
 Peranti teknologi
AI
Penyelidikan baharu daripada NeRF ada di sini: Adegan 3D dialih keluar tanpa kesan tanpa objek, tepat pada rambut
Peranti teknologi
AI
Penyelidikan baharu daripada NeRF ada di sini: Adegan 3D dialih keluar tanpa kesan tanpa objek, tepat pada rambut
Penyelidikan baharu daripada NeRF ada di sini: Adegan 3D dialih keluar tanpa kesan tanpa objek, tepat pada rambut

Medan Sinaran Neural (NeRF) telah menjadi kaedah sintesis pandangan baharu yang popular. Walaupun NeRF membuat generalisasi dengan pantas kepada rangkaian aplikasi dan set data yang lebih luas, penyuntingan terus senario pemodelan NeRF kekal sebagai cabaran besar. Tugas penting ialah mengalih keluar objek yang tidak diingini daripada pemandangan 3D dan mengekalkan konsistensi dengan pemandangan sekelilingnya, tugas ini dipanggil lukisan imej 3D. Dalam 3D, penyelesaian mesti konsisten merentas berbilang paparan dan sah dari segi geometri.
Dalam kertas kerja ini, penyelidik dari Samsung, University of Toronto dan institusi lain mencadangkan kaedah lukisan 3D baharu untuk menyelesaikan cabaran ini, memandangkan satu set imej pose yang kecil dan jarang dalam satu input imej Ambil perhatian bahawa rangka kerja model yang dicadangkan mula-mula cepat mendapatkan topeng segmentasi tiga dimensi objek sasaran dan menggunakan topeng, dan kemudian memperkenalkan kaedah berdasarkan pengoptimuman persepsi, yang menggunakan imej dua dimensi yang dipelajari untuk membaiki dan mengekstrak maklumat mereka. kepada ruang tiga dimensi sambil memastikan ketekalan paparan.
Penyelidikan ini juga membawa penanda aras baharu untuk menilai kaedah lukisan dalam adegan 3D dengan melatih set data adegan kehidupan sebenar yang mencabar. Khususnya, set data ini mengandungi paparan pemandangan yang sama dengan dan tanpa objek sasaran, membolehkan penanda aras lebih berprinsip bagi tugasan mengecat dalam ruang 3D.

- Alamat kertas: https://arxiv.org/pdf/2211.12254.pdf
- Halaman utama kertas: https://spinnerf3d.github.io/
Yang berikut adalah Kesan menunjukkan bahawa selepas mengalih keluar beberapa objek, ia masih boleh mengekalkan konsistensi dengan pemandangan sekelilingnya:

Perbandingan antara kaedah ini dan kaedah lain, lain-lain kaedah Terdapat artifak yang jelas, tetapi kaedah dalam artikel ini tidak begitu jelas:

Pengenalan kaedah
Pengarang menggunakan kaedah bersepadu Untuk menangani pelbagai cabaran dalam tugasan penyuntingan pemandangan 3D, kaedah ini memperoleh imej berbilang paparan adegan, menggunakan input pengguna untuk mengekstrak topeng 3D, dan menggunakan latihan NeRF untuk dimuatkan ke dalam imej topeng, supaya objek sasaran adalah munasabah rupa tiga dimensi dan bentuk geometri diganti. Kaedah pembahagian 2D interaktif sedia ada tidak mengambil kira aspek 3D, dan kaedah berasaskan NeRF semasa tidak dapat memperoleh hasil yang baik menggunakan anotasi yang jarang dan tidak mencapai ketepatan yang mencukupi. Walaupun beberapa algoritma berasaskan NeRF semasa membenarkan penyingkiran objek, mereka tidak cuba menyediakan bahagian ruang yang baru dijana. Mengikut kemajuan penyelidikan semasa, kerja ini adalah yang pertama mengendalikan segmentasi berbilang paparan interaktif secara serentak dan pemulihan imej 3D yang lengkap dalam satu rangka kerja.
