
 Peranti teknologi
AI
Saingan Midjourney ada di sini! 'Master Penyesuaian' Google StyleDrop meletupkan bulatan seni AI
Peranti teknologi
AI
Saingan Midjourney ada di sini! 'Master Penyesuaian' Google StyleDrop meletupkan bulatan seni AI
Saingan Midjourney ada di sini! 'Master Penyesuaian' Google StyleDrop meletupkan bulatan seni AI

Sebaik sahaja Google StyleDrop keluar, ia serta-merta melanda internet.
Memandangkan Malam Berbintang Van Gogh, AI menjadi pakar Van Gogh Selepas pemahaman peringkat atasan tentang gaya abstrak ini, ia boleh mencipta lukisan yang tidak terkira banyaknya.

Satu lagi gaya kartun, objek yang saya nak lukis jauh lebih comel.

Malah, ia boleh mengawal butiran dengan tepat dan mereka bentuk logo gaya asli.

Pesona StyleDrop ialah anda hanya memerlukan satu gambar sebagai rujukan, tidak kira betapa rumitnya gaya artistik itu, anda boleh menyahkonstruk dan mencipta semula ia.
Netizen menyatakan bahawa ini adalah satu lagi alat AI yang menghapuskan pereka.
Penyelidikan letupan StyleDrop ialah produk terbaharu daripada pasukan penyelidik Google.

Alamat kertas: https://arxiv.org/pdf/2306.00983.pdf
Kini, dengan alatan seperti StyleDrop, anda bukan sahaja boleh melukis dengan lebih kawalan, tetapi anda juga boleh menyelesaikan kerja halus yang tidak dapat dibayangkan sebelum ini, seperti melukis logo.
Malah saintis NVIDIA menggelarnya sebagai pencapaian "penomenal".

"Penyesuaian" induk
Pengarang kertas itu memperkenalkan bahawa inspirasi untuk StyleDrop datang daripada Penitis mata (penyerapan warna) /alat pemetik warna).
Begitu juga, StyleDrop juga berharap semua orang boleh dengan cepat dan mudah "memilih" gaya daripada satu/beberapa imej rujukan untuk menjana imej gaya itu.

Seorang sloth boleh mempunyai 18 gaya:

Panda mempunyai 24 gaya:

Lukisan cat air yang dilukis oleh kanak-kanak dikawal dengan sempurna oleh StyleDrop, malah kertas Lipatan mempunyai telah dipulihkan.
Saya perlu katakan, ia terlalu kuat.

Terdapat juga StyleDrop yang merujuk kepada reka bentuk huruf Inggeris dalam gaya yang berbeza:

Ia juga huruf gaya Van Gogh.

Terdapat juga lukisan garisan. Lukisan garisan adalah imej yang sangat abstrak dan memerlukan rasional yang sangat tinggi dalam gubahan gambar.

Sapuan bayang keju dalam gambar asal dipulihkan kepada objek dalam setiap gambar.

Rujuk penciptaan LOGO Android.

Di samping itu, para penyelidik juga memperluaskan keupayaan StyleDrop, bukan sahaja untuk menyesuaikan gaya, digabungkan dengan DreamBooth, tetapi juga untuk menyesuaikan kandungan .
Sebagai contoh, masih dalam gaya Van Gogh, hasilkan lukisan gaya yang serupa untuk Corgi kecil:
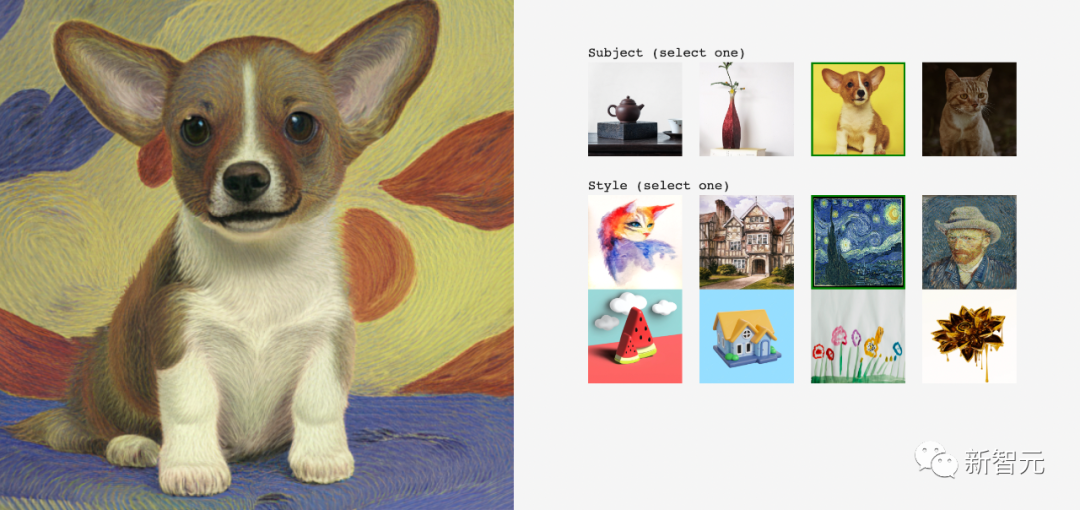
Ini satu lagi, Corgi di bawah terasa seperti "Sphinx" pada piramid Mesir.

