

Dalam sepuluh tahun yang lalu atau lebih, perkembangan pesat AI disebabkan terutamanya oleh kemajuan dalam amalan kejuruteraan teori AI tidak memainkan peranan dalam membimbing pembangunan algoritma yang direka secara empirik kotak.
Dengan populariti ChatGPT, keupayaan AI sentiasa dibesar-besarkan dan digembar-gemburkan, malah sehingga mengancam dan menculik masyarakat Adalah penting untuk menjadikan reka bentuk seni bina Transformer telus!

Baru-baru ini, pasukan Profesor Ma Yi mengeluarkan hasil penyelidikan terkini dan mereka bentuk kotak putih Transformer model KRAT yang boleh dijelaskan sepenuhnya secara matematik . Dan mencapai prestasi hampir dengan ViT pada set data dunia sebenar ImageNet-1K.
Pautan kod: https://github.com/Ma-Lab-Berkeley/CRATE
Pautan kertas: https://arxiv.org/abs/2306.01129
Dalam kertas kerja ini, penyelidik percaya bahawa matlamat pembelajaran perwakilan adalah untuk memampatkan dan mengubah data ( Sebagai contoh, pengedaran set token) untuk menyokong pencampuran taburan Gaussian berdimensi rendah pada subruang yang tidak koheren Kualiti perwakilan akhir boleh diukur dengan fungsi objektif bersatu pengurangan kadar jarang.
Dari perspektif ini, model rangkaian dalam yang popular seperti Transformer secara semula jadi boleh dianggap sebagai merealisasikan skim lelaran untuk mengoptimumkan matlamat ini secara beransur-ansur.
Khususnya, keputusan menunjukkan bahawa blok Transformer standard boleh diperolehi daripada pengoptimuman berselang-seli bahagian pelengkap objektif ini: pengendali perhatian diri berbilang kepala boleh dilihat sebagai meminimumkan Langkah penurunan kecerunan mengurangkan kadar pengekodan untuk memampatkan set token, dan perceptron berbilang lapisan seterusnya boleh dianggap sebagai cuba mengurangkan perwakilan token.
Penemuan ini juga mendorong reka bentuk satu siri seni bina rangkaian dalam seperti Transformer kotak putih yang boleh ditafsir sepenuhnya secara matematik Walaupun reka bentuknya ringkas, hasil percubaan menunjukkan bahawa rangkaian ini memang Belajar untuk mengoptimumkan matlamat reka bentuk: memampatkan dan perwakilan jarang bagi set data visual dunia sebenar berskala besar (seperti ImageNet) dan mencapai prestasi yang hampir dengan model Transformer (ViT) yang sangat kejuruteraan.
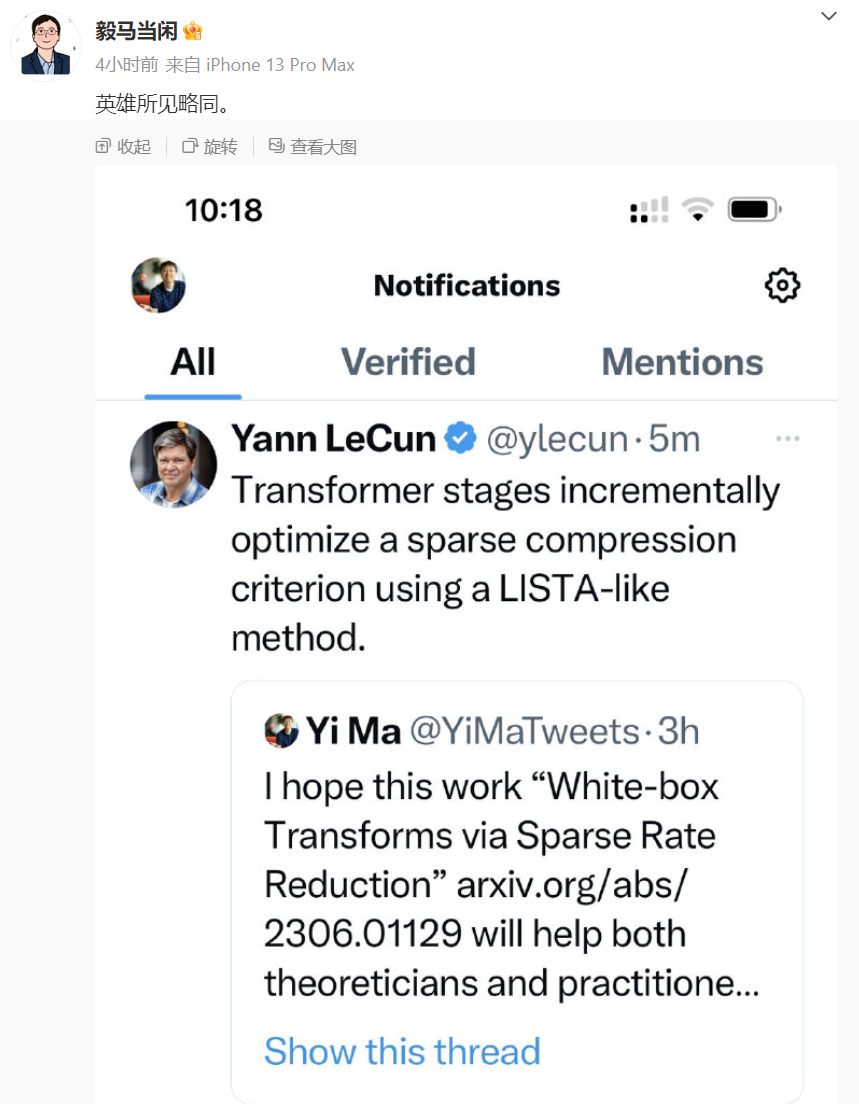
Pemenang Anugerah Turing Yann LeCun juga bersetuju dengan hasil kerja Profesor Ma Yi, percaya bahawa Transformer menggunakan kaedah yang serupa dengan LISTA (Learned Iterative Shrinkage and Thresholding Algorithm) untuk mengoptimumkan pemampatan jarang secara berperingkat.
Profesor Ma Yi menerima ijazah sarjana muda berganda dalam automasi dan matematik gunaan dari Universiti Tsinghua pada tahun 1995, dan ijazah sarjana dalam EECS dari Universiti of California, Berkeley, pada tahun 1997, menerima ijazah sarjana dalam matematik dan ijazah kedoktoran dalam EECS pada tahun 2000.

