
 pangkalan data
tutorial mysql
Hari ini saya akhirnya mengetahui sub-pangkalan data MySQL dan sub-jadual, jadi saya boleh membual tentangnya dalam temu bual!
pangkalan data
tutorial mysql
Hari ini saya akhirnya mengetahui sub-pangkalan data MySQL dan sub-jadual, jadi saya boleh membual tentangnya dalam temu bual!
Hari ini saya akhirnya mengetahui sub-pangkalan data MySQL dan sub-jadual, jadi saya boleh membual tentangnya dalam temu bual!
Kata Pengantar
Syarikat telah mengusahakan pemisahan perkhidmatan dan pembahagian data baru-baru ini, kerana jumlah data dalam satu jadual pakej adalah terlalu besar, dan ia masih berkembang pada 60W sehari.
Saya telah belajar tentang sub-pangkalan data dan sub-jadual pangkalan data sebelum ini, dan telah membaca beberapa catatan blog, tetapi saya hanya tahu konsep yang samar-samar, dan sekarang saya memikirkannya, semuanya kabur.
Saya menghabiskan sepanjang petang membaca sub-jadual pangkalan data dan membaca banyak artikel Sekarang saya akan membuat ringkasan:
Bahagian 1: Masalah yang dihadapi dalam proses pembangunan laman web sebenar.
Bahagian 2: Apakah cara pembahagian yang berbeza, perbezaan dan aspek yang boleh digunakan antara menegak dan mendatar.
Bahagian 3: Beberapa produk dan teknologi sumber terbuka pada masa ini di pasaran, dan apakah kelebihan dan kekurangannya.
Bahagian 4: Mungkin perkara yang paling penting, mengapa tidak disyorkan untuk memisahkan pangkalan data secara mendatar! ? Ini membolehkan anda merawatnya dengan teliti pada peringkat awal perancangan dan mengelakkan masalah yang disebabkan oleh pembahagian.
Penjelasan istilah
Perpustakaan: pangkalan data; jadual: sub-pangkalan data dan sub-jadual: sharding
Evolusi seni bina pangkalan data Pada mulanya, kami hanya menggunakan pangkalan data mesin tunggal, dan kemudian menghadapi lebih banyak lagi dan lebih banyak permintaan. Kami memisahkan operasi tulis dan operasi baca pangkalan data, menggunakan beberapa salinan pangkalan data hamba (Replikasi Budak) untuk bertanggungjawab membaca, dan menggunakan pangkalan data induk (Master) untuk bertanggungjawab untuk menulis data serentak dari pangkalan data induk untuk memastikan data konsisten. Dari segi seni bina, ia adalah penyegerakan tuan-hamba pangkalan data. Pustaka hamba boleh diskalakan secara mendatar, jadi lebih banyak permintaan baca tidak menjadi masalah.
Tetapi apabila bilangan pengguna meningkat dan permintaan menulis meningkat, apakah yang perlu kita lakukan? Menambah Master tidak dapat menyelesaikan masalah, kerana data perlu konsisten dan operasi tulis memerlukan penyegerakan antara dua induk, yang bersamaan dengan pendua dan lebih rumit.
Pada masa ini, anda perlu menggunakan sharding untuk membahagikan operasi tulis.
Masalah sebelum memecah pangkalan data dan jadual
Sebarang masalah terlalu besar atau terlalu kecil Masalah yang kami hadapi di sini ialah jumlah data terlalu besar.
Jumlah permintaan pengguna terlalu besar
Oleh kerana TPS pelayan tunggal, memori dan IO adalah terhad.
Penyelesaian: Edarkan permintaan kepada berbilang pelayan; sebenarnya, permintaan pengguna dan melaksanakan pertanyaan SQL pada dasarnya adalah sama, kedua-duanya meminta sumber, tetapi permintaan pengguna juga akan melalui get laluan, penghalaan, pelayan http, dsb.
Satu pangkalan data terlalu besar
Kapasiti pemprosesan pangkalan data tunggal adalah terhad
Ruang cakera yang tidak mencukupi pada pelayan di mana pangkalan data tunggal berada
IO kesesakan operasi pada satu pangkalan data
Penyelesaian: Bahagikan kepada lebih banyak perpustakaan yang lebih kecil
Jika satu jadual terlalu besar
CRUD adalah masalah;
Peluasan indeks, tamat masa pertanyaan
Penyelesaian: Bahagikan kepada beberapa jadual dengan set data yang lebih kecil.
Kaedah sharding pangkalan data dan jadual
secara amnya ialah segmentasi menegak dan segmentasi mendatar Ini ialah kaedah segmentasi yang diterangkan oleh set hasil, iaitu segmentasi ruang fizikal.
Kita bermula dari masalah yang kita hadapi dan selesaikan.
Explanation:
Firstly, bilangan permintaan pengguna terlalu besar, jadi kami menumpuk mesin untuk mengendalikannya (ini bukan tumpuan artikel ini)
Den perpustakaan tunggal terlalu besar. untuk melihat sama ada terdapat terlalu banyak data disebabkan terlalu banyak jadual, atau sama ada ia disebabkan oleh satu pangkalan data Terdapat banyak data dalam jadual.
Jika terdapat banyak jadual dan banyak data, gunakan segmentasi menegak dan bahagikannya kepada perpustakaan yang berbeza mengikut perniagaan.
