

Caching set data terhad dalam teknologi caching Java

Memandangkan kerumitan aplikasi moden terus meningkat, begitu juga permintaan terhadap pemprosesan data dan ketersediaan. Untuk menyelesaikan masalah ini, aplikasi teknologi caching secara beransur-ansur telah digunakan secara meluas.
Dalam teknologi caching Java, caching set data terhad ialah senario yang sangat biasa. Caching set data terhad biasanya bermakna bahawa beberapa set data (seperti set hasil pertanyaan pangkalan data) dicache dalam memori untuk meningkatkan kelajuan akses dan responsif data, dan saiz set data cache juga terhad kepada julat tertentu Apabila saiz cache dicapai Pada had, beberapa set data cache akan dihapuskan mengikut strategi tertentu untuk memberi ruang kepada set data baharu.
Mari bincangkan cara melaksanakan caching set data terhad dalam teknologi caching Java.
- Pemilihan struktur data cache
Dalam teknologi cache Java, terdapat dua struktur data cache utama: jadual cincang dan pepohon merah-hitam.
Ciri jadual cincang adalah untuk menyebarkan data yang disimpan melalui fungsi cincang, untuk mencapai tujuan mencari dan mengakses data dengan cepat. Memandangkan kelajuan carian jadual cincang adalah sangat pantas, ia digunakan secara meluas dalam caching senario set data.
Sebaliknya, ciri pokok merah-hitam adalah untuk mengisih dan mengimbangi data secara berterusan untuk memastikan ia dapat mengekalkan kelajuan carian yang pantas dalam kes yang paling teruk. Walaupun pokok merah-hitam tidak sepantas jadual cincang, ia mempunyai kesejagatan dan kestabilan yang lebih baik, dan lebih fleksibel untuk digunakan.
Mengikut keperluan yang berbeza, kami boleh memilih struktur data yang sesuai sebagai struktur storan untuk data cache. Jika kita perlu mencari data dengan cepat, adalah lebih sesuai untuk memilih jadual cincangan jika kita perlu menyokong carian julat, pengisihan dan operasi lain, lebih sesuai untuk memilih pokok merah-hitam.
- Pemilihan strategi cache
Strategi cache merujuk kepada cara untuk menghapuskan beberapa set data cache selepas cache mencapai had saiz tertentu untuk meninggalkan ruang yang mencukupi untuk menyimpan data baharu.
Terdapat tiga strategi caching biasa: masuk dahulu keluar dahulu (FIFO), paling kurang digunakan baru-baru ini (LRU) dan paling kurang digunakan baru-baru ini (LFU).
- Strategi first-in, first-out (FIFO) ialah strategi yang agak mudah, iaitu set data terawal yang memasuki cache dihapuskan dahulu. Walau bagaimanapun, strategi ini terdedah kepada situasi di mana entri data baharu mengatasi entri data lama.
- Strategi yang paling kurang digunakan (LRU) ialah strategi yang biasa digunakan. Strategi ini memilih set data yang paling kurang digunakan baru-baru ini untuk dihapuskan. Ini memastikan set data dalam cache kerap digunakan, dan bukannya beberapa set data yang jarang digunakan.
- Strategi paling kurang digunakan (LFU) ialah strategi untuk penyingkiran berdasarkan bilangan kali set data digunakan. Strategi ini memilih set data yang paling kurang kerap digunakan untuk penyingkiran. Strategi ini biasanya memerlukan merekodkan bilangan kali setiap set data digunakan, jadi ia agak rumit untuk dilaksanakan.
Mengikut senario dan keperluan aplikasi yang berbeza, anda boleh memilih strategi caching yang sesuai untuk pelaksanaan.
- Mekanisme pemuatan automatik
Apabila set data untuk disoal tidak wujud dalam cache, bagaimanakah set data harus dimuatkan dan disimpan? Ini memerlukan pelaksanaan mekanisme pemuatan automatik.
Mekanisme pemuatan automatik boleh memuatkan set data secara automatik dengan parameter pratetapan, pemuatan tak segerak dan storan cache. Dengan cara ini, apabila set data diperlukan pada masa akan datang, ia boleh diperolehi terus daripada cache untuk mempercepatkan capaian data.
