

Kemiskinan menyediakan saya

. Jika kaedah pra-latihan ini wujud, permulaannya memerlukan kuasa pengkomputeran, data dan sumber manual yang sangat sedikit, atau malah hanya korpus asal seorang dan satu kad. Selepas pemprosesan data tanpa pengawasan dan pemindahan pra-latihan ke domain anda sendiri, anda boleh mendapatkan NLG sampel, NLG dan keupayaan penaakulan vektor Keupayaan mengingat semula perwakilan vektor lain Adakah anda berminat untuk mencubanya.


Sama ada anda ingin melakukan sesuatu perlu diputuskan dengan mengukur input dan output. Pra-latihan adalah masalah besar dan memerlukan beberapa prasyarat dan sumber, serta faedah jangkaan yang mencukupi sebelum ia boleh dilaksanakan. Syarat yang biasanya diperlukan ialah: pembinaan korpus yang mencukupi Secara umumnya, kualiti adalah lebih jarang daripada kuantiti, jadi kualiti korpus boleh dilonggarkan, tetapi kuantiti mesti mencukupi, kedua, terdapat rizab bakat yang sepadan perbandingan, , model kecil lebih mudah untuk dilatih dan mempunyai halangan yang lebih sedikit, manakala model besar akan menghadapi lebih banyak masalah adalah sumber pengkomputeran Menurut senario dan padanan bakat, ia adalah yang terbaik untuk mempunyai kad grafik memori besar. Faedah yang dibawa oleh pra-latihan juga sangat intuitif Pemindahan model secara langsung boleh membawa kesan penambahbaikan secara langsung berkaitan dengan pelaburan pra-latihan dan perbezaan domain .
Dalam senario kami, medan data sangat berbeza daripada medan umum, malah perbendaharaan kata perlu diganti dengan ketara, dan skala perniagaan adalah mencukupi. Jika tidak dilatih terlebih dahulu, model itu juga akan diperhalusi khusus untuk setiap tugas hiliran. Manfaat yang dijangkakan daripada pra-latihan adalah pasti. Korpus kita kurang kualiti, tetapi cukup kuantiti. Sumber kuasa pengkomputeran adalah sangat terhad dan boleh diberi pampasan dengan memadankan rizab bakat yang sepadan. Pada masa ini, syarat untuk pra-latihan telah pun dipenuhi. 
Gambar di bawah adalah paradigma baharu yang kami cadangkan Apabila berhijrah ke bidang kami untuk meneruskan pra-latihan, kami menggunakan tugas pemodelan bahasa bersama dan tugas pembelajaran perbandingan untuk menjadikan model output mempunyai NLU sampel sifar, NLG, dan perwakilan vektor, keupayaan ini dimodelkan dan boleh diakses atas permintaan. Dengan cara ini, terdapat lebih sedikit model yang perlu diselenggara, terutamanya apabila projek dimulakan, ia boleh digunakan secara langsung untuk penyelidikan Jika penalaan lebih lanjut diperlukan, jumlah data yang diperlukan juga sangat berkurangan. .
Matlamat pra-latihan termasuk pemodelan bahasa dan perwakilan kontrastif Fungsi kehilangan ialah Total Loss = LM Loss + α CL Loss Ia dilatih bersama dengan tugas pemodelan bahasa dan tugas perwakilan kontras, di mana α mewakili pekali berat. Pemodelan bahasa menggunakan model topeng, serupa dengan T5, yang hanya menyahkod bahagian topeng. Tugas perwakilan kontras adalah serupa dengan CLIP Dalam kumpulan, terdapat sepasang sampel positif latihan yang berkaitan dan sampel bukan negatif lain Bagi setiap pasangan sampel (i, I) i, terdapat sampel positif I, dan yang lain sampel adalah sampel negatif , menggunakan kehilangan rentas entropi simetri untuk memaksa perwakilan sampel positif menjadi rapat dan perwakilan sampel negatif berada jauh. Menggunakan penyahkodan T5 boleh memendekkan panjang penyahkodan. Perwakilan vektor bukan linear diletakkan di atas pengekod pemuatan kepala Satu ialah perwakilan vektor diperlukan untuk menjadi lebih pantas dalam senario, dan satu lagi ialah dua fungsi yang ditunjukkan bertindak jauh untuk mengelakkan konflik sasaran latihan. Jadi di sini datang soalan tugas Cloze adalah sangat biasa dan tidak memerlukan sampel Jadi bagaimana pasangan sampel yang serupa berasal? 
