
 Peranti teknologi
AI
Ilustrasi kertas juga boleh dijana secara automatik, menggunakan model resapan, dan juga diterima oleh ICLR.
Peranti teknologi
AI
Ilustrasi kertas juga boleh dijana secara automatik, menggunakan model resapan, dan juga diterima oleh ICLR.
Ilustrasi kertas juga boleh dijana secara automatik, menggunakan model resapan, dan juga diterima oleh ICLR.

Generative AI telah menarik perhatian komuniti kecerdasan buatan Kedua-dua individu dan perusahaan telah mula berminat untuk mencipta aplikasi penukaran modal yang berkaitan, seperti gambar Vincent, video Vincent, muzik Vincent, dll.
Baru-baru ini, beberapa penyelidik dari institusi penyelidikan saintifik seperti ServiceNow Research dan LIVIA telah cuba menjana carta dalam kertas kerja berdasarkan penerangan teks. Untuk tujuan ini, mereka mencadangkan kaedah baharu FigGen, dan kertas berkaitan juga dimasukkan sebagai Tiny Paper dalam ICLR 2023.
 Gambar
Gambar
Alamat kertas: https://arxiv.org/pdf/2306.00800.pdf
Sesetengah orang mungkin bertanya, apakah yang sukar dalam menghasilkan carta? Bagaimanakah ini membantu penyelidikan saintifik?
Penjanaan carta penyelidikan saintifik membantu menyebarkan hasil penyelidikan dengan cara yang ringkas dan mudah difahami, dan menjana carta secara automatik boleh membawa banyak kelebihan kepada penyelidik, seperti menjimatkan masa dan tenaga tanpa menghabiskan banyak usaha mereka bentuk carta dari awal . Selain itu, mereka bentuk angka yang menarik secara visual dan mudah difahami boleh menjadikan kertas itu boleh diakses oleh lebih ramai orang.
Walau bagaimanapun, menjana gambar rajah juga menghadapi beberapa cabaran. Ia perlu mewakili hubungan yang kompleks antara komponen diskret seperti kotak, anak panah, teks, dll. Tidak seperti menjana imej semula jadi, konsep dalam graf kertas mungkin mempunyai perwakilan yang berbeza dan memerlukan pemahaman yang terperinci Contohnya, menjana graf rangkaian saraf akan melibatkan masalah yang tidak ditimbulkan dengan varians yang tinggi.
Oleh itu, penyelidik dalam kertas kerja ini melatih model generatif pada set data pasangan rajah kertas untuk menangkap hubungan antara komponen rajah dan teks yang sepadan dalam kertas. Ini memerlukan berurusan dengan panjang yang berbeza-beza dan penerangan teks yang sangat teknikal, gaya carta yang berbeza, nisbah bidang imej dan fon pemaparan teks, saiz dan isu orientasi.
Semasa proses pelaksanaan khusus, penyelidik telah diilhamkan oleh hasil teks-ke-imej baru-baru ini dan menggunakan model resapan untuk menjana carta yang berpotensi untuk menghasilkan carta penyelidikan saintifik daripada huraian teks - FigGen.
Apakah ciri unik model resapan ini? Mari kita beralih kepada butiran.
Model dan Kaedah
Para penyelidik melatih model resapan terpendam dari awal.