Penyelidik menggunakan model bebas 3D yang luar biasa untuk pembahagian dan pemulihan imej serta memindahkan output mereka ke ruang 3D dengan cara yang konsisten paparan. Membina kerja pada segmentasi interaktif 2D, model yang dicadangkan bermula daripada sebilangan kecil titik imej yang ditentukur pengguna dengan tetikus pada objek sasaran. Daripada ini, algoritma mereka memulakan topeng dengan model berasaskan video dan melatihnya menjadi pembahagian 3D yang koheren dengan memasang NeRF topeng semantik. Kemudian, pemulihan imej 2D yang telah terlatih digunakan pada set imej berbilang paparan Proses pemasangan NeRF digunakan untuk membina semula pemandangan imej 3D, menggunakan kehilangan persepsi untuk mengekang ketidakkonsistenan imej 2D, dan geometri yang dinormalkan. topeng kawasan imej kedalaman. Secara keseluruhan, kami menyediakan pendekatan lengkap, daripada pemilihan objek kepada sintesis paparan baharu bagi pemandangan terbenam, dalam rangka kerja bersatu dengan beban minimum kepada pengguna, seperti yang ditunjukkan dalam rajah di bawah. 
Ringkasnya, sumbangan karya ini adalah seperti berikut:
- Proses operasi pemandangan 3D yang lengkap, bermula daripada pemilihan objek interaksi pengguna dan berakhir dengan pemandangan NeRF yang dibaiki 3D
- Bahagikan model dua dimensi; diperluaskan kepada sarung berbilang paparan dan boleh memulihkan topeng konsisten 3D daripada anotasi jarang; ;
- Set data baharu untuk penilaian tugas penyuntingan 3D, termasuk Kebenaran Groud selepas operasi.
- Secara khusus, kajian ini mula-mula menerangkan cara untuk memulakan topeng 3D kasar daripada anotasi paparan tunggal. Nyatakan paparan kod sumber beranotasi sebagai I_1. Suapkan maklumat yang jarang tentang objek dan paparan sumber kepada model segmentasi interaktif untuk menganggarkan topeng objek sumber awal
. Pandangan latihan kemudiannya diambil sebagai urutan video, bersama dengan 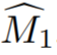 untuk memberikan model pembahagian contoh video V untuk mengira
untuk memberikan model pembahagian contoh video V untuk mengira 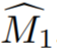 , di mana
, di mana 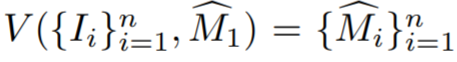 ialah tekaan awal topeng objek untuk I_i. Topeng awal selalunya tidak tepat berhampiran sempadan kerana paparan latihan sebenarnya bukan bingkai video bersebelahan dan model pembahagian video selalunya tidak diketahui 3D.
