
 Peranti teknologi
AI
Penyelidikan baharu oleh pasukan Tian Yuandong: Penalaan halus <1000 langkah, memanjangkan konteks LLaMA kepada 32K
Peranti teknologi
AI
Penyelidikan baharu oleh pasukan Tian Yuandong: Penalaan halus <1000 langkah, memanjangkan konteks LLaMA kepada 32K
Penyelidikan baharu oleh pasukan Tian Yuandong: Penalaan halus <1000 langkah, memanjangkan konteks LLaMA kepada 32K

Memandangkan semua orang terus menaik taraf dan mengulang model besar mereka sendiri, keupayaan LLM (Model Bahasa Besar) untuk memproses tetingkap konteks juga telah menjadi penunjuk penilaian yang penting.
Sebagai contoh, gpt-3.5-turbo OpenAI menyediakan pilihan tetingkap konteks 16k token, dan AnthropicAI telah meningkatkan keupayaan pemprosesan token Claude kepada 100k. Apakah konsep tetingkap konteks pemprosesan model besar Sebagai contoh, GPT-4 menyokong 32k token, yang bersamaan dengan 50 halaman teks, yang bermaksud bahawa GPT-4 boleh mengingati sehingga kira-kira 50 halaman kandungan semasa bercakap atau menjana teks.
Secara umumnya, keupayaan model bahasa yang besar untuk mengendalikan saiz tetingkap konteks telah ditentukan terlebih dahulu. Sebagai contoh, untuk model LLaMA yang dikeluarkan oleh Meta AI, saiz token inputnya mestilah kurang daripada 2048.
Walau bagaimanapun, dalam aplikasi seperti menjalankan perbualan panjang, meringkaskan dokumen panjang atau melaksanakan rancangan jangka panjang, had tetingkap konteks pratetap selalunya melebihi, dan oleh itu, LLM yang boleh mengendalikan tetingkap konteks yang lebih panjang adalah lebih popular.
Tetapi ini menghadapi masalah baharu Melatih LLM dengan tetingkap konteks yang panjang dari awal memerlukan banyak pelaburan. Ini secara semula jadi membawa kepada persoalan: bolehkah kita memanjangkan tetingkap konteks LLM pra-latihan sedia ada?
Pendekatan mudah adalah untuk memperhalusi Transformer sedia ada yang telah terlatih untuk mendapatkan tetingkap konteks yang lebih panjang. Walau bagaimanapun, keputusan empirikal menunjukkan bahawa model yang dilatih dengan cara ini menyesuaikan diri dengan sangat perlahan kepada tetingkap konteks yang panjang. Selepas 10000 kelompok latihan, peningkatan dalam tetingkap konteks berkesan masih sangat kecil, hanya dari 2048 hingga 2560 (seperti yang boleh dilihat dalam Jadual 4 dalam bahagian eksperimen). Ini menunjukkan bahawa pendekatan ini tidak cekap untuk menskalakan kepada tetingkap konteks yang lebih panjang.
Dalam artikel ini, penyelidik dari Meta memperkenalkan Position Interpolation (PI) untuk melanjutkan tetingkap konteks beberapa LLM pra-latihan sedia ada (termasuk LLaMA). Keputusan menunjukkan bahawa tetingkap konteks LLaMA berskala daripada 2k kepada 32k dengan kurang daripada 1000 langkah penalaan halus.
 Gambar
Gambar
Alamat kertas: https://arxiv.org/pdf/2306.15595.pdf
Idea utama penyelidikan ini, bukan untuk melakukan ekstrapolasi secara langsung indeks, Jadikan indeks kedudukan maksimum sepadan dengan had tetingkap konteks peringkat pra-latihan. Dalam erti kata lain, untuk menampung lebih banyak token input, kajian ini menginterpolasi pengekodan kedudukan pada kedudukan integer bersebelahan, mengambil kesempatan daripada fakta bahawa pengekodan kedudukan boleh digunakan pada kedudukan bukan integer, berbanding dengan mengekstrapolasi di luar kedudukan terlatih. yang terakhir boleh membawa kepada nilai bencana.
