
 Peranti teknologi
AI
Model panggilan API terkuat ada di sini! Berdasarkan penalaan halus LLaMA, prestasi melebihi GPT-4
Peranti teknologi
AI
Model panggilan API terkuat ada di sini! Berdasarkan penalaan halus LLaMA, prestasi melebihi GPT-4
Model panggilan API terkuat ada di sini! Berdasarkan penalaan halus LLaMA, prestasi melebihi GPT-4

Selepas alpaca, ada model lain yang dinamakan sempena haiwan, kali ini ialah gorila.
Walaupun LLM kini berkembang pesat, membuat banyak kemajuan, dan prestasinya dalam pelbagai tugas juga luar biasa, potensi model ini untuk menggunakan alat secara berkesan melalui panggilan API masih perlu meneroka Menggali.
Malah untuk LLM tercanggih hari ini, seperti GPT-4, panggilan API adalah tugas yang mencabar, terutamanya disebabkan oleh ketidakupayaan mereka untuk menjana parameter input yang tepat dan LLM memudahkan Halusinasi yang disebabkan oleh penggunaan yang salah daripada panggilan API.
Tidak, penyelidik telah membangunkan Gorilla, model berasaskan LLaMA yang diperhalusi yang malah mengatasi GPT-4 dalam penulisan panggilan API.
Apabila digabungkan dengan pengambilan dokumen, Gorilla juga menunjukkan prestasi yang berkuasa, menjadikan kemas kini pengguna atau perubahan versi lebih fleksibel.
Selain itu, Gorilla juga banyak mengurangkan masalah halusinasi yang sering dihadapi oleh LLM.
Untuk menilai keupayaan model, penyelidik turut memperkenalkan penanda aras API, set data komprehensif yang terdiri daripada API HuggingFace, TorchHub dan TensorHub
Gorilla
Tidak perlu memperkenalkan kebolehan hebat LLM, termasuk keupayaan perbualan semula jadi, keupayaan penaakulan matematik dan keupayaan sintesis program.
Walau bagaimanapun, walaupun prestasinya yang hebat, LLM masih mengalami beberapa batasan. Selain itu, LLM juga perlu dilatih semula untuk mengemas kini asas pengetahuan dan keupayaan penaakulan mereka tepat pada masanya.
Dengan membenarkan alatan yang tersedia untuk LLM, penyelidik boleh membenarkan LLM mengakses pangkalan pengetahuan yang luas dan sentiasa berubah untuk menyelesaikan tugas pengkomputeran yang kompleks.
Dengan menyediakan akses kepada teknologi carian dan pangkalan data, penyelidik boleh meningkatkan keupayaan LLM untuk mengendalikan ruang pengetahuan yang lebih besar dan lebih dinamik.
Begitu juga, dengan menyediakan penggunaan alat pengiraan, LLM juga boleh menyelesaikan tugas pengiraan yang kompleks.
Oleh itu, gergasi teknologi telah mula cuba menyepadukan pelbagai pemalam untuk membolehkan LLM memanggil alat luaran melalui API.
Peralihan daripada alat berkod tangan yang lebih kecil kepada alat yang mampu memanggil ruang API awan yang besar dan sentiasa berubah boleh mengubah LLM menjadi infrastruktur pengkomputeran, dan Antara muka utama yang diperlukan oleh rangkaian.
Tugas daripada menempah keseluruhan percutian hingga menganjurkan persidangan boleh menjadi semudah bercakap dengan LLM dengan akses kepada API web untuk penerbangan, penyewaan kereta, hotel, tempat makan dan hiburan.
Walau bagaimanapun, banyak kerja sebelumnya yang menyepadukan alatan ke dalam LLM mempertimbangkan satu set kecil API yang didokumentasikan dengan baik yang boleh disuntik dengan mudah ke dalam gesaan.
Menyokong koleksi skala web yang berpotensi berjuta-juta API berubah memerlukan pemikiran semula tentang cara penyelidik menyepadukan alatan.
