
 Peranti teknologi
AI
Analisis data lengkap dalam satu ayat, pembantu data model besar Universiti Zhejiang yang baharu menghapuskan keperluan untuk pengumpulan
Peranti teknologi
AI
Analisis data lengkap dalam satu ayat, pembantu data model besar Universiti Zhejiang yang baharu menghapuskan keperluan untuk pengumpulan
Analisis data lengkap dalam satu ayat, pembantu data model besar Universiti Zhejiang yang baharu menghapuskan keperluan untuk pengumpulan

Untuk memproses data, alat AI yang satu ini sudah memadai!
Bergantung pada model bahasa besar (LLM) di belakangnya, anda hanya perlu menghuraikandata yang ingin anda lihat dalam satu ayat, dan serahkan yang lain!
Pemprosesan, analisis, dan juga visualisasi semuanya boleh dilakukan dengan mudah, Anda tidak perlu membuat koleksi sendiri.
 Pictures
Pictures
Pembantu data AI berasaskan LLM ini dipanggil Data-Copilot dan dibangunkan oleh pasukan Universiti Zhejiang.
Pracetak kertas berkaitan telah dikeluarkan.
Kandungan berikut disediakan oleh penyumbang
Pelbagai industri seperti kewangan, meteorologi dan tenaga menjana sejumlah besar data heterogen setiap hari. Terdapat keperluan mendesak untuk alat untuk mengurus, memproses dan memaparkan data ini dengan berkesan.
DataCopilot mengurus dan memproses data besar-besaran secara autonomi dengan menggunakan model bahasa yang besar untuk memenuhi pelbagai pertanyaan pengguna, pengiraan, ramalan, visualisasi dan keperluan lain.
Anda hanya perlu memasukkan teks untuk memberitahu DataCopilot data yang anda ingin lihat, tanpa operasi yang membosankan, Tidak perlu menulis kod anda sendiri, DataCopilot menukar data asal secara autonomi kepada hasil visualisasi yang paling sesuai dengan hasrat pengguna.
Untuk mencapai rangka kerja universal yang meliputi pelbagai bentuk tugas berkaitan data, pasukan penyelidik mencadangkan Data-Copilot.
Model ini menyelesaikan masalah risiko kebocoran data, kuasa pengkomputeran yang lemah dan ketidakupayaan untuk mengendalikan tugas rumit yang disebabkan oleh hanya menggunakan LLM.
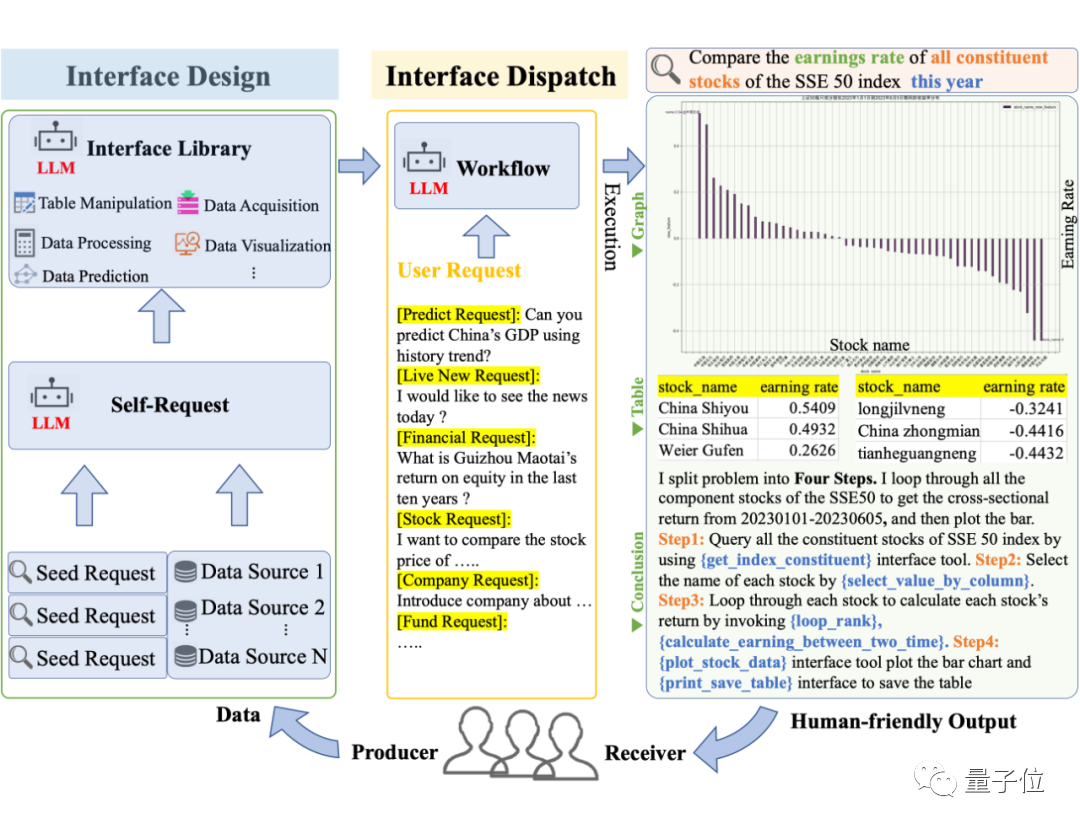 Gambar
Gambar
Apabila menerima permintaan yang kompleks, Data-Copilot akan mereka bentuk dan menjadualkansecara bebas antara muka bebas untuk membina aliran kerja bagi memenuhi hasrat pengguna.
