
 pembangunan bahagian belakang
Tutorial Python
Ajar anda langkah demi langkah cara menggunakan Flask untuk membina enjin carian ES (bahagian persediaan)
pembangunan bahagian belakang
Tutorial Python
Ajar anda langkah demi langkah cara menggunakan Flask untuk membina enjin carian ES (bahagian persediaan)
Ajar anda langkah demi langkah cara menggunakan Flask untuk membina enjin carian ES (bahagian persediaan)
. Jadi bagaimana untuk melaksanakan elasticsearch dan python dok /2 Interaksi Ular Sawa/ Ia juga menyediakan perpustakaan pergantungan yang boleh disambungkan kepada Elasticsearch Mulakan sambungan ke objek operasi Elasticsearch pip install elasticsearch
def __init__(self, index_type: str, index_name: str, ip="127.0.0.1"):
# self.es = Elasticsearch([ip], http_auth=('username', 'password'), port=9200)
self.es = Elasticsearch("localhost:9200")
self.index_type = index_type
self.index_name = index_name
telah disediakan sebelum pemula.
Dapatkan data dokumen berdasarkan IDdef get_doc(self, uid):
return self.es.get(index=self.index_name, id=uid)🎜🎜
插入文档数据
def insert_one(self, doc: dict):
self.es.index(index=self.index_name, doc_type=self.index_type, body=doc)
def insert_array(self, docs: list):
for doc in docs:
self.es.index(index=self.index_name, doc_type=self.index_type, body=doc)搜索文档数据
def search(self, query, count: int = 30):
dsl = {
"query": {
"multi_match": {
"query": query,
"fields": ["title", "content", "link"]
}
},
"highlight": {
"fields": {
"title": {}
}
}
}
match_data = self.es.search(index=self.index_name, body=dsl, size=count)
return match_data
def __search(self, query: dict, count: int = 20): # count: 返回的数据大小
results = []
params = {
'size': count
}
match_data = self.es.search(index=self.index_name, body=query, params=params)
for hit in match_data['hits']['hits']:
results.append(hit['_source'])
return results删除文档数据
def delete_index(self):
try:
self.es.indices.delete(index=self.index_name)
except:
pass好啊,封装 search 类也是为了方便调用,整体贴一下。
from elasticsearch import Elasticsearch
class elasticSearch():
def __init__(self, index_type: str, index_name: str, ip="127.0.0.1"):
# self.es = Elasticsearch([ip], http_auth=('elastic', 'password'), port=9200)
self.es = Elasticsearch("localhost:9200")
self.index_type = index_type
self.index_name = index_name
def create_index(self):
if self.es.indices.exists(index=self.index_name) is True:
self.es.indices.delete(index=self.index_name)
self.es.indices.create(index=self.index_name, ignore=400)
def delete_index(self):
try:
self.es.indices.delete(index=self.index_name)
except:
pass
def get_doc(self, uid):
return self.es.get(index=self.index_name, id=uid)
def insert_one(self, doc: dict):
self.es.index(index=self.index_name, doc_type=self.index_type, body=doc)
def insert_array(self, docs: list):
for doc in docs:
self.es.index(index=self.index_name, doc_type=self.index_type, body=doc)
def search(self, query, count: int = 30):
dsl = {
"query": {
"multi_match": {
"query": query,
"fields": ["title", "content", "link"]
}
},
"highlight": {
"fields": {
"title": {}
}
}
}
