
 Peranti teknologi
AI
Prompt membuka kunci keupayaan penjanaan model bahasa pertuturan, dan SpeechGen melaksanakan terjemahan pertuturan dan menampal berbilang tugas.
Peranti teknologi
AI
Prompt membuka kunci keupayaan penjanaan model bahasa pertuturan, dan SpeechGen melaksanakan terjemahan pertuturan dan menampal berbilang tugas.
Prompt membuka kunci keupayaan penjanaan model bahasa pertuturan, dan SpeechGen melaksanakan terjemahan pertuturan dan menampal berbilang tugas.


- Pautan kertas: https://arxiv.org/pdf/2306.02207.pdf
- Halaman demo: https://ga642381.github.io/SpeechPrompt/speechgen.html
- Kod: https://github.com /ga642381/SpeechGen
Pengenalan dan Motivasi
Model Bahasa Besar (LLMs) dalam Terdapat minat yang besar dalam kandungan janaan kecerdasan buatan (AIGC), terutamanya dengan kemunculan ChatGPT.
Walau bagaimanapun, cara memproses pertuturan berterusan dengan model bahasa besar kekal sebagai cabaran yang tidak dapat diselesaikan, yang menghalang penggunaan model bahasa besar dalam penjanaan pertuturan. Oleh kerana isyarat pertuturan mengandungi maklumat yang kaya, seperti pembesar suara dan emosi, melangkaui data teks biasa, model bahasa berasaskan pertuturan (LM pertuturan) terus muncul.
Walaupun model bahasa pertuturan masih di peringkat awal berbanding model bahasa berasaskan teks, ia mempunyai potensi besar kerana data pertuturan mengandungi maklumat yang lebih kaya daripada teks.
Penyelidik sedang meneroka secara aktif potensi paradigma segera untuk mengeluarkan kuasa model bahasa yang telah dilatih. Gesaan ini membimbing model bahasa yang telah dilatih untuk melaksanakan tugas hiliran tertentu dengan memperhalusi sebilangan kecil parameter. Teknik ini popular dalam bidang NLP kerana kecekapan dan keberkesanannya. Dalam bidang pemprosesan pertuturan, SpeechPrompt telah menunjukkan peningkatan ketara dalam kecekapan parameter dan mencapai prestasi kompetitif dalam pelbagai tugas klasifikasi pertuturan.
Walau bagaimanapun, sama ada pembayang boleh membantu model bahasa pertuturan menyelesaikan tugas penjanaan masih menjadi persoalan terbuka. Dalam kertas kerja ini, kami mencadangkan rangka kerja bersepadu yang inovatif: SpeechGen, yang bertujuan untuk melepaskan potensi model bahasa pertuturan untuk tugas penjanaan. Seperti yang ditunjukkan dalam rajah di bawah, sepatah perkataan dan gesaan tertentu (prompt) disalurkan kepada LM pertuturan sebagai input, dan LM pertuturan boleh melaksanakan tugas tertentu. Contohnya, jika gesaan merah digunakan sebagai input, pertuturan LM boleh melaksanakan tugas terjemahan pertuturan.
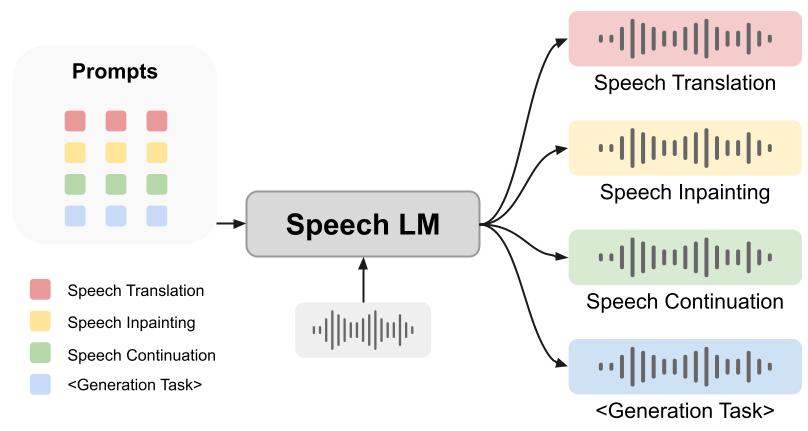
Rangka kerja yang kami cadangkan mempunyai kelebihan berikut:
1 model bahasa pertuturan yang bergantung padanya adalah bebas daripada data teks dan mempunyai nilai yang tidak boleh diukur. Lagipun, proses mendapatkan teks berpasangan dengan pertuturan memakan masa dan membosankan, dan dalam sesetengah bahasa teks yang betul tidak mungkin. Ciri bebas teks membolehkan keupayaan penjanaan pertuturan kami yang hebat untuk merangkumi pelbagai keperluan bahasa, yang memberi manfaat kepada semua manusia.
