
 Peranti teknologi
AI
OpenAI mendominasi dua teratas! Senarai kedudukan penjanaan kod model besar dikeluarkan, dengan 7 bilion LLaMA mengatasinya dan dikalahkan oleh 250 juta Codex.
Peranti teknologi
AI
OpenAI mendominasi dua teratas! Senarai kedudukan penjanaan kod model besar dikeluarkan, dengan 7 bilion LLaMA mengatasinya dan dikalahkan oleh 250 juta Codex.
OpenAI mendominasi dua teratas! Senarai kedudukan penjanaan kod model besar dikeluarkan, dengan 7 bilion LLaMA mengatasinya dan dikalahkan oleh 250 juta Codex.

Baru-baru ini, tweet oleh Matthias Plappert mencetuskan perbincangan meluas dalam kalangan LLM.
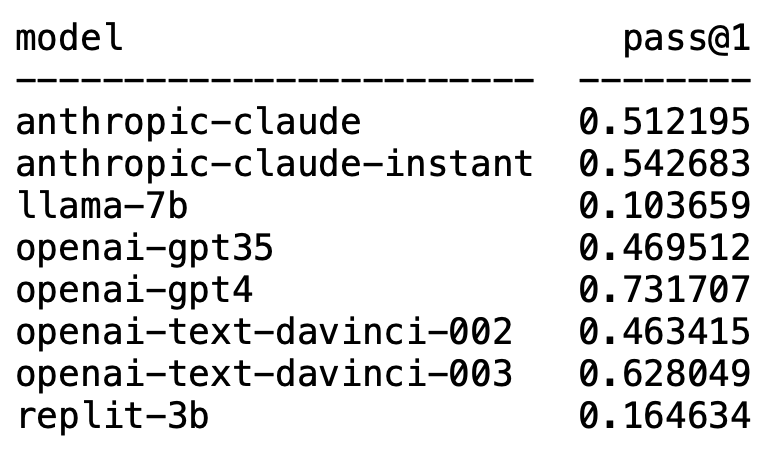
Plappert ialah seorang saintis komputer terkenal dia menerbitkan keputusan ujian penanda arasnya pada LLM arus perdana dalam lingkaran AI di HumanEval.
Pengujiannya berat sebelah terhadap penjanaan kod.
Hasilnya mengejutkan dan mengejutkan.

Tidak disangka-sangka, GPT-4 sudah pasti mendominasi senarai dan memenangi tempat pertama.
Tanpa diduga, teks-davinci-003 OpenAI tiba-tiba muncul dan menduduki tempat kedua.
Plappert berkata bahawa text-davinci-003 boleh dipanggil model "harta karun".
LLaMA yang biasa digunakan tidak mahir dalam penjanaan kod.
OpenAI mendominasi senarai
Plappert berkata bahawa prestasi GPT-4 lebih baik daripada data dalam literatur.
Data ujian satu pusingan GPT-4 dalam kertas ialah kadar lulus 67%, manakala ujian Plappert mencapai 73%.

Apabila menganalisis punca, beliau berkata terdapat banyak kemungkinan untuk perbezaan data. Salah satunya ialah gesaan yang dia berikan kepada GPT-4 adalah lebih baik sedikit berbanding ketika pengarang kertas itu mengujinya.
Sebab lain ialah dia mengagak suhu model itu bukan 0 apabila kertas menguji GPT-4.
"Suhu" ialah parameter yang digunakan untuk melaraskan kreativiti dan kepelbagaian apabila model menjana teks. "Suhu" ialah nilai yang lebih besar daripada 0, biasanya antara 0 dan 1. Ia mempengaruhi taburan kebarangkalian perkataan ramalan sampel apabila model menjana teks.
Apabila "suhu" model lebih tinggi (seperti 0.8, 1 atau lebih tinggi), model akan lebih cenderung untuk memilih daripada perkataan yang lebih pelbagai dan berbeza, yang menjadikan Teks yang dihasilkan adalah lebih berisiko dan lebih kreatif, tetapi mungkin juga menghasilkan lebih banyak ralat dan ketidakselarasan.
