
 Peranti teknologi
AI
Anjing robot Tencent berkembang: menguasai keupayaan membuat keputusan autonomi melalui pembelajaran mendalam
Peranti teknologi
AI
Anjing robot Tencent berkembang: menguasai keupayaan membuat keputusan autonomi melalui pembelajaran mendalam
Anjing robot Tencent berkembang: menguasai keupayaan membuat keputusan autonomi melalui pembelajaran mendalam

Pada 14 Jun, keupayaan Tencent Robotics membuat Keputusan telah dipertingkatkan dengan banyaknya.
Menjadikan anjing robot sebagai fleksibel dan stabil seperti manusia dan haiwan telah menjadi matlamat jangka panjang dalam bidang penyelidikan robotik Kemajuan berterusan teknologi pembelajaran mendalam membolehkan mesin menguasai kebolehan yang berkaitan melalui "pembelajaran" dan belajar menangani perubahan yang kompleks menjadi boleh dilaksanakan.
Memperkenalkan pra-latihan dan pembelajaran pengukuhan: menjadikan anjing robot lebih tangkas
Tencent Robotics Daripada belajar semula, anda boleh menggunakan semula pengetahuan pelbagai peringkat postur, persepsi alam sekitar dan perancangan strategik yang telah anda pelajari, dan membuat inferens tentang kes lain dari satu contoh untuk menghadapi persekitaran yang kompleks secara fleksibel


Siri pembelajaran ini dibahagikan kepada tiga peringkat:
Pada peringkat pertama, melalui sistem tangkapan gerakan yang biasa digunakan dalam teknologi permainan, penyelidik mengumpul data postur pergerakan anjing sebenar, termasuk berjalan, berlari, melompat, berdiri dan tindakan lain, dan menggunakan data ini untuk membina tiruan tugasan pembelajaran dalam simulator , dan kemudian abstrak dan mampatkan maklumat dalam data ini ke dalam model rangkaian saraf yang mendalam. Model-model ini bukan sahaja boleh merangkumi maklumat postur pergerakan haiwan dengan tepat, tetapi juga mempunyai kebolehtafsiran yang tinggi.
Tencent Robotik Teknologi dan data ini memainkan peranan tambahan tertentu dalam latihan ejen berasaskan simulasi fizikal dan penggunaan strategi robot dunia sebenar.
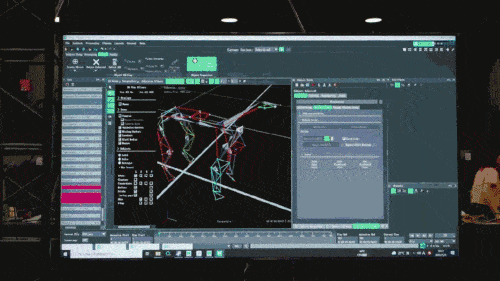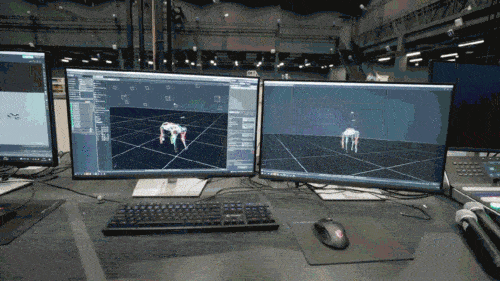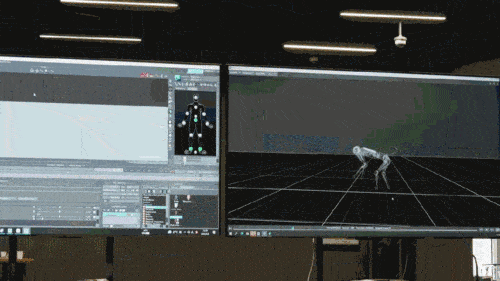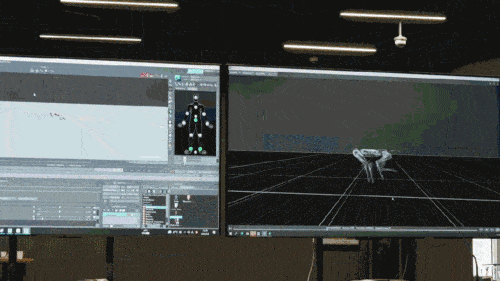
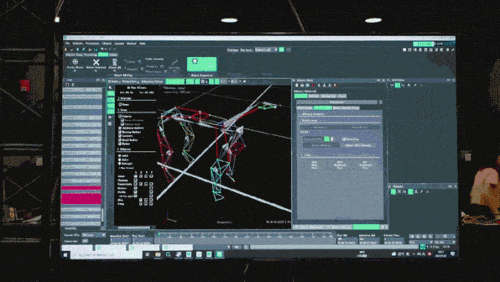

Model rangkaian saraf hanya menerima maklumat proprioseptif anjing robot (seperti status motor) sebagai input dan dilatih dalam cara pembelajaran tiruan. Dalam langkah seterusnya, model ini menggabungkan data deria dari persekitaran sekeliling, seperti menggunakan sensor lain untuk mengesan halangan di bawah kaki.