2. Kepelbagaian: Rangka kerja yang kami bangunkan sangat serba boleh dan boleh digunakan untuk pelbagai tugas penjanaan pertuturan. Eksperimen dalam makalah menggunakan terjemahan pertuturan, pemulihan pertuturan dan kesinambungan pertuturan sebagai contoh.
3 Mudah diikuti: Rangka kerja yang kami cadangkan menyediakan penyelesaian umum untuk pelbagai tugas penjanaan pertuturan, menjadikannya mudah untuk mereka bentuk model hiliran dan fungsi kehilangan.
4 Kebolehpindahan: Rangka kerja kami bukan sahaja mudah disesuaikan dengan model bahasa pertuturan yang lebih maju pada masa hadapan, tetapi juga mengandungi potensi besar untuk meningkatkan lagi kecekapan dan keberkesanan. Apa yang menarik terutamanya ialah rangka kerja kami akan membawa perkembangan yang lebih hebat apabila model bahasa pertuturan lanjutan tersedia.
5 Keterjangkauan: Rangka kerja kami direka dengan teliti dan hanya memerlukan latihan sebilangan kecil parameter dan bukannya keseluruhan model bahasa. Ini sangat mengurangkan beban pengiraan dan membolehkan proses latihan dilakukan pada GPU GTX 2080. Makmal universiti juga mampu membayar overhed pengiraan sedemikian.
Pengenalan SpeechGen
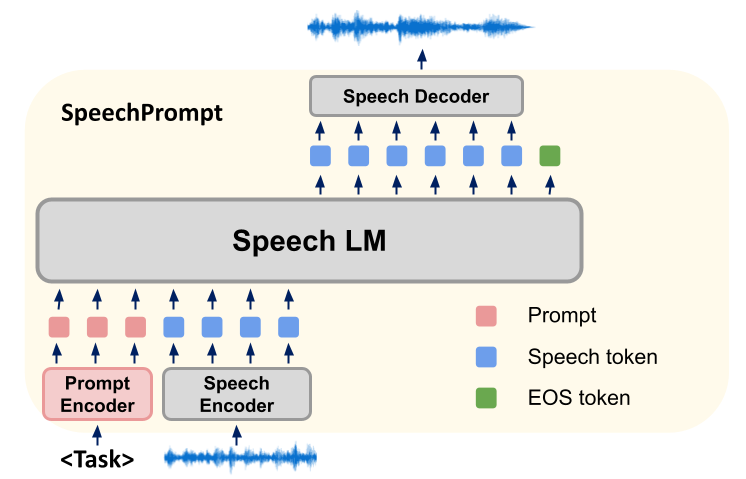
Kaedah penyelidikan kami adalah untuk membina rangka kerja baharu SpeechGen, yang terutamanya menggunakan model bahasa pertuturan (Model Bahasa Pertuturan, SLM) untuk menjalankan pelbagai Fine- penalaan untuk tugas penjanaan pertuturan hiliran. Semasa latihan, parameter SLM dikekalkan tetap dan kaedah kami memfokuskan pada pembelajaran vektor segera khusus tugasan. SLM cekap menjana output yang diperlukan untuk tugas penjanaan pertuturan tertentu dengan menyelaraskan vektor kiu dan unit input secara serentak. Output unit diskret ini kemudiannya dimasukkan ke dalam pensintesis pertuturan berasaskan unit, yang menjana bentuk gelombang yang sepadan.