Sudah tentu, sebagai kaedah pra-latihan, pasangan sampel mesti dilombong oleh algoritma tanpa pengawasan. Biasanya, kaedah asas yang digunakan dalam bidang pencarian maklumat untuk melombong sampel positif ialah reverse cloze, yang melombong beberapa serpihan dalam dokumen dan menganggap bahawa ia adalah berkaitan. Di sini kami membahagikan dokumen kepada ayat dan kemudian menghitung pasangan ayat. Kami menggunakan subrentetan biasa terpanjang untuk menentukan sama ada dua ayat berkaitan. Seperti yang ditunjukkan dalam rajah, dua pasangan ayat positif dan negatif diambil Jika subrentetan sepunya terpanjang cukup panjang pada tahap tertentu, ia dinilai serupa, jika tidak, ia tidak serupa. Ambang dipilih oleh anda sendiri Contohnya, ayat yang panjang memerlukan tiga aksara Cina, dan lebih banyak huruf Inggeris diperlukan Ayat pendek boleh menjadi lebih santai.
Kami menggunakan korelasi sebagai pasangan sampel dan bukannya kesetaraan semantik kerana kedua-dua matlamat itu bercanggah. Seperti yang ditunjukkan dalam rajah di atas, maksud kucing menangkap tikus dan tikus menangkap kucing adalah bertentangan tetapi berkaitan. Carian senario kami tertumpu terutamanya pada perkaitan. Selain itu, korelasi adalah lebih luas daripada kesetaraan semantik, dan kesetaraan semantik lebih sesuai untuk penalaan halus berterusan berdasarkan korelasi.
Sesetengah ayat ditapis beberapa kali, dan sesetengah ayat tidak ditapis. Kami mengehadkan kekerapan ayat yang dipilih. Bagi ayat yang tidak berjaya, ia boleh disalin sebagai sampel positif, disambung ke dalam ayat yang dipilih, atau kloz terbalik boleh digunakan sebagai sampel positif.
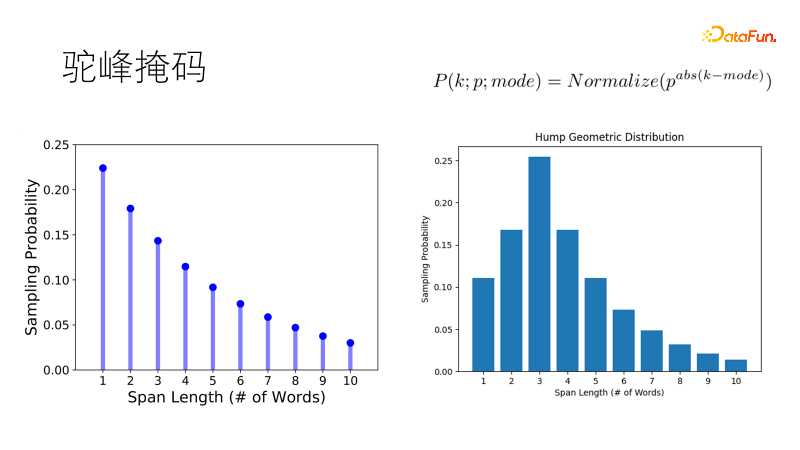
Kaedah penyamaran tradisional seperti SpanBert menggunakan taburan geometri untuk sampel panjang topeng mempunyai kebarangkalian tinggi dan topeng panjang mempunyai kebarangkalian yang rendah, dan sesuai untuk ayat yang panjang. Tetapi korpus kita berpecah-belah Apabila berhadapan dengan ayat pendek satu atau dua puluh perkataan, kecenderungan tradisional adalah menutup dua perkataan tunggal dan bukannya satu kata ganda, yang tidak memenuhi jangkaan kita. Jadi kami menambah baik taburan ini supaya ia mempunyai kebarangkalian tertinggi untuk mengambil sampel panjang optimum, dan kebarangkalian panjang lain secara beransur-ansur berkurangan, sama seperti bonggol unta, menjadi taburan geometri bonggol unta, yang lebih mantap dalam ayat pendek kami- senario yang kaya.