Bagaimanakah ia berfungsi?
StyleDrop dibina pada Muse dan terdiri daripada dua bahagian penting:
Salah satunya ialah penalaan halus yang berkesan bagi parameter Transformer visual yang dihasilkan, dan yang lain ialah lelaran dengan kereta api maklum balas.
Kemudian, penyelidik mensintesis imej daripada dua model yang diperhalusi.
Muse ialah model sintesis teks-ke-imej terbaharu berdasarkan Transformer imej yang dijana topeng. Ia mengandungi dua modul sintesis untuk penjanaan imej asas (256 × 256) dan resolusi super (512 × 512 atau 1024 × 1024).

Setiap modul terdiri daripada pengekod teks T, pengubah G, pensampel S dan pengekod imej Ia terdiri daripada penyahkod E dan penyahkod D.
T memetakan gesaan teks t∈T ke ruang benam berterusan E. G memproses pembenaman teks e ∈ E untuk menjana logaritma jujukan token visual l ∈ L. S mengekstrak jujukan token visual v ∈ V daripada logaritma melalui penyahkodan berulang yang menjalankan beberapa langkah inferens pengubah yang dikondisikan pada pembenaman teks e dan token visual dinyahkod daripada langkah sebelumnya.
Akhir sekali, D memetakan jujukan token diskret ke ruang piksel I. Secara ringkasnya, diberi teks gesaan t, komposisi imej I adalah seperti berikut:
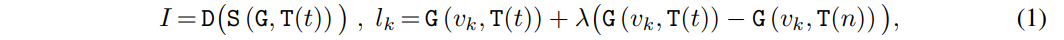
Rajah 2 ialah seni bina lapisan pengubah Muse yang dipermudahkan, yang telah diubah suai sebahagiannya untuk menyokong Penalaan Halus Cekap Parameter (PEFT) dan penyesuai.
Gunakan pengubah lapisan L untuk memproses jujukan token visual yang dipaparkan dalam warna hijau di bawah keadaan pembenaman teks e. Parameter yang dipelajari θ digunakan untuk membina pemberat untuk penalaan penyesuai.

Untuk melatih θ, dalam banyak kes, penyelidik hanya boleh memberikan gambar sebagai rujukan gaya.
Penyelidik perlu melampirkan gesaan teks secara manual. Mereka mencadangkan pendekatan ringkas dan bertemplat untuk membina gesaan teks yang terdiri daripada penerangan kandungan diikuti dengan frasa gaya perihalan.
Sebagai contoh, penyelidik menggunakan "kucing" untuk menerangkan objek dalam Jadual 1 dan menambahkan "lukisan cat air" sebagai penerangan gaya.