Rangka kerja SpeechGen kami terdiri daripada tiga elemen: Pengekod Pertuturan, SLM dan Penyahkod Pertuturan.
Pertama, pengekod pertuturan mengambil bentuk gelombang sebagai input dan menukarkannya kepada urutan unit yang diperoleh daripada perbendaharaan kata terhad. Untuk memendekkan panjang jujukan, unit berturut-turut berulang dikeluarkan untuk menghasilkan jujukan unit yang dimampatkan. SLM kemudiannya bertindak sebagai model bahasa untuk jujukan unit, mengoptimumkan kemungkinan dengan meramalkan unit sebelumnya dan unit seterusnya bagi jujukan unit. Kami membuat pelarasan segera kepada SLM untuk membimbingnya menjana unit yang sesuai untuk tugas itu. Akhir sekali, token yang dijana oleh SLM diproses oleh penyahkod pertuturan, menukarkannya semula kepada bentuk gelombang. Dalam strategi penalaan kiu kami, vektor kiu dimasukkan pada permulaan jujukan input, yang memandu arah SLM semasa penjanaan. Bilangan tepat pembayang yang dimasukkan bergantung pada seni bina SLM. Dalam model jujukan kepada jujukan, isyarat ditambahkan pada kedua-dua input pengekod dan input penyahkod, tetapi dalam seni bina pengekod sahaja atau penyahkod sahaja, hanya pembayang ditambahkan di hadapan jujukan input.
Dalam urutan-ke-jujukan SLM (seperti mBART), kami menggunakan model pembelajaran diselia sendiri (seperti HuBERT) untuk memproses input dan pertuturan sasaran. Melakukannya menjana unit diskret untuk input dan unit diskret yang sepadan untuk sasaran. Kami menambah vektor pembayang di hadapan kedua-dua input pengekod dan penyahkod untuk membina urutan input. Di samping itu, kami meningkatkan lagi keupayaan bimbingan isyarat dengan menggantikan pasangan nilai-kunci dalam mekanisme perhatian.
Dalam latihan model, kami menggunakan kehilangan entropi silang sebagai fungsi objektif untuk semua tugas penjanaan, dan mengira kerugian dengan membandingkan keputusan ramalan model dengan label unit diskret sasaran. Dalam proses ini, vektor kiu ialah satu-satunya parameter dalam model yang perlu dilatih, manakala parameter SLM kekal tidak berubah semasa proses latihan, yang memastikan ketekalan tingkah laku model. Dengan memasukkan vektor kiu, kami membimbing SLM untuk mengekstrak maklumat khusus tugasan daripada input dan meningkatkan kemungkinan menghasilkan output selaras dengan tugas penjanaan pertuturan tertentu. Pendekatan ini membolehkan kami memperhalusi dan melaraskan gelagat SLM tanpa mengubah suai parameter asasnya.
Secara amnya, kaedah penyelidikan kami adalah berdasarkan rangka kerja baharu SpeechGen, yang membimbing proses penjanaan model dengan melatih vektor segera, dan membolehkannya menjana pertuturan khusus Generate dengan berkesan output tugasan.
Eksperimen
Rangka kerja kami boleh digunakan untuk sebarang LM pertuturan dan pelbagai tugasan generasi, dan mempunyai potensi yang besar. Dalam percubaan kami, memandangkan VALL-E dan AudioLM bukan sumber terbuka, kami memilih untuk menggunakan Unit mBART sebagai LM pertuturan untuk kajian kes. Kami menggunakan terjemahan pertuturan, lukisan dalam pertuturan dan penerusan pertuturan sebagai contoh untuk menunjukkan keupayaan rangka kerja kami. Gambarajah skematik bagi ketiga-tiga tugasan ini ditunjukkan di bawah. Semua tugas adalah input suara, output suara, tiada bantuan teks diperlukan.