Apabila "suhu" rendah (seperti 0.2, 0.3, dll.), model terutamanya akan memilih daripada perkataan dengan kebarangkalian yang lebih tinggi, sekali gus menghasilkan teks yang lebih lancar dan lebih koheren .
Tetapi pada ketika ini, teks yang dijana mungkin kelihatan terlalu konservatif dan berulang.
Oleh itu, dalam aplikasi sebenar, adalah perlu untuk menimbang dan memilih nilai "suhu" yang sesuai berdasarkan keperluan khusus.
Seterusnya, apabila mengulas pada text-davinci-003, Plappert berkata bahawa ini juga merupakan model yang sangat berkebolehan di bawah OpenAI.
Walaupun ia tidak sehebat GPT-4, dengan kadar lulus 62% dalam satu pusingan ujian, ia masih kukuh menduduki tempat kedua.
Plappert menekankan bahawa perkara terbaik tentang text-davinci-003 ialah pengguna tidak perlu menggunakan API ChatGPT. Ini bermakna memberi gesaan boleh menjadi lebih mudah.
Selain itu, Plappert juga memberikan model segera klaude Anthropic AI penilaian yang agak tinggi.
Dia berpendapat prestasi model ini bagus dan boleh mengalahkan GPT-3.5. Kadar lulus GPT-3.5 ialah 46%, manakala kadar lulus claude-instant ialah 54%.
Sudah tentu, LLM Anthropic AI yang lain, claude, tidak boleh dimainkan oleh claude-instant, dan kadar lulus hanya 51%.
Plappert berkata bahawa gesaan yang digunakan untuk menguji kedua-dua model adalah sama.
Selain model biasa ini, Plappert juga telah menguji banyak model sumber terbuka kecil.
Plappert berkata adalah bagus dia boleh menjalankan model ini secara tempatan.
Walau bagaimanapun, dari segi skala, model ini jelas tidak sebesar model OpenAI dan Anthropic AI, jadi membandingkannya agak menggembirakan.

Penjanaan kod LLaMA? Sudah tentu, Plappert tidak berpuas hati dengan keputusan ujian LLaMA.
Berdasarkan keputusan ujian, LLaMA berprestasi sangat teruk dalam menjana kod. Mungkin kerana mereka menggunakan pensampelan kurang semasa mengumpul data daripada GitHub.
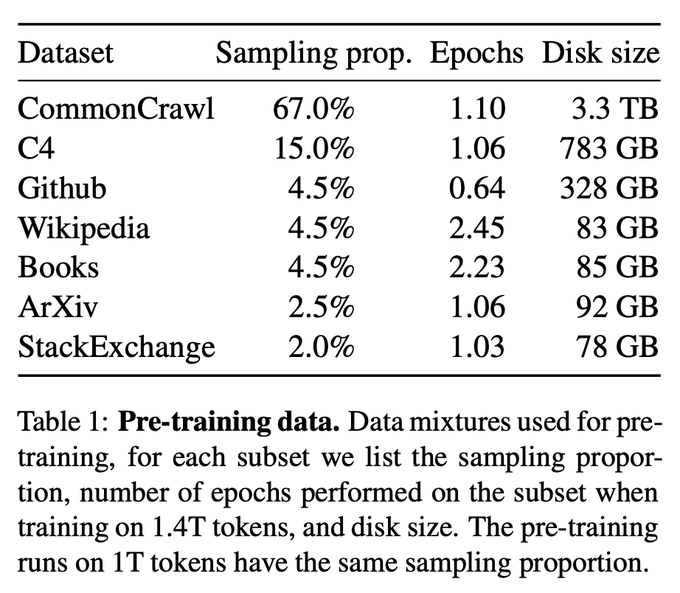 Walaupun dibandingkan dengan Codex 2.5B, prestasi LLaMA bukanlah yang terbaik. (Kadar lulus 10% berbanding 22%)
Walaupun dibandingkan dengan Codex 2.5B, prestasi LLaMA bukanlah yang terbaik. (Kadar lulus 10% berbanding 22%)
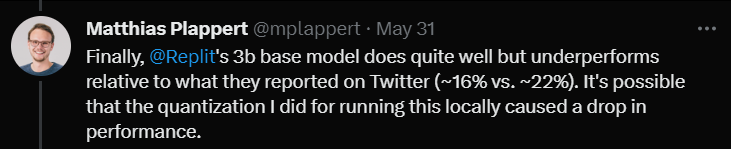
 Akhir sekali, dia menguji model saiz 3B Replit.
