
 Peranti teknologi
AI
Artikel panjang 10,000 perkataan menerangkan aplikasi model besar dalam bidang pemanduan autonomi
Peranti teknologi
AI
Artikel panjang 10,000 perkataan menerangkan aplikasi model besar dalam bidang pemanduan autonomi
Artikel panjang 10,000 perkataan menerangkan aplikasi model besar dalam bidang pemanduan autonomi

Dengan populariti ChatGPT, model besar telah mendapat perhatian yang lebih dan lebih, dan keupayaan yang dipaparkan oleh model besar adalah menakjubkan.
Dalam bidang seperti penjanaan imej, sistem pengesyoran dan terjemahan mesin, model besar telah mula memainkan peranan. Memandangkan beberapa perkataan pantas, lukisan reka bentuk yang dihasilkan oleh tapak web penjanaan imej Midjourney malah telah melepasi tahap banyak pereka profesional.
Mengapa model besar boleh menunjukkan kebolehan yang menakjubkan? Mengapakah prestasi model menjadi lebih baik apabila bilangan parameter dan kapasiti model meningkat?
Seorang pakar dari syarikat algoritma AI memberitahu pengarang: Peningkatan bilangan parameter model boleh difahami sebagai peningkatan dalam dimensi model, yang bermaksud bahawa kita boleh menggunakan cara yang lebih kompleks untuk mensimulasikan peraturan dunia sebenar. Ambil senario paling mudah sebagai contoh Berikan plot serakan pada satah Jika kita menggunakan garis lurus (fungsi satu pembolehubah) untuk menerangkan corak titik serakan pada plot, maka tidak kira apa parameternya, akan ada. sentiasa menjadi beberapa Titik di luar garisan ini. Jika kita menggunakan fungsi binari untuk mewakili corak titik ini, maka lebih banyak mata akan jatuh pada baris fungsi ini. Apabila dimensi fungsi meningkat, atau tahap kebebasan meningkat, semakin banyak mata akan jatuh pada baris ini, yang bermaksud bahawa undang-undang titik ini akan dipasang dengan lebih tepat.
Dalam erti kata lain, lebih besar bilangan parameter model, lebih mudah model itu sesuai dengan undang-undang data besar-besaran.
Dengan kemunculan ChatGPT, orang ramai telah mendapati bahawa apabila parameter model mencapai tahap tertentu, kesannya bukan sekadar "prestasi yang lebih baik", tetapi "di luar jangkaan" yang baik" .
Dalam bidang NLP (Natural Language Processing), terdapat fenomena menarik yang masih belum dapat dijelaskan oleh kalangan akademik dan industri tentang prinsip khusus: "Keupayaan Muncul".
Apakah itu "kemunculan"? "Kemunculan" bermaksud apabila bilangan parameter model meningkat secara linear ke tahap tertentu, ketepatan model meningkat secara eksponen.
Kita boleh melihat pada gambar Bahagian kiri gambar di bawah menunjukkan Undang-undang Skala Ini adalah fenomena yang ditemui oleh penyelidik OpenAI sebelum 2022. Maksudnya, dengan Apabila saiz parameter model meningkat secara eksponen, ketepatan model akan meningkat secara linear. Parameter model dalam gambar di sebelah kiri tidak berkembang secara eksponen tetapi secara linear
Menjelang Januari 2022, sesetengah penyelidik mendapati bahawa apabila skala parameter model melebihi tahap tertentu, ketepatan model bertambah baik Darjahnya jelas melebihi lengkung perkadaran, seperti yang ditunjukkan di sebelah kanan rajah di bawah.
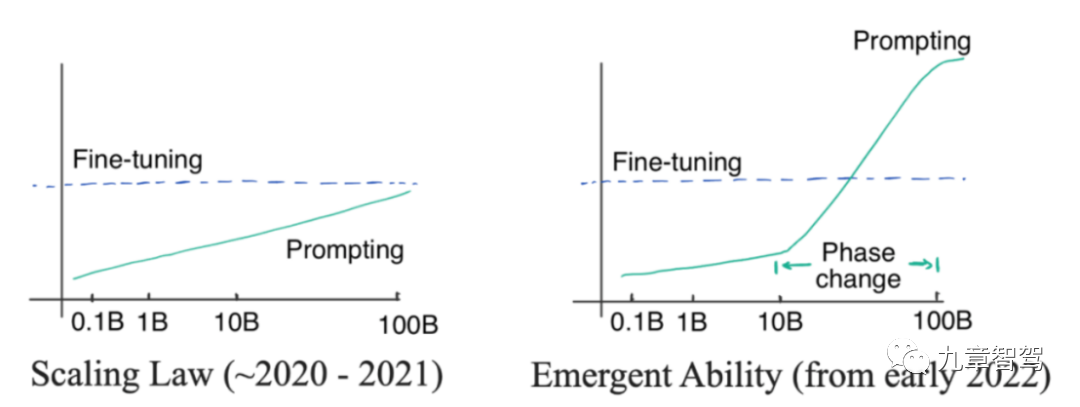
Gambarajah skematik "kemunculan"
Kami akan melaksanakannya di tahap aplikasi Didapati bahawa model besar boleh mencapai beberapa tugas yang tidak dapat dicapai oleh model kecil Contohnya, model besar boleh melakukan penambahan dan penolakan, penaakulan mudah, dll.
Apakah jenis model yang boleh dipanggil model besar?
Secara umumnya, kami percaya bahawa model dengan lebih daripada 100 juta parameter boleh dipanggil "model besar". Dalam bidang pemanduan autonomi, model besar terutamanya mempunyai dua makna: satu adalah model dengan lebih daripada 100 juta parameter; juga dipanggil model sebagai "model besar".
Mengikut definisi ini, model besar telah mula digunakan secara meluas dalam bidang pemanduan autonomi. Dalam awan, kita boleh memanfaatkan kelebihan kapasiti yang dibawa oleh peningkatan bilangan parameter model dan menggunakan model besar untuk menyelesaikan beberapa tugas seperti perlombongan data dan anotasi data. Di bahagian kereta, kita boleh menggabungkan beberapa model kecil yang bertanggungjawab untuk subtugas yang berbeza menjadi satu "model besar", yang boleh menjimatkan masa penaakulan dalam pengiraan sisi kereta dan meningkatkan keselamatan.
Secara konkrit, bagaimanakah model besar boleh dimainkan? Menurut maklumat yang penulis sampaikan dengan pakar industri, industri pada masa ini terutamanya menggunakan model besar dalam bidang persepsi. Seterusnya, kami akan memperkenalkan cara model besar masing-masing membolehkan tugas persepsi di awan dan di bahagian kereta.
01
Aplikasi model besar
1.1 Aplikasi model besar dalam awan
1.1.1 Anotasi data automatik
Anotasi automatik boleh dicapai dengan menggunakan pra-latihan model besar. Mengambil anotasi klip video sebagai contoh, anda boleh mula-mula menggunakan data klip besar-besaran tidak berlabel untuk melatih model besar melalui penyeliaan kendiri, dan kemudian menggunakan sejumlah kecil data klip berlabel secara manual untuk memperhalusi model supaya model mempunyai keupayaan pengesanan Model secara automatik boleh menganotasi data klip.
Semakin tinggi ketepatan pelabelan model, semakin tinggi tahap penggantian manusia.
Pada masa ini, banyak syarikat sedang mengkaji cara meningkatkan ketepatan pelabelan automatik model besar, dengan harapan untuk mencapai pelabelan automatik tanpa pemandu yang lengkap selepas ketepatan mencapai standard.
Leo, pengarah produk pemanduan pintar di SenseTime, memberitahu pengarang: Kami telah melakukan penilaian dan mendapati bahawa untuk sasaran biasa di jalan raya, ketepatan pelabelan automatik model besar SenseTime boleh mencapai lebih daripada 98%. Dengan cara ini, proses semakan manual seterusnya boleh menjadi sangat diperkemas.
