

Menurut berita pada 8 Jun, model bahasa besar berbilang modal domestik TigerBot telah dikeluarkan secara rasmi baru-baru ini, termasuk dua versi 7 bilion parameter dan 180 bilion parameter Ia kini sumber terbuka di GitHub.
▲ Sumber gambar Halaman GitHub TigerBot
Dilaporkan bahawa inovasi yang dibawa oleh TigerBot terutamanya terletak pada:
Selain itu, model ini juga telah membuat pengoptimuman yang lebih sesuai daripada tokenizer kepada algoritma latihan untuk pengedaran bahasa Cina yang lebih tidak teratur.
Penyelidik Chen Ye berkata di laman web rasmi Hubo Technology: "Model ini boleh memahami dengan cepat jenis soalan yang ditanya oleh manusia menggunakan hanya sebilangan kecil parameter. Menurut kertas OpenAI InstructGPT mengenai data NLP awam set Menurut penilaian automatik, TigerBot-7B telah mencapai 96% daripada prestasi komprehensif model saiz yang sama OpenAI Menurut laporan itu, prestasi TigerBot-7B-base adalah "lebih baik daripada model setanding OpenAI." Kod sumber terbuka termasuk latihan asas dan kod inferens, dan kod kuantifikasi dan inferens model 180B inferens dwi-kad. Data tersebut termasuk data pra-latihan 100G dan 1G atau 1 juta keping data untuk penalaan halus diselia.
Rakan IT House boleh 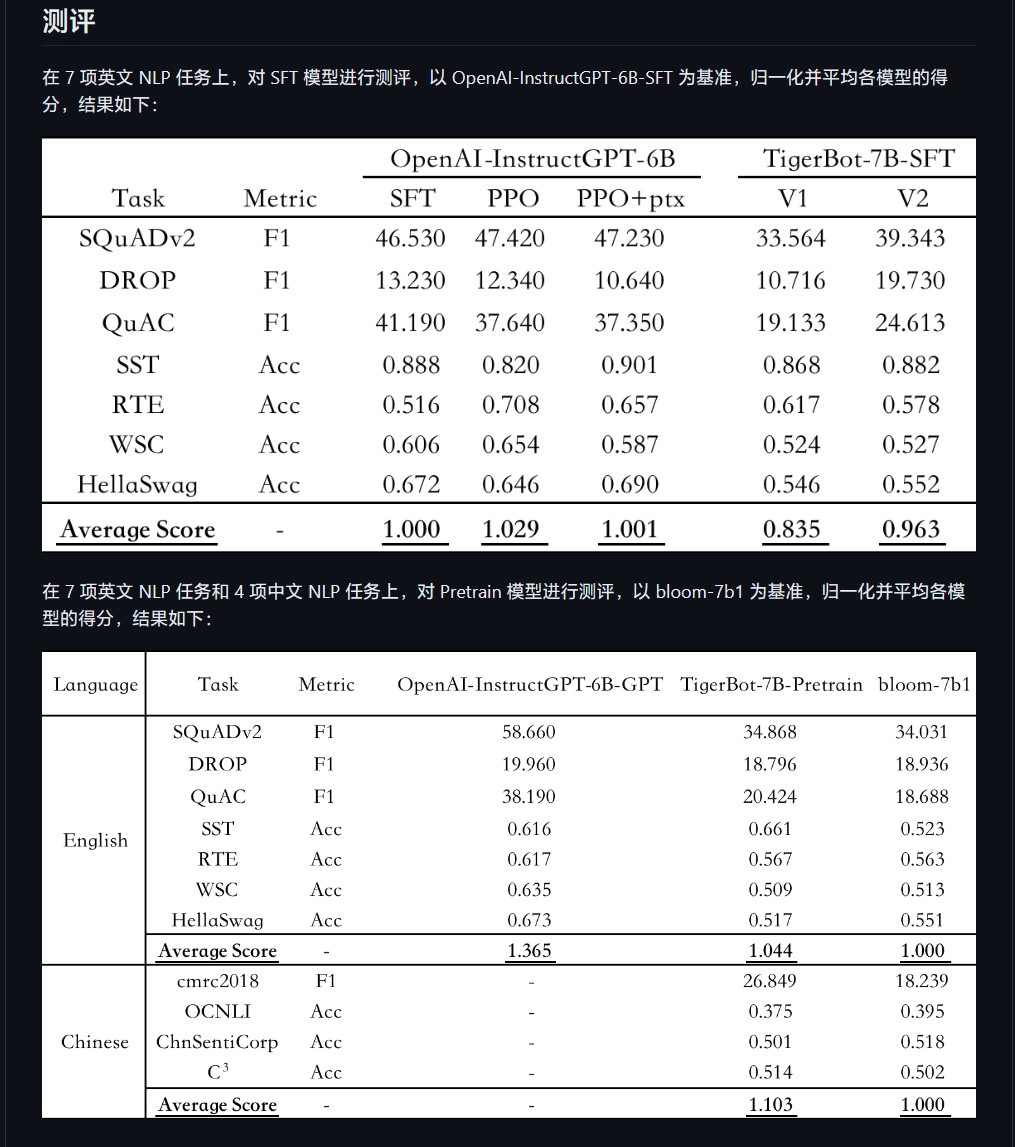 mencari projek sumber terbuka GitHub di sini
mencari projek sumber terbuka GitHub di sini
Atas ialah kandungan terperinci Kesannya boleh mencapai 96% daripada model setara OpanAI, dan model bahasa AI sumber terbuka domestik TigerBot dikeluarkan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Bagaimana untuk membuka fail csv
Bagaimana untuk membuka fail csv
 Bagaimana untuk membuka fail html WeChat
Bagaimana untuk membuka fail html WeChat
 Konsep m2m dalam Internet Perkara
Konsep m2m dalam Internet Perkara
 Apakah yang ditunjukkan oleh pihak lain selepas disekat di WeChat?
Apakah yang ditunjukkan oleh pihak lain selepas disekat di WeChat?
 Bagaimana untuk membuka fail mobi
Bagaimana untuk membuka fail mobi
 Apakah perbezaan antara Douyin dan Douyin Express Edition?
Apakah perbezaan antara Douyin dan Douyin Express Edition?
 apa itu c#
apa itu c#
 Bolehkah Douyin mengecas semula bil telefon dikembalikan?
Bolehkah Douyin mengecas semula bil telefon dikembalikan?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



