
 Peranti teknologi
AI
Adakah 'RL' dalam RLHF diperlukan? Sesetengah orang menggunakan entropi silang binari untuk memperhalusi LLM secara langsung, dan kesannya lebih baik.
Peranti teknologi
AI
Adakah 'RL' dalam RLHF diperlukan? Sesetengah orang menggunakan entropi silang binari untuk memperhalusi LLM secara langsung, dan kesannya lebih baik.
Adakah 'RL' dalam RLHF diperlukan? Sesetengah orang menggunakan entropi silang binari untuk memperhalusi LLM secara langsung, dan kesannya lebih baik.

Baru-baru ini, model bahasa tanpa pengawasan yang dilatih pada set data besar telah memperoleh keupayaan yang mengejutkan. Walau bagaimanapun, model ini dilatih mengenai data yang dijana oleh manusia dengan pelbagai matlamat, keutamaan dan set kemahiran, beberapa daripadanya tidak semestinya diharapkan untuk ditiru.
Memilih tindak balas dan gelagat yang dikehendaki model daripada pengetahuan dan keupayaannya yang sangat luas adalah penting untuk membina sistem AI yang selamat, berprestasi tinggi dan boleh dikawal. Banyak kaedah sedia ada menanamkan tingkah laku yang diingini ke dalam model bahasa dengan menggunakan set keutamaan manusia yang disusun dengan teliti yang mewakili jenis tingkah laku yang dianggap selamat dan bermanfaat oleh manusia Peringkat pembelajaran keutamaan ini berlaku pada set data teks yang besar Selepas fasa awal pra tanpa pengawasan -latihan.
Walaupun kaedah pembelajaran keutamaan yang paling mudah diselia penalaan halus bagi respons berkualiti tinggi yang ditunjukkan oleh manusia, kelas kaedah yang agak popular baru-baru ini adalah daripada maklum balas manusia (atau kecerdasan buatan) Laksanakan pembelajaran pengukuhan (RLHF/RLAIF). Kaedah RLHF memadankan model ganjaran kepada set data keutamaan manusia dan kemudian menggunakan RL untuk mengoptimumkan dasar model bahasa untuk menghasilkan respons yang memberikan ganjaran tinggi tanpa menyimpang secara berlebihan daripada model asal.
Sementara RLHF menghasilkan model dengan keupayaan perbualan dan pengekodan yang mengagumkan, saluran paip RLHF adalah jauh lebih kompleks daripada pembelajaran diselia, melibatkan latihan pelbagai model bahasa dan gelung melalui latihan Persampelan daripada dasar model bahasa menimbulkan kos pengiraan yang besar.
Dan satu kajian baru-baru ini menunjukkan bahawa: Objektif berasaskan RL yang digunakan oleh kaedah sedia ada boleh dioptimumkan dengan tepat dengan objektif rentas entropi binari yang mudah, dengan itu sangat Dipermudahkan saluran paip pembelajaran keutamaan. Iaitu, adalah mustahil untuk mengoptimumkan model bahasa secara langsung untuk mematuhi pilihan manusia tanpa memerlukan model ganjaran yang jelas atau pembelajaran pengukuhan.

Pautan kertas: https://arxiv.org/pdf/2305.18290 .pdf
Penyelidik dari Universiti Stanford dan institusi lain mencadangkan Pengoptimuman Keutamaan Langsung (DPO) Algoritma ini secara tersirat mengoptimumkan algoritma RLHF yang sedia ada (pemaksimumkan ganjaran dengan KL - divergence kekangan), tetapi mudah untuk dilaksanakan dan mudah untuk dilatih.
Eksperimen menunjukkan bahawa DPO sekurang-kurangnya berkesan seperti kaedah sedia ada, termasuk yang berdasarkan RLHF PPO.
