


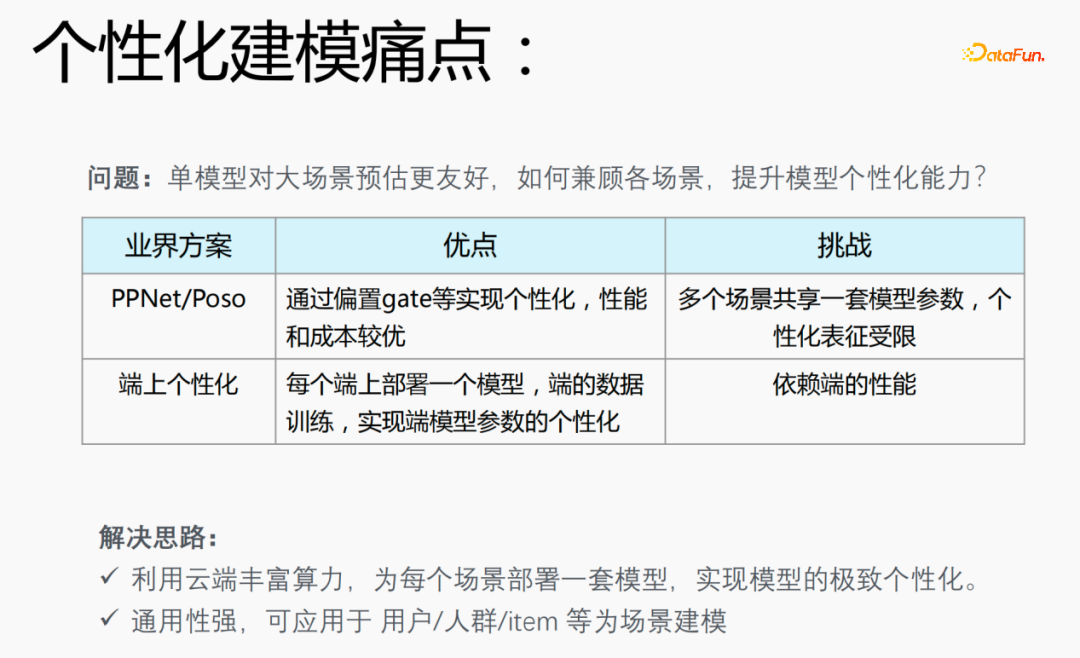
Dalam senario pengesyoran 20%, anda akan menggunakan 20% data pengedaran, anda akan menggunakan 20% masalah pengedaran sampel , yang membawa kepada masalah: model tunggal lebih mesra kepada anggaran pemandangan besar. Cara mengambil kira pelbagai senario dan meningkatkan keupayaan pemperibadian model adalah perkara yang menyakitkan dalam pemodelan diperibadikan. .

Matlamat kaedah pembelajaran tradisional adalah untuk mempelajari θ optimum untuk semua data, iaitu θ optimum global. Meta-pembelajaran menggunakan tugas sebagai dimensi untuk mempelajari 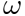 umum dalam adegan, dan kehilangan boleh mencapai tahap optimum dalam semua adegan. θ yang dipelajari melalui kaedah pembelajaran tradisional adalah lebih dekat kepada orang ramai dalam adegan besar, mempunyai ramalan yang lebih baik untuk adegan besar, dan mempunyai kesan purata pada ramalan ekor panjang adalah untuk mempelajari titik yang serupa dalam setiap adegan, dan menggunakan; setiap Data pemandangan atau data pemandangan baharu diperhalusi pada ketika ini untuk mencapai titik optimum bagi setiap adegan. Oleh itu, adalah mungkin untuk membina parameter model yang diperibadikan dalam setiap senario untuk mencapai matlamat pemperibadian muktamad. Dalam contoh di atas, orang ramai digunakan sebagai tugas untuk meta-pembelajaran, tetapi ia juga sesuai untuk pengguna atau item untuk digunakan sebagai tugas untuk pemodelan.
umum dalam adegan, dan kehilangan boleh mencapai tahap optimum dalam semua adegan. θ yang dipelajari melalui kaedah pembelajaran tradisional adalah lebih dekat kepada orang ramai dalam adegan besar, mempunyai ramalan yang lebih baik untuk adegan besar, dan mempunyai kesan purata pada ramalan ekor panjang adalah untuk mempelajari titik yang serupa dalam setiap adegan, dan menggunakan; setiap Data pemandangan atau data pemandangan baharu diperhalusi pada ketika ini untuk mencapai titik optimum bagi setiap adegan. Oleh itu, adalah mungkin untuk membina parameter model yang diperibadikan dalam setiap senario untuk mencapai matlamat pemperibadian muktamad. Dalam contoh di atas, orang ramai digunakan sebagai tugas untuk meta-pembelajaran, tetapi ia juga sesuai untuk pengguna atau item untuk digunakan sebagai tugas untuk pemodelan.
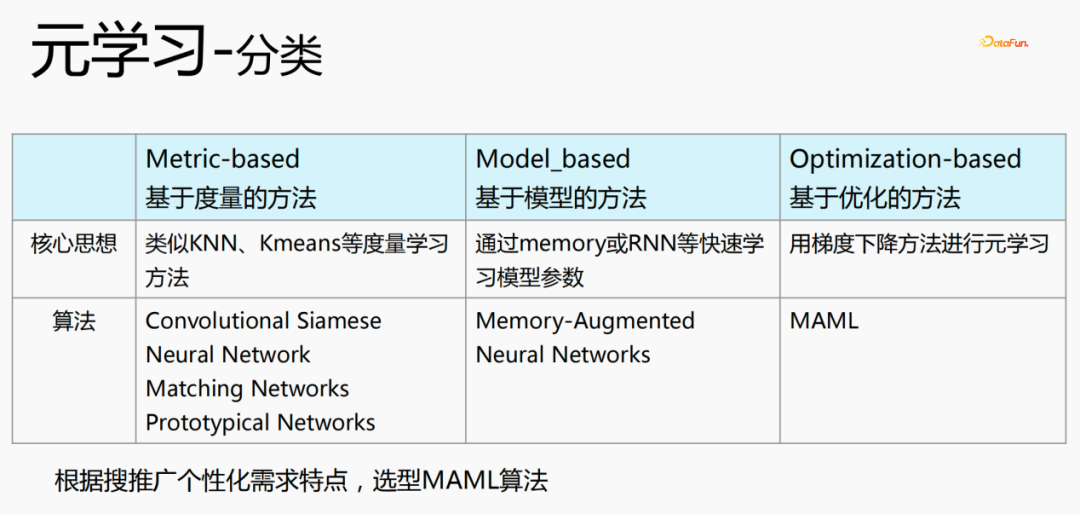
Terdapat tiga kategori meta-pembelajaran:

Model-Agnostic Meta-Learning (MAML) ialah algoritma yang tiada kaitan dengan struktur model dan ia sesuai untuk generalisasi dua bahagian: meta-train dan finetune.
