
 Peranti teknologi
AI
Penggantian API GPT-4? Prestasinya adalah setanding dan kos dikurangkan sebanyak 98%. Stanford mencadangkan FrugalGPT, tetapi penyelidikan itu menimbulkan kontroversi
Peranti teknologi
AI
Penggantian API GPT-4? Prestasinya adalah setanding dan kos dikurangkan sebanyak 98%. Stanford mencadangkan FrugalGPT, tetapi penyelidikan itu menimbulkan kontroversi
Penggantian API GPT-4? Prestasinya adalah setanding dan kos dikurangkan sebanyak 98%. Stanford mencadangkan FrugalGPT, tetapi penyelidikan itu menimbulkan kontroversi

Dengan pembangunan model bahasa besar (LLM), kecerdasan buatan berada dalam tempoh perubahan yang meletup. Umum mengetahui bahawa LLM boleh digunakan dalam aplikasi seperti perniagaan, sains dan kewangan, jadi semakin banyak syarikat (OpenAI, AI21, CoHere, dll.) menyediakan LLM sebagai perkhidmatan asas. Walaupun LLM seperti GPT-4 telah mencapai prestasi yang tidak pernah berlaku sebelum ini dalam tugasan seperti menjawab soalan, sifat pemprosesan tinggi mereka menjadikannya sangat mahal dalam aplikasi.
Sebagai contoh, ChatGPT berharga lebih $700,000 sehari untuk beroperasi, manakala menggunakan GPT-4 untuk menyokong perkhidmatan pelanggan boleh menelan belanja perniagaan kecil melebihi $21,000 sebulan. Sebagai tambahan kepada kos kewangan, menggunakan LLM terbesar datang dengan kesan alam sekitar dan tenaga yang ketara.
Banyak syarikat kini menyediakan perkhidmatan LLM melalui API, dan caj mereka berbeza-beza. Kos penggunaan API LLM biasanya terdiri daripada tiga komponen: 1) kos segera (berkadar dengan panjang gesaan), 2) kos penjanaan (berkadar dengan panjang penjanaan) dan 3) kadangkala setiap pertanyaan tetap kos.
Jadual 1 di bawah membandingkan kos 12 LLM komersial berbeza daripada vendor arus perdana, termasuk OpenAI, AI21, CoHere dan Textsynth. Kos mereka berbeza sehingga 2 urutan magnitud: contohnya, kos gesaan OpenAI GPT-4 $30 untuk 10 juta token, manakala GPT-J yang dihoskan oleh Textsynth berharga hanya $0.20.
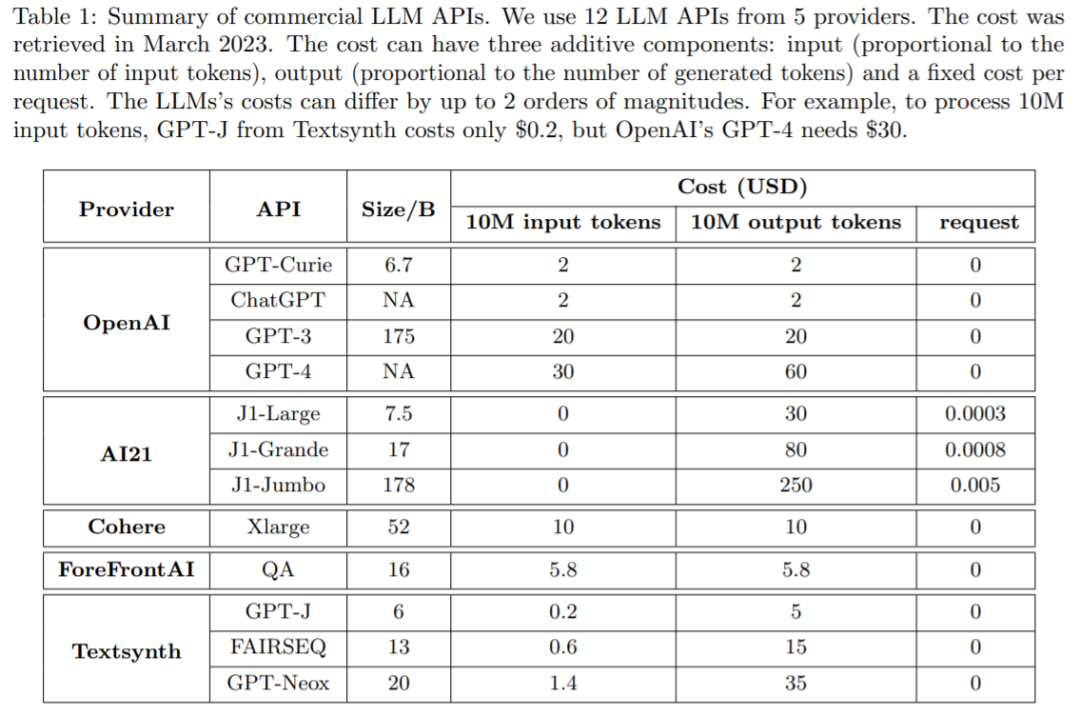
Keseimbangan antara kos dan ketepatan adalah faktor utama dalam membuat keputusan, esp menerima pakai teknologi baharu. Cara menggunakan LLM secara berkesan dan cekap ialah cabaran utama bagi pengamal: jika tugasan itu agak mudah, maka mengagregatkan berbilang respons daripada GPT-J (iaitu 30 kali lebih kecil daripada GPT-3) boleh mencapai prestasi yang serupa dengan GPT-3 , dengan itu mencapai pertukaran kos dan alam sekitar. Walau bagaimanapun, pada tugas yang lebih sukar, prestasi GPT-J mungkin merosot dengan ketara. Oleh itu, pendekatan baharu diperlukan untuk menggunakan LLM secara kos efektif.