Memasukkan penerangan kandungan dan gaya dalam gesaan teks adalah penting kerana ia membantu memisahkan kandungan daripada gaya, iaitu penyelidikan Matlamat utama kakitangan.
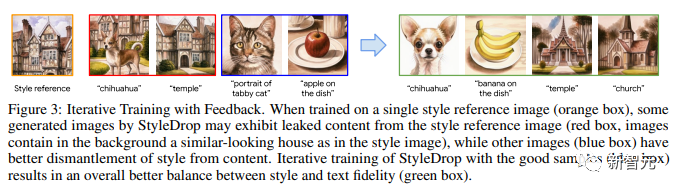
Rajah 3 menunjukkan latihan berulang dengan maklum balas.
Apabila latihan pada imej rujukan gaya tunggal (kotak oren), sesetengah imej yang dijana oleh StyleDrop mungkin mempamerkan kandungan yang diekstrak daripada imej rujukan gaya (kotak merah, imej Latar belakang mengandungi rumah yang serupa kepada imej gaya).
Imej lain (kotak biru) lebih baik memisahkan gaya daripada kandungan. Latihan berulang StyleDrop pada sampel yang baik (kotak biru) menghasilkan keseimbangan yang lebih baik antara gaya dan kesetiaan teks (kotak hijau).
Di sini penyelidik juga menggunakan dua kaedah:
-Score CLIP
Kaedah ini digunakan untuk mengukur penjajaran imej dan teks. Oleh itu, ia boleh menilai kualiti imej yang dijana dengan mengukur skor CLIP (iaitu, persamaan kosinus pembenaman CLIP visual dan tekstual).
Penyelidik boleh memilih imej CLIP dengan markah tertinggi. Mereka memanggil kaedah ini CLIP-feedback iterative training (CF).
Dalam eksperimen, penyelidik mendapati bahawa menggunakan skor CLIP untuk menilai kualiti imej sintetik ialah cara yang berkesan untuk meningkatkan ingatan semula (iaitu, kesetiaan teks) tanpa kehilangan kesetiaan Gaya yang berlebihan.
Walau bagaimanapun, skor CLIP mungkin tidak sejajar sepenuhnya dengan niat manusia, atau menangkap atribut gaya halus.
-HF
Maklum balas manusia (HF) ialah kaedah yang menyuntik niat pengguna terus ke dalam penilaian kualiti imej sintetik dengan cara yang lebih langsung.
Dalam penalaan halus LLM untuk pembelajaran pengukuhan, HF telah membuktikan kuasa dan keberkesanannya.
HF boleh digunakan untuk mengimbangi ketidakupayaan skor CLIP untuk menangkap atribut gaya halus.
Pada masa ini, sejumlah besar penyelidikan telah memfokuskan pada masalah pemperibadian model penyebaran teks ke imej untuk mensintesis imej yang mengandungi berbilang gaya peribadi.
Penyelidik menunjukkan cara DreamBooth dan StyleDrop boleh digabungkan dengan cara yang mudah untuk memperibadikan kedua-dua gaya dan kandungan.
Ini dilakukan dengan mengambil sampel daripada dua taburan generatif yang diubah suai, dipandu oleh θs untuk gaya dan θc untuk kandungan, secara bebas pada gaya dan imej rujukan kandungan masing-masing Parameter penyesuai terlatih.
Tidak seperti produk sedia ada, pendekatan pasukan tidak memerlukan latihan bersama parameter yang boleh dipelajari pada pelbagai konsep, yang membawa kepada keupayaan gabungan yang lebih besar, Kerana penyesuai pra-latihan dilatih pada topik dan gaya individu secara berasingan.
Proses pensampelan keseluruhan penyelidik mengikuti penyahkodan berulang Persamaan (1), dengan cara pensampelan logaritma yang berbeza dalam setiap langkah penyahkodan.
Biarkan t sebagai gesaan teks dan c sebagai gesaan teks tanpa deskriptor gaya Logaritma dikira dalam langkah k seperti berikut:
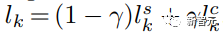
. 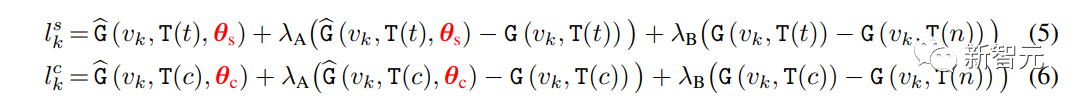
Di mana: γ digunakan untuk mengimbangi StyleDrop dan DreamBooth - jika γ ialah 0, kami mendapat StyleDrop, jika 1, kami mendapat DreamBooth.
Dengan menetapkan γ dengan sewajarnya, kita boleh mendapatkan imej yang sesuai.
Persediaan percubaan
Setakat ini, tiada Pelarasan gaya model generatif imej teks telah dikaji secara meluas.
Oleh itu, penyelidik mencadangkan rancangan eksperimen baharu:
-Pengumpulan data
The penyelidik mengumpul berpuluh-puluh gambar dalam gaya yang berbeza, daripada cat air dan lukisan minyak, ilustrasi rata, rendering 3D kepada arca daripada bahan yang berbeza.
-Konfigurasi Model
Penyelidik menggunakan penyesuai untuk menala StyleDrop berasaskan Muse. Untuk semua percubaan, pengoptimum Adam digunakan untuk mengemas kini berat penyesuai untuk 1000 langkah dengan kadar pembelajaran 0.00003. Melainkan dinyatakan sebaliknya, penyelidik menggunakan StyleDrop untuk mewakili model pusingan kedua, yang dilatih pada lebih daripada 10 imej sintetik dengan maklum balas manusia.
- Penilaian
Penilaian kuantitatif laporan penyelidikan berdasarkan CLIP, mengukur ketekalan gaya dan penjajaran teks. Selain itu, penyelidik menjalankan kajian keutamaan pengguna untuk menilai ketekalan gaya dan penjajaran teks.
Seperti yang ditunjukkan dalam rajah, hasil pemprosesan StyleDrop 18 gambar gaya berbeza dikumpul oleh penyelidik.
Seperti yang anda lihat, StyleDrop mampu menangkap nuansa tekstur, lorekan dan struktur pelbagai gaya, memberikan anda kawalan yang lebih baik terhadap gaya berbanding sebelum ini.

