
window.setTimeout(detect, 66) // 33 => 66
 Peranti teknologi
AI
Perlindungan masa nyata terhadap rentetan penyekat muka di web (berdasarkan pembelajaran mesin)
Peranti teknologi
AI
Perlindungan masa nyata terhadap rentetan penyekat muka di web (berdasarkan pembelajaran mesin)
Perlindungan masa nyata terhadap rentetan penyekat muka di web (berdasarkan pembelajaran mesin)

Serangan anti-muka, iaitu, sebilangan besar sekatan terapung, tetapi tidak menyekat orang dalam skrin video Ia kelihatan seperti terapung dari belakang orang itu.
Pembelajaran mesin telah popular selama beberapa tahun, tetapi ramai orang tidak tahu bahawa keupayaan ini juga boleh dijalankan dalam penyemak imbas
Artikel ini memperkenalkan proses pengoptimuman praktikal dalam rentetan video, disenaraikan; pada akhir artikel Beberapa senario di mana penyelesaian ini terpakai diterangkan, dengan harapan dapat membuka beberapa idea.
Demo mediapipe (https://google.github.io/mediapipe/) menunjukkan
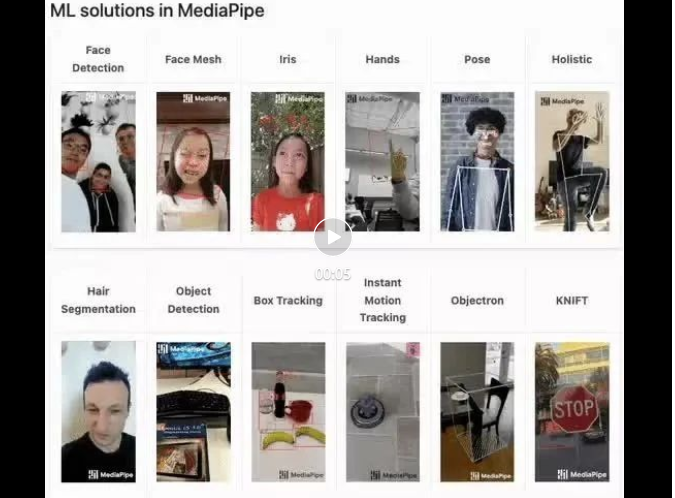
Prinsip pelaksanaan benteng anti muka arus perdana
Atas permintaan
Muat naik video
Pengiraan latar belakang pelayan mengekstrak kawasan potret dalam skrin video dan menukarnya kepada storan svg
Semasa pelanggan memainkan video, ia memuat turun svg daripada pelayan Digabungkan dengan benteng, benteng tidak dipaparkan dalam kawasan potret
Siaran langsung
- Apabila sauh menolak aliran, kawasan potret diekstrak daripada skrin dalam masa nyata (peranti hos) dan ditukar kepada svg
- Gabungkan data svg ke dalam strim video (SEI) dan tolak strim ke pelayan
- Pada masa yang sama semasa klien bermain video, huraikan svg daripada strim video (SEI)
- Gabungkan svg dengan sintesis Skrin pop timbul, kawasan potret tidak memaparkan rentetan
Pelan pelaksanaan artikel ini
Semasa pelanggan memainkan video, maklumat kawasan potret diekstrak daripada skrin dalam masa nyata, dan maklumat kawasan potret dieksport ke dalam gambar dan peluru Sintesis skrin, rentetan tidak akan dipaparkan dalam kawasan potret.
Prinsip Pelaksanaan
- Menggunakan perpustakaan sumber terbuka pembelajaran mesin untuk mengekstrak garis besar potret daripada imej video dalam masa nyata, seperti Pembahagian Badan (https://github.com/tensorflow/tfjs -models/blob/ master/body-segmentation/README.md)
- Eksport garis besar potret ke dalam gambar, dan tetapkan imej topeng lapisan barrage (https://developer.mozilla.org/ zh-CN/docs/ Web/CSS/mask-image)
Berbanding dengan penyelesaian tradisional (SEI secara langsung masa nyata)
Kelebihan:
- Mudah untuk dilaksanakan; hanya satu teg Video diperlukan Parameter, tidak memerlukan penyelarasan berbilang hujung
- Tiada penggunaan jalur lebar rangkaian
Kelemahan:
- Had prestasi teori adalah lebih rendah daripada penyelesaian tradisional; setara dengan menukar sumber prestasi untuk Sumber rangkaian
Masalah yang dihadapi
JavaScript diketahui mempunyai prestasi yang lemah, menjadikannya tidak sesuai untuk CPU- tugasan intensif. Daripada demo rasmi kepada amalan kejuruteraan, cabaran terbesar ialah prestasi.