3. Keputusan eksperimen
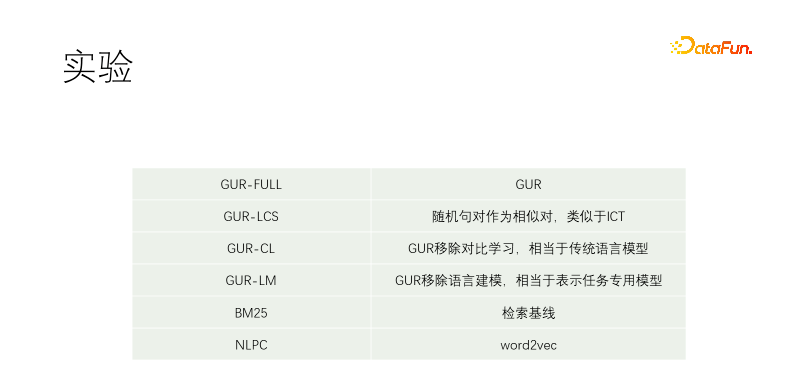
Kami menjalankan eksperimen terkawal. Termasuk GUR-FULL, yang menggunakan pemodelan bahasa dan perwakilan kontrastif vektor; pasangan sampel UR-LCS tidak ditapis oleh LCS tidak mempunyai pembelajaran perwakilan kontras, yang setara dengan model bahasa tradisional GUR-LM sahaja; pembelajaran perwakilan kontras, tanpa pembelajaran pemodelan bahasa, adalah setara dengan penalaan halus khusus untuk tugas hiliran NLPC ialah operator word2vec dalam Baidu.
Percubaan bermula dengan T5-kecil dan pra-latihan berterusan. Korpora latihan termasuk Wikipedia, Wikisource, CSL dan korpora kami sendiri. Korpus kami sendiri ditangkap dari perpustakaan bahan, dan kualitinya sangat buruk Bahagian kualiti terbaik ialah tajuk perpustakaan bahan. Oleh itu, apabila menggali sampel positif dalam dokumen lain, hampir mana-mana pasangan teks disaring, manakala dalam korpus kami, tajuk digunakan untuk memadankan setiap ayat teks. GUR-LCS belum dipilih oleh LCS Jika ia tidak dilakukan dengan cara ini, pasangan sampel akan menjadi terlalu buruk Jika ia dilakukan dengan cara ini, perbezaan dengan GUR-FULL akan menjadi lebih kecil.
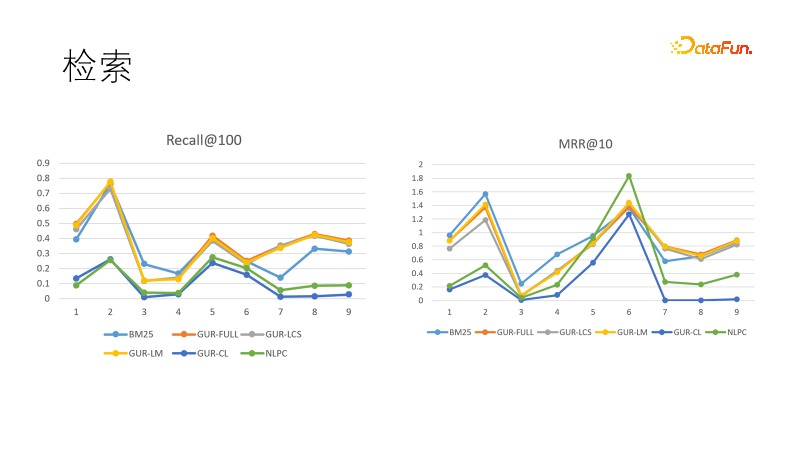
Kami menilai kesan perwakilan vektor model pada beberapa tugas mendapatkan semula. Gambar di sebelah kiri menunjukkan prestasi beberapa model dalam ingatan Kami mendapati bahawa model yang dipelajari melalui perwakilan vektor menunjukkan prestasi terbaik, mengatasi prestasi BM25. Kami juga membandingkan sasaran kedudukan, dan kali ini BM25 kembali untuk menang. Ini menunjukkan bahawa model padat mempunyai keupayaan generalisasi yang kuat dan model jarang mempunyai determinisme yang kuat, dan kedua-duanya boleh saling melengkapi. Malah, dalam tugas hiliran dalam bidang pencarian maklumat, model padat dan model jarang sering digunakan bersama.
