
 Peranti teknologi
AI
Dalam bidang perkhidmatan pelanggan, perubahan yang berkaitan dengan ChatGPT telah bermula
Peranti teknologi
AI
Dalam bidang perkhidmatan pelanggan, perubahan yang berkaitan dengan ChatGPT telah bermula
Dalam bidang perkhidmatan pelanggan, perubahan yang berkaitan dengan ChatGPT telah bermula


Dalam beberapa tahun kebelakangan ini, semakin banyak perniagaan telah menggunakan teknologi kecerdasan buatan untuk mengautomasikan pusat hubungan bagi mengendalikan panggilan, sembang dan mesej teks daripada berjuta-juta pelanggan. Kini, kemahiran komunikasi unggul ChatGPT sedang digabungkan dengan keupayaan utama yang disepadukan ke dalam sistem khusus perniagaan seperti pangkalan pengetahuan dalaman dan CRM.
Aplikasi model bahasa berskala besar (LLM) boleh meningkatkan pusat hubungan automatik, membolehkan mereka menyelesaikan permintaan pelanggan dari awal hingga akhir seperti perkhidmatan pelanggan manusia, dan telah mencapai hasil yang luar biasa. Sebaliknya, apabila lebih ramai pelanggan menyedari keupayaan ChatGPT seperti manusia, anda boleh bayangkan mereka akan mula menjadi lebih kecewa dengan sistem warisan yang sering memerlukan mereka menunggu 45 minit untuk maklumat kad kredit mereka dikemas kini.
Tetapi jangan takut. Walaupun menggunakan AI untuk menyelesaikan masalah pelanggan mungkin kelihatan ketinggalan zaman bagi pengguna awal, masa sebenarnya adalah sempurna.
LLM boleh menghentikan penurunan dalam kepuasan pelanggan
Kepuasan dalam industri perkhidmatan pelanggan telah menurun ke tahap terendah dalam beberapa dekad disebabkan kekurangan tempat duduk dan peningkatan permintaan. Kebangkitan LLM pasti akan menjadikan kecerdasan buatan sebagai isu teras bagi setiap bilik lembaga yang cuba membina semula kesetiaan pelanggan.
Perniagaan yang telah beralih kepada pilihan penyumberan luar yang mahal, atau menghapuskan pusat hubungan sama sekali, tiba-tiba melihat laluan yang mampan ke hadapan.
Pelan tindakan telah dilukis. AI boleh membantu mencapai tiga matlamat utama pusat panggilan: menyelesaikan isu pelanggan dalam deringan pertama, mengurangkan kos keseluruhan dan mengurangkan beban ejen (dan dengan berbuat demikian, meningkatkan pengekalan ejen).
Sejak beberapa tahun kebelakangan ini, pusat hubungan peringkat perusahaan telah menggunakan kecerdasan buatan untuk mengendalikan permintaan mereka yang paling biasa (mis., pengebilan, pengurusan akaun dan juga panggilan keluar), dan aliran ini nampaknya akan diteruskan pada 2023 Tahun terus berlalu.
Dengan melakukan ini, mereka telah dapat mengurangkan masa menunggu, membenarkan ejen mereka menumpukan pada panggilan yang menjana hasil atau nilai tambah, dan membebaskan diri mereka daripada strategi lapuk yang direka untuk menjauhkan pelanggan daripada ejen dan penyelesaian.
Semua ini boleh membawa kepada penjimatan kos, dan Gartner meramalkan bahawa penggunaan kecerdasan buatan akan mengurangkan kos pusat hubungan sebanyak lebih $80 bilion menjelang 2026.
LLM menjadikan automasi lebih mudah dan lebih baik berbanding sebelum ini
LLM dilatih mengenai set data awam yang besar. Pengetahuan yang luas tentang dunia ini sesuai dengan perkhidmatan pelanggan. Mereka dapat memahami dengan tepat keperluan sebenar pelanggan, tanpa mengira cara pemanggil bercakap atau menyampaikannya.
LLM telah disepadukan ke dalam platform automasi sedia ada, dengan berkesan meningkatkan keupayaan platform untuk memahami perbualan manusia tidak berstruktur sambil mengurangkan berlakunya ralat. Ini menghasilkan kadar penyelesaian yang lebih baik, langkah perbualan yang lebih sedikit, masa panggilan yang lebih singkat dan keperluan ejen yang lebih sedikit.