Amalan ini akhirnya mengoptimumkan penggunaan CPU kepada kira-kira 5% (2020 M1 Macbook), mencapai keadaan sedia pengeluaran.
Amalkan proses penalaan
Pilih model pembelajaran mesin
BodyPix (https://github.com/tensorflow/tfjs-models/blob/master/body-segmentation / src/body_pix/README.md)
Ketepatan terlalu lemah, mukanya sempit, dan jelas terdapat pertindihan antara rentetan dan tepi muka watak

BlazePose (https://github.com/tensorflow/tfjs-models/blob/master/pose-detection/src/blazepose_mediapipe/README.md)
Ketepatan yang sangat baik dan menyediakan maklumat titik badan, Tetapi prestasinya kurang baik

Contoh struktur data pengembalian
[{score: 0.8,keypoints: [{x: 230, y: 220, score: 0.9, score: 0.99, name: "nose"},{x: 212, y: 190, score: 0.8, score: 0.91, name: "left_eye"},...],keypoints3D: [{x: 0.65, y: 0.11, z: 0.05, score: 0.99, name: "nose"},...],segmentation: {maskValueToLabel: (maskValue: number) => { return 'person' },mask: {toCanvasImageSource(): ...toImageData(): ...toTensor(): ...getUnderlyingType(): ...}}}]MediaPipe SelfieSegmentation (https://github.com/tensorflow/tfjs-models/blob/ master /body-segmentation/src/selfie_segmentation_mediapipe/README.md)
Ketepatan yang sangat baik (kesan yang sama seperti model BlazePose), penggunaan CPU adalah kira-kira 15% lebih rendah daripada model BlazePose, prestasi lebih baik, tetapi anggota badan tidak disediakan dalam maklumat Point data yang dikembalikan
Contoh struktur data pulangan
{maskValueToLabel: (maskValue: number) => { return 'person' },mask: {toCanvasImageSource(): ...toImageData(): ...toTensor(): ...getUnderlyingType(): ...}}Pelaksanaan versi pertama
Rujuk kepada pelaksanaan rasmi model MediaPipe SelfieSegmentation (https://github.com/tensorflow/ tfjs-models/blob /master/body-segmentation/README.md#bodysegmentationdrawmask), tanpa pengoptimuman, CPU mengambil kira-kira 70%