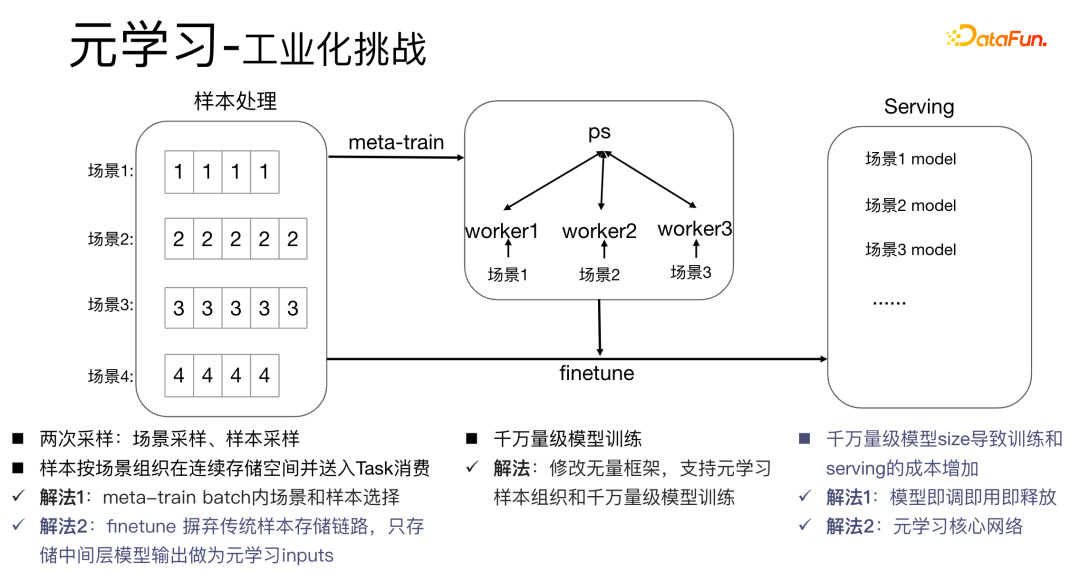
meta-train mempunyai pemulaan θ dan melaksanakan dua pensampelan, pensampelan tempat kejadian dan pensampelan sampel dalam medan. Langkah pertama ialah pensampelan tempat kejadian Dalam proses persampelan pusingan ini, jumlah sampel mempunyai ratusan ribu atau bahkan berjuta-juta tugas, dan n tugasan akan diambil daripada berjuta-juta tugasan, pada setiap adegan, sampel saiz kelompok untuk adegan ini dan bahagikan sampel bersaiz batch kepada dua bahagian, satu bahagian ialah Set Sokongan dan bahagian lain ialah Set Pertanyaan menggunakan Set Sokongan untuk mengemas kini theta setiap adegan menggunakan kaedah penurunan kecerunan stokastik, gunakan Set Pertanyaan mengira kerugian; untuk setiap adegan; dalam langkah keempat, tambah semua kerugian dan hantar kecerunan kembali ke θ berbilang pusingan pengiraan dilakukan secara keseluruhan sehingga syarat penamatan dipenuhi.
Antaranya, Set Sokongan boleh difahami sebagai set latihan, dan Set Pertanyaan boleh difahami sebagai set pengesahan.

Proses Finetune sangat hampir dengan proses meta-train θ diletakkan dalam adegan tertentu, set sokongan adegan diperoleh, dan kaedah penurunan kecerunan (SGD) digunakan untuk mendapatkan. parameter optimum tempat kejadian 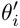 ; gunakan
; gunakan 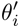 Jana hasil anggaran untuk sampel (set pertanyaan) untuk dijaringkan dalam senario tugas.
Jana hasil anggaran untuk sampel (set pertanyaan) untuk dijaringkan dalam senario tugas.
Mengaplikasikan algoritma meta-pembelajaran dalam senario industri akan menimbulkan cabaran yang agak besar: proses meta-train bagi pensampelan meta-pembelajaran dan persampelan meta-pembelajaran persampelan. Untuk sampel, adalah perlu untuk menyusun sampel dengan baik dan menyimpan dan memprosesnya dalam susunan adegan Pada masa yang sama, jadual kamus diperlukan untuk menyimpan hubungan yang sepadan antara sampel dan adegan ruang storan dan prestasi pengkomputeran Pada masa yang sama, sampel perlu disimpan dalam susunan adegan.
Kami mempunyai penyelesaian berikut:
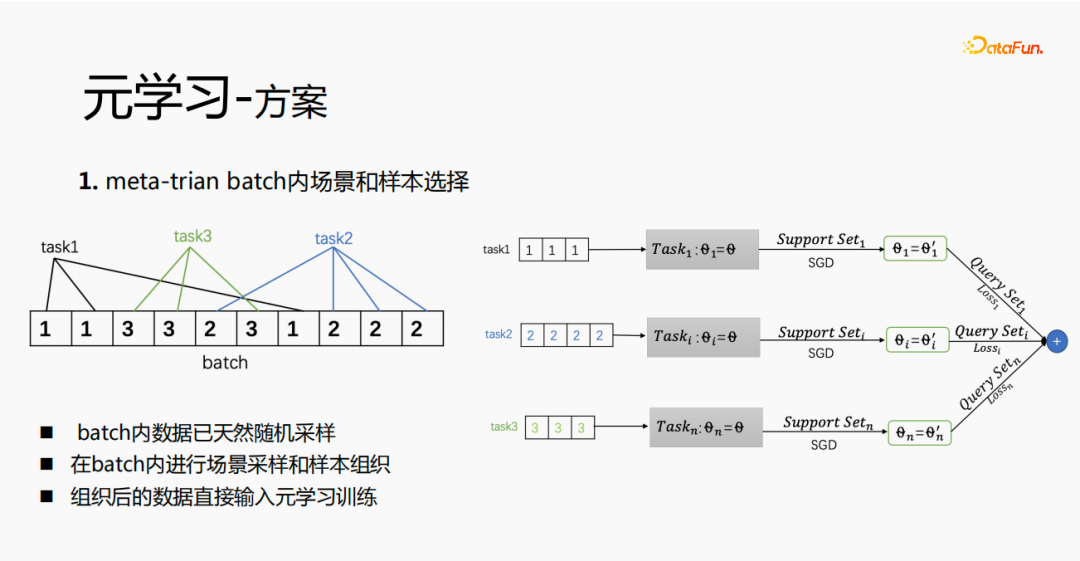
Pertama, pemilihan adegan dan sampel dalam kumpulan dilaksanakan dalam meta-train, dan setiap kumpulan akan mempunyai beberapa data data tergolong dalam tugas. Dalam satu kelompok, data ini diekstrak mengikut tugas, dan sampel yang diekstrak dimasukkan ke dalam proses latihan meta-train Ini menyelesaikan masalah keperluan untuk mengekalkan satu set pautan pemprosesan untuk pemilihan pemandangan dan pemilihan sampel.

Melalui kajian eksperimen dan membaca kertas, kami mendapati bahawa dalam penalaan halus dan dalam proses meta-pembelajaran, semakin dekat dengan lapisan ramalan, semakin besar kesan ke atas kesan ramalan model masa yang sama, lapisan emb mempunyai kesan yang lebih besar pada kesan ramalan model Kesan ramalan mempunyai kesan yang lebih besar, dan lapisan tengah tidak mempunyai kesan yang besar pada kesan ramalan. Jadi idea kami ialah meta-pembelajaran hanya memilih parameter yang lebih dekat dengan lapisan ramalan Dari perspektif kos, lapisan emb akan meningkatkan kos pembelajaran, dan lapisan emb tidak akan dilatih untuk meta-pembelajaran.
