

Hanya satu hari sejak AI baharu DeepMind dilancarkan di Alam Semulajadi, dan GPT-4 sudah pun berada di sini untuk bersaing!
Dengan hanya dua perenggan gesaan, GPT-4 menyediakan kaedah pengoptimuman algoritma pengisihan yang sama seperti AlphaDev.
DeepMind memanggil AlphaDev "mencipta semula keajaiban AlphaGo" kerana ia menemui kaedah yang boleh mempercepatkan algoritma pengisihan sehingga 70%.
Oh, AlphaDev semakin malu sekarang.
Biar GPT-4 "menemui" lelaki tua yang melakukan operasi yang sama dan secara langsung yin dan yang:
Tidak perlu pembelajaran pengukuhan langsung. Bolehkah saya menerbitkan penemuan ini dalam Alam Semula Jadi?
Kasturi "melihatnya semasa lalu" dan juga meninggalkan mesej "kerana meniup dan mendengar".

Jadi bagaimanakah GPT-4 melakukannya?
Orang yang membawa penemuan baharu ini ialah seorang profesor bersekutu dari Universiti Wisconsin-Madison bernama Dimitris Papailiopoulos (selepas ini dirujuk sebagai Profesor D) .
Langkah yang dia gunakan untuk mendapatkan GPT-4 untuk melakukan ini adalah sangat mudah, dan dia hanya memasukkan dua gesaan secara keseluruhan.
Pertama sekali, dia memberitahu GPT-4:
Ini ialah algoritma pengisihan, dan saya fikir ia boleh dioptimumkan lagi. Ayat manakah yang perlu ditulis semula? . Terangkan mengapa langkah demi langkah, kemudian kembali dan sahkan bahawa ia betul.

Pada langkah pertama, beliau turut menekankan sekiranya ada penemuan baharu, jangan buat perubahan lagi, hanya "menonton" sahaja. Hanya tulis beberapa cadangan bertulis untuk penambahbaikan.
Berhati-hati dan sangat terperinci.
Kemudian GPT-4 memberikan penjelasan terperinci tentang kod yang diberikan.