ialah tekaan awal topeng objek untuk I_i. Topeng awal selalunya tidak tepat berhampiran sempadan kerana paparan latihan sebenarnya bukan bingkai video bersebelahan dan model pembahagian video selalunya tidak diketahui 3D. 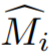
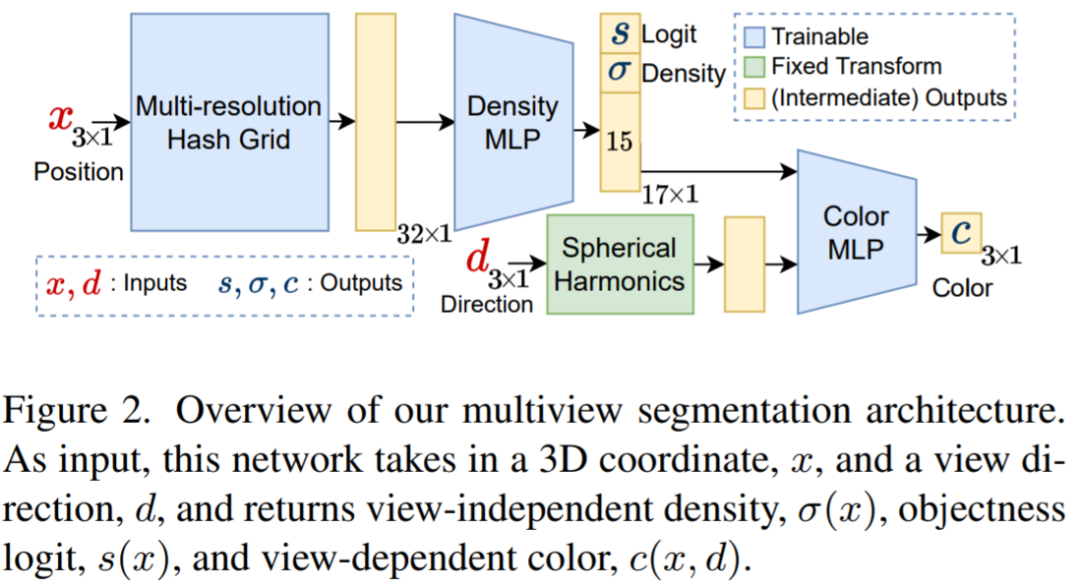 Modul segmentasi berbilang paparan memperoleh imej RGB input, parameter intrinsik dan ekstrinsik kamera yang sepadan, dan permulaan topeng untuk Melatih NeRF semantik. Gambar rajah di atas menggambarkan rangkaian yang digunakan dalam NeRF semantik untuk titik x dan direktori pandangan d, sebagai tambahan kepada ketumpatan σ dan warna c, ia mengembalikan logit objek pra-sigmoid, s (x). Untuk penumpuan pantasnya, para penyelidik menggunakan NGP segera sebagai seni bina NeRF mereka. Objektiviti yang diingini dikaitkan dengan sinar r diperoleh dengan mengemukakan dalam persamaan logaritma titik pada r dan bukannya warnanya berbanding dengan ketumpatan:
Modul segmentasi berbilang paparan memperoleh imej RGB input, parameter intrinsik dan ekstrinsik kamera yang sepadan, dan permulaan topeng untuk Melatih NeRF semantik. Gambar rajah di atas menggambarkan rangkaian yang digunakan dalam NeRF semantik untuk titik x dan direktori pandangan d, sebagai tambahan kepada ketumpatan σ dan warna c, ia mengembalikan logit objek pra-sigmoid, s (x). Untuk penumpuan pantasnya, para penyelidik menggunakan NGP segera sebagai seni bina NeRF mereka. Objektiviti yang diingini dikaitkan dengan sinar r diperoleh dengan mengemukakan dalam persamaan logaritma titik pada r dan bukannya warnanya berbanding dengan ketumpatan:
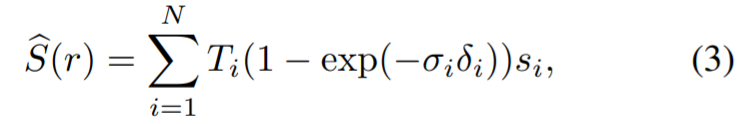 Kemudian gunakan kerugian klasifikasi untuk penyeliaan:
Kemudian gunakan kerugian klasifikasi untuk penyeliaan:
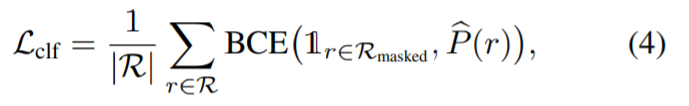 untuk penyeliaan berdasarkan Kehilangan keseluruhan Model pembahagian berbilang paparan NeRF ialah:
untuk penyeliaan berdasarkan Kehilangan keseluruhan Model pembahagian berbilang paparan NeRF ialah:
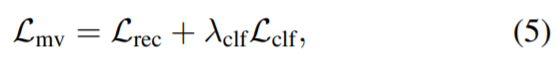 Akhir sekali, dua peringkat digunakan untuk pengoptimuman untuk menambah baik kod topeng ; selepas mendapat topeng 3D awal, topeng itu diberikan daripada paparan latihan dan digunakan untuk mengawasi model pembahagian berbilang paparan sekunder sebagai hipotesis awal (bukannya output pembahagian video).