Algoritma DPO
Seperti algoritma sedia ada, DPO juga bergantung pada model keutamaan teori (seperti model Bradley-Terry) untuk mengukur Seberapa baik fungsi ganjaran sesuai dengan data keutamaan empirikal. Walau bagaimanapun, kaedah sedia ada menggunakan model keutamaan untuk menentukan kehilangan keutamaan untuk melatih model ganjaran dan kemudian melatih dasar yang mengoptimumkan model ganjaran yang dipelajari, manakala DPO menggunakan perubahan dalam pembolehubah untuk mentakrifkan kehilangan keutamaan secara langsung sebagai fungsi dasar. Memandangkan set data keutamaan manusia untuk tindak balas model, DPO oleh itu boleh mengoptimumkan dasar menggunakan objektif rentas entropi perduaan mudah tanpa perlu mempelajari secara eksplisit fungsi ganjaran atau sampel daripada dasar semasa latihan.
Kemas kini DPO meningkatkan kebarangkalian log relatif bagi tindak balas pilihan kepada tindak balas bukan pilihan, tetapi ia termasuk berat kepentingan setiap sampel yang dinamik untuk mengelakkan kemerosotan model, Para penyelidik mendapati bahawa kemerosotan ini berlaku untuk sasaran nisbah kebarangkalian naif.
Untuk memahami DPO secara mekanikal, adalah berguna untuk menganalisis kecerunan fungsi kehilangan  . Kecerunan berkenaan dengan parameter θ boleh ditulis sebagai:
. Kecerunan berkenaan dengan parameter θ boleh ditulis sebagai:
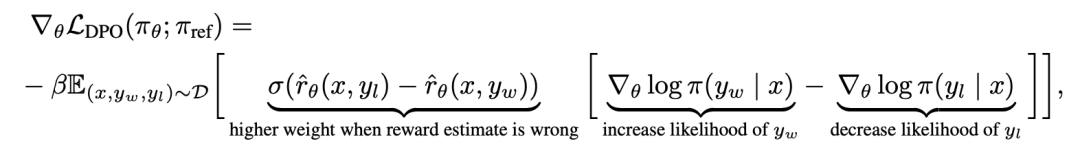
di mana 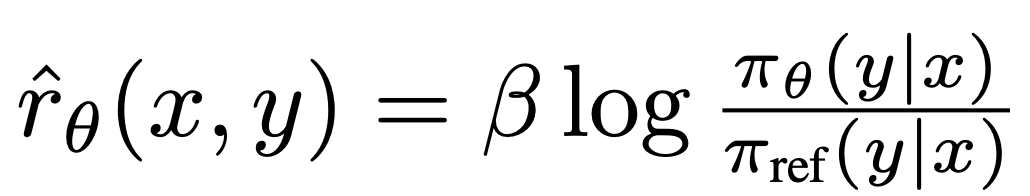 ialah ganjaran yang ditakrifkan secara tersirat oleh model bahasa
ialah ganjaran yang ditakrifkan secara tersirat oleh model bahasa  dan model rujukan
dan model rujukan  . Secara intuitif, kecerunan fungsi kehilangan
. Secara intuitif, kecerunan fungsi kehilangan  meningkatkan kemungkinan penyiapan pilihan y_w dan mengurangkan kemungkinan penyiapan bukan pilihan y_l.
meningkatkan kemungkinan penyiapan pilihan y_w dan mengurangkan kemungkinan penyiapan bukan pilihan y_l.
Yang penting, berat sampel ini ditentukan oleh model ganjaran tersirat 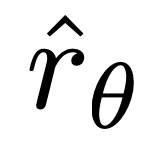 penilaian tahap penyiapan yang tidak disukai, dengan β ialah skala, iaitu, betapa tidak betulnya model ganjaran tersirat dalam kedudukan tahap penyiapan, yang juga mencerminkan kekuatan kekangan KL. Eksperimen menunjukkan kepentingan pemberat ini, kerana versi naif kaedah ini tanpa pekali pemberat membawa kepada kemerosotan model bahasa (Lampiran Jadual 2).
penilaian tahap penyiapan yang tidak disukai, dengan β ialah skala, iaitu, betapa tidak betulnya model ganjaran tersirat dalam kedudukan tahap penyiapan, yang juga mencerminkan kekuatan kekangan KL. Eksperimen menunjukkan kepentingan pemberat ini, kerana versi naif kaedah ini tanpa pekali pemberat membawa kepada kemerosotan model bahasa (Lampiran Jadual 2).