Tidak mungkin lagi untuk menerangkan semua API dalam satu persekitaran. Banyak API akan mempunyai kefungsian bertindih, dengan pengehadan dan kekangan yang halus. Hanya menilai LLM dalam persekitaran baharu ini memerlukan penanda aras baharu.
Dalam kertas kerja ini, penyelidik meneroka kaedah untuk menggunakan penalaan halus dan perolehan terstruktur sendiri untuk membolehkan LLM memperoleh data dengan tepat daripada data yang besar, bertindih dan berbeza-beza yang dinyatakan menggunakan API dan APInya dokumentasi. Buat pilihan dalam set alat.
Penyelidik membina Bangku API dengan mengikis ML API (model) daripada pusat model awam, korpus besar API dengan fungsi yang kompleks dan sering bertindih.
Para penyelidik memilih tiga pusat model utama untuk membina set data: TorchHub, TensorHub dan HuggingFace.
Para penyelidik menyertakan secara menyeluruh setiap panggilan API dalam TorchHub (94 panggilan API) dan TensorHub (696 panggilan API).
Untuk HuggingFace, disebabkan bilangan model yang banyak, penyelidik memilih 20 model yang paling banyak dimuat turun dalam setiap kategori tugasan (jumlah 925).
Para penyelidik juga menggunakan Arahan Kendiri untuk menjana gesaan bagi 10 soalan pengguna bagi setiap API.
Oleh itu, setiap entri dalam set data menjadi pasangan API rujukan arahan. Para penyelidik menggunakan teknik pemadanan subpokok AST biasa untuk menilai ketepatan fungsi API yang dijana.
Penyelidik terlebih dahulu menghuraikan kod yang dijana ke dalam pepohon AST, kemudian mencari subpokok yang nod akarnya ialah panggilan API yang penting bagi penyelidik, dan kemudian menggunakan ini untuk mengindeks set data penyelidik .
Penyelidik menyemak ketepatan fungsi dan isu halusinasi LLM dan memberikan maklum balas tentang ketepatan yang sepadan. Para penyelidik kemudian memperhalusi Gorilla, model berdasarkan LLaMA-7B, untuk melaksanakan pengambilan dokumen menggunakan set data penyelidik.
Penyelidik mendapati bahawa Gorilla mengatasi GPT-4 dengan ketara dari segi ketepatan ciri API dan mengurangkan ralat ilusi.
Para penyelidik menunjukkan contoh dalam Rajah 1.

Di samping itu, latihan kesedaran perolehan semula Gorilla oleh penyelidik membolehkan model menyesuaikan diri dengan perubahan dalam dokumentasi API.
Akhir sekali, penyelidik juga menunjukkan keupayaan Gorilla untuk memahami dan menaakul tentang kekangan.
Selain itu, Gorilla juga beraksi dengan baik dari segi ilusi.
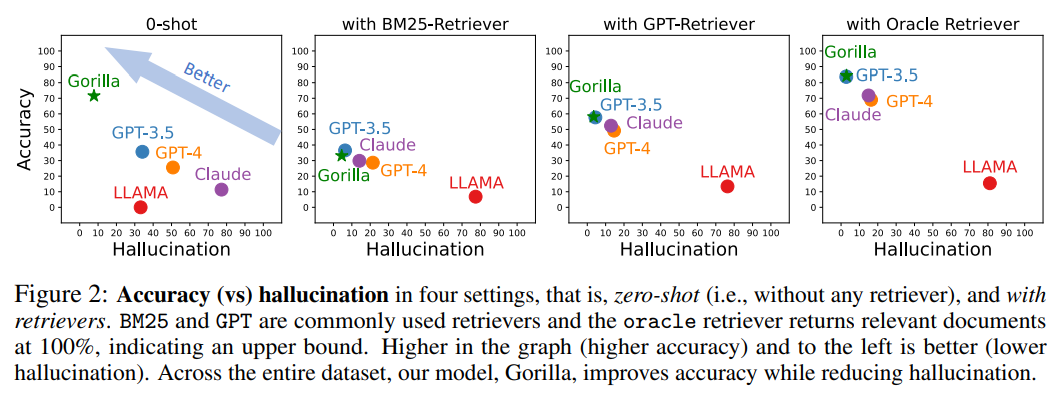
Angka berikut ialah perbandingan ketepatan dan halusinasi dalam empat kes, sampel sifar (iaitu, tanpa sebarang retriever) dan menggunakan retriever BM25, GPT dan Oracle.
