
 Peranti teknologi
AI
NTU dan Shanghai AI Lab menyusun 300+ kertas kerja: ulasan terkini pembahagian visual berdasarkan Transformer dikeluarkan
Peranti teknologi
AI
NTU dan Shanghai AI Lab menyusun 300+ kertas kerja: ulasan terkini pembahagian visual berdasarkan Transformer dikeluarkan
NTU dan Shanghai AI Lab menyusun 300+ kertas kerja: ulasan terkini pembahagian visual berdasarkan Transformer dikeluarkan

SAM (Segmen Anything), sebagai model segmentasi visual asas, telah menarik perhatian dan susulan ramai penyelidik dalam masa 3 bulan sahaja. Jika anda ingin memahami secara sistematik teknologi di sebalik SAM, bersaing dengan rentak involusi, dan boleh membuat model SAM anda sendiri, maka Tinjauan Segmentasi Berasaskan Transformer ini tidak boleh dilepaskan! Baru-baru ini, beberapa penyelidik dari Universiti Teknologi Nanyang dan Makmal Kepintaran Buatan Shanghai telah menulis ulasan tentang Segmentasi Berasaskan Transformer, secara sistematik menyemak model segmentasi dan pengesanan berdasarkan Transformer dalam beberapa tahun kebelakangan ini Model terbaharu yang disiasat adalah sehingga Jun tahun ini! Pada masa yang sama, semakan itu juga termasuk kertas kerja terkini dalam bidang berkaitan dan sejumlah besar analisis dan perbandingan eksperimen, dan mendedahkan beberapa hala tuju penyelidikan masa depan dengan prospek yang luas!
Segmentasi visual direka bentuk untuk memisahkan imej, bingkai video atau titik awan kepada berbilang segmen atau kumpulan. Teknologi ini mempunyai banyak aplikasi dunia nyata, seperti pemanduan autonomi, penyuntingan imej, persepsi robot dan analisis perubatan. Sepanjang dekad yang lalu, kaedah berasaskan pembelajaran mendalam telah mencapai kemajuan yang ketara dalam bidang ini. Baru-baru ini, Transformer telah menjadi rangkaian saraf berdasarkan mekanisme perhatian kendiri, pada asalnya direka untuk pemprosesan bahasa semula jadi, yang dengan ketara mengatasi kaedah konvolusi atau berulang sebelumnya dalam pelbagai tugas pemprosesan visual. Khususnya, Vision Transformer menyediakan penyelesaian yang berkuasa, bersatu dan lebih mudah untuk pelbagai tugasan segmentasi. Tinjauan ini memberikan gambaran menyeluruh tentang segmentasi visual berasaskan Transformer, meringkaskan kemajuan terkini. Pertama, kertas inimenyemak latar belakang, termasuk definisi masalah, set data dan kaedah lilitan sebelumnya. Seterusnya, kertas kerja ini meringkaskan meta-architecture yang menyatukan semua kaedah berasaskan Transformer terkini. Berdasarkan meta-architecture ini, artikel ini mengkaji pelbagai reka bentuk kaedah, termasuk pengubahsuaian kepada meta-architecture ini dan aplikasi yang berkaitan. Selain itu, artikel ini juga memperkenalkan beberapa tetapan berkaitan, termasuk segmentasi awan titik 3D, penalaan model asas, segmentasi adaptif domain, segmentasi cekap dan segmentasi perubatan. Tambahan pula, kertas kerja ini menyusun dan menilai semula kaedah ini pada beberapa set data yang diiktiraf secara meluas. Akhir sekali, kertas kerja mengenal pasti cabaran terbuka dalam bidang ini dan mencadangkan arah untuk penyelidikan masa depan. Artikel ini akan meneruskan dan menjejak kaedah segmentasi dan pengesanan berasaskan Transformer terkini.
Gambar Alamat projek: https://github.com/lxtGH/Awesome-Segmentation-With-Transformer
Alamat projek: https://github.com/lxtGH/Awesome-Segmentation-With-Transformer
Alamat kertas: https://arxi98v.pdf
Motivasi penyelidikan
Kemunculan ViT dan DETR telah mencapai kemajuan penuh dalam bidang segmentasi dan pengesanan Pada masa ini, kaedah kedudukan teratas pada hampir setiap tanda aras set data adalah berdasarkan Transformer. Atas sebab ini, adalah perlu untuk merumuskan secara sistematik dan membandingkan kaedah dan ciri teknikal arah ini.
- Seni bina model besar terkini semuanya berdasarkan struktur Transformer, termasuk model berbilang mod dan model asas segmentasi (SAM), dan pelbagai tugas visual semakin hampir kepada pemodelan model bersatu.
