
 Peranti teknologi
AI
Dia boleh mengatasi manusia dalam masa dua jam! Kelajuan AI terbaharu DeepMind menjalankan 26 permainan Atari
Peranti teknologi
AI
Dia boleh mengatasi manusia dalam masa dua jam! Kelajuan AI terbaharu DeepMind menjalankan 26 permainan Atari
Dia boleh mengatasi manusia dalam masa dua jam! Kelajuan AI terbaharu DeepMind menjalankan 26 permainan Atari

Ejen AI DeepMind mengusik dirinya sendiri lagi!
Lihat lelaki bernama BBF ini, dia menguasai 26 permainan Atari dalam masa 2 jam sahaja.
Anda mesti tahu bahawa ejen AI sentiasa berkesan dalam menyelesaikan masalah melalui pembelajaran pengukuhan, tetapi masalah terbesar ialah kaedah ini sangat tidak cekap dan memerlukan masa yang lama untuk diterokai.
 Gambar
Gambar
Kejayaan yang dibawakan oleh BBF adalah tepat dari segi kecekapan.
Tidak hairanlah nama penuhnya boleh dipanggil Bigger, Better, atau Faster.
Dan ia boleh melengkapkan latihan hanya pada satu kad, dan keperluan kuasa pengkomputeran juga jauh berkurangan.
BBF telah dicadangkan bersama oleh Google DeepMind dan Universiti Montreal Data dan kod ini adalah sumber terbuka.
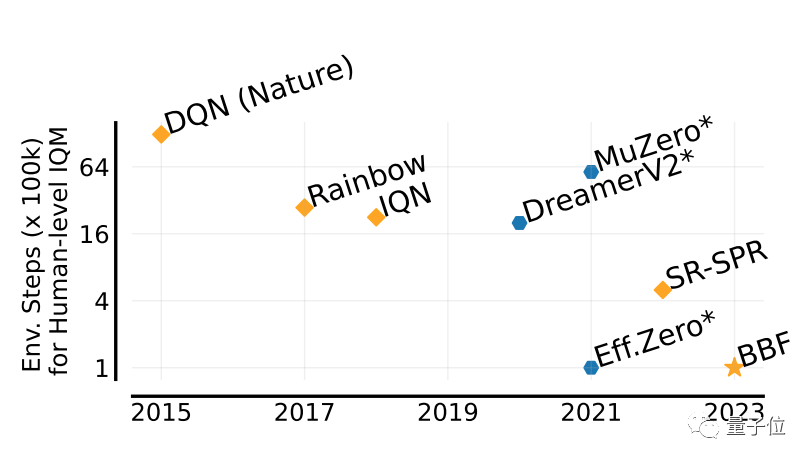
Boleh mencapai sehingga 5 kali ganda prestasi manusia
Nilai yang digunakan untuk menilai prestasi permainan BBF dipanggil IQM.
IQM ialah skor komprehensif bagi prestasi permainan pelbagai aspek Markah IQM dalam artikel ini dinormalkan berdasarkan manusia.
Berbanding dengan beberapa keputusan sebelumnya, BBF mencapai skor IQM tertinggi dalam set data ujian Atari 100K yang mengandungi 26 permainan Atari.
Dan, dalam 26 permainan yang telah dilatih, prestasi BBF telah melebihi prestasi manusia.
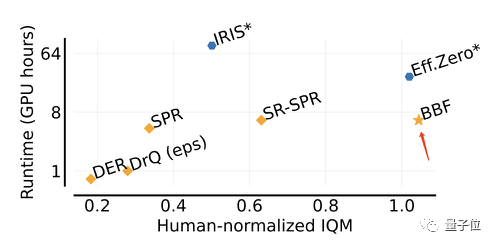
Berbanding dengan Eff.Zero, yang berprestasi serupa, BBF menggunakan hampir separuh masa GPU.
Bagi SPR dan SR-SPR, yang menggunakan masa GPU yang sama, prestasi mereka jauh di belakang BBF.