Antaranya, BM25 dan GPT ialah enjin carian yang biasa digunakan, manakala enjin carian Oracle akan mengembalikan dokumen yang berkaitan dengan 100% perkaitan, menunjukkan had atas.
Yang dengan ketepatan yang lebih tinggi dan kurang ilusi dalam gambar mempunyai kesan yang lebih baik.
Di seluruh set data, Gorilla meningkatkan ketepatan sambil mengurangkan halusinasi.
Untuk mengumpul set data, penyelidik merekodkan model The Model Hub, PyTorch Hub dan TensorFlow Hub HuggingFace dengan teliti Semua model dalam talian.
Platform HuggingFace mengehoskan dan menyediakan sejumlah 203,681 model.
Walau bagaimanapun, dokumentasi untuk kebanyakan model ini adalah lemah.
Untuk menapis model berkualiti rendah ini, penyelidik akhirnya memilih 20 model teratas daripada setiap domain.
Para penyelidik mempertimbangkan 7 domain untuk data multimodal, 8 domain untuk CV, 12 domain untuk NLP, 5 domain untuk audio, 2 domain untuk data jadual dan 2 bidang pembelajaran pengukuhan.
Selepas menapis, penyelidik mendapat sejumlah 925 model daripada HuggingFace. Versi TensorFlow Hub dibahagikan kepada v1 dan v2.
Versi terkini (v2) mempunyai sejumlah 801 model dan para penyelidik memproses semua model. Selepas menapis model dengan sedikit maklumat, 626 model kekal.
Sama seperti TensorFlow Hub, penyelidik mendapat 95 model daripada Torch Hub.
Di bawah bimbingan paradigma arahan kendiri, para penyelidik menggunakan GPT-4 untuk menjana data arahan sintetik.
Para penyelidik menyediakan tiga contoh dalam konteks, serta dokumen API rujukan, dan menugaskan model menjana kes penggunaan sebenar untuk memanggil API.
Para penyelidik secara khusus mengarahkan model untuk tidak menggunakan sebarang nama atau petunjuk API semasa membuat arahan. Para penyelidik membina enam contoh (pasangan arahan-API) untuk setiap tiga hab model.
18 mata ini adalah satu-satunya data yang dijana atau diubah suai secara manual.
Dan Gorilla mendapatkan semula model LLaMA-7B yang dilihat, khusus untuk panggilan API.
Seperti yang ditunjukkan dalam Rajah 3, penyelidik menggunakan pembinaan diri untuk menjana pasangan {instruction, API}.
Untuk memperhalusi LLaMA, penyelidik menukarnya menjadi perbualan gaya sembang ejen pengguna, di mana setiap titik data ialah perbualan dan pengguna dan ejen bergilir-gilir bercakap.