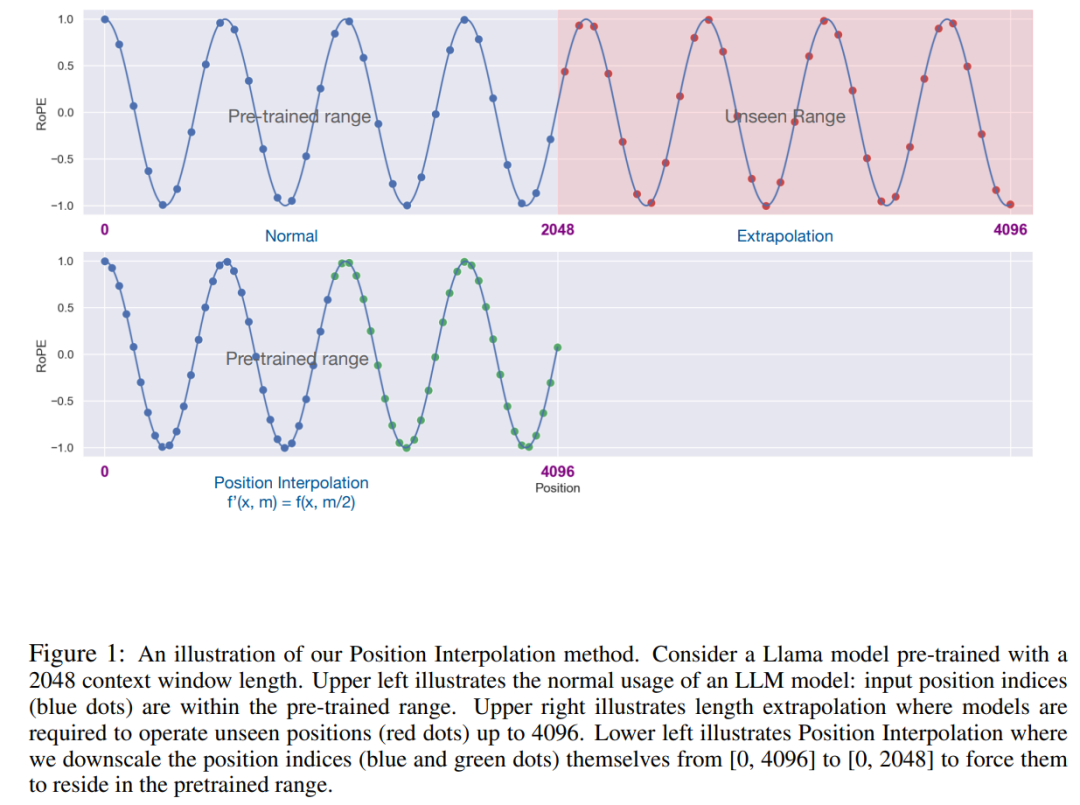
Kaedah PI memanjangkan saiz tetingkap konteks RoPE (pengekodan kedudukan diputar) berasaskan LLM pra-latihan seperti LLaMA kepada sehingga 32768 dengan penalaan halus yang minimum (dalam 1000 langkah), dengan baik pada pelbagai tugas yang memerlukan konteks yang panjang, termasuk pengambilan semula, pemodelan bahasa dan ringkasan dokumen yang panjang daripada LLaMA 7B hingga 65B. Pada masa yang sama, model yang dilanjutkan oleh PI mengekalkan kualiti yang agak baik dalam tetingkap konteks asalnya.
Method
rope hadir dalam model bahasa yang besar seperti Llama, Chatglm-6b, dan Palm yang kita kenal. pengekodan.