 Gambar
Gambar
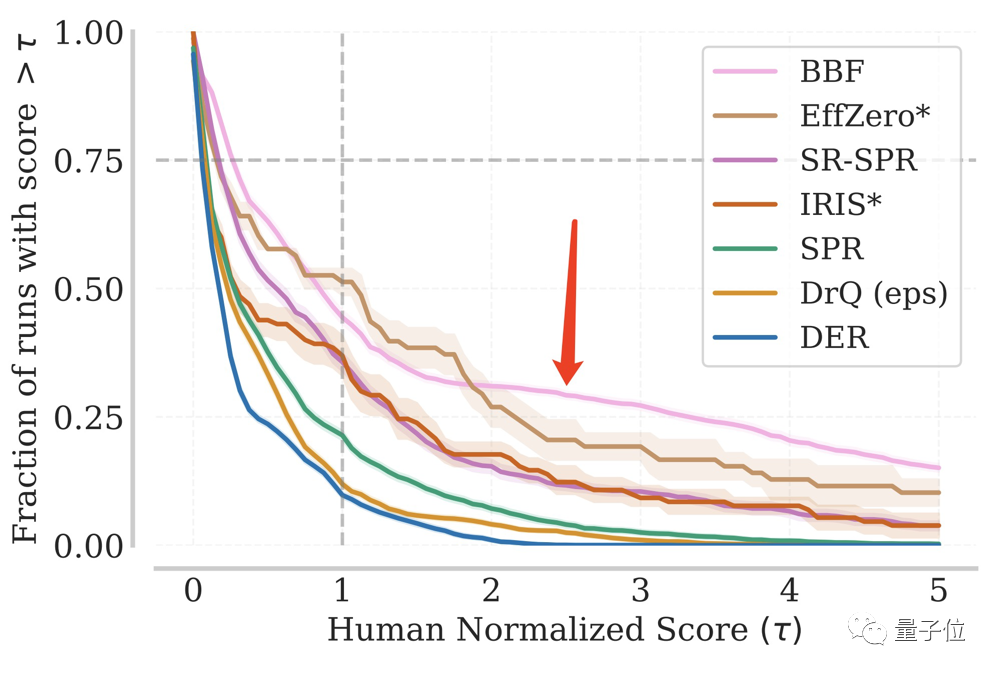
Dalam ujian berulang, bahagian BBF mencapai skor IQM tertentu sentiasa kekal pada tahap yang tinggi.
Walaupun dalam lebih 1/8 daripada jumlah ujian dijalankan, ia mencapai 5 kali ganda prestasi manusia.
 Gambar
Gambar
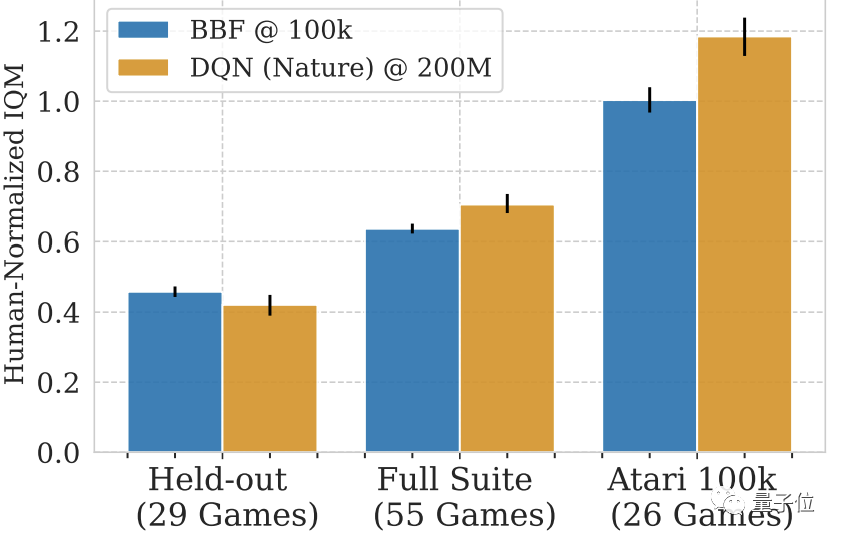
Walaupun dengan penambahan permainan Atari lain tanpa latihan, BBF boleh mencapai lebih daripada separuh skor IQM manusia.