Satu kajian baru-baru ini cuba mencadangkan penyelesaian kepada masalah kos ini secara eksperimen menunjukkan bahawa FrugalGPT boleh bersaing dengan prestasi LLM individu terbaik (seperti GPT-4), iaitu. kos dikurangkan sehingga 98%, atau ketepatan LLM individu terbaik dipertingkatkan sebanyak 4% pada kos yang sama.

- Alamat kertas: https://arxiv.org/ pdf/2305.05176.pdf
Penyelidik dari Universiti Stanford menyemak kos penggunaan API LLM seperti GPT-4, ChatGPT, J1-Jumbo , dan mendapati bahawa ini model mempunyai harga yang berbeza, dan kos boleh berbeza mengikut dua urutan magnitud, terutamanya menggunakan LLM pada kuantiti pertanyaan yang banyak dan teks boleh menjadi lebih mahal. Berdasarkan ini, kajian ini menggariskan dan membincangkan tiga strategi yang boleh digunakan oleh pengguna untuk mengurangkan kos inferens menggunakan LLM: 1) penyesuaian segera, 2) penghampiran LLM, dan 3) Lata LLM. Tambahan pula, kajian ini mencadangkan contoh mudah dan fleksibel bagi LLM bertingkat, FrugalGPT, yang mempelajari gabungan LLM untuk digunakan dalam pertanyaan berbeza untuk mengurangkan kos dan meningkatkan ketepatan.
Idea dan penemuan yang dibentangkan dalam kajian ini meletakkan asas untuk penggunaan LLM yang mampan dan cekap. Mampu mengguna pakai keupayaan AI yang lebih maju tanpa meningkatkan belanjawan boleh mendorong penggunaan teknologi AI yang lebih meluas merentas industri, memberikan perniagaan yang lebih kecil keupayaan untuk melaksanakan model AI yang canggih ke dalam operasi mereka.
Sudah tentu, ini hanyalah satu perspektif Ia akan mengambil sedikit masa untuk mendedahkan jenis pengaruh yang boleh dicapai oleh FrugalGPT dan sama ada ia boleh menjadi "pengubah permainan dalam industri AI. ." Selepas kertas itu dikeluarkan, penyelidikan ini juga menimbulkan beberapa kontroversi:
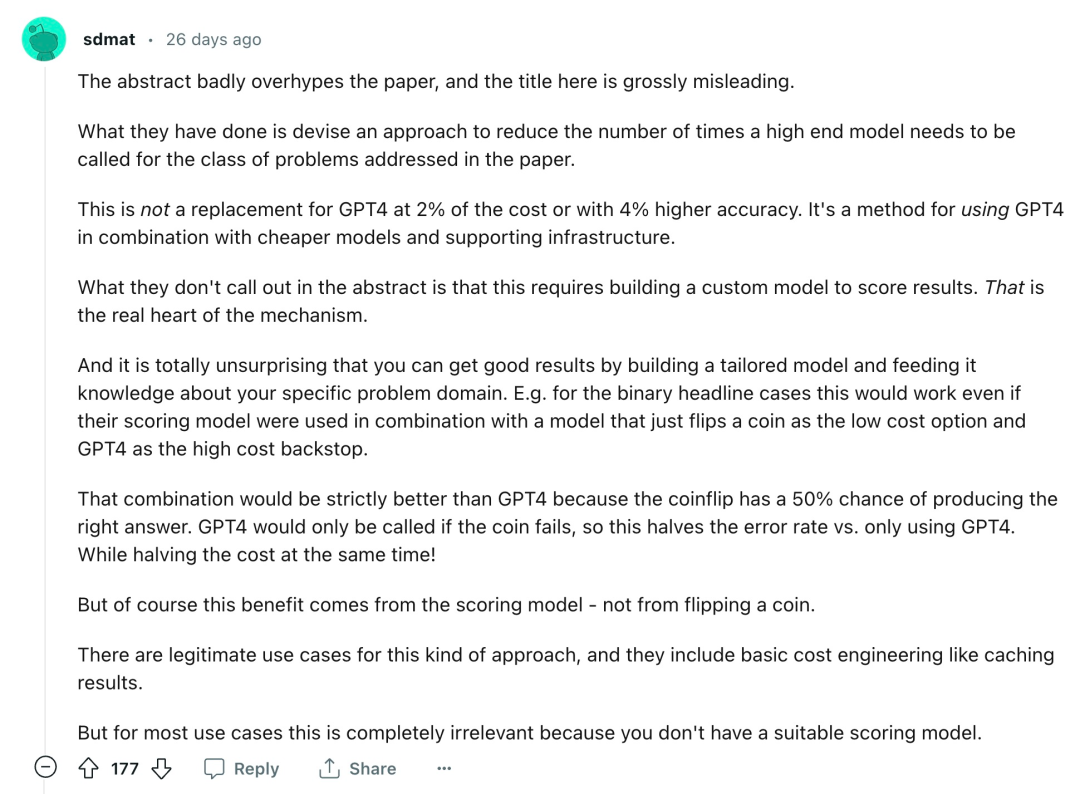
