
.
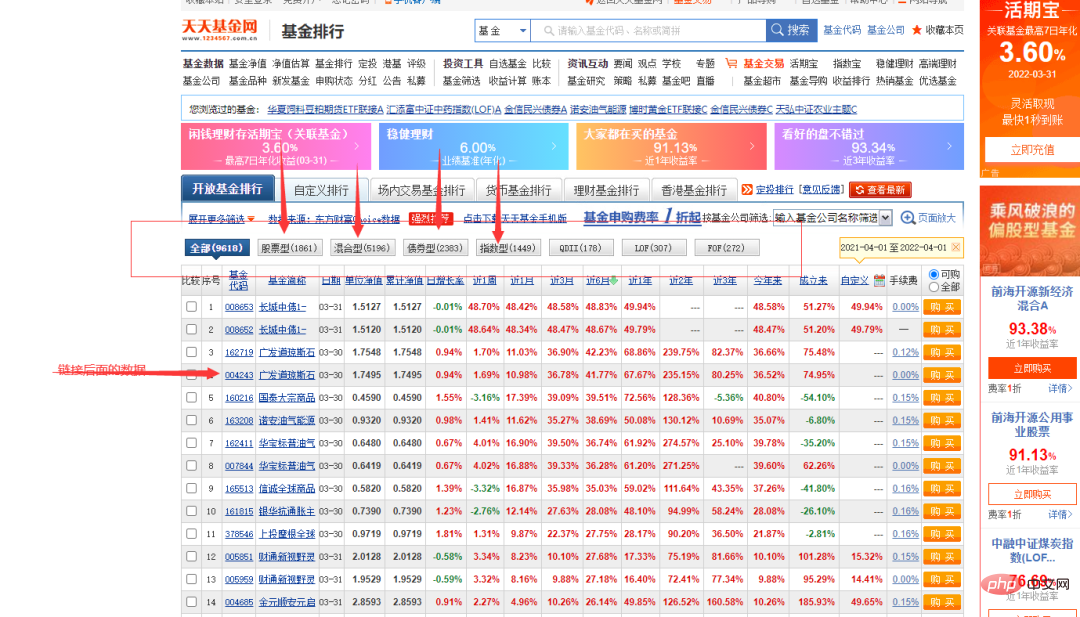
 Selepas mencari sumber data, langkah seterusnya adalah untuk melaksanakan kod tersebut.
Selepas mencari sumber data, langkah seterusnya adalah untuk melaksanakan kod tersebut.
response = requests.get(url, headers=headers, params=params, verify=False)
pattern = re.compile(r'.*?"(?P<items>.*?)".*?', re.S)
result = re.finditer(pattern, response.text)
ids = []
for item in result:
# print(item.group('items'))
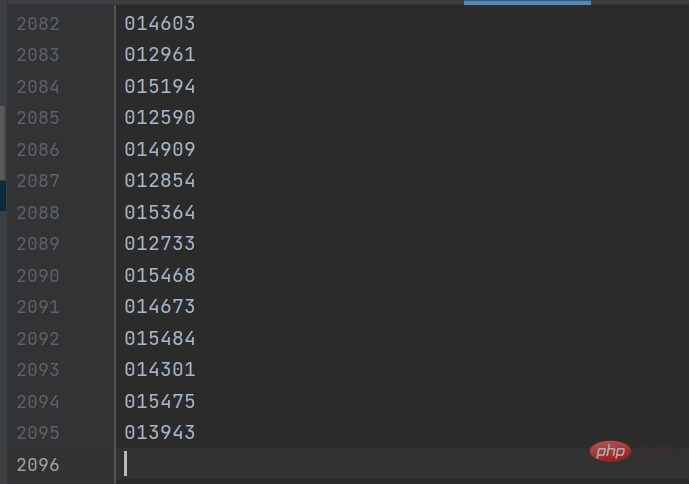
gp_id = item.group('items').split(',')[0]Hasilnya adalah seperti rajah di bawah:
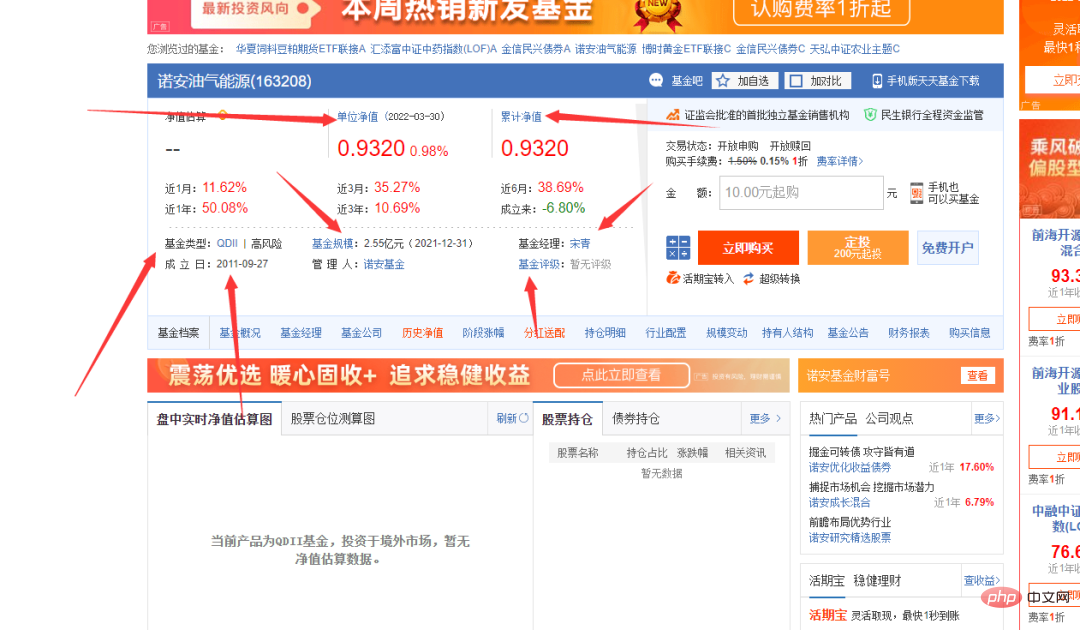
Kemudian bina pautan halaman butiran untuk mendapatkan maklumat dana pada halaman butiran adalah seperti berikut :
