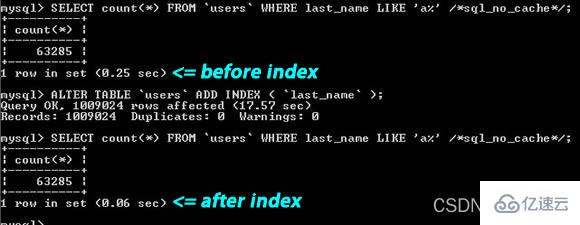
Daripada gambar di atas Anda dapat melihat bahawa rentetan carian "
last_name LIKE ‘a%'", satu diindeks, dan satu lagi tidak diindeks, prestasinya kira-kira 4 kali ganda lebih teruk.
Selain itu, anda juga perlu mengetahui jenis carian yang tidak boleh menggunakan pengindeksan biasa. Contohnya, apabila anda perlu mencari perkataan dalam artikel besar, seperti: “WHERE post_content LIKE ‘%apple%’”, indeks mungkin tidak bermakna. Anda mungkin perlu menggunakan indeks teks penuh MySQL atau membuat indeks sendiri (contohnya: cari kata kunci atau teg)
Jika aplikasi anda mempunyai banyak pertanyaan JOIN, anda harus memastikan bahawa medan Sertai dalam kedua-dua jadual diindeks. Dengan cara ini, MySQL akan memulakan mekanisme untuk mengoptimumkan pernyataan Join SQL untuk anda.
Selain itu, medan yang digunakan untuk Sertai ini hendaklah daripada jenis yang sama. Contohnya: jika anda meletakkan medanDECIMALdengan medan INTJoinbersama-sama, MySQL tidak boleh menggunakan indeksnya. Untuk jenisSTRINGtersebut, mereka juga perlu mempunyai set aksara yang sama. (Set aksara kedua-dua jadual mungkin berbeza)

Mahu mengganggu baris data yang dikembalikan secara rawak? Saya tidak tahu Siapa yang mencipta penggunaan ini, tetapi ramai orang baru suka menggunakannya dengan cara ini. Tetapi anda benar-benar tidak faham betapa teruknya masalah prestasi.
Jika anda benar-benar mahu mengocok baris data yang dikembalikan, anda mempunyai N cara untuk mencapai ini. Menggunakan ini hanya akan menyebabkan prestasi pangkalan data anda menurun secara eksponen. Masalahnya di sini ialah: MySQL perlu melaksanakan fungsiRAND()(yang menggunakan masa CPU), dan ini adalah untuk mengingati baris bagi setiap baris rekod, dan kemudian mengisihnya. Walaupun anda menggunakanLimit 1, ia tidak akan membantu (kerana anda perlu mengisih)
Contoh berikut memilih rekod secara rawak: 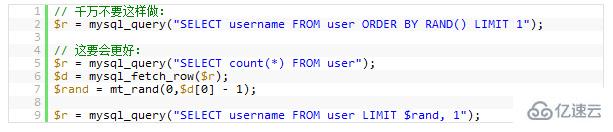
Semakin banyak data dibaca daripada pangkalan data, semakin perlahan pertanyaan itu. Selain itu, jika pelayan pangkalan data dan pelayan WEB anda adalah dua pelayan bebas, ini juga akan meningkatkan beban penghantaran rangkaian. Oleh itu, anda harus membina tabiat yang baik untuk mengambil apa sahaja yang anda perlukan.
9. Gunakan ENUM dan bukannya VARCHARKita harus menetapkan ID untuk setiap jadual dalam pangkalan data sebagai kunci utamanya. dan yang terbaik ialah jenis
INT(disyorkan untuk menggunakanUNSIGNED), dan tetapkan benderaAUTO_INCREMENTyang ditambah secara automatik.
Walaupun jadual pengguna anda mempunyai medan dengan kunci utama yang dipanggil "VARCHARsebagai kunci utama akan merendahkan prestasi. Selain itu, dalam program anda, anda harus menggunakan ID jadual untuk membina struktur data anda.
