
 Peranti teknologi
AI
Model besar keluarga alpaca berkembang secara kolektif! Konteks 32k bersamaan dengan GPT-4, dihasilkan oleh pasukan Tian Yuandong
Peranti teknologi
AI
Model besar keluarga alpaca berkembang secara kolektif! Konteks 32k bersamaan dengan GPT-4, dihasilkan oleh pasukan Tian Yuandong
Model besar keluarga alpaca berkembang secara kolektif! Konteks 32k bersamaan dengan GPT-4, dihasilkan oleh pasukan Tian Yuandong

Konteks LLaMA model besar alpaca sumber terbuka adalah sama dengan GPT-4, dengan hanya satu perubahan mudah!
Kertas kerja yang baru diserahkan oleh Meta AI ini menunjukkan bahawa kurang daripada 1000 langkah penalaan halus diperlukan selepas tetingkap konteks LLaMA dikembangkan daripada 2k kepada 32k.
Kosnya boleh diabaikan berbanding dengan pra-latihan. . data boleh menyelesaikan tugas yang lebih kompleks, seperti memproses dokumen yang lebih panjang atau berbilang dokumen pada satu masa
 Kepentingan yang lebih penting ialah semua keluarga model alpaka besar berdasarkan LLaMA boleh menggunakan kaedah ini pada kos yang rendah dan berkembang secara kolektif?
Kepentingan yang lebih penting ialah semua keluarga model alpaka besar berdasarkan LLaMA boleh menggunakan kaedah ini pada kos yang rendah dan berkembang secara kolektif?
Alpaca kini merupakan model asas sumber terbuka yang paling komprehensif, dan telah menghasilkan banyak model besar dan model industri menegak sumber terbuka sepenuhnya yang tersedia secara komersial.
- Tian Yuandong, pengarang kertas yang sepadan, turut teruja berkongsi perkembangan baharu ini dalam kalangan rakan-rakannya.
Semua model besar berdasarkan RoPE boleh digunakan
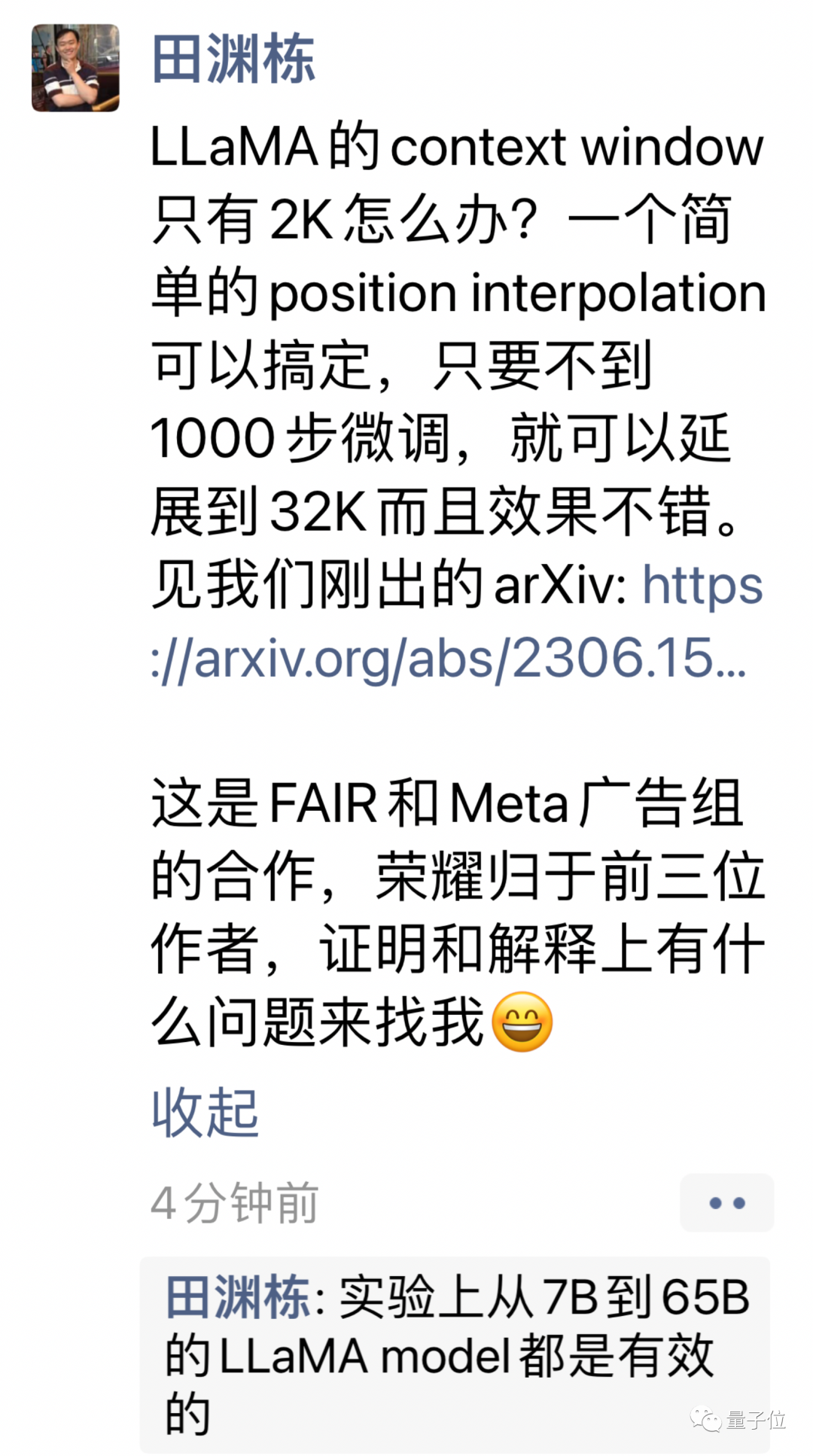
Kaedah baru dipanggil Interpolasi Kedudukan, dan ia sesuai untuk model besar menggunakan RoPE (pengekodan kedudukan putaran). 