- Segmentasi dan pengesanan telah menghasilkan banyak tugas hiliran yang berkaitan, dan kebanyakan tugas ini juga diselesaikan menggunakan struktur Transformer.
- Ciri Semakan
- Sistematik dan boleh dibaca.
- Artikel ini menyemak secara sistematik setiap definisi tugas bagi pembahagian, serta definisi tugas dan penunjuk penilaian yang berkaitan. Dan artikel ini bermula daripada kaedah konvolusi dan meringkaskan seni bina meta berdasarkan ViT dan DETR. Berdasarkan meta-architecture ini, ulasan ini meringkaskan dan meringkaskan kaedah yang berkaitan, dan secara sistematik menyemak kaedah terkini. Laluan semakan teknikal khusus ditunjukkan dalam Rajah 1. Klasifikasi terperinci dari perspektif teknikal.
- Berbanding dengan ulasan Transformer sebelumnya, klasifikasi kaedah artikel ini akan lebih terperinci. Artikel ini menghimpunkan kertas kerja dengan idea yang serupa dan membandingkan persamaan dan perbezaannya. Sebagai contoh, artikel ini akan mengklasifikasikan kaedah yang secara serentak mengubah suai bahagian penyahkod meta-seni bina kepada Perhatian Silang berasaskan imej dan pemodelan Perhatian Silang spatio-temporal berasaskan video. Kekomprehensif soalan kajian.
- Artikel ini akan menyemak semua arah pembahagian secara sistematik, termasuk tugasan pembahagian imej, video dan awan titik. Pada masa yang sama, artikel ini juga akan menyemak arah yang berkaitan seperti model segmentasi dan pengesanan set terbuka, segmentasi tanpa pengawasan dan segmentasi yang diselia dengan lemah.
