
 Peranti teknologi
AI
Apa lagi yang boleh dilakukan oleh NLP? Universiti Beihang, ETH, Universiti Sains dan Teknologi Hong Kong, Akademi Sains China dan institusi lain bersama-sama mengeluarkan kertas setebal seratus muka surat untuk menerangkan secara sistematik rantaian teknologi pasca-ChatGPT
Peranti teknologi
AI
Apa lagi yang boleh dilakukan oleh NLP? Universiti Beihang, ETH, Universiti Sains dan Teknologi Hong Kong, Akademi Sains China dan institusi lain bersama-sama mengeluarkan kertas setebal seratus muka surat untuk menerangkan secara sistematik rantaian teknologi pasca-ChatGPT
Apa lagi yang boleh dilakukan oleh NLP? Universiti Beihang, ETH, Universiti Sains dan Teknologi Hong Kong, Akademi Sains China dan institusi lain bersama-sama mengeluarkan kertas setebal seratus muka surat untuk menerangkan secara sistematik rantaian teknologi pasca-ChatGPT

Semuanya bermula dengan kemunculan ChatGPT...
Komuniti NLP yang dahulunya aman ketakutan dengan kedatangan "raksasa" yang tiba-tiba ini! Semalaman, seluruh bulatan NLP telah mengalami perubahan yang besar. Industri telah menyusuli dengan cepat, modal telah melonjak, dan ia telah memulakan jalan mereplikasi ChatGPT tiba-tiba jatuh ke dalam keadaan kekeliruan... Semua orang perlahan-lahan mula percaya bahawa "NLP telah diselesaikan!"
Namun, dilihat dari kalangan akademik NLP yang masih aktif baru-baru ini dan aliran kerja cemerlang yang tidak berkesudahan, ini bukanlah kes, malah boleh dikatakan "NLP baru sahaja menjadi nyata!"
Dalam beberapa bulan lalu, Universiti Beihang, Mila, Universiti Sains dan Teknologi Hong Kong, ETH Zurich (ETH ), Universiti Waterloo, Kolej Dartmouth, Selepas penyelidikan yang sistematik dan komprehensif, banyak institusi seperti Universiti Sheffield dan Akademi Sains China menghasilkan kertas setebal 110 halaman, yang menghuraikan secara sistematik rantaian teknologi dalam era pasca-ChatGPT: interaksi.

- Alamat kertas : https://arxiv.org/abs/2305.13246
- Sumber projek: https://github.com/InteractiveNLP-Team
- Kepada industri: Jika model besar mempunyai masalah yang sukar untuk diselesaikan seperti fakta dan ketepatan masa, bolehkah ChatGPT+X menyelesaikannya? Walaupun seperti Pemalam ChatGPT, biarkan ia berinteraksi dengan alatan untuk membantu kami menempah tiket, memesan makanan dan melukis gambar dalam satu langkah! Dalam erti kata lain, kita boleh mengurangkan beberapa batasan model besar semasa melalui beberapa rangka kerja teknikal yang sistematik.
-
Kepada akademia: Apakah AGI sebenar? Malah, seawal tahun 2020, Yoshua Bengio, salah satu daripada tiga gergasi pembelajaran mendalam dan pemenang Anugerah Turing, menerangkan pelan tindakan untuk model bahasa interaktif [1]: model bahasa yang boleh berinteraksi dengan persekitaran dan juga berinteraksi secara sosial. dengan agen lain Hanya dengan cara ini kita boleh mempunyai perwakilan semantik bahasa yang paling komprehensif. Pada tahap tertentu, interaksi dengan alam sekitar dan manusia mewujudkan kecerdasan manusia.
Apakah itu interaksi?
Sebenarnya konsep “interaksi” tidak dibayangkan oleh pengarang. Sejak kemunculan ChatGPT, banyak kertas kerja telah diterbitkan mengenai isu baharu dalam dunia NLP, seperti:
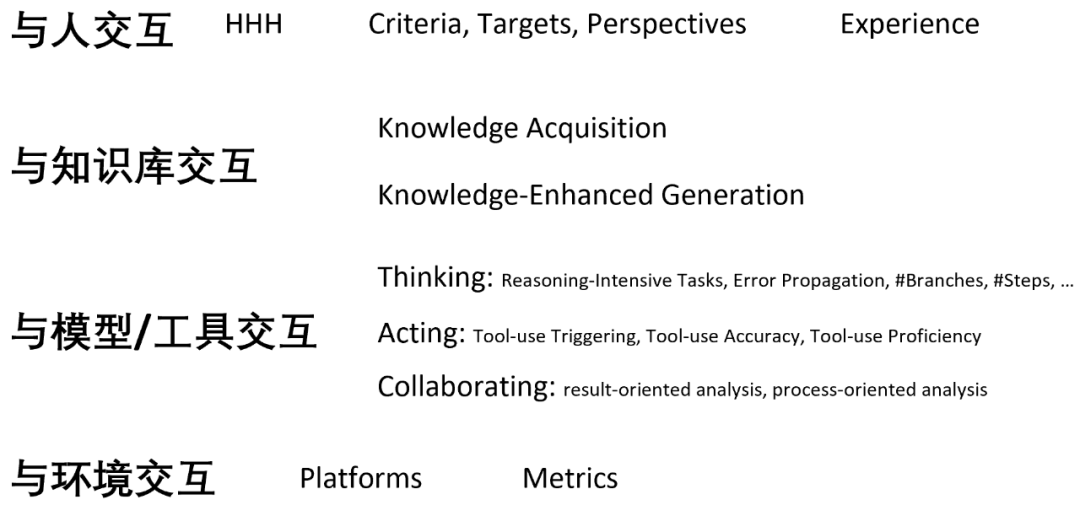
LM berinteraksi dengan manusia untuk lebih memahami dan memenuhi keperluan pengguna, respons yang diperibadikan dan penjajaran dengan nilai kemanusiaan ), dan menambah baik keseluruhan pengalaman pengguna;

- LM berinteraksi dengan model dan alatan untuk mengurai dan menyelesaikan tugasan penaakulan yang kompleks dengan berkesan, menggunakan pengetahuan khusus untuk mengendalikan subtugas tertentu, dan menggalakkan kemunculan tingkah laku sosial ejen; > LM berinteraksi dengan alam sekitar untuk mempelajari asas bahasa dan mengendalikan tugasan yang terkandung secara berkesan yang berkaitan dengan pemerhatian alam sekitar seperti penaakulan, perancangan dan membuat keputusan .