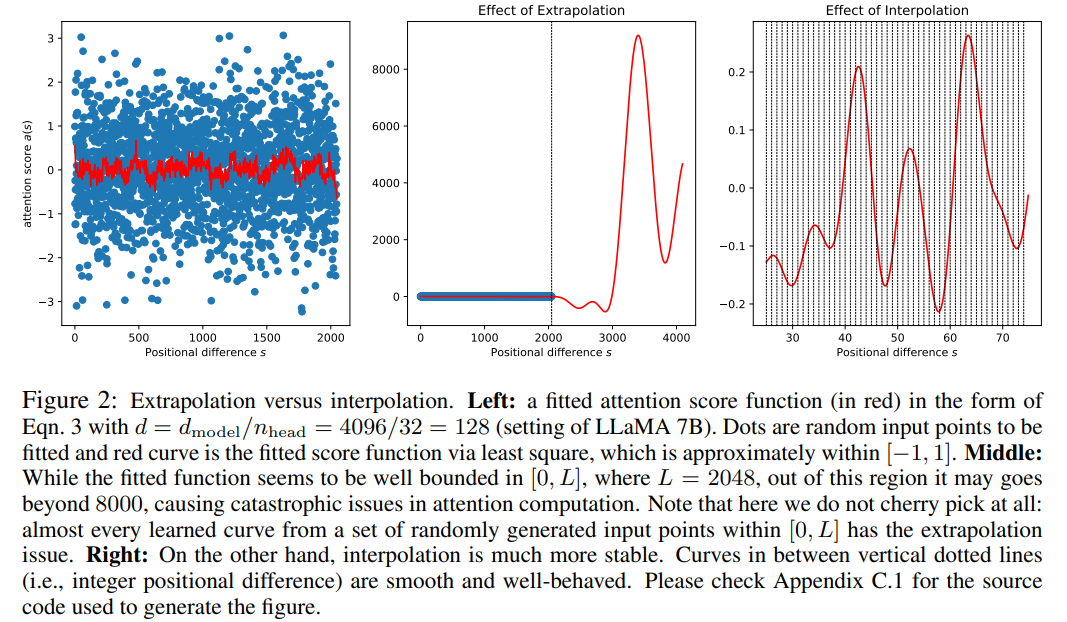
Walaupun skor perhatian dalam RoPE hanya bergantung pada kedudukan relatif, prestasi ekstrapolasinya tidak baik. Khususnya, apabila menskalakan terus ke tetingkap konteks yang lebih besar, kebingungan boleh meningkat kepada angka yang sangat tinggi (iaitu > 10^3).
Artikel ini menggunakan kaedah interpolasi kedudukan, dan perbandingannya dengan kaedah ekstrapolasi adalah seperti berikut. Oleh kerana kelancaran fungsi asas ϕ_j, interpolasi lebih stabil dan tidak membawa kepada outlier.
 Gambar
Gambar
Kajian ini menggantikan RoPE f dengan f ′ dan mendapat formula berikut
 Gambar
Gambar
Kajian ini memanggil penukaran pada interpolasi kedudukan pengekodan kedudukan. Langkah ini mengurangkan indeks kedudukan daripada [0, L′ ) kepada [0, L) untuk memadankan julat indeks asal sebelum mengira RoPE. Oleh itu, sebagai input kepada RoPE, jarak relatif maksimum antara mana-mana dua token telah dikurangkan daripada L 'ke L . Dengan menjajarkan julat indeks kedudukan dan jarak relatif sebelum dan selepas pengembangan, kesan ke atas pengiraan skor perhatian disebabkan pengembangan tetingkap konteks dikurangkan, yang menjadikan model lebih mudah untuk disesuaikan.
Perlu diambil perhatian bahawa kaedah indeks kedudukan penskalaan semula tidak memperkenalkan pemberat tambahan, dan juga tidak mengubah suai seni bina model dalam apa jua cara.
Eksperimen
Kajian ini menunjukkan bahawa interpolasi kedudukan secara berkesan boleh mengembangkan tetingkap konteks kepada 32 kali ganda saiz asal dan bahawa pengembangan ini boleh diselesaikan hanya dalam beberapa ratus langkah latihan.
