
 Peranti teknologi
AI
Google AudioPaLM melaksanakan penyelesaian dwi-modal 'teks + audio', model besar untuk bercakap dan mendengar
Peranti teknologi
AI
Google AudioPaLM melaksanakan penyelesaian dwi-modal 'teks + audio', model besar untuk bercakap dan mendengar
Google AudioPaLM melaksanakan penyelesaian dwi-modal 'teks + audio', model besar untuk bercakap dan mendengar

Model bahasa berskala besar, dengan prestasi hebat dan serba boleh, telah memacu pembangunan beberapa model besar berbilang modal, seperti audio, video, dsb.
Seni bina asas model bahasa kebanyakannya berdasarkan Transformer dan terutamanya penyahkod, jadi seni bina model boleh disesuaikan dengan modaliti jujukan lain tanpa terlalu banyak pelarasan.
Baru-baru ini, Google mengeluarkan model teks pertuturan bersatu AudioPaLM, yang menggabungkan teks dan token audio ke dalam perbendaharaan kata gabungan pelbagai mod, dan menggabungkannya dengan teg perihalan tugas yang berbeza untuk mencapai sebarang campuran pertuturan dan teks. hanya model pada tugasan, termasuk pengecaman pertuturan (ASR), sintesis teks ke pertuturan, terjemahan pertuturan automatik (AST), dan terjemahan pertuturan ke pertuturan (S2ST), dsb., menyatukan tugas yang secara tradisinya diselesaikan oleh model heterogen menjadi satu seni bina dan proses latihan. . /
 Di samping itu, memandangkan seni bina asas AudioPaLM ialah model Transformer yang besar, yang boleh dimulakan dengan pemberat model bahasa besar yang dipralatih pada teks, ia boleh mendapat manfaat daripada pengetahuan linguistik model seperti PaLM .
Di samping itu, memandangkan seni bina asas AudioPaLM ialah model Transformer yang besar, yang boleh dimulakan dengan pemberat model bahasa besar yang dipralatih pada teks, ia boleh mendapat manfaat daripada pengetahuan linguistik model seperti PaLM .
Dari perspektif hasil pelaksanaan, AudioPaLM telah mencapai hasil terkini pada penanda aras AST dan S2ST, dan prestasinya pada penanda aras ASR adalah setanding dengan model lain.
Dengan memanfaatkan isyarat audio AudioLM, model AudioPaLM mampu melaksanakan S2ST pada pemindahan pertuturan pembesar suara baharu, mengatasi kaedah sedia ada dari segi kualiti pertuturan dan pemeliharaan pertuturan.
Model AudioPaLM juga mempunyai keupayaan tangkapan sifar untuk melaksanakan tugas AST pada kombinasi input pertuturan/bahasa sasaran yang tidak dilihat dalam latihan.
AudioPaLMPara penyelidik menggunakan model Transformer penyahkod sahaja untuk memodelkan teks dan token pertuturan Teks dan audio telah dibahagikan sebelum dimasukkan ke dalam model, jadi input hanyalah jujukan integer, dan pada bahagian. tamat keluaran Kemudian lakukan operasi yang dinyahtokkan dan kembalikan kepada pengguna.