- Oleh itu, dalam kerangka interaktif, model bahasa bukan lagi model bahasa itu sendiri, tetapi model yang boleh "diperhatikan" dan "dilakonkan" , berasaskan bahasa. ejen yang boleh "dapat maklum balas".
- Berinteraksi dengan objek, pengarang memanggilnya "XXX-in-the-loop", menunjukkan bahawa objek ini mengambil bahagian dalam proses latihan model bahasa atau inferens, dan berdasarkan Satu bentuk lata, gelung, maklum balas atau lelaran terlibat. Berinteraksi dengan orang lain
Biarkan model bahasa berinteraksi dengan orang Interaksi boleh dibahagikan kepada tiga cara:
Gunakan gesaan untuk berkomunikasi
Gunakan maklum balas untuk belajar
- Gunakan konfigurasi untuk melaraskan
- Selain itu, untuk memastikan penggunaan berskala, model atau program sering digunakan untuk mensimulasikan tingkah laku atau pilihan manusia, yang adalah, simulasi daripada kajian sekolah menengah manusia.
- Secara umumnya, masalah teras yang perlu diselesaikan dalam interaksi manusia ialah penjajaran, iaitu bagaimana untuk menjadikan tindak balas model bahasa lebih selaras dengan keperluan pengguna dan banyak lagi. membantu. Ia tidak berbahaya dan berasas, membolehkan pengguna mendapat pengalaman pengguna yang lebih baik.
"Berkomunikasi menggunakan gesaan" terutamanya tertumpu pada sifat interaksi masa nyata dan berterusan, iaitu, ia menekankan sifat berterusan pelbagai pusingan dialog. Ini selaras dengan idea AI Perbualan [8]. Iaitu, melalui beberapa pusingan dialog, biarkan pengguna terus bertanya, supaya tindak balas model bahasa perlahan-lahan sejajar dengan keutamaan pengguna semasa dialog. Pendekatan ini biasanya tidak memerlukan pelarasan parameter model semasa interaksi.
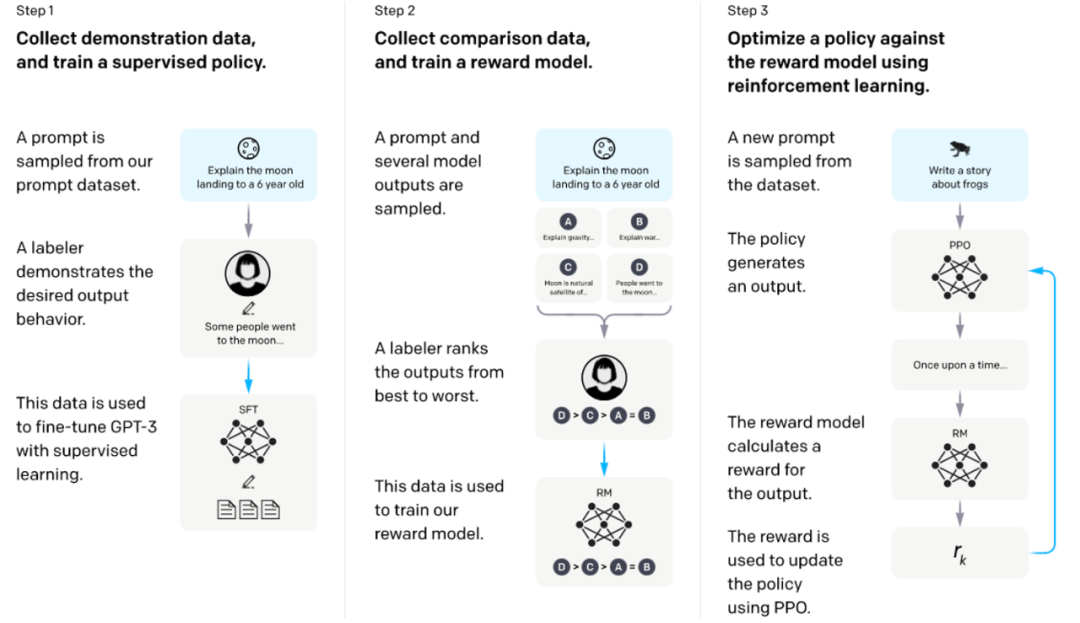
"Belajar menggunakan maklum balas" ialah cara penjajaran utama pada masa ini, iaitu membenarkan pengguna memberi maklum balas kepada respons model bahasa ini boleh menjadi "baik/buruk". yang menerangkan keutamaan ” anotasi juga boleh menjadi maklum balas yang lebih terperinci dalam bentuk bahasa semula jadi. Model perlu dilatih untuk membuat maklum balas ini setinggi mungkin. Contoh biasa ialah RLHF [7] yang digunakan oleh InstructGPT Ia mula-mula menggunakan data maklum balas keutamaan berlabel pengguna untuk respons model untuk melatih model ganjaran, dan kemudian menggunakan model ganjaran ini untuk melatih model bahasa dengan algoritma RL tertentu untuk memaksimumkan ganjaran. (seperti yang ditunjukkan di bawah) ).

Melatih model bahasa untuk mengikuti arahan dengan maklum balas manusia [7]
"Gunakan konfigurasi untuk melaraskan" ialah kaedah interaksi khas yang membolehkan pengguna melaraskan secara langsung hiperparameter model bahasa (seperti suhu), atau mod lata model bahasa, dsb. Contoh biasa ialah Rangkaian AI Google [9]. Model bahasa dengan gesaan pratetap yang berbeza disambungkan antara satu sama lain untuk membentuk rantaian penaakulan untuk memproses tugasan yang diperkemas. Pengguna boleh melaraskan kaedah sambungan nod ini melalui seret dan lepas UI.
"Belajar daripada simulasi manusia" boleh menggalakkan penggunaan berskala besar bagi tiga kaedah di atas, kerana terutamanya dalam proses latihan, menggunakan pengguna sebenar adalah tidak realistik. Sebagai contoh, RLHF biasanya perlu menggunakan model ganjaran untuk mensimulasikan pilihan pengguna. Contoh lain ialah ITG Microsoft Research [10], yang menggunakan model oracle untuk mensimulasikan tingkah laku penyuntingan pengguna.
Baru-baru ini, Profesor Stanford Percy Liang dan yang lain telah membina skema penilaian yang sangat sistematik untuk interaksi Manusia-LM: Menilai Interaksi Model Bahasa Manusia [11], pembaca yang berminat boleh Rujuk kertas ini atau teks asal.