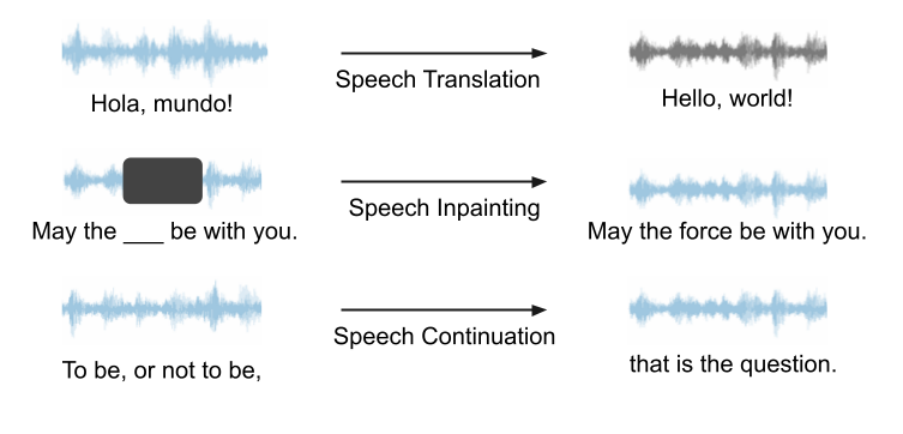
Terjemahan Suara
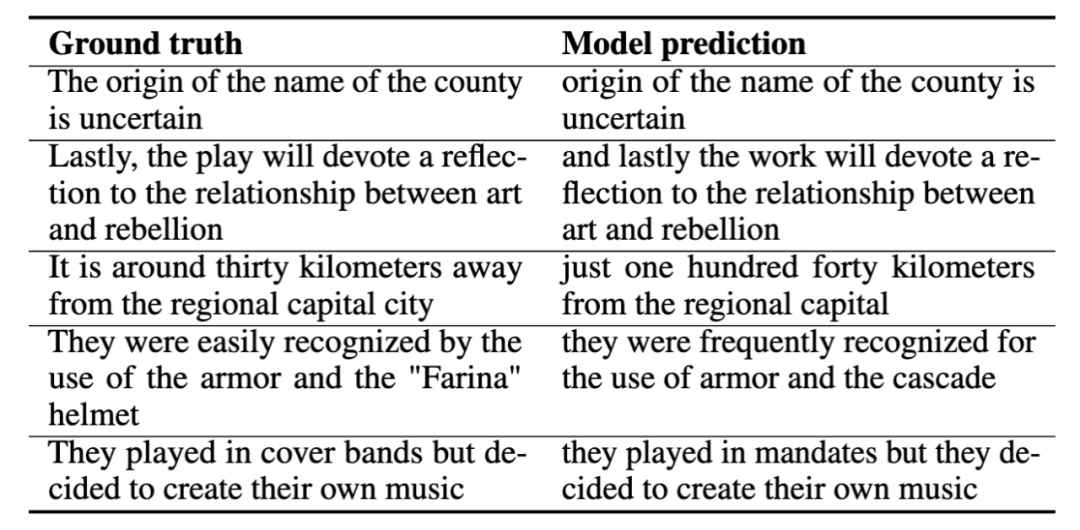
Kami sedang berlatih Apabila melakukan terjemahan pertuturan, tugasan Sepanyol-ke-Inggeris digunakan. Kami memasukkan pertuturan bahasa Sepanyol ke dalam model dan berharap model itu akan menghasilkan pertuturan bahasa Inggeris tanpa bantuan teks dalam keseluruhan proses. Di bawah ialah beberapa contoh terjemahan pertuturan, di mana kami menunjukkan jawapan yang betul (kebenaran asas) dan ramalan model (ramalan model). Contoh demonstrasi ini menunjukkan bahawa ramalan model menangkap makna teras jawapan yang betul.