Selain itu, di bawah enjin data MySQL, terdapat beberapa operasi yang memerlukan penggunaan kunci utama Dalam kes ini, Prestasi dan tetapan kunci utama menjadi sangat penting, seperti kelompok, sekatan...<.> Di sini, hanya terdapat satu pengecualian, iaitu "kunci asing" bagi "jadual bersekutu". Maksudnya, kunci utama jadual ini terdiri daripada kunci utama beberapa jadual individu. Kami memanggil keadaan ini sebagai "kunci asing". Contohnya: terdapat "jadual pelajar" dengan ID pelajar, dan "jadual kurikulum" dengan ID kursus Kemudian, "jadual gred" ialah "jadual persatuan", yang mengaitkan jadual pelajar dan jadual kursus jadual, ID pelajar dan ID kursus dipanggil "kunci asing" dan bersama-sama ia membentuk kunci utama.
Jenis ENUM sangat pantas dan padat. Malah, ia menjimatkan10. Dapatkan cadangan daripada PROCEDURE ANALYSE(), tetapi ia muncul sebagai rentetan. Dengan cara ini, ia menjadi agak sempurna untuk menggunakan medan ini untuk membuat beberapa senarai pilihan.
TINYINTJika anda mempunyai bidang, seperti "Jantina", "Negara", "Etnik", "Status" atau "Jabatan", dan anda tahu bahawa nilai medan ini terhad dan tetap, maka, anda hendaklah menggunakan
bukannyaENUM.VARCHARMySQL juga mempunyai "cadangan" (lihat item 10) untuk memberitahu anda cara menyusun semula struktur jadual anda. Apabila anda mempunyai medan
, cadangan ini akan memberitahu anda untuk menukarnya kepada jenisVARCHAR. MenggunakanENUManda boleh mendapatkan cadangan yang berkaitanPROCEDURE ANALYSE()
akan membenarkan MySQL membantu anda menganalisis medan anda dan bidangnya yang sebenar data dan akan memberi anda beberapa cadangan berguna. Cadangan ini hanya akan berguna jika terdapat data sebenar dalam jadual, kerana membuat beberapa keputusan besar memerlukan data sebagai asas.
PROCEDURE ANALYSE()Sebagai contoh, jika anda mencipta medan INT sebagai kunci utama anda, tetapi tidak banyak data, maka
akan mencadangkan anda menukar jenis medan ini kepadaPROCEDURE ANALYSE(). Atau jika anda menggunakan medanMEDIUMINT, kerana data tidak banyak, anda mungkin mendapat cadangan untuk menukarnya daripadaVARCHARkepada
. Cadangan ini semuanya mungkin kerana data tidak mencukupi, jadi pembuatan keputusan tidak cukup tepat.ENUMDalam
, anda boleh mengklikphpmyadminuntuk melihat cadangan ini apabila melihat jadual. . Cadangan ini hanya akan menjadi tepat kerana jadual anda mengandungi lebih banyak data. Sentiasa ingat,“Propose table structure”Anda adalah orang yang membuat keputusan muktamad
Melainkan anda mempunyai sebab yang sangat khusus untuk menggunakan nilai
NULL, anda harus sentiasa menyimpan medan andaNOT NULL. Ini mungkin kelihatan agak kontroversi, sila baca.
Pertama sekali, tanya diri anda betapa besar perbezaan antara "Empty" dan "NULL" (jikaINT, itu 0 dan NULL) jika anda rasa ada a perbezaan antara mereka Tiada perbezaan, maka anda tidak boleh menggunakanNULL. (Tahukah anda? Dalam Oracle, rentetanNULLdanEmptyadalah sama !)
Jangan fikirNULLtidak memerlukan ruang, ia memerlukan ruang tambahan , dan apabila anda membuat perbandingan, program anda akan menjadi lebih kompleks. Sudah tentu, ini tidak bermakna anda tidak boleh menggunakanNULLRealitinya sangat rumit, dan masih terdapat situasi di mana anda perlu menggunakan nilai NULL.