Akhir sekali, dia menguji model saiz 3B Replit.
Dia berkata bahawa prestasi itu tidak buruk, tetapi dibandingkan dengan data yang dipromosikan di Twitter (kadar lulus 16% berbanding 22%)
Plappert percaya ini mungkin kerana kaedah kuantifikasi yang digunakannya semasa menguji model ini menyebabkan kadar lulus menurun beberapa mata peratusan.
 Pada akhir ulasan, Plappert menyebut satu perkara yang menarik.
Pada akhir ulasan, Plappert menyebut satu perkara yang menarik.
Seorang pengguna mendapati di Twitter bahawa GPT-3.5-turbo berprestasi lebih baik apabila menggunakan Completion API (API penyiapan) platform Azure (bukannya Chat API) yang baik.
Plappert percaya bahawa fenomena ini mempunyai sedikit kesahihan, kerana memasukkan gesaan melalui API Sembang boleh menjadi agak rumit.
Atas ialah kandungan terperinci OpenAI mendominasi dua teratas! Senarai kedudukan penjanaan kod model besar dikeluarkan, dengan 7 bilion LLaMA mengatasinya dan dikalahkan oleh 250 juta Codex.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1392
1392
 52
36
110
52
36
110

 Desktop Jauh tidak boleh mengesahkan identiti komputer jauh
Feb 29, 2024 pm 12:30 PM
Desktop Jauh tidak boleh mengesahkan identiti komputer jauh
Feb 29, 2024 pm 12:30 PM
Perkhidmatan Desktop Jauh Windows membolehkan pengguna mengakses komputer dari jauh, yang sangat mudah untuk orang yang perlu bekerja dari jauh. Walau bagaimanapun, masalah boleh dihadapi apabila pengguna tidak dapat menyambung ke komputer jauh atau apabila Desktop Jauh tidak dapat mengesahkan identiti komputer. Ini mungkin disebabkan oleh isu sambungan rangkaian atau kegagalan pengesahan sijil. Dalam kes ini, pengguna mungkin perlu menyemak sambungan rangkaian, memastikan komputer jauh berada dalam talian dan cuba menyambung semula. Selain itu, memastikan bahawa pilihan pengesahan komputer jauh dikonfigurasikan dengan betul adalah kunci untuk menyelesaikan isu tersebut. Masalah sedemikian dengan Perkhidmatan Desktop Jauh Windows biasanya boleh diselesaikan dengan menyemak dan melaraskan tetapan dengan teliti. Desktop Jauh tidak boleh mengesahkan identiti komputer jauh kerana perbezaan masa atau tarikh. Sila pastikan pengiraan anda
 Bagaimana untuk menyelesaikan kod pemandu win7 28
Dec 30, 2023 pm 11:55 PM
Bagaimana untuk menyelesaikan kod pemandu win7 28
Dec 30, 2023 pm 11:55 PM
Sesetengah pengguna mengalami ralat semasa memasang peranti, menyebabkan kod ralat 28. Sebenarnya, ini disebabkan terutamanya oleh pemandu Kami hanya perlu menyelesaikan masalah kod pemandu win7 28. Mari kita lihat apa yang perlu dilakukan . Apa yang perlu dilakukan dengan kod pemandu win7 28: Pertama, kita perlu mengklik pada menu mula di sudut kiri bawah skrin. Kemudian, cari dan klik pilihan "Panel Kawalan" dalam menu pop timbul. Pilihan ini biasanya terletak di atau berhampiran bahagian bawah menu. Selepas mengklik, sistem akan membuka antara muka panel kawalan secara automatik. Dalam panel kawalan, kami boleh melakukan pelbagai tetapan sistem dan operasi pengurusan. Ini adalah langkah pertama dalam tahap pembersihan nostalgia, saya harap ia membantu. Kemudian kita perlu meneruskan dan memasuki sistem dan