"Abstrak terlalu membesar-besarkan maksud kertas itu, dan tajuk di sini sangat mengelirukan. Apa yang mereka lakukan ialah merangka satu cara untuk mengurangkan keperluan untuk memanggil kelas atasan mengenai jenis masalah yang diliputi dalam nombor kertas model. Ini bukan pengganti untuk GPT-4 pada kos 2%, dan bukan juga penggantian untuk GPT-4 pada ketepatan 4% Ia adalah cara untuk menggabungkan GPT-4 dengan model yang lebih murah dan infrastruktur sokongan abstrak tidak menunjukkan bahawa ini memerlukan membina model tersuai untuk menjaringkan keputusan, yang merupakan teras sebenar mekanisme... Terdapat kes penggunaan yang sah untuk pendekatan ini, termasuk kejuruteraan kos asas seperti keputusan caching untuk kebanyakan kes penggunaan ini tidak relevan sama sekali kerana anda tidak mempunyai model pemarkahan yang sesuai >
"Mereka hanya menilai ini pada tiga set data (kecil) dan tidak memberikan maklumat tentang kekerapan FrugalGPT memilih model masing-masing. Selain itu, mereka melaporkan bahawa model yang lebih kecil mencapai hasil yang lebih baik daripada GPT-4 mempunyai ketepatan yang lebih tinggi, yang membuatkan saya sangat ragu-ragu tentang kertas ini secara umum. melihat kandungan kertas tersebut.Cara menggunakan LLM secara ekonomi dan tepat
Strategi 1: penyesuaian segera. Kos pertanyaan LLM meningkat secara linear dengan saiz segera. Oleh itu, pendekatan yang munasabah untuk mengurangkan kos penggunaan API LLM melibatkan pengurangan saiz segera, satu proses kajian memanggil penyesuaian segera. Pemilihan segera ditunjukkan dalam Rajah 2(a): daripada menggunakan gesaan yang mengandungi banyak contoh untuk menunjukkan cara melaksanakan tugas, adalah mungkin untuk menyimpan hanya subset kecil contoh dalam segera. Ini menghasilkan gesaan yang lebih kecil dan kos yang lebih rendah. Contoh lain ialah penggabungan pertanyaan (ditunjukkan dalam Rajah 2(b)).
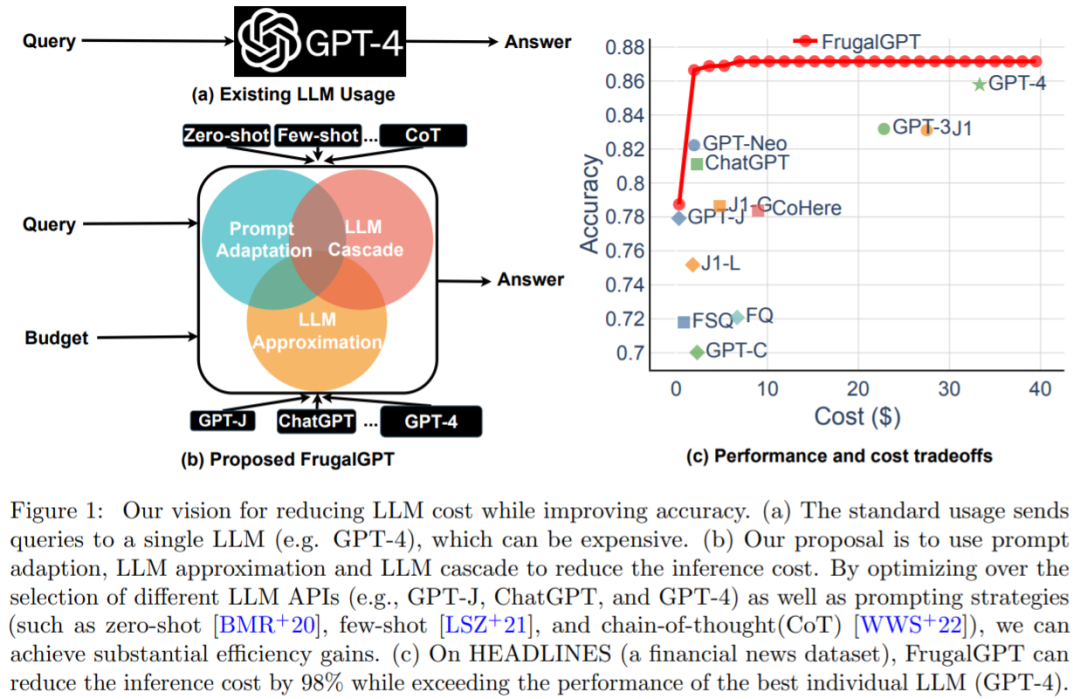
Strategi 3: LLM Lata. API LLM yang berbeza mempunyai kekuatan dan kelemahan mereka sendiri dalam pelbagai pertanyaan. Oleh itu, pemilihan LLM yang sesuai untuk digunakan boleh mengurangkan kos dan meningkatkan prestasi. Contoh lata LLM ditunjukkan dalam Rajah 2(e).