Tanpa bantuan manusia, ia boleh dengan mahir mengubah data mentah daripada sumber yang berbeza dan dalam format yang berbeza kepada output yang dimanusiakan seperti grafik, jadual dan teks.
 Gambar
Gambar
Sumbangan utama projek Data-Copilot termasuk:
- Menghubungkan sumber data dalam pelbagai bidang dan keperluan pengguna yang pelbagai, mengurangkan tenaga kerja yang membosankan dan pengetahuan profesional.
- Mencapai pengurusan autonomi, pemprosesan, analisis, ramalan dan visualisasi data, dan boleh mengubah data mentah kepada hasil bermaklumat yang paling sesuai dengan niat pengguna.
- Alat mempunyai dwi identiti pereka dan penjadual, termasuk dua proses: proses reka bentuk alat antara muka (pereka bentuk) dan proses penjadualan (penjadual).
- Data-Copilot Demo dibina berdasarkan data pasaran kewangan China.
Reka bentuk dan laksanakan aliran kerja secara bebas
Anda juga boleh mengambil contoh berikut untuk melihat prestasi Data-Copilot:
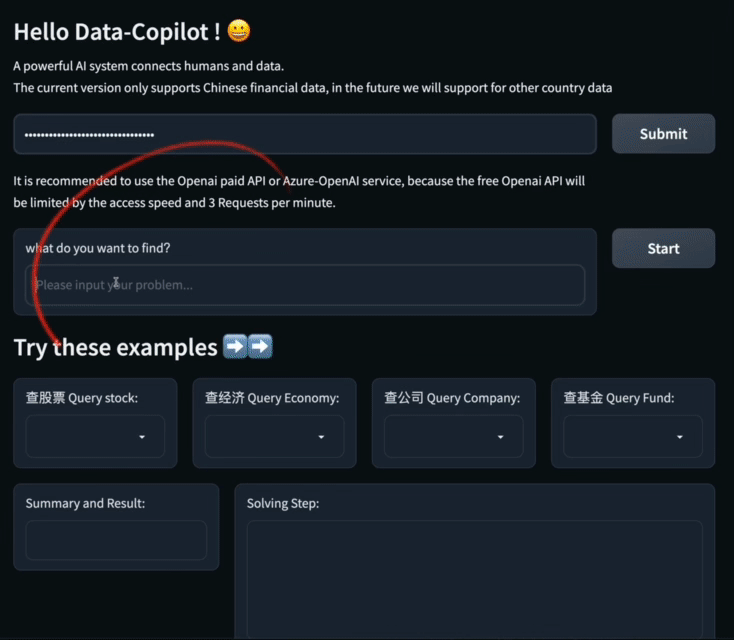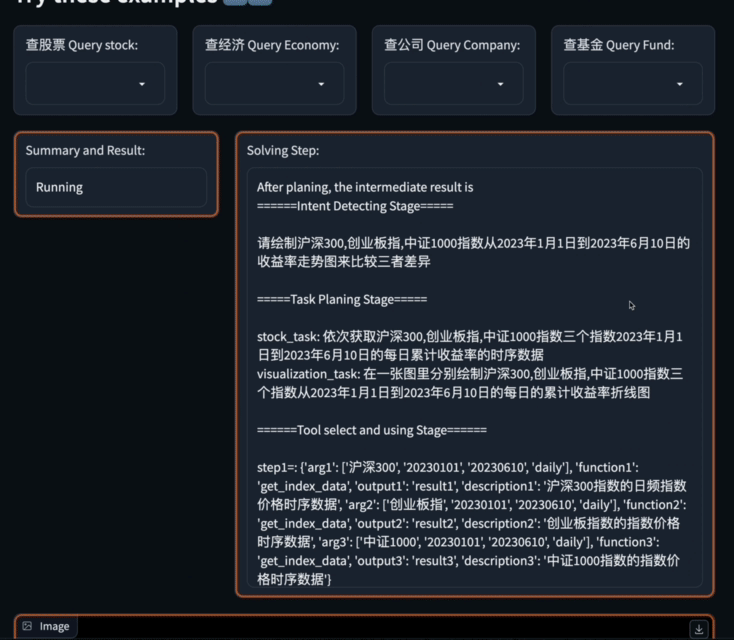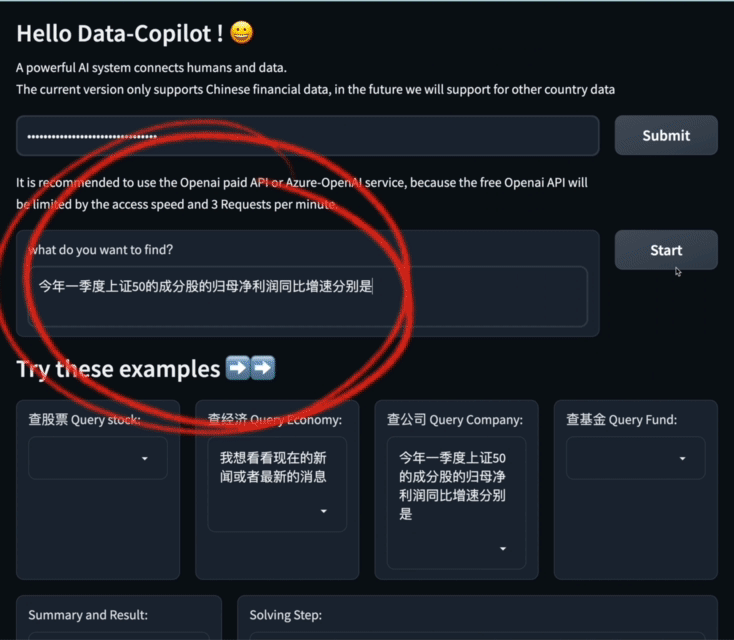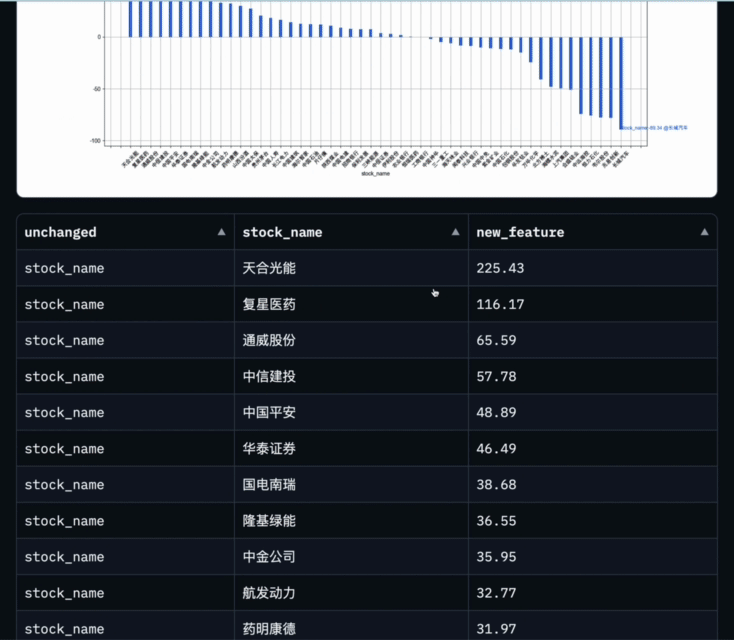
Apakah kadar pertumbuhan tahun ke tahun keuntungan bersih semua saham konstituen Shanghai Stock Exchange 50 Index pada suku pertama tahun ini
Data-Copilot Kami mereka bentuk aliran kerja sedemikian secara bebas:
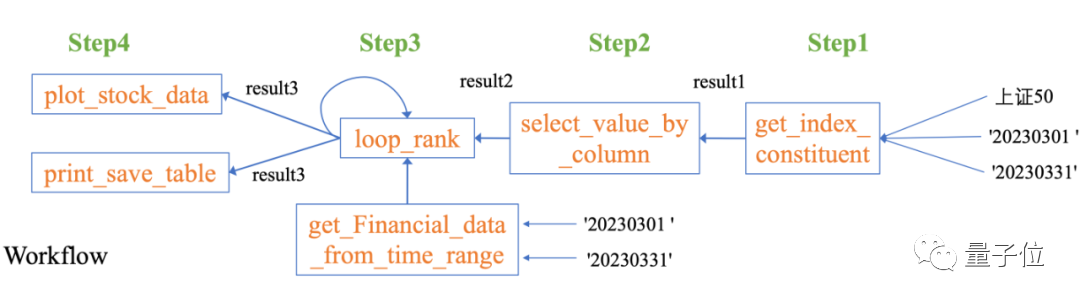 Pictures
Pictures
Untuk menangani masalah kompleks ini, Data-Copilot menggunakan antara muka loop_rank untuk melaksanakan pertanyaan gelung berbilang .