Sebagai perbandingan, penyelidik juga memperkenalkan hasil DreamBooth pada Imagen, DreamBooth's LoRA mengenai Hasil Resapan Stabil pelaksanaan dan penyongsangan tekstual.

Hasil khusus ditunjukkan dalam jadual, penjajaran imej-teks manusia (Teks) dan penjajaran gaya visual (Gaya ) Penunjuk penilaian skor (atas) dan skor CLIP (bawah).
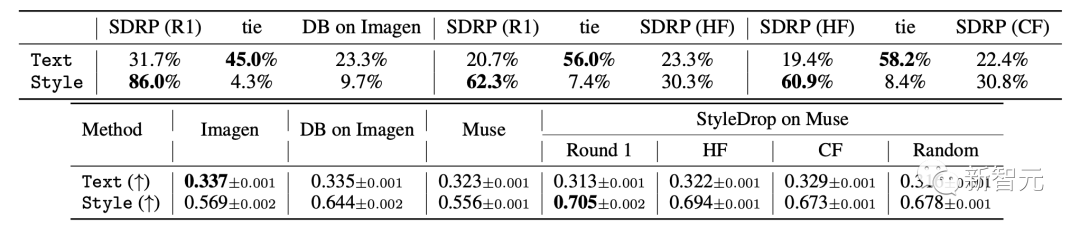
Perbandingan kualitatif bagi (a) DreamBooth, (b) StyleDrop dan (c) DreamBooth + StyleDrop:
Di sini, penyelidik menggunakan dua metrik skor CLIP yang dinyatakan di atas - skor teks dan gaya.
Untuk skor teks, penyelidik mengukur persamaan kosinus antara imej dan pembenaman teks. Untuk skor gaya, penyelidik mengukur persamaan kosinus antara rujukan gaya dan pembenaman imej sintetik.
Para penyelidik menjana sejumlah 1520 imej untuk 190 gesaan teks. Walaupun penyelidik berharap skor akhir akan lebih tinggi, metriknya tidak sempurna.
Sementara latihan berulang (IT) meningkatkan skor teks, yang selaras dengan matlamat penyelidik.
Walau bagaimanapun, sebagai pertukaran, markah gaya mereka pada model pusingan pertama dikurangkan kerana mereka dilatih pada imej sintetik dan gaya mungkin berat sebelah oleh pilih kasih.
DreamBooth pada Imagen adalah lebih rendah daripada StyleDrop dalam skor gaya (0.644 lwn. 0.694 untuk HF).
Para penyelidik mendapati bahawa peningkatan dalam skor gaya DreamBooth pada Imagen tidak jelas (0.569 → 0.644), manakala peningkatan StyleDrop pada Muse adalah lebih jelas (0.556 → 0.694).
Penyelidik menganalisis bahawa penalaan halus gaya pada Muse lebih berkesan berbanding Imagen.
Selain itu, untuk kawalan berbutir halus, StyleDrop menangkap perbezaan gaya yang halus, seperti offset warna, penggredan atau kawalan sudut tajam.
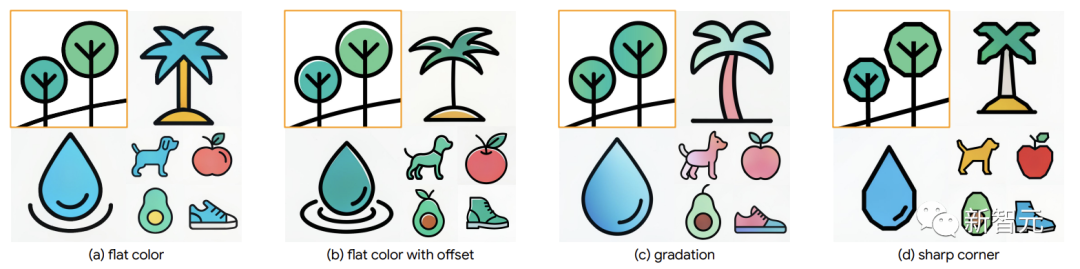
Komen hangat daripada netizen
Jika pereka mempunyai StyleDrop, kecekapan kerja 10x lebih pantas telah pun bermula .
Satu hari AI, 10 tahun kehidupan manusia, AIGC berkembang pada kelajuan cahaya, jenis kelajuan cahaya yang membutakan mata manusia!
Alat hanya mengikut trend, dan yang sepatutnya dihapuskan telah pun dihapuskan.
Alat ini lebih mudah digunakan berbanding Midjourney untuk membuat logo.
Atas ialah kandungan terperinci Saingan Midjourney ada di sini! 'Master Penyesuaian' Google StyleDrop meletupkan bulatan seni AI. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1677
1677
 14
1430
52
1333
25
1278
29
1257
24
14
1430
52
1333
25
1278
29
1257
24