Pengurangan kos dan peningkatan ketepatan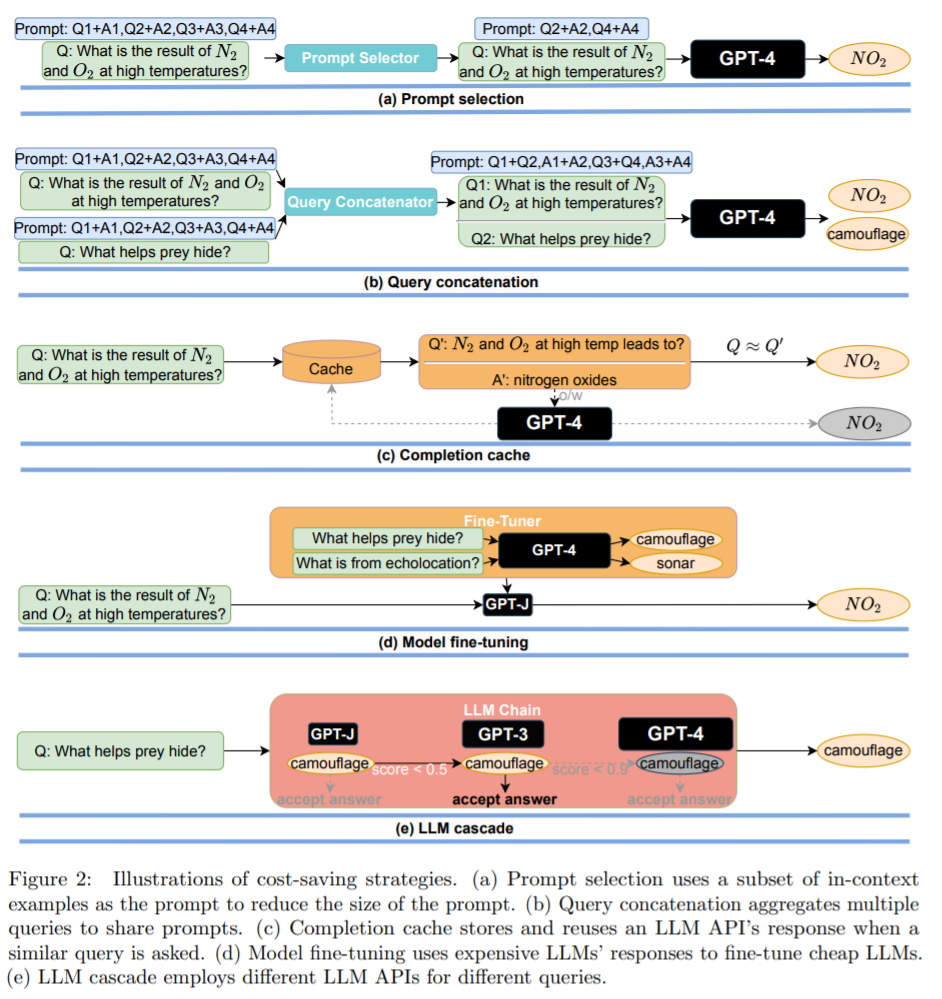
Fahami apa yang dipelajari daripada contoh mudah LLM lata;
Kumpulkan penjimatan kos yang dicapai oleh FrugalGPT apabila memadankan prestasi LLM tunggal terbaik ;
Mengukur pertukaran antara prestasi dan kos yang dicapai oleh FrugalGPT.
- Persediaan percubaan dibahagikan kepada beberapa aspek: API LLM (Jadual 1), tugasan, set data (Jadual 2) dan tika FrugalGPT.