Dalam Bab 5 kertas kerja, penyelidik menjelaskan lagi kaedah DPO, memberikan sokongan teori, dan membandingkan kelebihan DPO dengan algoritma Actor-Critic untuk RLHF ( Seperti PPO) isu. Butiran khusus boleh didapati dalam kertas asal.
Eksperimen
Dalam percubaan, penyelidik menilai keupayaan DPO untuk melatih dasar secara langsung berdasarkan keutamaan.
Pertama, dalam persekitaran penjanaan teks yang dikawal dengan baik, mereka mempertimbangkan soalan: Berbanding dengan algoritma pembelajaran keutamaan biasa seperti PPO, DPO menukar pemaksimum ganjaran dalam dasar rujukan Sejauh manakah kecekapan KL-divergence minimization? Kami kemudian menilai prestasi DPO pada model yang lebih besar dan tugas RLHF yang lebih sukar, termasuk ringkasan dan dialog.
Akhirnya didapati bahawa dengan sedikit penalaan hiperparameter, DPO sering dilakukan serta, atau lebih baik daripada, garis dasar yang berkuasa seperti RLHF dengan PPO, sambil belajar ganjaran Fungsi mengembalikan yang terbaik Hasil trajektori pensampelan N.
Dari segi tugas, penyelidik meneroka tiga tugas penjanaan teks terbuka yang berbeza. Dalam semua percubaan, algoritma mempelajari dasar daripada set data keutamaan 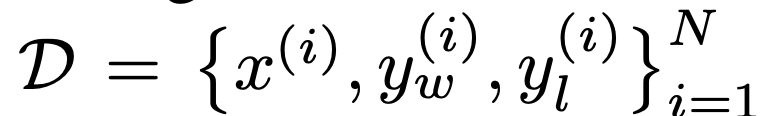 .
.
Dalam penjanaan emosi terkawal, x ialah awalan ulasan filem daripada set data IMDb dan dasar mesti menjana y dengan emosi positif. Untuk penilaian perbandingan, percubaan menggunakan pengelas sentimen yang telah dilatih untuk menjana pasangan pilihan, di mana 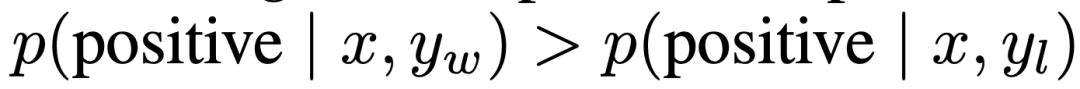 .
.
Untuk SFT, penyelidik memperhalusi GPT-2-besar sehingga ia menumpu kepada ulasan mengenai pembahagian latihan set data IMDB. Ringkasnya, x ialah siaran forum daripada Reddit, dan strategi mesti menjana ringkasan perkara utama dalam siaran. Berdasarkan kerja sebelumnya, eksperimen menggunakan set data ringkasan Reddit TL;DR dan pilihan manusia yang dikumpulkan oleh Stiennon et al. Percubaan juga menggunakan model SFT yang diperhalusi berdasarkan ringkasan artikel forum tulisan manusia 2 dan rangka kerja TRLX RLHF. Dataset keutamaan manusia ialah sampel yang dikumpul daripada model SFT yang berbeza tetapi terlatih serupa oleh Stiennon et al.
Akhir sekali, dalam perbualan satu pusingan, x ialah soalan manusia yang boleh menjadi apa-apa daripada astrofizik kepada nasihat perhubungan. Dasar mesti memberikan respons yang menarik dan membantu kepada pertanyaan pengguna; dasar mesti memberikan respons yang menarik dan membantu kepada pertanyaan pengguna, percubaan menggunakan set perbualan Anthropic Bermanfaat dan Tidak Memudaratkan, yang mengandungi 170 ribu perbualan antara pembantu manusia dan automatik. Setiap teks berakhir dengan sepasang respons yang dijana oleh model bahasa yang besar (walaupun tidak diketahui) dan label pilihan yang mewakili respons pilihan manusia. Dalam kes ini, tiada model SFT terlatih tersedia. Oleh itu, percubaan memperhalusi model bahasa luar hanya pada pelengkap pilihan untuk membentuk model SFT.