Akhir sekali, dua peringkat digunakan untuk pengoptimuman untuk menambah baik kod topeng ; selepas mendapat topeng 3D awal, topeng itu diberikan daripada paparan latihan dan digunakan untuk mengawasi model pembahagian berbilang paparan sekunder sebagai hipotesis awal (bukannya output pembahagian video).
Imej di atas menunjukkan gambaran keseluruhan kaedah pembaikan konsisten-pandangan. Memandangkan kekurangan data menghalang latihan langsung model lukisan ubah suai 3D, kajian ini memanfaatkan model lukisan 2D sedia ada untuk mendapatkan kedalaman dan penampilan terdahulu dan kemudian menyelia pemadanan NeRF pada pemandangan lengkap. NeRF terbenam ini dilatih menggunakan kehilangan berikut: 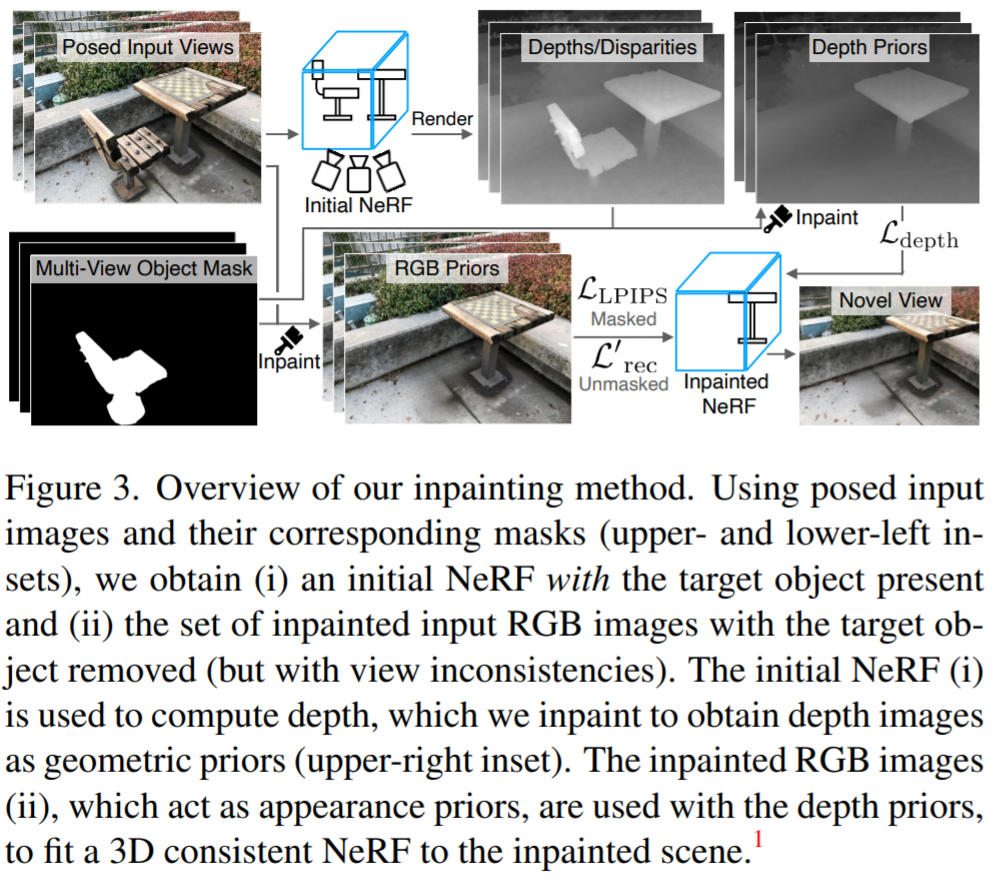
Kajian ini mencadangkan kaedah lukisan konsisten pandangan dengan input RGB. Pertama, kajian memindahkan pasangan imej dan topeng kepada pelukis dalam imej untuk mendapatkan imej RGB. Memandangkan setiap paparan dibaiki secara bebas, pandangan yang dibaiki digunakan secara langsung untuk mengawasi pembinaan semula NeRF. Dalam makalah ini, daripada menggunakan ralat min kuasa dua (MSE) sebagai kerugian untuk menjana topeng, para penyelidik mencadangkan untuk menggunakan LPIPS kehilangan persepsi untuk mengoptimumkan bahagian bertopeng imej, sementara masih menggunakan MSE untuk mengoptimumkan bahagian yang tidak bertopeng. Kehilangan ini dikira seperti berikut:
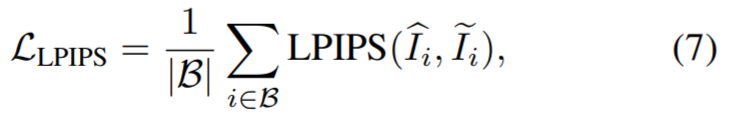
Walaupun dengan kehilangan persepsi, perbezaan antara pandangan yang dibaiki akan membawa secara tidak betul. model menumpu kepada geometri berkualiti rendah (cth., ukuran geometri "kabur" mungkin terbentuk berhampiran kamera untuk mengambil kira maklumat yang berbeza daripada setiap paparan). Oleh itu, penyelidik menggunakan peta kedalaman yang dijana sebagai panduan tambahan untuk model NeRF dan mengasingkan pemberat apabila mengira kehilangan persepsi, menggunakan kehilangan persepsi untuk muat hanya dengan warna tempat kejadian. Untuk melakukan ini, kami menggunakan NeRF yang dioptimumkan untuk imej yang mengandungi objek yang tidak diingini dan memaparkan peta kedalaman yang sepadan dengan paparan latihan. Kaedah pengiraan ialah menggunakan jarak ke kamera dan bukannya warna titik:
