

Pada hari Selasa waktu tempatan, MLCommons, sebuah pakatan industri terbuka dalam bidang pembelajaran mesin dan kecerdasan buatan, mendedahkan data terkini dua ujian penanda aras MLPerf Antaranya, cipset NVIDIA H100 mencatat rekod baharu dalam semua kategori dalam ujian prestasi kuasa pengkomputeran kecerdasan buatan, dan merupakan satu-satunya platform perkakasan yang mampu menjalankan semua ujian.
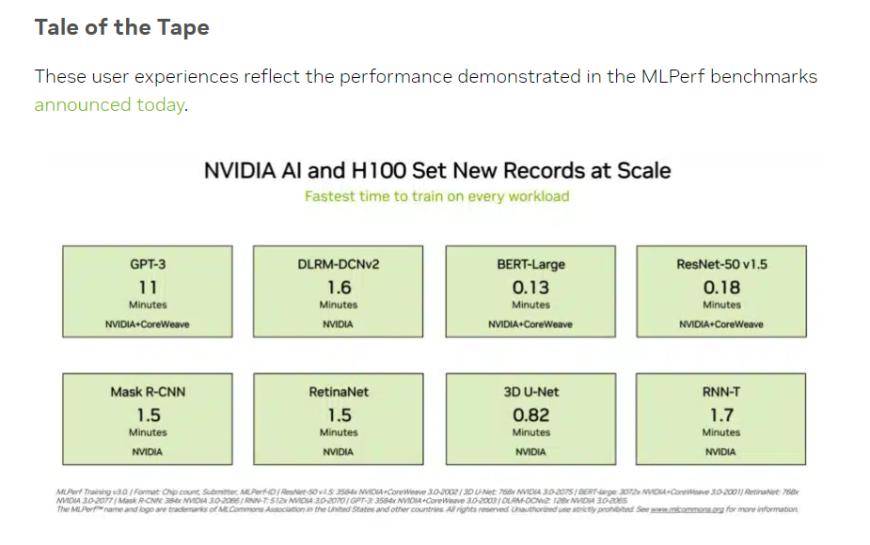
(Sumber: NVIDIA, MLCommons)
MLPerf ialah perikatan kepimpinan kecerdasan buatan yang terdiri daripada akademia, makmal dan industri Ia kini merupakan penanda aras penilaian prestasi AI yang diiktiraf di peringkat antarabangsa. Latihan v3.0 mengandungi 8 beban berbeza, termasuk penglihatan (klasifikasi imej, pembahagian imej bioperubatan, pengesanan objek untuk dua muatan), bahasa (pengecaman pertuturan, model bahasa besar, pemprosesan bahasa semula jadi) dan sistem pengesyoran. Dalam erti kata lain, vendor peralatan yang berbeza mengambil masa yang berbeza untuk menyelesaikan tugas penanda aras.
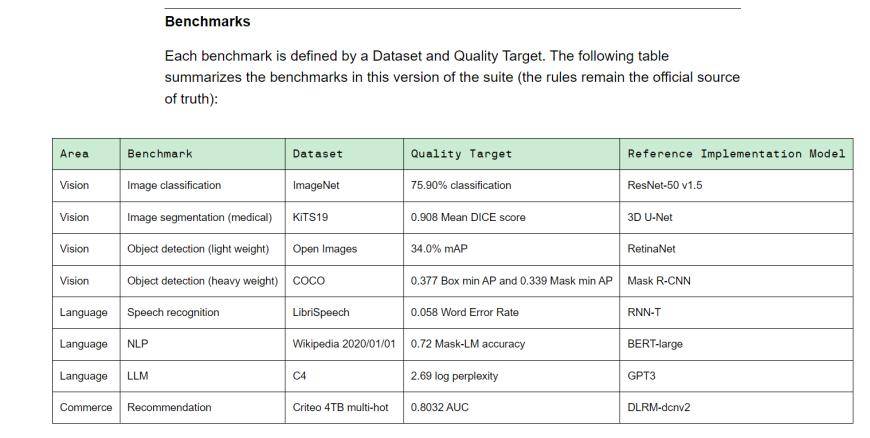
(Tanda aras latihan v3.0 latihan, sumber: MLCommons)
Dalam ujian latihan "model bahasa besar" yang pelabur lebih bimbangkan, data yang diserahkan oleh NVIDIA dan platform pengkomputeran awan GPU CoreWeave menetapkan standard industri yang kejam untuk ujian ini. Dengan usaha bersepadu 896 pemproses Intel Xeon 8462Y+ dan cip 3584 NVIDIA H100, ia hanya mengambil masa 10.94 minit untuk menyelesaikan tugas latihan model bahasa besar berdasarkan GPT-3.