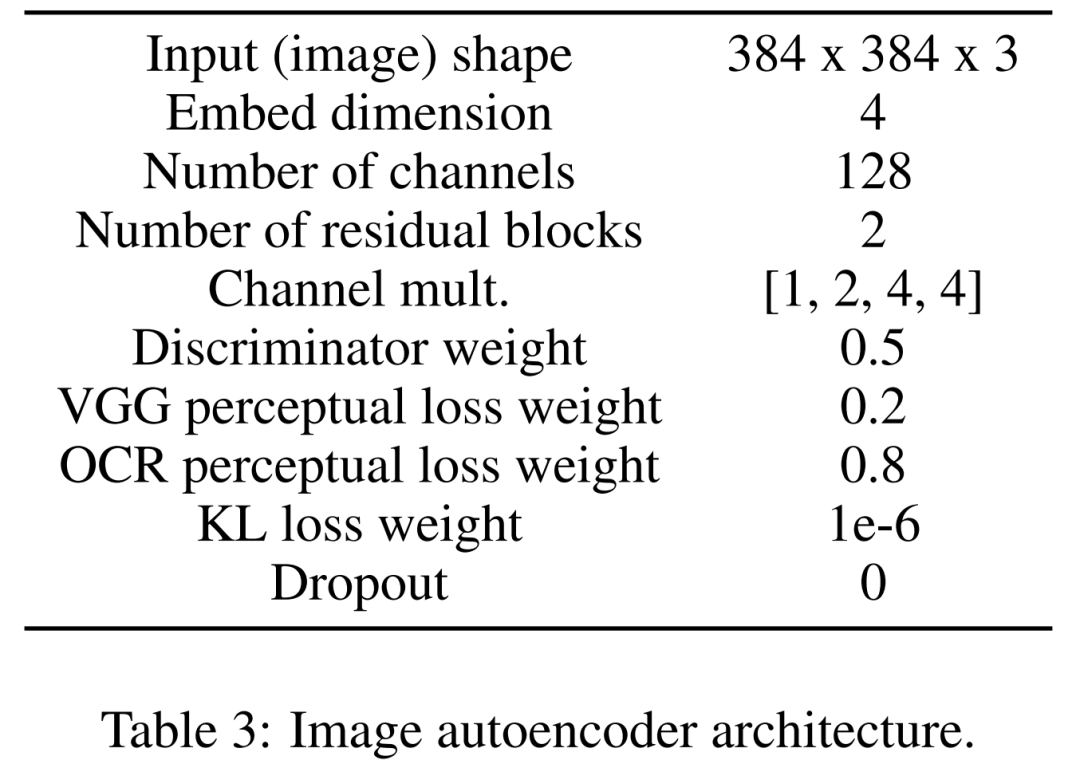
Mula-mula pelajari pengekod automatik imej untuk memetakan imej ke dalam perwakilan terpendam termampat. Pengekod imej menggunakan kehilangan KL dan kehilangan persepsi OCR. Pengekod teks yang digunakan untuk pelaziman dipelajari dari hujung ke hujung dalam latihan model resapan ini. Jadual 3 di bawah menunjukkan parameter terperinci seni bina autopengekod imej.
Model resapan kemudian berinteraksi secara langsung dalam ruang terpendam, melaksanakan penjadualan hadapan yang rosak data sambil belajar mengeksploitasikan U-Net bersyarat temporal dan tekstual untuk memulihkan proses.
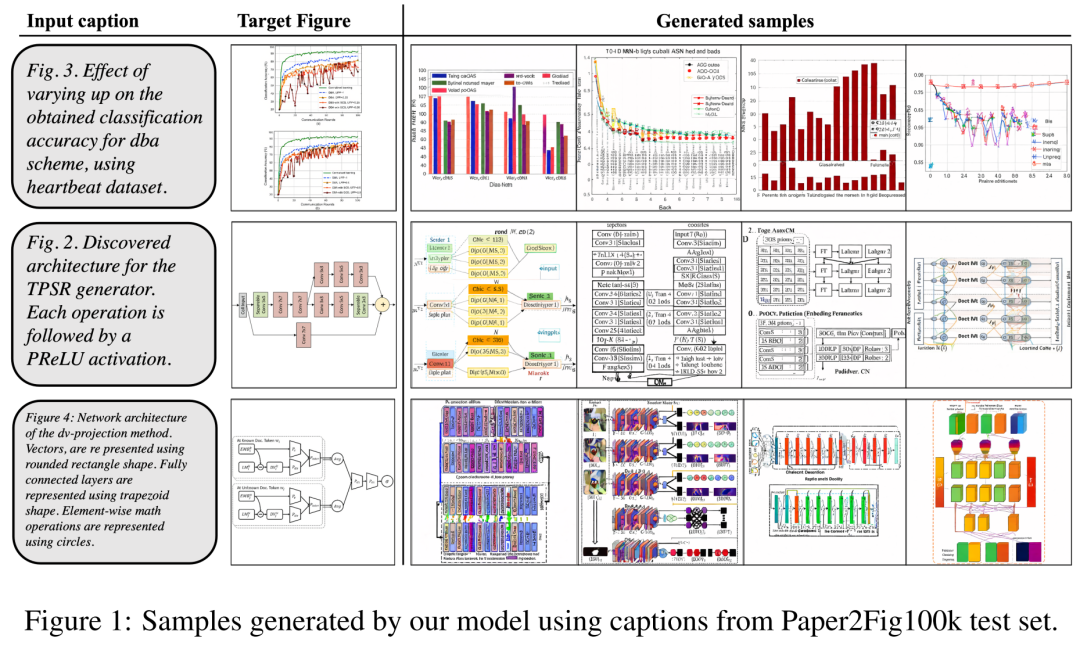
Bagi set data, penyelidik menggunakan Paper2Fig100k, yang terdiri daripada pasangan teks carta dalam kertas dan mengandungi 81,194 sampel latihan dan 21,259 sampel pengesahan. Rajah 1 di bawah ialah contoh rajah yang dijana menggunakan penerangan teks dalam set ujian Paper2Fig100k.
Butiran model