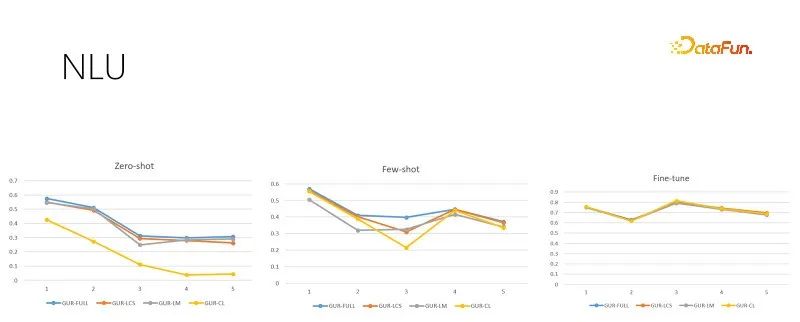
Gambar di atas adalah tugas penilaian NLU dengan saiz sampel latihan yang berbeza Setiap tugasan mempunyai berpuluh-puluh hingga ratusan kategori, dan skor ACC digunakan untuk menilai kesannya. Model GUR juga menukar label klasifikasi kepada vektor untuk mencari label terdekat bagi setiap ayat. Rajah di atas dari kiri ke kanan menunjukkan sampel sifar, sampel kecil dan penilaian penalaan halus yang mencukupi mengikut saiz sampel latihan yang semakin meningkat. Gambar di sebelah kanan ialah prestasi model selepas penalaan halus yang mencukupi, yang menunjukkan kesukaran setiap sub-tugas dan juga merupakan siling prestasi sampel sifar dan sampel kecil. Ia boleh dilihat bahawa model GUR boleh mencapai penaakulan sampel sifar dalam beberapa tugas klasifikasi dengan bergantung pada perwakilan vektor. Dan keupayaan sampel kecil model GUR adalah yang paling cemerlang.
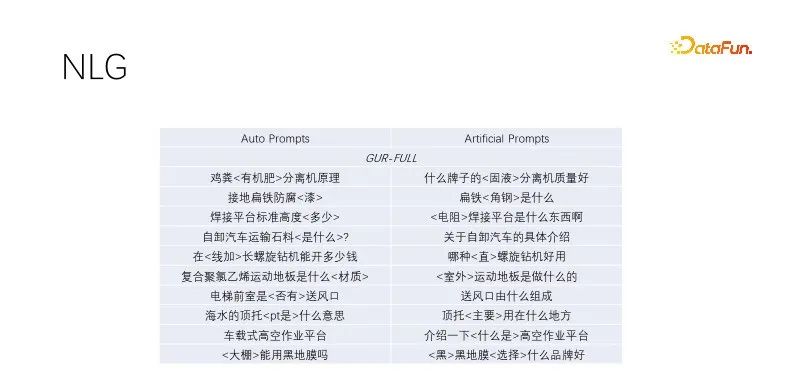
Ini ialah prestasi sampel sifar dalam NLG. Apabila kami melakukan penjanaan tajuk dan pengembangan pertanyaan, kami melombong tajuk dengan trafik berkualiti tinggi, mengekalkan kata kunci dan secara rawak menutup bukan kata kunci Model yang dilatih oleh pemodelan bahasa berprestasi baik. Kesan segera automatik ini serupa dengan kesan sasaran yang dibina secara manual, dengan kepelbagaian yang lebih luas dan mampu memenuhi pengeluaran besar-besaran. Beberapa model yang telah menjalani tugas pemodelan bahasa melakukan yang sama Rajah di atas menggunakan contoh model GUR.