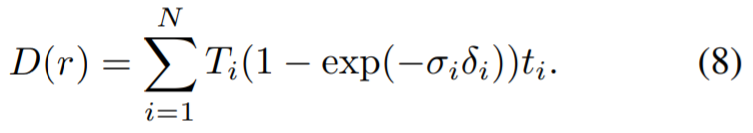
Kemudian Kedalaman yang diberikan adalah input kepada model pelukis dalam untuk mendapatkan peta kedalaman yang dilukis. Penyelidikan mendapati bahawa menggunakan LaMa untuk pemaparan mendalam, seperti RGB, boleh menghasilkan hasil yang cukup berkualiti tinggi. NeRF ini boleh menjadi model yang sama yang digunakan untuk pembahagian berbilang paparan, jika sumber lain digunakan untuk mendapatkan topeng, seperti topeng anotasi manusia, NeRF baharu akan dipasang ke tempat kejadian. Peta kedalaman ini kemudiannya digunakan untuk mengawasi geometri NeRF yang dilukis, yang mana kedalaman yang diberikan kemudian dimasukkan ke dalam model pengecat untuk mendapatkan peta kedalaman yang dilukis. Penyelidikan mendapati bahawa menggunakan LaMa untuk pemaparan mendalam, seperti RGB, boleh menghasilkan hasil yang cukup berkualiti tinggi. NeRF ini boleh menjadi model yang sama yang digunakan untuk pembahagian berbilang paparan, jika sumber lain digunakan untuk mendapatkan topeng, seperti topeng anotasi manusia, NeRF baharu akan dipasang ke tempat kejadian. Peta kedalaman ini kemudiannya digunakan untuk mengawasi geometri NeRF yang dicat dengan kedalaman pemaparannya kepada kedalaman yang dilukis  ke kedalaman yang dilukis jarak: >
ke kedalaman yang dilukis jarak: >
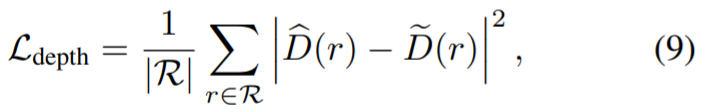
Berbilang paparan pembahagian: Mula-mula nilai model MVSeg tanpa sebarang pembetulan penyuntingan. Dalam eksperimen ini, diandaikan bahawa titik imej yang jarang telah diberikan model segmentasi interaktif siap pakai dan topeng sumber tersedia. Jadi tugasnya adalah untuk memindahkan topeng sumber ke pandangan lain. Jadual di bawah menunjukkan bahawa model baharu mengatasi garis dasar 2D (3D tidak konsisten) dan 3D. Di samping itu, pengoptimuman dua peringkat yang dicadangkan oleh penyelidik membantu meningkatkan lagi topeng yang dihasilkan.