Pertama ialah pengekod imej. Pada peringkat pertama, pengekod automatik imej mempelajari pemetaan daripada ruang piksel kepada perwakilan terpendam termampat, menjadikan latihan model resapan lebih pantas. Pengekod imej juga perlu belajar untuk memetakan imej asas kembali ke ruang piksel tanpa kehilangan butiran penting rajah (seperti kualiti pemaparan teks).
Untuk tujuan ini, penyelidik mentakrifkan codec konvolusi dengan halangan yang mengurangkan sampel imej pada faktor f=8. Pengekod dilatih untuk meminimumkan kehilangan KL, kehilangan sedar VGG dan kehilangan sedar OCR dengan pengedaran Gaussian.
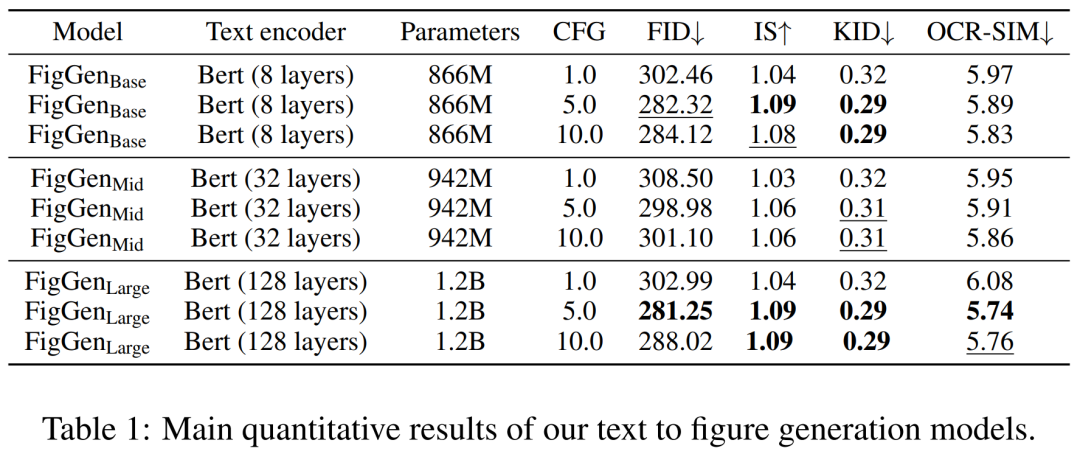
Kedua ialah pengekod teks. Penyelidik telah mendapati bahawa pengekod teks tujuan umum tidak sesuai untuk tugas penjanaan graf. Oleh itu, mereka mentakrifkan pengubah Bert yang dilatih dari awal dalam proses resapan, yang menggunakan saluran pembenaman bersaiz 512, yang juga merupakan saiz benam yang mengawal lapisan perhatian silang U-Net. Para penyelidik juga meneroka perubahan dalam bilangan lapisan pengubah di bawah tetapan yang berbeza (8, 32, dan 128).