Jika anda melihat 29 permainan yang tidak terlatih ini sahaja, markah BBF adalah 40 hingga 50% berbanding manusia.
 Gambar
Gambar
Diubah suai berdasarkan SR-SPR
Masalah yang mendorong penyelidikan BBF ialah bagaimana mengembangkan rangkaian pembelajaran pengukuhan yang mendalam apabila saiz sampel adalah jarang.
Untuk mengkaji masalah ini, DeepMind memfokuskan pada penanda aras Atari 100K.
Tetapi DeepMind tidak lama kemudian mendapati bahawa hanya meningkatkan saiz model tidak meningkatkan prestasinya.
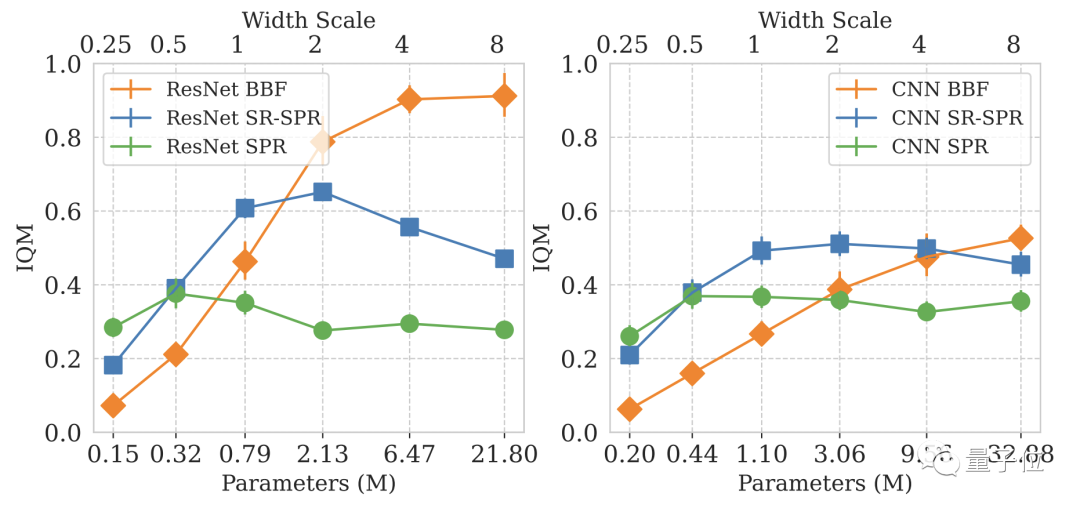 Gambar
Gambar
Dalam reka bentuk model pembelajaran mendalam, bilangan kemas kini setiap langkah (Nisbah Main Semula, RR) ialah parameter penting.
Khusus untuk permainan Atari, lebih besar nilai RR, lebih tinggi prestasi model dalam permainan.
Akhir sekali, DeepMind menggunakan SR-SPR sebagai enjin asas, dan nilai RR SR-SPR boleh mencecah sehingga 16.
Selepas pertimbangan menyeluruh, DeepMind memilih 8 sebagai nilai RR BBF.