response = requests.get(url, headers=headers) response.encoding = response.apparent_encoding selectors = etree.HTML(response.text) danweijingzhi1 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[1]/text()')[0] danweijingzhi2 = selectors.xpath('//dl[@class="dataItem02"]/dd[1]/span[2]/text()')[0] leijijingzhi = selectors.xpath('//dl[@class="dataItem03"]/dd[1]/span/text()')[0] lst = selectors.xpath('//div[@class="infoOfFund"]/table//text()')
Hasilnya adalah seperti yang ditunjukkan dalam rajah di bawah:
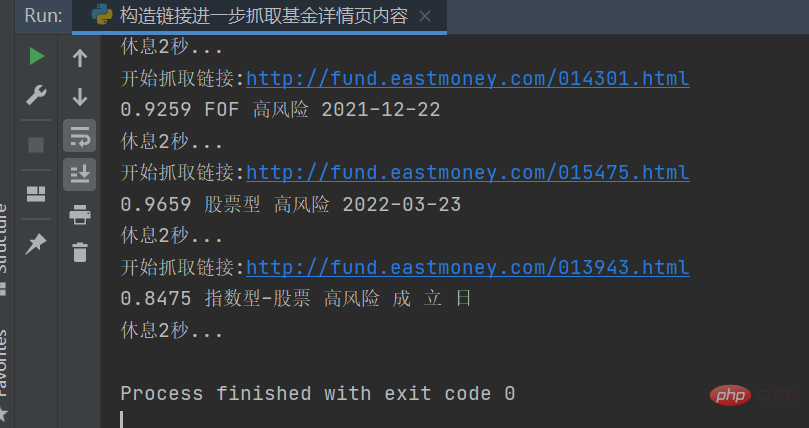 Proses maklumat khusus ke dalam rentetan yang sepadan, dan kemudian simpan ke fail
Proses maklumat khusus ke dalam rentetan yang sepadan, dan kemudian simpan ke fail csv Hasilnya adalah seperti yang ditunjukkan dalam rajah di bawah:
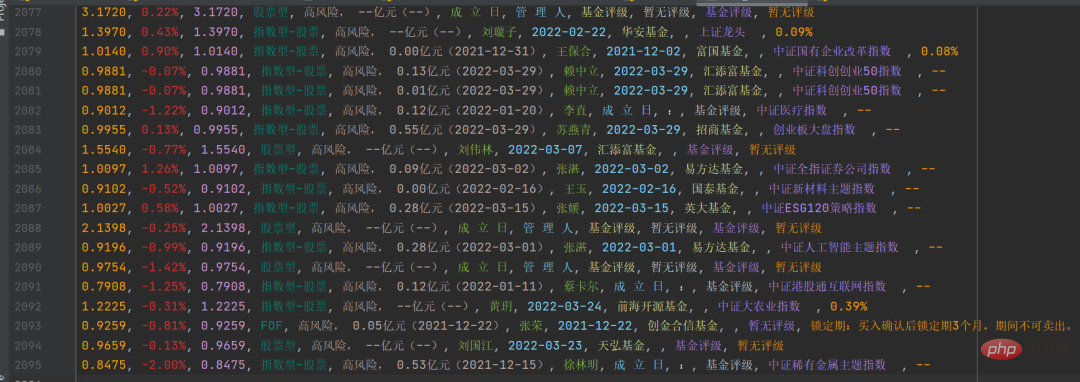 Dengan ini, anda boleh melakukan statistik dan analisis data selanjutnya.
Dengan ini, anda boleh melakukan statistik dan analisis data selanjutnya.