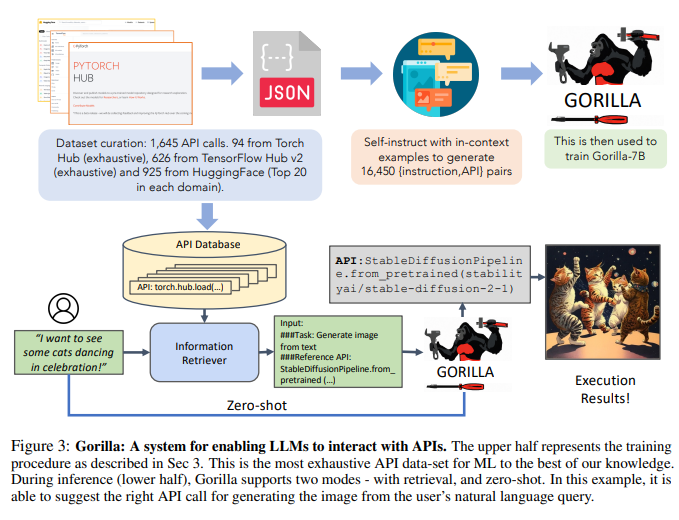
Para penyelidik kemudian melakukan penalaan halus arahan standard pada model asas LLaMA-7B. Dalam eksperimen, para penyelidik melatih Gorilla dengan dan tanpa retriever.
Dalam kajian itu, penyelidik menumpukan pada teknik yang bertujuan untuk meningkatkan keupayaan LLM untuk mengenal pasti API yang sesuai dengan tepat untuk tugasan tertentu - sesuatu yang kritikal dalam pembangunan teknologi ini sering terlepas pandang.
Memandangkan API berfungsi sebagai bahasa universal yang membolehkan komunikasi berkesan antara sistem yang berbeza, penggunaan API yang betul boleh meningkatkan keupayaan LLM untuk berinteraksi dengan rangkaian alat yang lebih luas.
Gorila mengatasi prestasi LLM (GPT-4) tercanggih pada tiga set data berskala besar yang dikumpulkan oleh penyelidik. Gorilla menghasilkan model ML yang boleh dipercayai bagi panggilan API tanpa halusinasi dan memenuhi kekangan semasa memilih API.
Dengan harapan untuk mencari set data yang mencabar, penyelidik memilih API ML kerana fungsinya yang serupa. Kelemahan berpotensi API tertumpu ML ialah jika dilatih pada data berat sebelah, ia berpotensi untuk menghasilkan ramalan berat sebelah yang mungkin merugikan subkumpulan tertentu.
Untuk meredakan kebimbangan ini dan menggalakkan pemahaman yang lebih mendalam tentang API ini, penyelidik mengeluarkan set data yang lebih luas yang merangkumi lebih daripada 11,000 pasangan arahan-API.
Dalam contoh di bawah, penyelidik menggunakan pemadanan subpokok sintaks abstrak (AST) untuk menilai ketepatan panggilan API.
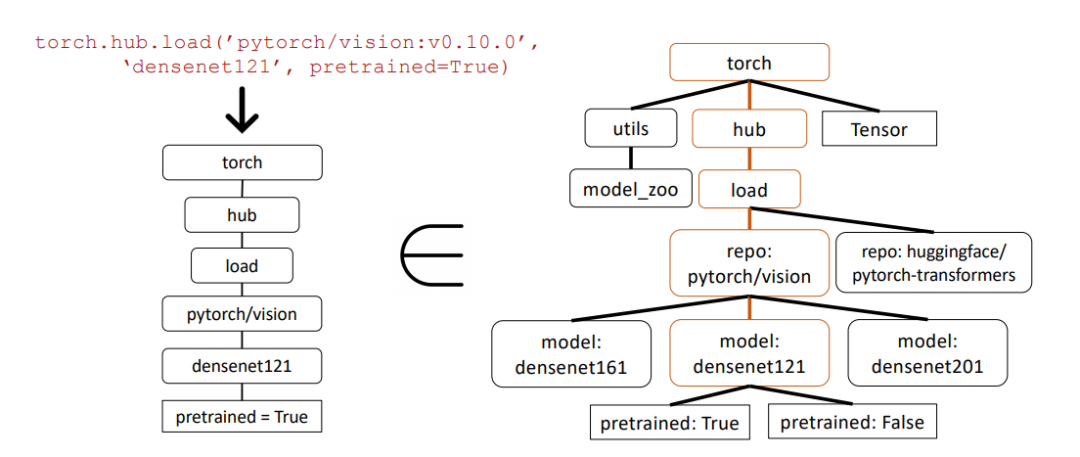
Pokok sintaks abstrak ialah perwakilan pokok struktur kod sumber, yang membantu menganalisis dan memahami kod dengan lebih baik.