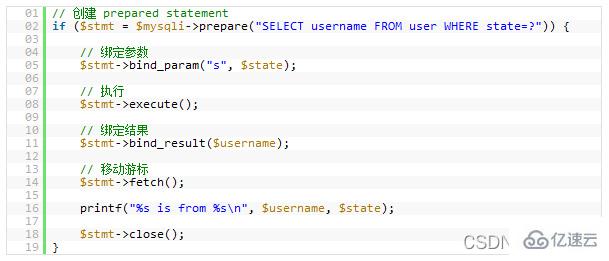
Prepared Statementsadalah seperti prosedur tersimpan Ia adalah koleksi pernyataan SQL yang berjalan di latar belakang menggunakanprepared statementsFaedah, sama ada isu prestasi atau isu keselamatan .Prepared StatementsAnda boleh menyemak beberapa pembolehubah yang telah anda terikat, yang boleh melindungi program anda daripada serangan "SQL injection". Sudah tentu, anda juga boleh menyemak pembolehubah anda secara manual Walau bagaimanapun, semakan manual terdedah kepada masalah dan sering dilupakan oleh pengaturcara. Masalah ini akan menjadi lebih baik apabila kita menggunakan beberapaframeworkatauORM.
Dari segi prestasi, apabila pertanyaan yang sama digunakan beberapa kali, ini akan membawa anda kelebihan prestasi yang besar. Anda boleh menentukan beberapa parameter untukPrepared Statementsini dan MySQL hanya akan menghuraikannya sekali.
Walaupun versi terkini MySQL menggunakanPrepared Statementsbentuk binari semasa menghantar , jadi ini akan menjadikan penghantaran rangkaian sangat cekap.
Sudah tentu, terdapat beberapa kes di mana kita perlu mengelak daripada menggunakanPrepared Statementskerana ia tidak menyokong caching pertanyaan. Tetapi ia dikatakan akan disokong selepas versi 5.1.
Untuk menggunakan pernyataan yang disediakan dalam PHP, anda boleh menyemak manualnya: sambungan mysql atau gunakan lapisan abstraksi pangkalan data, seperti: PDO.
Dalam keadaan biasa, apabila anda melaksanakan pernyataan SQL dalam skrip anda, program anda akan berhenti di sana sehingga pernyataan SQL dikembalikan Kemudian program anda terus dilaksanakan. Anda boleh menggunakan pertanyaan tidak buffer untuk menukar tingkah laku ini.
mysql_unbuffered_query()menghantar pernyataan SQL ke MySQL dan bukannyamysql_query()secara automatik dan menyimpan hasil carian sepertifethchlakukan. Ini akan menjimatkan banyak memori, terutamanya untuk pertanyaan yang menjana sejumlah besar hasil, dan anda tidak perlu menunggu sehingga semua keputusan dikembalikan Anda hanya perlu mengembalikan baris pertama data dan anda boleh mula bekerja serta-merta.
Walau bagaimanapun, ini disertakan dengan beberapa had. Kerana anda sama ada perlu membaca semua baris, atau anda perlu memanggilmysql_free_result()untuk mengosongkan keputusan sebelum pertanyaan seterusnya. Selain itu,mysql_num_rows()或 mysql_data_seek()tidak akan tersedia. Oleh itu, anda perlu mempertimbangkan dengan teliti sama ada hendak menggunakan pertanyaan tidak buffer.
Ramai pengaturcara akan mencipta medan
VARCHAR(15)untuk menyimpan IP dalam bentuk rentetan dan bukannya IP integer. Jika anda menggunakan integer untuk menyimpannya, ia hanya mengambil masa 4 bait dan anda boleh mempunyai medan panjang tetap. Selain itu, ini akan membawa anda kelebihan pertanyaan, terutamanya apabila anda perlu menggunakanWHEREkeadaan seperti ini:IP between ip1 and ip2.
Kita mesti menggunakanUNSIGNED INT, kerana alamat IP menggunakan keseluruhan integer tidak bertanda 32-bit.
Untuk pertanyaan anda, anda boleh menggunakanINET_ATON()untuk menukar IP rentetan kepada integer dan gunakanINET_NTOA()untuk menukar integer kepada IP rentetan. Dalam PHP, terdapat juga fungsi sedemikianip2long() 和 long2ip().
Jika semua medan dalam jadual adalah "panjang tetap", keseluruhan jadual akan dianggap "
static" atau "fixed-length". Sebagai contoh, tiada medan jenis berikut dalam jadual:VARCHAR,TEXT. Selagi anda memasukkan salah satu medan ini, jadual itu bukan lagi "jadual statik panjang tetap" dan enjin MySQL akan memprosesnya dengan cara lain.
Jadual panjang tetap akan meningkatkan prestasi kerana MySQL akan mencari dengan lebih pantas Kerana panjang tetap ini memudahkan pengiraan mengimbangi data seterusnya, pembacaan secara semula jadi akan menjadi lebih pantas. Dan jika medan itu bukan panjang tetap, maka setiap kali anda ingin mencari yang seterusnya, program perlu mencari kunci utama.
