
 Peranti teknologi
AI
Seni bina model GPT-4 bocor: mengandungi 1.8 trilion parameter dan menggunakan model pakar hibrid
Peranti teknologi
AI
Seni bina model GPT-4 bocor: mengandungi 1.8 trilion parameter dan menggunakan model pakar hibrid
Seni bina model GPT-4 bocor: mengandungi 1.8 trilion parameter dan menggunakan model pakar hibrid


Berita pada 13 Julai, Semianalysis media asing baru-baru ini mendedahkan model besar GPT-4 yang dikeluarkan oleh OpenAI pada Mac tahun ini, termasuk seni bina model GPT-4, infrastruktur latihan dan inferens, volum parameter dan set Data latihan, bilangan token, kos, Campuran Pakar dan parameter dan maklumat khusus lain.
▲ Sumber gambar Semianalysis
Media asing menyatakan bahawa GPT-4 mengandungi sejumlah 1.8 trilion parameter dalam 120 lapisan, manakala GPT-3 hanya mempunyai kira-kira 175 bilion parameter. Untuk memastikan kos berpatutan, OpenAI menggunakan model pakar hibrid untuk membina.
IT Home Nota: Mixture of Experts ialah sejenis rangkaian saraf Sistem memisahkan dan melatih berbilang model berdasarkan data Selepas output setiap model, sistem menyepadukan dan mengeluarkan model ini ke dalam satu tugas.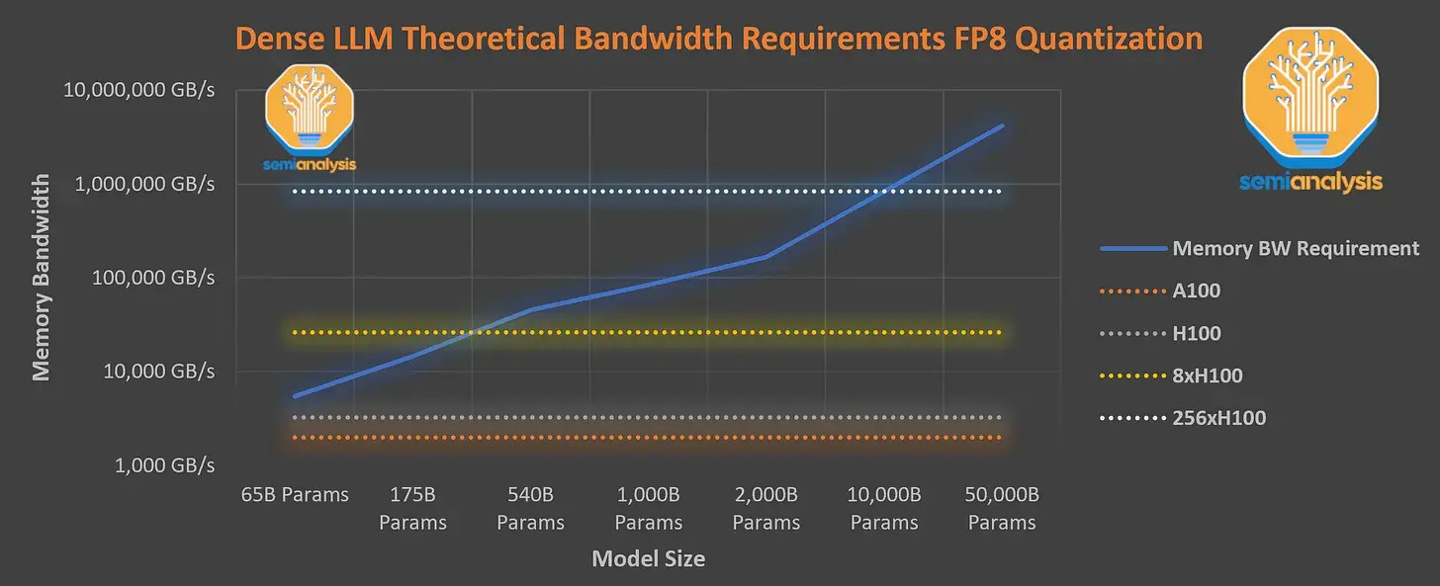
GPT-4 menggunakan 16 model pakar campuran (campuran pakar), setiap satu dengan 111 bilion parameter, dan setiap laluan laluan hadapan melalui dua model pakar .