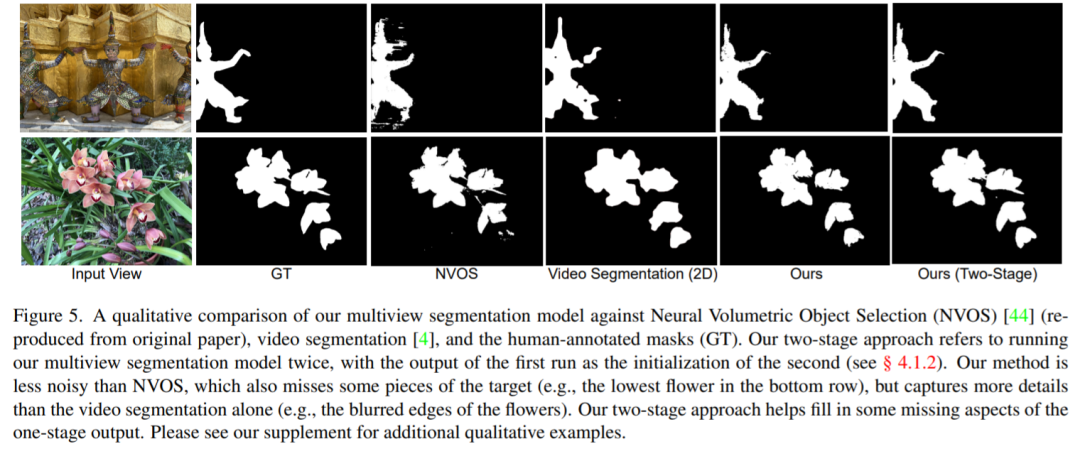
Jadual di bawah menunjukkan perbandingan kaedah MV dengan garis dasar Secara keseluruhannya, kaedah yang baru dicadangkan dengan ketara mengatasi kaedah pembaikan 2D dan 3D yang lain. Jadual di bawah selanjutnya menunjukkan bahawa mengalih keluar panduan daripada struktur geometri merendahkan kualiti pemandangan yang dibaiki.
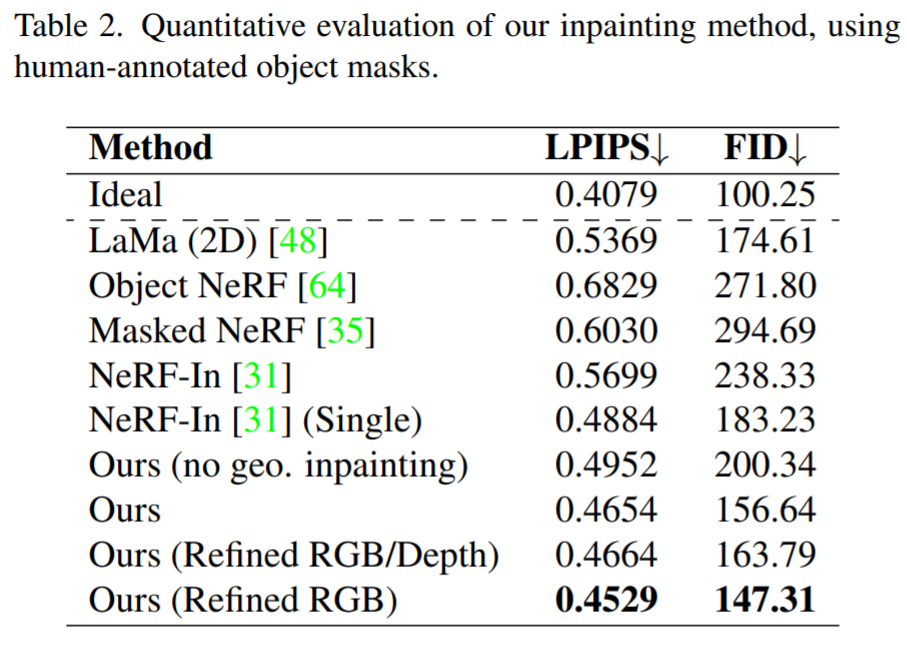
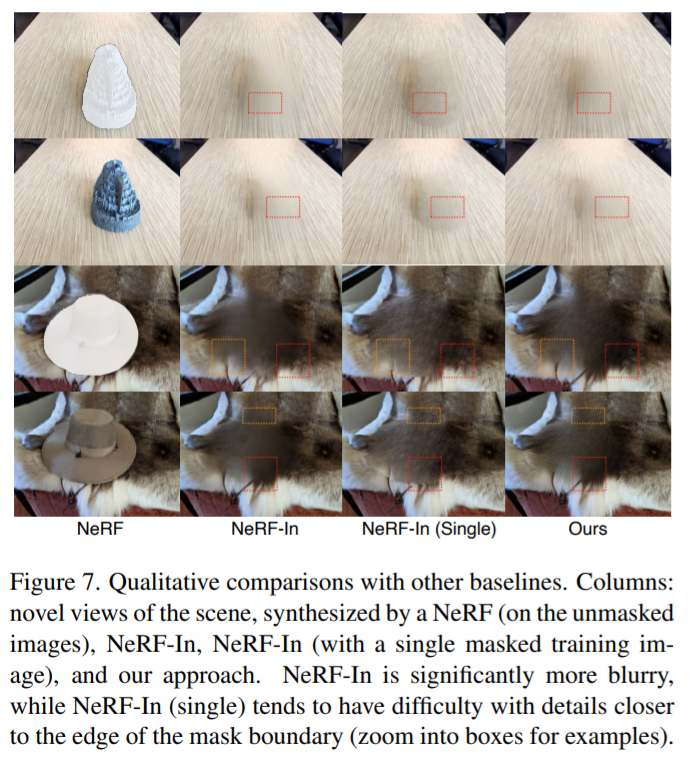
Keputusan kualitatif ditunjukkan dalam Rajah 6 dan Rajah 7. Rajah 6 menunjukkan bahawa kaedah kami boleh membina semula adegan konsisten pandangan dengan tekstur terperinci, termasuk pandangan koheren permukaan berkilat dan matte. Rajah 7 menunjukkan bahawa pendekatan persepsi kami mengurangkan kekangan pada pembinaan semula kawasan topeng yang tepat, dengan itu menghalang penampilan kabur apabila menggunakan semua imej, sementara juga mengelakkan artifak yang disebabkan oleh pengawasan satu pandangan.

Atas ialah kandungan terperinci Penyelidikan baharu daripada NeRF ada di sini: Adegan 3D dialih keluar tanpa kesan tanpa objek, tepat pada rambut. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1381
1381
 52
52

 Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Mengkonfigurasi firewall pelayan Mail Debian adalah langkah penting dalam memastikan keselamatan pelayan. Berikut adalah beberapa kaedah konfigurasi firewall yang biasa digunakan, termasuk penggunaan iptables dan firewalld. Gunakan iptables untuk mengkonfigurasi firewall untuk memasang iptables (jika belum dipasang): sudoapt-getupdateudoapt-getinstalliplesview peraturan iptables semasa: konfigurasi sudoiptable-l
 Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Kaedah pemasangan sijil SSL Server Server Debian
Apr 13, 2025 am 11:39 AM