Lukisan pertuturan
Dalam eksperimen kami tentang lukisan dalam pertuturan, kami khususnya klip Audio lebih lama daripada 2.5 saat dipilih sebagai ucapan sasaran untuk pemprosesan seterusnya, dan klip ucapan antara 0.8 dan 1.2 saat dipilih melalui proses pemilihan rawak. Kami kemudian menutup segmen yang dipilih untuk mensimulasikan bahagian yang hilang atau rosak dalam tugasan melukis pertuturan. Kami menggunakan kadar ralat perkataan (WER) dan kadar ralat aksara (CER) sebagai metrik untuk menilai tahap pembaikan segmen yang rosak.
Analisis perbandingan output yang dijana oleh SpeechGen dan pertuturan yang rosak, model kami boleh membina semula perbendaharaan kata yang dituturkan dengan ketara, mengurangkan WER daripada 41.68% kepada 28.61% dan CER daripada 25.10% dikurangkan kepada 10.75% , seperti yang ditunjukkan dalam jadual di bawah. Ini bermakna kaedah cadangan kami boleh meningkatkan keupayaan pembinaan semula pertuturan dengan ketara, akhirnya menggalakkan ketepatan dan kefahaman output pertuturan.

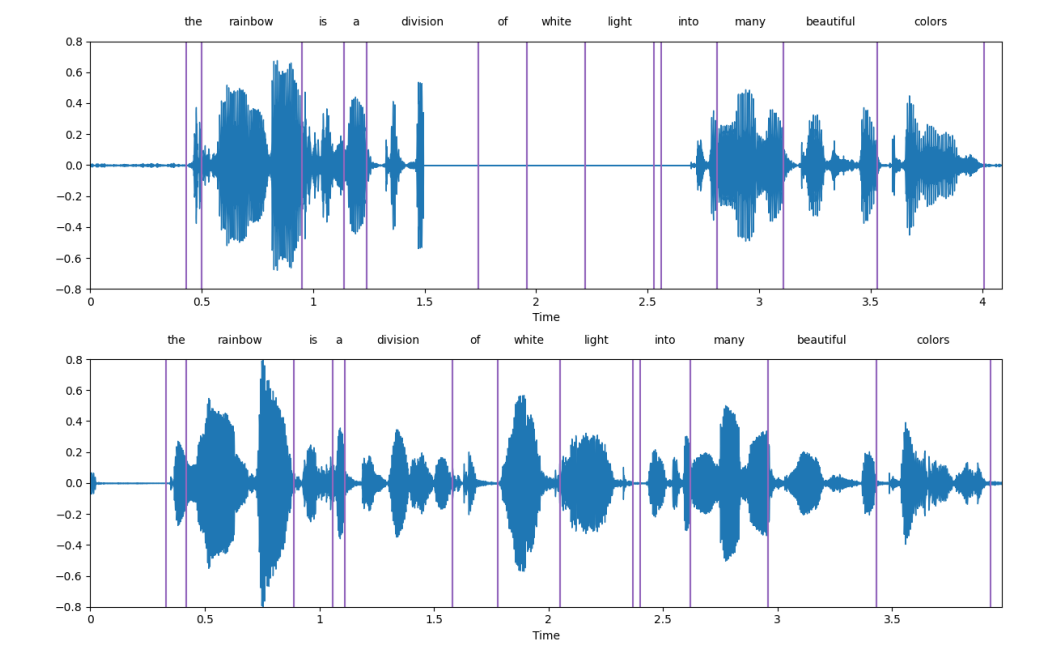
Gambar di bawah ialah contoh paparan Sub-gambar di atas ialah ucapan yang rosak, dan sub-gambar di bawah adalah Ucapan yang dihasilkan oleh SpeechGen dapat dilihat bahawa SpeechGen membaiki ucapan yang rosak dengan baik.
Suara Berterusan
Kami akan lulus LJSpeech menunjukkan aplikasi praktikal untuk tugas berterusan pertuturan. Semasa gesaan latihan (prompt), strategi kami adalah untuk membiarkan model hanya melihat segmen benih serpihan ini menduduki sebahagian daripada jumlah panjang pertuturan Kami memanggil ini nisbah keadaan (nisbah keadaan, r). , dan biarkan Model terus menjana pertuturan seterusnya.