Pada peringkat kedua, parameter rangkaian tambahan digunakan untuk menyambung postur pintar anjing robot yang dikuasai pada peringkat pertama dengan persepsi luaran, supaya anjing robot boleh bertindak balas terhadap persekitaran luaran melalui postur pintar yang telah dipelajarinya. Apabila anjing robot menyesuaikan diri dengan pelbagai persekitaran yang kompleks, pengetahuan yang menghubungkan postur pintar dengan persepsi luaran juga akan diperkukuh dan disimpan dalam struktur rangkaian saraf.



Pada peringkat ketiga, menggunakan rangkaian saraf yang diperolehi dalam dua peringkat pra-latihan di atas, anjing robot mempunyai prasyarat dan peluang untuk menumpukan pada menyelesaikan masalah pembelajaran dasar peringkat atas, dan akhirnya mempunyai keupayaan untuk menyelesaikan kompleks tugas hujung ke hujung. Dalam fasa ketiga, rangkaian tambahan akan ditambah untuk mengumpul data yang berkaitan dengan tugas yang kompleks, seperti mendapatkan maklumat tentang lawan dan bendera dalam permainan. Di samping itu, dengan menganalisis semua maklumat secara komprehensif, rangkaian saraf yang bertanggungjawab untuk pembelajaran strategi akan mempelajari strategi peringkat tinggi untuk tugas itu, seperti arah mana untuk dijalankan, meramalkan tingkah laku lawan untuk memutuskan sama ada untuk meneruskan mengejar, dsb.
Ilmu yang dipelajari pada setiap peringkat di atas boleh dikembangkan dan diselaraskan tanpa pembelajaran semula, jadi ia boleh terus terkumpul dan dipelajari secara berterusan.
Pertandingan Mengejar Halangan Anjing Robot: Memiliki keupayaan autonomi membuat keputusan dan mengawal
Untuk menguji kemahiran baharu yang diperoleh oleh Max ini, penyelidik telah diilhamkan oleh permainan mengejar halangan "World Chase Tag" dan mereka bentuk permainan mengejar halangan dua anjing. World Chase Tag ialah organisasi mengejar halangan kompetitif yang diasaskan di United Kingdom pada 2014. Ia diseragamkan daripada permainan mengejar kanak-kanak rakyat. Secara umumnya, setiap pusingan pertandingan mengejar halangan melibatkan dua orang atlet bersaing antara satu sama lain Seorang pengejar (dipanggil penyerang) dan seorang lagi pengelak (dipanggil pemain pertahanan apabila atlet bertanding sepanjang keseluruhan pasukan akan menerima satu mata apabila mereka berjaya mengelak lawan mereka (iaitu tiada sentuhan berlaku) semasa pusingan mengejar (iaitu 20 saat). Pasukan yang mendapat mata terbanyak dalam bilangan pusingan mengejar yang telah ditetapkan memenangi permainan.
Saiz padang pertandingan mengejar halangan anjing robot ialah 4.5 meter x 4.5 meter, dengan beberapa halangan bertaburan di atasnya. Pada permulaan permainan, dua anjing robot MAX akan diletakkan di lokasi rawak di lapangan, dan seekor anjing robot akan secara rawak diberikan peranan sebagai pengejar dan yang lain sebagai pengelak Pada masa yang sama, bendera akan diletakkan di lokasi rawak di lapangan.
Matlamat pengelak adalah untuk mendekati bendera yang mungkin tanpa ditangkap oleh pengejar. Tugas pengejar adalah untuk menangkap pengelak. Jika pengelak berjaya menyentuh bendera sebelum ditangkap, peranan kedua-dua anjing robot akan bertukar serta-merta, dan bendera akan muncul semula di lokasi rawak yang lain. Permainan berakhir apabila pengelak ditangkap oleh pengejar semasa dan anjing robot yang memainkan peranan pengejar menang. Dalam semua permainan, purata kelajuan hadapan dua anjing robot dihadkan kepada 0.5m/s.
