

Apakah pengekodan aksara yang paling biasa digunakan dalam komputer?

Pengekodan aksara yang paling biasa digunakan dalam komputer ialah pengekodan Unikod, yang merupakan piawaian pengekodan aksara yang ditakrifkan dan digunakan secara meluas oleh Organisasi Antarabangsa untuk Standardisasi Ia bertujuan untuk menyediakan pengecam unik untuk semua aksara yang diketahui di dunia, sama ada dalam Sama ada anda berada memasukkan, mengedit dan memaparkan teks dalam sistem pengendalian, atau menyemak imbas dan berkomunikasi di Internet, pengekodan Unicode boleh memastikan paparan dan penghantaran aksara yang betul.

Persekitaran pengendalian artikel ini: Sistem Windows 10, komputer dell g3.
Dalam pembangunan teknologi komputer, pengekodan aksara memainkan peranan penting. Pengekodan aksara ialah cara mewakili aksara sebagai nombor binari untuk memudahkan pengecaman dan pemprosesan yang betul oleh komputer semasa memproses dan menyimpan data teks. Skim pengekodan aksara yang berbeza digunakan secara meluas di negara dan wilayah yang berbeza, antaranya pengekodan aksara yang paling biasa ialah pengekodan Unikod.
Pengekodan Unikod ialah piawaian pengekodan aksara yang ditakrifkan dan digunakan secara meluas oleh International Organization for Standardization (ISO). Unicode bertujuan untuk menyediakan pengecam unik untuk semua aksara yang diketahui di dunia, sama ada huruf, nombor, tanda baca atau aksara khas. Ini bermakna pengekodan Unicode boleh mengandungi aksara daripada huruf Latin, huruf Yunani, huruf Cyrillic, dsb. kepada aksara Cina, huruf Jepun, angka Arab, dan bahasa dan simbol lain.
Pengekodan Unikod menggunakan jadual pengekodan bersatu, dipanggil set aksara Unikod atau titik kod Unikod. Jadual pengekodan ini mengandungi berjuta-juta titik kod, setiap titik kod sepadan dengan aksara Unicode yang unik. Aksara Unikod boleh diwakili dalam perenambelasan, diawali dengan "U+", diikuti dengan nilai titik kod aksara itu. Contohnya, pengekodan Unicode untuk huruf A ialah U+0041.
Pengekodan Unikod bukan sekadar skim pengekodan, ia juga mentakrifkan algoritma untuk memproses dan menukar pengekodan aksara. Skim pengekodan aksara yang paling biasa digunakan ialah UTF-8 (Format Transformasi Unikod - 8-bit). UTF-8 ialah pengekodan panjang boleh ubah yang menukar pengekodan Unicode kepada satu siri bait untuk penyimpanan dan penghantaran dalam sistem komputer. Pengekodan UTF-8 serasi dengan pengekodan ASCII, jadi untuk teks yang mengandungi hanya aksara ASCII, pengekodan UTF-8 dan pengekodan ASCII adalah sama.
Disebabkan aplikasi pengekodan Unicode yang meluas, orang ramai boleh menggunakan teks dalam bahasa yang berbeza pada komputer tanpa perlu mempertimbangkan isu pengekodan aksara. Sama ada anda memasukkan, mengedit dan memaparkan teks dalam sistem pengendalian, atau menyemak imbas dan berkomunikasi di Internet, pengekodan Unicode boleh memastikan paparan dan penghantaran aksara yang betul.
Selain pengekodan Unicode, terdapat beberapa skim pengekodan aksara lain yang digunakan dalam senario tertentu tertentu. Contohnya, aksara Cina sering menggunakan pengekodan GBK (pengekodan Guo Biao Kuai) atau GB2312. Skim pengekodan ini lebih cekap apabila memproses aksara Cina kerana ia hanya memerlukan satu atau dua bait untuk mewakili aksara Cina.
Walaupun terdapat skema pengekodan aksara lain, pengekodan Unikod masih merupakan pengekodan aksara yang paling biasa digunakan dalam komputer. Unicode menyediakan standard pengekodan aksara bersatu yang membolehkan komputer memproses dan memaparkan semua bahasa dan aksara di dunia. Sama ada dalam sistem pengendalian, bahasa pengaturcaraan atau aplikasi Internet, pengekodan Unicode memainkan peranan penting, menyediakan orang ramai dengan kaedah pemprosesan perkataan dan komunikasi yang mudah.