Berinteraksi dengan pangkalan pengetahuan
Terdapat tiga langkah untuk model bahasa berinteraksi dengan asas pengetahuan:
- Tentukan sumber ilmu tambahan: Sumber Ilmu
- Mendapatkan kembali pengetahuan: Mendapatkan Pengetahuan
- Gunakan pengetahuan untuk meningkatkan: Sila rujuk bahagian Gabungan Mesej Interaksi kertas ini untuk butirannya, dan saya tidak akan memperkenalkannya di sini.
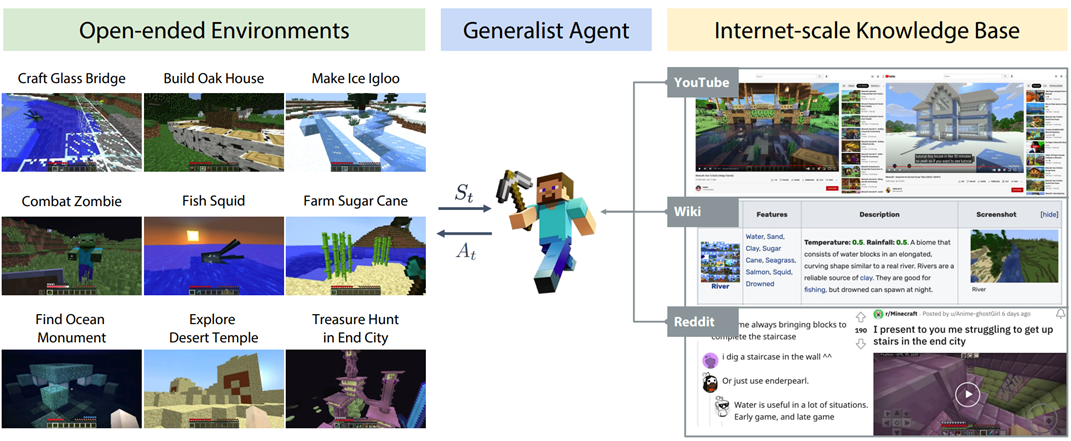
Secara umumnya, berinteraksi dengan pangkalan pengetahuan boleh mengurangkan "halusinasi" model bahasa, iaitu, meningkatkan fakta, ketepatan, dan lain-lain outputnya juga boleh membantu meningkatkan ketepatan masa model bahasa, membantu menambah pengetahuan dan keupayaan model bahasa (seperti yang ditunjukkan di bawah), dsb.
MineDojo [16]: Apabila ejen model bahasa menemui tugas yang tidak diketahui, ia boleh belajar daripada asas pengetahuan Cari bahan kajian, dan kemudian selesaikan tugasan ini dengan bantuan bahan.
"Sumber Pengetahuan" terbahagi kepada dua jenis, satu pengetahuan korpus tertutup (Corpus Knowledge), seperti WikiText, dsb.[15]; ialah pengetahuan rangkaian terbuka (Internet Knowledge), seperti pengetahuan yang boleh diperolehi menggunakan enjin carian [14].
“Pencarian Pengetahuan” dibahagikan kepada empat kaedah:
- Perwakilan jarang berasaskan bahasa dan pemadanan leksikal perolehan jarang (pendapatan jarang): seperti padanan n-gram, BM25, dsb.
- Pendapatan padat (pendapatan padat) berdasarkan perwakilan padat berasaskan bahasa dan padanan semantik: seperti menggunakan model menara tunggal atau dwi-menara sebagai retriever, dsb.
- Berdasarkan carian generatif: Ia adalah kaedah yang agak baharu. Kerja yang mewakili ialah Indeks Carian Boleh Dibezakan oleh Google Tay Yi et al. [12], yang menjimatkan pengetahuan dalam parameter. model bahasa, selepas memberikan pertanyaan, keluarkan secara langsung id dokumen atau kandungan dokumen pengetahuan yang sepadan kerana model bahasa adalah pangkalan pengetahuan [13]!
- Berdasarkan pembelajaran pengukuhan: Ia juga merupakan kaedah yang agak canggih seperti OpenAI's WebGPT [14] menggunakan maklum balas manusia untuk melatih model untuk mendapatkan pengetahuan yang betul.
Berinteraksi dengan model atau alatan
Model bahasa berinteraksi dengan model atau alatan, terutamanya Tujuannya adalah untuk menguraikan tugas-tugas yang kompleks, seperti menguraikan tugas-tugas penaakulan kompleks kepada beberapa sub-tugas, yang juga merupakan idea teras Rantaian Pemikiran [17]. Subtugas yang berbeza boleh diselesaikan menggunakan model atau alat dengan keupayaan yang berbeza Contohnya, tugasan pengkomputeran boleh diselesaikan menggunakan kalkulator, dan tugas mendapatkan semula boleh diselesaikan menggunakan model perolehan. Oleh itu, interaksi jenis ini bukan sahaja dapat meningkatkan keupayaan penaakulan, perancangan, dan membuat keputusan model bahasa, tetapi juga mengurangkan batasan model bahasa seperti "halusinasi" dan output yang tidak tepat. Khususnya, apabila alat digunakan untuk melaksanakan sub-tugas tertentu, ia mungkin mempunyai kesan tertentu pada dunia luar, seperti menggunakan API WeChat untuk menyiarkan kalangan rakan, dsb., yang dipanggil "Berorientasikan Alat Pembelajaran" [ 2].
Selain itu, kadangkala sukar untuk menguraikan tugas yang kompleks secara eksplisit. Dalam kes ini, peranan atau kemahiran yang berbeza boleh diberikan kepada model bahasa yang berbeza, dan kemudian Biarkan model bahasa ini secara tersirat dan automatik membentuk pembahagian kerja semasa proses kerjasama dan komunikasi bersama untuk mengurai tugas. Jenis interaksi ini bukan sahaja dapat memudahkan proses penyelesaian tugas yang kompleks, tetapi juga mensimulasikan masyarakat manusia dan membina beberapa bentuk masyarakat ejen pintar.
Pengarang menggabungkan model dan alatan, terutamanya kerana model dan alatan tidak semestinya dua kategori yang berasingan, contohnya, alat enjin carian dan model retriever tidak penting. Intipati ini ditakrifkan oleh pengarang menggunakan "selepas penguraian tugas, jenis subtugas yang dilakukan oleh objek jenis apa".