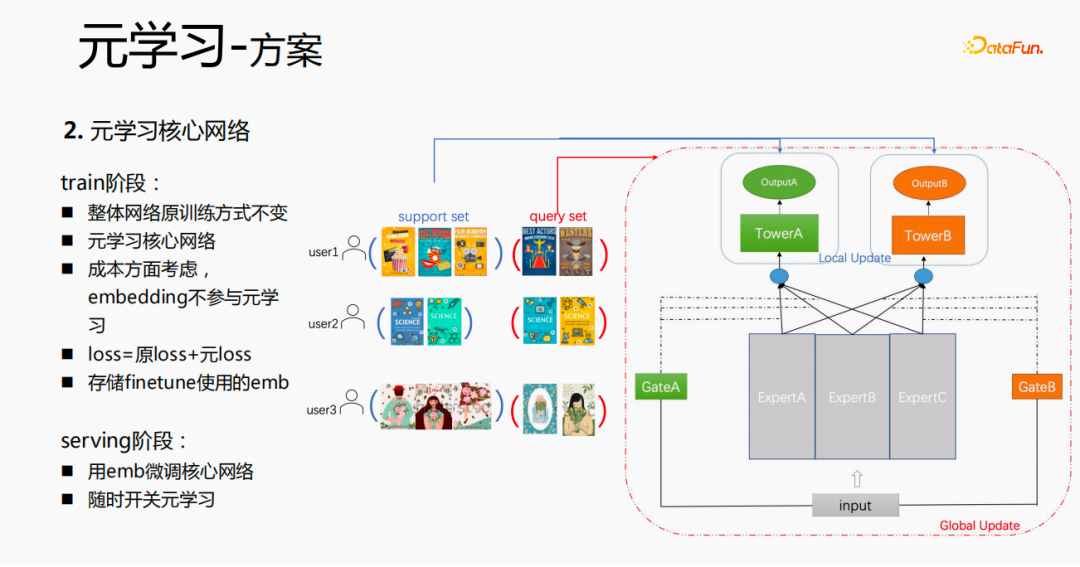
Proses latihan keseluruhan, seperti rangkaian latihan mmoe dalam gambar di atas, kita belajar parameter lapisan menara, dan parameter adegan lain masih dipelajari mengikut kaedah latihan asal. Sampel disusun dengan pengguna sebagai dimensi Setiap pengguna mempunyai data latihan sendiri Data latihan dibahagikan kepada dua bahagian, satu bahagian adalah set sokongan dan bahagian lain adalah set pertanyaan. Dalam set sokongan, hanya kandungan di sebelah tempatan dipelajari untuk kemas kini menara dan latihan parameter kemudian data set pertanyaan digunakan untuk mengira kehilangan keseluruhan rangkaian dan kemudian kecerunan dikembalikan untuk mengemas kini parameter keseluruhan rangkaian; .
Oleh itu, keseluruhan proses latihan ialah: kaedah latihan asal rangkaian keseluruhan kekal tidak berubah; meta-kerugian; apabila fintune, emb dilakukan penyimpanan. Dalam proses penyajian, emb digunakan untuk memperhalusi rangkaian teras, dan suis boleh digunakan untuk mengawal pembelajaran meta hidup dan mati.
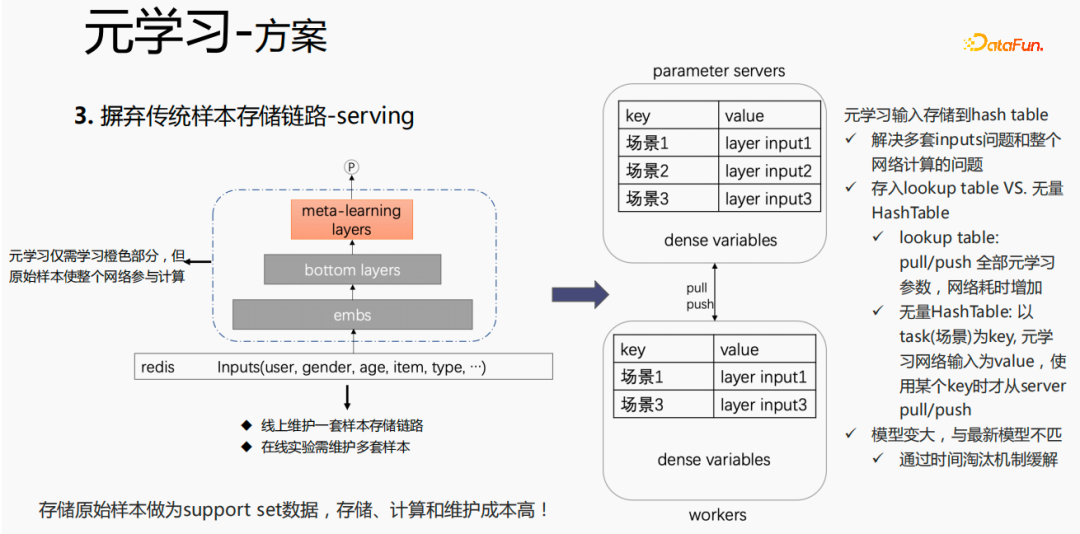
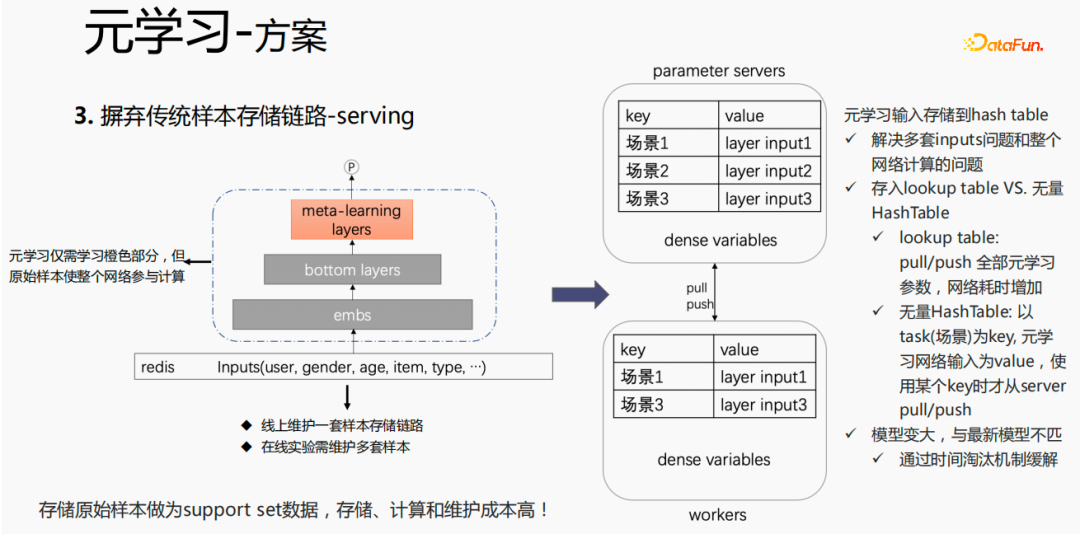
Untuk kaedah penyimpanan sampel tradisional, jika finetune dilakukan secara langsung semasa proses penyajian, akan ada masalah serius: satu set pautan storan sampel perlu dikekalkan dalam talian; perlu dikekalkan Berbilang set sampel. Pada masa yang sama, dalam proses finetune, sampel asal digunakan untuk finetune Sampel perlu melalui lapisan emb, lapisan bawah dan lapisan meta-pembelajaran proses menghidang dan tidak mempedulikan bahagian lain. Kami menganggap hanya menyimpan input meta-pembelajaran ke model semasa proses penyajian, yang boleh menjimatkan penyelenggaraan pautan sampel dan mencapai kesan tertentu Jika hanya bahagian emb disimpan, kos pengiraan dan kos penyelenggaraan bahagian ini boleh diselamatkan.