Pelanggan boleh bercakap dengan mesin menggunakan mana-mana ayat semula jadi, termasuk bertanya berbilang soalan, meminta mesin menunggu atau menghantar maklumat melalui teks. Penambahbaikan utama kepada LLM ialah resolusi panggilan yang dipertingkatkan, membolehkan lebih ramai pelanggan mendapat jawapan yang mereka perlukan tanpa perlu bercakap dengan ejen.
LLM juga mengurangkan dengan ketara masa yang diperlukan untuk menyesuaikan dan menggunakan kecerdasan buatan. Dengan API yang betul, pusat hubungan yang mempunyai kakitangan pendek boleh menyediakan penyelesaian dan berjalan dalam masa beberapa minggu tanpa perlu melatih kecerdasan buatan secara manual untuk memahami pelbagai permintaan yang mungkin dibuat oleh pelanggan.
Pusat hubungan menghadapi cabaran besar dan pada masa yang sama mesti memenuhi metrik SLA yang ketat dan memastikan tempoh panggilan pada tahap minimum. Dengan LLM, mereka bukan sahaja boleh menjawab lebih banyak panggilan tetapi juga menyelesaikan isu hujung ke hujung.
Automasi pusat panggilan mengurangkan risiko ChatGPT
Walaupun LLM mengagumkan, terdapat juga banyak kes jawapan yang tidak sesuai dan "halusinasi" yang didokumenkan - pada mesin Apabila ia tidak tahu apa yang hendak dikatakan, ia membentuk jawapan.
Untuk perusahaan, inilah sebab nombor satu LLM seperti ChatGPT tidak boleh berhubung secara langsung dengan pelanggan, apatah lagi menyepadukan mereka dengan sistem, peraturan dan platform perniagaan tertentu.
Platform AI sedia ada seperti Dialpad, Replicant dan Five9 menyediakan pusat hubungan dengan perlindungan untuk memanfaatkan kuasa LLM dengan lebih baik sambil mengurangkan risiko. Penyelesaian ini mematuhi piawaian SOC2, HIPAA dan PCI untuk memastikan perlindungan maksimum maklumat peribadi pelanggan.
Dan, kerana perbualan dikonfigurasikan khusus untuk setiap kes penggunaan, pusat hubungan boleh mengawal setiap perkataan yang dituturkan atau ditulis oleh mesin mereka, menghapuskan keperluan untuk input segera (iaitu pengguna yang cuba "menipu" LLM Risiko yang tidak dapat diramalkan yang disebabkan mengikut keadaan).
Dalam dunia kecerdasan buatan yang berubah dengan pantas, pusat hubungan mempunyai lebih banyak penyelesaian teknologi untuk dinilai berbanding sebelum ini.
Harapan pelanggan semakin meningkat dan perkhidmatan peringkat ChatGPT akan menjadi standard biasa tidak lama lagi. Semua tanda menunjukkan perkhidmatan pelanggan sebagai salah satu sektor yang paling mendapat manfaat daripada revolusi teknologi masa lalu.
Atas ialah kandungan terperinci Dalam bidang perkhidmatan pelanggan, perubahan yang berkaitan dengan ChatGPT telah bermula. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 ChatGPT kini membenarkan pengguna percuma menjana imej dengan menggunakan DALL-E 3 dengan had harian
Aug 09, 2024 pm 09:37 PM
ChatGPT kini membenarkan pengguna percuma menjana imej dengan menggunakan DALL-E 3 dengan had harian
Aug 09, 2024 pm 09:37 PM
DALL-E 3 telah diperkenalkan secara rasmi pada September 2023 sebagai model yang jauh lebih baik daripada pendahulunya. Ia dianggap sebagai salah satu penjana imej AI terbaik setakat ini, mampu mencipta imej dengan perincian yang rumit. Walau bagaimanapun, semasa pelancaran, ia adalah tidak termasuk
 Mengapakah model bahasa besar menggunakan SwiGLU sebagai fungsi pengaktifan?
Apr 08, 2024 pm 09:31 PM
Mengapakah model bahasa besar menggunakan SwiGLU sebagai fungsi pengaktifan?