Dalam proses pembangunan produk pemanduan pintar, SenseTime Jueying telah memperkenalkan pra-anotasi automatik model besar untuk kebanyakan tugas persepsi Berbanding dengan masa lalu, jumlah data yang sama boleh diperolehi Sampel, kitaran pelabelan dan kos pelabelan boleh dikurangkan lebih daripada berpuluh-puluh kali ganda, meningkatkan kecekapan pembangunan dengan ketara.
Secara umumnya, jangkaan semua orang untuk tugasan anotasi terutamanya termasuk kecekapan tinggi proses anotasi, ketepatan yang tinggi dan ketekalan hasil anotasi yang tinggi. Kecekapan tinggi dan ketepatan yang tinggi adalah mudah difahami. Apakah maksud konsistensi tinggi? Dalam algoritma BEV untuk pengecaman 3D, jurutera perlu menggunakan anotasi bersama lidar dan penglihatan, dan perlu bersama-sama memproses awan titik dan data imej. Dalam pautan pemprosesan jenis ini, jurutera mungkin juga perlu membuat beberapa anotasi pada peringkat masa, supaya hasil bingkai sebelumnya dan seterusnya tidak boleh terlalu berbeza.
Jika anotasi manual digunakan, kesan anotasi bergantung pada tahap anotasi bagi anotasi Tahap yang tidak sekata mungkin menyebabkan ketidakkonsistenan dalam hasil anotasi dan mungkin terdapat anotasi dalam. satu gambar. Bingkai lebih besar dan yang seterusnya lebih kecil Hasil anotasi model besar secara amnya lebih konsisten.
Walau bagaimanapun, beberapa pakar industri telah melaporkan bahawa masih terdapat beberapa kesukaran dalam melaksanakan anotasi automatik menggunakan model besar ke dalam aplikasi praktikal, terutamanya dalam hubungan antara syarikat pemanduan autonomi dan syarikat anotasi—— Banyak syarikat pemanduan autonomi akan menyumber luar sebahagian daripada kerja pelabelan kepada syarikat pelabelan Sesetengah syarikat tidak mempunyai pasukan pelabelan dalaman dan semua kerja pelabelan adalah daripada sumber luar.
Pada masa ini, sasaran yang diberi anotasi menggunakan kaedah pra-anotasi model besar adalah terutamanya sasaran 3D dinamik Syarikat pemanduan autonomi akan menggunakan model besar untuk membuat inferens pada video itu perlu diberi anotasi, dan kemudian Berikan hasil inferens - kotak 3D yang dijana oleh model kepada syarikat anotasi. Apabila pra-anotasi model besar dahulu, dan kemudian menyerahkan hasil pra-anotasi kepada syarikat anotasi, terdapat dua masalah utama yang terlibat: satu ialah platform anotasi bagi sesetengah syarikat anotasi mungkin tidak semestinya menyokong pemuatan hasil pra-anotasi ialah syarikat anotasi tidak semestinya bersedia untuk membuat pengubahsuaian pada hasil pra-anotasi.
Jika syarikat anotasi ingin memuatkan hasil pra-anotasi, ia memerlukan platform perisian yang menyokong pemuatan bingkai 3D yang dihasilkan oleh model besar. Walau bagaimanapun, sesetengah syarikat anotasi mungkin menggunakan anotasi manual terutamanya dan mereka tidak mempunyai platform perisian yang menyokong pemuatan hasil pra-anotasi model Jika mereka mendapat hasil model pra-anotasi semasa menyambung dengan pelanggan, mereka tidak mempunyai cara untuk menerimanya.
Selain itu, dari perspektif syarikat anotasi, hanya jika kesan pra-anotasi cukup baik mereka boleh benar-benar "menjimatkan usaha", jika tidak, mereka mungkin meningkatkan beban kerja mereka.
Jika kesan prapelabelan tidak cukup baik, syarikat pelabelan masih perlu melakukan banyak kerja pada masa hadapan, seperti melabelkan kotak yang hilang, memadamkan kotak yang dilabel dengan salah dan melaraskan saiz kotak. Kemudian, menggunakan pra-anotasi mungkin tidak benar-benar membantu mereka mengurangkan beban kerja mereka.
Oleh itu, dalam aplikasi praktikal, sama ada untuk menggunakan model besar untuk pra-anotasi perlu ditimbang oleh kedua-dua syarikat pemanduan autonomi dan syarikat anotasi.
Sudah tentu, kos semasa anotasi manual agak tinggi - jika syarikat anotasi bermula dari awal, kos anotasi manual bagi 1,000 bingkai data video mungkin mencecah 10,000 yuan. Oleh itu, syarikat pemanduan autonomi masih berharap untuk meningkatkan ketepatan pra-pelabelan model besar sebanyak mungkin dan mengurangkan beban kerja pelabelan manual sebanyak mungkin, sekali gus mengurangkan kos pelabelan.
1.1.2 Perlombongan Data
Model besar mempunyai generalisasi yang kuat, sesuai untuk perlombongan data ekor panjang.
Seorang pakar dari WeRide memberitahu pengarang: Jika kaedah berasaskan tag tradisional digunakan untuk melombong adegan ekor panjang, model secara amnya hanya boleh membezakan kategori imej yang diketahui. Pada tahun 2021, OpenAI mengeluarkan model CLIP (model berbilang mod imej teks yang boleh sepadan dengan teks dan imej selepas latihan pra tanpa pengawasan, dengan itu mengklasifikasikan imej berdasarkan teks dan bukannya bergantung hanya pada label imej) ), kita boleh juga mengguna pakai model berbilang mod imej-teks dan gunakan perihalan teks untuk mendapatkan semula data imej dalam log pemacu. Contohnya, adegan ekor panjang seperti ‘kenderaan binaan mengheret barang’ dan ‘lampu isyarat dengan dua mentol menyala serentak’.
Selain itu, model besar boleh mengekstrak ciri daripada data dengan lebih baik dan kemudian mencari sasaran dengan ciri yang serupa.
Seandainya kita ingin mencari gambar yang mengandungi pekerja sanitasi dari banyak gambar Kita tidak perlu melabelkan gambar secara khusus terlebih dahulu Kita boleh melatih model besar dengan jumlah gambar yang banyak mengandungi pekerja sanitasi, model besar boleh mengekstrak beberapa ciri pekerja sanitasi. Kemudian, sampel yang sepadan dengan ciri-ciri pekerja sanitasi didapati daripada gambar, dengan itu melombong hampir semua gambar yang mengandungi pekerja sanitasi.
1.1.3 Gunakan penyulingan pengetahuan untuk "mengajar" model kecil
Model Besar juga boleh menggunakan penyulingan pengetahuan untuk "mengajar" model kecil.
Apakah penyulingan pengetahuan? Untuk menerangkannya dalam istilah yang paling popular, model besar mula-mula mempelajari beberapa pengetahuan daripada data, atau mengekstrak beberapa maklumat, dan kemudian menggunakan pengetahuan yang dipelajari untuk "mengajar" model kecil.
Secara praktikal, kita boleh mempelajari imej yang perlu dilabelkan oleh model besar, dan model besar boleh melabelkan imej ini , menggunakan gambar ini untuk melatih model kecil ialah cara penyulingan pengetahuan yang paling mudah.
Sudah tentu, kami juga boleh menggunakan kaedah yang lebih kompleks, seperti pertama kali menggunakan model besar untuk mengekstrak ciri daripada data besar-besaran, dan ciri yang diekstrak ini boleh digunakan untuk melatih model kecil. Dalam erti kata lain, kita juga boleh mereka bentuk model yang lebih kompleks dan menambah model sederhana antara model besar dan model kecil Ciri yang diekstrak oleh model besar mula-mula melatih model sederhana, dan kemudian menggunakan model sederhana terlatih untuk mengekstrak ciri dan berikan mereka kepada model kecil. Jurutera boleh memilih kaedah reka bentuk mengikut keperluan mereka sendiri.
Penulis belajar daripada Xiaoma.ai bahawa dengan menyuling dan memperhalusi ciri yang diekstrak daripada model besar, model kecil seperti perhatian pejalan kaki dan pengecaman niat pejalan kaki boleh diperolehi peringkat pengekstrakan Dengan berkongsi model yang besar, jumlah pengiraan boleh dikurangkan.