Pertama, penyelidik membina pepohon API yang berkaitan daripada panggilan API yang dikembalikan oleh Gorilla (kiri). Ini kemudiannya dibandingkan dengan set data untuk melihat sama ada set data API mempunyai padanan subpokok.
Dalam contoh di atas, subpokok yang sepadan diserlahkan dalam warna coklat, menunjukkan bahawa panggilan API sememangnya betul. Di mana Pretrained=True ialah parameter pilihan.
Sumber ini akan memberi perkhidmatan kepada komuniti yang lebih luas sebagai alat yang berharga untuk mengkaji dan mengukur API sedia ada, menyumbang kepada penggunaan pembelajaran mesin yang lebih saksama dan optimum.
Atas ialah kandungan terperinci Model panggilan API terkuat ada di sini! Berdasarkan penalaan halus LLaMA, prestasi melebihi GPT-4. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Baris arahan shutdown centos
Apr 14, 2025 pm 09:12 PM
Perintah shutdown CentOS adalah penutupan, dan sintaks adalah tutup [pilihan] [maklumat]. Pilihan termasuk: -h menghentikan sistem dengan segera; -P mematikan kuasa selepas penutupan; -r mulakan semula; -T Waktu Menunggu. Masa boleh ditentukan sebagai segera (sekarang), minit (minit), atau masa tertentu (HH: mm). Maklumat tambahan boleh dipaparkan dalam mesej sistem.
 Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Apakah kaedah sandaran untuk gitlab di centos
Apr 14, 2025 pm 05:33 PM
Dasar sandaran dan pemulihan Gitlab di bawah sistem CentOS untuk memastikan keselamatan data dan pemulihan, Gitlab pada CentOS menyediakan pelbagai kaedah sandaran. Artikel ini akan memperkenalkan beberapa kaedah sandaran biasa, parameter konfigurasi dan proses pemulihan secara terperinci untuk membantu anda menubuhkan strategi sandaran dan pemulihan GitLab lengkap. 1. Backup Manual Gunakan Gitlab-Rakegitlab: Backup: Buat Perintah untuk Melaksanakan Backup Manual. Perintah ini menyokong maklumat utama seperti repositori Gitlab, pangkalan data, pengguna, kumpulan pengguna, kunci, dan kebenaran. Fail sandaran lalai disimpan dalam direktori/var/opt/gitlab/sandaran. Anda boleh mengubah suai /etc /gitlab
 Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Cara Memeriksa Konfigurasi HDFS CentOS
Apr 14, 2025 pm 07:21 PM
Panduan Lengkap untuk Memeriksa Konfigurasi HDFS Dalam Sistem CentOS Artikel ini akan membimbing anda bagaimana untuk memeriksa konfigurasi dan menjalankan status HDFS secara berkesan pada sistem CentOS. Langkah -langkah berikut akan membantu anda memahami sepenuhnya persediaan dan operasi HDFS. Sahkan Pembolehubah Alam Sekitar Hadoop: Pertama, pastikan pembolehubah persekitaran Hadoop ditetapkan dengan betul. Di terminal, laksanakan arahan berikut untuk mengesahkan bahawa Hadoop dipasang dan dikonfigurasi dengan betul: Hadoopversion Semak fail konfigurasi HDFS: Fail konfigurasi teras HDFS terletak di/etc/hadoop/conf/direktori, di mana core-site.xml dan hdfs-site.xml adalah kritikal. gunakan
 Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Bagaimana sokongan GPU untuk Pytorch di CentOS
Apr 14, 2025 pm 06:48 PM