Apr 08, 2024 pm 09:31 PM
Jika anda telah memberi perhatian kepada seni bina model bahasa yang besar, anda mungkin pernah melihat istilah "SwiGLU" dalam model dan kertas penyelidikan terkini. SwiGLU boleh dikatakan sebagai fungsi pengaktifan yang paling biasa digunakan dalam model bahasa besar Kami akan memperkenalkannya secara terperinci dalam artikel ini. SwiGLU sebenarnya adalah fungsi pengaktifan yang dicadangkan oleh Google pada tahun 2020, yang menggabungkan ciri-ciri SWISH dan GLU. Nama penuh Cina SwiGLU ialah "unit linear berpagar dua arah". Ia mengoptimumkan dan menggabungkan dua fungsi pengaktifan, SWISH dan GLU, untuk meningkatkan keupayaan ekspresi tak linear model. SWISH ialah fungsi pengaktifan yang sangat biasa yang digunakan secara meluas dalam model bahasa besar, manakala GLU telah menunjukkan prestasi yang baik dalam tugas pemprosesan bahasa semula jadi.
 Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Bolehkah penalaan halus benar-benar membolehkan LLM mempelajari perkara baharu: memperkenalkan pengetahuan baharu boleh menjadikan model menghasilkan lebih banyak halusinasi
Jun 11, 2024 pm 03:57 PM
Model Bahasa Besar (LLM) dilatih pada pangkalan data teks yang besar, di mana mereka memperoleh sejumlah besar pengetahuan dunia sebenar. Pengetahuan ini dibenamkan ke dalam parameter mereka dan kemudiannya boleh digunakan apabila diperlukan. Pengetahuan tentang model ini "diperbaharui" pada akhir latihan. Pada akhir pra-latihan, model sebenarnya berhenti belajar. Selaraskan atau perhalusi model untuk mempelajari cara memanfaatkan pengetahuan ini dan bertindak balas dengan lebih semula jadi kepada soalan pengguna. Tetapi kadangkala pengetahuan model tidak mencukupi, dan walaupun model boleh mengakses kandungan luaran melalui RAG, ia dianggap berfaedah untuk menyesuaikan model kepada domain baharu melalui penalaan halus. Penalaan halus ini dilakukan menggunakan input daripada anotasi manusia atau ciptaan LLM lain, di mana model menemui pengetahuan dunia sebenar tambahan dan menyepadukannya
 Gabungan sempurna ChatGPT dan Python: mencipta chatbot perkhidmatan pelanggan yang pintar
Oct 27, 2023 pm 06:00 PM
Gabungan sempurna ChatGPT dan Python: mencipta chatbot perkhidmatan pelanggan yang pintar
Oct 27, 2023 pm 06:00 PM
Gabungan sempurna ChatGPT dan Python: Mencipta Perkhidmatan Pelanggan Pintar Chatbot Pengenalan: Dalam era maklumat hari ini, sistem perkhidmatan pelanggan pintar telah menjadi alat komunikasi yang penting antara perusahaan dan pelanggan. Untuk memberikan pengalaman perkhidmatan pelanggan yang lebih baik, banyak syarikat telah mula beralih kepada chatbots untuk menyelesaikan tugas seperti perundingan pelanggan dan menjawab soalan. Dalam artikel ini, kami akan memperkenalkan cara menggunakan bahasa ChatGPT dan Python model OpenAI yang berkuasa untuk mencipta bot sembang perkhidmatan pelanggan yang pintar untuk meningkatkan
 Visualisasikan ruang vektor FAISS dan laraskan parameter RAG untuk meningkatkan ketepatan hasil
Mar 01, 2024 pm 09:16 PM
Visualisasikan ruang vektor FAISS dan laraskan parameter RAG untuk meningkatkan ketepatan hasil
Mar 01, 2024 pm 09:16 PM
Memandangkan prestasi model bahasa berskala besar sumber terbuka terus bertambah baik, prestasi dalam penulisan dan analisis kod, pengesyoran, ringkasan teks dan pasangan menjawab soalan (QA) semuanya bertambah baik. Tetapi apabila ia berkaitan dengan QA, LLM sering gagal dalam isu yang berkaitan dengan data yang tidak terlatih, dan banyak dokumen dalaman disimpan dalam syarikat untuk memastikan pematuhan, rahsia perdagangan atau privasi. Apabila dokumen ini disoal, LLM boleh berhalusinasi dan menghasilkan kandungan yang tidak relevan, rekaan atau tidak konsisten. Satu teknik yang mungkin untuk menangani cabaran ini ialah Retrieval Augmented Generation (RAG). Ia melibatkan proses meningkatkan respons dengan merujuk pangkalan pengetahuan berwibawa di luar sumber data latihan untuk meningkatkan kualiti dan ketepatan penjanaan. Sistem RAG termasuk sistem mendapatkan semula untuk mendapatkan serpihan dokumen yang berkaitan daripada korpus
 Bagaimana untuk memasang chatgpt pada telefon bimbit
Mar 05, 2024 pm 02:31 PM
Bagaimana untuk memasang chatgpt pada telefon bimbit
Mar 05, 2024 pm 02:31 PM
Langkah pemasangan: 1. Muat turun perisian ChatGTP dari laman web rasmi ChatGTP atau kedai mudah alih 2. Selepas membukanya, dalam antara muka tetapan, pilih bahasa sebagai bahasa Cina 3. Dalam antara muka permainan, pilih permainan mesin manusia dan tetapkan Spektrum bahasa Cina; 4 Selepas memulakan, masukkan arahan dalam tetingkap sembang untuk berinteraksi dengan perisian.