Memandangkan sesetengah pengguna tidak mahu membelanjakan kos pengkomputeran RR=8, DeepMind turut membangunkan versi RR=2 BBF
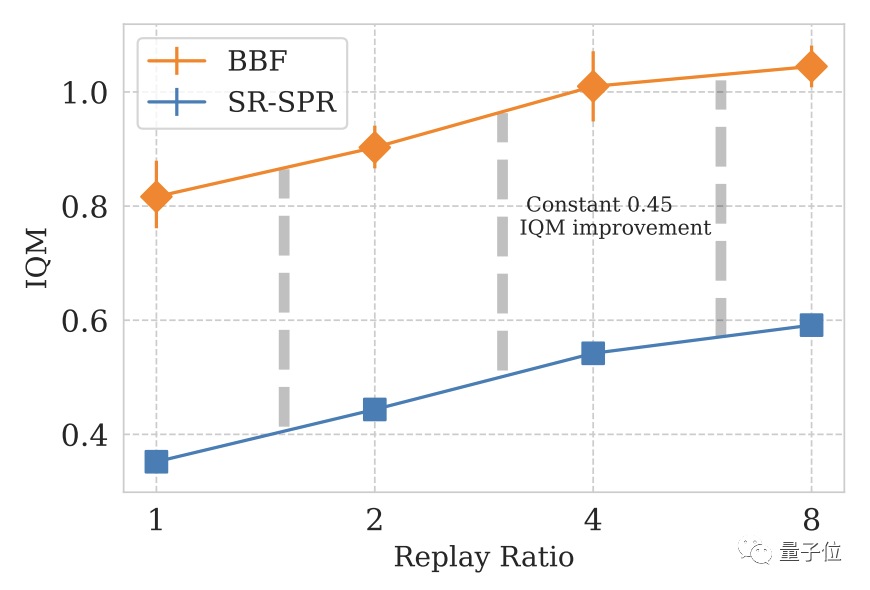 Pictures
Pictures
Selepas DeepMind mengubah suai banyak kandungan dalam SR-SPR sendiri, ia menerima pakai sendiri. Latihan penyeliaan yang diperolehi oleh BBF terutamanya merangkumi aspek berikut:
- Kekuatan tetapan semula lapisan lilitan yang lebih tinggi: Meningkatkan kekuatan set semula lapisan lilitan boleh meningkatkan amplitud gangguan untuk sasaran rawak, membolehkan model berprestasi lebih baik dan mengurangkan kehilangan Selepas kekuatan set semula BBF ditingkatkan, amplitud gangguan berubah daripada SR kepada SR . -SPR meningkat daripada 20% kepada 50%
- Saiz rangkaian yang lebih besar: Tingkatkan bilangan lapisan rangkaian saraf daripada 3 kepada 15 lapisan, dan tingkatkan lebar sebanyak 4 kali ganda
- Pengurangan julat (n) kemas kini: Ingin menambah baik model Prestasi memerlukan penggunaan nilai tidak tetap n. BBF ditetapkan semula setiap 40,000 langkah kecerunan Dalam 10,000 langkah kecerunan pertama setiap tetapan semula, n berkurangan secara eksponen daripada 10 kepada 3. Fasa pereputan menyumbang 25% daripada proses latihan BBF
- Faktor pereputan yang lebih besar (γ): Sesetengah orang mempunyai didapati peningkatan nilai γ semasa proses pembelajaran boleh meningkatkan prestasi model Nilai γ BBF meningkat daripada 0.97 tradisional kepada 0.997
- Pengecilan berat badan: Untuk mengelakkan berlakunya overfitting, pengecilan BBF adalah lebih kurang 0.1
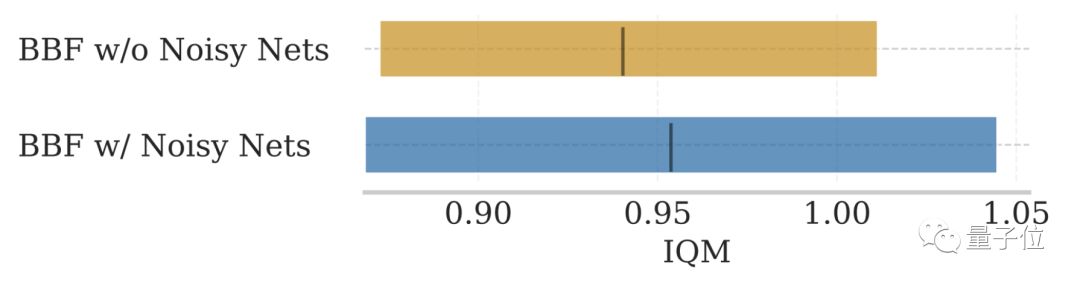
- Delete NoisyNet : NoisyNet yang disertakan dalam SR-SPR asal tidak dapat meningkatkan prestasi model
Hasil percubaan ablasi menunjukkan bahawa di bawah syarat 2 dan 8 kemas kini setiap langkah, faktor di atas mempunyai tahap kesan yang berbeza-beza terhadap prestasi BBF.