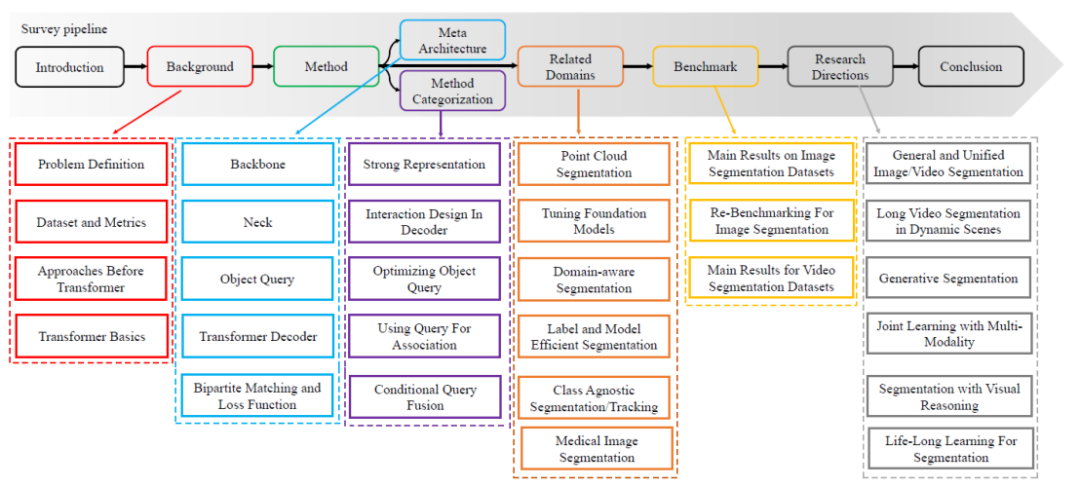 Rajah 1. Pelan hala kandungan tinjauan
Rajah 1. Pelan hala kandungan tinjauan
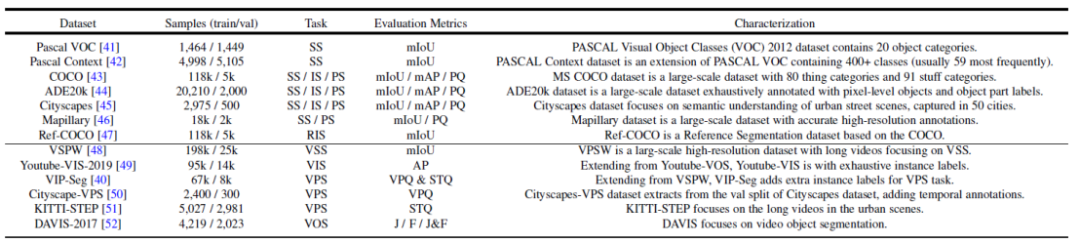
Figure 2. Ringkasan set data yang biasa digunakan dan tugas segmentasi
Segmentasi dan kaedah pengesanan berasaskan Ringkasan Ringkasan dan perbandingan
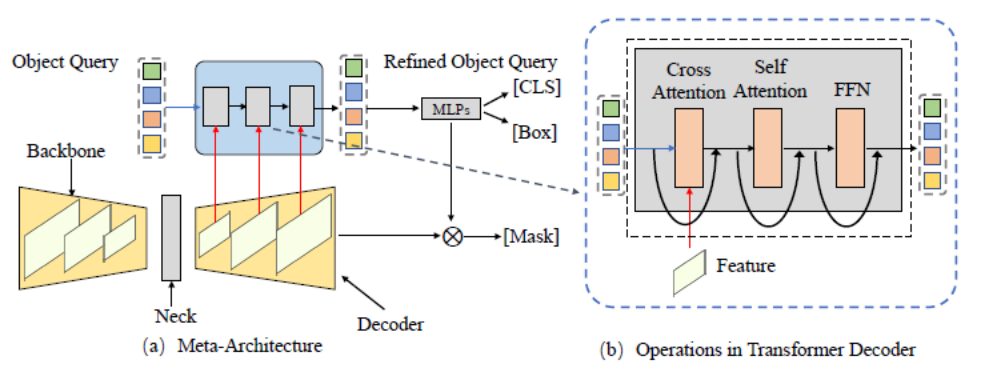
- Seni Bina)
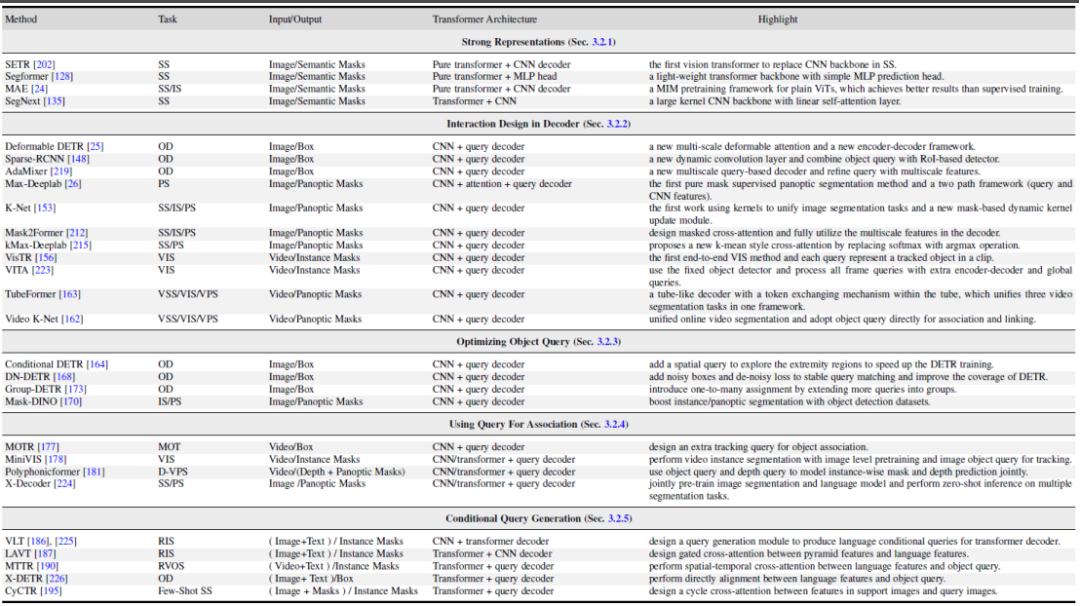
Artikel ini mula-mula meringkaskan seni bina meta berdasarkan rangka kerja DETR dan MaskFormer. Model ini termasuk modul berbeza berikut:
- Tulang belakang: Pengekstrak ciri, digunakan untuk mengekstrak ciri imej.
- Leher: Bina ciri berbilang skala untuk mengendalikan objek berbilang skala.
- Pertanyaan Objek: Objek pertanyaan, digunakan untuk mewakili setiap entiti dalam pemandangan, termasuk objek latar depan dan objek latar belakang.
- Penyahkod: penyahkod, digunakan untuk mengoptimumkan Pertanyaan Objek secara beransur-ansur dan ciri yang sepadan.
- Latihan Hujung-ke-Hujung: Reka bentuk berdasarkan Pertanyaan Objek boleh mencapai pengoptimuman hujung ke hujung.
Berdasarkan meta-architecture ini, kaedah sedia ada boleh dibahagikan kepada lima arah berbeza berikut untuk pengoptimuman dan pelarasan mengikut tugasan Seperti yang ditunjukkan dalam Rajah 4, setiap arah mengandungi beberapa sub-arah yang berbeza.