Pictures
udio embedding dan segmentation perkataan
 Proses menukarkan bentuk gelombang audio asal menjadi token termasuk mengekstrak embeddings dari model perwakilan ucapan yang ada, dan membezakan embeddings ke dalam set terhad token audio
Proses menukarkan bentuk gelombang audio asal menjadi token termasuk mengekstrak embeddings dari model perwakilan ucapan yang ada, dan membezakan embeddings ke dalam set terhad token audio
Dalam kerja terdahulu, embeddings telah diekstrak daripada model w2v-BERT dan dikuantisasi dengan k-means Dalam kertas kerja ini, penyelidik telah mencuba tiga skema: w2v-BERT: Gunakan w2v-BERT. -Model BERT dilatih pada data berbilang bahasa dan bukannya bahasa Inggeris tulen dan tiada pemprosesan normalisasi dilakukan sebelum pengelompokan k-means, jika tidak, ia akan menyebabkan persekitaran berbilang bahasa merosot prestasi sederhana. Kemudian jana token pada kadar 25Hz dengan saiz perbendaharaan kata 1024
USM-v1: Lakukan operasi serupa menggunakan pengekod 2 bilion parameter Universal Speech Model (USM) yang lebih berkuasa dan ekstrak benam dari lapisan tengah ;
USM-v2: Dilatih dengan kehilangan ASR tambahan dan diperhalusi untuk menyokong berbilang bahasa.
Ubah suai penyahkod teks sahaja
Dalam struktur penyahkod Transfomrer, kecuali untuk input dan lapisan keluaran softmax terakhir, bilangan token pemodelan tidak terlibat, dan dalam seni bina PaLM pembolehubah berat matriks input dan output dikongsi, iaitu, ia adalah transpose antara satu sama lain.
Jadi anda hanya perlu mengembangkan saiz matriks benam daripada (t × m) kepada (t+a) ×m untuk menukar model teks tulen kepada model yang boleh mensimulasikan kedua-dua teks dan audio, dengan t ialah saiz perbendaharaan kata teks, a ialah saiz perbendaharaan kata audio, dan m ialah dimensi benam. Untuk memanfaatkan model teks pra-latihan, para penyelidik menukar pusat pemeriksaan model sedia ada dengan menambah baris baharu pada matriks benam.
Pelaksanaan khusus ialah token t pertama sepadan dengan teg teks SentencePiece, dan token berikut mewakili teg audio Walaupun pembenaman teks menggunakan semula pemberat yang telah dilatih, pembenaman audio baru dimulakan dan mesti dimulakan. terlatih.
Hasil eksperimen menunjukkan bahawa berbanding dengan latihan semula dari awal, model pra-latihan berasaskan teks sangat berfaedah untuk meningkatkan prestasi tugasan berbilang modal pertuturan dan teks.
Penyahkodan token audio ke dalam audio asli
Untuk mensintesis bentuk gelombang audio daripada token audio, penyelidik mencuba dua kaedah berbeza:
penyahkodan Audio.yang serupa
2. Penyahkodan bukan autoregresif serupa dengan model SoundStorm
Kedua-dua kaedah perlu menjana token SoundStream terlebih dahulu, dan kemudian menggunakan penyahkod konvolusi untuk menukarnya kepada bentuk gelombang audio.
Para penyelidik dilatih tentang Multilingual LibriSpeech Keadaan pertuturan ialah sampel pertuturan sepanjang 3 saat, dinyatakan sebagai token audio dan token SoundStream
Dengan menyediakan sebahagian daripada ucapan input asal sebagai keadaan pertuturan, model. boleh bercakap Apabila pertuturan manusia diterjemahkan ke dalam bahasa yang berbeza, pertuturan pembesar suara asal dikekalkan Apabila audio asal lebih pendek daripada 3 saat, masa kosong diisi dengan main semula berulang.
Tugas latihan
Set data latihan yang digunakan ialah semua data teks pertuturan:
1. T.2ran Audio: T.2ran Audio: T.2ran Audio: T.2 ranskripsi pertuturan dalam data audio
3. Terjemahan Audio Terjemahan Audio: Terjemahan pertuturan dalam audio
4. Transkrip Terjemahan: Terjemahan bertulis dalam audio
termasuk: ...tugasan komponen terjemahan): Terjemah audio untuk mendapatkan audio yang diterjemahkan
4. TTS (Teks ke Ucapan): Baca kandungan yang ditranskripsi untuk mendapatkan audio. . model harus berprestasi untuk input yang diberikan ditentukan dengan menambahkan label sebelum input, menyatakan tugas dan nama bahasa Inggeris bahasa input Bahasa output juga boleh dipilih.