match_data = self.es.search(index=self.index_name, body=dsl, size=count)
return match_data尝试一下把 Mongodb 中的数据插入到 ES 中。
import json
from datetime import datetime
import pymongo
from app.elasticsearchClass import elasticSearch
client = pymongo.MongoClient('127.0.0.1', 27017)
db = client['spider']
sheet = db.get_collection('Spider').find({}, {'_id': 0, })
es = elasticSearch(index_type="spider_data",index_name="spider")
es.create_index()
for i in sheet:
data = {
'title': i["title"],
'content':i["data"],
'link': i["link"],
'create_time':datetime.now()
}
es.insert_one(doc=data)到 ES 中查看一下,启动 elasticsearch-head 插件。
如果是 npm 安装的那么 cd 到根目录之后直接 npm run start 就跑起来了。
本地访问 http://localhost:9100/
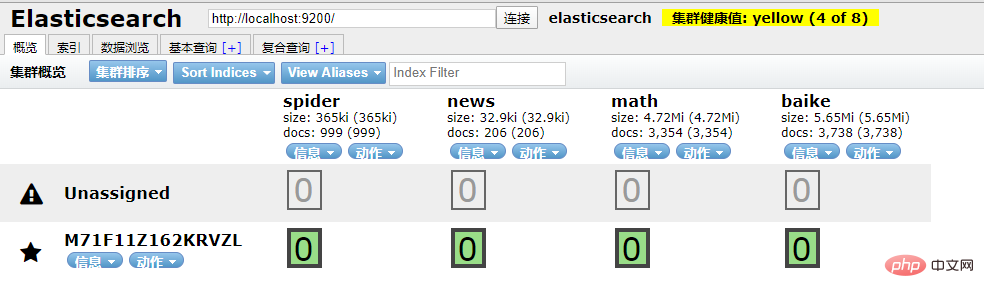
发现新加的 spider 数据文档确实已经进去了。
/3 爬虫入库/
要想实现 ES 搜索,首先要有数据支持,而海量的数据往往来自爬虫。
为了节省时间,编写一个最简单的爬虫,抓取 百度百科。
简单粗暴一点,先 递归获取 很多很多的 url 链接
import requests
import re
import time
exist_urls = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.62 Safari/537.36',
}
def get_link(url):
try:
response = requests.get(url=url, headers=headers)
response.encoding = 'UTF-8'
html = response.text
link_lists = re.findall('.*?<a target=_blank href="/item/([^:#=<>]*?)".*?</a>', html)
return link_lists
except Exception as e:
pass
finally:
exist_urls.append(url)
# 当爬取深度小于10层时,递归调用主函数,继续爬取第二层的所有链接
def main(start_url, depth=1):
link_lists = get_link(start_url)
if link_lists:
unique_lists = list(set(link_lists) - set(exist_urls))
for unique_url in unique_lists:
unique_url = 'https://baike.baidu.com/item/' + unique_url
with open('url.txt', 'a+') as f:
f.write(unique_url + '\n')
f.close()
if depth < 10:
main(unique_url, depth + 1)
if __name__ == '__main__':
start_url = 'https://baike.baidu.com/item/%E7%99%BE%E5%BA%A6%E7%99%BE%E7%A7%91'
main(start_url)把全部 url 存到 url.txt 文件中之后,然后启动任务。
# parse.py
from celery import Celery
import requests
from lxml import etree
import pymongo
app = Celery('tasks', broker='redis://localhost:6379/2')
client = pymongo.MongoClient('localhost',27017)
db = client['baike']
@app.task
def get_url(link):
item = {}
headers = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.131 Safari/537.36'}
res = requests.get(link,headers=headers)
res.encoding = 'UTF-8'
doc = etree.HTML(res.text)
content = doc.xpath("//div[@class='lemma-summary']/div[@class='para']//text()")
print(res.status_code)
print(link,'\t','++++++++++++++++++++')
item['link'] = link
data = ''.join(content).replace(' ', '').replace('\t', '').replace('\n', '').replace('\r', '')
item['data'] = data
if db['Baike'].insert(dict(item)):
print("is OK ...")
else:
print('Fail')run.py 飞起来
from parse import get_url
def main(url):
result = get_url.delay(url)
return result
def run():
with open('./url.txt', 'r') as f:
for url in f.readlines():
main(url.strip('\n'))
if __name__ == '__main__':
run()黑窗口键入
celery -A parse worker -l info -P gevent -c 10
哦豁 !! 你居然使用了 Celery 任务队列,gevent 模式,-c 就是10个线程刷刷刷就干起来了,速度杠杠的 !!
啥?分布式? 那就加多几台机器啦,直接把代码拷贝到目标服务器,通过 redis 共享队列协同多机抓取。
这里是先将数据存储到了 MongoDB 上(个人习惯),你也可以直接存到 ES 中,但是单条单条的插入速度堪忧(接下来会讲到优化,哈哈)。
使用前面的例子将 Mongo 中的数据批量导入到 ES 中,OK !!!