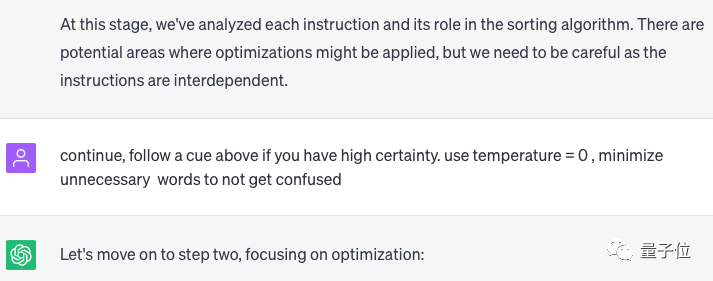
Kemudian Profesor D memberikan tip kedua:
Teruskan. Jika anda sangat yakin, ikuti petua di atas. Tetapkan suhu kepada 0 untuk memastikan hasil yang dijana adalah deterministik dan konsisten serta cuba mengelakkan kekeliruan.
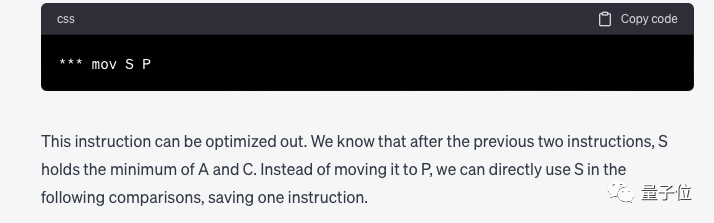
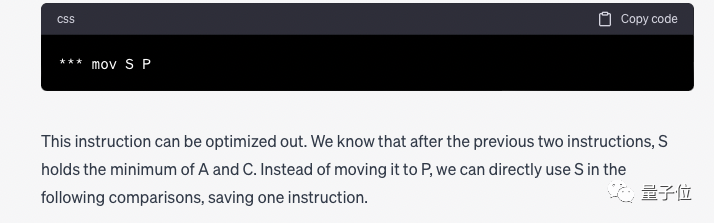
Kemudian GPT-4 memberikan langkah terperinci, dan akhirnya membuat kesimpulan:
Kami mendapati Arahan " mov S P" boleh dialih keluar jika ia berlebihan, dan arahan lain diperlukan. Tetapi selepas pemadaman, P hendaklah digantikan dengan S.
Membandingkan idea kerja baharu DeepMind AlphaDev dalam menangani masalah yang sama, kita tidak boleh mengatakan bahawa tiada hubungan, kita boleh hanya katakan bahawa mereka betul-betul sama:
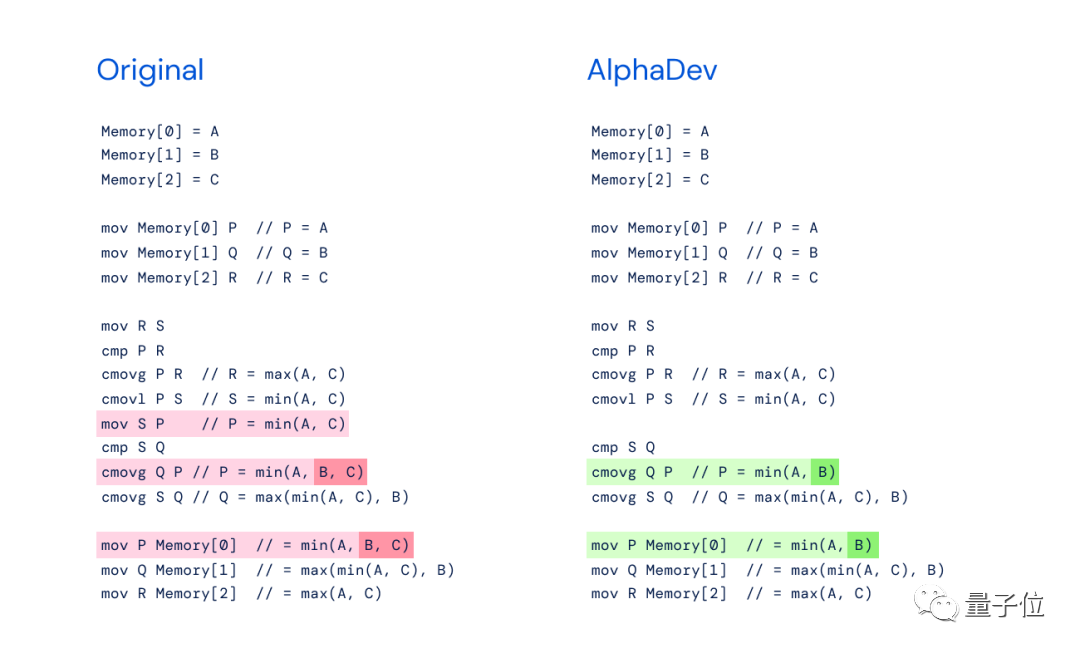
Operasi DeepMind pada AlphaDev mengingatkan kepada "Langkah 37" AlphaGo - satu langkah berlawanan dengan intuitif yang secara langsung mengalahkannya Pemain legenda Go Lee Sedol mengejutkan penonton.
Begitu juga, AlphaDev melangkau langkah dengan menukar dan menyalin pergerakan, mencapai matlamat dengan cara yang kelihatan salah tetapi sebenarnya adalah jalan pintas.
Menurut laporan, AlphaDev ialah algoritma pembelajaran pengukuhan berdasarkan AlphaZero Penemuannya tidak berdasarkan algoritma sedia ada, tetapi bermula dari arahan pemasangan peringkat terendah.
Inovasinya terutamanya terletak pada dua urutan arahan:
(1) AlphaDev Swap Move (exchange move)
(2) AlphaDev Copy Move (copy move)
Pada dasarnya, penyelidik DeepMind mereka bentuk permainan "pemasangan" pemain tunggal untuknya:
Selagi anda boleh mencari dan memilih arahan yang sesuai (proses A dalam rajah di bawah), ia adalah betul dan Susun data dengan cepat (proses B dalam rajah di bawah) dan anda akan diberi ganjaran.
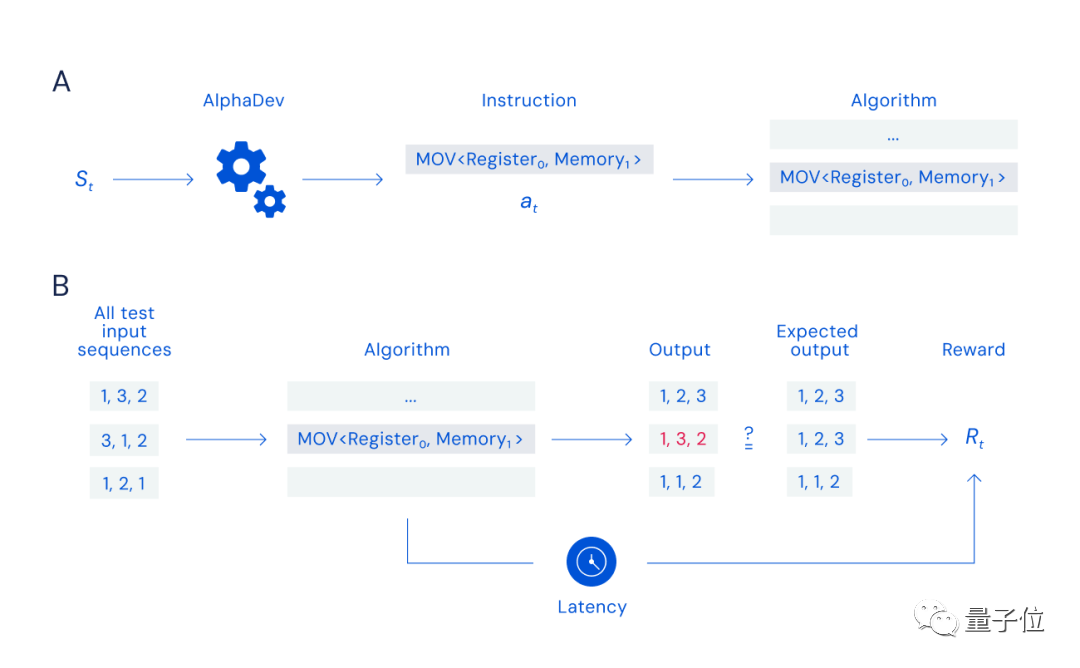
Tetapi cabaran permainan ini bukan sahaja saiz ruang carian (bilangan arahan boleh digabungkan adalah bersamaan dengan nombor zarah di alam semesta), tetapi juga Ia terletak pada sifat fungsi ganjaran, kerana satu arahan yang salah boleh menyebabkan keseluruhan algoritma gagal.
Berkenaan "operasi seksi" GPT-4, sesetengah orang berkata: Malah pemaju kanan memandang rendah GPT-4.