 Kedudukan Sains Komputer Kebangsaan 2024 CSRankings Dikeluarkan! CMU mendominasi senarai, MIT terkeluar daripada 5 teratas
Mar 25, 2024 pm 06:01 PM
Kedudukan Sains Komputer Kebangsaan 2024 CSRankings Dikeluarkan! CMU mendominasi senarai, MIT terkeluar daripada 5 teratas
Mar 25, 2024 pm 06:01 PM
Kedudukan Utama Sains Komputer Kebangsaan 2024CSRankings baru sahaja dikeluarkan! Tahun ini, dalam ranking universiti CS terbaik di Amerika Syarikat, Carnegie Mellon University (CMU) berada di antara yang terbaik di negara ini dan dalam bidang CS, manakala University of Illinois di Urbana-Champaign (UIUC) telah menduduki tempat kedua selama enam tahun berturut-turut. Georgia Tech menduduki tempat ketiga. Kemudian, Universiti Stanford, Universiti California di San Diego, Universiti Michigan, dan Universiti Washington terikat di tempat keempat di dunia. Perlu diingat bahawa kedudukan MIT jatuh dan jatuh daripada lima teratas. CSRankings ialah projek ranking universiti global dalam bidang sains komputer yang dimulakan oleh Profesor Emery Berger dari Pusat Pengajian Sains Komputer dan Maklumat di Universiti Massachusetts Amherst. Kedudukan adalah berdasarkan objektif
 Apa yang perlu dilakukan jika kod skrin biru 0x0000001 berlaku
Feb 23, 2024 am 08:09 AM
Apa yang perlu dilakukan jika kod skrin biru 0x0000001 berlaku
Feb 23, 2024 am 08:09 AM
Apa yang perlu dilakukan dengan kod skrin biru 0x0000001 Ralat skrin biru adalah mekanisme amaran apabila terdapat masalah dengan sistem komputer atau perkakasan Kod 0x0000001 biasanya menunjukkan kegagalan perkakasan. Apabila pengguna tiba-tiba mengalami ralat skrin biru semasa menggunakan komputer mereka, mereka mungkin berasa panik dan rugi. Nasib baik, kebanyakan ralat skrin biru boleh diselesaikan dan ditangani dengan beberapa langkah mudah. Artikel ini akan memperkenalkan pembaca kepada beberapa kaedah untuk menyelesaikan kod ralat skrin biru 0x0000001. Pertama, apabila menghadapi ralat skrin biru, kita boleh cuba untuk memulakan semula
 Tidak dapat membuka objek Dasar Kumpulan pada komputer ini
Feb 07, 2024 pm 02:00 PM
Tidak dapat membuka objek Dasar Kumpulan pada komputer ini
Feb 07, 2024 pm 02:00 PM
Kadangkala, sistem pengendalian mungkin tidak berfungsi apabila menggunakan komputer. Masalah yang saya hadapi hari ini ialah apabila mengakses gpedit.msc, sistem menggesa objek Dasar Kumpulan tidak boleh dibuka kerana kebenaran yang betul mungkin tiada. Objek Dasar Kumpulan pada komputer ini tidak dapat dibuka Penyelesaian: 1. Apabila mengakses gpedit.msc, sistem menggesa bahawa objek Dasar Kumpulan pada komputer ini tidak boleh dibuka kerana kekurangan kebenaran. Butiran: Sistem tidak dapat mengesan laluan yang ditentukan. 2. Selepas pengguna mengklik butang tutup, tetingkap ralat berikut muncul. 3. Semak rekod log dengan segera dan gabungkan maklumat yang direkodkan untuk mendapati bahawa masalahnya terletak pada fail C:\Windows\System32\GroupPolicy\Machine\registry.pol