1.1.4 Had atas prestasi model kenderaan ujian
Model besar tidak mengapa Digunakan untuk menguji had atas prestasi model sisi kereta. Apabila sesetengah syarikat sedang mempertimbangkan model mana yang hendak digunakan dalam kereta, mereka akan menguji beberapa model alternatif dalam awan terlebih dahulu untuk melihat model mana yang mempunyai kesan terbaik dan sejauh mana prestasi terbaik boleh dicapai selepas meningkatkan bilangan parameter.
Kemudian, model dengan kesan terbaik digunakan sebagai model asas, dan kemudian model asas disesuaikan dan dioptimumkan sebelum digunakan pada kenderaan.
1.1.5 Pembinaan semula dan penjanaan data adegan pemanduan autonomi
Hao Mo Zhixing ada di sini Ia telah disebut pada AI DAY pada Januari 2023: “Menggunakan teknologi NeRF, kami secara tersirat boleh menyimpan pemandangan dalam rangkaian saraf, dan kemudian mempelajari parameter tersirat tempat kejadian melalui pembelajaran diselia gambar yang diberikan, dan kemudian secara automatik Pembinaan Semula adegan memandu ”
Sebagai contoh, kita boleh memasukkan gambar, pose yang sepadan dan awan titik padat pemandangan berwarna ke dalam rangkaian, dan berdasarkan rangkaian grid titik, awan titik berwarna akan dipaparkan pada resolusi yang berbeza mengikut pose gambar input Lakukan rasterisasi untuk menjana deskriptor saraf pada berbilang skala, dan kemudian menggabungkan ciri pada skala yang berbeza melalui rangkaian.
Kemudian, deskriptor, kedudukan, parameter kamera sepadan dan parameter pendedahan imej awan titik padat yang dijana dimasukkan ke dalam rangkaian seterusnya untuk pemetaan nada yang diperhalusi, dan sintesis boleh selesai Menghasilkan gambar dengan warna dan pendedahan yang konsisten.
Dengan cara ini, kita boleh membina semula adegan itu. Kemudian, kita boleh menjana pelbagai data realiti tinggi dengan menukar perspektif, menukar pencahayaan, dan menukar bahan tekstur Contohnya, dengan menukar perspektif, kita boleh mensimulasikan pelbagai gelagat kenderaan utama seperti pertukaran lorong, lencongan dan U-. berpusing, malah mensimulasikan beberapa data perlanggaran yang akan berlaku.
1.2 Aplikasi model besar dalam kenderaan
1.2.1 Menggabungkan model kecil untuk mengesan tugas yang berbeza
Bentuk utama penggunaan model besar di bahagian sisi kereta adalah untuk menggabungkan model kecil yang mengendalikan sub-tugas yang berbeza untuk membentuk "model besar", dan kemudian melakukan inferens bersama . "Model besar" di sini tidak bermakna sejumlah besar parameter dalam pengertian tradisional - contohnya, model besar dengan lebih 100 juta parameter Sudah tentu, model gabungan akan menjadi lebih besar daripada model kecil yang mengendalikan subtugas yang berbeza.
Dalam model persepsi sisi kenderaan tradisional, model yang mengendalikan subtugas yang berbeza melakukan inferens secara bebas. Sebagai contoh, satu model bertanggungjawab untuk tugas pengesanan garisan lorong, dan model lain bertanggungjawab untuk tugas pengesanan lampu isyarat Apabila tugas persepsi meningkat, jurutera akan menambah model untuk melihat sasaran tertentu dalam sistem.
Sistem pemanduan automatik sebelum ini mempunyai fungsi yang lebih sedikit dan tugas persepsi adalah agak mudah Namun, dengan peningkatan fungsi sistem pemanduan automatik, semakin banyak tugas persepsi. Jika tugasan yang berbeza masih digunakan secara berasingan Jika model kecil yang bertanggungjawab untuk tugasan yang sepadan digunakan untuk alasan bebas, kelewatan sistem akan menjadi terlalu besar dan akan ada risiko keselamatan.
Rangka kerja persepsi berbilang tugas BEV Teknologi Juefei menggabungkan model persepsi tugas tunggal kecil sasaran berbeza untuk membentuk sistem yang boleh mengeluarkan maklumat statik pada masa yang sama - termasuk garisan lorong, Anak panah tanah , lintasan zebra persimpangan, garisan hentian, dsb., serta maklumat dinamik - termasuk lokasi, saiz, orientasi, dsb. peserta trafik. Rangka kerja algoritma persepsi pelbagai tugas BEV bagi Teknologi Juefei ditunjukkan dalam rajah di bawah:
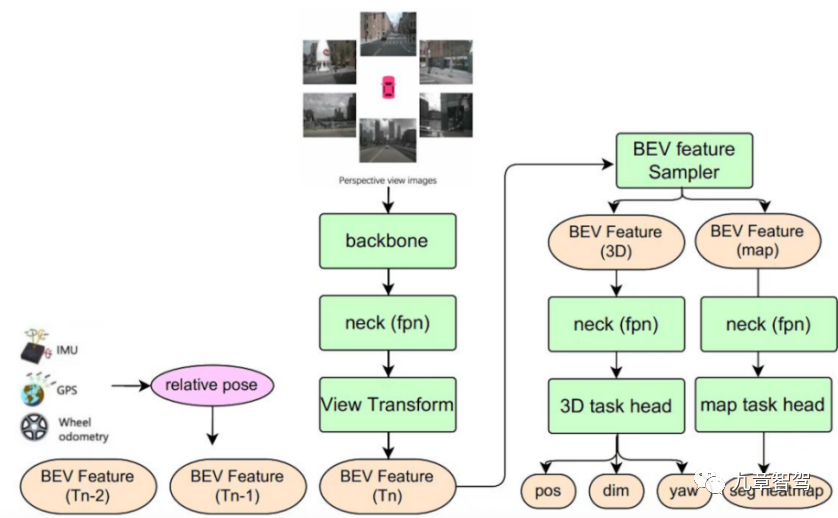
Teknologi Juefei Gambarajah Berbilang Skema BEV bagi rangka kerja algoritma kesedaran tugas
Model kesedaran pelbagai tugas merealisasikan gabungan ciri temporal - menyimpan ciri BEV pada detik bersejarah ke dalam baris gilir ciri. Dalam fasa inferens, semasa Sistem koordinat kenderaan sendiri pada masa itu digunakan sebagai penanda aras, dan ciri BEV pada masa sejarah adalah sejajar spatio-temporally (termasuk putaran ciri dan terjemahan) mengikut keadaan gerakan kenderaan sendiri. , dan kemudian ciri BEV yang diselaraskan pada masa sejarah disambungkan dengan ciri BEV pada masa semasa.
Dalam senario pemanduan autonomi, gabungan masa boleh meningkatkan ketepatan algoritma persepsi dan menebus pengehadan persepsi bingkai tunggal pada tahap tertentu. Mengambil subtugas pengesanan sasaran 3D yang ditunjukkan dalam rajah sebagai contoh, dengan gabungan temporal, model persepsi boleh mengesan beberapa sasaran yang tidak dapat dikesan oleh model persepsi bingkai tunggal (seperti sasaran yang terhalang pada saat semasa), dan juga boleh menilai sasaran dengan lebih tepat kelajuan pergerakan, dan membantu tugasan hiliran dalam ramalan trajektori sasaran.
Dr. Qi Yuhan, ketua teknologi penderiaan BEV di Juefei Technology, memberitahu pengarang: Menggunakan seni bina model sedemikian, apabila pengesanan tugas menjadi semakin kompleks, gabungan pelbagai tugas rangka kerja penderiaan boleh Ia memastikan persepsi masa nyata dan juga boleh mengeluarkan hasil persepsi yang lebih dan lebih tepat untuk penggunaan hiliran sistem pemanduan autonomi.