Yang terakhir ialah model resapan terpendam. Jadual 2 di bawah menunjukkan seni bina rangkaian U-Net. Kami melakukan proses resapan pada perwakilan terpendam yang setara dengan imej, dengan saiz input imej dimampatkan kepada 64x64x4, menjadikan model resapan lebih pantas. Mereka menentukan 1,000 langkah resapan dan penjadualan hingar linear. . yang mana empat kad grafik NVIDIA V100 12GB telah digunakan. Untuk mencapai kestabilan latihan, mereka memanaskan model dalam lelaran 50k tanpa menggunakan diskriminator.
Untuk melatih model resapan terpendam, para penyelidik juga menggunakan pengoptimum Adam, yang mempunyai saiz kelompok berkesan 32 dan kadar pembelajaran 1e−4. Apabila melatih model pada dataset Paper2Fig100k, mereka menggunakan lapan kad grafik NVIDIA A100 80GB. 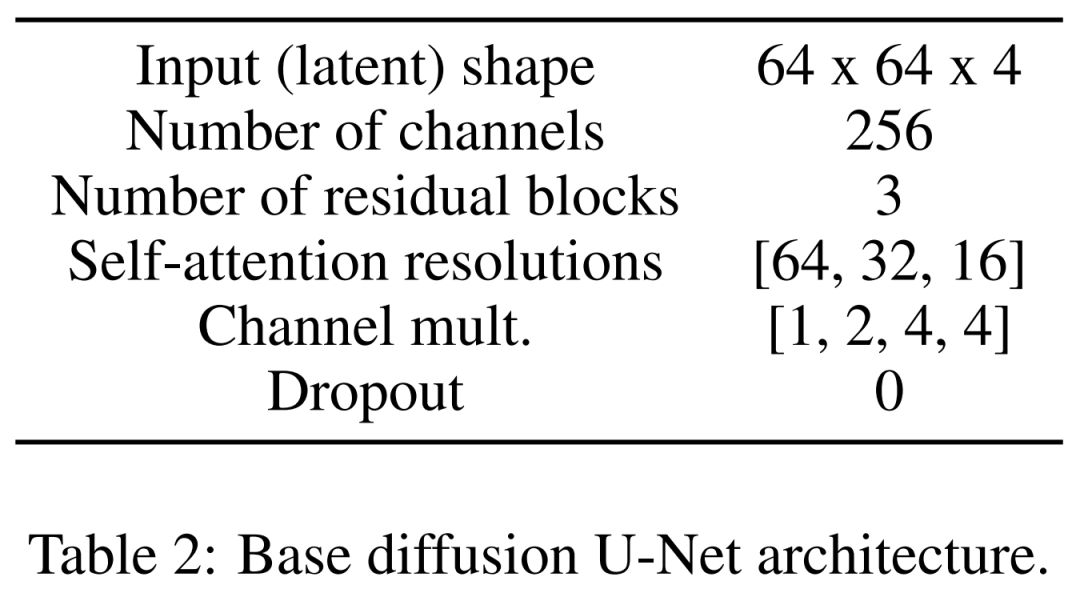
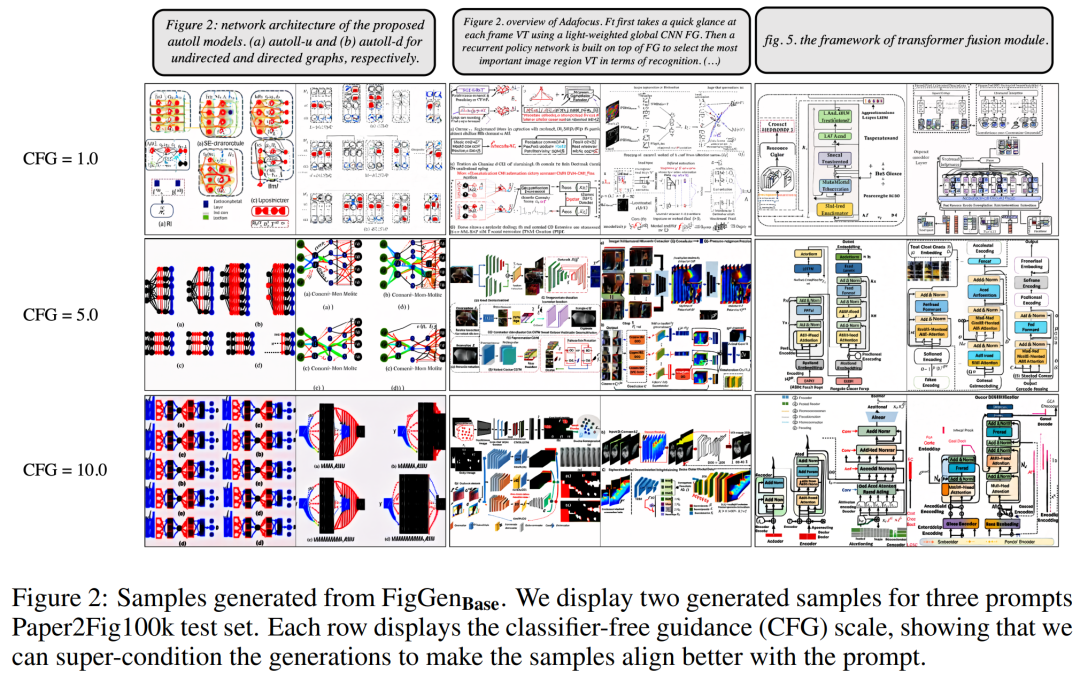
Hasil eksperimenSemasa proses penjanaan, para penyelidik menggunakan pensampel DDIM dengan 200 langkah dan menghasilkan 12,000 sampel untuk setiap model untuk mengira FID, IS, KID dan OCR-SIM1. Penggunaan teguh panduan bebas pengelas (CFG) untuk menguji hiperkondisi.