Daripada permainan ini, berdasarkan model pra-latihan, anjing robot itu sudah mempunyai keupayaan penaakulan dan membuat keputusan tertentu melalui pembelajaran pengukuhan yang mendalam:
Sebagai contoh, apabila pengejar menyedari bahawa ia tidak lagi dapat mengejar pengelak sebelum ia menyentuh bendera, pengejar akan melepaskan pengejaran dan sebaliknya mengembara jauh dari pengelak untuk menunggu langkah penting seterusnya. Bendera set muncul.
Selain itu, apabila pengejar hendak menangkap pengelak pada saat akhir, ia suka melompat dan membuat aksi "menerkam" ke arah pengelak, yang hampir sama dengan tingkah laku haiwan ketika menangkap mangsa, atau apabila pengelak hendak menyentuh bendera akan mempamerkan tingkah laku yang sama pada masa-masa tertentu. Ini semua adalah langkah pecutan proaktif yang diambil oleh anjing robot untuk memastikan kemenangannya.
Menurut laporan, semua strategi kawalan anjing robot dalam permainan adalah strategi rangkaian saraf Ia dipelajari dalam simulasi dan melalui pemindahan pukulan sifar (pemindahan pelarasan sifar), membolehkan rangkaian saraf mensimulasikan kaedah penaakulan manusia untuk mengenal pasti. jangan sekali-kali Lihat perkara baharu dan gunakan pengetahuan ini kepada anjing robot sebenar. Sebagai contoh, seperti yang ditunjukkan dalam rajah di bawah, pengetahuan untuk mengelakkan halangan yang dipelajari oleh anjing robot dalam model pra-latihan digunakan dalam permainan, walaupun adegan dengan halangan tidak dilatih dalam dunia maya Chase Tag Game ( hanya di dunia maya Selepas latihan dalam adegan permainan di atas tanah rata), anjing robot itu juga boleh berjaya menyelesaikan tugas itu.
Teknologi Pembelajaran Robotik Tencent diperkenalkan ke dalam bidang robot untuk meningkatkan keupayaan kawalan robot dan menjadikannya lebih fleksibel Ini juga meletakkan asas yang kukuh untuk robot memasuki kehidupan sebenar dan berkhidmat kepada manusia.
Atas ialah kandungan terperinci Anjing robot Tencent berkembang: menguasai keupayaan membuat keputusan autonomi melalui pembelajaran mendalam. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Apl model besar Tencent Yuanbao berada dalam talian! Hunyuan dinaik taraf untuk mencipta pembantu AI serba boleh yang boleh dibawa ke mana-mana
Jun 09, 2024 pm 10:38 PM
Apl model besar Tencent Yuanbao berada dalam talian! Hunyuan dinaik taraf untuk mencipta pembantu AI serba boleh yang boleh dibawa ke mana-mana
Jun 09, 2024 pm 10:38 PM
Pada 30 Mei, Tencent mengumumkan peningkatan menyeluruh model Hunyuannya Apl "Tencent Yuanbao" berdasarkan model Hunyuan telah dilancarkan secara rasmi dan boleh dimuat turun dari kedai aplikasi Apple dan Android. Berbanding dengan versi applet Hunyuan dalam peringkat ujian sebelumnya, Tencent Yuanbao menyediakan keupayaan teras seperti carian AI, ringkasan AI, dan penulisan AI untuk senario kecekapan kerja untuk senario kehidupan harian, permainan Yuanbao juga lebih kaya dan menyediakan pelbagai ciri , dan kaedah permainan baharu seperti mencipta ejen peribadi ditambah. "Tencent tidak akan berusaha untuk menjadi yang pertama membuat model besar, Liu Yuhong, naib presiden Tencent Cloud dan orang yang bertanggungjawab bagi model besar Tencent Hunyuan, berkata: "Pada tahun lalu, kami terus mempromosikan keupayaan untuk Model besar Tencent Hunyuan Dalam teknologi Poland yang kaya dan besar dalam senario perniagaan sambil mendapatkan cerapan tentang keperluan sebenar pengguna
 Di luar ORB-SLAM3! SL-SLAM: Adegan bertekstur lemah ringan, kegelisahan teruk dan lemah semuanya dikendalikan
May 30, 2024 am 09:35 AM
Di luar ORB-SLAM3! SL-SLAM: Adegan bertekstur lemah ringan, kegelisahan teruk dan lemah semuanya dikendalikan
May 30, 2024 am 09:35 AM
Ditulis sebelum ini, hari ini kita membincangkan bagaimana teknologi pembelajaran mendalam boleh meningkatkan prestasi SLAM berasaskan penglihatan (penyetempatan dan pemetaan serentak) dalam persekitaran yang kompleks. Dengan menggabungkan kaedah pengekstrakan ciri dalam dan pemadanan kedalaman, di sini kami memperkenalkan sistem SLAM visual hibrid serba boleh yang direka untuk meningkatkan penyesuaian dalam senario yang mencabar seperti keadaan cahaya malap, pencahayaan dinamik, kawasan bertekstur lemah dan seks yang teruk. Sistem kami menyokong berbilang mod, termasuk konfigurasi monokular, stereo, monokular-inersia dan stereo-inersia lanjutan. Selain itu, ia juga menganalisis cara menggabungkan SLAM visual dengan kaedah pembelajaran mendalam untuk memberi inspirasi kepada penyelidikan lain. Melalui percubaan yang meluas pada set data awam dan data sampel sendiri, kami menunjukkan keunggulan SL-SLAM dari segi ketepatan kedudukan dan keteguhan penjejakan.