Sebagai contoh, apabila anda mahu model melaksanakan ASR pada korpus Perancis, anda perlu menambah label [ASR French] di hadapan input audio selepas pembahagian perkataan untuk melaksanakan tugasan TTS dalam bahasa Inggeris, anda perlu menambah [TTS English] di hadapan teks; Untuk melaksanakan tugasan S2ST daripada bahasa Inggeris ke bahasa Perancis, audio bahasa Inggeris yang dibahagikan akan didahului oleh [S2ST English French]
Training Mix
perpustakaan SeqIO untuk mencampurkan data latihan Set data yang lebih besar mengalami pengurangan berat. .
Selain menilai kualiti terjemahan kandungan pertuturan, penyelidik juga menilai sama ada kualiti bahasa yang dijana oleh AudioPaLM adalah cukup tinggi dan sama ada suara pembesar suara dikekalkan apabila diterjemahkan ke dalam bahasa yang berbeza.
Metrik Objektif
Menggunakan sesuatu yang serupa dengan penganggar MOS tanpa rujukan, diberikan sampel audio, memberikan anggaran kualiti audio yang dirasakan pada skala dari 1 hingga 5. Untuk mengukur kualiti pemindahan pertuturan merentas bahasa, penyelidik menggunakan model pengesahan pembesar suara di luar rak dan mengira persamaan kosinus antara sumber (dikodkan/dikodkan dengan SoundStream) dan benam pertuturan yang diterjemahkan juga diukur pembenaman daripada ciri Akustik audio sumber kepada audio sasaran (keadaan rakaman, bunyi latar belakang).
Penilaian Subjektif
Para penyelidik menjalankan dua kajian bebas untuk menilai kualiti suara dan persamaan suara yang dihasilkan, menggunakan set sampel yang sama dalam kedua-dua kajian.
Disebabkan kualiti korpus yang tidak sekata, sesetengahnya mengandungi pertuturan bertindih yang kuat (contohnya, rancangan TV atau lagu yang dimainkan di latar belakang) atau bunyi yang sangat kuat (contohnya, pakaian bergesel dengan mikrofon yang dihasilkan oleh kesan herotan yang serupa). manusia Tugas penilai adalah rumit, jadi para penyelidik memutuskan untuk melakukan pra-penapis dengan memilih hanya input dengan anggaran MOS sekurang-kurangnya 3.0.
Penilaian disediakan pada skala 5 mata, daripada 1 (kualiti buruk atau bunyi berbeza sama sekali) hingga 5 (kualiti baik, bunyi yang sama).
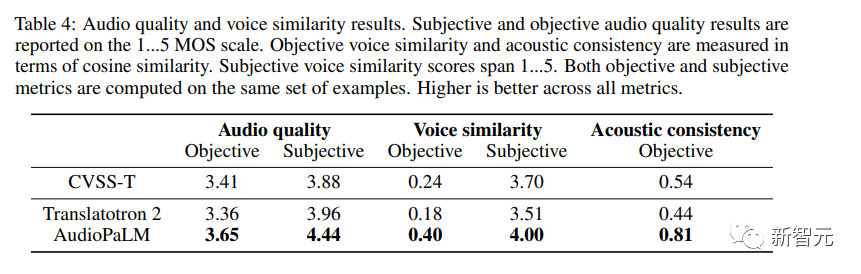 Gambar
Gambar
Ia boleh diperhatikan daripada keputusan bahawa AudioPaLM dengan ketara mengatasi sistem asas Translatotron 2 dari segi kualiti audio dan persamaan pertuturan dalam kedua-dua ukuran objektif dan subjektif, dan AudioPaLM adalah lebih baik daripada yang sebenar dalam Rakaman sintetik CVSS-T mempunyai kualiti yang lebih tinggi dan persamaan suara yang lebih baik, dan dipertingkatkan dengan ketara dalam kebanyakan penunjuk.