Jadual 1 di bawah menunjukkan keputusan pengekod teks yang berbeza. Ia boleh dilihat bahawa pengekod teks besar menghasilkan keputusan kualitatif yang terbaik dan penjanaan keadaan boleh diperbaiki dengan meningkatkan saiz CFG. Walaupun sampel kualitatif tidak mempunyai kualiti yang mencukupi untuk menyelesaikan masalah, FigGen telah memahami hubungan antara teks dan imej.
Rajah 2 di bawah menunjukkan sampel FigGen tambahan yang dijana semasa melaraskan parameter Bimbingan Percuma Pengelas (CFG). Para penyelidik memerhatikan bahawa peningkatan saiz CFG, yang juga ditunjukkan secara kuantitatif, membawa kepada peningkatan dalam kualiti imej.
Gambar
Rajah 3 di bawah menunjukkan lebih banyak contoh generasi daripada FigGen. Beri perhatian kepada variasi panjang antara sampel, serta tahap teknikal penerangan teks, yang akan mempengaruhi kesukaran model untuk menjana imej yang boleh difahami dengan betul.
 Gambar
Gambar
Walau bagaimanapun, para penyelidik juga mengakui bahawa walaupun carta yang dihasilkan ini tidak dapat memberikan bantuan praktikal kepada pengarang kertas kerja, ia masih merupakan hala tuju yang menjanjikan untuk diterokai.
 Sila rujuk kertas asal untuk butiran penyelidikan lanjut.