Apabila model bahasa berinteraksi dengan model atau alat, terdapat tiga jenis operasi:
- Pemikiran: Model berinteraksi dengan dirinya sendiri , lakukan penguraian tugas dan penaakulan;
- Lakonan: Model memanggil model lain, atau alat luaran, dsb., untuk membantu dengan penaakulan, atau mempunyai kesan sebenar pada dunia luaran ;
- Berkolaborasi: Ejen model berbilang bahasa berkomunikasi dan bekerjasama antara satu sama lain untuk menyelesaikan tugas tertentu atau mensimulasikan tingkah laku sosial manusia.
Nota: Berfikir terutamanya bercakap tentang "Rantaian Pemikiran Pelbagai Peringkat", iaitu: langkah penaakulan yang berbeza, sepadan dengan bahasa Panggilan model yang berbeza (berbilang model run), bukannya menjalankan model sekali dan mengeluarkan pemikiran+jawapan pada masa yang sama (model tunggal dijalankan) seperti Vanilla CoT [17]. ungkapan ReAct [18].
Tugas biasa Pemikiran termasuk ReAct [18], Paling Kurang Mendorong [19], Tanya Sendiri [20], dsb. Sebagai contoh, Least-to-Most Prompting [19] mula-mula menguraikan masalah yang kompleks kepada beberapa sub-masalah modul mudah, dan kemudian secara berulang memanggil model bahasa untuk menyelesaikannya satu demi satu.
Kerja tipikal lakonan termasuk ReAct [18], HuggingGPT [21], Toolformer [22], dsb. Sebagai contoh, Toolformer [22] memproses korpus pra-latihan model bahasa ke dalam bentuk dengan gesaan penggunaan alat Oleh itu, model bahasa terlatih boleh secara automatik memanggil alat yang betul pada masa yang tepat apabila menjana alat luaran (. seperti enjin carian, alat terjemahan, alat masa, kalkulator, dsb.) menyelesaikan sub-masalah tertentu.
Bekerjasama terutamanya termasuk:
- Interaksi gelung tertutup: seperti Model Socratic [23], dsb., melalui bahasa besar model dan model bahasa visual , interaksi gelung tertutup model bahasa audio untuk menyelesaikan tugas QA kompleks tertentu khusus untuk persekitaran visual.
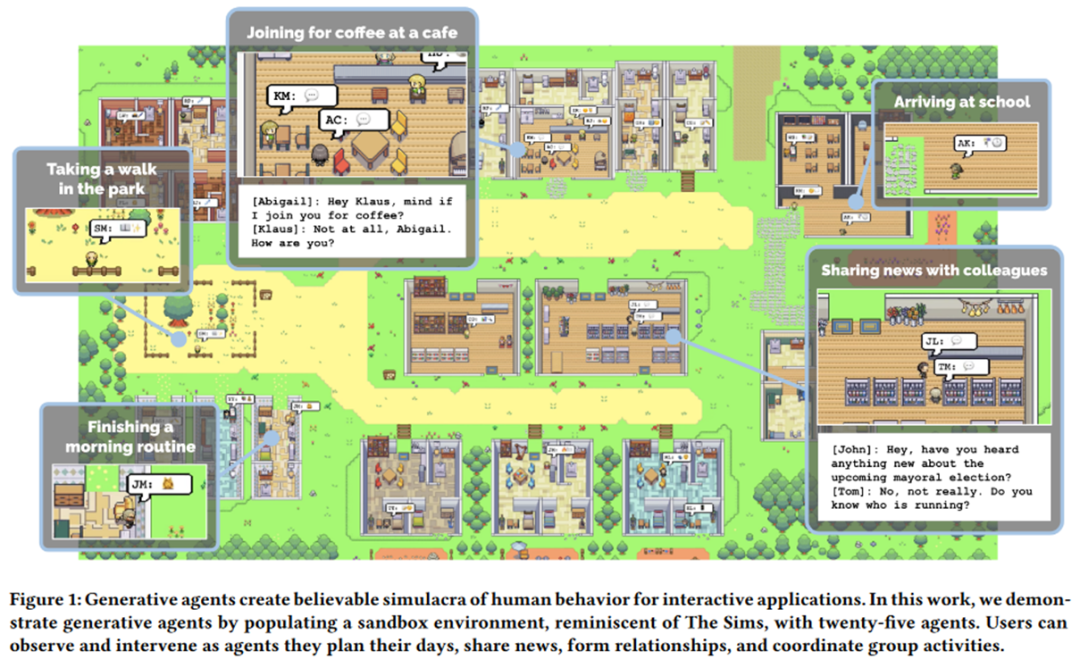
- Teori Minda: Bertujuan untuk membolehkan seorang ejen memahami dan meramalkan keadaan ejen lain untuk menggalakkan interaksi yang cekap antara satu sama lain. Sebagai contoh, Kertas Cemerlang EMNLP 2021, MindCraft [24], memberikan dua model bahasa yang berbeza kemahiran yang berbeza tetapi saling melengkapi, membolehkan mereka bekerjasama untuk menyelesaikan tugas tertentu dalam dunia MineCraft semasa proses komunikasi. Profesor terkenal Graham Neubig juga telah memberi perhatian yang besar kepada arah penyelidikan ini baru-baru ini, seperti [25]. Contoh paling tipikal ialah Ejen Generatif [26] Universiti Stanford yang baru-baru ini mengejutkan dunia: membina persekitaran kotak pasir dan membenarkan banyak ejen pintar yang disuntik dengan "jiwa" daripada model besar untuk bergerak bebas di dalamnya, mereka secara spontan boleh membentangkan beberapa seperti manusia. Tingkah laku sosial, seperti berbual dan bertanya khabar, mempunyai rasa "Dunia Barat" (seperti yang ditunjukkan di bawah). Di samping itu, karya yang lebih terkenal ialah karya baharu CAMEL [27] oleh pengarang DeepGCN, yang membolehkan dua ejen yang diberi kuasa oleh model besar untuk membangunkan permainan dan juga stok stok dalam proses berkomunikasi antara satu sama lain tanpa memerlukan terlalu banyak campur tangan manusia. campur tangan. Penulis dengan jelas mengemukakan konsep “Large Model Society” (LLM Society) dalam artikel tersebut.
