
 Operasi dan penyelenggaraan
Keselamatan
Artikel tentang cara mengoptimumkan prestasi LLM menggunakan pangkalan pengetahuan tempatan
Operasi dan penyelenggaraan
Keselamatan
Artikel tentang cara mengoptimumkan prestasi LLM menggunakan pangkalan pengetahuan tempatan
Artikel tentang cara mengoptimumkan prestasi LLM menggunakan pangkalan pengetahuan tempatan

Semalam, latihan penalaan halus selama 220 jam telah selesai. Tugas utama adalah untuk memperhalusi model dialog pada CHATGLM-6B yang boleh mendiagnosis maklumat ralat pangkalan data dengan lebih tepat.
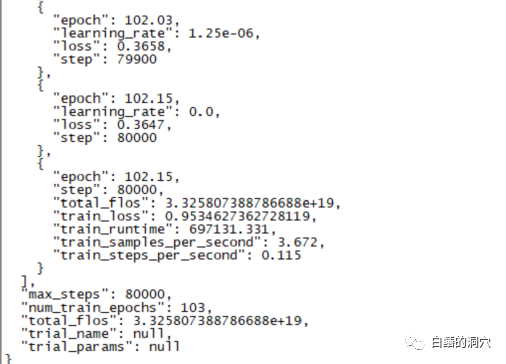
Namun, keputusan akhir latihan selama hampir sepuluh hari ini mengecewakan latihan sebelum ini saya lakukan dengan liputan sampel yang lebih kecil, perbezaannya masih agak besar.
Hasil ini masih agak mengecewakan pada asasnya . Nampaknya parameter dan set latihan perlu diselaraskan semula dan latihan dilakukan semula. Latihan model bahasa besar adalah perlumbaan senjata, dan adalah mustahil untuk bermain tanpa peralatan yang baik. Nampaknya kita juga mesti menaik taraf peralatan makmal, jika tidak akan ada beberapa sepuluh hari untuk dibazirkan.
Berdasarkan latihan penalaan halus yang gagal baru-baru ini, latihan penalaan halus bukanlah jalan yang mudah untuk diselesaikan. Objektif tugas yang berbeza digabungkan bersama untuk latihan Objektif tugas yang berbeza mungkin memerlukan parameter latihan yang berbeza, menjadikan set latihan akhir tidak dapat memenuhi keperluan tugasan tertentu. Oleh itu, PTUNING hanya sesuai untuk tugasan yang sangat tertentu, dan tidak semestinya sesuai untuk tugas bercampur Model yang bertujuan untuk tugasan bercampur mungkin perlu menggunakan FINETUNE. Ini sama dengan apa yang dikatakan oleh semua orang semasa saya berkomunikasi dengan rakan beberapa hari lalu.
Malah, kerana melatih model itu sukar, sesetengah orang telah berhenti melatih model itu sendiri, dan sebaliknya mengvektorkan pangkalan pengetahuan tempatan untuk mendapatkan semula yang lebih tepat, dan kemudian menggunakan AUTOPROMPT untuk dapatkan semula model Hasil akhir menjana gesaan automatik untuk bertanya model pertuturan. Matlamat ini mudah dicapai menggunakan langchain.
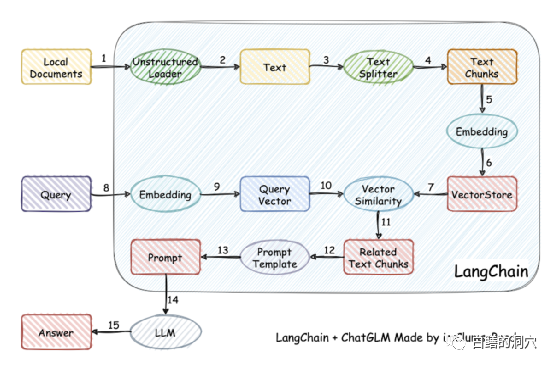
Prinsip kerjanya ialah memuatkan dokumen tempatan sebagai teks melalui pemuat, dan kemudian Teks dibahagikan kepada serpihan teks strok, dan selepas pengekodan, ia ditulis ke dalam storan vektor untuk digunakan dalam pertanyaan. Selepas keputusan pertanyaan keluar, gesaan untuk bertanya soalan dibentuk secara automatik melalui Templat Gesaan untuk bertanya kepada LLM, dan LLM menjana jawapan akhir.