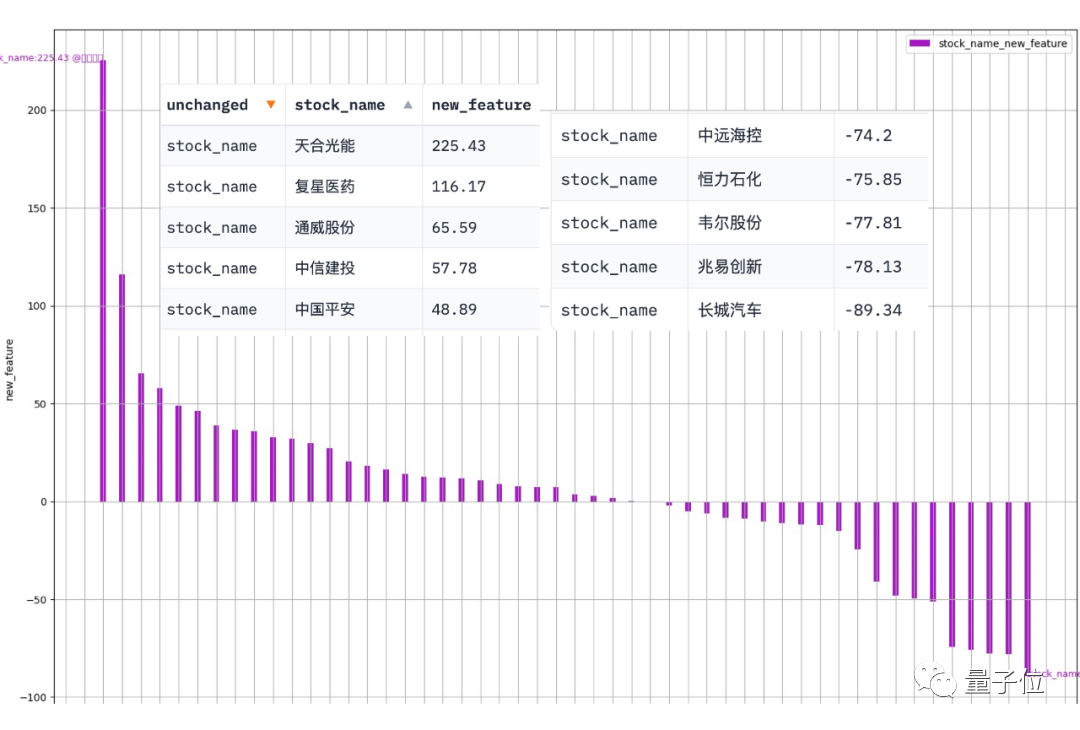
Data-Copilot mendapat keputusan ini selepas melaksanakan aliran kerja ini:
Abcissa ialah nama setiap stok komponen, dan ordinat ialah kadar pertumbuhan tahun ke tahun untung bersih pada suku pertama
 Gambar
Gambar
Sebagai tambahan kepada umum Selain proses pemprosesan data, Data-Copilot juga boleh menjana pelbagai jenis aliran kerja.
Pasukan penyelidik menguji Data-Copilot dalam dua mod aliran kerja: ramalan dan selari.
Meramalkan aliran kerja
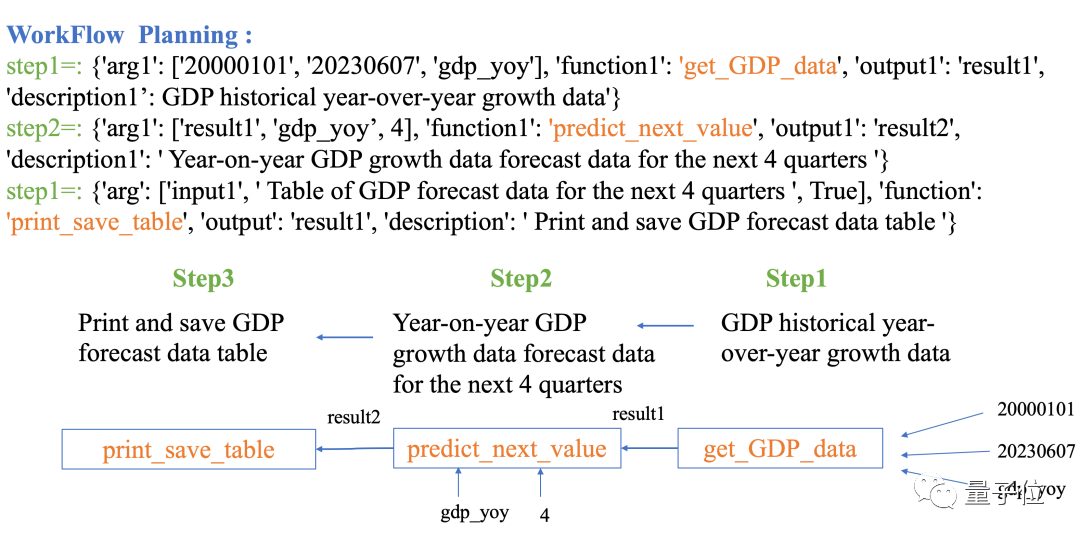
Data-Copilot juga boleh meramalkan bahagian selain daripada data yang diketahui Contohnya, masukkan soalan berikut:
Ramalkan KDNK suku tahunan China dalam empat suku berikut
Data-Copilot menggunakan sejarah Aliran Kerja
ini:Data KDNK → Gunakan model regresi linear untuk meramal masa depan → Jadual output
 gambar
gambar