Perlu diambil perhatian bahawa apabila melakukan pemuatan automatik, anda perlu menguasai keseimbangan antara parameter pemuatan dan saiz cache untuk mengelak daripada membebankan set data, mengakibatkan saiz cache yang berlebihan atau memuatkan set data yang terlalu sedikit, mengakibatkan dalam kadar hit yang berlebihan.
- Kawalan Concurrency
Kawalan Concurrency juga merupakan salah satu isu penting dalam teknologi caching. Jika berbilang benang mengendalikan cache pada masa yang sama, masalah baca dan tulis serentak mungkin berlaku, mengakibatkan ketidakkonsistenan data.
Untuk menyelesaikan masalah konkurensi, pelbagai kaedah boleh digunakan, seperti mekanisme kunci, mekanisme CAS (Banding Dan Tukar), dll.
Mekanisme kunci ialah kaedah yang agak biasa, dan anda boleh menggunakan kunci baca-tulis, kunci pesimis, kunci optimis, dsb. Ciri kunci baca-tulis ialah ia menyokong bacaan serentak, tetapi hanya boleh menulis secara bersendirian ciri kunci pesimis ialah secara lalai, ia dipercayai terdapat masalah dengan konkurensi dan perlu dikunci; kunci adalah bahawa secara lalai, ia dipercayai bahawa tidak ada masalah dengan concurrency Tidak dikunci.
Mengikut situasi konkurensi sebenar dan senario aplikasi, anda boleh memilih kaedah kawalan serentak yang sesuai untuk memastikan ketepatan dan ketersediaan cache.
Ringkasnya, caching set data terhad dalam teknologi caching Java memerlukan pertimbangan dari banyak aspek seperti pemilihan struktur data cache, pemilihan strategi caching, mekanisme pemuatan automatik dan kawalan konkurensi. Hanya dengan menggunakan kaedah pelaksanaan yang sesuai berdasarkan keperluan sebenar, cache boleh memainkan peranan maksimumnya dan meningkatkan prestasi keseluruhan dan ketersediaan aplikasi.
Atas ialah kandungan terperinci Caching set data terhad dalam teknologi caching Java. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 Klasifikasi imej dengan pembelajaran beberapa tangkapan menggunakan PyTorch
Apr 09, 2023 am 10:51 AM
Klasifikasi imej dengan pembelajaran beberapa tangkapan menggunakan PyTorch
Apr 09, 2023 am 10:51 AM
Dalam beberapa tahun kebelakangan ini, model berasaskan pembelajaran mendalam telah menunjukkan prestasi yang baik dalam tugas seperti pengesanan objek dan pengecaman imej. Mengenai set data klasifikasi imej yang mencabar seperti ImageNet, yang mengandungi 1,000 klasifikasi objek berbeza, sesetengah model kini melebihi tahap manusia. Tetapi model ini bergantung pada proses latihan yang diawasi, mereka dipengaruhi dengan ketara oleh ketersediaan data latihan berlabel, dan kelas yang model dapat mengesan adalah terhad kepada kelas yang dilatih. Memandangkan imej berlabel tidak mencukupi untuk semua kelas semasa latihan, model ini mungkin kurang berguna dalam tetapan dunia sebenar. Dan kami mahu model itu dapat mengenali kelas yang tidak pernah dilihat semasa latihan, kerana hampir mustahil untuk melatih imej semua objek berpotensi. Kami akan belajar daripada beberapa sampel
 Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Untuk menyediakan tanda aras dan sistem penilaian menjawab soalan saintifik dan kompleks baharu untuk model besar, UNSW, Argonne, University of Chicago dan institusi lain bersama-sama melancarkan rangka kerja SciQAG
Jul 25, 2024 am 06:42 AM
Editor |ScienceAI Question Answering (QA) set data memainkan peranan penting dalam mempromosikan penyelidikan pemprosesan bahasa semula jadi (NLP). Set data QA berkualiti tinggi bukan sahaja boleh digunakan untuk memperhalusi model, tetapi juga menilai dengan berkesan keupayaan model bahasa besar (LLM), terutamanya keupayaan untuk memahami dan menaakul tentang pengetahuan saintifik. Walaupun pada masa ini terdapat banyak set data QA saintifik yang meliputi bidang perubatan, kimia, biologi dan bidang lain, set data ini masih mempunyai beberapa kekurangan. Pertama, borang data adalah agak mudah, kebanyakannya adalah soalan aneka pilihan. Ia mudah dinilai, tetapi mengehadkan julat pemilihan jawapan model dan tidak dapat menguji sepenuhnya keupayaan model untuk menjawab soalan saintifik. Sebaliknya, Soal Jawab terbuka
 Melaksanakan OpenAI CLIP pada set data tersuai
Sep 14, 2023 am 11:57 AM
Melaksanakan OpenAI CLIP pada set data tersuai
Sep 14, 2023 am 11:57 AM
Pada Januari 2021, OpenAI mengumumkan dua model baharu: DALL-E dan CLIP. Kedua-dua model ialah model multimodal yang menyambungkan teks dan imej dalam beberapa cara. Nama penuh CLIP ialah Pra-latihan Bahasa-Imej Kontrastif (ContrastiveLanguage-Image-Pre-training), yang merupakan kaedah pra-latihan berdasarkan pasangan imej teks yang berbeza. Mengapa memperkenalkan CLIP? Kerana StableDiffusion yang popular pada masa ini bukanlah satu model, tetapi terdiri daripada berbilang model. Salah satu komponen utama ialah pengekod teks, yang digunakan untuk mengekod input teks pengguna ini ialah pengekod teks CL dalam model CLIP.