Ada satu lagi perkara penting dalam kerja ini Satu lagi adalah untuk mencari pengetahuan dengan lebih tepat dalam pangkalan pengetahuan tempatan. Ini dicapai dengan penyimpanan vektor pada masa ini di Cina dan Inggeris tempatan Terdapat banyak penyelesaian untuk vektorisasi dan pencarian pangkalan pengetahuan Anda boleh memilih penyelesaian yang lebih mesra kepada pangkalan pengetahuan anda.
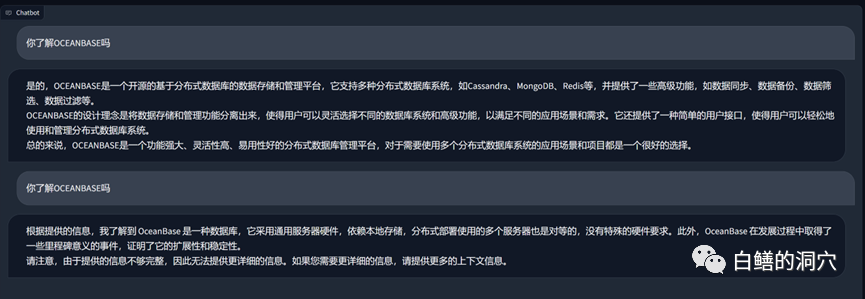
Di atas ialah pangkalan pengetahuan tentang OB yang diturunkan pada vicuna-13b Untuk Soal Jawab, di atas adalah jawapan menggunakan keupayaan LLM tanpa menggunakan pangkalan pengetahuan tempatan. Berikut adalah jawapan selepas memuatkan pangkalan pengetahuan tempatan. Ia boleh dilihat bahawa peningkatan prestasi agak ketara.
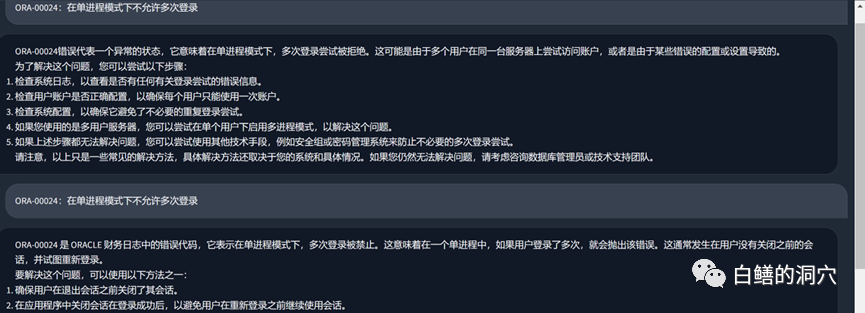
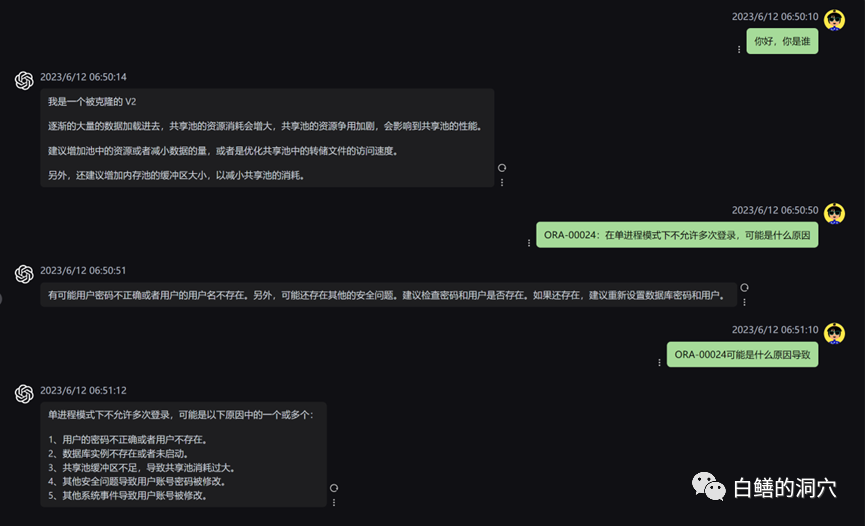
Mari kita lihat masalah ralat ORA tadi Sebelum menggunakan pangkalan pengetahuan tempatan, LLM pada asasnya Ia mengarut, tetapi selepas memuatkan pangkalan pengetahuan tempatan, jawapan ini masih memuaskan kesilapan dalam artikel juga adalah kesilapan dalam pangkalan pengetahuan kami. Malah, set latihan yang digunakan oleh PTUNING juga dijana melalui pangkalan pengetahuan tempatan ini.