Walau bagaimanapun, penggabungan model kecil pelbagai tugas juga akan membawa beberapa masalah. Dari peringkat algoritma, prestasi model yang digabungkan pada subtugas yang berbeza mungkin "digulung semula" - iaitu, prestasi pengesanan model adalah lebih rendah daripada model tugasan tunggal bebas. Walaupun struktur rangkaian model besar yang dibentuk dengan menggabungkan model kecil yang berbeza masih boleh menjadi sangat canggih, model gabungan itu perlu menyelesaikan masalah latihan bersama pelbagai tugas.
Dalam latihan bersama berbilang tugas, setiap subtugas mungkin tidak dapat berkumpul pada masa yang sama, dan setiap tugas akan dipengaruhi oleh "pemindahan negatif", dan model gabungan akan Ketepatan "rollback" berlaku pada tugasan tertentu. Pasukan algoritma perlu mengoptimumkan struktur model gabungan sebanyak mungkin, melaraskan strategi latihan bersama, dan mengurangkan kesan fenomena "pemindahan negatif".
1.2.2 Pengesanan Objek
Seorang pakar industri memberitahu pengarang: beberapa yang sebenar Objek dengan nilai yang agak tetap sesuai untuk pengesanan dengan model besar.
Jadi, apakah objek yang mempunyai nilai kebenaran yang agak tetap?
Apa yang dipanggil objek dengan nilai kebenaran tetap ialah objek yang nilai kebenarannya tidak akan dipengaruhi oleh cuaca, masa dan faktor lain, seperti garis lorong, tiang, tiang lampu, lampu isyarat , lintasan zebra, ruang bawah tanah Garisan tempat letak kereta, tempat letak kereta, dll. Kewujudan dan lokasi objek ini adalah tetap dan tidak akan berubah kerana faktor seperti hujan atau kegelapan Selagi kenderaan itu melalui kawasan yang sepadan, kedudukannya tetap . Objek sedemikian sesuai untuk pengesanan dengan model besar.
1.2.3 Ramalan topologi lorong
AI syarikat pemanduan autonomi dalam syarikat DAY menyebut: "Berdasarkan peta ciri BEV, kami menggunakan peta standard sebagai maklumat panduan dan menggunakan rangkaian pengekodan dan penyahkodan autoregresif untuk menyahkod ciri BEV ke dalam urutan titik topologi berstruktur untuk mencapai ramalan topologi lorong."
02
Cara memanfaatkan model besar dengan baik
Dengan trend sumber terbuka dalam industri, rangka kerja model asas ialah bukan lagi rahsia. Banyak kali, perkara yang menentukan sama ada syarikat boleh membuat produk yang baik ialah keupayaan kejuruteraannya.
Keupayaan kejuruteraan menentukan sama ada kita boleh mengesahkan kebolehlaksanaan idea dengan cepat apabila kita memikirkan beberapa kaedah yang mungkin berkesan dalam meningkatkan keupayaan sistem. Perkara besar yang dimiliki oleh Tesla dan Open AI ialah kedua-dua syarikat mempunyai keupayaan kejuruteraan yang kukuh. Mereka boleh menguji kebolehpercayaan idea secepat mungkin dan kemudian menggunakan data berskala besar pada model yang dipilih.
Untuk menggunakan sepenuhnya keupayaan model besar dalam amalan, keupayaan kejuruteraan syarikat adalah sangat penting. Seterusnya, kami akan menerangkan jenis keupayaan kejuruteraan yang diperlukan untuk menggunakan model besar mengikut proses pembangunan model.
2.1 Naik taraf storan data dan sistem pemindahan fail
Jumlah parameter model besar adalah sangat besar melatih model besar Bahagiannya juga besar. Sebagai contoh, pasukan algoritma Tesla menggunakan kira-kira 1.4 bilion imej untuk melatih rangkaian penghunian 3D yang dibincangkan oleh pasukan itu pada Hari AI tahun lepas.
Malah, nilai awal bilangan imej mungkin berpuluh-puluh atau ratusan kali ganda bilangan sebenar yang digunakan, kerana kita perlu menapis terlebih dahulu yang berharga untuk latihan model daripada data besar-besaran, oleh itu, memandangkan bilangan imej yang digunakan untuk latihan model ialah 1.4 bilion, bilangan imej asal mestilah lebih besar daripada 1.4 bilion.
Jadi, bagaimana hendak menyimpan berpuluh bilion malah ratusan bilion data imej? Ini adalah cabaran besar untuk kedua-dua sistem pembacaan fail dan sistem penyimpanan data. Khususnya, data pemanduan autonomi semasa adalah dalam bentuk klip, dan bilangan fail adalah besar, yang memerlukan kecekapan tinggi dalam penyimpanan segera fail kecil.
Untuk menghadapi cabaran sedemikian, sesetengah syarikat dalam industri menggunakan kaedah penyimpanan kepingan untuk data, dan kemudian menggunakan seni bina teragih untuk menyokong akses berbilang pengguna dan berbilang serentak lebar jalur pemprosesan boleh Mencapai 100G/s, kependaman I/O boleh serendah 2 milisaat. Apa yang dipanggil berbilang pengguna merujuk kepada ramai pengguna yang mengakses fail data tertentu pada masa yang sama merujuk kepada keperluan untuk mengakses fail data tertentu dalam berbilang benang Sebagai contoh, apabila jurutera melatih model, mereka menggunakan berbilang -benang. Setiap utas Semua memerlukan penggunaan fail data tertentu.
2.2 Cari seni bina rangkaian yang sesuai dengan cekap
Dengan data besar, bagaimana untuk memastikan model mengabstrak maklumat data dengan lebih baik? Ini memerlukan model mempunyai seni bina rangkaian yang sesuai untuk tugasan yang sepadan, supaya kelebihan bilangan parameter model yang besar dapat digunakan sepenuhnya, supaya model mempunyai keupayaan pengekstrakan maklumat yang kukuh.
Lucas, pengurus kanan R&D model besar di SenseTime, memberitahu pengarang: Kami mempunyai sistem reka bentuk model yang sangat besar separa automatik gred perindustrian Kami bergantung pada sistem ini mereka bentuk seni bina rangkaian model yang sangat besar Pada masa ini, anda boleh menggunakan sistem carian rangkaian saraf sebagai asas untuk mencari seni bina rangkaian yang paling sesuai untuk mempelajari data berskala besar.
Apabila mereka bentuk model kecil, kami bergantung terutamanya pada reka bentuk manual, penalaan dan lelaran untuk akhirnya mendapatkan model yang memuaskan, walaupun model ini tidak semestinya optimum Tetapi selepas lelaran, ia pada dasarnya boleh memenuhi keperluan.
Apabila berhadapan dengan model besar, kerana struktur rangkaian model besar adalah sangat kompleks, jika reka bentuk manual, penalaan dan lelaran digunakan, kuasa pengkomputeran akan digunakan dengan banyak, dan sewajarnya Kos tanah juga tinggi. Jadi, bagaimana untuk mereka bentuk seni bina rangkaian dengan cepat dan cekap yang cukup baik untuk latihan dengan sumber yang terhad adalah masalah yang perlu diselesaikan.
Lucas menjelaskan bahawa kami mempunyai satu set perpustakaan pengendali dan struktur rangkaian model boleh dilihat sebagai susunan dan gabungan set pengendali ini. Sistem carian gred industri ini boleh mengira cara mengatur dan menggabungkan pengendali dengan menetapkan parameter asas, termasuk berapa banyak lapisan rangkaian dan berapa besar parameter itu, untuk mencapai kesan model yang lebih baik.
Prestasi model boleh dinilai berdasarkan beberapa kriteria, termasuk ketepatan ramalan untuk set data tertentu, memori yang digunakan oleh model semasa berjalan dan masa yang diperlukan untuk menunggu pelaksanaan model. Dengan memberikan pemberat yang sesuai kepada metrik ini, kami boleh terus mengulang sehingga kami menemui model yang memuaskan. Sudah tentu, dalam peringkat carian, kami mula-mula akan cuba menggunakan beberapa adegan kecil untuk menilai pada mulanya kesan model.
Apabila menilai kesan model, bagaimana untuk memilih beberapa adegan yang lebih representatif?