4. Kesimpulan
Artikel ini mencadangkan paradigma pra-latihan baharu Eksperimen kawalan di atas menunjukkan bahawa latihan bersama tidak akan menyebabkan konflik matlamat. Apabila model GUR terus dilatih, ia boleh meningkatkan keupayaan perwakilan vektornya sambil mengekalkan keupayaan pemodelan bahasanya. Pra-latihan sekali, inferens dengan sifar sampel asal di mana-mana. Sesuai untuk pra-latihan kos rendah untuk jabatan perniagaan.

Pautan di atas merekodkan butiran latihan kami Untuk butiran rujukan, lihat petikan kertas itu. Saya berharap dapat memberikan sedikit sumbangan kepada pendemokrasian AI. Model besar dan kecil mempunyai senario aplikasi mereka sendiri Selain digunakan secara langsung untuk tugas hiliran, model GUR juga boleh digunakan bersama dengan model besar. Dalam perancangan, kami mula-mula menggunakan model kecil untuk pengecaman dan kemudian menggunakan model besar untuk mengarahkan tugasan Model besar juga boleh menghasilkan sampel untuk model kecil, dan model kecil GUR boleh menyediakan pengambilan vektor untuk model besar.
Model dalam kertas ialah model kecil yang dipilih untuk meneroka berbilang percubaan Secara praktikal, jika model yang lebih besar dipilih, keuntungan akan jelas. Penerokaan kami tidak mencukupi dan kerja lanjut diperlukan Jika anda bersedia, anda boleh menghubungi laohur@gmail.com dan berharap untuk membuat kemajuan bersama-sama dengan semua orang.
Atas ialah kandungan terperinci Kemiskinan menyediakan saya. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Pengenalan kepada lima kaedah pensampelan dalam tugas penjanaan bahasa semula jadi dan pelaksanaan kod Pytorch
Feb 20, 2024 am 08:50 AM
Pengenalan kepada lima kaedah pensampelan dalam tugas penjanaan bahasa semula jadi dan pelaksanaan kod Pytorch
Feb 20, 2024 am 08:50 AM
Dalam tugas penjanaan bahasa semula jadi, kaedah pensampelan ialah teknik untuk mendapatkan output teks daripada model generatif. Artikel ini akan membincangkan 5 kaedah biasa dan melaksanakannya menggunakan PyTorch. 1. GreedyDecoding Dalam penyahkodan tamak, model generatif meramalkan perkataan urutan keluaran berdasarkan urutan input masa langkah demi masa. Pada setiap langkah masa, model mengira taburan kebarangkalian bersyarat bagi setiap perkataan, dan kemudian memilih perkataan dengan kebarangkalian bersyarat tertinggi sebagai output langkah masa semasa. Perkataan ini menjadi input kepada langkah masa seterusnya, dan proses penjanaan diteruskan sehingga beberapa syarat penamatan dipenuhi, seperti urutan panjang tertentu atau penanda akhir khas. Ciri GreedyDecoding ialah setiap kali kebarangkalian bersyarat semasa adalah yang terbaik
 Bagaimana untuk melakukan penjanaan bahasa semula jadi asas menggunakan PHP
Jun 22, 2023 am 11:05 AM
Bagaimana untuk melakukan penjanaan bahasa semula jadi asas menggunakan PHP
Jun 22, 2023 am 11:05 AM