 Fahami dalam satu artikel: kaitan dan perbezaan antara AI, pembelajaran mesin dan pembelajaran mendalam
Mar 02, 2024 am 11:19 AM
Fahami dalam satu artikel: kaitan dan perbezaan antara AI, pembelajaran mesin dan pembelajaran mendalam
Mar 02, 2024 am 11:19 AM
Dalam gelombang perubahan teknologi yang pesat hari ini, Kecerdasan Buatan (AI), Pembelajaran Mesin (ML) dan Pembelajaran Dalam (DL) adalah seperti bintang terang, menerajui gelombang baharu teknologi maklumat. Ketiga-tiga perkataan ini sering muncul dalam pelbagai perbincangan dan aplikasi praktikal yang canggih, tetapi bagi kebanyakan peneroka yang baru dalam bidang ini, makna khusus dan hubungan dalaman mereka mungkin masih diselubungi misteri. Jadi mari kita lihat gambar ini dahulu. Dapat dilihat bahawa terdapat korelasi rapat dan hubungan progresif antara pembelajaran mendalam, pembelajaran mesin dan kecerdasan buatan. Pembelajaran mendalam ialah bidang khusus pembelajaran mesin dan pembelajaran mesin
 Super kuat! 10 algoritma pembelajaran mendalam teratas!
Mar 15, 2024 pm 03:46 PM
Super kuat! 10 algoritma pembelajaran mendalam teratas!
Mar 15, 2024 pm 03:46 PM
Hampir 20 tahun telah berlalu sejak konsep pembelajaran mendalam dicadangkan pada tahun 2006. Pembelajaran mendalam, sebagai revolusi dalam bidang kecerdasan buatan, telah melahirkan banyak algoritma yang berpengaruh. Jadi, pada pendapat anda, apakah 10 algoritma teratas untuk pembelajaran mendalam? Berikut adalah algoritma teratas untuk pembelajaran mendalam pada pendapat saya Mereka semua menduduki kedudukan penting dari segi inovasi, nilai aplikasi dan pengaruh. 1. Latar belakang rangkaian saraf dalam (DNN): Rangkaian saraf dalam (DNN), juga dipanggil perceptron berbilang lapisan, adalah algoritma pembelajaran mendalam yang paling biasa Apabila ia mula-mula dicipta, ia dipersoalkan kerana kesesakan kuasa pengkomputeran tahun, kuasa pengkomputeran, Kejayaan datang dengan letupan data. DNN ialah model rangkaian saraf yang mengandungi berbilang lapisan tersembunyi. Dalam model ini, setiap lapisan menghantar input ke lapisan seterusnya dan
 Kemajuan pengoptimuman memori versi seni bina Tencent QQ NT diumumkan, adegan sembang dikawal dalam masa 300M
Mar 05, 2024 pm 03:52 PM
Kemajuan pengoptimuman memori versi seni bina Tencent QQ NT diumumkan, adegan sembang dikawal dalam masa 300M
Mar 05, 2024 pm 03:52 PM
Difahamkan bahawa klien desktop Tencent QQ telah melalui beberapa siri pembaharuan drastik. Sebagai tindak balas kepada isu pengguna seperti penggunaan memori yang tinggi, pakej pemasangan yang besar dan permulaan yang perlahan, pasukan teknikal QQ telah membuat pengoptimuman khas pada memori dan telah membuat kemajuan secara berperingkat. Baru-baru ini, pasukan teknikal QQ menerbitkan artikel pengenalan pada platform InfoQ, berkongsi kemajuan berperingkatnya dalam pengoptimuman khas memori. Menurut laporan, cabaran memori versi baharu QQ dicerminkan terutamanya dalam empat aspek berikut: Bentuk produk: Ia terdiri daripada panel besar yang kompleks (100+ modul dengan kerumitan yang berbeza-beza) dan satu siri tetingkap berfungsi bebas. Terdapat koresponden satu-dengan-satu antara tetingkap dan proses pemaparan Bilangan proses tetingkap sangat mempengaruhi penggunaan memori Elektron. Untuk panel besar yang kompleks itu, apabila tiada