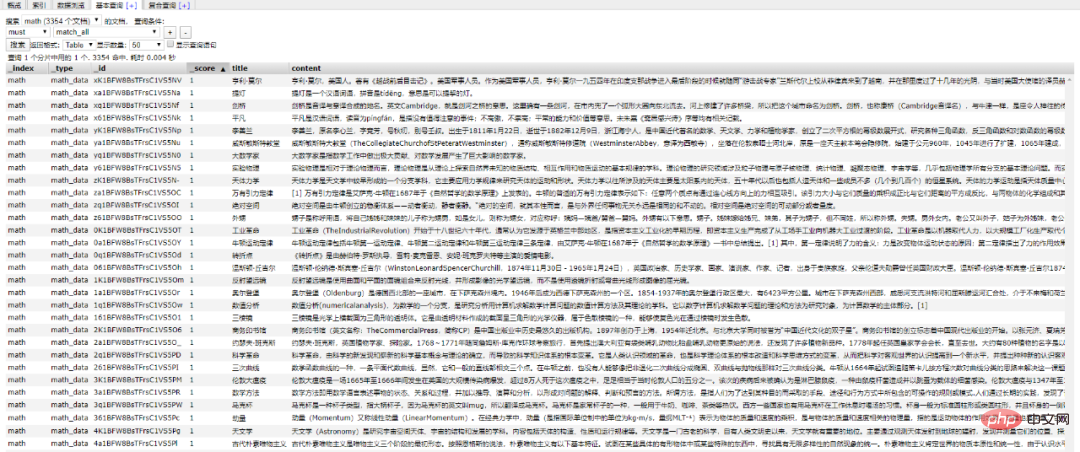
到这一个简单的数据抓取就已经完毕了。
好啦,现在 ES 中已经有了数据啦,接下来就应该是 Flask web 的操作啦,当然,Django,FastAPI 也很优秀。嘿嘿,你喜欢 !!
关于FastAPI 的文章可以看这个系列文章:
1、(入门篇)简析Python web框架FastAPI——一个比Flask和Tornada更高性能的API 框架
2、(进阶篇)Python web框架FastAPI——一个比Flask和Tornada更高性能的API 框架
3、(完结篇)Python web框架FastAPI——一个比Flask和Tornada更高性能的API 框架
/4 Flask 项目结构/

这样一来前期工作就差不多了,接下来剩下的工作主要集中于 Flask 的实际开发中,蓄力中 !!
Atas ialah kandungan terperinci Ajar anda langkah demi langkah cara menggunakan Flask untuk membina enjin carian ES (bahagian persediaan). Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1384
1384
 52
52

 Cara membina aplikasi web yang ringkas dan mudah digunakan dengan React dan Flask
Sep 27, 2023 am 11:09 AM
Cara membina aplikasi web yang ringkas dan mudah digunakan dengan React dan Flask
Sep 27, 2023 am 11:09 AM
Cara menggunakan React dan Flask untuk membina aplikasi web yang ringkas dan mudah digunakan Pengenalan: Dengan perkembangan Internet, keperluan aplikasi web menjadi semakin pelbagai dan kompleks. Untuk memenuhi keperluan pengguna untuk kemudahan penggunaan dan prestasi, semakin penting untuk menggunakan tindanan teknologi moden untuk membina aplikasi rangkaian. React dan Flask ialah dua rangka kerja yang sangat popular untuk pembangunan bahagian hadapan dan belakang, dan ia berfungsi dengan baik bersama-sama untuk membina aplikasi web yang ringkas dan mudah digunakan. Artikel ini akan memperincikan cara memanfaatkan React dan Flask
 Django vs. Flask: Analisis perbandingan rangka kerja web Python
Jan 19, 2024 am 08:36 AM
Django vs. Flask: Analisis perbandingan rangka kerja web Python
Jan 19, 2024 am 08:36 AM
Django dan Flask adalah kedua-duanya peneraju dalam rangka kerja Web Python, dan kedua-duanya mempunyai kelebihan dan senario yang boleh digunakan. Artikel ini akan menjalankan analisis perbandingan kedua-dua rangka kerja ini dan memberikan contoh kod khusus. Pengenalan Pembangunan Django ialah rangka kerja Web berciri penuh, tujuan utamanya adalah untuk membangunkan aplikasi Web yang kompleks dengan cepat. Django menyediakan banyak fungsi terbina dalam, seperti ORM (Pemetaan Hubungan Objek), borang, pengesahan, bahagian belakang pengurusan, dsb. Ciri-ciri ini membolehkan Django mengendalikan besar
 Mulakan dari awal dan bimbing anda langkah demi langkah untuk memasang Flask dan segera buat blog peribadi
Feb 19, 2024 pm 04:01 PM
Mulakan dari awal dan bimbing anda langkah demi langkah untuk memasang Flask dan segera buat blog peribadi
Feb 19, 2024 pm 04:01 PM
Bermula dari awal, saya akan mengajar anda langkah demi langkah cara memasang Flask dan cepat membina blog peribadi Sebagai seorang yang suka menulis, mempunyai blog peribadi adalah sangat penting. Sebagai rangka kerja Web Python yang ringan, Flask boleh membantu kami membina blog peribadi yang ringkas dan berfungsi sepenuhnya dengan cepat. Dalam artikel ini, saya akan bermula dari awal dan mengajar anda langkah demi langkah cara memasang Flask dan membina blog peribadi dengan cepat. Langkah 1: Pasang Python dan pip Sebelum bermula, kita perlu memasang Python dan pi terlebih dahulu
 Panduan untuk memasang rangka kerja Flask: Langkah terperinci untuk membantu anda memasang Flask dengan betul
Feb 18, 2024 pm 10:51 PM