Para penyelidik juga membandingkan sistem dalam kumpulan sumber tinggi dan rendah (Perancis, Jerman, Sepanyol dan Catalan berbanding bahasa lain) dan mendapati tiada perbezaan ketara dalam metrik antara kumpulan ini.
Atas ialah kandungan terperinci Google AudioPaLM melaksanakan penyelesaian dwi-modal 'teks + audio', model besar untuk bercakap dan mendengar. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

Video Face Swap
Tukar muka dalam mana-mana video dengan mudah menggunakan alat tukar muka AI percuma kami!

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1393
1393
 52
1207
24
52
1207
24

 Sesame Open Door Exchange Web Pautan Pautan Gerbang Perdagangan Laman Web Pendaftaran Terkini
Feb 28, 2025 am 11:06 AM
Sesame Open Door Exchange Web Pautan Pautan Gerbang Perdagangan Laman Web Pendaftaran Terkini
Feb 28, 2025 am 11:06 AM
Artikel ini memperkenalkan proses pendaftaran versi web Web Open Exchange (GATE.IO) dan aplikasi Perdagangan Gate secara terperinci. Sama ada pendaftaran web atau pendaftaran aplikasi, anda perlu melawat laman web rasmi atau App Store untuk memuat turun aplikasi tulen, kemudian isi nama pengguna, kata laluan, e -mel, nombor telefon bimbit dan maklumat lain, dan lengkap e -mel atau pengesahan telefon bimbit.
 Mengapa pautan Bybit Exchange tidak dimuat turun dan dipasang secara langsung?
Feb 21, 2025 pm 10:57 PM
Mengapa pautan Bybit Exchange tidak dimuat turun dan dipasang secara langsung?
Feb 21, 2025 pm 10:57 PM
Mengapa pautan Bybit Exchange tidak dimuat turun dan dipasang secara langsung? Bybit adalah pertukaran cryptocurrency yang menyediakan perkhidmatan perdagangan kepada pengguna. Aplikasi mudah alih Exchange tidak boleh dimuat turun terus melalui AppStore atau GooglePlay untuk sebab -sebab berikut: 1. Aplikasi pertukaran cryptocurrency sering tidak memenuhi keperluan ini kerana ia melibatkan perkhidmatan kewangan dan memerlukan peraturan dan standard keselamatan tertentu. 2. Undang -undang dan Peraturan Pematuhan di banyak negara, aktiviti yang berkaitan dengan urus niaga cryptocurrency dikawal atau terhad. Untuk mematuhi peraturan ini, aplikasi bybit hanya boleh digunakan melalui laman web rasmi atau saluran yang diberi kuasa lain
 WEB OPEN DOOR EXCHANGE WEB PAGE LOGIN VERSI VERSI UNTUK GATEIO Laman Web Rasmi Pintu Masuk
Mar 04, 2025 pm 11:48 PM
WEB OPEN DOOR EXCHANGE WEB PAGE LOGIN VERSI VERSI UNTUK GATEIO Laman Web Rasmi Pintu Masuk
Mar 04, 2025 pm 11:48 PM
Pengenalan terperinci kepada operasi log masuk versi Web Open Exchange, termasuk langkah masuk dan proses pemulihan kata laluan.
 Platform Perdagangan Pintu Terbuka Sesame Muat turun Versi Mudah Alih Platform Perdagangan Platform Perdagangan Alamat Muat Turun
Feb 28, 2025 am 10:51 AM
Platform Perdagangan Pintu Terbuka Sesame Muat turun Versi Mudah Alih Platform Perdagangan Platform Perdagangan Alamat Muat Turun
Feb 28, 2025 am 10:51 AM
Adalah penting untuk memilih saluran rasmi untuk memuat turun aplikasi dan memastikan keselamatan akaun anda.
