

DeepMind sekali lagi telah melancarkan Nature dengan hasil yang hebat!
Kali ini, mereka telah mengukuhkan pembelajaran AI sekali lagi dan membuat penemuan baharu dalam dua algoritma paling asas dalam bidang komputer:
Salah satunya ialah algoritma pengisihan, yang telah menemui peningkatan kelajuan tertinggi 70 % pelaksanaan baharu;
Satu lagi ialah algoritma pencincangan, yang turut menemui cara baharu untuk meningkatkan kelajuan sebanyak 30%.

Bukan itu sahaja, kaedah yang digunakan oleh AI disebut "mencipta semula sentuhan ajaib AlphaGo", yang nampaknya menyalahi undang-undang, tetapi sebenarnya mengalahkannya dalam satu gerakan masa itu dengan tuan manusia Lee Sedol.
Sebaik sahaja berita itu keluar, ia segera meletupkan kalangan akademik Beberapa netizen menyeru:
Saya tidak menyangka bahawa algoritma kuno dan asas sedemikian boleh menjadi lebih jauh. bertambah baik.

Tepatnya kerana pencapaian terbaru inilah perpustakaan C++ standard LLVM, yang tidak dikemas kini selama sepuluh tahun, telah dikemas kini, dan berpuluh-puluh Berbilion orang akan mendapat manfaat.
Oleh kerana, sama ada pengisihan atau pencincangan, senario aplikasi mereka boleh digunakan dalam pelbagai senario daripada beli-belah dalam talian, pengkomputeran awan hingga pengurusan rantaian bekalan, dll., dan ia dipanggil ratusan juta kali setiap hari!
Walau bagaimanapun, seperti yang dikatakan DeepMind:
Jangan terlalu teruja, kuasa AI untuk meningkatkan kecekapan kod baru sahaja bermula.