Secara umumnya, anda boleh memilih beberapa adegan biasa. Seni bina rangkaian direka bentuk terutamanya untuk memastikan model mempunyai keupayaan untuk mengekstrak maklumat utama daripada sejumlah besar data, dan bukannya berharap model itu dapat mempelajari ciri-ciri senario tertentu Oleh itu, selepas menentukan seni bina model, model akan digunakan Untuk menyelesaikan beberapa tugasan melombong senario long-tail, tetapi apabila memilih seni bina model, senario umum akan digunakan untuk menilai keupayaan model.
Dengan sistem carian rangkaian saraf berkecekapan tinggi dan berketepatan tinggi, kecekapan pengiraan dan ketepatan pengiraan adalah cukup tinggi, supaya kesan model boleh menumpu dengan cepat dan ia boleh ditemui dengan cepat dalam ruang yang besar. Seni bina rangkaian yang berfungsi dengan baik.
2.3 Meningkatkan kecekapan latihan model
Selepas kerja asas sebelum ini selesai, kami datang ke sesi latihan di tempat Pengoptimuman sesi latihan.
2.3.1 Operator pengoptimuman
Rangkaian saraf boleh difahami sebagai terdiri daripada banyak asas Ia diperoleh daripada susunan dan gabungan pengendali Dalam satu tangan, pengiraan operator menduduki sumber kuasa pengkomputeran, dan sebaliknya, ia menduduki memori. Jika pengendali boleh dioptimumkan untuk meningkatkan kecekapan pengiraan pengendali, maka kecekapan latihan boleh dipertingkatkan.
Sudah ada beberapa rangka kerja latihan AI di pasaran - seperti PyTorch, TensorFlow, dll. Rangka kerja latihan ini boleh menyediakan pengendali asas untuk jurutera pembelajaran mesin memanggil untuk membina model mereka sendiri. . Sesetengah syarikat akan membina rangka kerja latihan mereka sendiri dan mengoptimumkan pengendali asas untuk meningkatkan kecekapan latihan.
PyTorch dan TensorFlow perlu memastikan fleksibiliti sebanyak mungkin, jadi pengendali yang disediakan oleh PyTorch dan TensorFlow secara amnya sangat asas. Perusahaan boleh menyepadukan pengendali asas mengikut keperluan mereka sendiri, menghapuskan keperluan untuk menyimpan hasil perantaraan, menjimatkan penggunaan memori dan mengelakkan kehilangan prestasi.
Selain itu, untuk menyelesaikan masalah bahawa sesetengah pengendali tertentu tidak dapat menggunakan keselarian GPU dengan baik kerana pergantungan tinggi mereka pada keputusan pertengahan semasa pengiraan, beberapa syarikat dalam industri telah membina perpustakaan pecutan mereka sendiri, mengurangkan pergantungan pengendali ini pada hasil perantaraan, supaya proses pengiraan dapat menggunakan sepenuhnya kelebihan pengkomputeran selari GPU dan meningkatkan kelajuan latihan.
Sebagai contoh, pada empat model Transformer arus perdana, LightSeq ByteDance mencapai sehingga 8x pecutan berdasarkan PyTorch.
2.3.2 Gunakan strategi selari dengan baik
Pengkomputeran selari ialah " gunakan Kaedah "ruang-untuk-masa" adalah untuk menyelaraskan data tanpa kebergantungan pengiraan sebanyak mungkin, membahagikan kelompok besar kepada kelompok kecil, mengurangkan masa menunggu GPU melahu dalam setiap langkah pengiraan, dan meningkatkan daya pemprosesan pengiraan.
Banyak syarikat pada masa ini menggunakan rangka kerja latihan PyTorch Rangka kerja latihan ini termasuk mod DDP - sebagai mod latihan selari data teragih, mod DDP mereka bentuk pengedaran data Mekanisme ini boleh menyokong berbilang-. latihan mesin dan berbilang kad Contohnya, jika sebuah syarikat mempunyai 8 pelayan dan setiap pelayan mempunyai 8 kad, maka kita boleh menggunakan 64 kad untuk latihan pada masa yang sama.
Tanpa mod ini, jurutera hanya boleh menggunakan satu mesin dengan berbilang kad untuk melatih model. Katakan kita kini menggunakan 100,000 data imej untuk melatih model Dalam mod berbilang kad mesin tunggal, masa latihan akan menjadi lebih daripada seminggu. Jika kita ingin menggunakan hasil latihan untuk menilai tekaan tertentu, atau ingin memilih yang terbaik daripada beberapa model alternatif, masa latihan sedemikian akan menjadikan tempoh menunggu yang diperlukan untuk mengesahkan tekaan dengan cepat dan menguji kesan model dengan cepat sangat lama. Kemudian kecekapan R&D akan menjadi sangat rendah.
Dengan latihan selari berbilang mesin dan berbilang kad, kebanyakan hasil eksperimen dapat dilihat dalam masa 2-3 hari, proses pengesahan kesan model adalah banyak lebih pantas.
Dari segi kaedah selari khusus, selari model dan selari jujukan boleh digunakan terutamanya.
Selarian model boleh dibahagikan kepada selari Paip dan selari Tensor, seperti yang ditunjukkan dalam rajah di bawah.
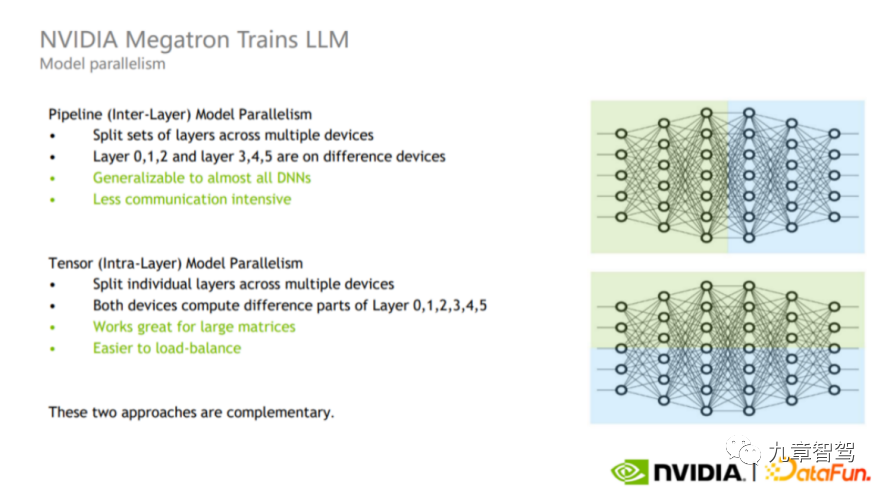
Gambarajah skematik paralelisme saluran paip dan selari tensor, gambar itu datang daripada NVIDIA
Sejajaran saluran paip ialah selari antara lapisan (bahagian atas gambar semasa proses latihan, jurutera boleh membahagikan lapisan model yang berbeza kepada GPU yang berbeza untuk pengiraan). Sebagai contoh, seperti yang ditunjukkan di bahagian atas rajah, bahagian hijau lapisan dan bahagian biru boleh dikira pada GPU yang berbeza.
Selarian tensor ialah selari dalam lapisan (bahagian bawah gambar Jurutera boleh membahagikan pengiraan lapisan kepada GPU yang berbeza). Mod ini sesuai untuk pengiraan matriks besar kerana ia boleh mencapai pengimbangan beban antara GPU, tetapi bilangan komunikasi dan jumlah data adalah agak besar.
Selain keselarian model, terdapat juga Keselarian Jujukan Memandangkan Keselarian Tensor tidak memisahkan Lapisan-norma dan Keciciran, kedua-dua operator ini akan diulang antara setiap GPU jumlah pengiraan tidak besar, ia mengambil banyak memori video aktif.