Pada 2018, Profesor Ma Yi menyertai Jabatan Kejuruteraan Elektrik dan Sains Komputer di Universiti California, Berkeley pada Januari tahun ini, beliau menyertai Universiti Hong Kong sebagai Pengarah Institut Sains Data, dan baru-baru ini mengambil alih sebagai Ketua Jabatan Pengkomputeran di Universiti Hong Kong.
Arah penyelidikan utama ialah penglihatan komputer 3D, model berdimensi rendah data berdimensi tinggi, pengoptimuman skalabiliti dan pembelajaran mesin Topik penyelidikan terkini termasuk pembinaan semula dan interaksi geometri 3D berskala besar Hubungan antara model dimensi rendah dan rangkaian dalam.
Tujuan utama kertas kerja ini adalah untuk menggunakan rangka kerja yang lebih bersatu untuk mereka bentuk struktur rangkaian yang serupa dengan Transformer, supaya dapat mencapai kepastian matematik Prestasi praktikal yang boleh ditafsir dan baik.
Untuk tujuan ini, para penyelidik mencadangkan untuk mempelajari jujukan pemetaan tambahan untuk mendapatkan perwakilan data input (set token) yang paling sedikit dimampatkan dan paling jarang, mengoptimumkan satu kesatuan Fungsi objektif ialah untuk mengurangkan kadar sparsity.