Selain itu, ia mempunyai 55 bilion parameter perhatian yang dikongsi dan dilatih menggunakan set data yang mengandungi 13 trilion token tidak unik dan dikira sebagai lebih banyak token berdasarkan bilangan lelaran. Panjang konteks peringkat pra-latihan GPT-4 ialah 8k, dan versi 32k adalah hasil penalaan halus 8k Kos latihan agak tinggi kelajuan 33.33 Token sesaat model Parametrik, jadi latihan model ini memerlukan kos inferens yang sangat tinggi Dikira pada AS$1 sejam untuk mesin fizikal H100, kos satu latihan adalah setinggi AS$63 juta (kira-kira 451 juta yuan. ). Dalam hal ini,
OpenAI memilih untuk menggunakan GPU A100 dalam awan untuk melatih model, mengurangkan kos latihan akhir kepada kira-kira AS$21.5 juta (kira-kira 154 juta yuan), yang mengambil masa lebih lama untuk mengurangkan kos latihan.
Atas ialah kandungan terperinci Seni bina model GPT-4 bocor: mengandungi 1.8 trilion parameter dan menggunakan model pakar hibrid. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1377
1377
 52
52

 Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Model MoE sumber terbuka paling berkuasa di dunia ada di sini, dengan keupayaan bahasa Cina setanding dengan GPT-4, dan harganya hanya hampir satu peratus daripada GPT-4-Turbo
May 07, 2024 pm 04:13 PM
Bayangkan model kecerdasan buatan yang bukan sahaja mempunyai keupayaan untuk mengatasi pengkomputeran tradisional, tetapi juga mencapai prestasi yang lebih cekap pada kos yang lebih rendah. Ini bukan fiksyen sains, DeepSeek-V2[1], model MoE sumber terbuka paling berkuasa di dunia ada di sini. DeepSeek-V2 ialah gabungan model bahasa pakar (MoE) yang berkuasa dengan ciri-ciri latihan ekonomi dan inferens yang cekap. Ia terdiri daripada 236B parameter, 21B daripadanya digunakan untuk mengaktifkan setiap penanda. Berbanding dengan DeepSeek67B, DeepSeek-V2 mempunyai prestasi yang lebih kukuh, sambil menjimatkan 42.5% kos latihan, mengurangkan cache KV sebanyak 93.3% dan meningkatkan daya pemprosesan penjanaan maksimum kepada 5.76 kali. DeepSeek ialah sebuah syarikat yang meneroka kecerdasan buatan am
 Memilih model benam yang paling sesuai dengan data anda: Ujian perbandingan OpenAI dan benam berbilang bahasa sumber terbuka
Feb 26, 2024 pm 06:10 PM
Memilih model benam yang paling sesuai dengan data anda: Ujian perbandingan OpenAI dan benam berbilang bahasa sumber terbuka
Feb 26, 2024 pm 06:10 PM
OpenAI baru-baru ini mengumumkan pelancaran model benam generasi terbaru mereka embeddingv3, yang mereka dakwa sebagai model benam paling berprestasi dengan prestasi berbilang bahasa yang lebih tinggi. Kumpulan model ini dibahagikan kepada dua jenis: pembenaman teks-3-kecil yang lebih kecil dan pembenaman teks-3-besar yang lebih berkuasa dan lebih besar. Sedikit maklumat didedahkan tentang cara model ini direka bentuk dan dilatih, dan model hanya boleh diakses melalui API berbayar. Jadi terdapat banyak model pembenaman sumber terbuka Tetapi bagaimana model sumber terbuka ini dibandingkan dengan model sumber tertutup OpenAI? Artikel ini akan membandingkan secara empirik prestasi model baharu ini dengan model sumber terbuka. Kami merancang untuk membuat data
 Paradigma pengaturcaraan baharu, apabila Spring Boot bertemu OpenAI
Feb 01, 2024 pm 09:18 PM
Paradigma pengaturcaraan baharu, apabila Spring Boot bertemu OpenAI
Feb 01, 2024 pm 09:18 PM
Pada tahun 2023, teknologi AI telah menjadi topik hangat dan memberi impak besar kepada pelbagai industri, terutamanya dalam bidang pengaturcaraan. Orang ramai semakin menyedari kepentingan teknologi AI, dan komuniti Spring tidak terkecuali. Dengan kemajuan berterusan teknologi GenAI (General Artificial Intelligence), ia menjadi penting dan mendesak untuk memudahkan penciptaan aplikasi dengan fungsi AI. Dengan latar belakang ini, "SpringAI" muncul, bertujuan untuk memudahkan proses membangunkan aplikasi berfungsi AI, menjadikannya mudah dan intuitif serta mengelakkan kerumitan yang tidak perlu. Melalui "SpringAI", pembangun boleh membina aplikasi dengan lebih mudah dengan fungsi AI, menjadikannya lebih mudah untuk digunakan dan dikendalikan.