Ejen Generatif: Simulakra Interaktif Tingkah Laku Manusia, https://arxiv.org/pdf/2304.03442 .pdfBerinteraksi dengan persekitaran
Model bahasa dan persekitaran tergolong kepada dua kuadran berbeza: model bahasa dibina pada simbol teks abstrak dan mahir dalam penaakulan peringkat tinggi, perancangan, membuat keputusan dan tugas-tugas lain manakala persekitaran dibina di atas isyarat deria tertentu (seperti maklumat visual, maklumat pendengaran , dsb.), dan simulasi Atau beberapa tugas peringkat rendah mungkin berlaku secara semula jadi, seperti menyediakan pemerhatian, maklum balas, peralihan keadaan, dsb. (contohnya: sebiji epal jatuh ke tanah di dunia nyata, dan "menjalar" muncul dalam enjin simulasi di hadapan anda). Oleh itu, untuk membolehkan model bahasa berinteraksi secara berkesan dan cekap dengan persekitaran, ia merangkumi dua aspek usaha:
Asas Modaliti: membolehkan model bahasa memproses maklumat berbilang modal seperti imej dan audio
- Asas Mampu: membolehkan model bahasa menganalisis maklumat yang mungkin dan sesuai pada skala tertentu; senario persekitaran Objek melakukan tindakan yang mungkin dan sesuai.
- Yang paling tipikal untuk Modality Grounding ialah model bahasa visual. Secara umumnya, ia boleh dijalankan menggunakan model menara tunggal seperti OFA [28], model dua menara seperti BridgeTower [29], atau interaksi model bahasa dan model visual seperti BLIP-2 [30]. Tiada butiran lanjut akan dinyatakan di sini, pembaca boleh merujuk kertas ini untuk butirannya.
Terdapat dua pertimbangan utama untuk Affordance Grounding, iaitu: cara melaksanakan (1) persepsi skala adegan (persepsi skala adegan) di bawah syarat tugasan yang diberikan, dan (2 ) tindakan yang mungkin. Contohnya:
Sebagai contoh, dalam adegan di atas, tugasan yang diberikan "Sila tutup lampu di ruang tamu" dan "Persepsi skala pemandangan" memerlukan kami mencari semua lampu dengan kotak merah, bukannya memilih yang hijau yang tidak ada di ruang tamu tetapi di dapur Untuk lampu yang dibulatkan, "tindakan yang mungkin" memerlukan kita untuk menentukan cara yang boleh dilakukan untuk mematikan lampu Sebagai contoh, menarik lampu tali memerlukan tindakan "tarik". dan menghidupkan dan mematikan lampu memerlukan tindakan "suis togol".
Secara amnya, Affordance Grounding boleh diselesaikan menggunakan fungsi nilai yang bergantung pada persekitaran, seperti SayCan [31], dsb., atau model pembumian khusus seperti Grounded Decoding [ 32] tunggu. Ia juga boleh diselesaikan dengan berinteraksi dengan orang, model, alatan, dll. (seperti yang ditunjukkan di bawah).
Monolog Dalaman [33]
Apakah interaksi itu digunakan :Antaramuka Interaksi
Dalam bab Antaramuka Interaksi kertas kerja, penulis secara sistematik membincangkan penggunaan, kebaikan dan keburukan interaksi yang berbeza bahasa dan media interaksi , termasuk:
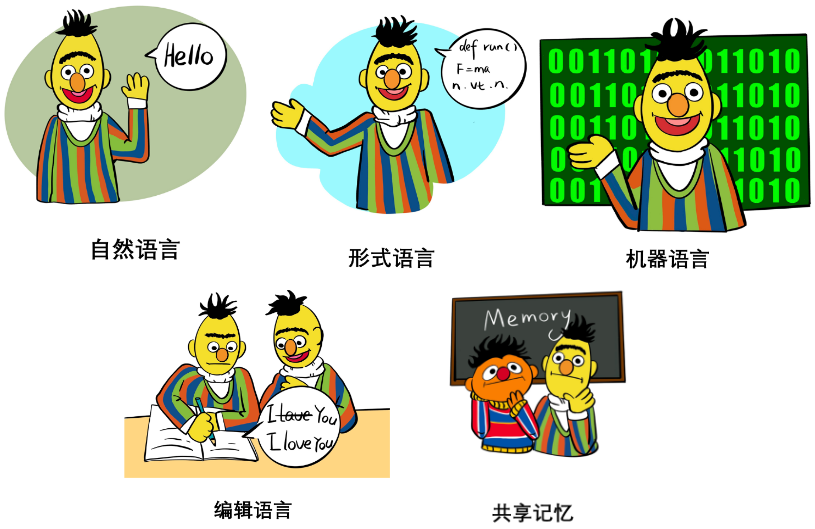
- Bahasa semula jadi: seperti contoh beberapa pukulan, arahan tugas, penugasan peranan dan juga bahasa semula jadi berstruktur, dsb. Ciri-ciri dan fungsinya dalam generalisasi dan ekspresitiviti dibincangkan terutamanya.
- Bahasa formal: seperti kod, tatabahasa, formula matematik, dsb. Ciri-ciri dan fungsinya dalam parsability dan keupayaan penaakulan dibincangkan terutamanya.
- Bahasa mesin: seperti gesaan lembut, token visual diskret, dsb. Ciri-ciri dan fungsinya dalam generalisasi, teori kesesakan maklumat, kecekapan interaksi, dll. terutamanya dibincangkan.
- Pengeditan: Ini terutamanya termasuk operasi seperti memadam, memasukkan, menggantikan dan mengekalkan teks. Prinsip, sejarah, kelebihan, dan batasan semasa dibincangkan.
- Memori dikongsi: terutamanya termasuk memori keras dan memori lembut yang pertama merekodkan status sejarah dalam log sebagai memori, dan yang kedua menggunakan modul luaran memori yang boleh dibaca dan boleh ditulis untuk menyimpannya. Tensor. Kertas kerja membincangkan ciri, fungsi dan batasan kedua-duanya.