Penjanaan bahasa semula jadi ialah teknologi kecerdasan buatan yang menukar data kepada teks bahasa semula jadi. Dalam era data besar hari ini, semakin banyak perniagaan perlu menggambarkan atau mempersembahkan data kepada pengguna, dan penjanaan bahasa semula jadi ialah kaedah yang sangat berkesan. PHP ialah bahasa skrip sebelah pelayan yang sangat popular yang boleh digunakan untuk membangunkan aplikasi web. Artikel ini akan memperkenalkan secara ringkas cara menggunakan PHP untuk penjanaan bahasa semula jadi asas. Memperkenalkan perpustakaan penjanaan bahasa semula jadi Pustaka fungsi yang disertakan dengan PHP tidak termasuk fungsi yang diperlukan untuk penjanaan bahasa semula jadi, jadi
 Kejuruteraan Trafik menggandakan ketepatan penjanaan kod: daripada 19% kepada 44%
Feb 05, 2024 am 09:15 AM
Kejuruteraan Trafik menggandakan ketepatan penjanaan kod: daripada 19% kepada 44%
Feb 05, 2024 am 09:15 AM
Pengarang kertas baharu mencadangkan cara untuk "meningkatkan" penjanaan kod. Penjanaan kod ialah keupayaan yang semakin penting dalam kecerdasan buatan. Ia secara automatik menjana kod komputer berdasarkan penerangan bahasa semula jadi dengan melatih model pembelajaran mesin. Teknologi ini mempunyai prospek aplikasi yang luas dan boleh mengubah spesifikasi perisian kepada kod yang boleh digunakan, mengautomasikan pembangunan bahagian belakang dan membantu pengaturcara manusia untuk meningkatkan kecekapan kerja. Walau bagaimanapun, menjana kod berkualiti tinggi masih mencabar untuk sistem AI, berbanding dengan tugas bahasa seperti terjemahan atau ringkasan. Kod mesti mematuhi sintaks bahasa pengaturcaraan sasaran dengan tepat, mengendalikan kes tepi dan input yang tidak dijangka dengan anggun, dan mengendalikan banyak butiran kecil perihalan masalah dengan tepat. Malah pepijat kecil yang mungkin kelihatan tidak berbahaya di kawasan lain boleh mengganggu sepenuhnya kefungsian program, menyebabkan
 Membina penjana teks menggunakan rantai Markov
Apr 09, 2023 pm 10:11 PM
Membina penjana teks menggunakan rantai Markov
Apr 09, 2023 pm 10:11 PM
Dalam artikel ini, kami akan memperkenalkan projek pembelajaran mesin popular yang dipanggil penjana teks Anda akan belajar cara membina penjana teks dan belajar cara melaksanakan rantaian Markov untuk mencapai model ramalan yang lebih pantas. Pengenalan kepada Penjana Teks Penjanaan teks popular di seluruh industri, terutamanya dalam mudah alih, apl dan sains data. Malah akhbar menggunakan penjanaan teks untuk membantu proses penulisan. Dalam kehidupan seharian, kami akan berhubung dengan beberapa teknologi penjanaan teks, cadangan carian, Smart Compose, dan robot sembang adalah semua contoh aplikasi Artikel ini akan menggunakan rantai Markov untuk membina penjana teks. Ini akan menjadi model berasaskan aksara yang mengambil aksara sebelumnya bagi rantai dan menjana huruf seterusnya dalam jujukan. Dengan melatih program kami tentang contoh perkataan,
 Kursor disepadukan dengan GPT-4 menjadikan penulisan kod semudah berbual Satu era baharu pengekodan dalam bahasa semula jadi telah tiba.
Apr 04, 2023 pm 12:15 PM
Kursor disepadukan dengan GPT-4 menjadikan penulisan kod semudah berbual Satu era baharu pengekodan dalam bahasa semula jadi telah tiba.