Untuk menyelesaikan masalah ini, dalam proses sebenar, kita boleh mengambil kesempatan daripada fakta bahawa Layer-norm dan Dropout adalah bebas antara satu sama lain di sepanjang dimensi jujukan (iaitu , Layer_norm antara lapisan berbeza dan Dropout tidak menjejaskan satu sama lain), split Layer-norm dan Dropout, seperti yang ditunjukkan dalam rajah di bawah. Kelebihan perpecahan ini ialah ia tidak meningkatkan volum komunikasi dan boleh mengurangkan penggunaan memori dengan banyak.
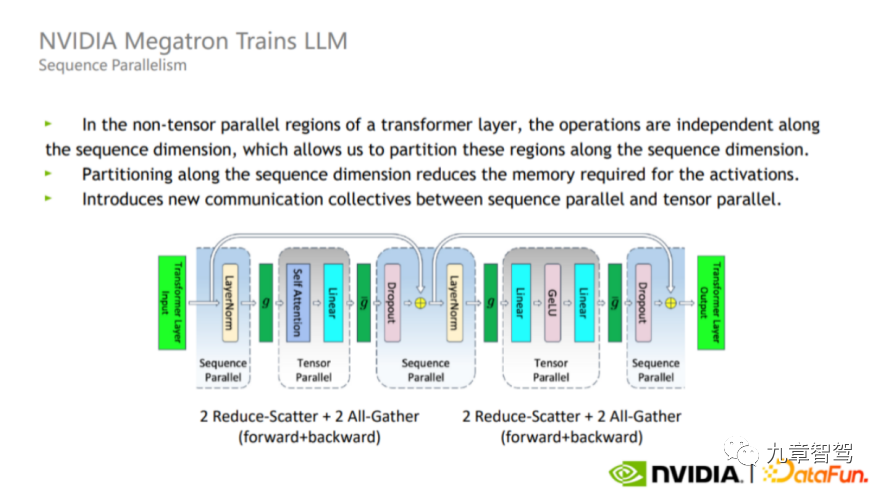
Susun rajah selari, gambar daripada NVIDIA
Dalam amalan, model yang berbeza mempunyai strategi selari yang sesuai Jurutera perlu mencari strategi selari yang sesuai selepas penyahpepijatan berterusan berdasarkan ciri model, ciri perkakasan yang digunakan dan proses pengiraan pertengahan.
2.3.3 Gunakan dengan baik sifat "jarang"
Apabila melatih model, anda juga mesti menggunakan sparsity dengan baik, iaitu, tidak setiap neuron mesti "diaktifkan" - iaitu, apabila menambah data latihan, tidak setiap parameter model mesti berdasarkan The newly data tambahan dikemas kini, tetapi beberapa parameter model kekal tidak berubah, dan beberapa parameter model dikemas kini dengan data yang baru ditambah.
Pemprosesan jarang yang baik boleh memastikan ketepatan sambil meningkatkan kecekapan latihan model.
Sebagai contoh, dalam tugas persepsi, apabila gambar baharu diperkenalkan, anda boleh memilih parameter yang perlu dikemas kini berdasarkan gambar ini untuk melaksanakan pengekstrakan ciri yang disasarkan.
2.3.4 Pemprosesan bersepadu maklumat asas
Secara umumnya, terdapat lebih banyak lagi daripada Model akan digunakan, dan model ini mungkin menggunakan data yang sama Contohnya, kebanyakan model akan menggunakan data video. Jika setiap model memuatkan dan memproses data video, akan terdapat banyak pengiraan berulang. Kami boleh memproses pelbagai maklumat mod secara seragam seperti video, awan titik, peta dan isyarat CAN yang perlu digunakan oleh kebanyakan model, supaya model yang berbeza boleh menggunakan semula hasil pemprosesan.
2.3.5 Mengoptimumkan konfigurasi perkakasan
Apabila sebenarnya menggunakan latihan teragih, 1,000 mesin boleh digunakan. Bagaimana untuk mendapatkan hasil perantaraan semasa proses latihan - seperti kecerunan - daripada pelayan berbeza yang menyimpan data, dan kemudian menjalankan latihan teragih berskala besar adalah satu cabaran besar.
Untuk menangani cabaran ini, anda perlu terlebih dahulu mempertimbangkan cara mengkonfigurasi CPU, GPU, dll., cara memilih kad rangkaian dan seberapa pantas kad rangkaian itu, supaya penghantaran antara mesin boleh menjadi cepat.
Kedua, adalah perlu untuk menyegerakkan parameter dan menyimpan hasil perantaraan, tetapi apabila skala besar, perkara ini akan menjadi sangat sukar, yang akan melibatkan beberapa kerja komunikasi rangkaian.
Selain itu, keseluruhan proses latihan mengambil masa yang lama, jadi kestabilan kluster perlu sangat tinggi.
03
Adakah bermakna untuk terus meningkatkan parameter model?
Sekarang model besar sudah boleh memainkan beberapa peranan dalam bidang pemanduan autonomi, jika kita terus meningkatkan parameter model, bolehkah kita menjangkakan bahawa model besar boleh menunjukkan beberapa kesan yang menakjubkan?
Menurut komunikasi penulis dengan pakar algoritma dalam bidang pemanduan autonomi, jawapan semasa mungkin tidak, kerana fenomena "kemunculan" yang disebutkan di atas masih belum digunakan dalam CV ( Penglihatan Komputer) Medan muncul. Pada masa ini, bilangan parameter model yang digunakan dalam bidang pemanduan autonomi adalah jauh lebih kecil daripada ChatGPT. Kerana apabila tiada kesan "kemunculan", terdapat hubungan yang linear secara kasar antara peningkatan prestasi model dan peningkatan dalam bilangan parameter Memandangkan kekangan kos, syarikat masih belum memaksimumkan bilangan parameter dalam model.
Mengapa fenomena “kemunculan” masih belum berlaku dalam bidang penglihatan komputer? Penjelasan pakar ialah:
Pertama sekali, walaupun terdapat lebih banyak data visual di dunia daripada data teks, data imej adalah jarang, iaitu, ia mungkin tidak terdapat dalam kebanyakan foto . Berapa banyak maklumat yang berkesan dan kebanyakan piksel dalam setiap imej tidak memberikan maklumat yang berkesan. Jika kita mengambil selfie, kecuali muka di tengah, tiada maklumat yang sah di kawasan latar belakang.
Kedua, data imej mempunyai perubahan skala yang ketara dan tidak berstruktur sama sekali. Perubahan skala bermakna objek yang mengandungi semantik yang sama boleh menjadi besar atau kecil dalam gambar yang sepadan. Sebagai contoh, saya mula-mula mengambil gambar diri sendiri, dan kemudian meminta rakan yang berada jauh untuk mengambil gambar lain untuk saya Dalam kedua-dua gambar, perkadaran wajah dalam foto itu sangat berbeza. Tidak berstruktur bermakna hubungan antara setiap piksel tidak pasti.
Tetapi dalam bidang pemprosesan bahasa semula jadi, memandangkan bahasa adalah alat untuk komunikasi antara orang, konteks biasanya berkaitan, dan ketumpatan maklumat setiap ayat secara amnya adalah besar tiada masalah perubahan skala Sebagai contoh, dalam mana-mana bahasa, perkataan "epal" biasanya tidak terlalu panjang.
Oleh itu, pemahaman data visual itu sendiri akan menjadi lebih sukar daripada bahasa semula jadi.
Seorang pakar industri memberitahu pengarang: Walaupun kita boleh menjangkakan bahawa prestasi model akan bertambah baik apabila bilangan parameter meningkat, keberkesanan kos semasa untuk terus meningkatkan bilangan parameter adalah rendah.
Sebagai contoh, jika kita mengembangkan kapasiti model sepuluh kali ganda pada asas sedia ada, kadar ralat relatifnya boleh dikurangkan sebanyak 90%. Pada masa ini, model sudah boleh menyelesaikan beberapa tugas penglihatan komputer seperti pengecaman muka. Jika kita terus mengembangkan kapasiti model sepuluh kali ganda pada masa ini dan kadar ralat relatif terus menurun sebanyak 90%, tetapi nilai yang boleh dicapai tidak meningkat sepuluh kali ganda, maka tidak perlu untuk kita terus berkembang. kapasiti model.