const canvas = document.createElement('canvas')canvas.width = videoEl.videoWidthcanvas.height = videoEl.videoHeightasync function detect (): Promise<void> {const segmentation = await segmenter.segmentPeople(videoEl)const foregroundColor = { r: 0, g: 0, b: 0, a: 0 }const backgroundColor = { r: 0, g: 0, b: 0, a: 255 } const mask = await toBinaryMask(segmentation, foregroundColor, backgroundColor) await drawMask(canvas, canvas, mask, 1, 9)// 导出Mask图片,需要的是轮廓,图片质量设为最低handler(canvas.toDataURL('image/png', 0)) window.setTimeout(detect, 33)} detect().catch(console.error)Kurangkan kekerapan pengekstrakan dan mengimbangi pengalaman prestasi
Selesaikan kesesakan prestasi Menganalisis graf nyalaan, didapati bahawa kesesakan prestasi berada dalam toBinaryMask dan toDataURL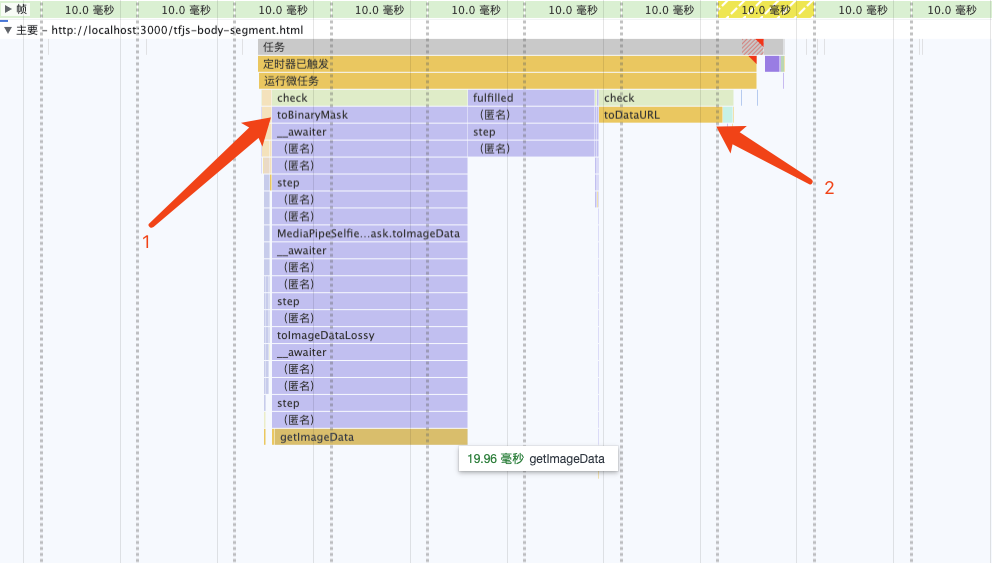 Menulis Semula keBinaryMask🎜 >
Menulis Semula keBinaryMask🎜 >
window.setTimeout(detect, 66) // 33 => 66
Salin selepas log masuk
Langkah 2 dan 3 adalah bersamaan dengan mengisi kandungan di luar kawasan potret dengan warna hitam (mengisi terbalik ImageBitmap), untuk bekerjasama dengan css (imej topeng), jika tidak hanya apabila Bendungan hanya kelihatan apabila ia terapung ke kawasan potret (betul-betul bertentangan dengan kesan sasaran).
window.setTimeout(detect, 66) // 33 => 66
globalCompositeOperation MDN(https://developer.mozilla.org/zh-CN/docs/Web/API/CanvasRenderingContext2D/globalCompositeOperation)
此时,CPU 占用 33% 左右
多线程优化
我原先认为toDataURL是由浏览器内部实现的,无法再进行优化,现在只有优化toDataURL这个耗时操作了。
虽没有替换实现,但可使用 OffscreenCanvas (https://developer.mozilla.org/zh-CN/docs/Web/API/OffscreenCanvas)+ Worker,将耗时任务转移到 Worker 中去, 避免占用主线程,就不会影响用户体验了。
并且ImageBitmap实现了Transferable接口,可被转移所有权,跨 Worker 传递也没有性能损耗(https://hughfenghen.github.io/fe-basic-course/js-concurrent.html#%E4%B8%A4%E4%B8%AA%E6%96%B9%E6%B3%95%E5%AF%B9%E6%AF%94)。
// 前文 detect 的反向填充 ImageBitmap 也可以转移到 Worker 中// 用 OffscreenCanvas 实现, 此处略过 const reader = new FileReaderSync()// OffscreenCanvas 不支持 toDataURL,使用 convertToBlob 代替offsecreenCvsEl.convertToBlob({type: 'image/png',quality: 0}).then((blob) => {const dataURL = reader.readAsDataURL(blob)self.postMessage({msgType: 'mask',val: dataURL})}).catch(console.error)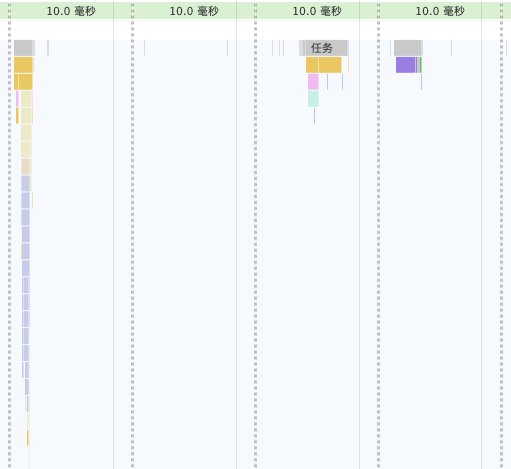