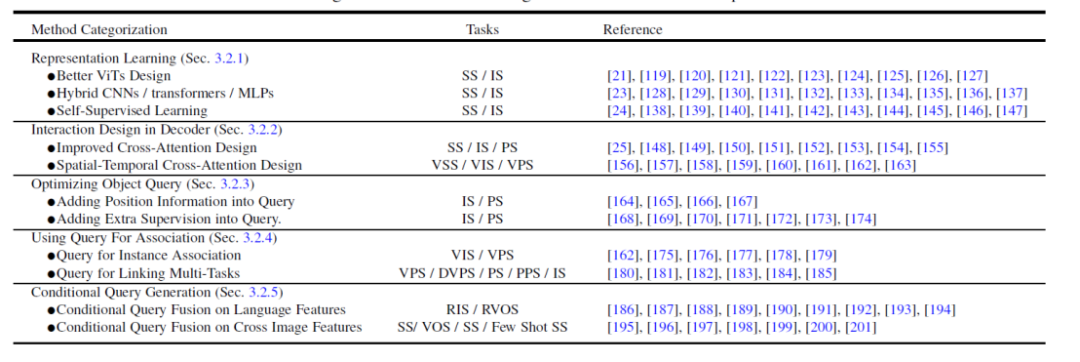
Rajah 4. Ringkasan dan perbandingan kaedah Segmentasi Berasaskan Transformer
- Pembelajaran ekspresi ciri yang lebih baik, Pembelajaran Perwakilan. Perwakilan ciri visual yang berkuasa sentiasa membawa kepada hasil pembahagian yang lebih baik. Artikel ini membahagikan kerja berkaitan kepada tiga aspek: reka bentuk Transformer visual yang lebih baik, CNN/Transformer/MLP hibrid dan pembelajaran diselia sendiri.
- Reka bentuk kaedah di bahagian penyahkod, Reka Bentuk Interaksi dalam Dekoder. Bab ini mengkaji reka bentuk penyahkod Transformer baharu. Kertas kerja ini membahagikan reka bentuk penyahkod kepada dua kumpulan: satu untuk menambah baik reka bentuk perhatian silang dalam pembahagian imej, dan satu lagi untuk reka bentuk perhatian silang spasio-temporal dalam pembahagian video. Yang pertama memberi tumpuan kepada mereka bentuk penyahkod yang lebih baik yang menambah baik pada yang dalam DETR asal. Yang terakhir memanjangkan pengesan dan penyegmen objek berasaskan objek pertanyaan kepada domain video untuk pengesanan objek video (VOD), pembahagian contoh video (VIS) dan pembahagian piksel video (VPS), memfokuskan pada pemodelan konsistensi dan korelasi temporal.
- Cuba untuk Mengoptimumkan Pertanyaan Objek dari perspektif pengoptimuman objek pertanyaan. Berbanding dengan Faster-RCNN, DETR mempunyai jadual penumpuan yang lebih panjang. Disebabkan oleh peranan utama objek pertanyaan, beberapa kaedah sedia ada telah dikaji untuk mempercepatkan latihan dan meningkatkan prestasi. Mengikut kaedah pertanyaan objek, kertas ini membahagikan literatur berikut kepada dua aspek: menambah maklumat lokasi dan menggunakan penyeliaan tambahan. Maklumat lokasi menyediakan petunjuk untuk persampelan latihan pantas ciri pertanyaan. Penyeliaan tambahan memberi tumpuan kepada mereka bentuk fungsi kerugian khusus sebagai tambahan kepada fungsi kehilangan lalai DETR.
- Gunakan objek pertanyaan untuk mengaitkan ciri dan kejadian, Menggunakan Pertanyaan Untuk Persatuan. Memanfaat daripada kesederhanaan objek pertanyaan, beberapa kajian terkini telah menggunakannya sebagai alat korelasi untuk menyelesaikan tugasan hiliran. Terdapat dua kegunaan utama: satu ialah perkaitan peringkat contoh, dan satu lagi ialah perkaitan peringkat tugas. Yang pertama menggunakan idea diskriminasi contoh untuk menyelesaikan masalah padanan peringkat contoh dalam video, seperti pembahagian dan penjejakan video. Yang terakhir menggunakan objek pertanyaan untuk merapatkan subtugas yang berbeza untuk mencapai pembelajaran berbilang tugas yang cekap.