 Tencent Photon H Studio sedang mengambil pekerja di Hangzhou dan merancang untuk membuat RPG dunia terbuka 3A
Feb 05, 2024 pm 01:45 PM
Tencent Photon H Studio sedang mengambil pekerja di Hangzhou dan merancang untuk membuat RPG dunia terbuka 3A
Feb 05, 2024 pm 01:45 PM
Baru-baru ini, Tencent Interactive Entertainment Recruitment mengeluarkan maklumat pengambilan, menunjukkan bahawa Photon H Studio komited untuk membangunkan projek RPG dunia terbuka peringkat AAA yang kaya kandungan. Jawatan pengambilan hangat meliputi pelbagai bidang seperti jurutera UE5, bahagian belakang, reka bentuk tahap, reka bentuk adegan aksi, pemodelan watak, kesan khas dan pengedaran, dll. Sasaran lokasi kerja jawatan ini adalah di Hangzhou, di mana NetEase beribu pejabat.
 AlphaFold 3 dilancarkan, meramalkan secara menyeluruh interaksi dan struktur protein dan semua molekul hidupan, dengan ketepatan yang jauh lebih tinggi berbanding sebelum ini
Jul 16, 2024 am 12:08 AM
AlphaFold 3 dilancarkan, meramalkan secara menyeluruh interaksi dan struktur protein dan semua molekul hidupan, dengan ketepatan yang jauh lebih tinggi berbanding sebelum ini
Jul 16, 2024 am 12:08 AM
Editor |. Kulit Lobak Sejak pengeluaran AlphaFold2 yang berkuasa pada tahun 2021, saintis telah menggunakan model ramalan struktur protein untuk memetakan pelbagai struktur protein dalam sel, menemui ubat dan melukis "peta kosmik" setiap interaksi protein yang diketahui. Baru-baru ini, Google DeepMind mengeluarkan model AlphaFold3, yang boleh melakukan ramalan struktur bersama untuk kompleks termasuk protein, asid nukleik, molekul kecil, ion dan sisa yang diubah suai. Ketepatan AlphaFold3 telah dipertingkatkan dengan ketara berbanding dengan banyak alat khusus pada masa lalu (interaksi protein-ligan, interaksi asid protein-nukleik, ramalan antibodi-antigen). Ini menunjukkan bahawa dalam satu rangka kerja pembelajaran mendalam yang bersatu, adalah mungkin untuk dicapai
 Pemilik atas telah mula bermain-main dengan sumber terbuka Tencent 'AniPortrait' untuk membenarkan foto menyanyi dan bercakap.
Apr 07, 2024 am 09:01 AM
Pemilik atas telah mula bermain-main dengan sumber terbuka Tencent 'AniPortrait' untuk membenarkan foto menyanyi dan bercakap.
Apr 07, 2024 am 09:01 AM
Model AniPortrait adalah sumber terbuka dan boleh dimainkan secara bebas. "Alat produktiviti baharu untuk Xiaopozhan Ghost Zone Baru-baru ini, projek baharu yang dikeluarkan oleh Tencent Open Source menerima penilaian sedemikian di Twitter. Projek ini ialah AniPortrait, yang menjana potret animasi berkualiti tinggi berdasarkan audio dan imej rujukan. Tanpa berlengah lagi, mari kita lihat demo yang mungkin diberi amaran oleh surat peguam: Imej anime juga boleh bercakap dengan mudah: Projek itu telah menerima pujian meluas selepas hanya beberapa hari sejak ia dilancarkan: bilangan Bintang GitHub telah melebihi 2,800. Mari kita lihat inovasi AniPortrait. Tajuk kertas: AniPortrait:Sintesis Dipacu Audio