Cara berinteraksi: kaedah interaksi
Kertas ini juga membincangkannya secara menyeluruh, dalam terperinci dan sistematik Pelbagai kaedah interaksi, terutamanya termasuk:
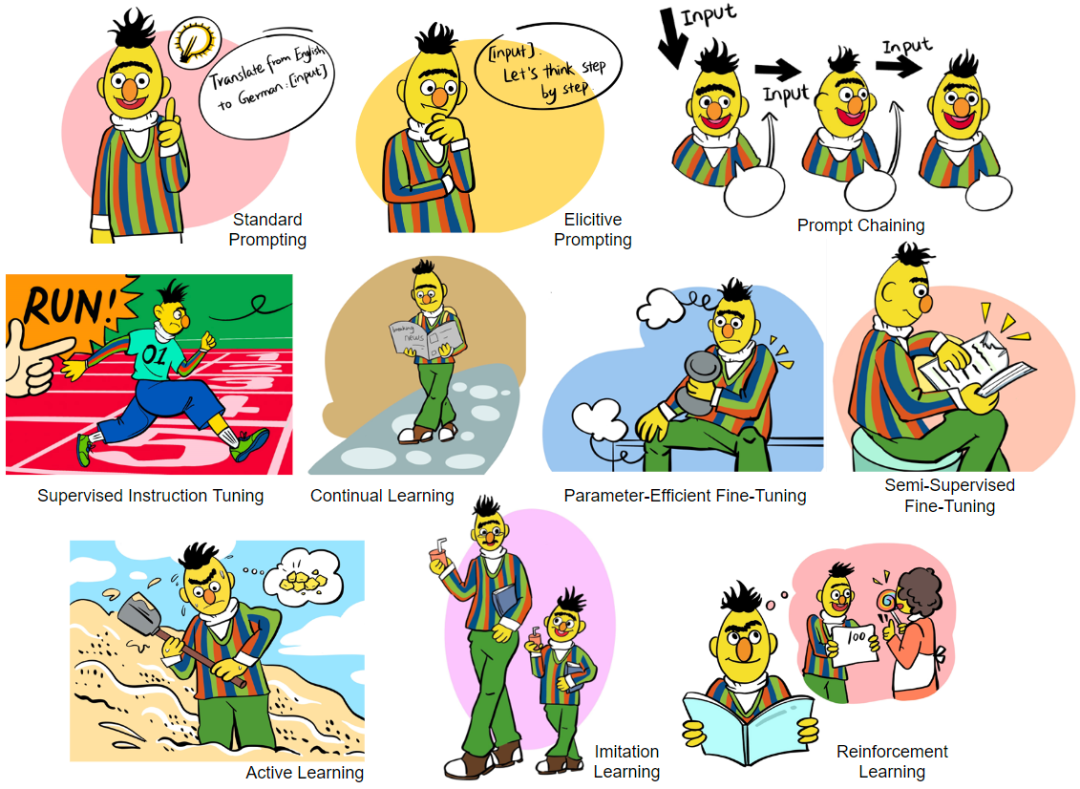
- Mendorong: Tanpa melaraskan parameter model, model bahasa hanya dipanggil melalui kejuruteraan segera, meliputi Pembelajaran Dalam Konteks, Rantaian Pemikiran dan petua penggunaan alat ( Penggunaan alat), rantaian penaakulan lata ( Prompt Chaining) dan kaedah lain, prinsip, fungsi, pelbagai helah dan batasan pelbagai teknik dorongan dibincangkan secara terperinci, seperti pertimbangan kebolehkawalan dan keteguhan, dsb.
- Penalaan Halus: Laraskan parameter model untuk membolehkan model belajar dan mengemas kini daripada maklumat interaktif. Bahagian ini merangkumi kaedah seperti Penalaan Arahan Terselia, Penalaan Halus Cekap Parameter, Pembelajaran Berterusan dan Penalaan Halus Separuh Penyeliaan. Prinsip, fungsi, kelebihan, pertimbangan dalam penggunaan khusus, dan batasan kaedah ini dibincangkan secara terperinci. Ia juga termasuk sebahagian daripada Penyuntingan Pengetahuan (iaitu, menyunting pengetahuan di dalam model).
- Pembelajaran Aktif: Rangka kerja algoritma pembelajaran aktif interaktif.
- Pembelajaran Pengukuhan: Rangka kerja algoritma pembelajaran pengukuhan interaktif, membincangkan rangka kerja pembelajaran pengukuhan dalam talian, rangka kerja pembelajaran pengukuhan luar talian, pembelajaran daripada maklum balas manusia (RLHF), pembelajaran daripada maklum balas alam sekitar ( RLEF), pembelajaran daripada Maklum balas AI (RLAIF) dan kaedah lain.
- Pembelajaran Tiruan: Rangka kerja algoritma pembelajaran tiruan interaktif, membincangkan pembelajaran tiruan dalam talian, pembelajaran tiruan luar talian, dsb.
- Penggabungan Mesej Interaksi: Menyediakan rangka kerja bersatu untuk semua kaedah interaksi di atas Pada masa yang sama, dalam rangka kerja ini, ia berkembang ke luar dan membincangkan penyelesaian gabungan pengetahuan dan maklumat yang berbeza, seperti. silang- Skim gabungan perhatian (perhatian silang), skema gabungan penyahkodan terkekang (penyahkodan terkekang), dsb.
Perbincangan lain
Disebabkan had ruang, artikel ini tidak memperincikan perbincangan lain, seperti penilaian, aplikasi, etika, keselamatan dan arahan pembangunan masa hadapan. Walau bagaimanapun, kandungan ini masih menduduki 15 halaman dalam teks asal kertas, jadi pembaca disyorkan untuk melihat lebih banyak butiran dalam teks asal Berikut ialah garis besar kandungan ini:
Penilaian interaksi
Perbincangan penilaian dalam kertas kerja terutamanya melibatkan kata kunci berikut:
Aplikasi utama NLP interaktif
Berinteraksi dengan model dan alatan: CTG Berpandukan Pengelas dsb. - Berinteraksi dengan persekitaran: kemampuan pembumian dll.