Kami menggunakan kaedah berikut:
Letakkan storan dalam jadual carian model akan dianggap sebagai pembolehubah padat dan disimpan dalam ps Semua parameter akan ditarik ke pekerja Apabila mengemas kini, semua pembolehubah ini akan Bertambah masa rangkaian. Cara lain ialah menggunakan HashTable yang tidak terhingga The HashTable disimpan dalam bentuk kunci dan nilai lapisan adegan yang diperlukan dari ps. Tekan atau tarik akan menjimatkan masa rangkaian secara keseluruhan, jadi kami mencuba kaedah ini untuk menyimpan input lapisan meta. Pada masa yang sama, jika lapisan meta-pembelajaran disimpan dalam model, ia akan menjadikan model lebih besar dan menghadapi masalah tamat tempoh, mengakibatkan ketidakpadanan dengan model semasa Kami menggunakan penghapusan masa untuk menyelesaikan masalah ini, iaitu, untuk menghapuskan benam tamat tempoh , Ini bukan sahaja menjadikan model lebih kecil, tetapi juga menyelesaikan masalah masa nyata.
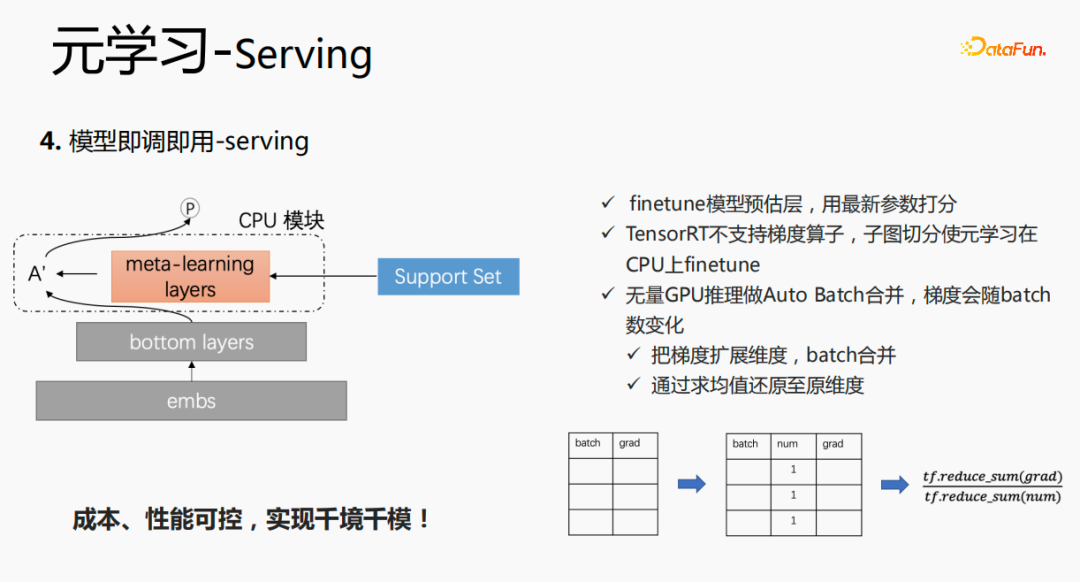
Dalam peringkat penyajian, model ini akan menggunakan pembenaman adalah input ke lapisan bawah Apabila membuat markah, ia tidak sama dengan kaedah asal melalui lapisan meta-pembelajaran dan Parameter lapisan ini dikemas kini, dan parameter yang dikemas kini digunakan untuk pemarkahan. Proses ini tidak boleh dikira pada GPU, jadi kami melaksanakan proses pada CPU. Pada masa yang sama, inferens GPU Wuliang melakukan penggabungan Auto Batch untuk menggabungkan berbilang permintaan asas , tambah dimensi num Semasa mengira kecerunan, tambahkan grad dan proseskannya mengikut nombor untuk mengekalkan kestabilan kecerunan. Pada akhirnya, kos dan prestasi boleh dikawal, dan pelbagai senario dan model dicapai.
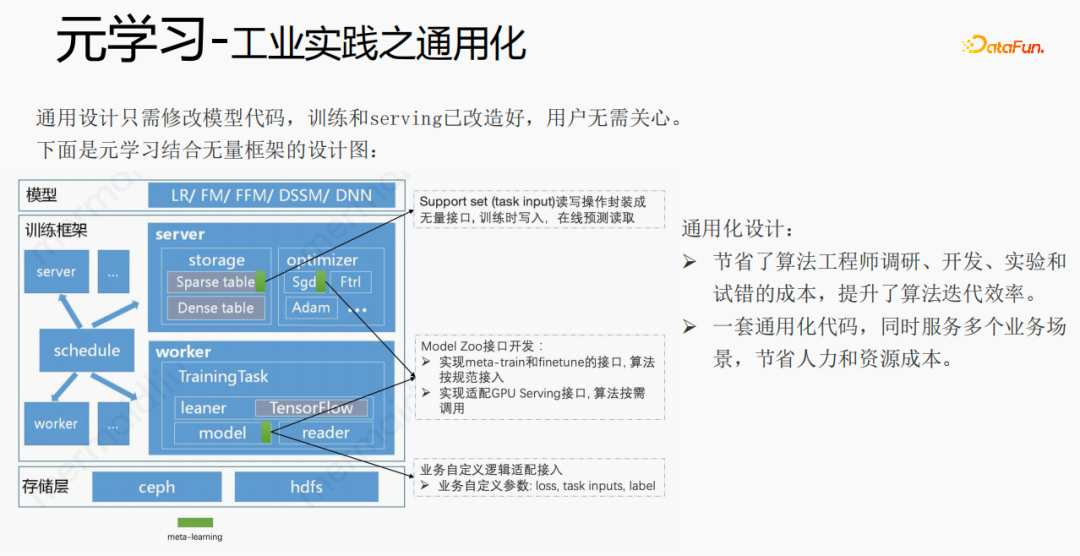
Menggunakan rangka kerja dan komponen untuk generalisasi meta-pembelajaran, apabila pengguna mengakses, mereka hanya perlu mengubah suai kod model dan penyajian, mereka hanya perlu memanggil apa yang telah kami sediakan. Laksanakan antara muka yang baik, seperti antara muka membaca dan menulis set sokongan, antara muka pelaksanaan meta-train dan finetune, dan antara muka penyesuaian penyajian GPU. Pengguna hanya perlu memasukkan parameter berkaitan perniagaan seperti kehilangan, input tugas, label, dsb. Reka bentuk ini menjimatkan kos penyelidikan, pembangunan, percubaan dan percubaan dan ralat jurutera algoritma, dan meningkatkan kecekapan lelaran algoritma Pada masa yang sama, kod umum boleh menyediakan pelbagai senario perniagaan, menjimatkan tenaga manusia dan kos sumber.
