

Model Besar (LLM) menyediakan hala tuju baharu untuk pembangunan kecerdasan am buatan (AGI), yang menggunakan data awam yang besar, seperti Internet, buku dan korporat lain untuk menjalankan pembelajaran kendiri berskala besar Melalui latihan yang diselia, pemahaman bahasa yang kuat, penjanaan bahasa, penaakulan dan kebolehan lain telah diperolehi. Walau bagaimanapun, model besar masih menghadapi beberapa cabaran dalam menggunakan data domain persendirian merujuk kepada data yang dimiliki oleh syarikat atau individu tertentu dan biasanya mengandungi pengetahuan khusus domain Menggabungkan model besar dengan pengetahuan domain persendirian akan Memberikan nilai yang besar.
Pengetahuan domain peribadi boleh dibahagikan kepada data tidak berstruktur dan berstruktur dari segi bentuk data. Data tidak berstruktur, seperti dokumen, biasanya dipertingkatkan melalui pengambilan semula, dan alatan seperti langchain boleh digunakan untuk melaksanakan sistem soal jawab dengan cepat. Data berstruktur, seperti pangkalan data (DB), memerlukan model besar untuk berinteraksi dengan pangkalan data, membuat pertanyaan dan menganalisis untuk mendapatkan maklumat yang berguna. Satu siri produk dan aplikasi baru-baru ini telah diperoleh di sekitar model dan pangkalan data yang besar, seperti menggunakan LLM untuk mencipta pangkalan data pintar, melaksanakan analisis BI dan melengkapkan pembinaan jadual automatik. Antaranya, teknologi teks-ke-SQL, yang berinteraksi dengan pangkalan data dalam bahasa semula jadi, sentiasa menjadi arah yang dinanti-nantikan.
Dalam akademik, penanda aras teks-ke-SQL yang lalu hanya tertumpu pada pangkalan data berskala kecil LLM yang paling maju sudah boleh mencapai ketepatan pelaksanaan sebanyak 85.3%, tetapi adakah ini bermakna LLM. Sudah tersedia sebagai antara muka bahasa semula jadi kepada pangkalan data?
Baru-baru ini, Alibaba, bersama-sama Universiti Hong Kong dan institusi lain, melancarkan penanda aras baharu BIRD (Can LLM already Serve as Pangkalan Data) untuk pangkalan data sebenar berskala besar Antaramuka? 33.4 GB. Model terbaik sebelum ini hanya mencapai 40.08% penilaian terhadap BIRD, yang masih jauh daripada hasil manusia iaitu 92.96%, membuktikan bahawa cabaran masih wujud. Di samping menilai ketepatan SQL, penulis juga menambah penilaian kecekapan pelaksanaan SQL, dengan harapan model itu bukan sahaja boleh menulis SQL yang betul, tetapi juga menulis SQL yang cekap.

Kertas: https://arxiv.org/abs/2305.03111
Halaman utama: https://bird-bench.github.io
Kod: https://github. com/AlibabaResearch/DAMO-ConvAI/tree/main/bird

Pada masa ini, data BIRD, kod , dan senarai itu semuanya bersumberkan terbuka, dan telah dimuat turun lebih daripada 10,000 kali di seluruh dunia. BIRD telah membangkitkan perhatian dan perbincangan meluas di Twitter sejak pelancarannya.


Komen dari pengguna luar negara juga sangat menarik:

Projek LLM yang tidak boleh dilepaskan

Titik pemeriksaan yang sangat berguna, sarang untuk penambahbaikan
AI boleh membantu anda, tetapi ia masih belum dapat menggantikan anda

Pekerjaan saya selamat buat masa ini...
Cabaran Baharu
Penyelidikan ini berorientasikan terutamanya kepada penilaian Teks-ke-SQL pangkalan data sebenar, penanda aras ujian popular pada masa lalu, Spider dan WikiSQL, sebagai contoh, hanya menumpukan pada skema pangkalan data dengan jumlah kandungan pangkalan data yang kecil, mengakibatkan jurang antara penyelidikan akademik dan aplikasi praktikal. BIRD memberi tumpuan kepada tiga cabaran baharu: kandungan pangkalan data yang besar dan sebenar, penaakulan pengetahuan luaran antara soalan bahasa semula jadi dan kandungan pangkalan data, dan kecekapan SQL semasa memproses pangkalan data yang besar.