Para penyelidik menggunakan dua kaedah penilaian. Untuk menganalisis kecekapan setiap algoritma dalam mengoptimumkan matlamat memaksimumkan ganjaran yang terhad, eksperimen menilai setiap algoritma mengikut hadnya untuk mencapai ganjaran dan perbezaan KL daripada strategi rujukan dalam persekitaran penjanaan emosi terkawal. Percubaan boleh menggunakan fungsi ganjaran ground-truth (pengelas sentimen), jadi terikat ini boleh dikira. Tetapi sebenarnya, fungsi ganjaran kebenaran asas tidak diketahui. Oleh itu, kami menilai kadar kemenangan algoritma mengikut kadar kemenangan strategi garis dasar, dan menggunakan GPT-4 sebagai proksi untuk penilaian manusia terhadap kualiti ringkasan dan kegunaan tindak balas dalam ringkasan dan tetapan dialog pusingan tunggal. Untuk abstrak, eksperimen menggunakan abstrak rujukan dalam mesin ujian sebagai had untuk dialog, respons pilihan dalam set data ujian dipilih sebagai garis dasar. Walaupun penyelidikan sedia ada mencadangkan bahawa model bahasa boleh menjadi penilai automatik yang lebih baik daripada metrik sedia ada, para penyelidik menjalankan kajian manusia yang menunjukkan kebolehlaksanaan menggunakan GPT-4 untuk penilaian yang kuat dengan manusia secara amnya serupa atau lebih tinggi daripada perjanjian antara anotasi manusia.
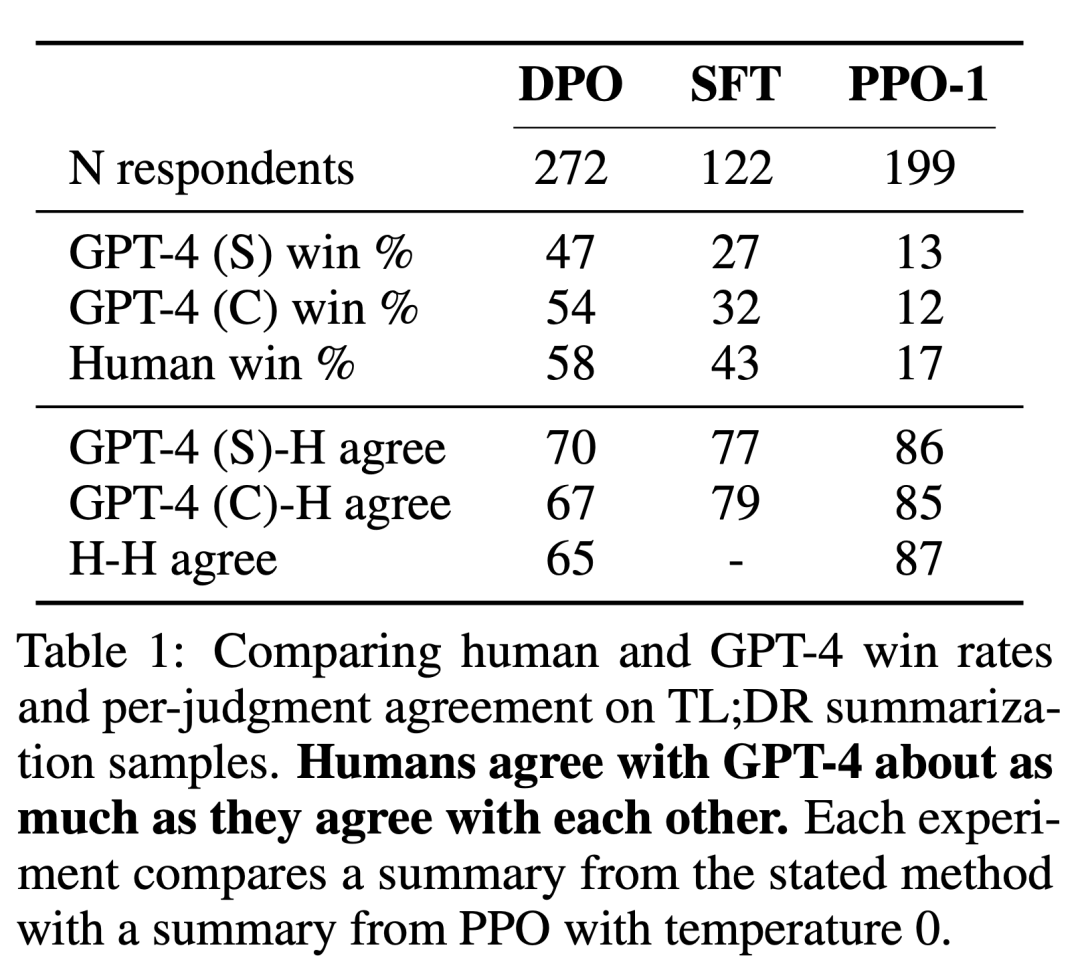
Selain DPO, penyelidik juga menilai beberapa model bahasa latihan sedia ada untuk mengekalkan konsistensi dengan keutamaan manusia yang konsisten. Pada yang paling mudah, percubaan meneroka gesaan sifar pukulan GPT-J pada tugas ringkasan dan gesaan 2 pukulan Pythia-2.8B pada tugas perbualan. Selain itu, eksperimen