Berikut ialah beberapa contoh Teks hitam mewakili segmen benih, dan teks merah adalah ayat yang dihasilkan oleh SpeechGen (teks di sini pertama kali diperoleh melalui pengecaman pertuturan. Semasa latihan Dan. semasa proses inferens, model melaksanakan tugas pertuturan ke pertuturan sepenuhnya dan tidak menerima sebarang maklumat teks sama sekali). Nisbah keadaan yang berbeza membolehkan SpeechGen menghasilkan ayat dengan panjang yang berbeza-beza untuk mencapai keselarasan dan melengkapkan ayat yang lengkap. Dari perspektif kualiti, ayat yang dihasilkan pada asasnya konsisten secara sintaksis dengan serpihan benih dan berkaitan secara semantik. Walaupun, ucapan yang dihasilkan masih tidak dapat menyampaikan makna yang lengkap dengan sempurna. Kami menjangkakan bahawa isu ini akan ditangani dalam model pertuturan yang lebih berkuasa pada masa hadapan.
Kekurangan dan hala tuju masa depan
Model bahasa pertuturan dan penjanaan pertuturan berada dalam peringkat yang pesat, dan rangka kerja kami menyediakan cara untuk memanfaatkan model bahasa yang berkuasa dengan bijak Kemungkinan penjanaan pertuturan . Walau bagaimanapun, rangka kerja ini masih mempunyai sedikit ruang untuk penambahbaikan, dan terdapat banyak isu yang patut dikaji lebih lanjut.
1. Berbanding dengan model bahasa berasaskan teks, model bahasa pertuturan masih dalam peringkat awal pembangunan. Walaupun rangka kerja isyarat yang kami cadangkan boleh mendorong model bahasa pertuturan untuk melakukan tugas penjanaan pertuturan, ia tidak dapat mencapai prestasi yang cemerlang. Walau bagaimanapun, dengan kemajuan berterusan model bahasa pertuturan, seperti perubahan besar daripada GSLM kepada Unit mBART, prestasi gesaan telah meningkat dengan ketara. Khususnya, tugasan yang sebelum ini mencabar GSLM kini menunjukkan prestasi yang lebih baik di bawah Unit mBART. Kami menjangkakan bahawa model bahasa pertuturan yang lebih maju akan muncul pada masa hadapan.
2. Di luar maklumat kandungan: Model bahasa pertuturan semasa tidak dapat menangkap sepenuhnya maklumat pembesar suara dan emosi, yang membawa cabaran kepada rangka kerja segera pertuturan semasa dalam memproses maklumat ini dengan berkesan. Untuk mengatasi had ini, kami memperkenalkan modul pasang dan main yang secara khusus menyuntik maklumat pembesar suara dan emosi ke dalam rangka kerja. Melangkah ke hadapan, kami menjangkakan bahawa model bahasa pertuturan masa hadapan akan menyepadukan dan mengeksploitasi maklumat di luar ini untuk meningkatkan prestasi dan mengendalikan aspek yang berkaitan dengan penutur dan emosi tugas penjanaan pertuturan dengan lebih baik.
3. Kemungkinan penjanaan segera: Untuk penjanaan segera, kami mempunyai pilihan fleksibel yang boleh menyepadukan pelbagai jenis arahan, termasuk arahan teks dan imej. Bayangkan kita boleh melatih rangkaian saraf untuk mengambil imej atau teks sebagai input, dan bukannya menggunakan pembenaman terlatih sebagai pembayang seperti yang kita lakukan dalam artikel ini. Rangkaian terlatih ini akan menjadi penjana petunjuk, menambah variasi pada rangka kerja. Pendekatan ini akan menjadikan penjanaan segera lebih menarik dan berwarna-warni.
Kesimpulan
Dalam kertas kerja ini kami meneroka penggunaan pembayang untuk membuka kunci prestasi model bahasa pertuturan dalam pelbagai tugasan generatif. Kami mencadangkan rangka kerja bersatu dipanggil SpeechGen yang hanya mempunyai ~10M parameter boleh dilatih. Rangka kerja kami yang dicadangkan mempunyai beberapa sifat utama, termasuk bebas teks, serba boleh, kecekapan, kebolehpindahan dan keterjangkauan. Untuk menunjukkan keupayaan rangka kerja SpeechGen, kami menggunakan Unit mBART sebagai kajian kes dan menjalankan eksperimen pada tiga tugas penjanaan pertuturan yang berbeza: terjemahan pertuturan, pembaikan pertuturan dan penerusan pertuturan.