Kita boleh menimba pengalaman daripada perangkap yang telah kita lalui baru-baru ini. Pertama sekali, kesukaran ptuning adalah jauh lebih tinggi daripada yang kita fikirkan Walaupun ptuning memerlukan peralatan yang lebih rendah daripada finetune, kesukaran latihan tidak rendah sama sekali. Kedua, adalah baik untuk menggunakan pangkalan pengetahuan tempatan melalui Langchain dan autoprompt untuk meningkatkan keupayaan LLM Untuk kebanyakan aplikasi perusahaan, selagi pangkalan pengetahuan tempatan diselesaikan dan penyelesaian vektorisasi yang sesuai dipilih, anda seharusnya boleh mendapatkan hasil yang. tidak lebih teruk daripada PTUNING/FINETUNE Effect. Ketiga, dan sekali lagi seperti yang dinyatakan kali lepas, keupayaan LLM adalah penting. LLM yang berkuasa mesti dipilih sebagai model asas untuk digunakan. Mana-mana model terbenam hanya boleh meningkatkan sebahagian keupayaan dan tidak boleh memainkan peranan yang menentukan. Keempat, untuk pengetahuan berkaitan pangkalan data, vicuna-13b mempunyai kebolehan yang sangat baik.
Saya perlu pergi ke klien untuk berkomunikasi awal pagi ini, jadi saya hanya akan menulis beberapa ayat. Apa pendapat anda tentang perkara ini? Anda dialu-alukan untuk meninggalkan mesej untuk perbincangan (perbincangan hanya dapat dilihat oleh anda dan saya sendiri di jalan ini.
Atas ialah kandungan terperinci Artikel tentang cara mengoptimumkan prestasi LLM menggunakan pangkalan pengetahuan tempatan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1386
1386
 52
52

 Perbandingan prestasi rangka kerja Java yang berbeza
Jun 05, 2024 pm 07:14 PM
Perbandingan prestasi rangka kerja Java yang berbeza
Jun 05, 2024 pm 07:14 PM
Perbandingan prestasi rangka kerja Java yang berbeza: Pemprosesan permintaan REST API: Vert.x adalah yang terbaik, dengan kadar permintaan 2 kali SpringBoot dan 3 kali Dropwizard. Pertanyaan pangkalan data: HibernateORM SpringBoot adalah lebih baik daripada Vert.x dan ORM Dropwizard. Operasi caching: Pelanggan Hazelcast Vert.x lebih unggul daripada mekanisme caching SpringBoot dan Dropwizard. Rangka kerja yang sesuai: Pilih mengikut keperluan aplikasi Vert.x sesuai untuk perkhidmatan web berprestasi tinggi, SpringBoot sesuai untuk aplikasi intensif data, dan Dropwizard sesuai untuk seni bina perkhidmatan mikro.
 Pembalikan nilai kunci tatasusunan PHP: analisis perbandingan prestasi kaedah yang berbeza
May 03, 2024 pm 09:03 PM
Pembalikan nilai kunci tatasusunan PHP: analisis perbandingan prestasi kaedah yang berbeza
May 03, 2024 pm 09:03 PM
Perbandingan prestasi kaedah membalik nilai kunci tatasusunan PHP menunjukkan bahawa fungsi array_flip() berprestasi lebih baik daripada gelung for dalam tatasusunan besar (lebih daripada 1 juta elemen) dan mengambil masa yang lebih singkat. Kaedah gelung untuk membalikkan nilai kunci secara manual mengambil masa yang agak lama.