 Ameca generasi kedua ada di sini! Dia boleh berkomunikasi dengan penonton dengan lancar, ekspresi mukanya lebih realistik, dan dia boleh bercakap berpuluh-puluh bahasa.
Mar 04, 2024 am 09:10 AM
Ameca generasi kedua ada di sini! Dia boleh berkomunikasi dengan penonton dengan lancar, ekspresi mukanya lebih realistik, dan dia boleh bercakap berpuluh-puluh bahasa.
Mar 04, 2024 am 09:10 AM
Robot humanoid Ameca telah dinaik taraf kepada generasi kedua! Baru-baru ini, di Persidangan Komunikasi Mudah Alih Sedunia MWC2024, robot Ameca paling canggih di dunia muncul semula. Di sekitar venue, Ameca menarik sejumlah besar penonton. Dengan restu GPT-4, Ameca boleh bertindak balas terhadap pelbagai masalah dalam masa nyata. "Jom kita menari." Apabila ditanya sama ada dia mempunyai emosi, Ameca menjawab dengan beberapa siri mimik muka yang kelihatan sangat hidup. Hanya beberapa hari yang lalu, EngineeredArts, syarikat robotik British di belakang Ameca, baru sahaja menunjukkan hasil pembangunan terkini pasukan itu. Dalam video tersebut, robot Ameca mempunyai keupayaan visual dan boleh melihat serta menerangkan keseluruhan bilik dan objek tertentu. Perkara yang paling menakjubkan ialah dia juga boleh
 750,000 pusingan pertempuran satu lawan satu antara model besar, GPT-4 memenangi kejuaraan, dan Llama 3 menduduki tempat kelima
Apr 23, 2024 pm 03:28 PM
750,000 pusingan pertempuran satu lawan satu antara model besar, GPT-4 memenangi kejuaraan, dan Llama 3 menduduki tempat kelima
Apr 23, 2024 pm 03:28 PM
Mengenai Llama3, keputusan ujian baharu telah dikeluarkan - komuniti penilaian model besar LMSYS mengeluarkan senarai kedudukan model besar Llama3 menduduki tempat kelima, dan terikat untuk tempat pertama dengan GPT-4 dalam kategori Bahasa Inggeris. Gambar ini berbeza daripada Penanda Aras yang lain Senarai ini berdasarkan pertempuran satu lawan satu antara model, dan penilai dari seluruh rangkaian membuat cadangan dan skor mereka sendiri. Pada akhirnya, Llama3 menduduki tempat kelima dalam senarai, diikuti oleh tiga versi GPT-4 dan Claude3 Super Cup Opus yang berbeza. Dalam senarai tunggal Inggeris, Llama3 mengatasi Claude dan terikat dengan GPT-4. Mengenai keputusan ini, ketua saintis Meta LeCun sangat gembira, tweet semula dan
 Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
Kerja selepas kematian Pasukan Penyelarasan Super OpenAI: Dua model besar bermain permainan, dan output menjadi lebih mudah difahami
Jul 19, 2024 am 01:29 AM