Keputusan selepas pelaksanaan adalah seperti berikut:
. Hasilkan carta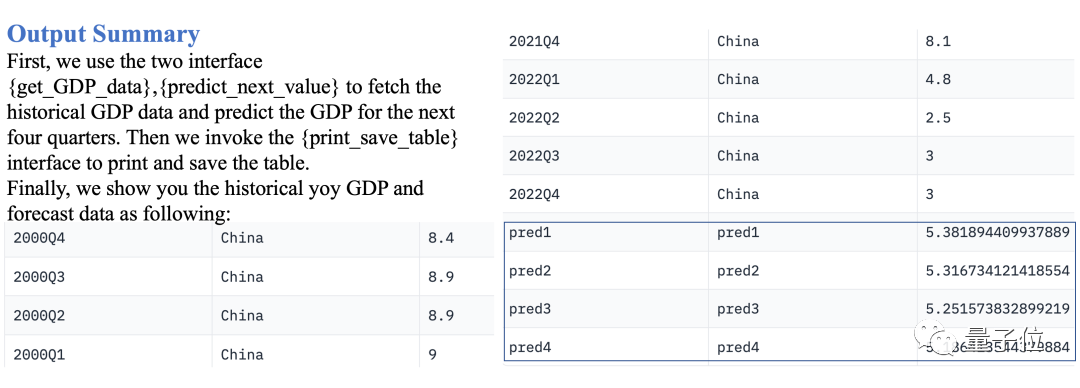 Gambar
Gambar
Kaedah umum Dopi-Main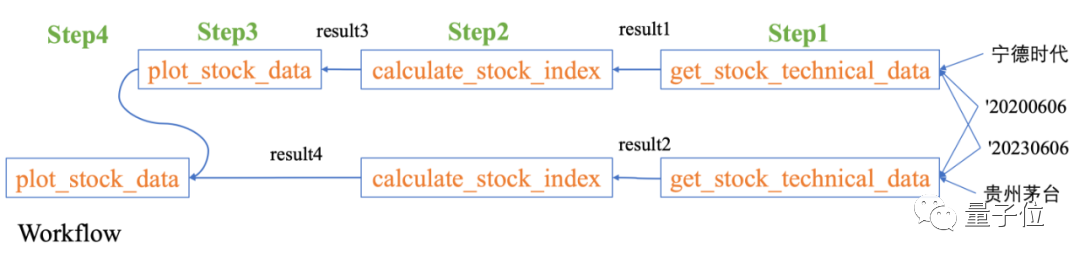 sistem model bahasa besar dengan reka bentuk antara muka dan Terdapat dua peringkat utama penjadualan antara muka.
sistem model bahasa besar dengan reka bentuk antara muka dan Terdapat dua peringkat utama penjadualan antara muka.
Reka bentuk antara muka: Pasukan penyelidik mereka bentuk proses permintaan sendiri untuk membolehkan LLM menjana permintaan yang mencukupi secara autonomi daripada sebilangan kecil permintaan benih. Kemudian, LLM secara berulang mereka bentuk dan mengoptimumkan antara muka berdasarkan permintaan yang dijana. Antara muka ini diterangkan menggunakan bahasa semula jadi, menjadikannya mudah untuk dilanjutkan dan dipindahkan antara platform yang berbeza.