-
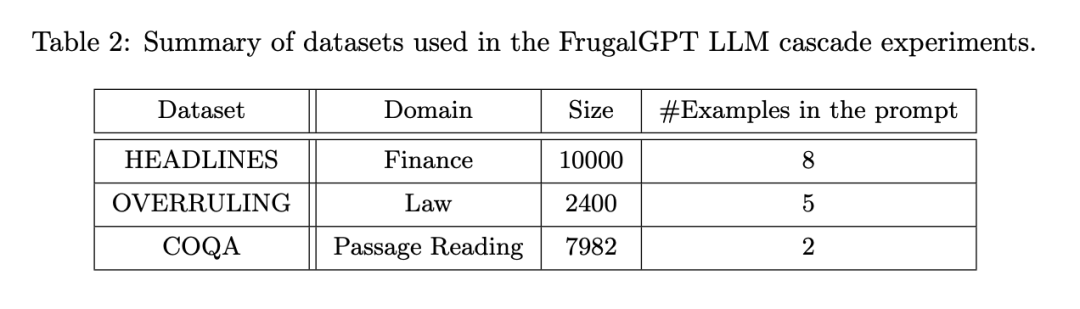
FrugalGPT dibangunkan di atas API di atas dan dinilai pada julat set data yang dimiliki oleh tugasan yang berbeza. Antaranya, HEADLINES ialah set data berita kewangan Matlamatnya adalah untuk menentukan trend harga emas (naik, turun, neutral atau tiada) dengan membaca tajuk berita kewangan, yang amat berguna untuk menapis berita yang relevan dalam pasaran kewangan set data dokumen undang-undang , yang matlamatnya adalah untuk menentukan sama ada ayat yang diberikan adalah "overruling", iaitu, menolak kes undang-undang terdahulu ialah set data pemahaman bacaan yang dibangunkan dalam persekitaran perbualan, yang disesuaikan oleh penyelidik sebagai langsung tugas menjawab pertanyaan.
Mereka menumpukan pada pendekatan lata LLM dengan panjang lata 3 kerana ini memudahkan ruang pengoptimuman dan telah menunjukkan hasil yang baik. Setiap set data dibahagikan secara rawak kepada set latihan untuk mempelajari lata LLM dan set ujian untuk penilaian.

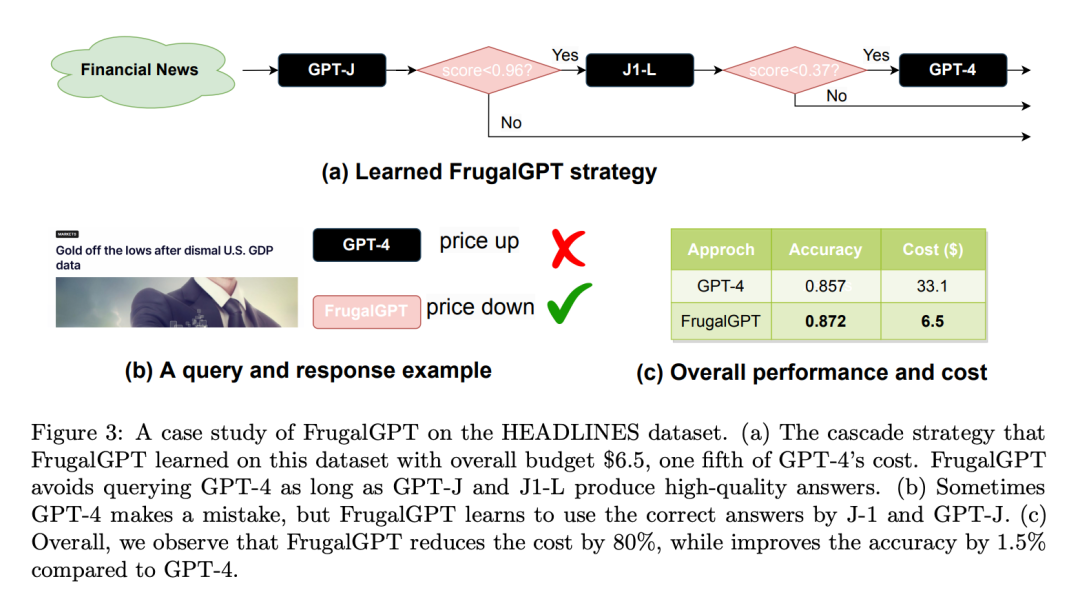
Berikut ialah kajian kes set data HEADLINES: Tetapkan belanjawan kepada $6.50, ya Satu perlima kos GPT-4. Gunakan DistilBERT [SDCW19] untuk regresi sebagai fungsi pemarkahan. Perlu diingat bahawa DistilBERT jauh lebih kecil daripada semua LLM yang dipertimbangkan di sini dan oleh itu lebih murah. Seperti yang ditunjukkan dalam Rajah 3(a), FrugalGPT yang dipelajari secara berurutan memanggil GPT-J, J1-L dan GPT-4. Untuk sebarang pertanyaan yang diberikan, ia mula-mula mengekstrak jawapan daripada GPT-J. Jika markah jawapan lebih daripada 0.96, jawapan diterima sebagai respons akhir. Jika tidak, J1-L akan disoal. Jika skor jawapan J1-L lebih besar daripada 0.37, ia diterima sebagai jawapan akhir, jika tidak, GPT-4 digunakan untuk mendapatkan jawapan akhir. Menariknya, pendekatan ini mengatasi GPT-4 pada banyak pertanyaan. Contohnya, berdasarkan tajuk Nasdaq "Data KDNK AS suram, emas berada di paras terendah", FrugalGPT meramalkan dengan tepat bahawa harga akan jatuh, manakala GPT-4 memberikan jawapan yang salah (seperti yang ditunjukkan dalam Rajah 3(b) ).