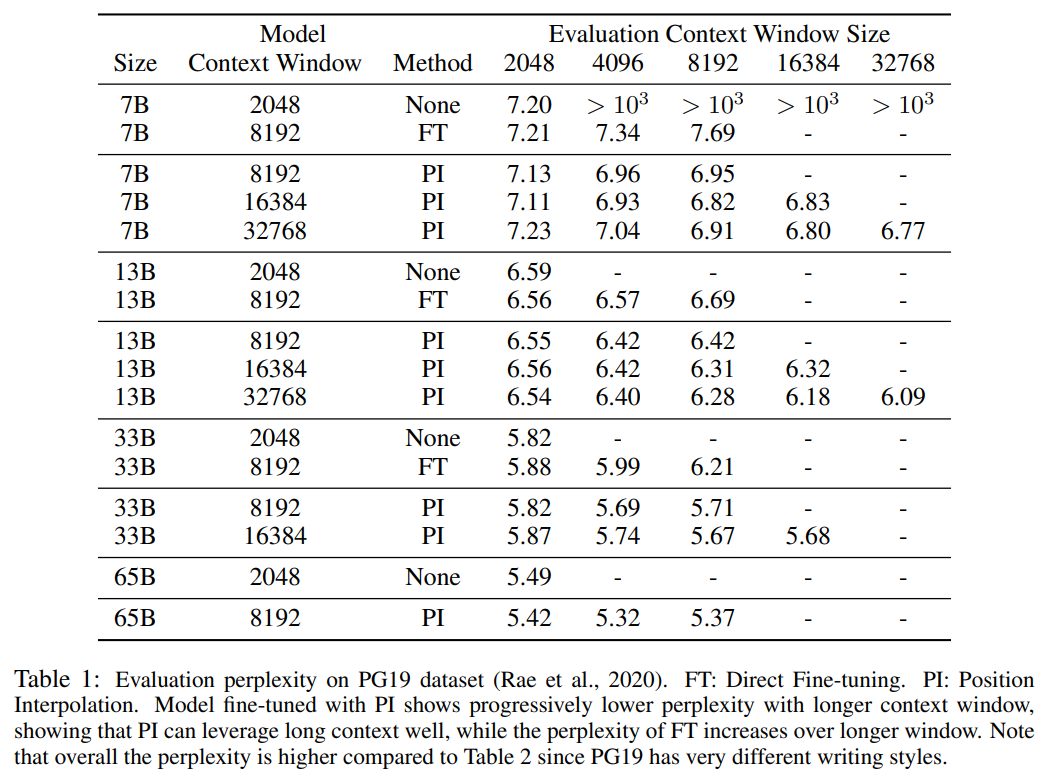
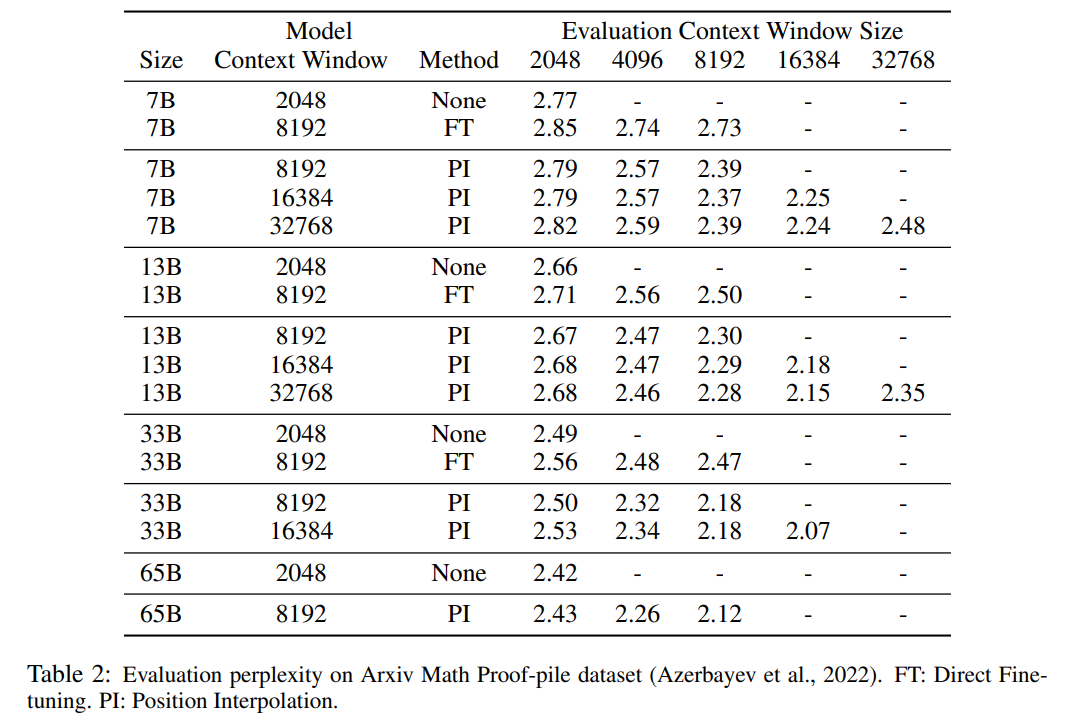
Jadual 1 dan Jadual 2 melaporkan kebingungan model PI dan model garis dasar pada set data cerucuk Bukti Matematik PG-19 dan Arxiv. Keputusan menunjukkan bahawa model yang dilanjutkan menggunakan kaedah PI dengan ketara meningkatkan kebingungan pada saiz tetingkap konteks yang lebih panjang.