Selain itu, jadual panjang tetap lebih mudah untuk dicache dan dibina semula. Walau bagaimanapun, satu-satunya kesan sampingan ialah medan panjang tetap akan membazirkan sedikit ruang , kerana medan panjang tetap akan memperuntukkan begitu banyak ruang sama ada anda menggunakannya atau tidak.
Menggunakan teknologi "vertical split" (lihat item seterusnya), anda boleh membahagikan jadual anda kepada dua, satu dengan panjang tetap dan satu dengan panjang berubah daripada.
"Pecahan menegak" ialah kaedah menukar jadual dalam pangkalan data kepada beberapa jadual mengikut lajur, yang boleh mengurangkan kerumitan dan medan nombor jadual , supaya mencapai tujuan pengoptimuman. (Saya pernah membuat projek di bank dan melihat jadual dengan lebih daripada 100 medan, yang menakutkan)
Contoh 1: Terdapat medan dalam jadual Pengguna iaitu alamat rumah . Ini Medan adalah medan pilihan, sebagai perbandingan, dan kecuali untuk maklumat peribadi apabila anda beroperasi dalam pangkalan data, anda tidak perlu membaca atau menulis semula medan ini dengan kerap. Jadi, mengapa tidak meletakkannya dalam jadual lain? Ini akan menjadikan jadual anda mempunyai prestasi yang lebih baik, sering kali, untuk jadual pengguna, saya hanya mempunyai ID pengguna, nama pengguna dan kata laluan. dan lain-lain akan digunakan dengan kerap. Jam tangan yang lebih kecil akan sentiasa mempunyai prestasi yang lebih baik
.
Contoh 2: Anda mempunyai medan yang dipanggil "last_login" yang akan dikemas kini setiap kali pengguna log masuk. Walau bagaimanapun, setiap kemas kini akan menyebabkan cache pertanyaan jadual dikosongkan. Oleh itu, anda boleh meletakkan medan ini dalam jadual lain, supaya ia tidak menjejaskan pembacaan berterusan ID pengguna, nama pengguna dan peranan pengguna anda, kerana cache pertanyaan akan membantu anda meningkatkan banyak prestasi.
Selain itu, anda perlu memberi perhatian kepada fakta bahawa anda tidak akan kerap menyertai jadual yang dibentuk oleh medan yang dipisahkan ini, jika tidak, prestasi akan menjadi lebih teruk daripada tanpa pemisahan ia akan turun secara eksponen
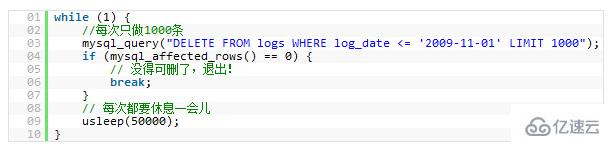
Jika anda perlu melaksanakan penyataan besar pada tapak web dalam talian
DELETEatauINSERTpertanyaan, anda. perlu berhati-hati untuk mengelakkan operasi anda menyebabkan seluruh tapak web anda berhenti bertindak balas. Kerana kedua-dua operasi ini akan mengunci jadual, setelah jadual dikunci, tiada operasi lain boleh masuk.
Apache akan mempunyai banyak proses atau utas anak. Oleh itu, ia berfungsi dengan agak cekap, dan pelayan kami tidak mahu mempunyai terlalu banyak proses kanak-kanak, utas dan pautan pangkalan data Ini memerlukan banyak sumber pelayan, terutamanya memori.
Jika anda mengunci jadual anda untuk satu tempoh masa, seperti 30 saat, maka untuk tapak dengan volum trafik yang tinggi, bilangan proses/benang akses, pautan pangkalan data dan fail terbuka yang terkumpul dalam 30 saat ini, ia mungkin bukan sahaja menghentikan perkhidmatan WEB andaCrash, tetapi juga boleh menyebabkan seluruh pelayan anda ditutup serta-merta.