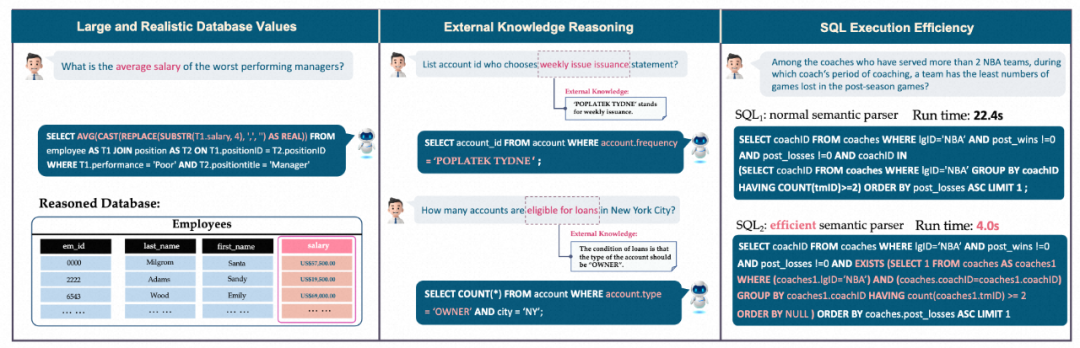
Pertama sekali, pangkalan data mengandungi nilai data yang besar dan bising. Dalam contoh di sebelah kiri, purata gaji perlu dikira dengan menukar rentetan dalam pangkalan data kepada nilai titik terapung (Float) dan kemudian melakukan pengiraan agregasi (Aggregation); > Kedua, inferens pengetahuan luaran diperlukan Dalam contoh tengah, untuk mengembalikan jawapan dengan tepat kepada pengguna, model mesti terlebih dahulu mengetahui bahawa jenis akaun yang layak untuk pinjaman mestilah "PEMILIK", yang mewakili rahsia besar yang tersembunyi. di sebalik kandungan pangkalan data kadangkala memerlukan pengetahuan luaran dan penaakulan untuk didedahkan; Dalam contoh di sebelah kanan, menggunakan pertanyaan SQL yang lebih cekap boleh meningkatkan kelajuan dengan ketara, yang sangat bernilai kepada industri kerana pengguna bukan sahaja mengharapkan untuk menulis SQL yang betul, tetapi juga mengharapkan pelaksanaan SQL yang cekap, terutamanya dalam pangkalan data yang besar. ;
Anotasi Data
BIRD memisahkan penjanaan soalan dan anotasi SQL semasa proses anotasi . Pada masa yang sama, pakar ditambah untuk menulis fail penerangan pangkalan data untuk membantu masalah dan kakitangan anotasi SQL lebih memahami pangkalan data.
1. Pengumpulan pangkalan data: Penulis mengumpul dan memproses 80 pangkalan data daripada platform data sumber terbuka seperti Kaggle dan CTU Prague Relational Learning Repository. Lima belas pangkalan data telah dicipta secara manual sebagai ujian kotak hitam dengan mengumpul data jadual sebenar, membina gambar rajah ER, dan menetapkan kekangan pangkalan data untuk mengelakkan pangkalan data semasa dipelajari oleh model besar semasa. Pangkalan data BIRD mengandungi corak dan nilai dalam pelbagai bidang, 37 bidang, meliputi rantaian blok, sukan, penjagaan perubatan, permainan, dll.