Penjadualan antara muka: Selepas menerima permintaan pengguna, LLM merancang dan memanggil alat antara muka berdasarkan penerangan antara muka rekaan sendiri dan dalam demonstrasi konteks, menggunakan aliran kerja yang memenuhi keperluan pengguna dan membentangkan hasil kepada pengguna dalam pelbagai bentuk. 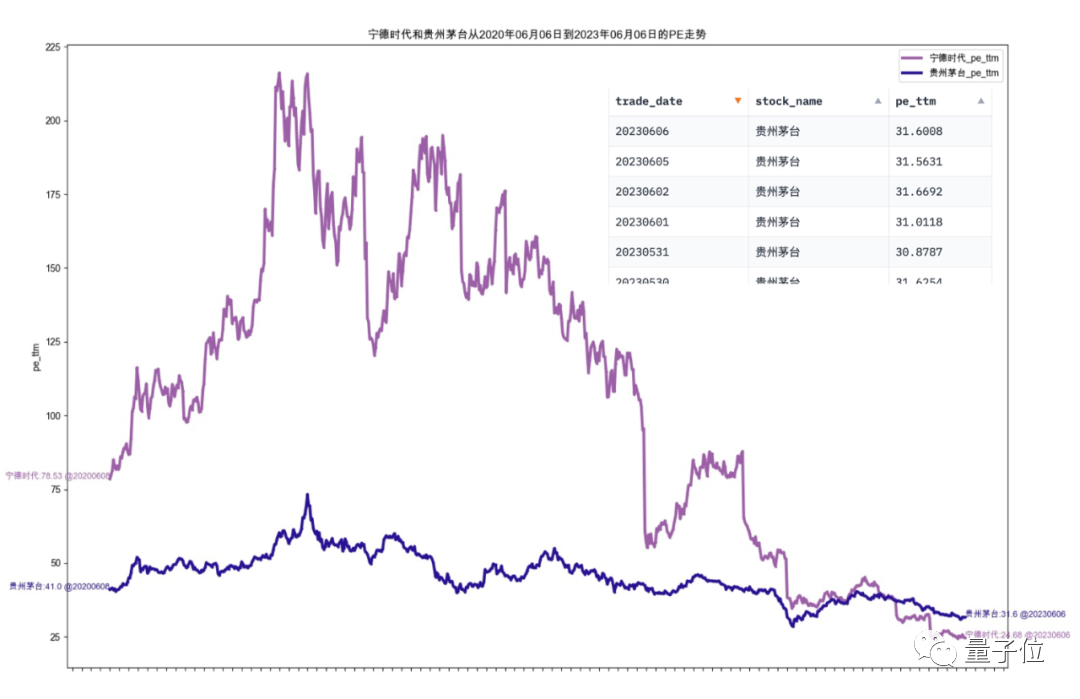 Data-Copilot mencapai pemprosesan dan visualisasi data yang sangat automatik dengan menjana permintaan secara automatik dan mereka bentuk antara muka secara bebas untuk memenuhi keperluan pengguna dan memaparkan hasil kepada pengguna dalam pelbagai bentuk.
Data-Copilot mencapai pemprosesan dan visualisasi data yang sangat automatik dengan menjana permintaan secara automatik dan mereka bentuk antara muka secara bebas untuk memenuhi keperluan pengguna dan memaparkan hasil kepada pengguna dalam pelbagai bentuk.
Gambar
- Reka bentuk antara muka
- Seperti yang ditunjukkan dalam gambar di atas, pengurusan data mesti dilaksanakan terlebih dahulu, dan langkah pertama memerlukan alat antara muka.
Pertama sekali, LLM menggunakan sebilangan kecil permintaan benih dan secara bebas menjana sejumlah besar permintaan (meneroka data mengikut permintaan diri) untuk merangkumi pelbagai senario aplikasi sebanyak mungkin.  Kemudian, LLM mereka bentuk antara muka yang sepadan untuk permintaan ini (takrifan antara muka: hanya termasuk perihalan dan parameter), dan secara beransur-ansur mengoptimumkan reka bentuk antara muka (gabungan antara muka) dalam setiap lelaran.
Kemudian, LLM mereka bentuk antara muka yang sepadan untuk permintaan ini (takrifan antara muka: hanya termasuk perihalan dan parameter), dan secara beransur-ansur mengoptimumkan reka bentuk antara muka (gabungan antara muka) dalam setiap lelaran.
Seperti yang ditunjukkan di bawah: Alat antara muka Data-Copilot yang direka bentuk sendiri untuk pemprosesan data
- gambar
- Penjadualan antara muka
- Pada peringkat sebelumnya, penyelidik memperoleh pelbagai alatan untuk pemerolehan data dan alat pemprosesan antara muka. Setiap antara muka mempunyai penerangan fungsi yang jelas dan eksplisit. Seperti yang ditunjukkan dalam rajah di atas untuk dua pertanyaan, Data-Copilot membentuk aliran kerja daripada data untuk menghasilkan berbilang bentuk melalui perancangan dan panggilan antara muka yang berbeza dalam permintaan masa nyata.
Data-Copilot terlebih dahulu melakukan analisis niat untuk memahami permintaan pengguna dengan tepat.
Setelah niat pengguna difahami dengan tepat, Data-Copilot akan merancang aliran kerja yang munasabah untuk mengendalikan permintaan pengguna. Data-Copilot akan menjana JSON format tetap yang mewakili setiap langkah penjadualan, seperti step={“arg”:””, “function”:””, “output”:””,”description”:””} .  Berpandukan penerangan dan contoh antara muka, Data-Copilot mengatur penjadualan antara muka dalam setiap langkah, sama ada secara berurutan atau selari.