Salam semua, saya seorang yang mahir Python. Artikel ini terutamanya berkongsi penggunaan perangkak web Python untuk mendapatkan maklumat data dana Projek ini tidak terlalu sukar, tetapi terdapat beberapa masalah. Semua orang dialu-alukan untuk mencubanya Saya akan membantu menyelesaikannya.
Artikel ini terutamanya menangkap klasifikasi [jenis saham] Saya tidak melakukannya untuk jenis lain Anda dialu-alukan untuk mencubanya, logiknya adalah sama, hanya menukar parameter. 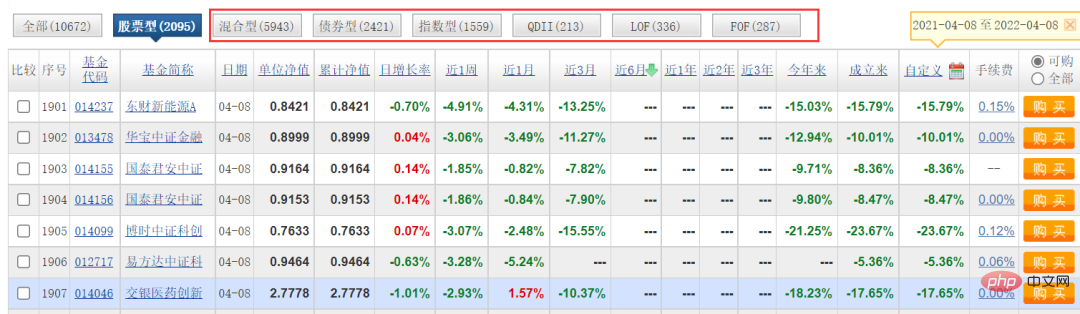
Atas ialah kandungan terperinci Ajar anda langkah demi langkah cara menggunakan perangkak web Python untuk mendapatkan maklumat dana. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!



















![[Web front-end] Permulaan pantas Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