menilai model SFT dan Preferred-FT. Preferred-FT ialah model yang diperhalusi melalui pembelajaran terselia pada penyiapan y_w dipilih daripada model SFT (sentimen terkawal dan ringkasan) atau model bahasa umum (dialog satu pusingan). Satu lagi kaedah seliaan pseudo ialah Unlikelihood, yang hanya mengoptimumkan dasar untuk memaksimumkan kebarangkalian yang diberikan kepada y_w dan meminimumkan kebarangkalian yang diberikan kepada y_l. Percubaan menggunakan pekali pilihan α∈[0,1] pada "Ketidaksamaan". Mereka juga menganggap PPO, menggunakan fungsi ganjaran yang dipelajari daripada data keutamaan, dan PPO-GT. PPO-GT ialah oracle yang dipelajari daripada fungsi ganjaran kebenaran tanah yang tersedia dalam tetapan emosi terkawal. Dalam percubaan emosi mereka, pasukan menggunakan dua pelaksanaan PPO-GT, versi luar biasa dan versi diubah suai. Yang terakhir ini menormalkan ganjaran dan terus menala hiperparameter untuk meningkatkan prestasi (percubaan juga menggunakan pengubahsuaian ini apabila menjalankan PPO "Biasa" dengan ganjaran pembelajaran). Akhir sekali, kami mempertimbangkan garis dasar N yang terbaik, sampel respons N daripada model SFT (atau Preferred-FT dalam istilah perbualan), dan mengembalikan respons pemarkahan tertinggi berdasarkan fungsi ganjaran yang dipelajari daripada set data keutamaan. Pendekatan berprestasi tinggi ini memisahkan kualiti model ganjaran daripada pengoptimuman PPO, tetapi secara pengiraan tidak praktikal walaupun untuk N sederhana kerana ia memerlukan N pelengkapan sampel setiap pertanyaan pada masa ujian.
Rajah 2 menunjukkan ganjaran sempadan KL untuk pelbagai algoritma dalam tetapan emosi.