Berpandukan penerangan dan contoh antara muka, Data-Copilot mengatur penjadualan antara muka dalam setiap langkah, sama ada secara berurutan atau selari.
Data-Copilot dengan ketara mengurangkan pergantungan pada tenaga kerja dan kepakaran yang membosankan dengan menyepadukan LLM ke dalam setiap peringkat tugas berkaitan data, secara automatik mengubah data mentah kepada hasil visualisasi mesra pengguna berdasarkan permintaan pengguna.
Halaman projek GitHub: https://github.com/zwq2018/Data-Copilot- Alamat kertas: https://arxiv.org/abs/2306.07209
.co/spaces/zwq2018/Data-Copilot
Atas ialah kandungan terperinci Analisis data lengkap dalam satu ayat, pembantu data model besar Universiti Zhejiang yang baharu menghapuskan keperluan untuk pengumpulan. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1384
1384
 52
52

 Sumber terbuka! Di luar ZoeDepth! DepthFM: Anggaran kedalaman monokular yang cepat dan tepat!
Apr 03, 2024 pm 12:04 PM
Sumber terbuka! Di luar ZoeDepth! DepthFM: Anggaran kedalaman monokular yang cepat dan tepat!
Apr 03, 2024 pm 12:04 PM
0. Apakah fungsi artikel ini? Kami mencadangkan DepthFM: model anggaran kedalaman monokular generatif yang serba boleh dan pantas. Sebagai tambahan kepada tugas anggaran kedalaman tradisional, DepthFM juga menunjukkan keupayaan terkini dalam tugas hiliran seperti mengecat kedalaman. DepthFM cekap dan boleh mensintesis peta kedalaman dalam beberapa langkah inferens. Mari kita baca karya ini bersama-sama ~ 1. Tajuk maklumat kertas: DepthFM: FastMonocularDepthEstimationwithFlowMatching Pengarang: MingGui, JohannesS.Fischer, UlrichPrestel, PingchuanMa, Dmytr
 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 Apr 09, 2024 am 11:52 AM
Apr 09, 2024 am 11:52 AM
AI memang mengubah matematik. Baru-baru ini, Tao Zhexuan, yang telah mengambil perhatian terhadap isu ini, telah memajukan keluaran terbaru "Buletin Persatuan Matematik Amerika" (Buletin Persatuan Matematik Amerika). Memfokuskan pada topik "Adakah mesin akan mengubah matematik?", ramai ahli matematik menyatakan pendapat mereka Seluruh proses itu penuh dengan percikan api, tegar dan menarik. Penulis mempunyai barisan yang kuat, termasuk pemenang Fields Medal Akshay Venkatesh, ahli matematik China Zheng Lejun, saintis komputer NYU Ernest Davis dan ramai lagi sarjana terkenal dalam industri. Dunia AI telah berubah secara mendadak Anda tahu, banyak artikel ini telah dihantar setahun yang lalu.
 Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Hello, Atlas elektrik! Robot Boston Dynamics hidup semula, gerakan pelik 180 darjah menakutkan Musk
Apr 18, 2024 pm 07:58 PM
Boston Dynamics Atlas secara rasmi memasuki era robot elektrik! Semalam, Atlas hidraulik hanya "menangis" menarik diri daripada peringkat sejarah Hari ini, Boston Dynamics mengumumkan bahawa Atlas elektrik sedang berfungsi. Nampaknya dalam bidang robot humanoid komersial, Boston Dynamics berazam untuk bersaing dengan Tesla. Selepas video baharu itu dikeluarkan, ia telah pun ditonton oleh lebih sejuta orang dalam masa sepuluh jam sahaja. Orang lama pergi dan peranan baru muncul. Ini adalah keperluan sejarah. Tidak dinafikan bahawa tahun ini adalah tahun letupan robot humanoid. Netizen mengulas: Kemajuan robot telah menjadikan majlis pembukaan tahun ini kelihatan seperti manusia, dan tahap kebebasan adalah jauh lebih besar daripada manusia Tetapi adakah ini benar-benar bukan filem seram? Pada permulaan video, Atlas berbaring dengan tenang di atas tanah, seolah-olah terlentang. Apa yang berikut adalah rahang-jatuh
 Kelajuan Internet Data Selular Perlahan pada iPhone: Pembetulan
May 03, 2024 pm 09:01 PM
Kelajuan Internet Data Selular Perlahan pada iPhone: Pembetulan
May 03, 2024 pm 09:01 PM