Jadi, jika anda mempunyai proses yang besar dan anda pasti akan membahagikannya, menggunakanLIMITsyarat adalah cara yang baik untuk melakukannya. Berikut ialah contoh:
Bagi kebanyakan enjin pangkalan data, operasi cakera keras mungkin adalah. kesesakan yang paling ketara. Jadi, menjadikan data anda padat boleh sangat membantu dalam situasi ini kerana ia mengurangkan akses kepada cakera keras.
Lihat dokumentasi MySQLStorage Requirementsuntuk melihat semua jenis data.
Jika jadual hanya mempunyai beberapa lajur (seperti jadual kamus, jadual konfigurasi), maka kami tidak mempunyai sebab untuk menggunakanINTsebagai kunci utama Ia akan menjadi lebih menjimatkan untuk menggunakanMEDIUMINT, SMALLINTatau TINYINT yang lebih kecil . Jika anda tidak perlu menjejaki masa, lebih baik menggunakanDATEdaripadaDATETIME.
Sudah tentu, anda juga perlu meninggalkan ruang yang cukup untuk pengembangan Jika tidak, jika anda melakukan ini pada masa hadapan, anda akan mati dengan buruk. LihatSlashdotuntuk contoh (6 November 2009),ALTER TABLEyang mudah. 🎜> Kenyataan itu mengambil masa lebih 3 jam kerana terdapat 16 juta keping data di dalamnya.
Terdapat dua enjin storan dalam MySQL, MyISAM dan InnoDB, dan setiap enjin mempunyai kebaikan dan keburukan. Artikel Cool Shell sebelum ini "MySQL: InnoDB atau MyISAM membincangkan perkara ini?"
MyISAM sesuai untuk sesetengah aplikasi yang memerlukan bilangan pertanyaan yang banyak, tetapi ia tidak begitu baik untuk operasi tulis yang banyak. Walaupun anda hanya perlu mengemas kini medan, keseluruhan jadual akan dikunci dan proses lain, malah proses membaca, tidak boleh beroperasi sehingga operasi membaca selesai. Selain itu, MyISAM sangat pantas untuk pengiraan sepertiSELECT COUNT(*).
Trend InnoDB akan menjadi enjin storan yang sangat kompleks Untuk beberapa aplikasi kecil, ia akan menjadi lebih perlahan daripadaMyISAM. Sebab lain ialah ia menyokong "penguncian baris", jadi ia akan menjadi lebih baik apabila terdapat lebih banyak operasi tulis. Selain itu, ia juga menyokong aplikasi yang lebih maju, seperti transaksi.
Menggunakan ORM (
Object Relational Mapper), anda boleh mendapatkan keuntungan prestasi yang boleh dipercayai. Semua yang boleh dilakukan oleh ORM juga boleh ditulis secara manual. Walau bagaimanapun, ini memerlukan pakar peringkat tinggi.
Perkara yang paling penting tentang ORM ialah "Lazy Loading", iaitu, ia hanya akan melakukannya apabila perlu untuk mendapatkan nilai. Tetapi anda juga perlu berhati-hati tentang kesan sampingan mekanisme ini, kerana ia berkemungkinan mengurangkan prestasi dengan mencipta banyak, banyak pertanyaan kecil.
ORM juga boleh membungkus penyata SQL anda ke dalam transaksi, yang jauh lebih pantas daripada melaksanakannya secara individu.
Pada masa ini, PHP ORM kegemaran peribadi saya ialah:Doctrine
Tujuan "pautan kekal" ialah. untuk digunakan Untuk mengurangkan bilangan penciptaan semula sambungan MySQL. Apabila pautan dibuat, ia kekal bersambung selama-lamanya, walaupun selepas operasi pangkalan data telah tamat. Selain itu, sejak Apache kami mula menggunakan semula proses anak - iaitu, permintaan HTTP seterusnya akan menggunakan semula proses anak Apache dan menggunakan semula sambungan MySQL yang sama.
Secara teori, ini kedengaran hebat. Tetapi dari pengalaman peribadi (dan kebanyakan orang), ciri ini menimbulkan lebih banyak masalah. Kerana, anda hanya mempunyai bilangan pautan yang terhad, isu memori, pemegang fail, dsb.
Selain itu, Apache berjalan dalam persekitaran yang sangat selari dan akan mencipta banyak proses. Inilah sebabnya mekanisme "pautan kekal" ini tidak berfungsi dengan baik. Sebelum anda membuat keputusan untuk menggunakan "pautan kekal", anda perlu berhati-hati mempertimbangkan seni bina keseluruhan sistem anda
Apabila membuat pertanyaan, lajur indeks tidak boleh menjadi sebahagian daripada ungkapan atau parameter fungsi, jika tidak, indeks tidak boleh digunakan.