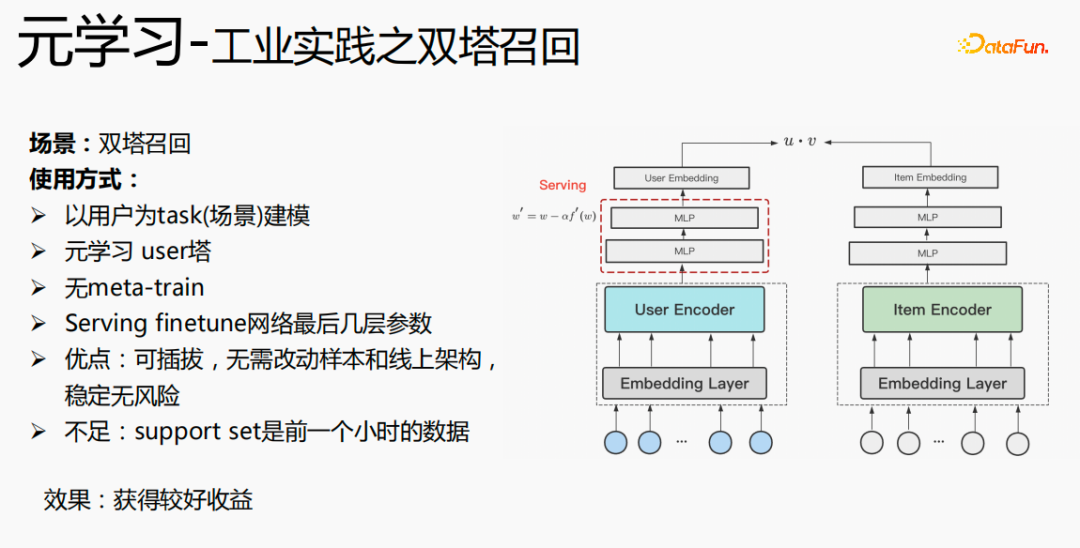
Penggunaan meta-pembelajaran dalam senario ingat semula menara berkembar dimodelkan dengan pengguna sebagai dimensi, termasuk menara pengguna dan menara item. Kelebihan model adalah: boleh pasang, tidak perlu menukar sampel dan seni bina dalam talian, stabil dan bebas risiko adalah bahawa set sokongan adalah data jam sebelumnya, yang mempunyai masalah masa nyata;

Satu lagi senario aplikasi meta-pembelajaran adalah dalam senario ingat semula urutan Senario ini dimodelkan dengan pengguna sebagai senario, dan jujukan tingkah laku pengguna sebagai set sampel yang positif , yang akan kami kekalkan A baris gilir sampel negatif, sampel dalam baris gilir pensampelan digunakan sebagai sampel negatif, dan sampel positif disambungkan ke dalam set sokongan. Kelebihan ini ialah: prestasi masa nyata yang lebih kukuh dan kos yang lebih rendah.
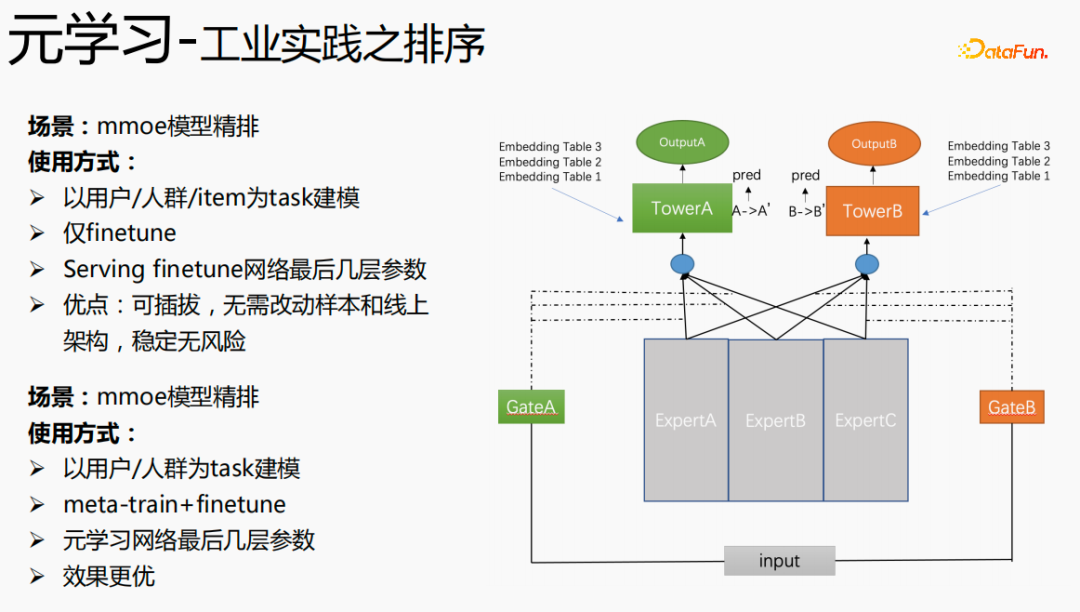
Akhirnya, meta-pembelajaran juga digunakan dalam senario pengisihan, seperti model pengisihan halus mmoe dalam gambar di atas Terdapat dua kaedah pelaksanaan: hanya menggunakan finetune, dan menggunakan kedua-dua meta-train dan finetune. Kaedah pelaksanaan kedua adalah lebih berkesan.
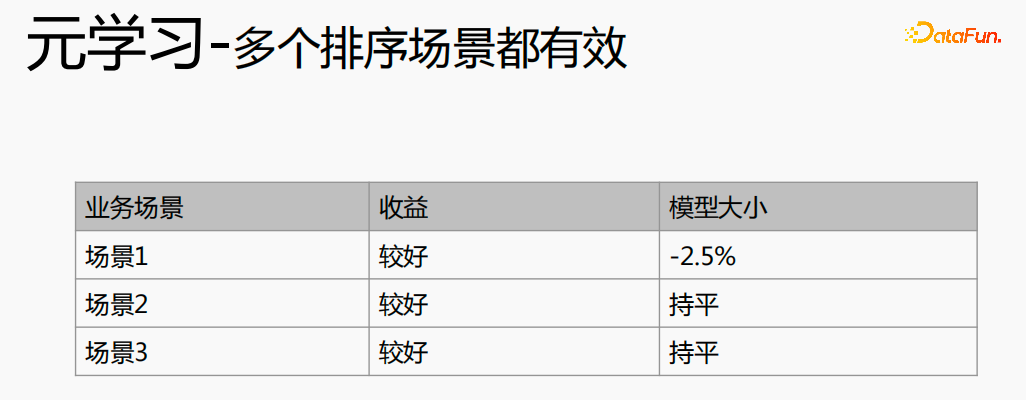
Meta-pembelajaran telah mencapai keputusan yang baik dalam senario yang berbeza.
Setiap adegan mempunyai berbilang pintu masuk yang disyorkan. Ia adalah perlu untuk mewujudkan satu set pautan daripada ingatan kepada kedudukan kasar kepada kedudukan halus untuk setiap adegan, yang memerlukan kos. Terutamanya adegan kecil dan data trafik sederhana dan panjang adalah jarang, dan ruang pengoptimuman adalah terhad. Bolehkah kami menyepadukan sampel portal cadangan yang serupa, latihan luar talian dan perkhidmatan dalam talian dalam satu produk ke dalam satu set untuk menjimatkan kos dan meningkatkan hasil?