- Penjanaan objek pertanyaan bersyarat pelbagai mod, Penjanaan Pertanyaan Bersyarat. Bab ini tertumpu terutamanya pada tugas pembahagian pelbagai mod. Objek pertanyaan pertanyaan bersyarat digunakan terutamanya untuk mengendalikan tugas pemadanan ciri silang modal dan imej silang. Bergantung pada keadaan input tugas, kepala penyahkod menggunakan pertanyaan berbeza untuk mendapatkan topeng segmentasi yang sepadan. Mengikut sumber input yang berbeza, kertas kerja ini membahagikan karya ini kepada dua aspek: ciri bahasa dan ciri imej. Kaedah ini adalah berdasarkan strategi menggabungkan objek pertanyaan dengan ciri model yang berbeza, dan telah mencapai hasil yang baik dalam tugasan segmentasi berbilang mod dan segmentasi beberapa syot.
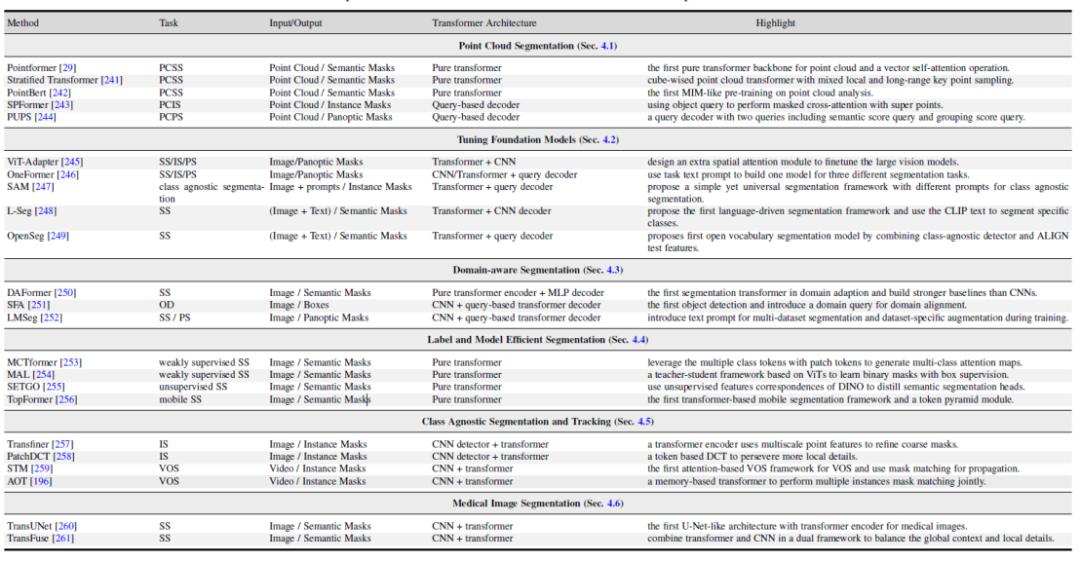
Rajah 5 menunjukkan beberapa perbandingan kerja yang mewakili dalam 5 arah berbeza ini. Untuk butiran kaedah dan perbandingan yang lebih khusus, sila rujuk kandungan kertas tersebut. . 1. Kaedah pembahagian awan titik berasaskan pengubah. 2. Visi dan penalaan model besar berbilang modal. 3. Penyelidikan tentang model segmentasi berkaitan domain, termasuk pembelajaran pemindahan domain dan pembelajaran generalisasi domain. 4. Pembahagian semantik yang cekap: model pembahagian yang tidak diselia dan diselia dengan lemah. 5. Pembahagian dan penjejakan bebas kelas. 6. Pembahagian imej perubatan.
 Gambar
Gambar
Rajah 6. Ringkasan dan perbandingan kaedah berasaskan Transformer dalam bidang penyelidikan berkaitan
Perbandingan hasil eksperimen kaedah berbeza
. Eksperimen penanda aras pada semantik set data segmentasi
Rajah 8. Eksperimen penanda aras set data segmentasi panorama
Artikel ini juga menggunakan keadaan reka bentuk percubaan yang sama secara seragam untuk membandingkan hasil beberapa kerja perwakilan pada berbilang set data pada segmentasi panorama dan segmentasi semantik. Didapati apabila menggunakan strategi latihan dan pengekod yang sama, jurang antara prestasi kaedah akan mengecil.
Selain itu, artikel ini juga membandingkan hasil kaedah segmentasi berasaskan Transformer terkini pada pelbagai set data dan tugasan yang berbeza. (Segmentasi semantik, segmentasi instance, segmentasi panorama dan tugasan segmentasi video yang sepadan)
Arah Masa Depan
Selain itu, artikel ini juga menyediakan analisis beberapa kemungkinan arah penyelidikan masa hadapan. Tiga arah berbeza diberikan di sini sebagai contoh.