Menghadapi ketinggalan, sambungan data mudah alih perlahan pada iPhone? Biasanya, kekuatan internet selular pada telefon anda bergantung pada beberapa faktor seperti rantau, jenis rangkaian selular, jenis perayauan, dsb. Terdapat beberapa perkara yang boleh anda lakukan untuk mendapatkan sambungan Internet selular yang lebih pantas dan boleh dipercayai. Betulkan 1 – Paksa Mulakan Semula iPhone Kadangkala, paksa memulakan semula peranti anda hanya menetapkan semula banyak perkara, termasuk sambungan selular. Langkah 1 – Hanya tekan kekunci naikkan kelantangan sekali dan lepaskan. Seterusnya, tekan kekunci Turun Kelantangan dan lepaskannya semula. Langkah 2 - Bahagian seterusnya proses adalah untuk menahan butang di sebelah kanan. Biarkan iPhone selesai dimulakan semula. Dayakan data selular dan semak kelajuan rangkaian. Semak semula Betulkan 2 – Tukar mod data Walaupun 5G menawarkan kelajuan rangkaian yang lebih baik, ia berfungsi lebih baik apabila isyarat lemah
 KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
KAN, yang menggantikan MLP, telah diperluaskan kepada konvolusi oleh projek sumber terbuka
Jun 01, 2024 pm 10:03 PM
Awal bulan ini, penyelidik dari MIT dan institusi lain mencadangkan alternatif yang sangat menjanjikan kepada MLP - KAN. KAN mengatasi MLP dari segi ketepatan dan kebolehtafsiran. Dan ia boleh mengatasi prestasi MLP berjalan dengan bilangan parameter yang lebih besar dengan bilangan parameter yang sangat kecil. Sebagai contoh, penulis menyatakan bahawa mereka menggunakan KAN untuk menghasilkan semula keputusan DeepMind dengan rangkaian yang lebih kecil dan tahap automasi yang lebih tinggi. Khususnya, MLP DeepMind mempunyai kira-kira 300,000 parameter, manakala KAN hanya mempunyai kira-kira 200 parameter. KAN mempunyai asas matematik yang kukuh seperti MLP berdasarkan teorem penghampiran universal, manakala KAN berdasarkan teorem perwakilan Kolmogorov-Arnold. Seperti yang ditunjukkan dalam rajah di bawah, KAN telah
 Daya hidup kecerdasan super membangkitkan! Tetapi dengan kedatangan AI yang mengemas kini sendiri, ibu tidak perlu lagi bimbang tentang kesesakan data
Apr 29, 2024 pm 06:55 PM
Daya hidup kecerdasan super membangkitkan! Tetapi dengan kedatangan AI yang mengemas kini sendiri, ibu tidak perlu lagi bimbang tentang kesesakan data
Apr 29, 2024 pm 06:55 PM
Saya menangis hingga mati. Dunia sedang membina model besar. Data di Internet tidak mencukupi. Model latihan kelihatan seperti "The Hunger Games", dan penyelidik AI di seluruh dunia bimbang tentang cara memberi makan data ini kepada pemakan yang rakus. Masalah ini amat ketara dalam tugas berbilang modal. Pada masa mereka mengalami kerugian, pasukan pemula dari Jabatan Universiti Renmin China menggunakan model baharu mereka sendiri untuk menjadi yang pertama di China untuk menjadikan "suapan data yang dijana model itu sendiri" menjadi kenyataan. Selain itu, ia merupakan pendekatan serampang dua mata dari segi pemahaman dan sisi penjanaan Kedua-dua pihak boleh menjana data baharu berbilang modal yang berkualiti tinggi dan memberikan maklum balas data kepada model itu sendiri. Apakah model? Awaker 1.0, model berbilang modal besar yang baru sahaja muncul di Forum Zhongguancun. Siapa pasukan itu? Enjin Sophon. Diasaskan oleh Gao Yizhao, pelajar kedoktoran di Sekolah Kecerdasan Buatan Hillhouse Universiti Renmin.
 Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Robot Tesla bekerja di kilang, Musk: Tahap kebebasan tangan akan mencapai 22 tahun ini!
May 06, 2024 pm 04:13 PM
Video terbaru robot Tesla Optimus dikeluarkan, dan ia sudah boleh berfungsi di kilang. Pada kelajuan biasa, ia mengisih bateri (bateri 4680 Tesla) seperti ini: Pegawai itu juga mengeluarkan rupanya pada kelajuan 20x - pada "stesen kerja" kecil, memilih dan memilih dan memilih: Kali ini ia dikeluarkan Salah satu sorotan video itu ialah Optimus menyelesaikan kerja ini di kilang, sepenuhnya secara autonomi, tanpa campur tangan manusia sepanjang proses. Dan dari perspektif Optimus, ia juga boleh mengambil dan meletakkan bateri yang bengkok, memfokuskan pada pembetulan ralat automatik: Berkenaan tangan Optimus, saintis NVIDIA Jim Fan memberikan penilaian yang tinggi: Tangan Optimus adalah robot lima jari di dunia paling cerdik. Tangannya bukan sahaja boleh disentuh