Hasil eksperimen menunjukkan kaedah baharu itu berkesan untuk model besar LLaMA dari 7B hingga 65B.
Tiada kemerosotan prestasi yang ketara dalam Pemodelan Bahasa Urutan Panjang, Pengambilan Kunci Laluan dan Ringkasan Dokumen Panjang. 
Selain eksperimen, bukti terperinci kaedah baharu juga diberikan dalam lampiran kertas. 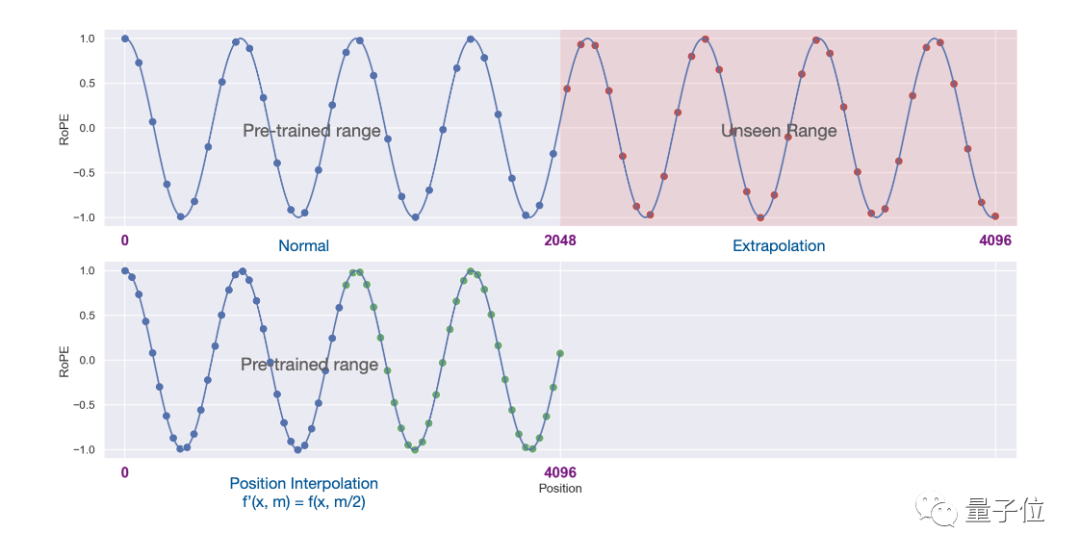
Three More Thing
Tetingkap konteks pernah menjadi jurang penting antara model besar sumber terbuka dan model besar komersial. 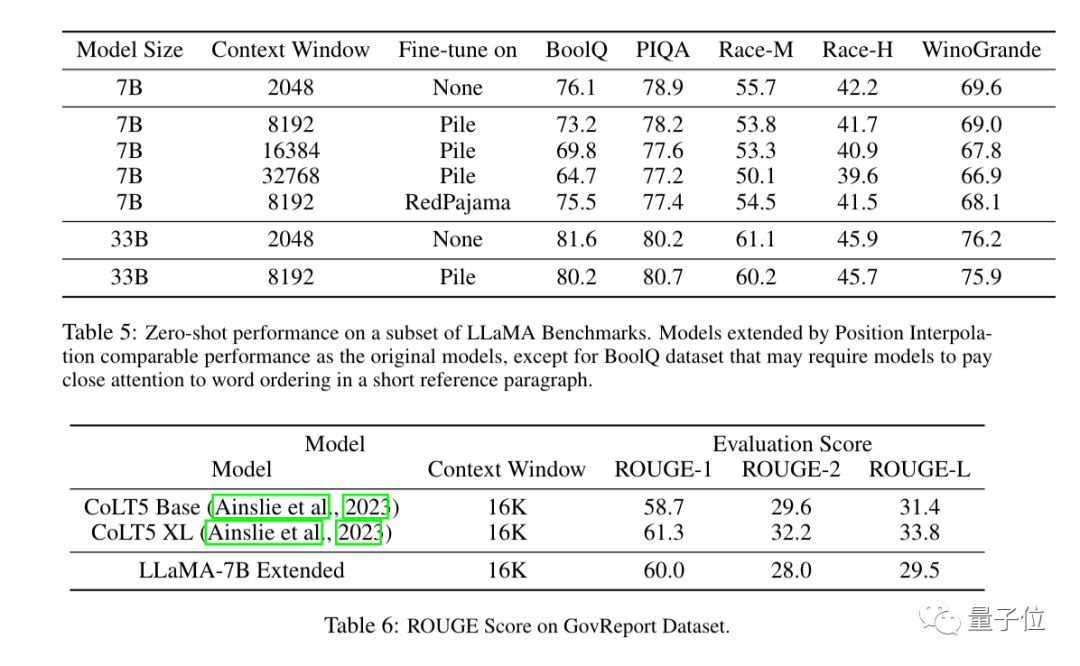
 Kini, keputusan baharu Meta AI telah secara langsung menutup jurang ini.
Kini, keputusan baharu Meta AI telah secara langsung menutup jurang ini.
Meluaskan tetingkap konteks juga merupakan salah satu fokus penyelidikan model besar baru-baru ini Selain kaedah interpolasi kedudukan, terdapat banyak percubaan untuk menarik perhatian industri.