- Kemas kiniTambahkan model segmentasi universal dan bersatu. Menggunakan struktur Transformer untuk menyatukan tugas pembahagian yang berbeza adalah satu trend. Penyelidikan terkini menggunakan Transformers berasaskan objek pertanyaan untuk melaksanakan tugas pembahagian yang berbeza di bawah satu seni bina. Satu hala tuju penyelidikan yang mungkin adalah untuk menyatukan tugas pembahagian imej dan video pada pelbagai set data segmentasi melalui satu model. Model umum ini boleh mencapai pembahagian yang serba boleh dan mantap dalam pelbagai senario Contohnya, pengesanan dan pembahagian kategori jarang dalam pelbagai senario membantu robot membuat keputusan yang lebih baik.
-
Model segmentasi digabungkan dengan penaakulan visual. Penaakulan visual memerlukan robot memahami perkaitan antara objek dalam adegan, dan pemahaman ini memainkan peranan penting dalam perancangan gerakan. Penyelidikan terdahulu telah meneroka menggunakan hasil segmentasi sebagai input kepada model penaakulan visual untuk pelbagai aplikasi seperti pengesanan objek dan pemahaman pemandangan. Segmen bersama dan penaakulan visual boleh menjadi arah yang menjanjikan, dengan potensi yang saling menguntungkan untuk kedua-dua segmentasi dan klasifikasi hubungan. Dengan memasukkan penaakulan visual ke dalam proses pembahagian, penyelidik boleh memanfaatkan kuasa penaakulan untuk meningkatkan ketepatan pembahagian, manakala keputusan pembahagian juga boleh memberikan input yang lebih baik untuk penaakulan visual.
-
Penyelidikan tentang model segmentasi pembelajaran berterusan. Kaedah segmentasi sedia ada biasanya ditanda aras pada set data dunia tertutup dengan set kategori yang dipratentukan, iaitu dengan mengandaikan bahawa sampel latihan dan ujian mempunyai kategori dan ruang ciri yang sama yang diketahui lebih awal. Walau bagaimanapun, senario dunia sebenar selalunya bersifat terbuka dan tidak stabil, dan kategori data baharu mungkin sentiasa muncul. Contohnya, dalam kenderaan autonomi dan diagnostik perubatan, situasi yang tidak dijangka mungkin timbul secara tiba-tiba. Terdapat jurang yang jelas antara prestasi dan keupayaan kaedah sedia ada dalam senario dunia sebenar dan dunia tertutup. Oleh itu, diharapkan konsep-konsep baharu dapat diserapkan secara beransur-ansur dan berterusan ke dalam pangkalan pengetahuan sedia ada bagi model segmentasi, supaya model tersebut dapat melibatkan diri dalam pembelajaran sepanjang hayat.
Untuk arah penyelidikan lanjut, sila rujuk kertas asal.
Atas ialah kandungan terperinci NTU dan Shanghai AI Lab menyusun 300+ kertas kerja: ulasan terkini pembahagian visual berdasarkan Transformer dikeluarkan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1382
1382
 52
52

 Kertas Stable Diffusion 3 akhirnya telah dikeluarkan, dan butiran seni bina didedahkan Adakah ia akan membantu untuk menghasilkan semula Sora?
Mar 06, 2024 pm 05:34 PM
Kertas Stable Diffusion 3 akhirnya telah dikeluarkan, dan butiran seni bina didedahkan Adakah ia akan membantu untuk menghasilkan semula Sora?
Mar 06, 2024 pm 05:34 PM
Kertas StableDiffusion3 akhirnya di sini! Model ini dikeluarkan dua minggu lalu dan menggunakan seni bina DiT (DiffusionTransformer) yang sama seperti Sora. Ia menimbulkan kekecohan apabila ia dikeluarkan. Berbanding dengan versi sebelumnya, kualiti imej yang dijana oleh StableDiffusion3 telah dipertingkatkan dengan ketara Ia kini menyokong gesaan berbilang tema, dan kesan penulisan teks juga telah dipertingkatkan, dan aksara bercelaru tidak lagi muncul. StabilityAI menegaskan bahawa StableDiffusion3 ialah satu siri model dengan saiz parameter antara 800M hingga 8B. Julat parameter ini bermakna model boleh dijalankan terus pada banyak peranti mudah alih, dengan ketara mengurangkan penggunaan AI
 Anugerah kertas ICCV'23 'Fighting of Gods'! Meta Divide Everything dan ControlNet telah dipilih secara bersama, dan terdapat satu lagi artikel yang mengejutkan para hakim
Oct 04, 2023 pm 08:37 PM
Anugerah kertas ICCV'23 'Fighting of Gods'! Meta Divide Everything dan ControlNet telah dipilih secara bersama, dan terdapat satu lagi artikel yang mengejutkan para hakim
Oct 04, 2023 pm 08:37 PM
ICCV2023, persidangan penglihatan komputer teratas yang diadakan di Paris, Perancis, baru sahaja tamat! Anugerah kertas terbaik tahun ini hanyalah "pergaduhan antara tuhan". Sebagai contoh, dua kertas kerja yang memenangi Anugerah Kertas Terbaik termasuk ControlNet, sebuah karya yang menumbangkan bidang AI graf Vincentian. Sejak menjadi sumber terbuka, ControlNet telah menerima 24k bintang di GitHub. Sama ada untuk model resapan atau keseluruhan bidang penglihatan komputer, anugerah kertas ini sememangnya wajar diberi penghormatan untuk anugerah kertas terbaik telah dianugerahkan kepada satu lagi kertas kerja yang sama terkenal, Meta "Separate Everything" ”Model SAM. Sejak pelancarannya, "Segment Everything" telah menjadi "penanda aras" untuk pelbagai model AI segmentasi imej, termasuk yang datang dari belakang.