Kecuali Nvidia, hanya portfolio produk Intel yang menerima data penilaian mengenai projek ini. Dalam sistem yang dibina dengan 96 pemproses Xeon 8380 dan 96 cip AI Habana Gaudi2, masa untuk menyelesaikan ujian yang sama ialah 311.94 minit. Menggunakan platform dengan cip 768 H100, ujian perbandingan mendatar hanya mengambil masa 45.6 minit.
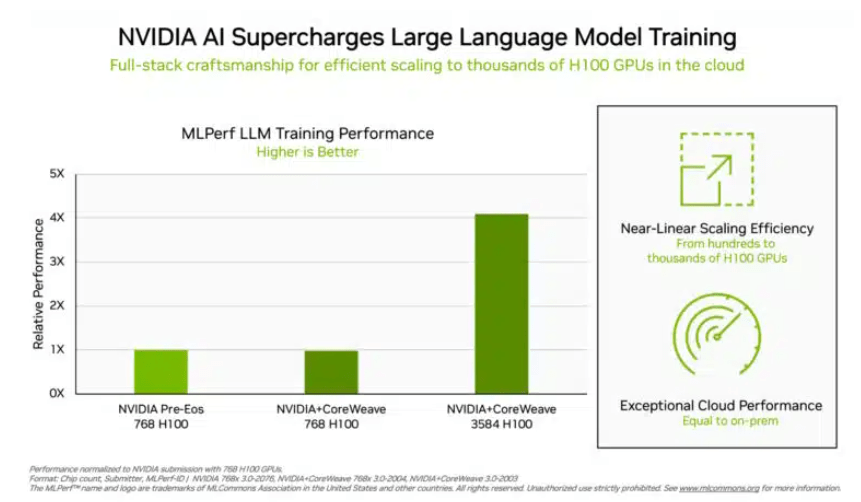
(Lebih banyak cip, lebih baik data, sumber: NVIDIA)
Mengenai keputusan ini, Intel juga berkata masih ada ruang untuk penambahbaikan. Secara teorinya, selagi lebih banyak cip disusun, hasil pengiraan secara semula jadi akan lebih cepat. Jordan Plawner, pengarah kanan produk AI Intel, memberitahu media bahawa keputusan pengkomputeran Habana akan dipertingkatkan sebanyak 1.5 kali kepada 2 kali. Plawner enggan mendedahkan harga khusus Habana Gaudi2, hanya mengatakan bahawa industri memerlukan pengeluar kedua untuk menyediakan cip latihan AI, dan data MLPerf menunjukkan bahawa Intel mempunyai keupayaan untuk memenuhi permintaan ini.
Dalam latihan model BERT-Large yang lebih biasa kepada pelabur China, NVIDIA dan CoreWeave menolak data kepada 0.13 minit yang melampau Dalam kes 64 kad, data ujian juga mencapai 0.89 minit. Infrastruktur semasa model besar arus perdana ialah struktur Transformer dalam model BERT.
Sumber: Financial Associated Press
Atas ialah kandungan terperinci NVIDIA H100 mendominasi ujian prestasi AI yang berwibawa, menyelesaikan latihan model besar berdasarkan GPT-3 dalam 11 minit. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Apakah motor servo
Apakah motor servo
 Pengenalan kepada kaedah diagnostik SEO
Pengenalan kepada kaedah diagnostik SEO
 Apakah yang termasuk storan penyulitan data?
Apakah yang termasuk storan penyulitan data?
 Apakah perbezaan utama antara linux dan windows
Apakah perbezaan utama antara linux dan windows
 Memori yang boleh bertukar maklumat secara terus dengan CPU ialah a
Memori yang boleh bertukar maklumat secara terus dengan CPU ialah a
 Bagaimana untuk membuka fail mds
Bagaimana untuk membuka fail mds
 Tukar warna latar belakang perkataan kepada putih
Tukar warna latar belakang perkataan kepada putih
 Apakah alat pembangunan?
Apakah alat pembangunan?








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