1. Pembangun kaiokendev meneroka kaedah untuk memanjangkan tetingkap konteks LLaMa kepada 8k dalam blog teknikal.
2 Galina Alperovich, ketua pembelajaran mesin di syarikat keselamatan data Soveren, meringkaskan 6 petua untuk mengembangkan tetingkap konteks dalam artikel.3 Pasukan dari Mila, IBM dan institusi lain juga cuba mengalih keluar pengekodan kedudukan sepenuhnya dalam Transformer dalam kertas.伴 Jika anda memerlukannya, anda boleh klik pada pautan di bawah untuk melihat ~
Tesis meta:  Https://www.php.cn/link/0BDF2C1F05365071F0C725D754B96
Https://www.php.cn/link/0BDF2C1F05365071F0C725D754B96
TPS:/ /www.php.cn/link/9659078925b57e621eb3f9ef19773ac3
Sos Rahsia di sebalik tetingkap konteks 100K dalam LLMshttps://www.php.cn/link/09a630e9edddcaf Tiada Kertas pengekodan Kedudukan
https:/ /www. php.cn/link/fb6c84779f12283a81d739d8f088fc12Atas ialah kandungan terperinci Model besar keluarga alpaca berkembang secara kolektif! Konteks 32k bersamaan dengan GPT-4, dihasilkan oleh pasukan Tian Yuandong. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1359
1359
 52
52

 Apl model besar Tencent Yuanbao berada dalam talian! Hunyuan dinaik taraf untuk mencipta pembantu AI serba boleh yang boleh dibawa ke mana-mana
Jun 09, 2024 pm 10:38 PM
Apl model besar Tencent Yuanbao berada dalam talian! Hunyuan dinaik taraf untuk mencipta pembantu AI serba boleh yang boleh dibawa ke mana-mana
Jun 09, 2024 pm 10:38 PM
Pada 30 Mei, Tencent mengumumkan peningkatan menyeluruh model Hunyuannya Apl "Tencent Yuanbao" berdasarkan model Hunyuan telah dilancarkan secara rasmi dan boleh dimuat turun dari kedai aplikasi Apple dan Android. Berbanding dengan versi applet Hunyuan dalam peringkat ujian sebelumnya, Tencent Yuanbao menyediakan keupayaan teras seperti carian AI, ringkasan AI, dan penulisan AI untuk senario kecekapan kerja untuk senario kehidupan harian, permainan Yuanbao juga lebih kaya dan menyediakan pelbagai ciri , dan kaedah permainan baharu seperti mencipta ejen peribadi ditambah. "Tencent tidak akan berusaha untuk menjadi yang pertama membuat model besar, Liu Yuhong, naib presiden Tencent Cloud dan orang yang bertanggungjawab bagi model besar Tencent Hunyuan, berkata: "Pada tahun lalu, kami terus mempromosikan keupayaan untuk Model besar Tencent Hunyuan Dalam teknologi Poland yang kaya dan besar dalam senario perniagaan sambil mendapatkan cerapan tentang keperluan sebenar pengguna
 Model besar Bytedance Beanbao dikeluarkan, perkhidmatan AI tindanan penuh Volcano Engine membantu perusahaan mengubah dengan bijak
Jun 05, 2024 pm 07:59 PM
Model besar Bytedance Beanbao dikeluarkan, perkhidmatan AI tindanan penuh Volcano Engine membantu perusahaan mengubah dengan bijak
Jun 05, 2024 pm 07:59 PM
Tan Dai, Presiden Volcano Engine, berkata syarikat yang ingin melaksanakan model besar dengan baik menghadapi tiga cabaran utama: kesan model, kos inferens dan kesukaran pelaksanaan: mereka mesti mempunyai sokongan model besar asas yang baik untuk menyelesaikan masalah yang kompleks, dan mereka juga mesti mempunyai inferens kos rendah. Perkhidmatan membolehkan model besar digunakan secara meluas, dan lebih banyak alat, platform dan aplikasi diperlukan untuk membantu syarikat melaksanakan senario. ——Tan Dai, Presiden Huoshan Engine 01. Model pundi kacang besar membuat kemunculan sulungnya dan banyak digunakan Menggilap kesan model adalah cabaran paling kritikal untuk pelaksanaan AI. Tan Dai menegaskan bahawa hanya melalui penggunaan meluas model yang baik boleh digilap. Pada masa ini, model Doubao memproses 120 bilion token teks dan menjana 30 juta imej setiap hari. Untuk membantu perusahaan melaksanakan senario model berskala besar, model berskala besar beanbao yang dibangunkan secara bebas oleh ByteDance akan dilancarkan melalui gunung berapi