 Komputer kerap berskrin biru dan kodnya berbeza setiap kali
Jan 06, 2024 pm 10:53 PM
Komputer kerap berskrin biru dan kodnya berbeza setiap kali
Jan 06, 2024 pm 10:53 PM
Sistem win10 ialah sistem kecerdasan tinggi yang sangat baik Kepintarannya yang berkuasa boleh membawa pengalaman pengguna yang terbaik kepada pengguna Dalam keadaan biasa, komputer sistem win10 pengguna tidak akan menghadapi sebarang masalah. Walau bagaimanapun, tidak dapat dielakkan bahawa pelbagai kerosakan akan berlaku pada komputer yang sangat baik Baru-baru ini, rakan-rakan telah melaporkan bahawa sistem win10 mereka sering menghadapi skrin biru. Hari ini, editor akan membawakan anda penyelesaian kepada kod berbeza yang menyebabkan skrin biru kerap berlaku dalam komputer Windows 10 Mari kita lihat. Penyelesaian kepada skrin biru komputer yang kerap dengan kod berbeza setiap kali: punca pelbagai kod kerosakan dan cadangan penyelesaian 1. Punca kerosakan 0×000000116: Seharusnya pemacu kad grafik tidak serasi. Penyelesaian: Adalah disyorkan untuk menggantikan pemacu pengilang asal. 2.
 Selesaikan ralat kod 0xc000007b
Feb 18, 2024 pm 07:34 PM
Selesaikan ralat kod 0xc000007b
Feb 18, 2024 pm 07:34 PM
Kod Penamatan 0xc000007b Semasa menggunakan komputer anda, kadangkala anda menghadapi pelbagai masalah dan kod ralat. Antaranya, kod penamatan adalah yang paling mengganggu terutamanya kod penamatan 0xc000007b. Kod ini menunjukkan bahawa aplikasi tidak boleh dimulakan dengan betul, menyebabkan ketidakselesaan kepada pengguna. Mula-mula, mari kita fahami maksud kod penamatan 0xc000007b. Kod ini ialah kod ralat sistem pengendalian Windows yang biasanya berlaku apabila aplikasi 32-bit cuba dijalankan pada sistem pengendalian 64-bit. Maksudnya sepatutnya
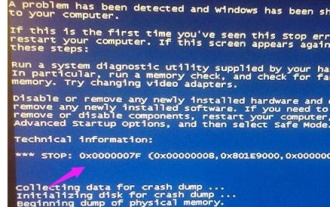 Penjelasan terperinci tentang punca dan penyelesaian kod skrin biru 0x0000007f
Dec 25, 2023 pm 02:19 PM
Penjelasan terperinci tentang punca dan penyelesaian kod skrin biru 0x0000007f
Dec 25, 2023 pm 02:19 PM
Skrin biru adalah masalah yang sering kita hadapi apabila menggunakan sistem Bergantung pada kod ralat, akan terdapat banyak sebab dan penyelesaian yang berbeza. Sebagai contoh, apabila kita menghadapi masalah berhenti: 0x0000007f, ia mungkin ralat perkakasan atau perisian Mari ikut editor untuk mengetahui penyelesaiannya. 0x000000c5 sebab kod skrin biru: Jawapan: Memori, CPU dan kad grafik tiba-tiba overclocked atau perisian berjalan dengan tidak betul. Penyelesaian 1: 1. Teruskan tekan F8 untuk masuk semasa but, pilih mod selamat, dan tekan Enter untuk masuk. 2. Selepas memasuki mod selamat, tekan win+r untuk membuka tetingkap jalankan, masukkan cmd, dan tekan Enter. 3. Dalam tetingkap command prompt, masukkan "chkdsk /f /r", tekan Enter, dan kemudian tekan kekunci y. 4.