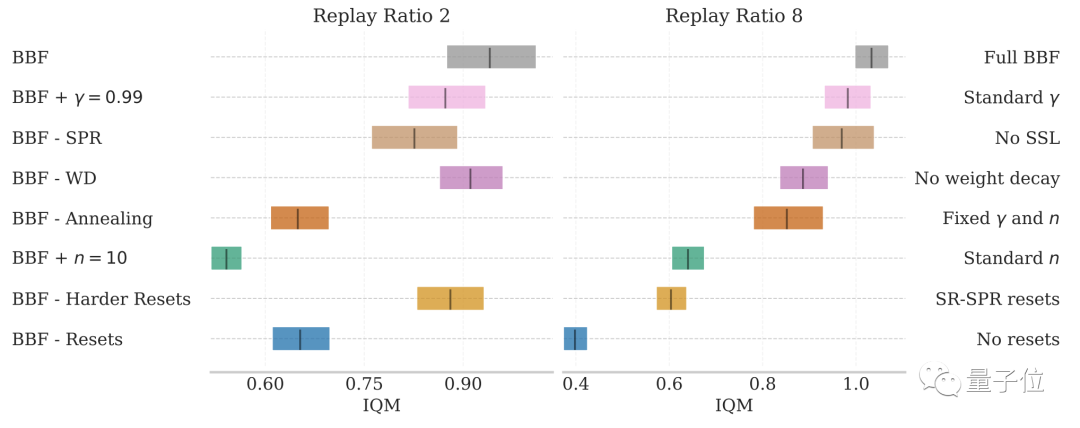 Gambar
Gambar
Antaranya, kesan tetapan semula keras dan pengurangan julat kemas kini adalah yang paling ketara.
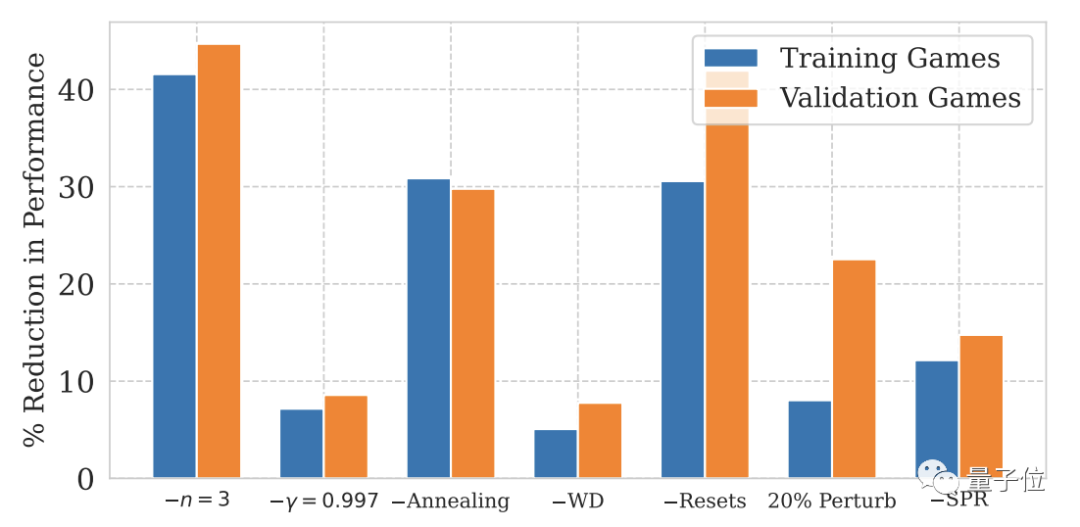 Pictures
Pictures
Untuk NoisyNet, yang tidak disebut dalam dua angka di atas, kesan ke atas prestasi model tidak ketara.