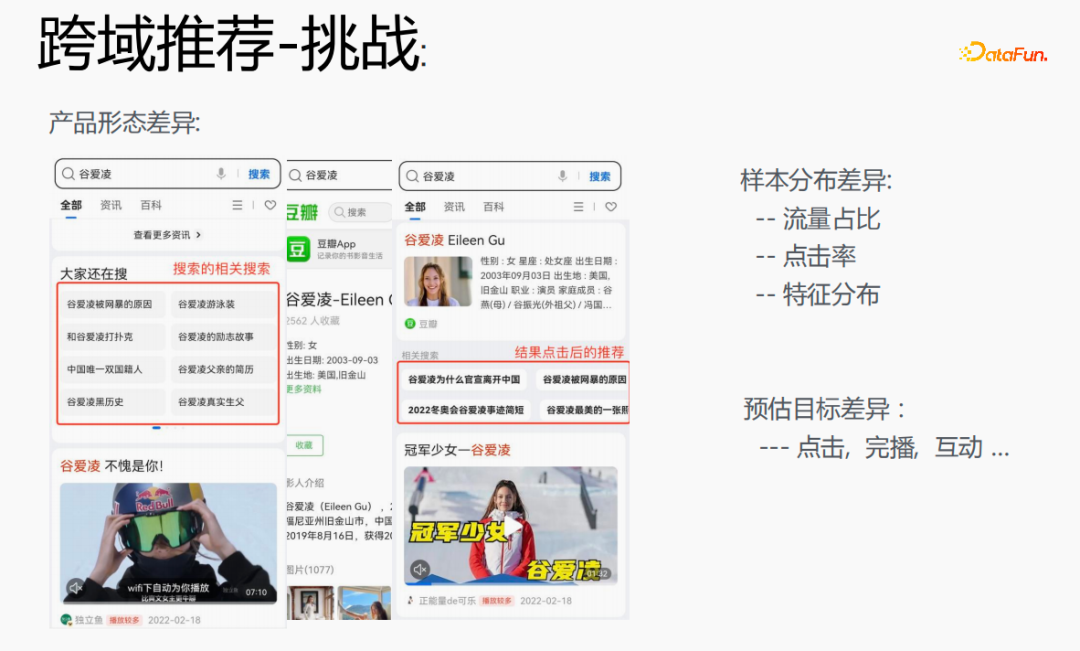
Walau bagaimanapun, terdapat cabaran tertentu dalam melakukannya. Cari Gu Ailing pada penyemak imbas, dan istilah carian yang berkaitan akan muncul Selepas mengklik pada kandungan tertentu dan kembali, cadangan selepas mengklik pada hasil akan muncul Perkadaran trafik, kadar klik lalu dan pengedaran ciri kedua-duanya adalah agak berbeza. Pada masa yang sama, Terdapat juga perbezaan dalam anggaran sasaran.
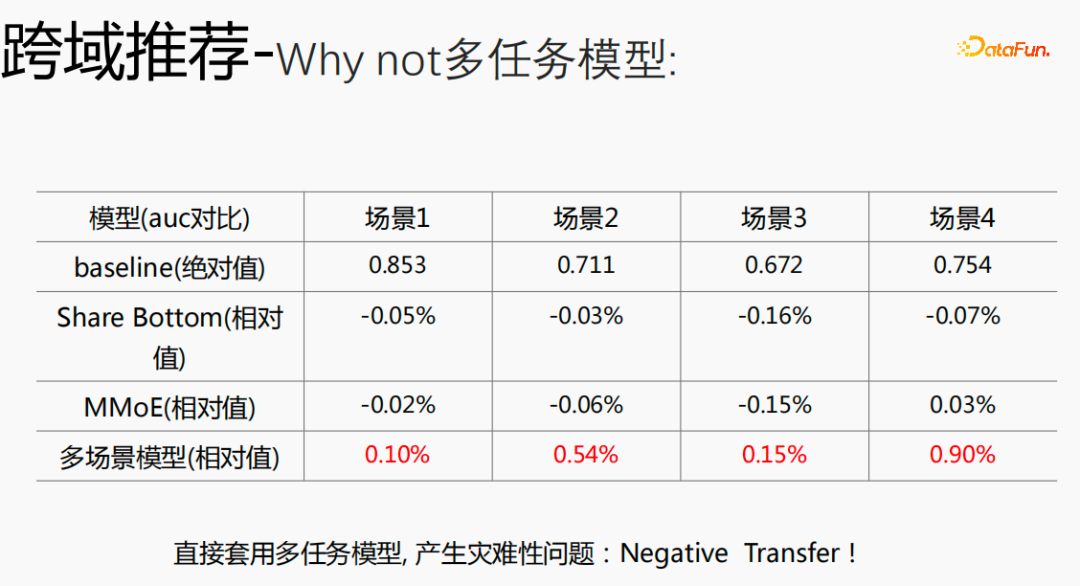
Jika anda menggunakan model berbilang tugas untuk model merentas domain, masalah serius akan berlaku dan anda tidak akan mendapat manfaat yang lebih baik.
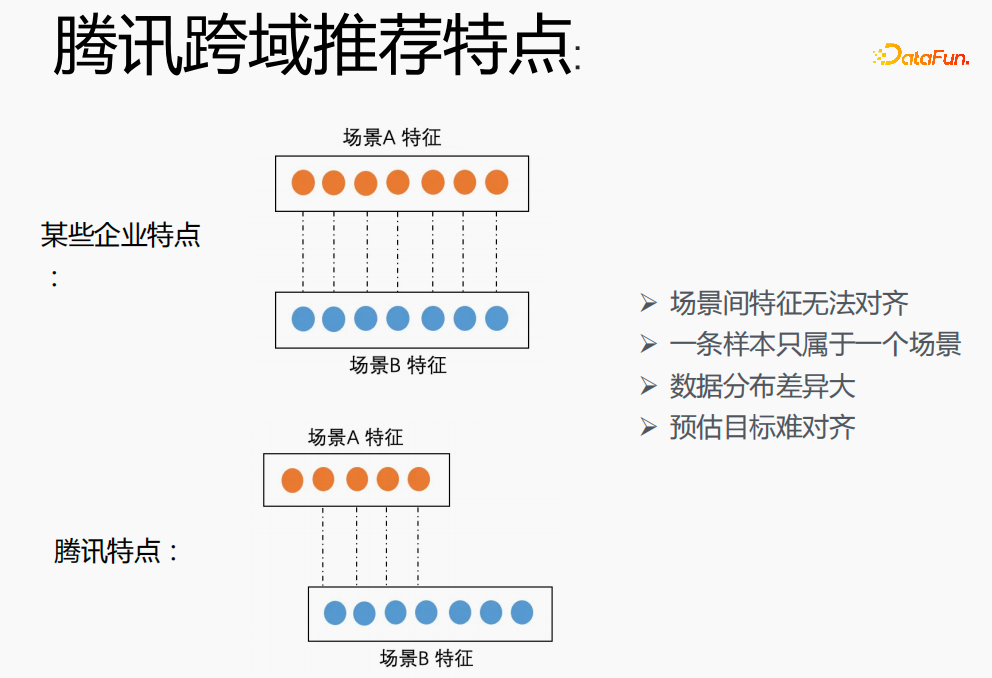
Melaksanakan pemodelan merentas senario dalam Tencent merupakan satu cabaran besar. Pertama, dalam syarikat lain, ciri dua senario boleh sepadan dengan satu sama lain, tetapi dalam medan pengesyoran merentas domain Tencent, ciri dua senario itu tidak boleh diselaraskan hanya dalam satu senario pengedaran adalah sangat berbeza, dan sukar untuk menyelaraskan sasaran yang dianggarkan.