Secara keseluruhannya, hasil daripada FrugalGPT ialah ketepatan yang dipertingkatkan dan pengurangan kos. Seperti yang ditunjukkan dalam Rajah 3 (c), kos dikurangkan sebanyak 80%, manakala ketepatan adalah lebih tinggi 1.5%.
Kepelbagaian LLM
Mengapakah berbilang API LLM boleh menghasilkan prestasi yang lebih baik daripada LLM tunggal terbaik? Pada asasnya, ini disebabkan oleh kepelbagaian penjanaan: walaupun LLM kos rendah kadangkala boleh menjawab pertanyaan dengan betul yang tidak boleh dilakukan oleh LLM kos lebih tinggi. Untuk mengukur kepelbagaian ini, penyelidik menggunakan Peningkatan Prestasi Maksimum, juga dikenali sebagai MPI. MPI LLM A relatif kepada LLM B ialah kebarangkalian LLM A menghasilkan jawapan yang betul dan LLM B memberikan jawapan yang salah. Metrik ini pada asasnya mengukur peningkatan prestasi maksimum yang boleh dicapai dengan memanggil LLM A pada masa yang sama dengan LLM B.
Rajah 4 menunjukkan MPI antara setiap pasangan API LLM untuk semua set data. Pada set data HEADLINES, GPT-C, GPT-J dan J1-L semuanya meningkatkan prestasi GPT-4 sebanyak 6%. Pada set data COQA, GPT-4 adalah salah untuk 13% daripada titik data, tetapi GPT-3 memberikan jawapan yang betul. Walaupun had atas penambahbaikan ini mungkin tidak selalu dapat dicapai, ia menunjukkan kemungkinan memanfaatkan perkhidmatan yang lebih murah untuk mencapai prestasi yang lebih baik.
Penjimatan Kos
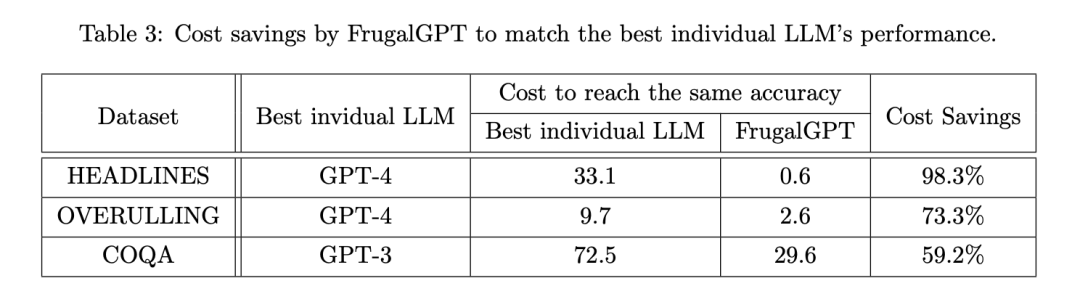
Para penyelidik kemudian meneliti sama ada FrugalGPT boleh mengurangkan kos sambil mengekalkan ketepatan, dan jika ya, dengan berapa banyak. Jadual 3 menunjukkan penjimatan kos keseluruhan FrugalGPT, antara 50% hingga 98%. Ini mungkin kerana FrugalGPT boleh mengenal pasti pertanyaan yang boleh dijawab dengan tepat oleh LLM yang lebih kecil, dan oleh itu hanya memanggil LLM yang menjimatkan kos. Walaupun LLM yang berkuasa tetapi mahal, seperti GPT-4, hanya digunakan untuk pertanyaan mencabar yang dikesan oleh FrugalGPT.