 NeRF dan pemanduan autonomi masa lalu dan sekarang, ringkasan hampir 10 kertas kerja!
Nov 14, 2023 pm 03:09 PM
NeRF dan pemanduan autonomi masa lalu dan sekarang, ringkasan hampir 10 kertas kerja!
Nov 14, 2023 pm 03:09 PM
Sejak Medan Sinaran Neural dicadangkan pada tahun 2020, bilangan kertas kerja yang berkaitan telah meningkat secara eksponen. Ia bukan sahaja menjadi hala tuju cabang penting pembinaan semula tiga dimensi, tetapi juga secara beransur-ansur menjadi aktif di sempadan penyelidikan sebagai alat penting untuk pemanduan autonomi. . NeRF telah muncul secara tiba-tiba dalam tempoh dua tahun yang lalu, terutamanya kerana ia melangkau pengekstrakan dan pemadanan titik ciri, geometri dan triangulasi epipolar, PnP serta Pelarasan Bundle dan langkah lain dalam saluran paip pembinaan semula CV tradisional, malah melangkau pembinaan semula jaringan, pemetaan dan pengesanan cahaya , terus daripada 2D Imej input digunakan untuk mempelajari medan sinaran, dan kemudian imej yang dihasilkan yang menghampiri foto sebenar adalah output daripada medan sinaran. Dengan kata lain, biarkan model tiga dimensi tersirat berdasarkan rangkaian saraf sesuai dengan perspektif yang ditentukan
 Tangkapan skrin sembang mendedahkan peraturan tersembunyi semakan AI! AAAAI 3000 yuan kuat terima?
Apr 12, 2023 am 08:34 AM
Tangkapan skrin sembang mendedahkan peraturan tersembunyi semakan AI! AAAAI 3000 yuan kuat terima?
Apr 12, 2023 am 08:34 AM
Ketika tarikh akhir penyerahan kertas AAI 2023 semakin hampir, tangkapan skrin sembang tanpa nama dalam kumpulan penyerahan AI tiba-tiba muncul di Zhihu. Salah seorang daripada mereka mendakwa bahawa dia boleh menyediakan perkhidmatan "3,000 yuan terima kuat". Sejurus berita itu keluar, ia segera membangkitkan kemarahan orang ramai di kalangan netizen. Namun, jangan tergesa-gesa lagi. Bos Zhihu "Fine Tuning" berkata bahawa ini kemungkinan besar hanya "keseronokan lisan". Menurut "Fine Tuning", salam dan jenayah geng adalah masalah yang tidak dapat dielakkan dalam apa jua bidang. Dengan kebangkitan openreview, pelbagai kelemahan cmt telah menjadi lebih jelas Pada masa hadapan, ruang yang ditinggalkan untuk bulatan kecil untuk beroperasi akan menjadi lebih kecil, tetapi akan sentiasa ada ruang. Kerana ini adalah masalah peribadi, bukan masalah dengan sistem dan mekanisme penyerahan. Memperkenalkan open r
 Ilustrasi kertas juga boleh dijana secara automatik, menggunakan model resapan, dan juga diterima oleh ICLR.
Jun 27, 2023 pm 05:46 PM
Ilustrasi kertas juga boleh dijana secara automatik, menggunakan model resapan, dan juga diterima oleh ICLR.
Jun 27, 2023 pm 05:46 PM
Generatif AI telah menarik perhatian komuniti kecerdasan buatan Kedua-dua individu dan perusahaan telah mula berminat untuk mencipta aplikasi penukaran modal yang berkaitan, seperti gambar Vincent, video Vincent, muzik Vincent, dll. Baru-baru ini, beberapa penyelidik dari institusi penyelidikan saintifik seperti ServiceNow Research dan LIVIA telah cuba menjana carta dalam kertas kerja berdasarkan penerangan teks. Untuk tujuan ini, mereka mencadangkan kaedah baru FigGen, dan kertas berkaitan juga dimasukkan dalam ICLR2023 sebagai TinyPaper. Alamat kertas bergambar: https://arxiv.org/pdf/2306.00800.pdf Sesetengah orang mungkin bertanya, apakah yang sukar untuk menjana carta dalam kertas itu? Bagaimanakah ini membantu penyelidikan saintifik?