 Video Google AI lagi hebat! VideoPrism, pengekod visual universal semua-dalam-satu, menyegarkan 30 ciri prestasi SOTA
Feb 26, 2024 am 09:58 AM
Video Google AI lagi hebat! VideoPrism, pengekod visual universal semua-dalam-satu, menyegarkan 30 ciri prestasi SOTA
Feb 26, 2024 am 09:58 AM
Selepas model video AI Sora menjadi popular, syarikat utama seperti Meta dan Google telah mengetepikan untuk melakukan penyelidikan dan mengejar OpenAI. Baru-baru ini, penyelidik dari pasukan Google mencadangkan pengekod video universal - VideoPrism. Ia boleh mengendalikan pelbagai tugas pemahaman video melalui satu model beku. Alamat kertas imej: https://arxiv.org/pdf/2402.13217.pdf Contohnya, VideoPrism boleh mengelaskan dan mengesan orang yang meniup lilin dalam video di bawah. Pengambilan teks video imej, berdasarkan kandungan teks, kandungan yang sepadan dalam video boleh diambil semula. Untuk contoh lain, huraikan video di bawah - seorang gadis kecil sedang bermain dengan blok bangunan. Soalan dan jawapan QA juga tersedia.
 Bagaimana untuk membahagikan set data dengan betul? Ringkasan tiga kaedah biasa
Apr 08, 2023 pm 06:51 PM
Bagaimana untuk membahagikan set data dengan betul? Ringkasan tiga kaedah biasa
Apr 08, 2023 pm 06:51 PM
Mengurai set data menjadi set latihan membantu kami memahami model, yang penting untuk cara model membuat generalisasi kepada data baharu yang tidak kelihatan. Sesuatu model mungkin tidak digeneralisasikan dengan baik kepada data baru yang tidak kelihatan jika ia terlalu dipasang. Oleh itu ramalan yang baik tidak boleh dibuat. Mempunyai strategi pengesahan yang sesuai ialah langkah pertama untuk berjaya mencipta ramalan yang baik dan menggunakan nilai perniagaan model AI Artikel ini telah menyusun beberapa strategi pemisahan data biasa. Pembahagian kereta api dan ujian mudah membahagikan set data kepada bahagian latihan dan pengesahan, dengan 80% latihan dan 20% pengesahan. Anda boleh melakukan ini menggunakan pensampelan rawak Scikit. Pertama, benih rawak perlu diperbaiki, jika tidak, pemisahan data yang sama tidak boleh dibandingkan dan hasilnya tidak boleh dihasilkan semula semasa penyahpepijatan. Jika set data
 Latihan selari PyTorch Contoh kod lengkap DistributedDataParallel
Apr 10, 2023 pm 08:51 PM
Latihan selari PyTorch Contoh kod lengkap DistributedDataParallel
Apr 10, 2023 pm 08:51 PM
Masalah melatih rangkaian neural dalam yang besar (DNN) menggunakan set data yang besar merupakan cabaran utama dalam bidang pembelajaran mendalam. Apabila saiz DNN dan set data meningkat, begitu juga keperluan pengiraan dan memori untuk melatih model ini. Ini menjadikannya sukar atau bahkan mustahil untuk melatih model ini pada satu mesin dengan sumber pengkomputeran yang terhad. Beberapa cabaran utama dalam melatih DNN besar menggunakan set data besar termasuk: Masa latihan yang panjang: Proses latihan boleh mengambil masa beberapa minggu atau bahkan beberapa bulan untuk disiapkan, bergantung pada kerumitan model dan saiz set data. Had memori: DNN yang besar mungkin memerlukan jumlah memori yang besar untuk menyimpan semua parameter model, kecerunan dan pengaktifan perantaraan semasa latihan. Ini boleh menyebabkan kesilapan ingatan dan mengehadkan apa yang boleh dilatih pada satu mesin.