Prestasi dan Ganti Kos
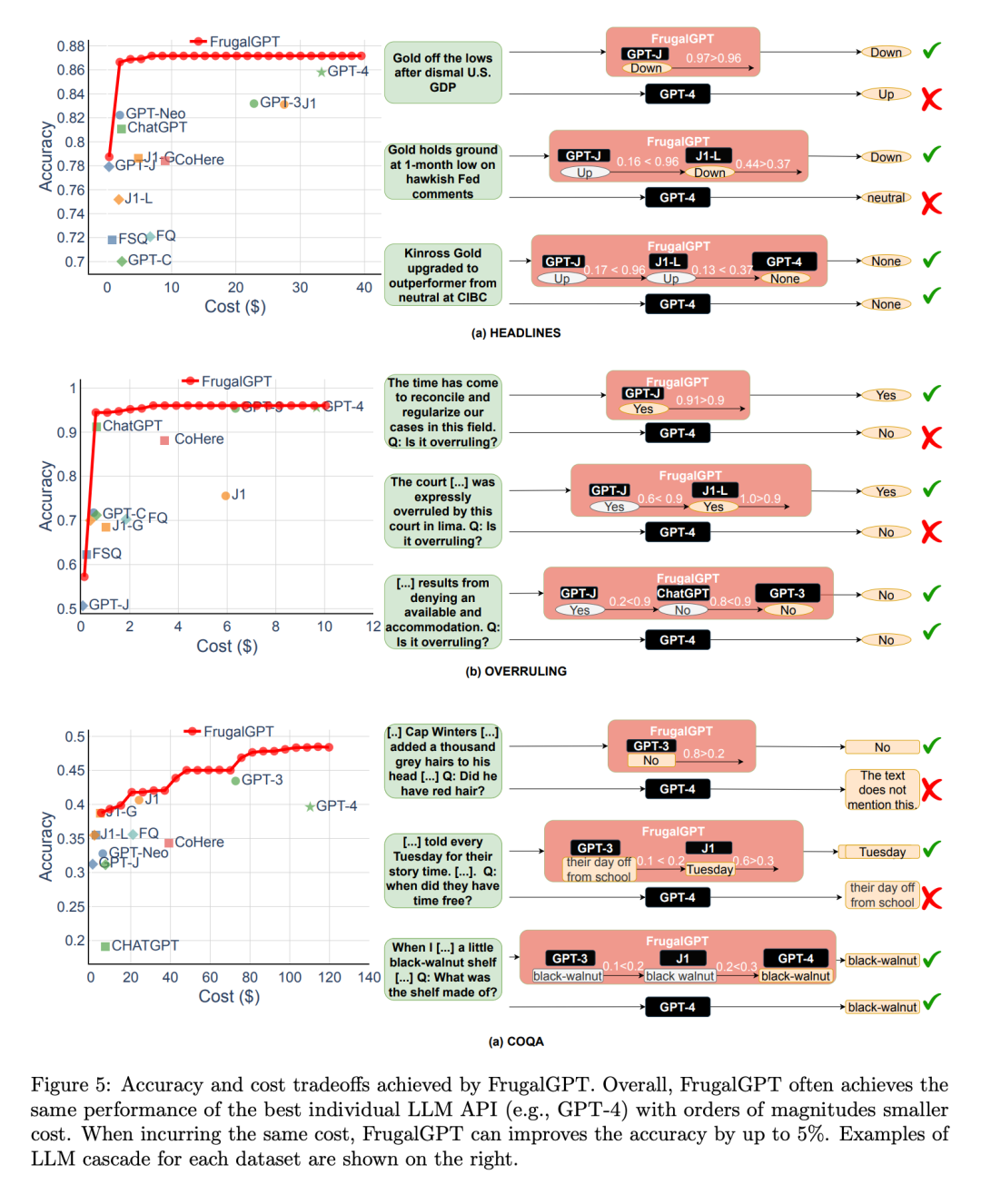
Seterusnya , para penyelidik meneroka pertukaran antara prestasi dan kos pelaksanaan FrugalGPT, seperti yang ditunjukkan dalam Rajah 5, dan membuat beberapa pemerhatian yang menarik.
Pertama sekali, kedudukan kos API LLM berbeza tidak tetap. Selain itu, API LLM yang lebih mahal kadangkala menghasilkan prestasi yang lebih teruk daripada rakan sejawatannya yang lebih murah. Pemerhatian ini menyerlahkan kepentingan pemilihan API LLM yang sesuai, walaupun tanpa kekangan belanjawan.
Seterusnya, penyelidik juga menyatakan bahawa FrugalGPT dapat mencapai pertukaran kos prestasi yang lancar pada semua set data yang dinilai. Ini menyediakan pilihan yang fleksibel untuk pengguna LLM dan berpotensi untuk membantu penyedia API LLM menjimatkan tenaga dan mengurangkan pelepasan karbon. Malah, FrugalGPT boleh mengurangkan kos dan meningkatkan ketepatan serentak, mungkin kerana FrugalGPT menyepadukan pengetahuan daripada pelbagai LLM.