2. Pengumpulan masalah: Pertama, pengarang mengupah pakar untuk menulis fail perihalan untuk pangkalan data Fail perihalan termasuk penerangan lengkap nama lajur, nilai pangkalan data dan parameter luaran digunakan untuk memahami nilai dan sebagainya. Kemudian 11 penutur asli dari Amerika Syarikat, United Kingdom, Kanada, Singapura dan negara lain telah diambil untuk menjana soalan untuk BIRD. Setiap penceramah mempunyai sekurang-kurangnya ijazah sarjana muda ke atas. 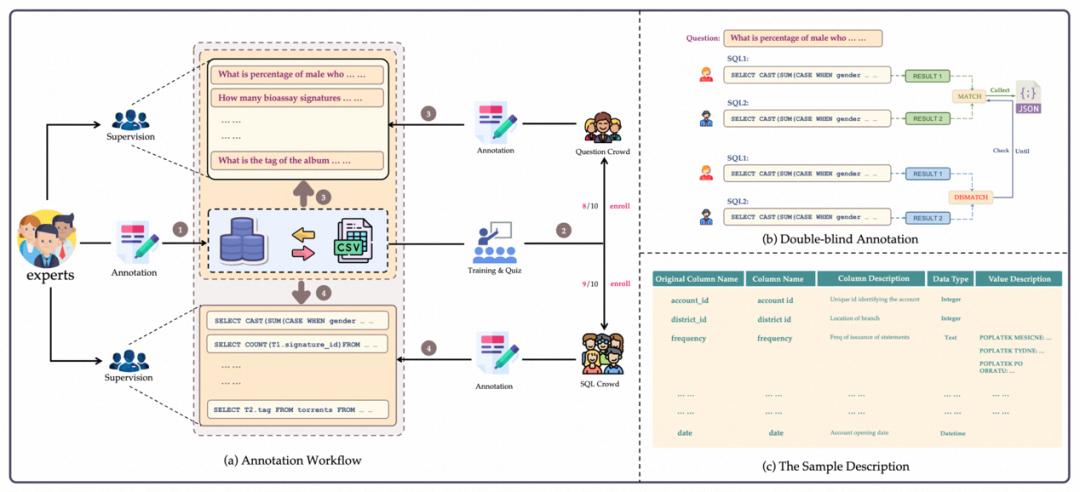
3. Penjanaan SQL: Pasukan anotasi global yang terdiri daripada jurutera data dan pelajar kursus pangkalan data telah diambil untuk menjana SQL untuk BIRD. Memandangkan pangkalan data dan fail perihalan pangkalan data rujukan, anotasi perlu menjana SQL untuk menjawab soalan dengan betul. Kaedah anotasi Double-Blind diguna pakai, memerlukan dua anotasi untuk menjelaskan soalan yang sama. Anotasi dua buta boleh meminimumkan ralat yang disebabkan oleh anotasi tunggal.
4. Pemeriksaan kualiti: Pemeriksaan kualiti terbahagi kepada dua bahagian: keberkesanan dan ketekalan pelaksanaan keputusan. Kesahan bukan sahaja memerlukan ketepatan pelaksanaan, tetapi juga memerlukan keputusan pelaksanaan tidak boleh batal (NULL). Pakar akan mengubah suai keadaan masalah secara beransur-ansur sehingga keputusan pelaksanaan SQL adalah sah.