 Top 10 Disyorkan untuk App Perdagangan Aset Digital Crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Top 10 Disyorkan untuk App Perdagangan Aset Digital Crypto (2025 Global Ranking)
Mar 18, 2025 pm 12:15 PM
Artikel ini mencadangkan sepuluh platform perdagangan cryptocurrency teratas yang memberi perhatian kepada, termasuk Binance, OKX, Gate.io, Bitflyer, Kucoin, Bybit, Coinbase Pro, Kraken, BYDFI dan Xbit yang desentralisasi. Platform ini mempunyai kelebihan mereka sendiri dari segi kuantiti mata wang transaksi, jenis urus niaga, keselamatan, pematuhan, dan ciri khas. Memilih platform yang sesuai memerlukan pertimbangan yang komprehensif berdasarkan pengalaman perdagangan anda sendiri, toleransi risiko dan keutamaan pelaburan. Semoga artikel ini membantu anda mencari saman terbaik untuk diri sendiri
 Portal Log Masuk Versi Rasmi Binance Binance
Feb 21, 2025 pm 05:42 PM
Portal Log Masuk Versi Rasmi Binance Binance
Feb 21, 2025 pm 05:42 PM
Untuk mengakses versi Login Laman Web Binance yang terkini, ikuti langkah mudah ini. Pergi ke laman web rasmi dan klik butang "Login" di sudut kanan atas. Pilih kaedah log masuk anda yang sedia ada. Masukkan nombor mudah alih berdaftar atau e -mel dan kata laluan anda dan pengesahan lengkap (seperti kod pengesahan mudah alih atau Google Authenticator). Selepas pengesahan yang berjaya, anda boleh mengakses Portal Log masuk laman web rasmi Binance.
 Bitget Trading Platform Rasmi App Muat turun dan Alamat Pemasangan
Feb 25, 2025 pm 02:42 PM
Bitget Trading Platform Rasmi App Muat turun dan Alamat Pemasangan
Feb 25, 2025 pm 02:42 PM
Panduan ini menyediakan langkah muat turun dan pemasangan terperinci untuk aplikasi Bitget Exchange rasmi, sesuai untuk sistem Android dan iOS. Panduan ini mengintegrasikan maklumat dari pelbagai sumber yang berwibawa, termasuk laman web rasmi, App Store, dan Google Play, dan menekankan pertimbangan semasa muat turun dan pengurusan akaun. Pengguna boleh memuat turun aplikasinya dari saluran rasmi, termasuk App Store, muat turun APK laman web rasmi dan melompat laman web rasmi, dan lengkap pendaftaran, pengesahan identiti dan tetapan keselamatan. Di samping itu, panduan itu merangkumi soalan dan pertimbangan yang sering ditanya, seperti
 Alamat muat turun terbaru Bitget pada tahun 2025: Langkah -langkah untuk mendapatkan aplikasi rasmi
Feb 25, 2025 pm 02:54 PM
Alamat muat turun terbaru Bitget pada tahun 2025: Langkah -langkah untuk mendapatkan aplikasi rasmi
Feb 25, 2025 pm 02:54 PM
Panduan ini menyediakan langkah muat turun dan pemasangan terperinci untuk aplikasi Bitget Exchange rasmi, sesuai untuk sistem Android dan iOS. Panduan ini mengintegrasikan maklumat dari pelbagai sumber yang berwibawa, termasuk laman web rasmi, App Store, dan Google Play, dan menekankan pertimbangan semasa muat turun dan pengurusan akaun. Pengguna boleh memuat turun aplikasinya dari saluran rasmi, termasuk App Store, muat turun APK laman web rasmi dan melompat laman web rasmi, dan lengkap pendaftaran, pengesahan identiti dan tetapan keselamatan. Di samping itu, panduan itu merangkumi soalan dan pertimbangan yang sering ditanya, seperti