可以看到两个耗时的操作消失了
此时,CPU 占用 15% 左右
降低分辨率
继续分析,上图重新计算样式(紫色部分)耗时约 3ms
Demo 足够简单很容易推测到是这行代码导致的,发现 imgStr 大概 100kb 左右(视频分辨率 1280x720)。
danmakuContainer.style.webkitMaskImage = `url(${imgStr})通过canvas缩小图片尺寸(360P甚至更低),再进行推理。
优化后,导出的 imgStr 大概 12kb,重新计算样式耗时约 0.5ms。
此时,CPU 占用 5% 左右

启动条件优化
虽然提取 Mask 整个过程的 CPU 占用已优化到可喜程度。
当在画面没人的时候,或没有弹幕时候,可以停止计算,实现 0 CPU 占用。
无弹幕判断比较简单(比如 10s 内收超过两条弹幕则启动计算),也不在该 SDK 实现范围,略过
判定画面是否有人
第一步中为了高性能,选择的模型只有ImageBitmap,并没有提供肢体点位信息,所以只能使用getImageData返回的像素点值来判断画面是否有人。
画面无人时,CPU 占用接近 0%
发布构建优化
依赖包的提交较大,构建出的 bundle 体积:684.75 KiB / gzip: 125.83 KiB
所以,可以进行异步加载SDK,提升页面加载性能。
- 分别打包一个 loader,一个主体
- 由业务方 import loader,首次启用时异步加载主体
这个两步前端工程已经非常成熟了,略过细节。
运行效果

总结
过程
- 选择高性能模型后,初始状态 CPU 70%
- 降低 Mask 刷新频率(15FPS),CPU 50%
- 重写开源库实现(toBinaryMask),CPU 33%
- 多线程优化,CPU 15%
- 降低分辨率,CPU 5%
- 判断画面是否有人,无人时 CPU 接近 0%
CPU 数值指主线程占用
注意事项
- 兼容性:Chrome 79及以上,不支持 Firefox、Safari。因为使用了OffscreenCanvas
- 不应创建多个或多次创建segmenter实例(bodySegmentation.createSegmenter),如需复用请保存实例引用,因为:
- 创建实例时低性能设备会有明显的卡顿现象
- 会内存泄露;如果无法避免,这是mediapipe 内存泄露 解决方法(https://github.com/google/mediapipe/issues/2819#issuecomment-1160335349)
经验
- 优化完成之后,提取并应用 Mask 关键计算量在 GPU (30%左右),而不是 CPU
- 性能优化需要业务场景分析,防挡弹幕场景可以使用低分辨率、低刷新率的 mask-image,能大幅减少计算量
- 该方案其他应用场景:
- 替换/模糊人物背景
- 人像马赛克
- 人像抠图
- 卡通头套,虚拟饰品,如猫耳朵、兔耳朵、带花、戴眼镜什么的(换一个模型,略改)
- 关注Web 神经网络 API (https://mp.weixin.qq.com/s/v7-xwYJqOfFDIAvwIVZVdg)进展,以后实现相关功能也许会更简单
本期作者

刘俊
Jurutera Pembangunan Kanan Bilibili
Atas ialah kandungan terperinci Perlindungan masa nyata terhadap rentetan penyekat muka di web (berdasarkan pembelajaran mesin). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Bagaimana untuk menyesuaikan simbol saiz semula melalui CSS dan menjadikannya seragam dengan warna latar belakang?
Apr 05, 2025 pm 02:30 PM
Bagaimana untuk menyesuaikan simbol saiz semula melalui CSS dan menjadikannya seragam dengan warna latar belakang?