Sebagai contoh, pertanyaan berikut tidak boleh menggunakan indeks lajur actor_id:
#这是错误的SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5;
Kaedah pengoptimuman: Ungkapan dan operasi fungsi boleh dialihkan ke sebelah kanan tanda sama. Seperti berikut:
SELECT actor_id FROM sakila.actor WHERE actor_id = 5 - 1;
Apabila berbilang lajur perlu digunakan sebagai syarat untuk pertanyaan, menggunakan indeks berbilang lajur mempunyai prestasi yang lebih baik daripada menggunakan berbilang indeks lajur tunggal.
Sebagai contoh, dalam penyataan berikut, sebaiknya tetapkan actor_id dan film_id sebagai indeks berbilang lajur. Yuanfudao ada soalan, lihat pautan untuk butiran, yang boleh membantu anda memahami dengan lebih mendalam.
SELECT film_id, actor_ id FROM sakila.film_actorWHERE actor_id = 1 AND film_id = 1;
Biar lajur indeks yang paling terpilih diletakkan dahulu.
Selektiviti indeks merujuk kepada nisbah nilai indeks unik kepada jumlah rekod. Nilai maksimum ialah 1, di mana setiap rekod mempunyai indeks unik yang sepadan dengannya. Semakin tinggi selektiviti, semakin tinggi diskriminasi setiap rekod dan semakin tinggi kecekapan pertanyaan.
Sebagai contoh, dalam hasil yang ditunjukkan di bawah, customer_id lebih selektif daripada staff_id, jadi sebaiknya letakkan lajur customer_id di hadapan indeks berbilang lajur.
SELECT COUNT(DISTINCT staff_id)/COUNT(*) AS staff_id_selectivity, COUNT(DISTINCT customer_id)/COUNT(*) AS customer_id_selectivity, COUNT(*) FROM payment; #结果如下 staff_id_selectivity: 0.0001 customer_id_selectivity: 0.0373 COUNT(*): 16049
Untuk lajur jenis BLOB、TEXT 和 VARCHAR, indeks awalan mesti digunakan untuk mengindeks aksara permulaan sahaja.
Pemilihan panjang awalan perlu ditentukan berdasarkan pemilihan indeks.
Indeks mengandungi nilai semua medan yang perlu disoal. Ia mempunyai kelebihan berikut:
1 Indeks biasanya jauh lebih kecil daripada saiz baris data dengan membaca hanya indeks boleh mengurangkan jumlah akses data.
2. Sesetengah enjin storan (seperti MyISAM) hanya mengindeks cache dalam memori, dan data bergantung pada sistem pengendalian untuk cache. Oleh itu, mengakses hanya indeks menghapuskan keperluan untuk panggilan sistem (yang selalunya memakan masa).
3. Untuk enjin InnoDB, jika indeks sekunder boleh menampung pertanyaan, tidak perlu mengakses indeks utama.
mysql meletakkan % di belakang apabila menggunakan suka untuk pertanyaan kabur untuk mengelakkan pertanyaan kabur pada permulaan.
Kerana MySQL akan menggunakan indeks hanya apabila menggunakan % berikut apabila menggunakan pertanyaan suka.
Contohnya: ‘%ptd_’ dan ‘%ptd_%’ tidak menggunakan indeks manakala ‘ptd_%’ menggunakan indeks.