 Tutorial mengenai cara mendaftar, menggunakan dan membatalkan akaun Ouyi OKEX
Mar 31, 2025 pm 04:21 PM
Tutorial mengenai cara mendaftar, menggunakan dan membatalkan akaun Ouyi OKEX
Mar 31, 2025 pm 04:21 PM
Artikel ini memperkenalkan secara terperinci pendaftaran, penggunaan dan prosedur pembatalan akaun Ouyi OKEX. Untuk mendaftar, anda perlu memuat turun aplikasinya, masukkan nombor telefon bimbit atau alamat e-mel anda untuk mendaftar, dan menyelesaikan pengesahan nama sebenar. Penggunaan meliputi langkah -langkah operasi seperti log masuk, cas semula dan pengeluaran, transaksi dan tetapan keselamatan. Untuk membatalkan akaun, anda perlu menghubungi perkhidmatan pelanggan Ouyi OKEX, memberikan maklumat yang diperlukan dan menunggu pemprosesan, dan akhirnya mendapatkan pengesahan pembatalan akaun. Melalui artikel ini, pengguna dengan mudah dapat menguasai pengurusan kitaran hayat lengkap akaun Ouyi Okex dan menjalankan urus niaga aset digital dengan selamat dan mudah.
 Bagaimana untuk mengoptimumkan segmentasi kata Jieba untuk meningkatkan kesan pengekstrakan kata kunci dari komen tempat yang indah?
Apr 01, 2025 pm 06:24 PM
Bagaimana untuk mengoptimumkan segmentasi kata Jieba untuk meningkatkan kesan pengekstrakan kata kunci dari komen tempat yang indah?
Apr 01, 2025 pm 06:24 PM
Bagaimana untuk mengoptimumkan segmentasi kata jieba untuk meningkatkan pengekstrakan kata kunci komen tempat yang indah? Semasa menggunakan segmentasi perkataan jieba untuk memproses data komen tempat yang indah, jika hasil segmentasi perkataan diabaikan ...
 Kemas kini terkini mengenai kedudukan mata wang maya tertua
Apr 22, 2025 am 07:18 AM
Kemas kini terkini mengenai kedudukan mata wang maya tertua
Apr 22, 2025 am 07:18 AM
Kedudukan mata wang maya '"tertua" adalah seperti berikut: 1. Bitcoin (BTC), yang dikeluarkan pada 3 Januari 2009, adalah mata wang digital yang terdesentralisasi pertama. 2. Litecoin (LTC), yang dikeluarkan pada 7 Oktober 2011, dikenali sebagai "versi ringan Bitcoin". 3. Ripple (XRP), yang dikeluarkan pada tahun 2011, direka untuk pembayaran rentas sempadan. 4. Dogecoin (Doge), yang dikeluarkan pada 6 Disember 2013, adalah "koin meme" berdasarkan kod Litecoin. 5. Ethereum (ETH), yang dikeluarkan pada 30 Julai 2015, adalah platform pertama untuk menyokong kontrak pintar. 6. Tether (USDT), yang dikeluarkan pada tahun 2014, adalah stablecoin pertama yang akan berlabuh ke dolar AS 1: 1. 7. Ada,
 Web IDE Directory Tree Indentation: Mengapa hasil rendering Google Chrome dan Firefox Browsers berbeza?
Apr 04, 2025 pm 10:15 PM