 Gambar
Gambar
Alamat kertas: https://arxiv.org/abs/2305.19452Halaman projek GitHub: https://github.com/google-research/google-research/tree/master_faster_better Pautan rujukan: [1]
https://www.php.cn/link/69b4fa3be19bdf400df34e41b93636a4[2]https://www.marktechpost.com/2023/06/12/superhuman-the-performance -atari-100k-penanda aras-kuasa-bbf-ejen-rl-berasaskan-nilai-baru-dari-google-deepmind-mila-and-universite-de-montreal/
— Tamat —
Atas ialah kandungan terperinci Dia boleh mengatasi manusia dalam masa dua jam! Kelajuan AI terbaharu DeepMind menjalankan 26 permainan Atari. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Apakah sintaks untuk menambah lajur dalam SQL
Apr 09, 2025 pm 02:51 PM
Apakah sintaks untuk menambah lajur dalam SQL
Apr 09, 2025 pm 02:51 PM
Sintaks untuk menambah lajur dalam sql adalah alter table table_name tambah column_name data_type [not null] [default default_value]; Di mana table_name adalah nama jadual, column_name adalah nama lajur baru, data_type adalah jenis data, tidak null menentukan sama ada nilai null dibenarkan, dan lalai default_value menentukan nilai lalai.
 Jadual Jelas SQL: Petua Pengoptimuman Prestasi
Apr 09, 2025 pm 02:54 PM
Jadual Jelas SQL: Petua Pengoptimuman Prestasi
Apr 09, 2025 pm 02:54 PM
Petua untuk Meningkatkan Prestasi Pembersihan Jadual SQL: Gunakan jadual Truncate dan bukannya memadam, membebaskan ruang dan menetapkan semula lajur Identiti. Lumpuhkan kekangan utama asing untuk mengelakkan penghapusan cascading. Gunakan operasi enkapsulasi transaksi untuk memastikan konsistensi data. Batch memadam data besar dan hadkan bilangan baris melalui had. Membina semula indeks selepas membersihkan untuk meningkatkan kecekapan pertanyaan.
 Gunakan penyataan padam untuk membersihkan jadual SQL
Apr 09, 2025 pm 03:00 PM
Gunakan penyataan padam untuk membersihkan jadual SQL
Apr 09, 2025 pm 03:00 PM
Ya, pernyataan padam boleh digunakan untuk membersihkan jadual SQL, langkah -langkahnya adalah seperti berikut: Gunakan pernyataan padam: padam dari meja_name; Ganti Table_name dengan nama jadual untuk dibersihkan.
 phpmyadmin mencipta jadual data
Apr 10, 2025 pm 11:00 PM
phpmyadmin mencipta jadual data
Apr 10, 2025 pm 11:00 PM
Untuk membuat jadual data menggunakan phpmyadmin, langkah -langkah berikut adalah penting: Sambungkan ke pangkalan data dan klik tab baru. Namakan jadual dan pilih enjin penyimpanan (disyorkan innoDB). Tambah butiran lajur dengan mengklik butang Tambah Lajur, termasuk nama lajur, jenis data, sama ada untuk membenarkan nilai null, dan sifat lain. Pilih satu atau lebih lajur sebagai kunci utama. Klik butang Simpan untuk membuat jadual dan lajur.
 Bagaimana untuk menangani pemecahan memori Redis?