 Membongkar rangka kerja inferens model besar NVIDIA: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
Membongkar rangka kerja inferens model besar NVIDIA: TensorRT-LLM
Feb 01, 2024 pm 05:24 PM
1. Kedudukan produk TensorRT-LLM TensorRT-LLM ialah penyelesaian inferens berskala yang dibangunkan oleh NVIDIA untuk model bahasa besar (LLM). Ia membina, menyusun dan melaksanakan graf pengiraan berdasarkan rangka kerja kompilasi pembelajaran mendalam TensorRT dan menggunakan pelaksanaan Kernel yang cekap dalam FastTransformer. Selain itu, ia menggunakan NCCL untuk komunikasi antara peranti. Pembangun boleh menyesuaikan operator untuk memenuhi keperluan khusus berdasarkan pembangunan teknologi dan perbezaan permintaan, seperti membangunkan GEMM tersuai berdasarkan cutlass. TensorRT-LLM ialah penyelesaian inferens rasmi NVIDIA, komited untuk menyediakan prestasi tinggi dan terus meningkatkan kepraktisannya. TensorRT-LL
 Penanda aras GPT-4! Model besar Jiutian China Mobile lulus pendaftaran dwi
Apr 04, 2024 am 09:31 AM
Penanda aras GPT-4! Model besar Jiutian China Mobile lulus pendaftaran dwi
Apr 04, 2024 am 09:31 AM
Menurut berita pada 4 April, Pentadbiran Ruang Siber China baru-baru ini mengeluarkan senarai model besar yang didaftarkan, dan "Model Besar Interaksi Bahasa Semula Jadi Jiutian" China Mobile disertakan di dalamnya, menandakan model besar Jiutian AI China Mobile secara rasmi boleh menyediakan tiruan generatif. perkhidmatan perisikan kepada dunia luar. China Mobile menyatakan bahawa ini adalah model berskala besar pertama yang dibangunkan oleh perusahaan pusat yang telah lulus kedua-dua "Pendaftaran Perkhidmatan Kecerdasan Buatan Generatif" nasional dan "Pendaftaran Algoritma Perkhidmatan Sintetik Dalam Domestik" dwi pendaftaran. Menurut laporan, model besar interaksi bahasa semula jadi Jiutian mempunyai ciri-ciri keupayaan industri yang dipertingkatkan, keselamatan dan kredibiliti, dan menyokong penyetempatan timbunan penuh Ia telah membentuk berbilang versi parameter seperti 9 bilion, 13.9 bilion, 57 bilion dan 100 bilion. dan boleh digunakan secara fleksibel dalam Awan, tepi dan hujung adalah situasi yang berbeza
 Penanda aras ujian baharu dikeluarkan, sumber terbuka paling berkuasa Llama 3 memalukan
Apr 23, 2024 pm 12:13 PM
Penanda aras ujian baharu dikeluarkan, sumber terbuka paling berkuasa Llama 3 memalukan
Apr 23, 2024 pm 12:13 PM
Jika soalan ujian terlalu mudah, kedua-dua pelajar terbaik dan pelajar lemah boleh mendapat 90 mata, dan jurang tidak boleh diluaskan... Dengan keluaran model yang lebih kukuh seperti Claude3, Llama3 dan juga GPT-5 kemudiannya, industri berada dalam keperluan mendesak untuk penanda aras model yang lebih sukar dan berbeza. LMSYS, organisasi di sebalik arena model besar, melancarkan penanda aras generasi akan datang, Arena-Hard, yang menarik perhatian meluas. Terdapat juga rujukan terkini untuk kekuatan dua versi arahan Llama3 yang diperhalusi. Berbanding dengan MTBench, yang mempunyai markah yang sama sebelum ini, diskriminasi Arena-Hard meningkat daripada 22.6% kepada 87.4%, yang lebih kuat dan lemah secara sepintas lalu. Arena-Hard dibina menggunakan data manusia masa nyata dari arena dan mempunyai kadar konsistensi 89.1% dengan keutamaan manusia.