Web IDE Directory Tree Indentation: Mengapa hasil rendering Google Chrome dan Firefox Browsers berbeza?
Apr 04, 2025 pm 10:15 PM
Mengenai perbezaan rendering pokok direktori webide di bawah pelayar yang berbeza artikel ini akan meneroka nama semula web di Google Chrome dan Firefox ...
 Bagaimana menyelesaikan masalah navigator.mediadevices yang kembali tidak ditentukan dalam halaman http?
Apr 05, 2025 am 07:30 AM
Bagaimana menyelesaikan masalah navigator.mediadevices yang kembali tidak ditentukan dalam halaman http?
Apr 05, 2025 am 07:30 AM
Selepas H5 Pengendalian Masalah Pengendalian Media Pengambilan Media Semasa Menggunakan Aplikasi H5, kadang -kadang anda menghadapi masalah dengan pengambilalihan media halaman halaman, terutamanya apabila menggunakan navigator.medi ...
 Adakah Pengesahan Google dan Microsoft menyokong algoritma HOTP? Bagaimana menyelesaikan masalah yang tidak disokong?
Apr 02, 2025 pm 03:39 PM
Adakah Pengesahan Google dan Microsoft menyokong algoritma HOTP? Bagaimana menyelesaikan masalah yang tidak disokong?
Apr 02, 2025 pm 03:39 PM
Perbincangan sama ada Google dan Microsoft Authenticators menyokong algoritma HOTP Apabila menggunakan pengesahan dua faktor, kami sering menggunakan Google dan Microsoft ...
 Cara mengeluarkan wang tunai dari versi web OUYI
Mar 27, 2025 pm 05:03 PM
Cara mengeluarkan wang tunai dari versi web OUYI
Mar 27, 2025 pm 05:03 PM
Proses Pengeluaran Versi Web OUYI: Log masuk ke akaun, masukkan halaman aset, dan pilih mata wang dan kaedah pengeluaran (mata wang atau mata wang fiat). Pengeluaran semula rantaian mesti diisi dalam alamat pengeluaran yang betul dan rangkaian yang sepadan, dan pengeluaran mata wang fiat mesti terikat ke akaun bank. Hantar permohonan selepas menyelesaikan pengesahan keselamatan dan tunggu semakan tersebut tiba. Pastikan anda menyemak alamat, rangkaian dan maklumat lain, dan perhatikan yuran pengendalian dan jumlah pengeluaran minimum.
 Ringkasan Portal Muat turun Versi Sepuluh Apple untuk Aplikasi Pertukaran Mata Wang Digital
Apr 22, 2025 am 09:27 AM
Ringkasan Portal Muat turun Versi Sepuluh Apple untuk Aplikasi Pertukaran Mata Wang Digital
Apr 22, 2025 am 09:27 AM
Menyediakan pelbagai alat perdagangan kompleks dan analisis pasaran. Ia meliputi lebih daripada 100 negara, mempunyai jumlah dagangan derivatif harian purata lebih daripada AS $ 30 bilion, menyokong lebih daripada 300 pasangan dagangan dan 200 kali leverage, mempunyai kekuatan teknikal yang kuat, pangkalan pengguna global yang besar, menyediakan platform perdagangan profesional, penyelesaian penyimpanan yang selamat dan pasangan perdagangan yang kaya.