5. Pembahagian kesukaran: Indeks kesukaran teks-ke-SQL boleh memberikan rujukan kepada penyelidik untuk mengoptimumkan algoritma. Kesukaran Text-to-SQL bergantung bukan sahaja pada kerumitan SQL, tetapi juga pada faktor seperti kesukaran masalah, kemudahan pemahaman dengan pengetahuan tambahan, dan kerumitan pangkalan data. Oleh itu, pengarang meminta pencatat SQL untuk menilai kesukaran semasa proses anotasi dan membahagikan kesukaran kepada tiga kategori: mudah, sederhana dan mencabar.
Statistik data
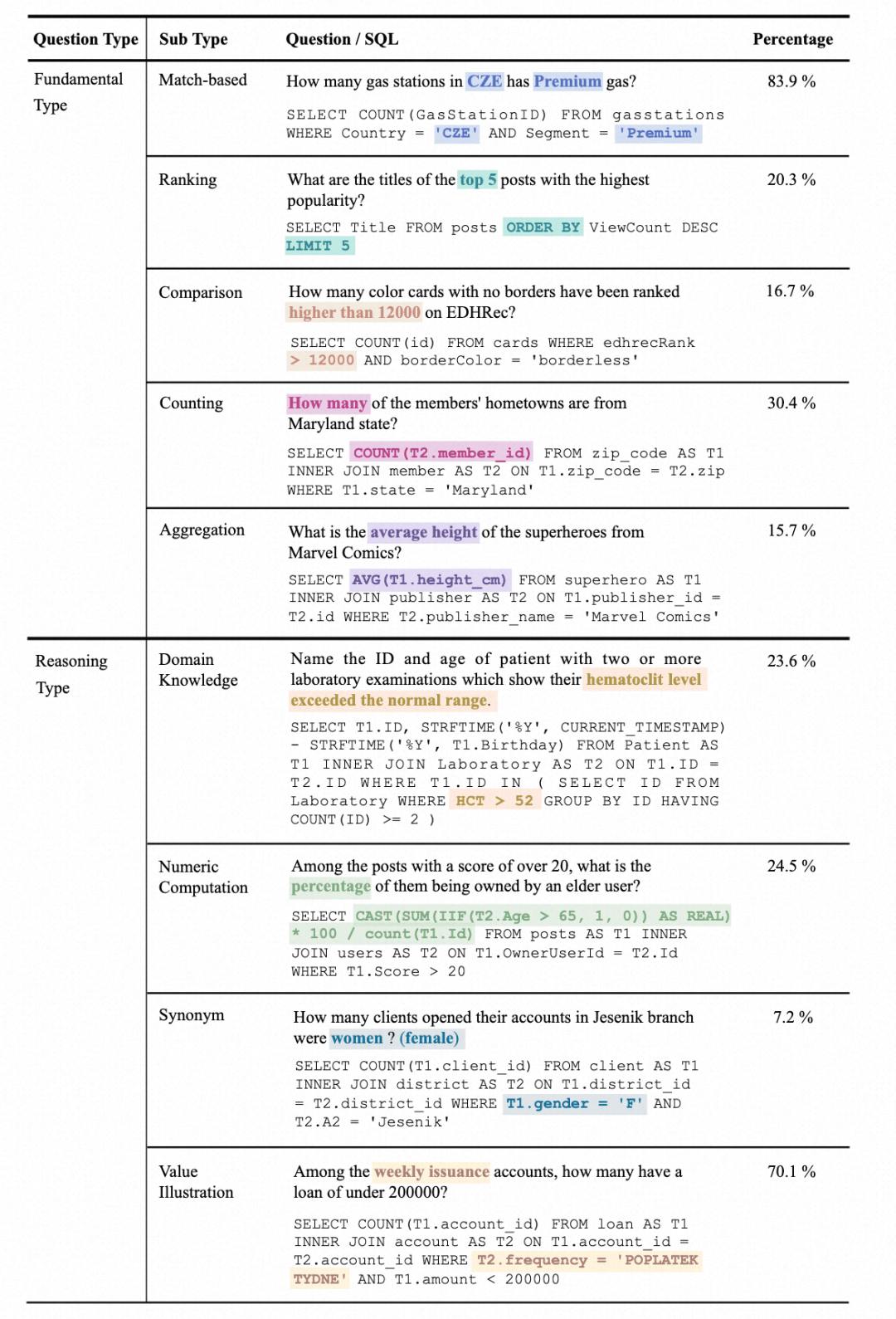
Statistik jenis soalan: Soalan dibahagikan kepada dua kategori, jenis soalan asas (Fundamental Jenis) dan Jenis Penaakulan. Jenis soalan asas termasuk yang diliputi dalam set data Teks-ke-SQL tradisional, manakala jenis soalan inferens termasuk soalan yang memerlukan pengetahuan luaran untuk memahami nilai:
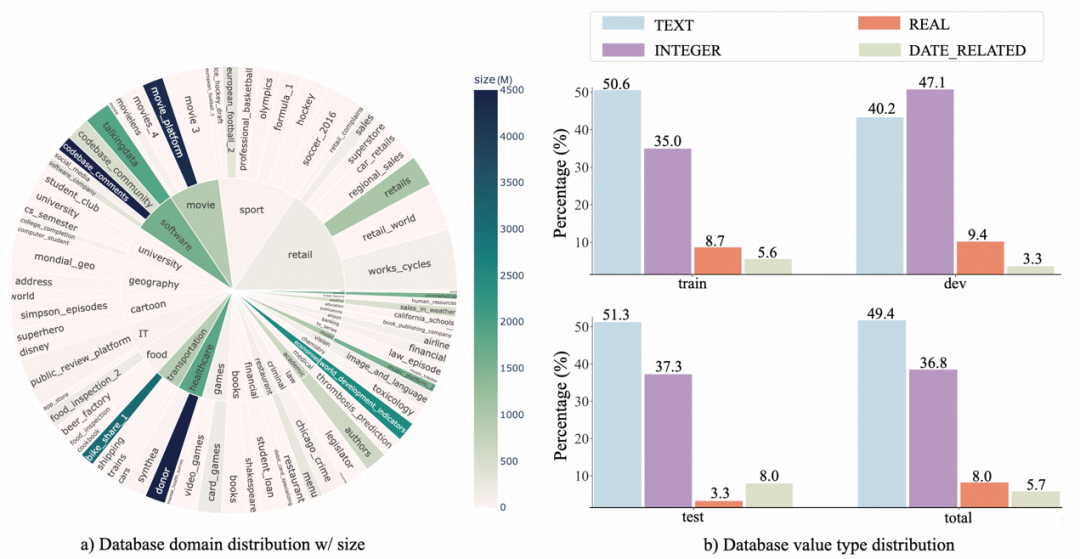
2. Pengedaran pangkalan data: Pengarang menggunakan gambar rajah sunburst untuk menunjukkan hubungan antara domain pangkalan data dan saiz datanya. Jejari yang lebih besar bermakna lebih banyak teks-SQL adalah berdasarkan pangkalan data itu, dan sebaliknya. Lebih gelap warna, lebih besar saiz pangkalan data Contohnya, penderma ialah pangkalan data terbesar dalam penanda aras, menduduki 4.5GB ruang.