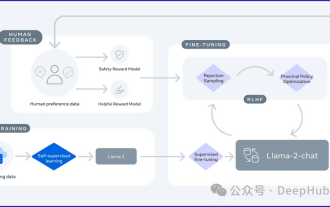 Pengoptimuman LLM menggunakan teknologi SPIN untuk latihan penalaan halus permainan sendiri
Jan 25, 2024 pm 12:21 PM
Pengoptimuman LLM menggunakan teknologi SPIN untuk latihan penalaan halus permainan sendiri
Jan 25, 2024 pm 12:21 PM
2024 ialah tahun pembangunan pesat untuk model bahasa besar (LLM). Dalam latihan LLM, kaedah penjajaran ialah cara teknikal yang penting, termasuk penyeliaan penalaan halus (SFT) dan pembelajaran pengukuhan dengan maklum balas manusia (RLHF) yang bergantung pada pilihan manusia. Kaedah ini telah memainkan peranan penting dalam pembangunan LLM, tetapi kaedah penjajaran memerlukan sejumlah besar data beranotasi secara manual. Menghadapi cabaran ini, penalaan halus telah menjadi bidang penyelidikan yang rancak, dengan para penyelidik giat berusaha untuk membangunkan kaedah yang boleh mengeksploitasi data manusia dengan berkesan. Oleh itu, pembangunan kaedah penjajaran akan menggalakkan lagi kejayaan dalam teknologi LLM. Universiti California baru-baru ini menjalankan kajian yang memperkenalkan teknologi baharu yang dipanggil SPIN (SelfPlayfInetuNing). S
 Menggunakan graf pengetahuan untuk meningkatkan keupayaan model RAG dan mengurangkan tanggapan palsu model besar
Jan 14, 2024 pm 06:30 PM
Menggunakan graf pengetahuan untuk meningkatkan keupayaan model RAG dan mengurangkan tanggapan palsu model besar
Jan 14, 2024 pm 06:30 PM
Halusinasi adalah masalah biasa apabila bekerja dengan model bahasa besar (LLM). Walaupun LLM boleh menjana teks yang lancar dan koheren, maklumat yang dijananya selalunya tidak tepat atau tidak konsisten. Untuk mengelakkan LLM daripada halusinasi, sumber pengetahuan luaran, seperti pangkalan data atau graf pengetahuan, boleh digunakan untuk memberikan maklumat fakta. Dengan cara ini, LLM boleh bergantung pada sumber data yang boleh dipercayai ini, menghasilkan kandungan teks yang lebih tepat dan boleh dipercayai. Pangkalan Data Vektor dan Graf Pengetahuan Pangkalan Data Vektor Pangkalan data vektor ialah satu set vektor berdimensi tinggi yang mewakili entiti atau konsep. Ia boleh digunakan untuk mengukur persamaan atau korelasi antara entiti atau konsep yang berbeza, dikira melalui perwakilan vektornya. Pangkalan data vektor boleh memberitahu anda, berdasarkan jarak vektor, bahawa "Paris" dan "Perancis" lebih dekat daripada "Paris" dan