Apabila kertas kerja ini diserahkan kepada arXiv, Google mencadangkan model bahasa pertuturan yang lebih maju-SPECTRON, yang menunjukkan kepada kita bahawa model bahasa pertuturan boleh memodelkan pembesar suara dan Kemungkinan maklumat seperti emosi. Ini sudah pasti berita yang menggembirakan Memandangkan model bahasa pertuturan lanjutan terus dicadangkan, rangka kerja bersatu kami mempunyai potensi yang besar.
Atas ialah kandungan terperinci Prompt membuka kunci keupayaan penjanaan model bahasa pertuturan, dan SpeechGen melaksanakan terjemahan pertuturan dan menampal berbilang tugas.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Bagaimana untuk menilai keberkesanan kos sokongan komersial untuk rangka kerja Java
Jun 05, 2024 pm 05:25 PM
Bagaimana untuk menilai keberkesanan kos sokongan komersial untuk rangka kerja Java
Jun 05, 2024 pm 05:25 PM
Menilai kos/prestasi sokongan komersial untuk rangka kerja Java melibatkan langkah-langkah berikut: Tentukan tahap jaminan yang diperlukan dan jaminan perjanjian tahap perkhidmatan (SLA). Pengalaman dan kepakaran pasukan sokongan penyelidikan. Pertimbangkan perkhidmatan tambahan seperti peningkatan, penyelesaian masalah dan pengoptimuman prestasi. Timbang kos sokongan perniagaan terhadap pengurangan risiko dan peningkatan kecekapan.
 Bagaimanakah keluk pembelajaran rangka kerja PHP berbanding rangka kerja bahasa lain?
Jun 06, 2024 pm 12:41 PM
Bagaimanakah keluk pembelajaran rangka kerja PHP berbanding rangka kerja bahasa lain?
Jun 06, 2024 pm 12:41 PM
Keluk pembelajaran rangka kerja PHP bergantung pada kecekapan bahasa, kerumitan rangka kerja, kualiti dokumentasi dan sokongan komuniti. Keluk pembelajaran rangka kerja PHP adalah lebih tinggi jika dibandingkan dengan rangka kerja Python dan lebih rendah jika dibandingkan dengan rangka kerja Ruby. Berbanding dengan rangka kerja Java, rangka kerja PHP mempunyai keluk pembelajaran yang sederhana tetapi masa yang lebih singkat untuk bermula.
 Bagaimanakah pilihan rangka kerja PHP yang ringan mempengaruhi prestasi aplikasi?
Jun 06, 2024 am 10:53 AM
Bagaimanakah pilihan rangka kerja PHP yang ringan mempengaruhi prestasi aplikasi?
Jun 06, 2024 am 10:53 AM
Rangka kerja PHP yang ringan meningkatkan prestasi aplikasi melalui saiz kecil dan penggunaan sumber yang rendah. Ciri-cirinya termasuk: saiz kecil, permulaan pantas, penggunaan memori yang rendah, kelajuan dan daya tindak balas yang dipertingkatkan, dan penggunaan sumber yang dikurangkan: SlimFramework mencipta API REST, hanya 500KB, responsif yang tinggi dan daya pemprosesan yang tinggi.
 Perbandingan prestasi rangka kerja Java
Jun 04, 2024 pm 03:56 PM
Perbandingan prestasi rangka kerja Java
Jun 04, 2024 pm 03:56 PM
Mengikut penanda aras, untuk aplikasi kecil dan berprestasi tinggi, Quarkus (permulaan pantas, memori rendah) atau Micronaut (TechEmpower cemerlang) adalah pilihan yang ideal. SpringBoot sesuai untuk aplikasi bertindan penuh yang besar, tetapi mempunyai masa permulaan dan penggunaan memori yang lebih perlahan.