Atas ialah kandungan terperinci Apakah pengekodan aksara yang paling biasa digunakan dalam komputer?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

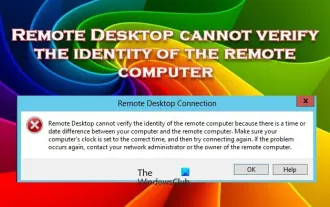 Desktop Jauh tidak boleh mengesahkan identiti komputer jauh
Feb 29, 2024 pm 12:30 PM
Desktop Jauh tidak boleh mengesahkan identiti komputer jauh
Feb 29, 2024 pm 12:30 PM
Perkhidmatan Desktop Jauh Windows membolehkan pengguna mengakses komputer dari jauh, yang sangat mudah untuk orang yang perlu bekerja dari jauh. Walau bagaimanapun, masalah boleh dihadapi apabila pengguna tidak dapat menyambung ke komputer jauh atau apabila Desktop Jauh tidak dapat mengesahkan identiti komputer. Ini mungkin disebabkan oleh isu sambungan rangkaian atau kegagalan pengesahan sijil. Dalam kes ini, pengguna mungkin perlu menyemak sambungan rangkaian, memastikan komputer jauh berada dalam talian dan cuba menyambung semula. Selain itu, memastikan bahawa pilihan pengesahan komputer jauh dikonfigurasikan dengan betul adalah kunci untuk menyelesaikan isu tersebut. Masalah sedemikian dengan Perkhidmatan Desktop Jauh Windows biasanya boleh diselesaikan dengan menyemak dan melaraskan tetapan dengan teliti. Desktop Jauh tidak boleh mengesahkan identiti komputer jauh kerana perbezaan masa atau tarikh. Sila pastikan pengiraan anda
 Kedudukan Sains Komputer Kebangsaan 2024 CSRankings Dikeluarkan! CMU mendominasi senarai, MIT terkeluar daripada 5 teratas
Mar 25, 2024 pm 06:01 PM
Kedudukan Sains Komputer Kebangsaan 2024 CSRankings Dikeluarkan! CMU mendominasi senarai, MIT terkeluar daripada 5 teratas
Mar 25, 2024 pm 06:01 PM
Kedudukan Utama Sains Komputer Kebangsaan 2024CSRankings baru sahaja dikeluarkan! Tahun ini, dalam ranking universiti CS terbaik di Amerika Syarikat, Carnegie Mellon University (CMU) berada di antara yang terbaik di negara ini dan dalam bidang CS, manakala University of Illinois di Urbana-Champaign (UIUC) telah menduduki tempat kedua selama enam tahun berturut-turut. Georgia Tech menduduki tempat ketiga. Kemudian, Universiti Stanford, Universiti California di San Diego, Universiti Michigan, dan Universiti Washington terikat di tempat keempat di dunia. Perlu diingat bahawa kedudukan MIT jatuh dan jatuh daripada lima teratas. CSRankings ialah projek ranking universiti global dalam bidang sains komputer yang dimulakan oleh Profesor Emery Berger dari Pusat Pengajian Sains Komputer dan Maklumat di Universiti Massachusetts Amherst. Kedudukan adalah berdasarkan objektif
 Apakah e dalam komputer?
Aug 31, 2023 am 09:36 AM
Apakah e dalam komputer?
Aug 31, 2023 am 09:36 AM
"e" komputer ialah simbol notasi saintifik Huruf "e" digunakan sebagai pemisah eksponen dalam notasi saintifik, yang bermaksud "didarabkan kepada kuasa 10". 10^E, di mana M ialah nombor antara 1 dan 10 dan E mewakili eksponen.
 Betulkan: Kod ralat Microsoft Teams 80090016 Modul Platform Dipercayai komputer anda telah gagal
Apr 19, 2023 pm 09:28 PM
Betulkan: Kod ralat Microsoft Teams 80090016 Modul Platform Dipercayai komputer anda telah gagal
Apr 19, 2023 pm 09:28 PM
<p>MSTeams ialah platform yang dipercayai untuk berkomunikasi, bersembang atau menelefon dengan rakan sepasukan dan rakan sekerja. Kod ralat 80090016 pada MSTeams dan mesej <strong>Modul Platform Dipercayai komputer anda telah gagal</strong> Apl tidak akan membenarkan anda log masuk sehingga kod ralat diselesaikan. Jika anda menemui mesej sedemikian semasa membuka MS Teams atau mana-mana aplikasi Microsoft lain, maka artikel ini boleh membimbing anda untuk menyelesaikan isu tersebut. </p><h2&
 Apakah maksud komputer cu?