Langkah -langkah untuk memasang sijil SSL pada pelayan mel Debian adalah seperti berikut: 1. Pasang OpenSSL Toolkit terlebih dahulu, pastikan bahawa OpenSSL Toolkit telah dipasang pada sistem anda. Jika tidak dipasang, anda boleh menggunakan arahan berikut untuk memasang: sudoapt-getupdateudoapt-getinstallopenssl2. Menjana permintaan kunci dan sijil peribadi seterusnya, gunakan OpenSSL untuk menjana kunci peribadi RSA 2048-bit dan permintaan sijil (CSR): Membuka
 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Sony mengesahkan kemungkinan menggunakan GPU khas di PS5 Pro untuk membangunkan AI dengan AMD
Apr 13, 2025 pm 11:45 PM
Sony mengesahkan kemungkinan menggunakan GPU khas di PS5 Pro untuk membangunkan AI dengan AMD
Apr 13, 2025 pm 11:45 PM
Mark Cerny, Ketua Arkitek SonyinterActiveEntainment (SIE, Sony Interactive Entertainment), telah mengeluarkan lebih banyak butiran perkakasan dari PlayStation5Pro hos generasi akan datang (PS5Pro), termasuk GPU seni bina AMDRDNA2.x yang dinamakan, dan Kod Arsitektur AMDRDNA2.x yang dinamakan. Tumpuan peningkatan prestasi PS5Pro masih pada tiga tiang, termasuk GPU yang lebih kuat, jejak sinar maju dan fungsi resolusi super PSSR yang berkuasa AI. GPU mengamalkan seni bina AmdrDNA2 yang disesuaikan, yang Sony menamakan RDNA2.x, dan ia mempunyai beberapa seni bina RDNA3.
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 Apakah kaedah penalaan prestasi zookeeper di CentOS
Apr 14, 2025 pm 03:18 PM
Apakah kaedah penalaan prestasi zookeeper di CentOS
Apr 14, 2025 pm 03:18 PM
Penalaan prestasi zookeeper pada centOs boleh bermula dari pelbagai aspek, termasuk konfigurasi perkakasan, pengoptimuman sistem operasi, pelarasan parameter konfigurasi, pemantauan dan penyelenggaraan, dan lain -lain. Memori yang cukup: memperuntukkan sumber memori yang cukup untuk zookeeper untuk mengelakkan cakera kerap membaca dan menulis. CPU multi-teras: Gunakan CPU multi-teras untuk memastikan bahawa zookeeper dapat memprosesnya selari.