- Pembantu Penulisan Interaktif (Pembantu Penulisan) Kandungan Sokongan: Jenis sokongan kandungan


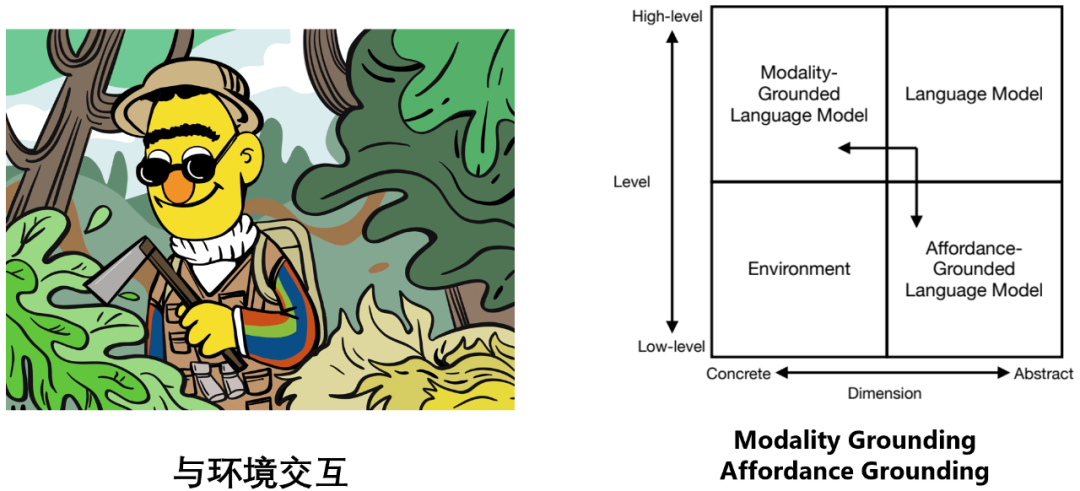 Model bahasa dan persekitaran tergolong kepada dua kuadran berbeza: model bahasa dibina pada simbol teks abstrak dan mahir dalam penaakulan peringkat tinggi, perancangan, membuat keputusan dan tugas-tugas lain manakala persekitaran dibina di atas isyarat deria tertentu (seperti maklumat visual, maklumat pendengaran , dsb.), dan simulasi Atau beberapa tugas peringkat rendah mungkin berlaku secara semula jadi, seperti menyediakan pemerhatian, maklum balas, peralihan keadaan, dsb. (contohnya: sebiji epal jatuh ke tanah di dunia nyata, dan "menjalar" muncul dalam enjin simulasi di hadapan anda).
Model bahasa dan persekitaran tergolong kepada dua kuadran berbeza: model bahasa dibina pada simbol teks abstrak dan mahir dalam penaakulan peringkat tinggi, perancangan, membuat keputusan dan tugas-tugas lain manakala persekitaran dibina di atas isyarat deria tertentu (seperti maklumat visual, maklumat pendengaran , dsb.), dan simulasi Atau beberapa tugas peringkat rendah mungkin berlaku secara semula jadi, seperti menyediakan pemerhatian, maklum balas, peralihan keadaan, dsb. (contohnya: sebiji epal jatuh ke tanah di dunia nyata, dan "menjalar" muncul dalam enjin simulasi di hadapan anda). 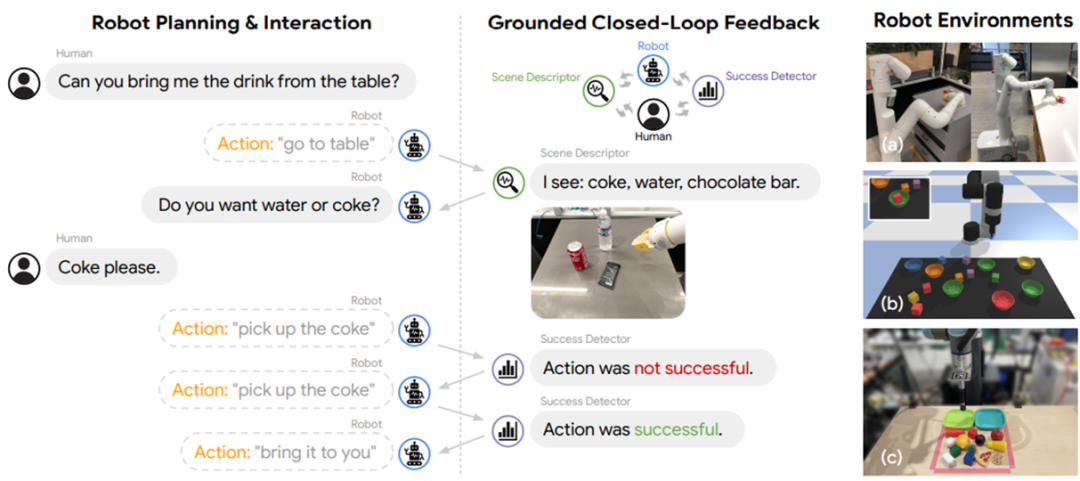
- Pemeriksaan dan Penggilapan Kandungan: Jenis penyemakan dan penggilapan kandungan
- Pengayaan Kandungan: Jenis pengayaan kandungan
- Penciptaan Bersama Kandungan: Penciptaan Kandungan
- AI Terjelma
-
- Permainan (Permainan Teks)
- Platform Permainan Interaktif yang mengandungi teks: Platform Permainan Teks Interaktif
- Betapa interaktifnya model bahasa boleh menguasakan permainan teks sahaja: Bermain Permainan Teks Sahaja
- Cara model bahasa interaktif boleh menguasai permainan yang termasuk media teks: Memperkasakan Permainan Berbantukan Teks
- Aplikasi lain
- Pengkhususan bidang dan tugas (Pengkhususan): Contohnya, cara mencipta rangka kerja model bahasa khusus untuk bidang kewangan, bidang perubatan, dsb. berdasarkan interaksi .
- Peribadi & Keperibadian: Contohnya, cara mencipta model bahasa khusus kepada pengguna atau dengan personaliti tertentu berdasarkan interaksi.
- Penilaian Berasaskan Model
Etika dan Keselamatan
Membincangkan kesan model bahasa interaktif terhadap pendidikan, dan turut membincangkan isu etika dan keselamatan seperti berat sebelah sosial dan privasi.
Hal Tuju Pembangunan Masa Depan dan Cabaran
- Penjajaran: Masalah penjajaran model bahasa, bagaimana untuk menjadikan output model lebih tidak berbahaya, lebih sesuai dengan nilai kemanusiaan, lebih munasabah, dsb.
- Penjelmaan Sosial: Masalah asas model bahasa, bagaimana untuk menggalakkan lagi penjelmaan dan sosialisasi model bahasa.
- Keplastikan: Isu keplastikan model bahasa, cara memastikan pengemaskinian berterusan pengetahuan model tanpa melupakan pengetahuan yang diperoleh sebelum ini semasa proses kemas kini.
- Kelajuan & Kecekapan: Isu seperti kelajuan inferens dan kecekapan latihan model bahasa, cara mempercepatkan inferens tanpa menjejaskan prestasi dan kecekapan latihan dipercepat.