 Pasukan China memenangi anugerah kertas terbaik dan kertas sistem terbaik, dan keputusan penyelidikan CoRL diumumkan.
Nov 10, 2023 pm 02:21 PM
Pasukan China memenangi anugerah kertas terbaik dan kertas sistem terbaik, dan keputusan penyelidikan CoRL diumumkan.
Nov 10, 2023 pm 02:21 PM
Sejak pertama kali diadakan pada 2017, CoRL telah menjadi salah satu persidangan akademik terbaik dunia dalam persimpangan robotik dan pembelajaran mesin. CoRL ialah persidangan tema tunggal untuk penyelidikan pembelajaran robot, meliputi pelbagai topik seperti robotik, pembelajaran mesin dan kawalan, termasuk teori dan aplikasi Persidangan CoRL 2023 akan diadakan di Atlanta, Amerika Syarikat, dari 6 hingga 9 November. Menurut data rasmi, 199 kertas kerja dari 25 negara telah dipilih untuk CoRL tahun ini. Topik popular termasuk operasi, pembelajaran pengukuhan dan banyak lagi. Walaupun CoRL berskala lebih kecil daripada persidangan akademik AI yang besar seperti AAAI dan CVPR, memandangkan populariti konsep seperti model besar, kecerdasan terkandung dan robot humanoid meningkat tahun ini, penyelidikan berkaitan yang patut diberi perhatian juga akan
 Kedudukan CVPR 2023 dikeluarkan, kadar penerimaan ialah 25.78%! 2,360 kertas telah diterima, dan bilangan penyerahan meningkat kepada 9,155
Apr 13, 2023 am 09:37 AM
Kedudukan CVPR 2023 dikeluarkan, kadar penerimaan ialah 25.78%! 2,360 kertas telah diterima, dan bilangan penyerahan meningkat kepada 9,155
Apr 13, 2023 am 09:37 AM
Sebentar tadi, CVPR 2023 mengeluarkan kenyataan yang mengatakan: Tahun ini, kami menerima rekod 9,155 kertas (peningkatan 12% daripada CVPR 2022), dan menerima 2,360 kertas, dengan kadar penerimaan 25.78%. Mengikut statistik, bilangan penyerahan kepada CVPR hanya meningkat daripada 1,724 kepada 2,145 dalam tempoh 7 tahun dari 2010 hingga 2016. Selepas 2017, ia melonjak dengan pesat dan memasuki tempoh pertumbuhan pesat Pada 2019, ia melebihi 5,000 buat kali pertama, dan menjelang 2022, jumlah penyerahan telah mencapai 8,161. Seperti yang anda lihat, sebanyak 9,155 kertas telah diserahkan pada tahun ini, sememangnya mencatat rekod. Selepas wabak itu dilonggarkan, sidang kemuncak CVPR tahun ini akan diadakan di Kanada. Tahun ini ia akan menjadi persidangan trek tunggal dan pemilihan Lisan tradisional akan dibatalkan. penyelidikan google
 Kertas hangat baharu Microsoft: Transformer berkembang kepada 1 bilion token
Jul 22, 2023 pm 03:34 PM
Kertas hangat baharu Microsoft: Transformer berkembang kepada 1 bilion token
Jul 22, 2023 pm 03:34 PM
Memandangkan semua orang terus menaik taraf dan mengulang model besar mereka sendiri, keupayaan LLM (model bahasa besar) untuk memproses tetingkap konteks juga telah menjadi penunjuk penilaian yang penting. Sebagai contoh, model bintang GPT-4 menyokong 32k token, yang bersamaan dengan 50 halaman teks, Anthropic, yang diasaskan oleh bekas ahli OpenAI, telah meningkatkan keupayaan pemprosesan token Claude kepada 100k, iaitu kira-kira 75,000 perkataan, iaitu secara kasarnya bersamaan dengan meringkaskan "Harry Potter" dengan satu klik 》Bahagian Pertama. Dalam penyelidikan terbaru Microsoft, mereka terus mengembangkan Transformer kepada 1 bilion token kali ini. Ini membuka kemungkinan baharu untuk memodelkan jujukan yang sangat panjang, seperti menganggap keseluruhan korpus atau malah keseluruhan Internet sebagai satu jujukan. Sebagai perbandingan, biasa