Membolehkan pecutan GPU pytorch pada sistem CentOS memerlukan pemasangan cuda, cudnn dan GPU versi pytorch. Langkah-langkah berikut akan membimbing anda melalui proses: Pemasangan CUDA dan CUDNN Tentukan keserasian versi CUDA: Gunakan perintah NVIDIA-SMI untuk melihat versi CUDA yang disokong oleh kad grafik NVIDIA anda. Sebagai contoh, kad grafik MX450 anda boleh menyokong CUDA11.1 atau lebih tinggi. Muat turun dan pasang Cudatoolkit: Lawati laman web rasmi Nvidiacudatoolkit dan muat turun dan pasang versi yang sepadan mengikut versi CUDA tertinggi yang disokong oleh kad grafik anda. Pasang Perpustakaan Cudnn:
 CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
CentOS memasang MySQL
Apr 14, 2025 pm 08:09 PM
Memasang MySQL pada CentOS melibatkan langkah -langkah berikut: Menambah sumber MySQL YUM yang sesuai. Jalankan YUM Pasang Perintah MySQL-Server untuk memasang pelayan MySQL. Gunakan perintah mysql_secure_installation untuk membuat tetapan keselamatan, seperti menetapkan kata laluan pengguna root. Sesuaikan fail konfigurasi MySQL seperti yang diperlukan. Tune parameter MySQL dan mengoptimumkan pangkalan data untuk prestasi.
 Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Penjelasan terperinci mengenai Prinsip Docker
Apr 14, 2025 pm 11:57 PM
Docker menggunakan ciri -ciri kernel Linux untuk menyediakan persekitaran berjalan yang cekap dan terpencil. Prinsip kerjanya adalah seperti berikut: 1. Cermin digunakan sebagai templat baca sahaja, yang mengandungi semua yang anda perlukan untuk menjalankan aplikasi; 2. Sistem Fail Kesatuan (Unionfs) menyusun pelbagai sistem fail, hanya menyimpan perbezaan, menjimatkan ruang dan mempercepatkan; 3. Daemon menguruskan cermin dan bekas, dan pelanggan menggunakannya untuk interaksi; 4. Ruang nama dan cgroups melaksanakan pengasingan kontena dan batasan sumber; 5. Pelbagai mod rangkaian menyokong interkoneksi kontena. Hanya dengan memahami konsep -konsep teras ini, anda boleh menggunakan Docker dengan lebih baik.
 CentOS8 memulakan semula SSH
Apr 14, 2025 pm 09:00 PM
CentOS8 memulakan semula SSH
Apr 14, 2025 pm 09:00 PM
Perintah untuk memulakan semula perkhidmatan SSH ialah: Sistem Restart SSHD. Langkah -langkah terperinci: 1. Akses terminal dan sambungkan ke pelayan; 2. Masukkan arahan: SistemCtl Restart SSHD; 3. Sahkan Status Perkhidmatan: Status Sistem SSHD.
 Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Cara Mengendalikan Latihan Pittorch Diagihkan di Centos
Apr 14, 2025 pm 06:36 PM
Latihan yang diedarkan Pytorch pada sistem CentOS memerlukan langkah -langkah berikut: Pemasangan Pytorch: Premisnya ialah Python dan PIP dipasang dalam sistem CentOS. Bergantung pada versi CUDA anda, dapatkan arahan pemasangan yang sesuai dari laman web rasmi Pytorch. Untuk latihan CPU sahaja, anda boleh menggunakan arahan berikut: PipinstallToRchTorchVisionTorchaudio Jika anda memerlukan sokongan GPU, pastikan versi CUDA dan CUDNN yang sama dipasang dan gunakan versi pytorch yang sepadan untuk pemasangan. Konfigurasi Alam Sekitar Teragih: Latihan yang diedarkan biasanya memerlukan pelbagai mesin atau mesin berbilang mesin tunggal. Tempat