 Kaedah Konfigurasi Hos Mantan Pelayan Mail Debian Mail
Apr 13, 2025 am 11:36 AM
Kaedah Konfigurasi Hos Mantan Pelayan Mail Debian Mail
Apr 13, 2025 am 11:36 AM
Mengkonfigurasi hos maya untuk pelayan mel pada sistem Debian biasanya melibatkan memasang dan mengkonfigurasi perisian pelayan mel (seperti Postfix, Exim, dan lain -lain) daripada Apache Httpserver, kerana Apache digunakan terutamanya untuk fungsi pelayan web. Berikut adalah langkah asas untuk mengkonfigurasi host maya pelayan mel: Pasang pakej sistem kemas kini pelayan pos Postfix: SudoaptDateSudoaptPrade Pasang Postfix: sudoapt
 Akhirnya berubah! Fungsi carian Microsoft Windows akan membawa kemas kini baru
Apr 13, 2025 pm 11:42 PM
Akhirnya berubah! Fungsi carian Microsoft Windows akan membawa kemas kini baru
Apr 13, 2025 pm 11:42 PM
Penambahbaikan Microsoft ke fungsi carian Windows telah diuji pada beberapa saluran Windows Insider di EU. Sebelum ini, fungsi carian Windows bersepadu dikritik oleh pengguna dan mempunyai pengalaman yang buruk. Kemas kini ini membahagikan fungsi carian ke dalam dua bahagian: carian tempatan dan carian web berasaskan Bing untuk meningkatkan pengalaman pengguna. Versi baru antara muka carian melakukan carian fail tempatan secara lalai. Jika anda perlu mencari dalam talian, anda perlu mengklik tab "Microsoft Bingwebsearch" untuk menukar. Selepas bertukar, bar carian akan memaparkan "Microsoft Bingwebsearch:", di mana pengguna boleh memasukkan kata kunci. Langkah ini berkesan mengelakkan pencampuran hasil carian tempatan dengan hasil carian Bing