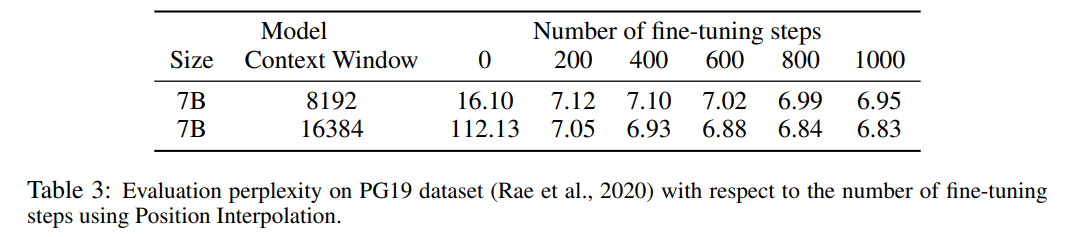
Jadual 3 melaporkan hubungan antara kebingungan dan bilangan langkah penalaan halus apabila memanjangkan model LLaMA 7B kepada saiz tetingkap konteks 8192 dan 16384 menggunakan kaedah PI pada set data PG19.
Ia dapat dilihat daripada keputusan bahawa tanpa penalaan halus (bilangan langkah ialah 0), model boleh menunjukkan keupayaan pemodelan bahasa tertentu, contohnya, apabila tetingkap konteks dikembangkan kepada 8192, kebingungan adalah kurang daripada 20 (berbanding Di bawah, kebingungan kaedah ekstrapolasi langsung adalah lebih besar daripada 10^3). Pada 200 langkah, kebingungan model melebihi model asal pada saiz tetingkap konteks 2048, menunjukkan bahawa model itu dapat menggunakan jujukan yang lebih panjang dengan berkesan untuk pemodelan bahasa berbanding tetapan pra-latihan. Peningkatan mantap dalam model dilihat pada 1000 langkah dan kebingungan yang lebih baik dicapai.
 Gambar
Gambar
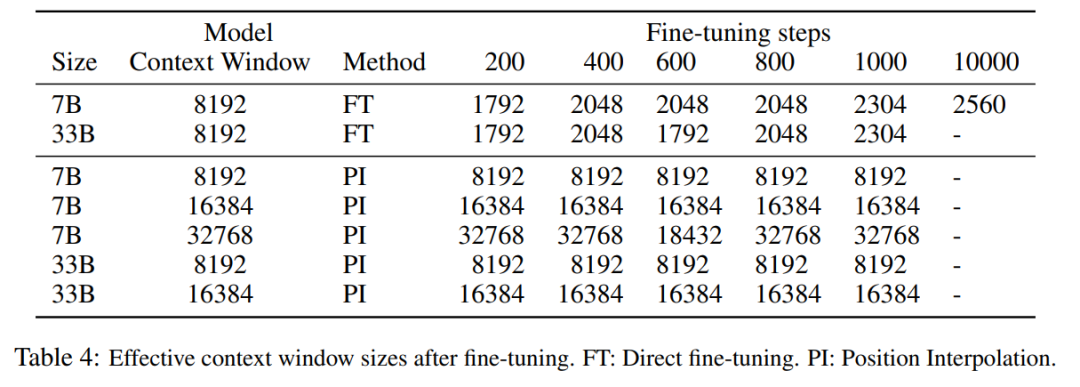
Jadual di bawah menunjukkan bahawa model yang dilanjutkan oleh PI berjaya mencapai matlamat penskalaan dari segi saiz tetingkap konteks yang berkesan, iaitu selepas hanya 200 langkah penalaan halus, saiz tetingkap konteks yang berkesan mencapai nilai maksimum, Konsisten merentas saiz model 7B dan 33B dan sehingga 32768 tetingkap konteks. Sebaliknya, saiz tetingkap konteks berkesan model LLaMA yang dilanjutkan hanya dengan penalaan halus langsung hanya meningkat daripada 2048 kepada 2560, tanpa tanda peningkatan saiz tetingkap dipercepatkan yang ketara walaupun selepas lebih daripada 10000 langkah penalaan halus.