Memperluas kapasiti model akan meningkatkan kos, kerana model yang lebih besar memerlukan lebih banyak data latihan dan lebih banyak kuasa pengkomputeran. Apabila ketepatan model mencapai julat yang boleh diterima, kita perlu membuat pertukaran antara peningkatan kos dan ketepatan yang bertambah baik, dan mengurangkan kos sebanyak mungkin dengan ketepatan yang boleh diterima mengikut keperluan sebenar.
Walaupun masih terdapat beberapa tugasan yang kami perlukan untuk meningkatkan ketepatan, model besar terutamanya menggantikan beberapa kerja manual dalam awan, seperti anotasi automatik, perlombongan data, dll., yang boleh dilakukan oleh manusia. Sekiranya kosnya terlalu tinggi, maka akaun ekonomi tidak akan dikira.
Walau bagaimanapun, beberapa pakar industri memberitahu pengarang: Walaupun ia masih belum mencapai titik perubahan kualitatif, apabila parameter model meningkat dan jumlah data meningkat, kita sememangnya boleh memerhatikan bahawa ketepatan model telah diteruskan Dalam promosi. Jika ketepatan model yang digunakan untuk tugas pelabelan cukup tinggi, tahap pelabelan automatik akan dipertingkatkan, sekali gus mengurangkan banyak kos buruh. Pada masa ini, walaupun kos latihan akan meningkat apabila saiz model meningkat, kos secara kasarnya berkaitan secara linear dengan bilangan parameter model. Walaupun kos latihan akan meningkat, pengurangan tenaga kerja boleh mengimbangi peningkatan ini, jadi peningkatan bilangan parameter masih akan membawa faedah.
Selain itu, kami juga akan menggunakan beberapa teknik untuk meningkatkan bilangan parameter model sambil meningkatkan kecekapan latihan untuk meminimumkan kos latihan. Kita boleh meningkatkan bilangan parameter model dan meningkatkan ketepatan model sambil mengekalkan kos tetap dalam skala model sedia ada. Ini bersamaan dengan menghalang kos model daripada meningkat secara linear apabila bilangan parameter model meningkat Kita boleh mencapai bahawa kos hampir tidak meningkat atau hanya meningkat sedikit.
04
Aplikasi lain yang mungkin untuk model besar
Selain aplikasi yang dinyatakan di atas, bagaimana lagi kita boleh Apa tentang mencari nilai model besar?
4.1 Dalam bidang persepsi
CMU Research Scientist Max memberitahu penulis: untuk menggunakan model besar untuk mencapai tugas persepsi, terasnya adalah bukan menyusun parameter, tetapi Untuk mencipta rangka kerja yang boleh 'beredar secara dalaman'. Jika keseluruhan model tidak dapat mencapai gelung dalaman, atau tidak dapat mencapai latihan dalam talian yang berterusan, sukar untuk mencapai keputusan yang baik.
Jadi, bagaimana untuk melaksanakan "gelung dalaman" model? Kita boleh merujuk kepada rangka kerja latihan ChatGPT, seperti yang ditunjukkan dalam rajah di bawah.
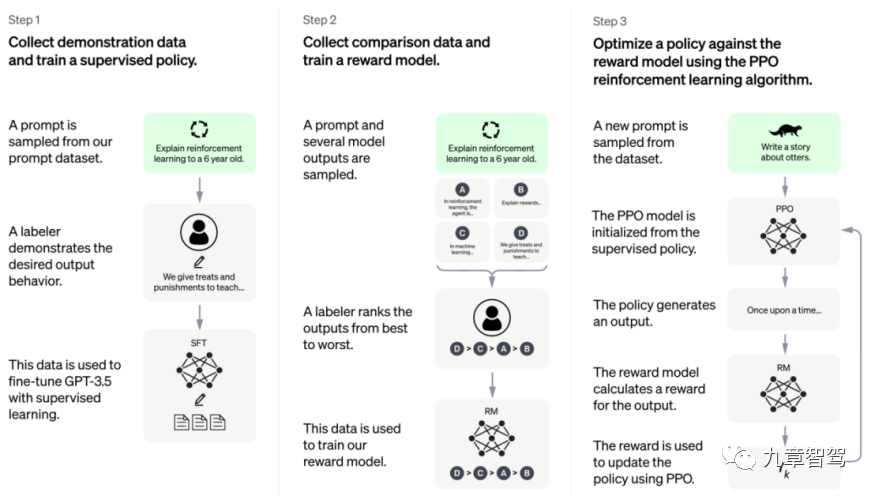
Rangka kerja latihan ChatGPT, gambar diambil dari laman web rasmi Open AI
Rangka kerja model ChatGPT boleh dibahagikan kepada tiga langkah: langkah pertama ialah pembelajaran diselia, di mana jurutera mula-mula mengumpul dan melabel sebahagian daripada data, dan kemudian menggunakan bahagian data ini untuk melatih model ; langkah kedua adalah untuk mereka bentuk model ganjaran ( Model Ganjaran), model boleh mengeluarkan beberapa hasil pelabelan dengan sendirinya, dalam langkah ketiga, kita boleh melaksanakan pembelajaran diselia sendiri melalui jalan yang serupa dengan pembelajaran pengukuhan, yang dalam bahasa yang lebih popular; dipanggil "bermain dengan diri sendiri", atau Sebut "gelung dalaman".
Selagi langkah ketiga dicapai, model tidak lagi memerlukan jurutera menambah data berlabel, tetapi boleh mengira kerugian dengan sendirinya selepas mendapat data tidak berlabel, dan kemudian mengemas kini parameter , dan seterusnya kitaran, dan akhirnya melengkapkan latihan.
“Jika kita boleh mereka bentuk Dasar Ganjaran yang sesuai semasa melakukan tugasan persepsi supaya latihan model tidak lagi bergantung pada data beranotasi, kita boleh mengatakan bahawa model itu telah mencapai 'gelung dalaman'. Parameter boleh dikemas kini secara berterusan berdasarkan data tidak berlabel ”
4.2 Dalam bidang perancangan
Dalam bidang seperti Go, lebih mudah untuk menilai kualiti setiap langkah, kerana matlamat kami umumnya hanya termasuk memenangi permainan akhirnya.
Namun, dalam bidang perancangan pemanduan autonomi, sistem penilaian untuk tingkah laku yang dipaparkan oleh sistem pemanduan autonomi tidak jelas. Selain memastikan keselamatan, setiap orang mempunyai perasaan yang berbeza tentang keselesaan, dan kami juga mungkin ingin sampai ke destinasi kami secepat mungkin.
Beralih kepada adegan sembang, sama ada maklum balas yang robot berikan setiap kali adalah "baik" atau "buruk" sebenarnya bukanlah sistem penilaian yang sangat jelas seperti Go. Ia serupa dengan ini dengan memandu sendiri, setiap orang mempunyai piawaian yang berbeza tentang apa yang "baik" dan "buruk", dan dia mungkin mempunyai keperluan yang sukar untuk dinyatakan.
Dalam langkah kedua rangka kerja latihan ChatGPT, anotasi mengisih hasil keluaran mengikut model, dan kemudian menggunakan hasil yang diisih ini untuk melatih Model Ganjaran. Pada awalnya, Model Ganjaran ini tidak sempurna, tetapi melalui latihan berterusan, kita boleh menjadikan Model Ganjaran ini terus menghampiri kesan yang kita inginkan.
Seorang pakar dari syarikat kecerdasan buatan memberitahu penulis: Dalam bidang perancangan pemanduan autonomi, kami boleh terus mengumpul data mengenai pemanduan kereta dan kemudian memberitahu model dalam keadaan apa yang manusia kehendaki mengambil alih ( Dalam erti kata lain, orang akan merasakan bahawa terdapat bahaya), dalam keadaan apa ia boleh memandu secara normal, kemudian apabila jumlah data meningkat, Model Ganjaran akan semakin hampir kepada kesempurnaan.