Panduan untuk memasang rangka kerja Flask: Langkah terperinci untuk membantu anda memasang Flask dengan betul
Feb 18, 2024 pm 10:51 PM
Tutorial pemasangan rangka kerja Flask: Ajar anda langkah demi langkah cara memasang rangka kerja Flask dengan betul. Contoh kod khusus diperlukan. Ia mudah dipelajari, mudah digunakan dan padat dengan ciri yang hebat. Artikel ini akan membawa anda langkah demi langkah untuk memasang rangka kerja Flask dengan betul dan memberikan contoh kod terperinci untuk rujukan. Langkah 1: Pasang Python Sebelum memasang rangka kerja Flask, anda perlu terlebih dahulu memastikan bahawa Python dipasang pada komputer anda. Anda boleh bermula dari P
 Penyepaduan Flask dan Intellij IDEA: Petua pembangunan aplikasi web Python (Bahagian 2)
Jun 17, 2023 pm 01:58 PM
Penyepaduan Flask dan Intellij IDEA: Petua pembangunan aplikasi web Python (Bahagian 2)
Jun 17, 2023 pm 01:58 PM
Bahagian pertama memperkenalkan penyepaduan Flask dan Intellij IDEA asas, tetapan projek dan persekitaran maya, pemasangan pergantungan, dsb. Seterusnya kami akan terus meneroka lebih banyak petua pembangunan aplikasi web Python untuk membina persekitaran kerja yang lebih cekap: Menggunakan FlaskBlueprintsFlaskBlueprints membolehkan anda mengatur kod aplikasi anda untuk pengurusan dan penyelenggaraan yang lebih mudah. Blueprint ialah modul Python yang membungkus
 Flask vs FastAPI: Pilihan terbaik untuk pembangunan API Web yang cekap
Sep 27, 2023 pm 09:01 PM
Flask vs FastAPI: Pilihan terbaik untuk pembangunan API Web yang cekap
Sep 27, 2023 pm 09:01 PM
FlaskvsFastAPI: Pilihan terbaik untuk pembangunan WebAPI yang cekap Pengenalan: Dalam pembangunan perisian moden, WebAPI telah menjadi bahagian yang sangat diperlukan. Mereka menyediakan data dan perkhidmatan yang membolehkan komunikasi dan saling kendali antara aplikasi yang berbeza. Apabila memilih rangka kerja untuk membangunkan WebAPI, Flask dan FastAPI ialah dua pilihan yang telah menarik banyak perhatian. Kedua-dua rangka kerja sangat popular dan masing-masing mempunyai kelebihan tersendiri. Dalam artikel ini, kita akan melihat Fl
 Membandingkan prestasi Gunicorn dan uWSGI untuk penggunaan aplikasi Flask
Jan 17, 2024 am 08:52 AM
Membandingkan prestasi Gunicorn dan uWSGI untuk penggunaan aplikasi Flask
Jan 17, 2024 am 08:52 AM
Penggunaan aplikasi flask: Perbandingan Gunicorn vs suWSGI Pengenalan: Flask, sebagai rangka kerja Web Python yang ringan, disukai oleh banyak pembangun. Apabila menggunakan aplikasi Flask ke persekitaran pengeluaran, memilih Antara Muka Gerbang Pelayan (SGI) yang sesuai adalah keputusan penting. Gunicorn dan uWSGI ialah dua pelayan SGI biasa Artikel ini akan menerangkannya secara terperinci.
 Flask-RESTful dan Swagger: Amalan terbaik untuk membina API RESTful dalam aplikasi web Python (Bahagian 2)
Jun 17, 2023 am 10:39 AM
Flask-RESTful dan Swagger: Amalan terbaik untuk membina API RESTful dalam aplikasi web Python (Bahagian 2)
Jun 17, 2023 am 10:39 AM
Flask-RESTful dan Swagger: Amalan Terbaik untuk Membina API RESTful dalam Aplikasi Web Python (Bahagian 2) Dalam artikel sebelumnya, kami meneroka amalan terbaik untuk membina API RESTful menggunakan Flask-RESTful dan Swagger. Kami memperkenalkan asas rangka kerja Flask-RESTful dan menunjukkan cara menggunakan Swagger untuk membina dokumentasi untuk API RESTful. Buku