 Gambar
Gambar
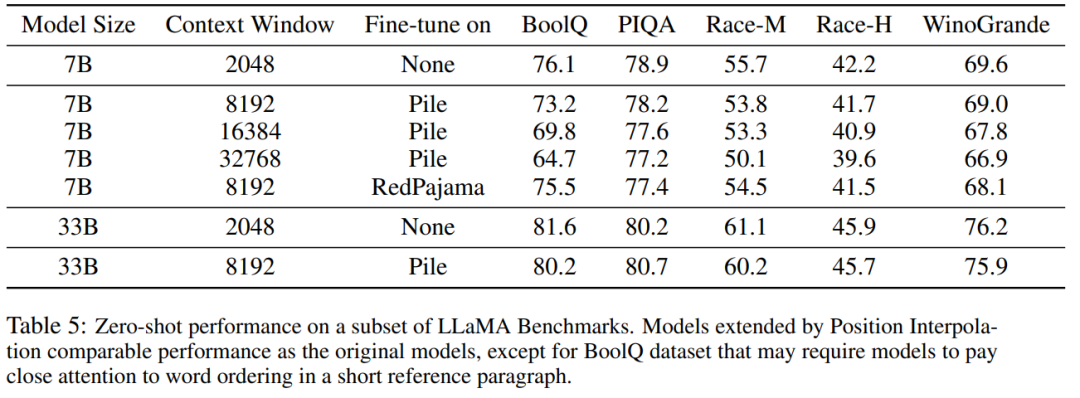
Jadual 5 menunjukkan bahawa model yang dilanjutkan kepada 8192 menghasilkan hasil yang setanding pada tugasan asas asal, yang direka bentuk untuk tetingkap konteks yang lebih kecil, untuk saiz model 7B dan 33B yang mencapai tugasan penanda aras sehingga 2%.
 Gambar
Gambar
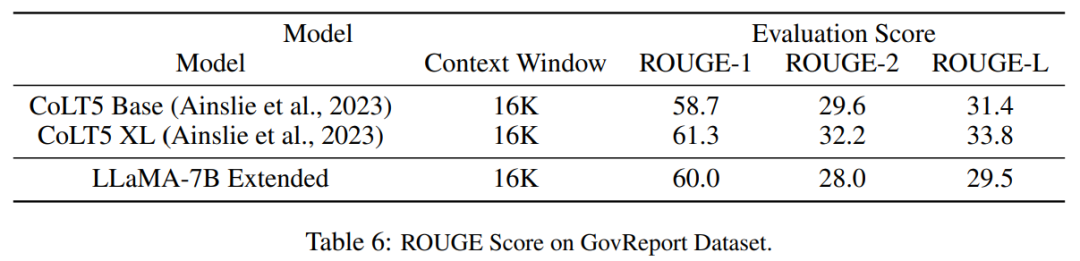
Jadual 6 menunjukkan bahawa model PI dengan tetingkap konteks 16384 boleh mengendalikan tugas ringkasan teks panjang dengan berkesan.