Dalam erti kata lain, kita boleh mempertimbangkan untuk berhenti menulis Model Ganjaran yang sempurna secara eksplisit, dan sebaliknya mendapatkan penyelesaian yang sentiasa menghampiri kesempurnaan dengan memberi maklum balas secara berterusan kepada model.
Berbanding dengan amalan biasa semasa dalam bidang perancangan, iaitu cuba mencari penyelesaian optimum secara eksplisit dengan bergantung pada peraturan penulisan manual, mula-mula menggunakan Model Ganjaran awal, dan kemudian secara berterusan mengoptimumkan berdasarkan data, adalah anjakan paradigma.
Selepas menggunakan kaedah ini, modul perancangan pengoptimuman boleh menerima pakai proses yang agak standard Apa yang perlu kita lakukan ialah mengumpul data secara berterusan dan kemudian melatih Model Ganjaran, yang tidak lagi seperti itu kaedah tradisional itu bergantung kepada kedalaman pemahaman jurutera terhadap keseluruhan modul perancangan.
Selain itu, semua data sejarah boleh digunakan untuk latihan Kami tidak perlu risau tentang perkara itu selepas perubahan peraturan tertentu, walaupun beberapa masalah semasa telah diselesaikan, sebahagian daripadanya mereka telah digunakan sebelum ini. Masalah yang telah diselesaikan akan muncul semula yang akan membelenggu kita sekiranya kita menggunakan kaedah tradisional.
Atas ialah kandungan terperinci Artikel panjang 10,000 perkataan menerangkan aplikasi model besar dalam bidang pemanduan autonomi. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1384
1384
 52
52

 Bagaimana untuk menyelesaikan masalah ekor panjang dalam senario pemanduan autonomi?
Jun 02, 2024 pm 02:44 PM
Bagaimana untuk menyelesaikan masalah ekor panjang dalam senario pemanduan autonomi?
Jun 02, 2024 pm 02:44 PM
Semalam semasa temu bual, saya telah ditanya sama ada saya telah membuat sebarang soalan berkaitan ekor panjang, jadi saya fikir saya akan memberikan ringkasan ringkas. Masalah ekor panjang pemanduan autonomi merujuk kepada kes tepi dalam kenderaan autonomi, iaitu, kemungkinan senario dengan kebarangkalian yang rendah untuk berlaku. Masalah ekor panjang yang dirasakan adalah salah satu sebab utama yang kini mengehadkan domain reka bentuk pengendalian kenderaan autonomi pintar satu kenderaan. Seni bina asas dan kebanyakan isu teknikal pemanduan autonomi telah diselesaikan, dan baki 5% masalah ekor panjang secara beransur-ansur menjadi kunci untuk menyekat pembangunan pemanduan autonomi. Masalah ini termasuk pelbagai senario yang berpecah-belah, situasi yang melampau dan tingkah laku manusia yang tidak dapat diramalkan. "Ekor panjang" senario tepi dalam pemanduan autonomi merujuk kepada kes tepi dalam kenderaan autonomi (AVs) kes Edge adalah senario yang mungkin dengan kebarangkalian yang rendah untuk berlaku. kejadian yang jarang berlaku ini
 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 Apr 09, 2024 am 11:52 AM
Apr 09, 2024 am 11:52 AM
AI memang mengubah matematik. Baru-baru ini, Tao Zhexuan, yang telah mengambil perhatian terhadap isu ini, telah memajukan keluaran terbaru "Buletin Persatuan Matematik Amerika" (Buletin Persatuan Matematik Amerika). Memfokuskan pada topik "Adakah mesin akan mengubah matematik?", ramai ahli matematik menyatakan pendapat mereka Seluruh proses itu penuh dengan percikan api, tegar dan menarik. Penulis mempunyai barisan yang kuat, termasuk pemenang Fields Medal Akshay Venkatesh, ahli matematik China Zheng Lejun, saintis komputer NYU Ernest Davis dan ramai lagi sarjana terkenal dalam industri. Dunia AI telah berubah secara mendadak Anda tahu, banyak artikel ini telah dihantar setahun yang lalu.
 Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Google gembira: prestasi JAX mengatasi Pytorch dan TensorFlow! Ia mungkin menjadi pilihan terpantas untuk latihan inferens GPU
Apr 01, 2024 pm 07:46 PM
Prestasi JAX, yang dipromosikan oleh Google, telah mengatasi Pytorch dan TensorFlow dalam ujian penanda aras baru-baru ini, menduduki tempat pertama dalam 7 penunjuk. Dan ujian tidak dilakukan pada TPU dengan prestasi JAX terbaik. Walaupun dalam kalangan pembangun, Pytorch masih lebih popular daripada Tensorflow. Tetapi pada masa hadapan, mungkin lebih banyak model besar akan dilatih dan dijalankan berdasarkan platform JAX. Model Baru-baru ini, pasukan Keras menanda aras tiga hujung belakang (TensorFlow, JAX, PyTorch) dengan pelaksanaan PyTorch asli dan Keras2 dengan TensorFlow. Pertama, mereka memilih satu set arus perdana
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Mari kita bincangkan tentang sistem pemanduan autonomi hujung ke hujung dan generasi seterusnya, serta beberapa salah faham tentang pemanduan autonomi hujung ke hujung?
Apr 15, 2024 pm 04:13 PM
Mari kita bincangkan tentang sistem pemanduan autonomi hujung ke hujung dan generasi seterusnya, serta beberapa salah faham tentang pemanduan autonomi hujung ke hujung?
Apr 15, 2024 pm 04:13 PM
Pada bulan lalu, atas sebab-sebab yang diketahui umum, saya telah mengadakan pertukaran yang sangat intensif dengan pelbagai guru dan rakan sekelas dalam industri. Topik yang tidak dapat dielakkan dalam pertukaran secara semula jadi adalah hujung ke hujung dan Tesla FSDV12 yang popular. Saya ingin mengambil kesempatan ini untuk menyelesaikan beberapa buah fikiran dan pendapat saya pada masa ini untuk rujukan dan perbincangan anda. Bagaimana untuk mentakrifkan sistem pemanduan autonomi hujung ke hujung, dan apakah masalah yang sepatutnya dijangka diselesaikan hujung ke hujung? Menurut definisi yang paling tradisional, sistem hujung ke hujung merujuk kepada sistem yang memasukkan maklumat mentah daripada penderia dan secara langsung mengeluarkan pembolehubah yang membimbangkan tugas. Sebagai contoh, dalam pengecaman imej, CNN boleh dipanggil hujung-ke-hujung berbanding kaedah pengekstrak ciri + pengelas tradisional. Dalam tugas pemanduan autonomi, masukkan data daripada pelbagai penderia (kamera/LiDAR
 SOTA terbaharu nuScenes |. SparseAD: Pertanyaan jarang membantu pemanduan autonomi hujung ke hujung yang cekap!
Apr 17, 2024 pm 06:22 PM
SOTA terbaharu nuScenes |. SparseAD: Pertanyaan jarang membantu pemanduan autonomi hujung ke hujung yang cekap!
Apr 17, 2024 pm 06:22 PM
Ditulis di hadapan & titik permulaan Paradigma hujung ke hujung menggunakan rangka kerja bersatu untuk mencapai pelbagai tugas dalam sistem pemanduan autonomi. Walaupun kesederhanaan dan kejelasan paradigma ini, prestasi kaedah pemanduan autonomi hujung ke hujung pada subtugas masih jauh ketinggalan berbanding kaedah tugasan tunggal. Pada masa yang sama, ciri pandangan mata burung (BEV) padat yang digunakan secara meluas dalam kaedah hujung ke hujung sebelum ini menyukarkan untuk membuat skala kepada lebih banyak modaliti atau tugasan. Paradigma pemanduan autonomi hujung ke hujung (SparseAD) tertumpu carian jarang dicadangkan di sini, di mana carian jarang mewakili sepenuhnya keseluruhan senario pemanduan, termasuk ruang, masa dan tugas, tanpa sebarang perwakilan BEV yang padat. Khususnya, seni bina jarang bersatu direka bentuk untuk kesedaran tugas termasuk pengesanan, penjejakan dan pemetaan dalam talian. Di samping itu, berat