Jika jawapan yang diberikan oleh model AI tidak dapat difahami sama sekali, adakah anda berani menggunakannya? Memandangkan sistem pembelajaran mesin digunakan dalam bidang yang lebih penting, menjadi semakin penting untuk menunjukkan sebab kita boleh mempercayai output mereka, dan bila tidak mempercayainya. Satu cara yang mungkin untuk mendapatkan kepercayaan dalam output sistem yang kompleks adalah dengan menghendaki sistem menghasilkan tafsiran outputnya yang boleh dibaca oleh manusia atau sistem lain yang dipercayai, iaitu, difahami sepenuhnya sehingga apa-apa ralat yang mungkin boleh dilakukan. dijumpai. Contohnya, untuk membina kepercayaan dalam sistem kehakiman, kami memerlukan mahkamah memberikan pendapat bertulis yang jelas dan boleh dibaca yang menjelaskan dan menyokong keputusan mereka. Untuk model bahasa yang besar, kita juga boleh menggunakan pendekatan yang sama. Walau bagaimanapun, apabila mengambil pendekatan ini, pastikan model bahasa menjana
 Editor Zed berasaskan Rust telah menjadi sumber terbuka, dengan sokongan terbina dalam untuk OpenAI dan GitHub Copilot
Feb 01, 2024 pm 02:51 PM
Editor Zed berasaskan Rust telah menjadi sumber terbuka, dengan sokongan terbina dalam untuk OpenAI dan GitHub Copilot
Feb 01, 2024 pm 02:51 PM
Pengarang丨Disusun oleh TimAnderson丨Dihasilkan oleh Noah|51CTO Technology Stack (WeChat ID: blog51cto) Projek editor Zed masih dalam peringkat pra-keluaran dan telah menjadi sumber terbuka di bawah lesen AGPL, GPL dan Apache. Editor menampilkan prestasi tinggi dan berbilang pilihan dibantu AI, tetapi pada masa ini hanya tersedia pada platform Mac. Nathan Sobo menjelaskan dalam catatan bahawa dalam asas kod projek Zed di GitHub, bahagian editor dilesenkan di bawah GPL, komponen bahagian pelayan dilesenkan di bawah AGPL dan bahagian GPUI (GPU Accelerated User) The interface) mengguna pakai Lesen Apache2.0. GPUI ialah produk yang dibangunkan oleh pasukan Zed
 Model paling berkuasa di dunia bertukar tangan semalaman, menandakan berakhirnya era GPT-4! Claude 3 mengetik GPT-5 terlebih dahulu, dan membaca kertas 10,000 perkataan dalam masa 3 saat.
Mar 06, 2024 pm 12:58 PM
Model paling berkuasa di dunia bertukar tangan semalaman, menandakan berakhirnya era GPT-4! Claude 3 mengetik GPT-5 terlebih dahulu, dan membaca kertas 10,000 perkataan dalam masa 3 saat.
Mar 06, 2024 pm 12:58 PM
Kelantangan gila, kelantangannya gila, dan model besar telah berubah lagi. Baru-baru ini, model AI paling berkuasa di dunia bertukar tangan dalam sekelip mata, dan GPT-4 ditarik dari altar. Anthropic mengeluarkan siri model Claude3 terbaharu Satu penilaian ayat: Ia benar-benar menghancurkan GPT-4! Dari segi penunjuk kebolehan berbilang modal dan bahasa, Claude3 menang. Dalam kata-kata Anthropic, model siri Claude3 telah menetapkan penanda aras industri baharu dalam penaakulan, matematik, pengekodan, pemahaman dan penglihatan berbilang bahasa! Anthropic ialah syarikat permulaan yang ditubuhkan oleh pekerja yang "membelot" daripada OpenAI kerana konsep keselamatan yang berbeza Produk mereka telah berulang kali memukul OpenAI. Kali ini, Claude3 juga menjalani pembedahan besar.