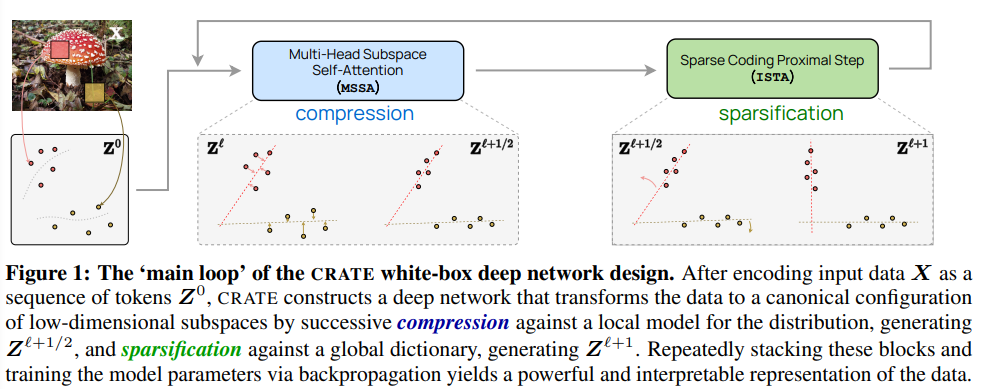
Rangka kerja ini menyatukan "Model Transformer dan perhatian kendiri", "model resapan dan pengurangan hingar", "pencarian berstruktur dan pengurangan kadar" (Model mencari struktur dan pengurangan kadar ), dan menunjukkan bahawa lapisan rangkaian dalam seperti Transformer boleh diperoleh secara semula jadi daripada melancarkan skim pengoptimuman berulang untuk mengoptimumkan matlamat pengurangan kadar sparsity secara berperingkat.
Sasaran dipetakan
Perhatian Diri melalui Denoising Token ke Arah Berbilang Subruang
Para penyelidik menggunakan model pengedaran token yang ideal untuk menunjukkan bahawa jika ia bergerak ke arah Noise siri subruang dimensi rendah, fungsi pemarkahan yang berkaitan akan mengambil bentuk eksplisit yang serupa dengan pengendali perhatian diri dalam Transformer.
Perhatian Diri melalui Memampatkan Set Token melalui Pengoptimuman Pengurangan Kadar
Penyelidik memperoleh perhatian kendiri berbilang kepala lapisan ialah langkah penurunan kecerunan terungkap untuk meminimumkan bahagian kadar pengekodan lossy daripada pengurangan kadar, sekali gus menunjukkan cara alternatif untuk mentafsir lapisan perhatian diri sebagai perwakilan token termampat.
MLP melalui Iterative Shrinkage-Thresholding Algorithm (ISTA) untuk Pengekodan Jarang
Para penyelidik menunjukkan blok Transformer The perceptron berbilang lapisan serta-merta selepas lapisan perhatian kendiri berbilang kepala boleh ditafsirkan sebagai (dan boleh digantikan dengan) lapisan yang secara beransur-ansur mengoptimumkan baki sasaran pengurangan kadar sparsity dengan membina pengekodan jarang perwakilan token.
Berdasarkan pemahaman di atas, penyelidik mencipta seni bina Transformer kotak putih baharu CRATE (Pengekodan KADAR pengurangan TransformEr) untuk mempelajari fungsi objektif dan pembelajaran mendalam seni bina dan perwakilan terakhir yang dipelajari boleh ditafsirkan secara matematik sepenuhnya, di mana setiap lapisan melakukan satu langkah algoritma pengecilan berselang-seli untuk mengoptimumkan matlamat pengurangan sparsity.

Dapat diperhatikan bahawa CRATE memilih cara yang paling mudah untuk membina pada setiap peringkat binaan, selagi bahagian yang baru dibina kekal sebagai sama Peranan konseptual boleh diganti terus dan seni bina kotak putih baru diperolehi.
Matlamat percubaan penyelidik bukan sahaja untuk bersaing dengan Transformer lain yang direka dengan baik menggunakan reka bentuk asas, tetapi juga termasuk:
1 Tidak seperti rangkaian kotak hitam yang direka secara empirik yang biasanya hanya dinilai pada prestasi hujung ke hujung, rangkaian reka bentuk kotak putih boleh melihat ke dalam seni bina yang mendalam dan mengesahkan lapisan yang dipelajari. rangkaian. Sama ada ia benar-benar melaksanakan matlamat reka bentuknya , iaitu, pengoptimuman tambahan bagi matlamat.
2 Walaupun seni bina CRATE adalah mudah, hasil percubaan harus mengesahkan potensi besar seni bina ini, iaitu, ia boleh digunakan pada skala besar. set data dan tugasan dunia sebenar Mencapai prestasi yang sepadan dengan model Transformer yang sangat kejuruteraan.
Seni bina model
Dengan menukar dimensi token, bilangan pengepala dan bilangan lapisan, penyelidikan Kami mencipta empat model CRATE dengan saiz yang berbeza, dilambangkan sebagai CRATE-Tiny, CRATE-Small, CRATE-Base dan CRATE-Large
set data dan pengoptimuman
Artikel ini terutamanya menganggap ImageNet-1K sebagai platform ujian dan menggunakan pengoptimum Lion untuk melatih model CRATE dengan saiz model yang berbeza.
Prestasi pembelajaran pemindahan CRATE juga dinilai: model yang dilatih pada ImageNet-1K telah digunakan sebagai model pra-latihan, dan kemudian ia dilatih pada beberapa set data hiliran yang biasa digunakan (CIFAR10/100, Oxford Flowers, Oxford-IIT-Pets) untuk memperhalusi CRATE.
Adakah lapisan CRATE mencapai matlamat reka bentuknya?