#进行全表查询,没有用到索引 EXPLAIN SELECT * FROM `user` WHERE username LIKE '%ptd_%'; EXPLAIN SELECT * FROM `user` WHERE username LIKE '%ptd_'; #有用到索引 EXPLAIN SELECT * FROM `user` WHERE username LIKE 'ptd_%';
Contoh lain: pertanyaan yang biasa digunakan untuk semua orang bernama Zhang dalam pangkalan data:
SELECT * FROM `user` WHERE username LIKE '张%';
比如:
SELECT * FROM t WHERE id IN (2,3)SELECT * FROM t1 WHERE username IN (SELECT username FROM t2)
优化方式:如果是连续数值,可以用between代替。如下:
SELECT * FROM t WHERE id BETWEEN 2 AND 3
如果是子查询,可以用exists代替。如下:
SELECT * FROM t1 WHERE EXISTS (SELECT * FROM t2 WHERE t1.username = t2.username)
如:
SELECT * FROM t WHERE id = 1 OR id = 3
优化方式:可以用union代替or。如下:
SELECT * FROM t WHERE id = 1UNIONSELECT * FROM t WHERE id = 3
SELECT * FROM t WHERE score IS NULL
优化方式:可以给字段添加默认值0,对0值进行判断。如下:
SELECT * FROM t WHERE score = 0
同第1个,单独的列;
SELECT * FROM t2 WHERE score/10 = 9SELECT * FROM t2 WHERE SUBSTR(username,1,2) = 'li'
优化方式:可以将表达式、函数操作移动到等号右侧。如下:
SELECT * FROM t2 WHERE score = 10*9SELECT * FROM t2 WHERE username LIKE 'li%'
SELECT * FROM t WHERE 1=1
优化方式:用代码拼装sql时进行判断,没where加where,有where加and。
索引的好处:建立索引后,查询时不会扫描全表,而会查询索引表锁定结果。索引的缺点:在数据库进行DML操作的时候,除了维护数据表之外,还需要维护索引表,运维成本增加。应用场景:数据量比较大,查询字段较多的情况。
索引规则:
1.选用选择性高的字段作为索引,一般unique的选择性最高;
2.复合索引:选择性越高的排在越前面。(左前缀原则);
3.如果查询条件中两个条件都是选择性高的,最好都建索引;
Explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explain 结果来优化查询语句。
比较重要的字段有:
select_type: 查询类型,有简单查询、联合查询、子查询等;key: 使用的索引;rows: 扫描的行数;
1.减少请求的数据量
只返回必要的列:最好不要使用
SELECT *语句。
只返回必要的行:使用LIMIT语句来限制返回的数据。
缓存重复查询的数据:使用缓存可以避免在数据库中进行查询,特别在要查询的数据经常被重复查询时,缓存带来的查询性能提升将会是非常明显的。
2.减少服务器端扫描的行数
最有效的方式是使用索引来覆盖查询。
1.切分大查询
一个大查询如果一次性执行的话,可能一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。
2.分解大连接查询
将一个大连接查询分解成对每一个表进行一次单表查询,然后在应用程序中进行关联,这样做的好处有:
让缓存更高效:对于连接查询,如果其中一个表发生变化,那么整个查询缓存就无法使用。而分解后的多个查询,即使其中一个表发生变化,对其它表的查询缓存依然可以使用。
分解成多个单表查询,这些单表查询的缓存结果更可能被其它查询使用到,从而减少冗余记录的查询。
减少锁竞争;
在应用层进行连接,可以更容易对数据库进行拆分,从而更容易做到高性能和可伸缩。
查询本身效率也可能会有所提升。例如下面的例子中,使用 IN() 代替连接查询,可以让 MySQL 按照 ID 顺序进行查询,这可能比随机的连接要更高效。
SELECT * FROM tab JOIN tag_post ON tag_post.tag_id=tag.id JOIN post ON tag_post.post_id=post.id WHERE tag.tag='mysql'; SELECT * FROM tag WHERE tag='mysql'; SELECT * FROM tag_post WHERE tag_id=1234; SELECT * FROM post WHERE post.id IN (123,456,567,9098,8904);
通过对查询语句的分析,可以了解查询语句执行的情况,找出查询语句执行的瓶颈,从而优化查询语句。mysql中提供了EXPLAIN语句和
DESCRIBE语句,用来分析查询语句。EXPLAIN语句的基本语法如下:
EXPLAIN [EXTENDED] SELECT select_options;
使用EXTENED关键字,EXPLAIN语句将产生附加信息。select_options是select语句的查询选项,包括from where子句等等。
执行该语句,可以分析EXPLAIN后面的select语句的执行情况,并且能够分析出所查询的表的一些特征。
例如:EXPLAIN SELECT * FROM user;
查询结果进行解释说明:
a、id:select识别符,这是select的查询序列号。