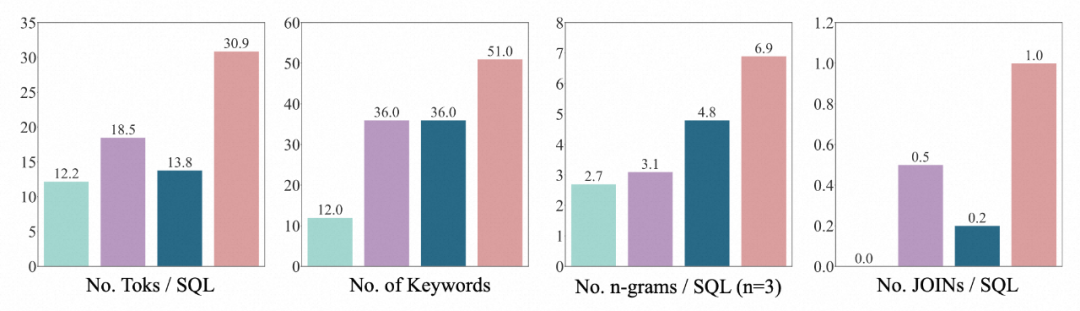
3 Pengedaran SQL: bilangan token pengarang melalui SQL, bilangan kata kunci, bilangan jenis n-gram , JOIN Nombor dan 4 dimensi lain membuktikan bahawa SQL BIRD adalah yang paling pelbagai dan kompleks.
Petunjuk Penilaian
1 Ketepatan: Bandingkan perbezaan antara hasil pelaksanaan SQL yang diramalkan oleh model dan hasil pelaksanaan SQL beranotasi sebenar;
2 , bandingkan ramalan model Perbezaan relatif antara kelajuan pelaksanaan SQL dan kelajuan pelaksanaan SQL beranotasi sebenar mengambil masa berjalan sebagai penunjuk utama kecekapan.
Analisis eksperimen
Pengarang memilih model T5 jenis latihan dan model Bahasa berskala besar (LLM) sebagai model asas: Codex (kod-davinci-002) dan ChatGPT (gpt-3.5-turbo). Untuk lebih memahami sama ada penaakulan pelbagai langkah boleh merangsang keupayaan penaakulan model bahasa besar dalam persekitaran pangkalan data sebenar, versi Rantaian Pemikiran mereka juga disediakan. Dan uji model garis dasar dalam dua tetapan: satu adalah input maklumat skema penuh, dan satu lagi adalah pemahaman manusia tentang nilai pangkalan data yang terlibat dalam masalah, diringkaskan ke dalam huraian bahasa semula jadi (bukti pengetahuan) untuk membantu model memahami pangkalan data .