Apabila indeks lapisan meningkat, anda boleh melihat bahawa model CRATE-Small mempunyai kedua-dua istilah mampatan dan sparsifikasi dalam kebanyakan kes , peningkatan dalam ukuran sparsity lapisan terakhir adalah disebabkan oleh lapisan linear tambahan yang digunakan untuk pengelasan.
Keputusan menunjukkan bahawa CRATE sesuai dengan matlamat reka bentuk asal: setelah dipelajari, ia pada dasarnya belajar untuk memampatkan dan mengurangkan perwakilan secara beransur-ansur melalui lapisannya.

Selepas mengukur terma mampatan dan sparsifikasi pada model CRATE skala lain dan pusat pemeriksaan model perantaraan, didapati bahawa keputusan eksperimen masih sangat konsisten , dengan Model dengan lebih banyak lapisan cenderung untuk mengoptimumkan matlamat dengan lebih berkesan, mengesahkan pemahaman sebelumnya tentang peranan setiap lapisan.
Perbandingan prestasi
Dengan mengukur ketepatan tertinggi pada ImageNet-1K dan The prestasi empirikal rangkaian yang dicadangkan dikaji melalui prestasi pembelajaran pemindahan pada beberapa set data hiliran yang digunakan secara meluas.
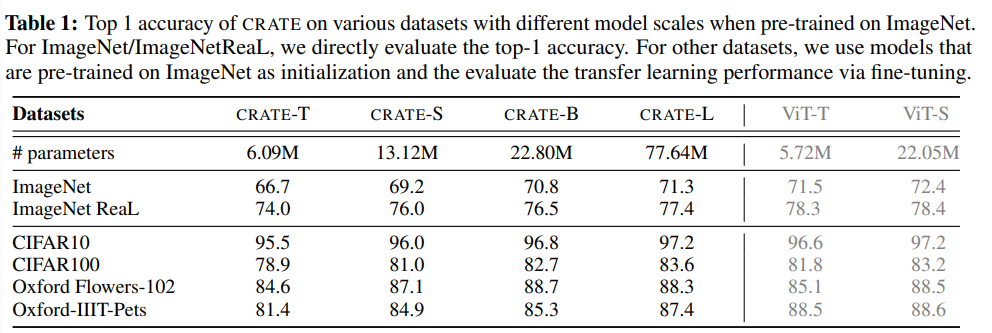
Memandangkan seni bina yang direka bentuk menggunakan perkongsian parameter dalam kedua-dua blok perhatian (MSSA) dan blok MLP (ISTA), model CRATE-Base ( 22.08 juta) mempunyai bilangan parameter yang serupa dengan ViT-Small (22.05 juta).
Ia boleh dilihat bahawa apabila bilangan parameter model adalah serupa, rangkaian yang dicadangkan dalam artikel mencapai ImageNet-1K dan memindahkan prestasi pembelajaran serupa dengan ViT, tetapi reka bentuk CRATE adalah lebih mudah, Kebolehtafsiran yang kuat.
Di samping itu, di bawah hiperparameter latihan yang sama, CRATE boleh terus berkembang, iaitu, terus meningkatkan prestasi dengan mengembangkan saiz model, sambil mengembangkan secara langsung saiz ViT pada ImageNet -1K dan Tidak selalu membawa kepada peningkatan prestasi yang konsisten.
Maksudnya, rangkaian CRATE, walaupun sederhana, sudah boleh mempelajari pemampatan yang diperlukan dan perwakilan jarang pada set data dunia nyata berskala besar dan berfungsi dengan baik pada pelbagai tugas seperti klasifikasi dan pemindahan pembelajaran) untuk mencapai prestasi yang setanding dengan rangkaian Transformer yang lebih kejuruteraan (seperti ViT).
Atas ialah kandungan terperinci LeCun menyokong karya lima tahun Profesor Ma Yi: Transformer kotak putih yang boleh ditafsir secara matematik yang prestasinya tidak kalah dengan ViT.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 0x80070057 penyelesaian ralat parameter
0x80070057 penyelesaian ralat parameter
 Apakah pelayan nama domain akar
Apakah pelayan nama domain akar
 Kaedah Window.setInterval().
Kaedah Window.setInterval().
 apa itu url
apa itu url
 Pengaturcaraan bahasa peringkat tinggi
Pengaturcaraan bahasa peringkat tinggi
 Bagaimana untuk menyelesaikan tiada laluan ke hos
Bagaimana untuk menyelesaikan tiada laluan ke hos
 Apakah yang perlu saya lakukan jika chaturbate tersekat?
Apakah yang perlu saya lakukan jika chaturbate tersekat?
 Bagaimana untuk memulihkan pangkalan data mysql
Bagaimana untuk memulihkan pangkalan data mysql








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