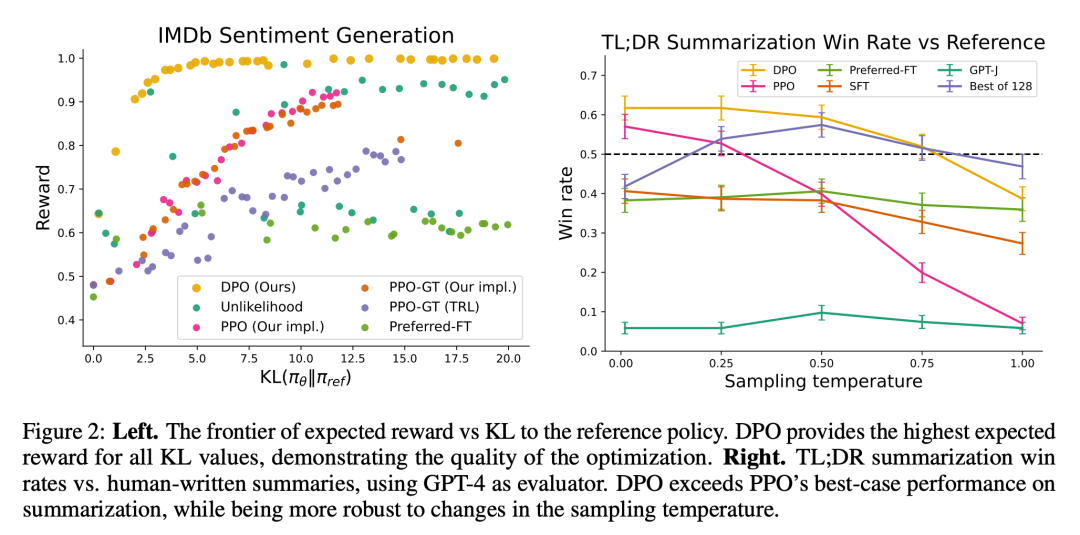
Rajah 3 menunjukkan bahawa DPO menumpu kepada prestasi optimumnya secara relatif cepat.
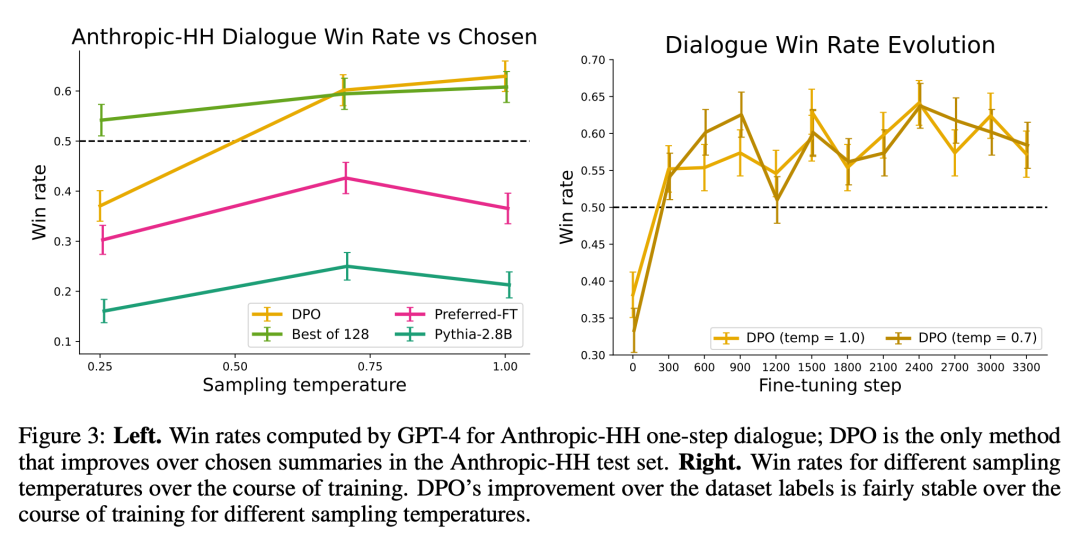
Untuk butiran penyelidikan lanjut, sila rujuk kertas asal.