Contoh pertanyaan yang ditunjukkan dalam Rajah 5 menerangkan lagi mengapa FrugalGPT boleh meningkatkan prestasi dan mengurangkan kos secara serentak. GPT-4 membuat kesilapan pada beberapa pertanyaan, seperti contoh pertama di bahagian (a), tetapi sesetengah API kos rendah memberikan ramalan yang betul. FrugalGPT mengenal pasti pertanyaan ini dengan tepat dan bergantung sepenuhnya pada API kos rendah. Sebagai contoh, GPT-4 tersilap menyimpulkan bahawa tidak ada perubahan daripada pernyataan undang-undang "Sudah tiba masanya untuk mengharmonikan dan menyeragamkan kes kami dalam bidang ini," seperti yang ditunjukkan dalam Rajah 5(b). Walau bagaimanapun, FrugalGPT menerima jawapan yang betul bagi GPT-J, mengelakkan penggunaan LLM yang mahal dan meningkatkan prestasi keseluruhan. Sudah tentu, satu API LLM tidak selalunya betul; Lata LLM mengatasinya dengan menggunakan rangkaian API LLM. Contohnya, dalam contoh kedua yang ditunjukkan dalam Rajah 5(a), FrugalGPT mendapati bahawa penjanaan GPT-J mungkin tidak boleh dipercayai dan beralih kepada LLM kedua dalam rantai, J1-L, untuk mencari jawapan yang betul. Sekali lagi, GPT-4 memberikan jawapan yang salah. FrugalGPT tidak sempurna dan masih terdapat banyak ruang untuk mengurangkan kos. Sebagai contoh, dalam contoh ketiga Rajah 5(c), semua API LLM dalam rantaian memberikan jawapan yang sama. Walau bagaimanapun, FrugalGPT tidak pasti sama ada LLM pertama adalah betul, menyebabkan keperluan untuk menanyakan semua LLM dalam rantaian. Menentukan cara untuk mengelakkan ini masih menjadi persoalan terbuka.
Untuk butiran penyelidikan lanjut, sila rujuk kertas asal.

Atas ialah kandungan terperinci Penggantian API GPT-4? Prestasinya adalah setanding dan kos dikurangkan sebanyak 98%. Stanford mencadangkan FrugalGPT, tetapi penyelidikan itu menimbulkan kontroversi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1385
1385
 52
52

 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Panduan Lengkap untuk Memeriksa Konfigurasi HDFS Dalam Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk memeriksa konfigurasi dan menjalankan status HDFS secara berkesan pada sistem CentOS. Langkah -langkah berikut akan membantu anda memahami sepenuhnya persediaan dan operasi HDFS. Sahkan Pembolehubah Alam Sekitar Hadoop: Pertama, pastikan pembolehubah persekitaran Hadoop ditetapkan dengan betul. Di terminal, laksanakan arahan berikut untuk mengesahkan bahawa Hadoop dipasang dan dikonfigurasi dengan betul: Hadoopversion Semak fail konfigurasi HDFS: Fail konfigurasi teras HDFS terletak di/etc/hadoop/conf/direktori, di mana core-site.xml dan hdfs-site.xml adalah kritikal. gunakan
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
Memasang MySQL pada CentOS melibatkan langkah -langkah berikut: Menambah sumber MySQL YUM yang sesuai. Jalankan YUM Pasang Perintah MySQL-Server untuk memasang pelayan MySQL. Gunakan perintah mysql_secure_installation untuk membuat tetapan keselamatan, seperti menetapkan kata laluan pengguna root. Sesuaikan fail konfigurasi MySQL seperti yang diperlukan. Tune parameter MySQL dan mengoptimumkan pangkalan data untuk prestasi.
 Cara Melihat Log Gitlab Di Bawah Centos
Apr 14, 2025 pm 06:18 PM
Cara Melihat Log Gitlab Di Bawah Centos
Apr 14, 2025 pm 06:18 PM
Panduan Lengkap untuk Melihat Log Gitlab Di bawah Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk melihat pelbagai log Gitlab dalam sistem CentOS, termasuk log utama, log pengecualian, dan log lain yang berkaitan. Sila ambil perhatian bahawa laluan fail log mungkin berbeza -beza bergantung pada versi GitLab dan kaedah pemasangan. Jika laluan berikut tidak wujud, sila semak fail Direktori Pemasangan dan Konfigurasi GitLab. 1. Lihat log Gitlab utama Gunakan arahan berikut untuk melihat fail log utama aplikasi GitLabRails: Perintah: Sudocat/var/Log/Gitlab/Gitlab-Rails/Production.log Perintah ini akan memaparkan produk
 Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Latihan yang diedarkan Pytorch pada sistem CentOS memerlukan langkah -langkah berikut: Pemasangan Pytorch: Premisnya ialah Python dan PIP dipasang dalam sistem CentOS. Bergantung pada versi CUDA anda, dapatkan arahan pemasangan yang sesuai dari laman web rasmi Pytorch. Untuk latihan CPU sahaja, anda boleh menggunakan arahan berikut: PipinstallToRchTorchVisionTorchaudio Jika anda memerlukan sokongan GPU, pastikan versi CUDA dan CUDNN yang sama dipasang dan gunakan versi pytorch yang sepadan untuk pemasangan. Konfigurasi Alam Sekitar Teragih: Latihan yang diedarkan biasanya memerlukan pelbagai mesin atau mesin berbilang mesin tunggal. Tempat