b、select_type:标识select语句的类型。
它可以是以下几种取值:
b1、SIMPLE(simple)表示简单查询,其中不包括连接查询和子查询。
b2、PRIMARY(primary)表示主查询,或者是最外层的查询语句。
b3、UNION(union)表示连接查询的第2个或者后面的查询语句。
b4、DEPENDENT UNION(dependent union)连接查询中的第2个或者后面的select语句。取决于外面的查询。
b5、UNION RESULT(union result)连接查询的结果。
b6、SUBQUERY(subquery)子查询的第1个select语句。
b7、DEPENDENT SUBQUERY(dependent subquery)子查询的第1个select,取决于外面的查询。
b8、DERIVED(derived)导出表的SELECT(FROM子句的子查询)。
c、table:表示查询的表。
d、type:表示表的连接类型。
下面按照从最佳类型到最差类型的顺序给出各种连接类型。
d1、system,该表是仅有一行的系统表。这是const连接类型的一个特例。
d2、const,数据表最多只有一个匹配行,它将在查询开始时被读取,并在余下的查询优化中作为常量对待。const表查询速度很快,因为它们只读一次。const用于使用常数值比较primary key或者unique索引的所有部分的场合。
例如:EXPLAIN SELECT * FROM user WHERE id=1;
d3、eq_ref,对于每个来自前面的表的行组合,从该表中读取一行。当一个索引的所有部分都在查询中使用并且索引是UNIQUE或者PRIMARY KEY时候,即可使用这种类型。eq_ref可以用于使用“=”操作符比较带索引的列。比较值可以为常量或者一个在该表前面所读取的表的列的表达式。
例如:EXPLAIN SELECT * FROM user,db_company WHERE user.company_id = db_company.id;
d4、ref对于来自前面的表的任意行组合,将从该表中读取所有匹配的行。这种类型用于所以既不是UNION也不是primaey key的情况,或者查询中使用了索引列的左子集,即索引中左边的部分组合。ref可以用于使用=或者操作符的带索引的列。
d5、ref_or_null,该连接类型如果ref,但是如果添加了mysql可以专门搜索包含null值的行,在解决子查询中经常使用该连接类型的优化。
d6、index_merge,该连接类型表示使用了索引合并优化方法。在这种情况下,key列包含了使用的索引的清单,key_len包含了使用的索引的最长的关键元素。
d7、unique_subquery,该类型替换了下面形式的in子查询的ref。是一个索引查询函数,可以完全替代子查询,效率更高。
d8、index_subquery,该连接类型类似于unique_subquery,可以替换in子查询,但是只适合下列形式的子查询中非唯一索引。
d9、range,只检索给定范围的行,使用一个索引来选择行。key列显示使用了那个索引。key_len包含所使用索引的最长关键元素。当使用=,,>,>=,,between或者in操作符,用常量比较关键字列时,类型为range。
d10、index,该连接类型与all相同,除了只扫描索引树。着通常比all快,引文索引问价通常比数据文件小。
d11、all,对于前面的表的任意行组合,进行完整的表扫描。如果表是第一个没有标记const的表,这样不好,并且在其他情况下很差。通常可以增加更多的索引来避免使用all连接。
e、possible_keys:possible_keys列指出mysql能使用那个索引在该表中找到行。如果该列是null,则没有相关的索引。在这种情况下,可以通过检查where子句看它是否引起某些列或者适合索引的列来提高查询性能。如果是这样,可以创建适合的索引来提高查询的性能。
f.key: Menunjukkan indeks yang sebenarnya digunakan dalam pertanyaan Jika tiada indeks dipilih, nilai lajur ini adalah batal Untuk memaksa mysql menggunakan atau mengabaikan indeks dalam lajur possible_key, gunakanforce index、use index或者ignore indexdalam pertanyaan. .
g,key_len: Menunjukkan panjang medan indeks pilihan MySQL yang dikira dalam bait Jika kuncinya nol, panjangnya adalah null. Ambil perhatian bahawa nilai key_len menentukan bilangan medan dalam indeks berbilang lajur mysql sebenarnya akan digunakan.
h,ref: Menunjukkan lajur, pemalar atau indeks yang hendak digunakan untuk menanyakan rekod.
i,rows: Memaparkan bilangan baris yang MySQL mesti semak semasa membuat pertanyaan dalam jadual.
j,Extra: Maklumat terperinci lajur ini apabila mysql memproses pertanyaan.
Atas ialah kandungan terperinci Apakah teknik pengoptimuman untuk pangkalan data mysql?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