Apr 04, 2023 pm 12:15 PM
Github Copilot X yang menyepadukan GPT-4 masih dalam ujian dalaman berskala kecil, manakala Kursor yang menyepadukan GPT-4 telah dikeluarkan secara terbuka. Kursor ialah IDE yang menyepadukan GPT-4 dan boleh menulis kod dalam bahasa semula jadi, menjadikan penulisan kod semudah berbual. Masih terdapat perbezaan besar antara GPT-4 dan GPT-3.5 dalam keupayaan mereka untuk memproses dan menulis kod. Laporan ujian dari laman web rasmi. Dua yang pertama ialah GPT-4, satu menggunakan input teks dan satu lagi menggunakan input imej; Github Copilot X menyepadukan GPT-4 masih dalam ujian berskala kecil, dan
 Dengan liputan penuh nilai dan perlindungan privasi, Pentadbiran Ruang Siber China merancang untuk 'mewujudkan peraturan' untuk AI generatif
Apr 13, 2023 pm 03:34 PM
Dengan liputan penuh nilai dan perlindungan privasi, Pentadbiran Ruang Siber China merancang untuk 'mewujudkan peraturan' untuk AI generatif
Apr 13, 2023 pm 03:34 PM
Pada 11 April, Pentadbiran Ruang Siber China (selepas ini dirujuk sebagai Pentadbiran Ruang Siber China) merangka dan mengeluarkan "Langkah-Langkah Pengurusan Perkhidmatan Kecerdasan Buatan Generatif (Draf untuk Komen)" dan melancarkan permintaan pendapat selama sebulan daripada orang ramai. Langkah pengurusan ini (draf untuk ulasan) mempunyai sejumlah 21 artikel Dari segi skop aplikasi, ia termasuk kedua-dua entiti yang menyediakan perkhidmatan kecerdasan buatan generatif, serta organisasi dan individu yang menggunakan perkhidmatan ini kandungan kecerdasan buatan generatif orientasi nilai, prinsip latihan untuk penyedia perkhidmatan, perlindungan hak privasi/harta intelek dan hak lain, dsb. Kemunculan model dan produk bahasa semula jadi generatif berskala besar seperti GPT bukan sahaja membolehkan orang ramai mengalami kemajuan pesat kecerdasan buatan, tetapi juga mendedahkan risiko keselamatan, termasuk penjanaan maklumat berat sebelah dan diskriminasi.
 Adakah perlu 'participle'? Andrej Karpathy: Sudah tiba masanya untuk membuang bagasi bersejarah ini
May 20, 2023 pm 12:52 PM
Adakah perlu 'participle'? Andrej Karpathy: Sudah tiba masanya untuk membuang bagasi bersejarah ini
May 20, 2023 pm 12:52 PM
Kemunculan AI perbualan seperti ChatGPT telah menjadikan orang terbiasa dengan perkara seperti ini: masukkan sekeping teks, kod atau gambar, dan robot perbualan akan memberi anda jawapan yang anda inginkan. Tetapi di sebalik kaedah interaksi mudah ini, model AI perlu melakukan pemprosesan dan pengiraan data yang sangat kompleks, dan tokenisasi adalah perkara biasa. Dalam bidang pemprosesan bahasa semula jadi, tokenisasi merujuk kepada membahagikan input teks kepada unit yang lebih kecil, dipanggil "token". Token ini boleh berupa perkataan, subkata atau aksara, bergantung pada strategi pembahagian perkataan dan keperluan tugas tertentu. Sebagai contoh, jika kita melakukan tokenisasi pada ayat "Saya suka makan epal", kita akan mendapat urutan token: [&qu
 Banyak negara merancang untuk mengharamkan ChatGPT Adakah sangkar untuk 'binatang' itu datang?
Apr 10, 2023 pm 02:40 PM
Banyak negara merancang untuk mengharamkan ChatGPT Adakah sangkar untuk 'binatang' itu datang?
Apr 10, 2023 pm 02:40 PM
"Kecerdasan buatan mahu melarikan diri dari penjara", "AI menjana kesedaran diri", "AI akhirnya akan membunuh manusia", "evolusi kehidupan berasaskan silikon"... pernah hanya muncul dalam fantasi teknologi seperti cyberpunk Plot akan datang benar tahun ini, dan model bahasa semula jadi generatif sedang dipersoalkan seperti tidak pernah berlaku sebelum ini. Yang paling menarik perhatian ialah ChatGPT Dari akhir Mac hingga awal April, robot perbualan teks yang dibangunkan oleh OpenAI ini tiba-tiba berubah daripada wakil "produktiviti lanjutan" kepada ancaman kepada manusia. Pertama, ia dinamakan oleh beribu-ribu elit dalam kalangan teknologi dan dimasukkan dalam surat terbuka untuk "menggantung latihan sistem AI yang lebih berkuasa daripada GPT-4" kemudian, organisasi etika teknologi Amerika meminta Suruhanjaya Perdagangan Persekutuan A.S. untuk menyiasat OpenAI dan melarang keluaran versi komersial