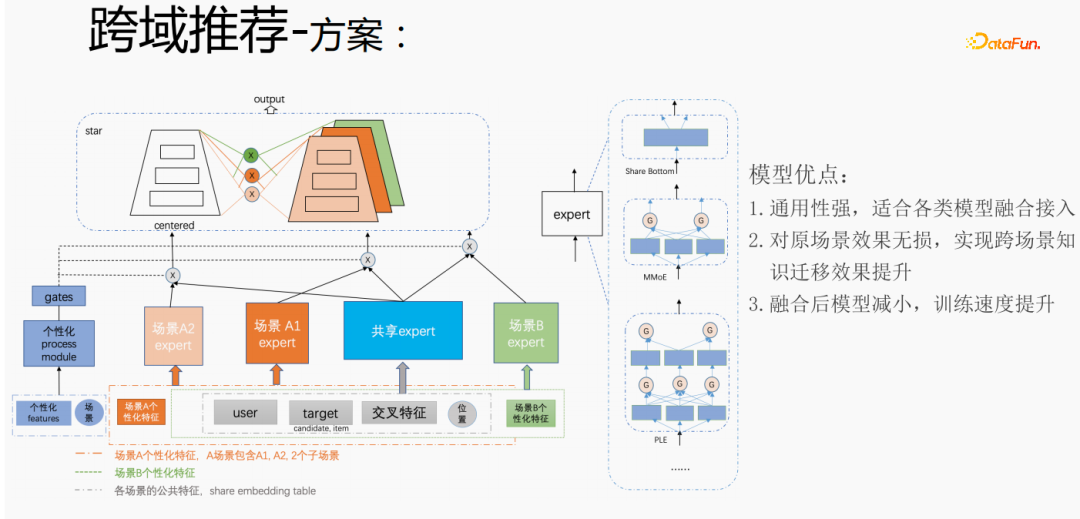
Mengikut keperluan peribadi bagi senario pengesyoran merentas domain Tencent, kaedah di atas digunakan untuk mengendalikannya. Untuk pembenaman bersama ciri umum, ciri yang diperibadikan adegan mempunyai ruang pembenaman bebasnya sendiri Dalam bahagian model, terdapat pakar yang dikongsi dan pakar yang diperibadikan Semua data akan mengalir ke pakar yang dikongsi, dan sampel setiap adegan akan memilikinya Peribadikan pakar, integrasikan pakar yang dikongsi dan pakar yang diperibadikan melalui pintu yang diperibadikan, masukkannya ke dalam menara, dan gunakan kaedah bintang untuk menyelesaikan masalah jarang sasaran dalam senario yang berbeza. Untuk bahagian pakar, sebarang struktur model boleh digunakan, seperti bahagian bawah Kongsi, MMoE, PLE atau struktur model penuh pada senario perniagaan. Kelebihan kaedah ini ialah: model ini sangat serba boleh dan sesuai untuk akses gabungan pelbagai model kerana pakar adegan boleh dipindahkan secara langsung, kesan adegan asal tidak rosak, dan kesan pemindahan pengetahuan senario silang dipertingkatkan; selepas gabungan, model dikurangkan dan kelajuan latihan dipertingkatkan Perbaiki sambil menjimatkan kos.
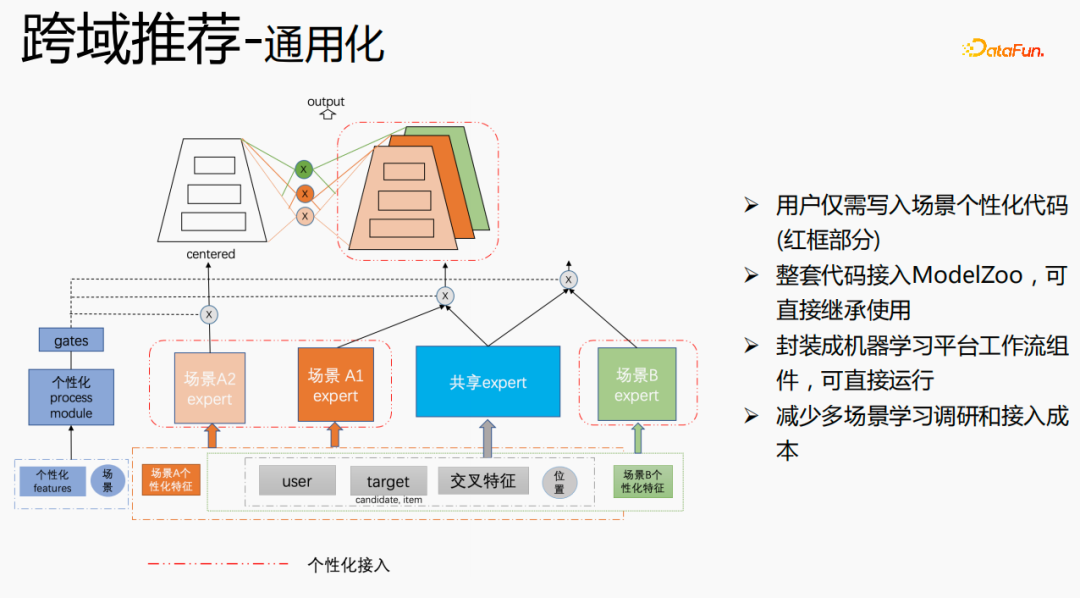
Kami telah menjalankan pembinaan universal Bahagian merah ialah kandungan yang memerlukan akses diperibadikan, seperti: ciri diperibadikan, struktur model diperibadikan, dsb. Pengguna hanya perlu menulis kod diperibadikan. Untuk bahagian lain, kami telah menyambungkan keseluruhan set kod kepada ModelZoo, yang boleh diwarisi dan digunakan secara terus, dan dirangkumkan ke dalam komponen aliran kerja platform pembelajaran mesin, yang boleh dijalankan secara langsung Kaedah ini mengurangkan kos penyelidikan pembelajaran berbilang senario dan akses.
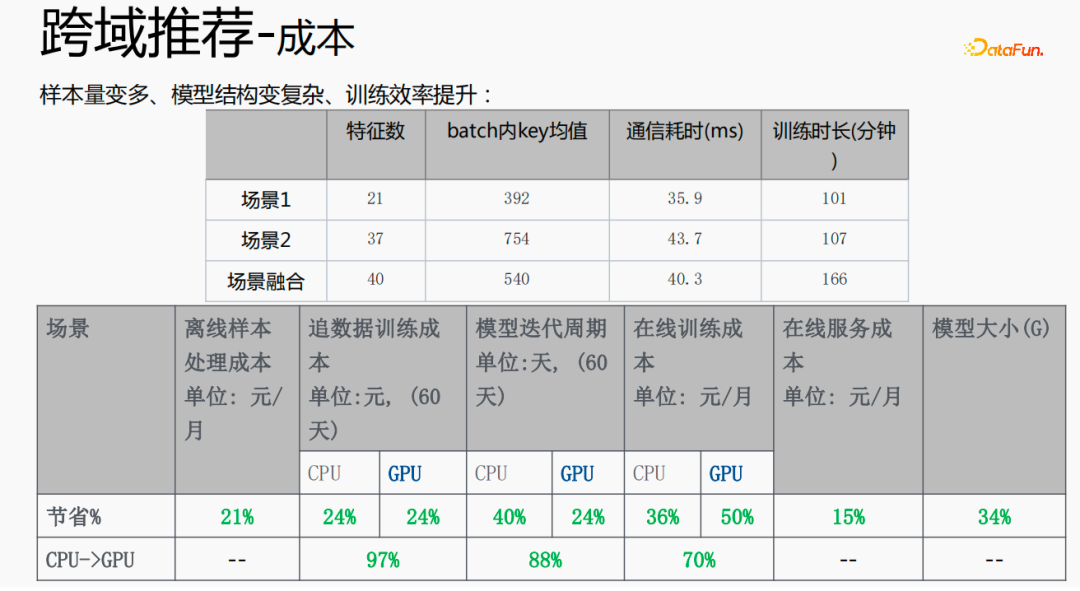
Kaedah ini meningkatkan saiz sampel dan merumitkan struktur model, tetapi kecekapan dipertingkatkan. Sebabnya adalah seperti berikut: Memandangkan beberapa ciri dikongsi, bilangan ciri selepas gabungan adalah kurang daripada jumlah ciri dua adegan disebabkan oleh fungsi pembenaman dikongsi, nilai kunci min dalam kelompok adalah lebih kecil daripada jumlah dua adegan; mengurangkan Ia menjimatkan masa menarik atau menolak dari sisi pelayan, dengan itu menjimatkan masa komunikasi dan mengurangkan masa latihan keseluruhan.