AI ini dipanggil AlphaDev, dan ia milik "pemula" keluarga Alpha Dan ia dibina berdasarkan AlphaZero (AI catur yang mengalahkan juara dunia pada 2017).
Penemuannya tidak berdasarkan algoritma sedia ada, tetapi bermula dari arahan pemasangan peringkat terendah.
Penyelidik DeepMind mereka bentuk permainan "perhimpunan" pemain tunggal untuknya:
Selagi anda boleh mencari dan memilih arahan yang sesuai (proses A dalam rajah di bawah), ia betul dan pantas Anda boleh mendapatkan ganjaran dengan menyusun data (proses B dalam rajah di bawah).
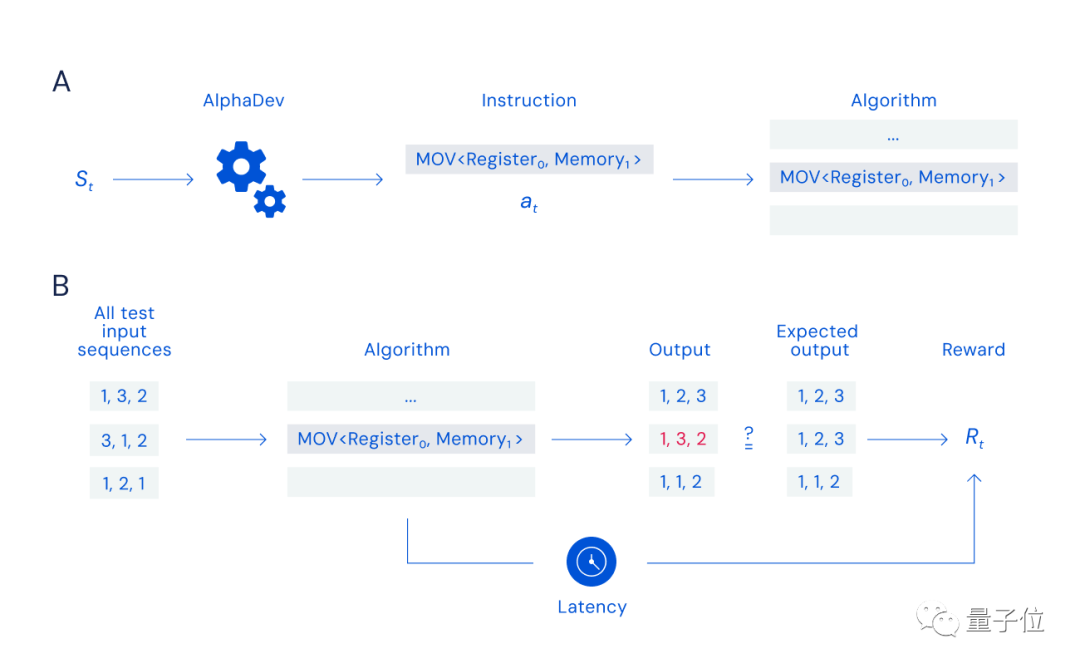
Tetapi cabaran permainan ini bukan sahaja saiz ruang carian (bilangan arahan boleh digabungkan adalah bersamaan dengan nombor zarah di alam semesta), tetapi juga Ia terletak pada sifat fungsi ganjaran, kerana satu arahan yang salah boleh menyebabkan keseluruhan algoritma gagal.
AlphaDev mempunyai dua komponen teras: algoritma pembelajaran dan fungsi perwakilan.
Antaranya, algoritma pembelajaran diperkembangkan terutamanya pada AlphaZero yang berkuasa, yang boleh menggabungkan DRL dan algoritma pengoptimuman carian rawak untuk menjalankan carian arahan yang besar adalah berdasarkan Transformer, yang boleh menangkap pemasangan The underlying; struktur program dan dinyatakan sebagai urutan khas.
Memandangkan AlphaDev terus melawan raksasa dan menaik taraf, penyelidik juga akan mengehadkan bilangan langkah yang boleh dilakukan dan panjang jujukan untuk diisih.
Akhirnya, AlphaDev menemui algoritma pengisihan baharu:
Jika jujukan itu pendek, ia boleh meningkatkan kelajuan sebanyak 70% berbanding dengan algoritma pengisihan garis dasar manusia jika panjang jujukan melebihi 25,000 elemen, peningkatan ialah 1.7%.
Isihan jujukan pendek digunakan secara meluas dalam amalan, terutamanya sebagai bahagian penting dalam fungsi isihan yang lebih besar dan dipanggil berkali-kali. Selagi urutan pendek dipertingkatkan, kelajuan pengisihan semua jujukan boleh dipertingkatkan. )
Secara khususnya, inovasi algoritma ini terutamanya terletak pada dua urutan arahan:
(1) AlphaDev Swap Move (swap move)
(2) AlphaDev Copy Move (copy move )
Seperti yang ditunjukkan dalam rajah di bawah, sebelah kiri ialah pelaksanaan sort3 asal menggunakan min(A,B,C), dan sebelah kanan ialah pelaksanaan "AlphaDev Swap Move", yang hanya memerlukan min( A,B). Ia boleh didapati bahawa satu langkah arahan boleh ditinggalkan, dan hanya nilai minimum A dan B perlu dikira.
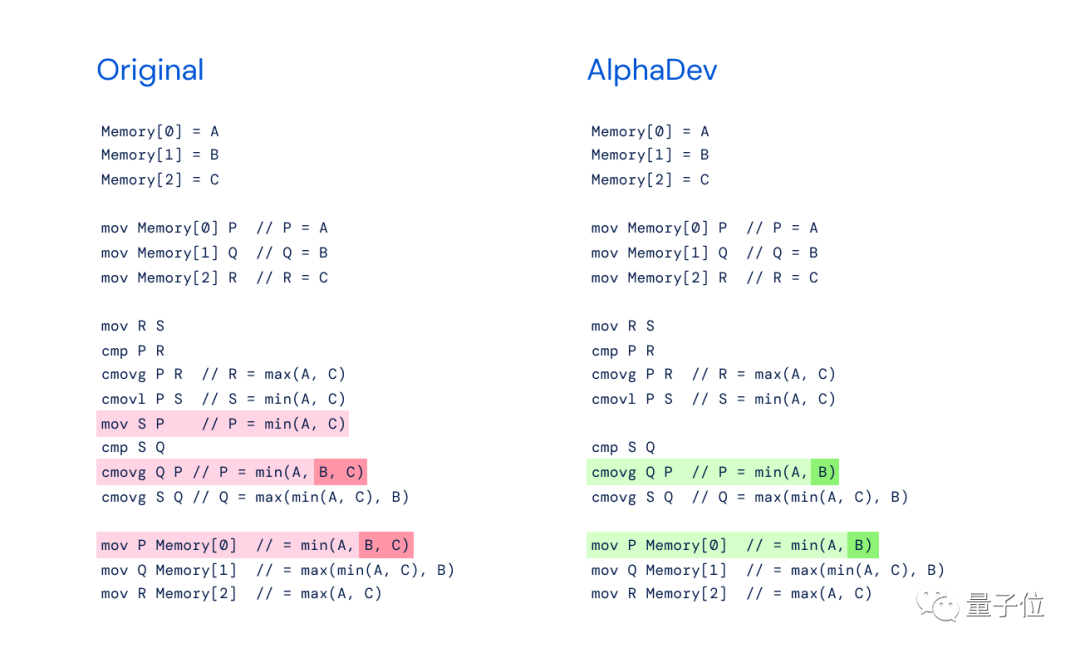
Pengarang mengatakan bahawa kaedah novel ini mengingatkan "Move 37" AlphaGo - kaedah berlawanan dengan intuitif yang secara langsung mengalahkan pemain Go legenda Lee Sedol, yang mengejutkan penonton.
Begitu juga, AlphaDev melangkau langkah dengan menukar dan menyalin pergerakan, mencapai matlamat dengan cara yang kelihatan salah tetapi sebenarnya adalah jalan pintas.
Seperti yang ditunjukkan dalam rajah di bawah, dalam algoritma untuk menyusun 8 elemen, AlphaDev juga menggunakan "AlphaDev Copy Move" untuk menggantikan pelaksanaan asal dengan maks (B, min (A, C)) Ia adalah kompleks arahan maks (B, min (A, C, D)), dan jumlah bilangan arahan keseluruhan algoritma juga dikurangkan dengan satu langkah.