- Panjang Konteks: Had saiz tetingkap konteks model bahasa. Cara mengembangkan saiz tetingkap konteks supaya ia boleh mengendalikan teks yang lebih panjang.
- Penjanaan Teks Panjang: Masalah penjanaan teks panjang model bahasa. Cara menjadikan model bahasa mengekalkan prestasi cemerlang dalam senario penjanaan teks yang sangat panjang.
- Kebolehaksesan: Isu ketersediaan model bahasa. Cara membuat model bahasa daripada sumber tertutup kepada sumber terbuka dan cara membolehkan model bahasa digunakan pada peranti pinggir seperti sistem kenderaan dan komputer riba tanpa kehilangan prestasi yang berlebihan.
- Analisis: Analisis model bahasa, kebolehtafsiran dan isu lain. Contohnya, bagaimana untuk meramalkan prestasi model selepas ditingkatkan untuk membimbing pembangunan model besar, cara menerangkan mekanisme dalaman model besar, dsb.
- Kreativiti: Isu kreatif dalam model bahasa. Bagaimana untuk menjadikan model bahasa lebih kreatif, lebih mampu menggunakan metafora, metafora, dll., dan mencipta pengetahuan baru, dsb.
- Penilaian: Cara menilai model besar am dengan lebih baik, cara menilai ciri interaktif model bahasa, dsb.
Atas ialah kandungan terperinci Apa lagi yang boleh dilakukan oleh NLP? Universiti Beihang, ETH, Universiti Sains dan Teknologi Hong Kong, Akademi Sains China dan institusi lain bersama-sama mengeluarkan kertas setebal seratus muka surat untuk menerangkan secara sistematik rantaian teknologi pasca-ChatGPT. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1374
1374
 52
52

 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
 Apr 09, 2024 am 11:52 AM
Apr 09, 2024 am 11:52 AM
AI memang mengubah matematik. Baru-baru ini, Tao Zhexuan, yang telah mengambil perhatian terhadap isu ini, telah memajukan keluaran terbaru "Buletin Persatuan Matematik Amerika" (Buletin Persatuan Matematik Amerika). Memfokuskan pada topik "Adakah mesin akan mengubah matematik?", ramai ahli matematik menyatakan pendapat mereka Seluruh proses itu penuh dengan percikan api, tegar dan menarik. Penulis mempunyai barisan yang kuat, termasuk pemenang Fields Medal Akshay Venkatesh, ahli matematik China Zheng Lejun, saintis komputer NYU Ernest Davis dan ramai lagi sarjana terkenal dalam industri. Dunia AI telah berubah secara mendadak Anda tahu, banyak artikel ini telah dihantar setahun yang lalu.
 Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Prestasi JAX, yang dipromosikan oleh Google, telah mengatasi Pytorch dan TensorFlow dalam ujian penanda aras baru-baru ini, menduduki tempat pertama dalam 7 penunjuk. Dan ujian tidak dilakukan pada TPU dengan prestasi JAX terbaik. Walaupun dalam kalangan pembangun, Pytorch masih lebih popular daripada Tensorflow. Tetapi pada masa hadapan, mungkin lebih banyak model besar akan dilatih dan dijalankan berdasarkan platform JAX. Model Baru-baru ini, pasukan Keras menanda aras tiga hujung belakang (TensorFlow, JAX, PyTorch) dengan pelaksanaan PyTorch asli dan Keras2 dengan TensorFlow. Pertama, mereka memilih satu set arus perdana
 Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Video terbaru robot Tesla Optimus dikeluarkan, dan ia sudah boleh berfungsi di kilang. Pada kelajuan biasa, ia mengisih bateri (bateri 4680 Tesla) seperti ini: Pegawai itu juga mengeluarkan rupanya pada kelajuan 20x - pada "stesen kerja" kecil, memilih dan memilih dan memilih: Kali ini ia dikeluarkan Salah satu sorotan video itu ialah Optimus menyelesaikan kerja ini di kilang, sepenuhnya secara autonomi, tanpa campur tangan manusia sepanjang proses. Dan dari perspektif Optimus, ia juga boleh mengambil dan meletakkan bateri yang bengkok, memfokuskan pada pembetulan ralat automatik: Berkenaan tangan Optimus, saintis NVIDIA Jim Fan memberikan penilaian yang tinggi: Tangan Optimus adalah robot lima jari di dunia paling cerdik. Tangannya bukan sahaja boleh disentuh
 FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
Pengesanan objek ialah masalah yang agak matang dalam sistem pemanduan autonomi, antaranya pengesanan pejalan kaki adalah salah satu algoritma terawal untuk digunakan. Penyelidikan yang sangat komprehensif telah dijalankan dalam kebanyakan kertas kerja. Walau bagaimanapun, persepsi jarak menggunakan kamera fisheye untuk pandangan sekeliling agak kurang dikaji. Disebabkan herotan jejari yang besar, perwakilan kotak sempadan standard sukar dilaksanakan dalam kamera fisheye. Untuk mengurangkan perihalan di atas, kami meneroka kotak sempadan lanjutan, elips dan reka bentuk poligon am ke dalam perwakilan kutub/sudut dan mentakrifkan metrik mIOU pembahagian contoh untuk menganalisis perwakilan ini. Model fisheyeDetNet yang dicadangkan dengan bentuk poligon mengatasi model lain dan pada masa yang sama mencapai 49.5% mAP pada set data kamera fisheye Valeo untuk pemanduan autonomi
 Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
FP8 dan ketepatan pengiraan titik terapung yang lebih rendah bukan lagi "paten" H100! Lao Huang mahu semua orang menggunakan INT8/INT4, dan pasukan Microsoft DeepSpeed memaksa diri mereka menjalankan FP6 pada A100 tanpa sokongan rasmi daripada Nvidia. Keputusan ujian menunjukkan bahawa kaedah baharu TC-FPx FP6 kuantisasi pada A100 adalah hampir atau kadangkala lebih pantas daripada INT4, dan mempunyai ketepatan yang lebih tinggi daripada yang terakhir. Selain itu, terdapat juga sokongan model besar hujung ke hujung, yang telah bersumberkan terbuka dan disepadukan ke dalam rangka kerja inferens pembelajaran mendalam seperti DeepSpeed. Keputusan ini juga mempunyai kesan serta-merta pada mempercepatkan model besar - di bawah rangka kerja ini, menggunakan satu kad untuk menjalankan Llama, daya pemprosesan adalah 2.65 kali lebih tinggi daripada dua kad. satu