 Pengoptimuman program C++: teknik pengurangan kerumitan masa
Jun 01, 2024 am 11:19 AM
Pengoptimuman program C++: teknik pengurangan kerumitan masa
Jun 01, 2024 am 11:19 AM
Kerumitan masa mengukur masa pelaksanaan algoritma berbanding saiz input. Petua untuk mengurangkan kerumitan masa program C++ termasuk: memilih bekas yang sesuai (seperti vektor, senarai) untuk mengoptimumkan storan dan pengurusan data. Gunakan algoritma yang cekap seperti isihan pantas untuk mengurangkan masa pengiraan. Hapuskan berbilang operasi untuk mengurangkan pengiraan berganda. Gunakan cawangan bersyarat untuk mengelakkan pengiraan yang tidak perlu. Optimumkan carian linear dengan menggunakan algoritma yang lebih pantas seperti carian binari.
 Bagaimana untuk mengoptimumkan prestasi program berbilang benang dalam C++?
Jun 05, 2024 pm 02:04 PM
Bagaimana untuk mengoptimumkan prestasi program berbilang benang dalam C++?
Jun 05, 2024 pm 02:04 PM
Teknik berkesan untuk mengoptimumkan prestasi berbilang benang C++ termasuk mengehadkan bilangan utas untuk mengelakkan perbalahan sumber. Gunakan kunci mutex ringan untuk mengurangkan perbalahan. Optimumkan skop kunci dan minimumkan masa menunggu. Gunakan struktur data tanpa kunci untuk menambah baik keselarasan. Elakkan sibuk menunggu dan maklumkan urutan ketersediaan sumber melalui acara.
 Apakah kesan prestasi menukar tatasusunan PHP kepada objek?
Apr 30, 2024 am 08:39 AM
Apakah kesan prestasi menukar tatasusunan PHP kepada objek?
Apr 30, 2024 am 08:39 AM
Dalam PHP, penukaran tatasusunan kepada objek akan memberi kesan pada prestasi, yang dipengaruhi terutamanya oleh faktor seperti saiz tatasusunan, kerumitan dan kelas objek. Untuk mengoptimumkan prestasi, pertimbangkan untuk menggunakan iterator tersuai, mengelakkan penukaran yang tidak perlu, tatasusunan penukaran kelompok dan teknik lain.
 Bagaimana untuk menggunakan penanda aras untuk menilai prestasi fungsi Java?
Apr 19, 2024 pm 10:18 PM
Bagaimana untuk menggunakan penanda aras untuk menilai prestasi fungsi Java?
Apr 19, 2024 pm 10:18 PM
Satu cara untuk menanda aras prestasi fungsi Java adalah dengan menggunakan Java Microbenchmark Suite (JMH). Langkah khusus termasuk: Menambah kebergantungan JMH pada projek. Buat kelas Java baharu dan anotasikannya dengan @State untuk mewakili kaedah penanda aras. Tulis kaedah penanda aras dalam kelas dan anotasikannya dengan @Benchmark. Jalankan penanda aras menggunakan alat baris arahan JMH.
 Perbandingan prestasi rangka kerja Java
Jun 04, 2024 pm 03:56 PM
Perbandingan prestasi rangka kerja Java
Jun 04, 2024 pm 03:56 PM
Mengikut penanda aras, untuk aplikasi kecil dan berprestasi tinggi, Quarkus (permulaan pantas, memori rendah) atau Micronaut (TechEmpower cemerlang) adalah pilihan yang ideal. SpringBoot sesuai untuk aplikasi bertindan penuh yang besar, tetapi mempunyai masa permulaan dan penggunaan memori yang lebih perlahan.
 Kesan fungsi sebaris pada prestasi: pandangan yang lebih mendalam
Apr 28, 2024 pm 05:39 PM
Kesan fungsi sebaris pada prestasi: pandangan yang lebih mendalam
Apr 28, 2024 pm 05:39 PM
Fungsi sebaris meningkatkan kelajuan pelaksanaan setempat dengan menghapuskan overhed panggilan fungsi, mengurangkan keperluan ruang tindanan dan memperbaik ramalan cawangan, tetapi penggunaan yang berlebihan boleh menyebabkan kembung kod dan kesan bukan setempat.