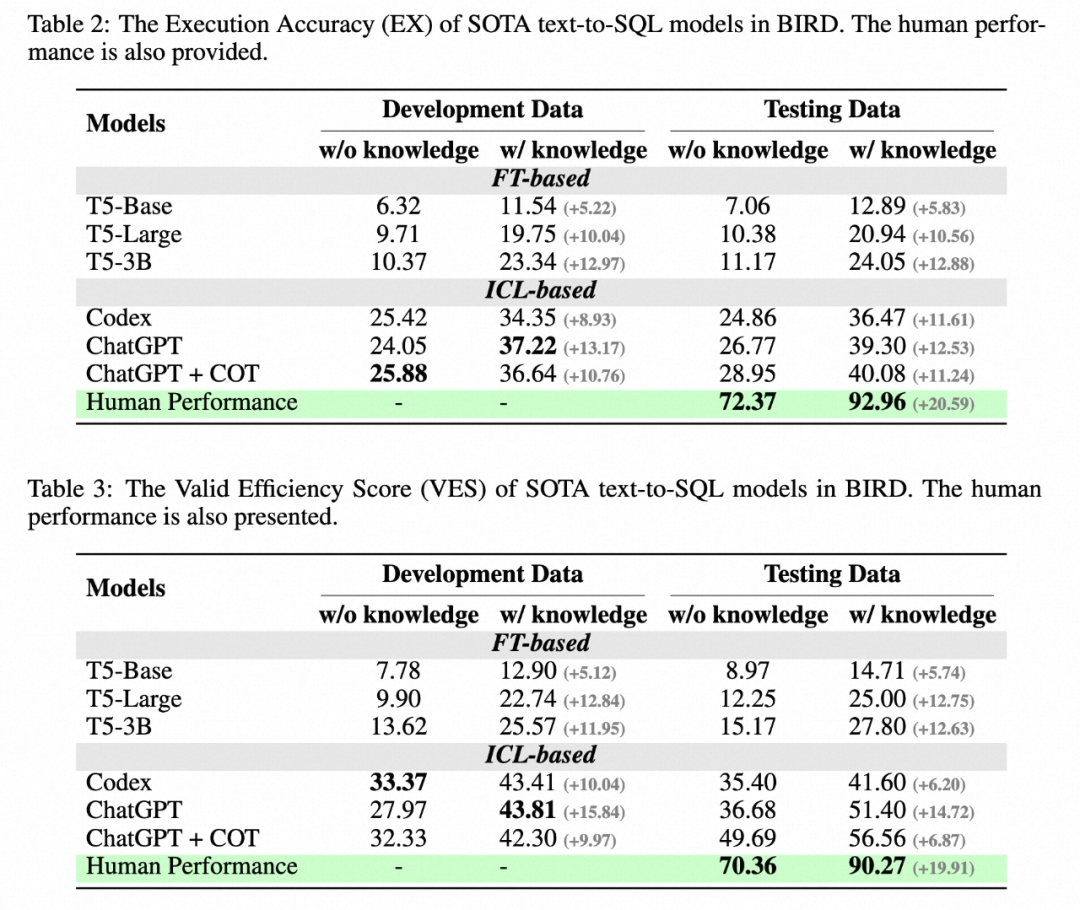
Penulis memberikan beberapa kesimpulan:
1 : Meningkatkan bukti pengetahuan (knowledge evidence) pada pemahaman nilai pangkalan data mempunyai peningkatan yang ketara Ini membuktikan bahawa dalam senario pangkalan data sebenar, hanya bergantung pada keupayaan penghuraian semantik tidak mencukupi dengan tepat Jawab.
2. Rantaian pemikiran tidak semestinya bermanfaat sepenuhnya: apabila model tidak mempunyai huraian nilai pangkalan data dan pukulan sifar, inferens COT model itu boleh dijana dengan lebih tepat. . Namun, apabila diberi pengetahuan tambahan (knowledge evidence), LLM diminta melakukan COT dan mendapati kesannya tidak ketara malah merosot. Oleh itu, dalam senario ini, LLM mungkin menjana konflik pengetahuan. Bagaimana untuk menyelesaikan konflik ini supaya model boleh menerima kedua-dua pengetahuan luaran dan mendapat manfaat daripada penaakulan pelbagai langkah yang berkuasa sendiri akan menjadi hala tuju penyelidikan utama pada masa hadapan.
3. Jurang dengan manusia: BIRD juga menyediakan penunjuk manusia Pengarang menggunakan peperiksaan untuk menguji prestasi pencatat apabila menghadapi ujian yang ditetapkan untuk kali pertama, dan menggunakannya sebagai asas untuk penunjuk manusia. . Eksperimen telah mendapati bahawa LLM terbaik semasa masih jauh di belakang manusia, membuktikan bahawa cabaran masih wujud. Penulis melakukan analisis ralat terperinci dan menyediakan beberapa arah yang berpotensi untuk penyelidikan masa depan.

Aplikasi LLM dalam medan pangkalan data akan menyediakan pengguna dengan lebih bijak dan mudah Pengalaman interaktif pangkalan data. Kemunculan BIRD akan menggalakkan pembangunan pintar interaksi antara bahasa semula jadi dan pangkalan data sebenar, menyediakan ruang untuk kemajuan dalam teknologi teks-ke-SQL untuk senario pangkalan data sebenar, dan membantu penyelidik membangunkan aplikasi pangkalan data yang lebih maju dan praktikal.
Atas ialah kandungan terperinci Apabila LLM bertemu Pangkalan Data: Alibaba DAMO Academy dan HKU melancarkan penanda aras Teks-ke-SQL baharu. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