Apr 10, 2025 pm 02:24 PM
Bagaimana untuk menangani pemecahan memori Redis?
Apr 10, 2025 pm 02:24 PM
Pemecahan ingatan redis merujuk kepada kewujudan kawasan bebas kecil dalam ingatan yang diperuntukkan yang tidak dapat ditugaskan semula. Strategi mengatasi termasuk: Mulakan semula Redis: Kosongkan memori sepenuhnya, tetapi perkhidmatan mengganggu. Mengoptimumkan struktur data: Gunakan struktur yang lebih sesuai untuk Redis untuk mengurangkan bilangan peruntukan dan siaran memori. Laraskan parameter konfigurasi: Gunakan dasar untuk menghapuskan pasangan nilai kunci yang paling kurang baru-baru ini. Gunakan mekanisme kegigihan: sandarkan data secara teratur dan mulakan semula redis untuk membersihkan serpihan. Pantau penggunaan memori: Cari masalah tepat pada masanya dan ambil langkah.
 Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:33 PM
Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:33 PM
Mewujudkan pangkalan data Oracle tidak mudah, anda perlu memahami mekanisme asas. 1. Anda perlu memahami konsep pangkalan data dan Oracle DBMS; 2. Menguasai konsep teras seperti SID, CDB (pangkalan data kontena), PDB (pangkalan data pluggable); 3. Gunakan SQL*Plus untuk membuat CDB, dan kemudian buat PDB, anda perlu menentukan parameter seperti saiz, bilangan fail data, dan laluan; 4. Aplikasi lanjutan perlu menyesuaikan set aksara, memori dan parameter lain, dan melakukan penalaan prestasi; 5. Beri perhatian kepada ruang cakera, keizinan dan parameter, dan terus memantau dan mengoptimumkan prestasi pangkalan data. Hanya dengan menguasai ia dengan mahir memerlukan amalan yang berterusan, anda boleh benar -benar memahami penciptaan dan pengurusan pangkalan data Oracle.
 Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:36 PM
Cara Membuat Pangkalan Data Oracle Cara Membuat Pangkalan Data Oracle
Apr 11, 2025 pm 02:36 PM
Untuk membuat pangkalan data Oracle, kaedah biasa adalah menggunakan alat grafik DBCA. Langkah -langkah adalah seperti berikut: 1. Gunakan alat DBCA untuk menetapkan DBName untuk menentukan nama pangkalan data; 2. Tetapkan SYSPASSWORD dan SYSTEMPASSWORD kepada kata laluan yang kuat; 3. Tetapkan aksara dan NationalCharacterset ke Al32utf8; 4. Tetapkan MemorySize dan Tablespacesize untuk menyesuaikan mengikut keperluan sebenar; 5. Tentukan laluan logfile. Kaedah lanjutan dibuat secara manual menggunakan arahan SQL, tetapi lebih kompleks dan terdedah kepada kesilapan. Perhatikan kekuatan kata laluan, pemilihan set aksara, saiz dan memori meja makan
 Pantau titisan redis dengan perkhidmatan pengeksport redis
Apr 10, 2025 pm 01:36 PM
Pantau titisan redis dengan perkhidmatan pengeksport redis
Apr 10, 2025 pm 01:36 PM
Pemantauan yang berkesan terhadap pangkalan data REDIS adalah penting untuk mengekalkan prestasi yang optimum, mengenal pasti kemungkinan kesesakan, dan memastikan kebolehpercayaan sistem keseluruhan. Perkhidmatan Pengeksport Redis adalah utiliti yang kuat yang direka untuk memantau pangkalan data REDIS menggunakan Prometheus. Tutorial ini akan membimbing anda melalui persediaan lengkap dan konfigurasi perkhidmatan pengeksport REDIS, memastikan anda membina penyelesaian pemantauan dengan lancar. Dengan mengkaji tutorial ini, anda akan mencapai tetapan pemantauan operasi sepenuhnya