Apr 05, 2025 pm 02:30 PM
Kaedah penyesuaian simbol saiz semula dalam CSS bersatu dengan warna latar belakang. Dalam perkembangan harian, kita sering menghadapi situasi di mana kita perlu menyesuaikan butiran antara muka pengguna, seperti menyesuaikan ...
 Bagaimana cara memaparkan 'badan bulat jingnan mai' yang dipasang dengan betul di laman web?
Apr 05, 2025 pm 10:33 PM
Bagaimana cara memaparkan 'badan bulat jingnan mai' yang dipasang dengan betul di laman web?
Apr 05, 2025 pm 10:33 PM
Menggunakan fail font yang dipasang di laman web baru -baru ini, saya memuat turun fon percuma dari internet dan berjaya memasangnya ke dalam sistem saya. Sekarang ...
 Teks di bawah susun atur flex ditinggalkan tetapi bekas dibuka? Bagaimana menyelesaikannya?
Apr 05, 2025 pm 11:00 PM
Teks di bawah susun atur flex ditinggalkan tetapi bekas dibuka? Bagaimana menyelesaikannya?
Apr 05, 2025 pm 11:00 PM
Masalah pembukaan kontena kerana peninggalan teks yang berlebihan di bawah susun atur flex dan penyelesaian digunakan ...
 Mengapa elemen Div tertentu dalam penyemak imbas tepi tidak dipaparkan? Bagaimana menyelesaikan masalah ini?
Apr 05, 2025 pm 08:21 PM
Mengapa elemen Div tertentu dalam penyemak imbas tepi tidak dipaparkan? Bagaimana menyelesaikan masalah ini?
Apr 05, 2025 pm 08:21 PM
Bagaimana menyelesaikan masalah paparan yang disebabkan oleh helaian gaya ejen pengguna? Apabila menggunakan penyemak imbas Edge, elemen Div dalam projek tidak dapat dipaparkan. Setelah memeriksa, saya menyiarkan ...
 Bagaimana untuk mengawal bahagian atas dan akhir halaman dalam tetapan percetakan penyemak imbas melalui JavaScript atau CSS?
Apr 05, 2025 pm 10:39 PM
Bagaimana untuk mengawal bahagian atas dan akhir halaman dalam tetapan percetakan penyemak imbas melalui JavaScript atau CSS?
Apr 05, 2025 pm 10:39 PM
Cara menggunakan JavaScript atau CSS untuk mengawal bahagian atas dan akhir halaman dalam tetapan percetakan penyemak imbas. Dalam tetapan percetakan penyemak imbas, ada pilihan untuk mengawal sama ada paparan ...
 Kenapa lembaran gaya tersuai berkuatkuasa pada laman web tempatan di Safari tetapi tidak di halaman Baidu?
Apr 05, 2025 pm 05:15 PM
Kenapa lembaran gaya tersuai berkuatkuasa pada laman web tempatan di Safari tetapi tidak di halaman Baidu?
Apr 05, 2025 pm 05:15 PM
Perbincangan Menggunakan Stylesheets Custom Di Safari Hari Ini Kami akan membincangkan soalan mengenai penggunaan gaya gaya tersuai untuk penyemak imbas Safari. Pemula depan ...
 Mengapa margin negatif tidak berkuatkuasa dalam beberapa kes? Bagaimana menyelesaikan masalah ini?
Apr 05, 2025 pm 10:18 PM
Mengapa margin negatif tidak berkuatkuasa dalam beberapa kes? Bagaimana menyelesaikan masalah ini?
Apr 05, 2025 pm 10:18 PM
Mengapa margin negatif tidak berkuatkuasa dalam beberapa kes? Semasa pengaturcaraan, margin negatif dalam CSS (negatif ...
 Bagaimana cara menggunakan fail fon yang dipasang di laman web di laman web?
Apr 05, 2025 pm 10:57 PM
Bagaimana cara menggunakan fail fon yang dipasang di laman web di laman web?
Apr 05, 2025 pm 10:57 PM
Cara Menggunakan Fail Font yang Dipasang Secara Tempatan Di Laman Web Adakah anda menghadapi situasi ini dalam pembangunan laman web: anda telah memasang fon pada komputer anda ...