Sila rujuk kertas asal untuk butiran penyelidikan lanjut.
Atas ialah kandungan terperinci Ilustrasi kertas juga boleh dijana secara automatik, menggunakan model resapan, dan juga diterima oleh ICLR.. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1376
1376
 52
52

 Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Geospatial Laravel: Pengoptimuman peta interaktif dan sejumlah besar data
Apr 08, 2025 pm 12:24 PM
Cecair memproses 7 juta rekod dan membuat peta interaktif dengan teknologi geospatial. Artikel ini meneroka cara memproses lebih dari 7 juta rekod menggunakan Laravel dan MySQL dan mengubahnya menjadi visualisasi peta interaktif. Keperluan Projek Cabaran Awal: Ekstrak Wawasan berharga menggunakan 7 juta rekod dalam pangkalan data MySQL. Ramai orang mula -mula mempertimbangkan bahasa pengaturcaraan, tetapi mengabaikan pangkalan data itu sendiri: Bolehkah ia memenuhi keperluan? Adakah penghijrahan data atau pelarasan struktur diperlukan? Bolehkah MySQL menahan beban data yang besar? Analisis awal: Penapis utama dan sifat perlu dikenalpasti. Selepas analisis, didapati bahawa hanya beberapa atribut yang berkaitan dengan penyelesaiannya. Kami mengesahkan kemungkinan penapis dan menetapkan beberapa sekatan untuk mengoptimumkan carian. Carian Peta Berdasarkan Bandar
 Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Cara menyelesaikan MySQL tidak dapat dimulakan
Apr 08, 2025 pm 02:21 PM
Terdapat banyak sebab mengapa permulaan MySQL gagal, dan ia boleh didiagnosis dengan memeriksa log ralat. Penyebab umum termasuk konflik pelabuhan (periksa penghunian pelabuhan dan ubah suai konfigurasi), isu kebenaran (periksa keizinan pengguna yang menjalankan perkhidmatan), ralat fail konfigurasi (periksa tetapan parameter), rasuah direktori data (memulihkan data atau membina semula ruang meja), isu ruang jadual InnoDB (semak fail ibdata1) Apabila menyelesaikan masalah, anda harus menganalisisnya berdasarkan log ralat, cari punca utama masalah, dan mengembangkan tabiat sandaran data secara teratur untuk mencegah dan menyelesaikan masalah.
 Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Cara Menggunakan MySQL Selepas Pemasangan
Apr 08, 2025 am 11:48 AM
Artikel ini memperkenalkan operasi pangkalan data MySQL. Pertama, anda perlu memasang klien MySQL, seperti MySqlworkbench atau Command Line Client. 1. Gunakan perintah MySQL-Uroot-P untuk menyambung ke pelayan dan log masuk dengan kata laluan akaun root; 2. Gunakan CreateTatabase untuk membuat pangkalan data, dan gunakan Pilih pangkalan data; 3. Gunakan createtable untuk membuat jadual, menentukan medan dan jenis data; 4. Gunakan InsertInto untuk memasukkan data, data pertanyaan, kemas kini data dengan kemas kini, dan padam data dengan padam. Hanya dengan menguasai langkah -langkah ini, belajar menangani masalah biasa dan mengoptimumkan prestasi pangkalan data anda boleh menggunakan MySQL dengan cekap.
 Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote (Platform) memerlukan kalangan
Apr 08, 2025 pm 12:27 PM
Jurutera Backend Senior Remote Company Kekosongan Syarikat: Lokasi Lokasi: Jauh Pejabat Jauh Jenis: Gaji sepenuh masa: $ 130,000- $ 140,000 Penerangan Pekerjaan Mengambil bahagian dalam penyelidikan dan pembangunan aplikasi mudah alih Circle dan ciri-ciri berkaitan API awam yang meliputi keseluruhan kitaran hayat pembangunan perisian. Tanggungjawab utama kerja pembangunan secara bebas berdasarkan rubyonrails dan bekerjasama dengan pasukan react/redux/relay front-end. Membina fungsi teras dan penambahbaikan untuk aplikasi web dan bekerjasama rapat dengan pereka dan kepimpinan sepanjang proses reka bentuk berfungsi. Menggalakkan proses pembangunan positif dan mengutamakan kelajuan lelaran. Memerlukan lebih daripada 6 tahun backend aplikasi web kompleks
 Bolehkah mysql kembali json
Apr 08, 2025 pm 03:09 PM
Bolehkah mysql kembali json
Apr 08, 2025 pm 03:09 PM
MySQL boleh mengembalikan data JSON. Fungsi JSON_EXTRACT mengekstrak nilai medan. Untuk pertanyaan yang kompleks, pertimbangkan untuk menggunakan klausa WHERE untuk menapis data JSON, tetapi perhatikan kesan prestasinya. Sokongan MySQL untuk JSON sentiasa meningkat, dan disyorkan untuk memberi perhatian kepada versi dan ciri terkini.
 Memahami sifat asid: tiang pangkalan data yang boleh dipercayai
Apr 08, 2025 pm 06:33 PM
Memahami sifat asid: tiang pangkalan data yang boleh dipercayai
Apr 08, 2025 pm 06:33 PM
Penjelasan terperinci mengenai atribut asid asid pangkalan data adalah satu set peraturan untuk memastikan kebolehpercayaan dan konsistensi urus niaga pangkalan data. Mereka menentukan bagaimana sistem pangkalan data mengendalikan urus niaga, dan memastikan integriti dan ketepatan data walaupun dalam hal kemalangan sistem, gangguan kuasa, atau pelbagai pengguna akses serentak. Gambaran keseluruhan atribut asid Atomicity: Transaksi dianggap sebagai unit yang tidak dapat dipisahkan. Mana -mana bahagian gagal, keseluruhan transaksi dilancarkan kembali, dan pangkalan data tidak mengekalkan sebarang perubahan. Sebagai contoh, jika pemindahan bank ditolak dari satu akaun tetapi tidak meningkat kepada yang lain, keseluruhan operasi dibatalkan. Begintransaction; UpdateAcCountSsetBalance = Balance-100Wh
 Mysql tidak dapat dipasang setelah memuat turun
Apr 08, 2025 am 11:24 AM
Mysql tidak dapat dipasang setelah memuat turun
Apr 08, 2025 am 11:24 AM
Sebab utama kegagalan pemasangan MySQL adalah: 1. Isu kebenaran, anda perlu menjalankan sebagai pentadbir atau menggunakan perintah sudo; 2. Ketergantungan hilang, dan anda perlu memasang pakej pembangunan yang relevan; 3. Konflik pelabuhan, anda perlu menutup program yang menduduki port 3306 atau mengubah suai fail konfigurasi; 4. Pakej pemasangan adalah korup, anda perlu memuat turun dan mengesahkan integriti; 5. Pembolehubah persekitaran dikonfigurasikan dengan salah, dan pembolehubah persekitaran mesti dikonfigurasi dengan betul mengikut sistem operasi. Selesaikan masalah ini dan periksa dengan teliti setiap langkah untuk berjaya memasang MySQL.
 Kunci utama MySQL boleh menjadi batal
Apr 08, 2025 pm 03:03 PM
Kunci utama MySQL boleh menjadi batal
Apr 08, 2025 pm 03:03 PM
Kunci utama MySQL tidak boleh kosong kerana kunci utama adalah atribut utama yang secara unik mengenal pasti setiap baris dalam pangkalan data. Jika kunci utama boleh kosong, rekod tidak dapat dikenal pasti secara unik, yang akan membawa kepada kekeliruan data. Apabila menggunakan lajur integer sendiri atau UUIDs sebagai kunci utama, anda harus mempertimbangkan faktor-faktor seperti kecekapan dan penghunian ruang dan memilih penyelesaian yang sesuai.