Gabungan pelbagai senario boleh mengurangkan kos keseluruhan: pemprosesan sampel luar talian boleh mengurangkan kos sebanyak 21%; menggunakan CPU untuk mengejar data akan menjimatkan 24% daripada kos, manakala masa lelaran model juga akan dikurangkan sebanyak 40; %, dan latihan dalam talian Kos, kos perkhidmatan dalam talian dan saiz model semuanya akan dikurangkan, jadi kos keseluruhan pautan dikurangkan. Pada masa yang sama, menggabungkan data berbilang adegan bersama adalah lebih sesuai untuk pengkomputeran GPU Menggabungkan CPU dua adegan tunggal kepada GPU akan menjimatkan perkadaran yang lebih tinggi.
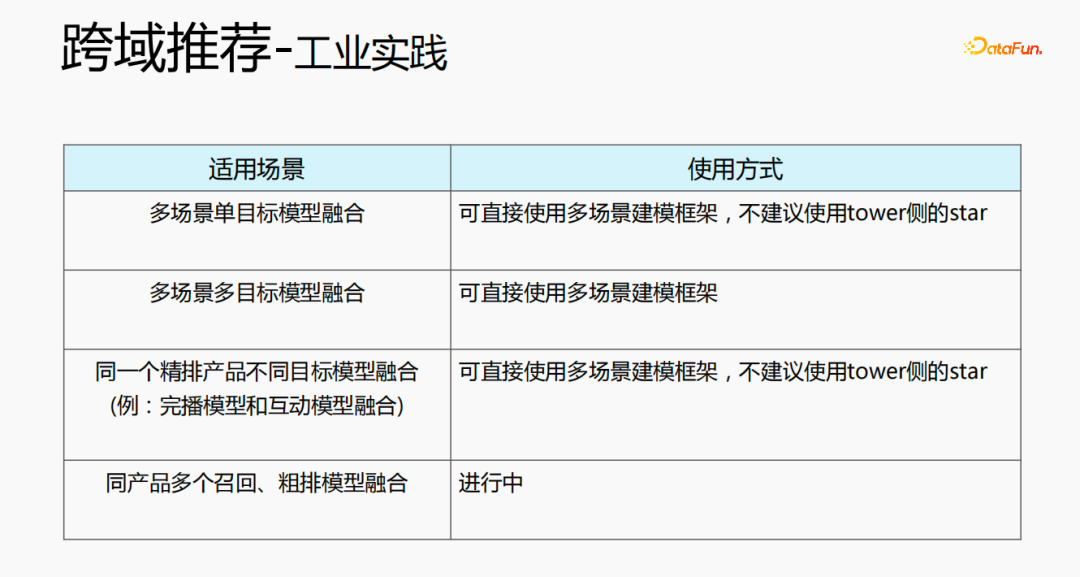
Pengesyoran merentas domain boleh digunakan dalam pelbagai cara. Yang pertama ialah struktur model objektif tunggal berbilang adegan, yang boleh menggunakan rangka kerja pemodelan berbilang adegan -objektif, dan boleh terus menggunakan rangka kerja pemodelan berbilang adegan Jenis ketiga ialah gabungan model sasaran yang berbeza untuk produk penjadualan halus yang sama Anda boleh terus menggunakan rangka kerja pemodelan berbilang senario bintang di bahagian menara; yang terakhir ialah gabungan beberapa model penarikan balik dan penjadualan kasar untuk produk yang sama sedang dibangunkan.
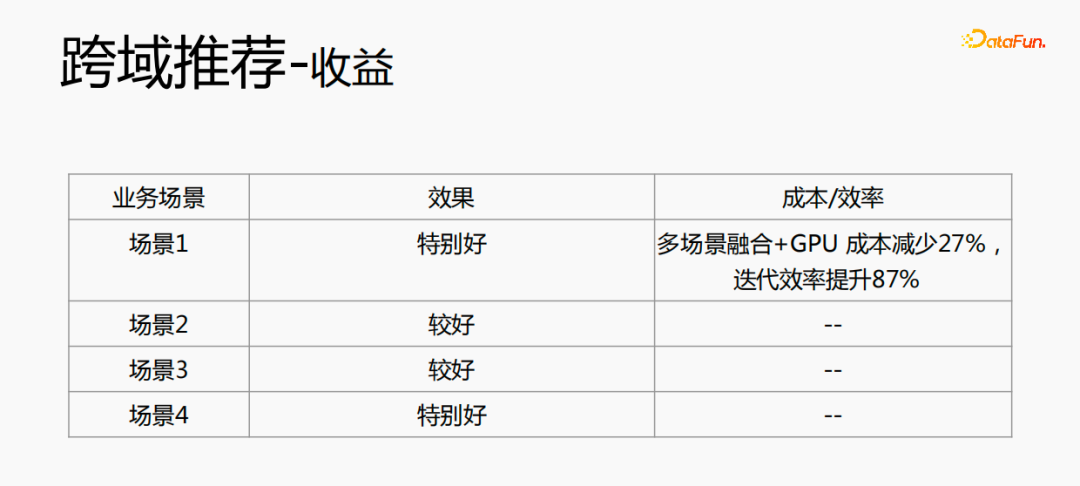
Pengesyoran merentas domain bukan sahaja meningkatkan kesan, tetapi juga menjimatkan banyak kos.
Atas ialah kandungan terperinci Amalan industri pengesyoran meta-pembelajaran dan merentas domain Tencent TRS. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!
 Algoritma penggantian halaman
Algoritma penggantian halaman
 Pengumpulan kekunci pintasan komputer
Pengumpulan kekunci pintasan komputer
 Apakah perbezaan antara kolam benang musim bunga dan kolam benang jdk?
Apakah perbezaan antara kolam benang musim bunga dan kolam benang jdk?
 Apakah yang perlu saya lakukan jika eDonkey Search tidak dapat menyambung ke pelayan?
Apakah yang perlu saya lakukan jika eDonkey Search tidak dapat menyambung ke pelayan?
 Pengesyoran perisian desktop Android
Pengesyoran perisian desktop Android
 Kaedah penukaran kata laluan MySQL
Kaedah penukaran kata laluan MySQL
 Cara menyusun dalam excel
Cara menyusun dalam excel
 Bagaimana untuk mengubah saiz gambar dalam ps
Bagaimana untuk mengubah saiz gambar dalam ps








![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