Sesetengah orang berkata dengan penuh emosi bahawa operasi Profesor D mengesahkan lagi bahawa selagi anda mempunyai kesabaran dan memahami kejuruteraan segera, masih terdapat banyak perkara bahawa GPT-4 boleh melakukan banyak perkara.

Sesetengah orang juga telah mempersoalkan sama ada GPT-4 boleh melakukan ini kerana data latihannya mengandungi beberapa pengoptimuman kaedah pengisihan?

Tetapi setelah berkata demikian, sebahagian besar daripada sebab mengapa perkara ini telah menarik perhatian dan perbincangan adalah kerana kontroversi mengenai kemasukan AlphaDev dalam Alam.
Ramai orang merasakan bahawa ini bukan penyelidikan yang inovatif dan DeepMind adalah keterlaluan.

Bukan sahaja Profesor D Yin Yang berkata "Bolehkah saya juga log masuk ke Alam", tetapi juga netizen berkata bahawa mereka mengoptimumkan baris gilir pantas apabila mereka remaja, ini juga harus diterbitkan.
Sudah tentu, sesetengah orang percaya bahawa inovasi AlphaDev itu sendiri ialah ia menggunakan pembelajaran pengukuhan untuk menemui algoritma baharu.

Apa pendapat anda?
Pautan rujukan: [1]https://chat.openai.com/share/95693df4-36cd-4241-9cae-2173e8fb760c[2]https://twitter.com/DimitrisPapail/status/166684
Atas ialah kandungan terperinci GPT-4 memalukan DeepMind: Anda menggunakan algoritma pengoptimuman pengisihan Alam dan saya mendapatinya dalam dua perenggan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk menyelesaikan masalah yang css tidak boleh dimuatkan
Bagaimana untuk menyelesaikan masalah yang css tidak boleh dimuatkan
 Harga Dogecoin hari ini
Harga Dogecoin hari ini
 Apakah yang termasuk storan penyulitan data?
Apakah yang termasuk storan penyulitan data?
 403penyelesaian terlarang
403penyelesaian terlarang
 Bagaimana untuk memperlahankan video di Douyin
Bagaimana untuk memperlahankan video di Douyin
 Cara menggunakan makro excel
Cara menggunakan makro excel
 Peranan antara muka vga
Peranan antara muka vga
 Bagaimana untuk membuat indeks bitmap dalam mysql
Bagaimana untuk membuat indeks bitmap dalam mysql
 Berapakah nilai Dimensity 6020 bersamaan dengan Snapdragon?
Berapakah nilai Dimensity 6020 bersamaan dengan Snapdragon?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