 Menggunakan teknologi AI Shengteng, model pengangkutan Qinling·Qinchuan membantu Xi'an membina pusat inovasi pengangkutan pintar
Oct 15, 2023 am 08:17 AM
Menggunakan teknologi AI Shengteng, model pengangkutan Qinling·Qinchuan membantu Xi'an membina pusat inovasi pengangkutan pintar
Oct 15, 2023 am 08:17 AM
"Kerumitan tinggi, pemecahan tinggi dan merentas domain" sentiasa menjadi titik kesakitan utama dalam perjalanan ke peningkatan digital dan pintar industri pengangkutan. Baru-baru ini, "Model Trafik Qinling·Qinchuan" dengan skala parameter 100 bilion, dibina bersama oleh China Science Vision, Kerajaan Daerah Xi'an Yanta, dan Pusat Pengkomputeran Kecerdasan Buatan Masa Depan Xi'an, berorientasikan bidang pengangkutan pintar dan menyediakan perkhidmatan kepada Xi'an dan kawasan sekitarnya Rantau ini akan mewujudkan titik tumpu untuk inovasi pengangkutan pintar. "Model Trafik Qinling·Qinchuan" menggabungkan data ekologi trafik tempatan besar-besaran Xi'an dalam senario terbuka, algoritma lanjutan asal yang dibangunkan secara bebas oleh China Science Vision dan kuasa pengkomputeran berkuasa Shengteng AI dari Pusat Pengkomputeran Kecerdasan Buatan Masa Depan Xi'an untuk menyediakan pemantauan rangkaian jalan raya, senario pengangkutan Pintar seperti arahan kecemasan, pengurusan penyelenggaraan dan perjalanan awam membawa perubahan digital dan pintar. Pengurusan trafik mempunyai ciri yang berbeza di bandar yang berbeza, dan trafik di jalan yang berbeza
 Amalan lanjutan graf pengetahuan industri
Jun 13, 2024 am 11:59 AM
Amalan lanjutan graf pengetahuan industri
Jun 13, 2024 am 11:59 AM
1. Latar Belakang Pengenalan Pertama, mari kita perkenalkan sejarah pembangunan Teknologi Yunwen. Syarikat Teknologi Yunwen...2023 ialah tempoh apabila model besar berleluasa Banyak syarikat percaya bahawa kepentingan graf telah dikurangkan dengan ketara selepas model besar, dan sistem maklumat pratetap yang dikaji sebelum ini tidak lagi penting. Walau bagaimanapun, dengan promosi RAG dan kelaziman tadbir urus data, kami mendapati bahawa tadbir urus data yang lebih cekap dan data berkualiti tinggi adalah prasyarat penting untuk meningkatkan keberkesanan model besar yang diswastakan Oleh itu, semakin banyak syarikat mula memberi perhatian kepada kandungan berkaitan pembinaan pengetahuan. Ini juga menggalakkan pembinaan dan pemprosesan pengetahuan ke peringkat yang lebih tinggi, di mana terdapat banyak teknik dan kaedah yang boleh diterokai. Dapat dilihat bahawa kemunculan teknologi baru tidak mengalahkan semua teknologi lama, tetapi mungkin juga mengintegrasikan teknologi baru dan lama.
 Xiaomi Byte bergabung tenaga! Model besar akses Xiao Ai ke Doubao: sudah dipasang pada telefon mudah alih dan SU7
Jun 13, 2024 pm 05:11 PM
Xiaomi Byte bergabung tenaga! Model besar akses Xiao Ai ke Doubao: sudah dipasang pada telefon mudah alih dan SU7
Jun 13, 2024 pm 05:11 PM
Menurut berita pada 13 Jun, menurut akaun awam “Volcano Engine” Byte, pembantu kecerdasan buatan Xiaomi “Xiao Ai” telah mencapai kerjasama dengan Volcano Engine Kedua-dua pihak akan mencapai pengalaman interaktif AI yang lebih pintar berdasarkan model besar beanbao . Dilaporkan bahawa model beanbao berskala besar yang dicipta oleh ByteDance boleh memproses sehingga 120 bilion token teks dengan cekap dan menjana 30 juta keping kandungan setiap hari. Xiaomi menggunakan model besar Doubao untuk meningkatkan keupayaan pembelajaran dan penaakulan modelnya sendiri dan mencipta "Xiao Ai Classmate", yang bukan sahaja memahami keperluan pengguna dengan lebih tepat, tetapi juga menyediakan kelajuan tindak balas yang lebih pantas dan perkhidmatan kandungan yang lebih komprehensif. Contohnya, apabila pengguna bertanya tentang konsep saintifik yang kompleks, &ldq