 Mengira kos karbon bagi kecerdasan buatan
Apr 12, 2023 am 08:52 AM
Mengira kos karbon bagi kecerdasan buatan
Apr 12, 2023 am 08:52 AM
Jika anda sedang mencari topik yang menarik, Artificial Intelligence (AI) tidak akan mengecewakan anda. Kecerdasan buatan merangkumi satu set algoritma statistik yang kuat dan membengkokkan minda yang boleh bermain catur, mentafsir tulisan tangan yang ceroboh, memahami pertuturan, mengklasifikasikan imej satelit dan banyak lagi. Ketersediaan set data gergasi untuk melatih model pembelajaran mesin telah menjadi salah satu faktor utama dalam kejayaan kecerdasan buatan. Tetapi semua kerja pengiraan ini tidak percuma. Sesetengah pakar AI semakin bimbang tentang kesan alam sekitar yang dikaitkan dengan membina algoritma baharu, perdebatan yang telah mendorong idea baharu tentang cara membuat mesin belajar dengan lebih cekap untuk mengurangkan jejak karbon AI. Kembali ke Bumi Untuk mendapatkan butirannya, kita perlu terlebih dahulu mempertimbangkan beribu-ribu pusat data (bersebaran di seluruh dunia) yang mengendalikan permintaan pengkomputeran kami 24/7.
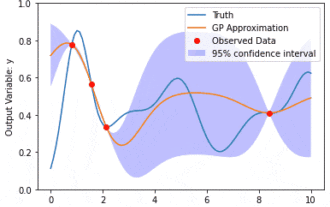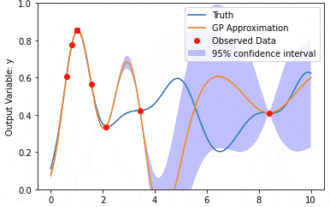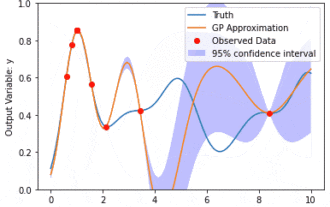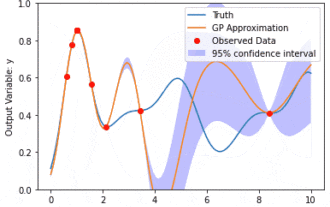 Pemodelan data menggunakan Kernel Model Gaussian Processes (KMGPs)
Jan 30, 2024 am 11:15 AM
Pemodelan data menggunakan Kernel Model Gaussian Processes (KMGPs)
Jan 30, 2024 am 11:15 AM
Proses Gaussian Model Kernel (KMGPs) ialah alat canggih untuk mengendalikan kerumitan pelbagai set data. Ia memanjangkan konsep proses Gaussian tradisional melalui fungsi kernel. Artikel ini akan membincangkan secara terperinci asas teori, aplikasi praktikal dan cabaran KMGP. Model kernel Proses Gaussian ialah lanjutan daripada proses Gaussian tradisional dan digunakan dalam pembelajaran mesin dan statistik. Sebelum memahami kmgp, anda perlu menguasai pengetahuan asas proses Gaussian, dan kemudian memahami peranan model kernel. Proses Gaussian (GP) ialah satu set pembolehubah rawak, bilangan pembolehubah terhingga yang diedarkan bersama dengan taburan Gaussian, dan digunakan untuk menentukan taburan kebarangkalian fungsi. Proses Gaussian biasanya digunakan dalam regresi dan tugas klasifikasi dalam pembelajaran mesin dan boleh digunakan untuk menyesuaikan taburan kebarangkalian data. Ciri penting proses Gaussian ialah keupayaan mereka untuk memberikan anggaran dan ramalan ketidakpastian