Aug 15, 2023 am 09:58 AM
Apakah maksud komputer cu?
Aug 15, 2023 am 09:58 AM
Maksud cu dalam komputer bergantung kepada konteks: 1. Unit Kawalan, dalam pemproses pusat komputer, CU ialah komponen yang bertanggungjawab untuk menyelaras dan mengawal keseluruhan proses pengkomputeran 2. Unit Pengiraan, dalam pemproses grafik atau lain-lain pemproses dipercepatkan, CU ialah unit asas untuk memproses tugas pengkomputeran selari.
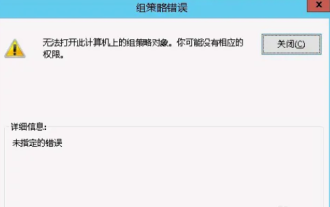 Tidak dapat membuka objek Dasar Kumpulan pada komputer ini
Feb 07, 2024 pm 02:00 PM
Tidak dapat membuka objek Dasar Kumpulan pada komputer ini
Feb 07, 2024 pm 02:00 PM
Kadangkala, sistem pengendalian mungkin tidak berfungsi apabila menggunakan komputer. Masalah yang saya hadapi hari ini ialah apabila mengakses gpedit.msc, sistem menggesa objek Dasar Kumpulan tidak boleh dibuka kerana kebenaran yang betul mungkin tiada. Objek Dasar Kumpulan pada komputer ini tidak dapat dibuka Penyelesaian: 1. Apabila mengakses gpedit.msc, sistem menggesa bahawa objek Dasar Kumpulan pada komputer ini tidak boleh dibuka kerana kekurangan kebenaran. Butiran: Sistem tidak dapat mengesan laluan yang ditentukan. 2. Selepas pengguna mengklik butang tutup, tetingkap ralat berikut muncul. 3. Semak rekod log dengan segera dan gabungkan maklumat yang direkodkan untuk mendapati bahawa masalahnya terletak pada fail C:\Windows\System32\GroupPolicy\Machine\registry.pol
 Bagaimana untuk menyelesaikan masalah watak bercelaru dalam log tomcat?
Dec 28, 2023 pm 01:50 PM
Bagaimana untuk menyelesaikan masalah watak bercelaru dalam log tomcat?
Dec 28, 2023 pm 01:50 PM
Apakah kaedah untuk menyelesaikan masalah balak tomcat bercelaru? Tomcat ialah bekas JavaServlet sumber terbuka yang popular yang digunakan secara meluas untuk menyokong penggunaan dan menjalankan aplikasi JavaWeb. Walau bagaimanapun, kadangkala aksara bercelaru muncul apabila menggunakan Tomcat untuk merekodkan log, yang menyebabkan banyak masalah kepada pembangun. Artikel ini akan memperkenalkan beberapa kaedah untuk menyelesaikan masalah log Tomcat yang kacau. Laraskan tetapan pengekodan aksara Tomcat menggunakan pengekodan aksara ISO-8859-1 secara lalai.
 Skrip Python untuk log keluar dari komputer
Sep 05, 2023 am 08:37 AM
Skrip Python untuk log keluar dari komputer
Sep 05, 2023 am 08:37 AM
Dalam era digital hari ini, automasi memainkan peranan penting dalam memperkemas dan memudahkan pelbagai tugas. Salah satu tugas ini adalah untuk log keluar komputer, yang biasanya dilakukan secara manual dengan memilih pilihan log keluar daripada antara muka pengguna sistem pengendalian. Tetapi bagaimana jika kita boleh mengautomasikan proses ini menggunakan skrip Python? Dalam catatan blog ini, kami akan meneroka cara membuat skrip Python yang boleh log keluar dari komputer anda dengan hanya beberapa baris kod. Dalam artikel ini, kami akan melalui proses langkah demi langkah untuk mencipta skrip Python untuk log keluar dari komputer anda. Kami akan merangkumi prasyarat yang diperlukan, membincangkan cara yang berbeza untuk log keluar secara pemrograman dan menyediakan panduan langkah demi langkah untuk menulis skrip. Selain itu, kami akan menangani pertimbangan khusus platform dan menyerlahkan amalan terbaik