 Gambar
Gambar
Atas ialah kandungan terperinci Penyelidikan baharu oleh pasukan Tian Yuandong: Penalaan halus <1000 langkah, memanjangkan konteks LLaMA kepada 32K. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1371
1371
 52
52

 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
 Alat dengar Meta Quest 3S VR mampu milik baharu muncul di FCC, mencadangkan pelancaran yang akan berlaku
Sep 04, 2024 am 06:51 AM
Alat dengar Meta Quest 3S VR mampu milik baharu muncul di FCC, mencadangkan pelancaran yang akan berlaku
Sep 04, 2024 am 06:51 AM
Acara Meta Connect 2024 ditetapkan pada 25 hingga 26 September, dan dalam acara ini, syarikat itu dijangka memperkenalkan set kepala realiti maya mampu milik baharu. Dikhabarkan sebagai Meta Quest 3S, set kepala VR nampaknya telah muncul pada penyenaraian FCC. cadangan ini
 Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Video terbaru robot Tesla Optimus dikeluarkan, dan ia sudah boleh berfungsi di kilang. Pada kelajuan biasa, ia mengisih bateri (bateri 4680 Tesla) seperti ini: Pegawai itu juga mengeluarkan rupanya pada kelajuan 20x - pada "stesen kerja" kecil, memilih dan memilih dan memilih: Kali ini ia dikeluarkan Salah satu sorotan video itu ialah Optimus menyelesaikan kerja ini di kilang, sepenuhnya secara autonomi, tanpa campur tangan manusia sepanjang proses. Dan dari perspektif Optimus, ia juga boleh mengambil dan meletakkan bateri yang bengkok, memfokuskan pada pembetulan ralat automatik: Berkenaan tangan Optimus, saintis NVIDIA Jim Fan memberikan penilaian yang tinggi: Tangan Optimus adalah robot lima jari di dunia paling cerdik. Tangannya bukan sahaja boleh disentuh
 FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
FisheyeDetNet: algoritma pengesanan sasaran pertama berdasarkan kamera fisheye
Apr 26, 2024 am 11:37 AM
Pengesanan objek ialah masalah yang agak matang dalam sistem pemanduan autonomi, antaranya pengesanan pejalan kaki adalah salah satu algoritma terawal untuk digunakan. Penyelidikan yang sangat komprehensif telah dijalankan dalam kebanyakan kertas kerja. Walau bagaimanapun, persepsi jarak menggunakan kamera fisheye untuk pandangan sekeliling agak kurang dikaji. Disebabkan herotan jejari yang besar, perwakilan kotak sempadan standard sukar dilaksanakan dalam kamera fisheye. Untuk mengurangkan perihalan di atas, kami meneroka kotak sempadan lanjutan, elips dan reka bentuk poligon am ke dalam perwakilan kutub/sudut dan mentakrifkan metrik mIOU pembahagian contoh untuk menganalisis perwakilan ini. Model fisheyeDetNet yang dicadangkan dengan bentuk poligon mengatasi model lain dan pada masa yang sama mencapai 49.5% mAP pada set data kamera fisheye Valeo untuk pemanduan autonomi
 Model sumber terbuka pertama yang melepasi tahap GPT4o! Llama 3.1 bocor: 405 bilion parameter, pautan muat turun dan kad model tersedia
Jul 23, 2024 pm 08:51 PM
Model sumber terbuka pertama yang melepasi tahap GPT4o! Llama 3.1 bocor: 405 bilion parameter, pautan muat turun dan kad model tersedia
Jul 23, 2024 pm 08:51 PM
Sediakan GPU anda! Llama3.1 akhirnya muncul, tetapi sumbernya bukan Meta rasmi. Hari ini, berita bocor versi baharu model besar Llama menjadi tular di Reddit Selain model asas, ia juga termasuk hasil penanda aras 8B, 70B dan parameter maksimum 405B. Rajah di bawah menunjukkan hasil perbandingan setiap versi Llama3.1 dengan OpenAIGPT-4o dan Llama38B/70B. Ia boleh dilihat bahawa walaupun versi 70B melebihi GPT-4o pada pelbagai penanda aras. Sumber imej: https://x.com/mattshumer_/status/1815444612414087294 Jelas sekali, versi 3.1 daripada 8B dan 70
 Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
Satu kad menjalankan Llama 70B lebih pantas daripada dua kad, Microsoft hanya meletakkan FP6 ke dalam A100 |
Apr 29, 2024 pm 04:55 PM
FP8 dan ketepatan pengiraan titik terapung yang lebih rendah bukan lagi "paten" H100! Lao Huang mahu semua orang menggunakan INT8/INT4, dan pasukan Microsoft DeepSpeed memaksa diri mereka menjalankan FP6 pada A100 tanpa sokongan rasmi daripada Nvidia. Keputusan ujian menunjukkan bahawa kaedah baharu TC-FPx FP6 kuantisasi pada A100 adalah hampir atau kadangkala lebih pantas daripada INT4, dan mempunyai ketepatan yang lebih tinggi daripada yang terakhir. Selain itu, terdapat juga sokongan model besar hujung ke hujung, yang telah bersumberkan terbuka dan disepadukan ke dalam rangka kerja inferens pembelajaran mendalam seperti DeepSpeed. Keputusan ini juga mempunyai kesan serta-merta pada mempercepatkan model besar - di bawah rangka kerja ini, menggunakan satu kad untuk menjalankan Llama, daya pemprosesan adalah 2.65 kali lebih tinggi daripada dua kad. satu