 Amalan terbaik dokumentasi rangka kerja Golang
Jun 04, 2024 pm 05:00 PM
Amalan terbaik dokumentasi rangka kerja Golang
Jun 04, 2024 pm 05:00 PM
Menulis dokumentasi yang jelas dan komprehensif adalah penting untuk rangka kerja Golang. Amalan terbaik termasuk mengikut gaya dokumentasi yang ditetapkan, seperti Panduan Gaya Pengekodan Google. Gunakan struktur organisasi yang jelas, termasuk tajuk, subtajuk dan senarai, serta sediakan navigasi. Menyediakan maklumat yang komprehensif dan tepat, termasuk panduan permulaan, rujukan API dan konsep. Gunakan contoh kod untuk menggambarkan konsep dan penggunaan. Pastikan dokumentasi dikemas kini, jejak perubahan dan dokumen ciri baharu. Sediakan sokongan dan sumber komuniti seperti isu dan forum GitHub. Buat contoh praktikal, seperti dokumentasi API.
 Bagaimana untuk memilih rangka kerja golang terbaik untuk senario aplikasi yang berbeza
Jun 05, 2024 pm 04:05 PM
Bagaimana untuk memilih rangka kerja golang terbaik untuk senario aplikasi yang berbeza
Jun 05, 2024 pm 04:05 PM
Pilih rangka kerja Go terbaik berdasarkan senario aplikasi: pertimbangkan jenis aplikasi, ciri bahasa, keperluan prestasi dan ekosistem. Rangka kerja Common Go: Gin (aplikasi Web), Echo (Perkhidmatan Web), Fiber (daya pemprosesan tinggi), gorm (ORM), fasthttp (kelajuan). Kes praktikal: membina REST API (Fiber) dan berinteraksi dengan pangkalan data (gorm). Pilih rangka kerja: pilih fasthttp untuk prestasi utama, Gin/Echo untuk aplikasi web yang fleksibel, dan gorm untuk interaksi pangkalan data.
 Penjelasan praktikal terperinci pembangunan rangka kerja golang: Soalan dan Jawapan
Jun 06, 2024 am 10:57 AM
Penjelasan praktikal terperinci pembangunan rangka kerja golang: Soalan dan Jawapan
Jun 06, 2024 am 10:57 AM
Dalam pembangunan rangka kerja Go, cabaran biasa dan penyelesaiannya ialah: Pengendalian ralat: Gunakan pakej ralat untuk pengurusan dan gunakan perisian tengah untuk mengendalikan ralat secara berpusat. Pengesahan dan kebenaran: Sepadukan perpustakaan pihak ketiga dan cipta perisian tengah tersuai untuk menyemak bukti kelayakan. Pemprosesan serentak: Gunakan goroutine, mutex dan saluran untuk mengawal akses sumber. Ujian unit: Gunakan pakej, olok-olok dan stub untuk pengasingan dan alat liputan kod untuk memastikan kecukupan. Penerapan dan pemantauan: Gunakan bekas Docker untuk membungkus penggunaan, menyediakan sandaran data dan menjejak prestasi dan ralat dengan alat pengelogan dan pemantauan.
 Apakah salah faham yang biasa berlaku dalam proses pembelajaran kerangka Golang?
Jun 05, 2024 pm 09:59 PM
Apakah salah faham yang biasa berlaku dalam proses pembelajaran kerangka Golang?
Jun 05, 2024 pm 09:59 PM
Terdapat lima salah faham dalam pembelajaran rangka kerja Go: terlalu bergantung pada rangka kerja dan fleksibiliti terhad. Jika anda tidak mengikut konvensyen rangka kerja, kod tersebut akan menjadi sukar untuk dikekalkan. Menggunakan perpustakaan lapuk boleh menyebabkan isu keselamatan dan keserasian. Penggunaan pakej yang berlebihan mengaburkan struktur kod. Mengabaikan pengendalian ralat membawa kepada tingkah laku yang tidak dijangka dan ranap sistem.