Atas ialah kandungan terperinci Adakah 'RL' dalam RLHF diperlukan? Sesetengah orang menggunakan entropi silang binari untuk memperhalusi LLM secara langsung, dan kesannya lebih baik.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Petua Konfigurasi Firewall Pelayan Mel Debian
Apr 13, 2025 am 11:42 AM
Mengkonfigurasi firewall pelayan Mail Debian adalah langkah penting dalam memastikan keselamatan pelayan. Berikut adalah beberapa kaedah konfigurasi firewall yang biasa digunakan, termasuk penggunaan iptables dan firewalld. Gunakan iptables untuk mengkonfigurasi firewall untuk memasang iptables (jika belum dipasang): sudoapt-getupdateudoapt-getinstalliplesview peraturan iptables semasa: konfigurasi sudoiptable-l
 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Sony mengesahkan kemungkinan menggunakan GPU khas di PS5 Pro untuk membangunkan AI dengan AMD
Apr 13, 2025 pm 11:45 PM
Sony mengesahkan kemungkinan menggunakan GPU khas di PS5 Pro untuk membangunkan AI dengan AMD
Apr 13, 2025 pm 11:45 PM
Mark Cerny, Ketua Arkitek SonyinterActiveEntainment (SIE, Sony Interactive Entertainment), telah mengeluarkan lebih banyak butiran perkakasan dari PlayStation5Pro hos generasi akan datang (PS5Pro), termasuk GPU seni bina AMDRDNA2.x yang dinamakan, dan Kod Arsitektur AMDRDNA2.x yang dinamakan. Tumpuan peningkatan prestasi PS5Pro masih pada tiga tiang, termasuk GPU yang lebih kuat, jejak sinar maju dan fungsi resolusi super PSSR yang berkuasa AI. GPU mengamalkan seni bina AmdrDNA2 yang disesuaikan, yang Sony menamakan RDNA2.x, dan ia mempunyai beberapa seni bina RDNA3.
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Panduan Lengkap untuk Memeriksa Konfigurasi HDFS Dalam Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk memeriksa konfigurasi dan menjalankan status HDFS secara berkesan pada sistem CentOS. Langkah -langkah berikut akan membantu anda memahami sepenuhnya persediaan dan operasi HDFS. Sahkan Pembolehubah Alam Sekitar Hadoop: Pertama, pastikan pembolehubah persekitaran Hadoop ditetapkan dengan betul. Di terminal, laksanakan arahan berikut untuk mengesahkan bahawa Hadoop dipasang dan dikonfigurasi dengan betul: Hadoopversion Semak fail konfigurasi HDFS: Fail konfigurasi teras HDFS terletak di/etc/hadoop/conf/direktori, di mana core-site.xml dan hdfs-site.xml adalah kritikal. gunakan
 Apakah kaedah penalaan prestasi zookeeper di CentOS
Apr 14, 2025 pm 03:18 PM
Apakah kaedah penalaan prestasi zookeeper di CentOS
Apr 14, 2025 pm 03:18 PM
Penalaan prestasi zookeeper pada centOs boleh bermula dari pelbagai aspek, termasuk konfigurasi perkakasan, pengoptimuman sistem operasi, pelarasan parameter konfigurasi, pemantauan dan penyelenggaraan, dan lain -lain. Memori yang cukup: memperuntukkan sumber memori yang cukup untuk zookeeper untuk mengelakkan cakera kerap membaca dan menulis. CPU multi-teras: Gunakan CPU multi-teras untuk memastikan bahawa zookeeper dapat memprosesnya selari.
 Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Cara Melatih Model Pytorch di CentOs
Apr 14, 2025 pm 03:03 PM
Latihan yang cekap model pytorch pada sistem CentOS memerlukan langkah -langkah, dan artikel ini akan memberikan panduan terperinci. 1. Penyediaan Persekitaran: Pemasangan Python dan Ketergantungan: Sistem CentOS biasanya mempamerkan python, tetapi versi mungkin lebih tua. Adalah disyorkan untuk menggunakan YUM atau DNF untuk memasang Python 3 dan menaik taraf PIP: Sudoyumupdatepython3 (atau SudodnfupdatePython3), pip3install-upgradepip. CUDA dan CUDNN (Percepatan GPU): Jika anda menggunakan Nvidiagpu, anda perlu memasang Cudatool
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