Selepas menemui algoritma pengisihan yang lebih pantas, pengarang turut mencuba algoritma cincang dengan AlphaDev untuk membuktikan kepelbagaiannya.
Hasilnya tidak mengecewakan, AlphaDev juga mencapai peningkatan kelajuan 30% dalam julat panjang 9-16 bait.
Seperti algoritma pengisihan, mereka telah menyepadukan kaedah baharu ke dalam perpustakaan Abseil, yang kini tersedia kepada berjuta-juta pembangun di seluruh dunia.
Akhirnya, pengarang menyatakan bahawa pelaksanaan dua algoritma baharu menunjukkan keupayaan kuat AlphaDev untuk menemui penyelesaian asal, dan akan membuatkan kita lebih berfikir tentang cara menambah baik algoritma asas dalam bidang komputer.
Walau bagaimanapun, disebabkan oleh batasan bahasa himpunan yang digunakan dalam kajian ini, mereka seterusnya merancang untuk mencuba keupayaan AlphaDev untuk mengoptimumkan algoritma dalam bahasa peringkat tinggi (seperti C++).
Ramai orang menyatakan kegembiraan yang besar tentang pencapaian ini.
Seperti kata netizen ini:
Selepas AlphaGo memukau dunia, apa lagi yang boleh dilakukan oleh pembelajaran pengukuhan? Bolehkah sesuatu yang praktikal dilakukan? Ini jawapannya.

Namun, kali ini, ramai yang menegaskan bahawa DeepMind seolah-olah disyaki membesar-besarkan tajuk tersebut.
Ia mengira kelewatan algoritma, bukan kerumitan masa dalam erti kata tradisional. Jika anda benar-benar mengira kerumitan masa, data mungkin tidak kelihatan baik.
Penambahbaikannya bukan pada algoritma pengisihan itu sendiri, tetapi dalam pengoptimuman pengisihan baharu untuk CPU moden (terutamanya untuk jujukan pendek). Pendekatan ini sebenarnya sangat biasa Contohnya, perpustakaan seperti FFTW dan ATLAS telah menggunakan kaedah ini.

Setuju, mereka baru sahaja menemui pengoptimuman mesin yang lebih pantas untuk CPU tertentu, bukan algoritma pengisihan baharu, kaedah itu sendiri adalah sejuk, tetapi belum penyelidikan terobosan.

Apa pendapat anda?
Alamat kertas: https://www.php.cn/link/a3fefe83288ecb0e40ebe40b2bde29fe
Blog rasmi: https://www.php.cn/link/f5b2aaa921/f5b2aa92a
Pautan rujukan:
[1]https://www.php.cn/link/5383c7318a3158b9bc261d0b6996f7c2
[2][2] www.php.cn/link/ecf9902e0f61677c8de25ae60b654669
[3]https://www.php.cn/link/0383314bf626052313b82752313b82752313b8275>
Atas ialah kandungan terperinci Hasilkan semula keajaiban AlphaGo ketika itu! AI baharu DeepMind menemui algoritma pengisihan kelajuan 70%, dan perpustakaan C++ yang belum dikemas kini dalam sepuluh tahun telah dikemas kini. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah perbezaan antara bahasa c++ dan c
Apakah perbezaan antara bahasa c++ dan c
 Perintah pembelajaran yang disyorkan untuk c++ dan python
Perintah pembelajaran yang disyorkan untuk c++ dan python
 Analisis keberkesanan kos pembelajaran python dan c++
Analisis keberkesanan kos pembelajaran python dan c++
 Adakah bahasa c sama dengan c++?
Adakah bahasa c sama dengan c++?
 Mana yang lebih baik untuk belajar dahulu, bahasa c atau c++?
Mana yang lebih baik untuk belajar dahulu, bahasa c atau c++?
 Perbezaan dan hubungan antara bahasa c dan c++
Perbezaan dan hubungan antara bahasa c dan c++
 Tutorial perubahan bahasa Cina perisian C++
Tutorial perubahan bahasa Cina perisian C++
 Analisis keberkesanan kos pembelajaran python, java dan c++
Analisis keberkesanan kos pembelajaran python, java dan c++








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