Jika jumlah data dalam satu jadual terlalu besar, pembahagian mendatar harus digunakan, iaitu, data jadual dibahagikan kepada berbilang jadual mengikut peraturan tertentu, atau malah berbilang jadual pada berbilang perpustakaan.
分库分表的顺序应该是先垂直分,后水平分. Kerana pembahagian menegak adalah lebih mudah dan lebih konsisten dengan cara kita menangani masalah dunia sebenar.
Pecah menegak
Pecah meja menegak
juga "memecahkan meja besar kepada meja kecil", yang berdasarkan medan lajur. Secara amnya, terdapat banyak medan dalam jadual, dan medan yang tidak biasa digunakan, mempunyai data yang besar dan panjang (seperti medan jenis teks) dibahagikan kepada "jadual lanjutan". Ia biasanya ditujukan kepada jadual besar dengan beratus-ratus lajur, dan juga mengelakkan masalah "merentas halaman" yang disebabkan oleh terlalu banyak data semasa membuat pertanyaan.
Sub-pustaka menegak
Sub-pustaka menegak bertujuan untuk memisahkan perniagaan yang berbeza dalam sistem, seperti pangkalan data untuk pengguna, pangkalan data untuk produk dan pangkalan data untuk pesanan. Selepas pemisahan, ia harus diletakkan pada berbilang pelayan dan bukannya satu pelayan. kenapa? Bayangkan laman web membeli-belah menyediakan perkhidmatan kepada dunia luar dan mempunyai CRUD untuk pengguna, produk, pesanan, dll. Sebelum berpecah, semuanya jatuh ke dalam pustaka tunggal, yang akan menjadikan pangkalan data Keupayaan pemprosesan pangkalan data tunggal telah menjadi hambatan. Selepas membahagikan pangkalan data secara menegak, jika ia masih diletakkan pada pelayan pangkalan data, apabila bilangan pengguna meningkat, kapasiti pemprosesan pangkalan data tunggal akan menjadi hambatan, dan Ruang cakera, memori, tps, dsb. bagi satu pelayan adalah sangat ketat. Oleh itu, kita perlu membahagikannya kepada beberapa pelayan, supaya masalah di atas dapat diselesaikan dan kita tidak akan menghadapi masalah sumber mesin tunggal pada masa hadapan. 单库处理能力成为瓶颈。按垂直分库后,如果还是放在一个数据库服务器上, 随着用户量增大,这会让单个数据库的处理能力成为瓶颈,还有单个服务器的磁盘空间,内存,tps等非常吃紧。所以我们要拆分到多个服务器上,这样上面的问题都解决了,以后也不会面对单机资源问题。
数据库业务层面的拆分,和服务的治理,降级机制类似,也能对不同业务的数据分别的进行管理,维护,监控,扩展等。数据库往往最容易成为应用系统的瓶颈,而数据库本身属于有状态的,相对于Web和应用服务器来讲,是比较难实现横向扩展
Downgrade adalah serupa, Ia juga boleh mengurus, menyelenggara, memantau, mengembangkan, dsb. data perniagaan yang berbeza secara berasingan. Pangkalan data selalunya paling berkemungkinan menjadi kesesakan sistem aplikasi, dan pangkalan data itu sendiri tergolong dalam warna: rgba(27, 31, 35, 0.05);font-family: "Operator Mono", Consolas, Monaco, Menlo, monospace;word-break: break-all;color: rgb(239, 112, 96);" >Stateful lebih sukar untuk dilaksanakan daripada pelayan web dan aplikasiPeluasan mendatar. Sumber sambungan pangkalan data adalah berharga dan keupayaan pemprosesan mesin tunggal adalah terhad Dalam senario konkurensi tinggi, sub-pangkalan data menegak boleh menembusi kesesakan IO, bilangan sambungan dan sumber perkakasan mesin tunggal pada tahap tertentu. 🎜. pangkalan data dan sub-jadualakan Data satu jadual dipecahkan kepada berbilang pelayan Setiap pelayan mempunyai pangkalan data dan jadual yang sepadan, tetapi pengumpulan data dalam jadual adalah berbeza dengan berkesan dapat mengurangkan kesesakan prestasi dan tekanan mesin tunggal dan pangkalan data tunggal, dan menembusi Bottleneck dalam IO, bilangan sambungan, sumber perkakasan, dsb. Peraturan sharding mendatar
JulatRANGE,HASH取模等),切分到多张表里面去。但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈
- Sistem pusat beli-belah secara amnya menggunakan pengguna dan pesanan sebagai jadual utama, dan kemudian menggunakan jadual yang berkaitan sebagai jadual tambahan Ini tidak akan menyebabkan masalah seperti transaksi merentas pangkalan data ID pengguna diambil, dan kemudian cincangan diambil dan diedarkan kepada pangkalan data yang berbeza
- Sebagai contoh, Qiniu Cloud harus membahagikan perniagaan mengikut masa 6 bulan yang lalu atau walaupun setahun yang lalu dan meletakkannya ke dalam jadual lain, kebarangkalian data dalam jadual ini menjadi lebih kecil, jadi tidak perlu meletakkannya bersama "data panas". pemisahan data panas dan sejuk"
.
Masalah yang dihadapi selepas sub-pangkalan data dan jadual
Sokongan transaksi
Selepas sub-pangkalan data dan jadual, ia menjadi Transaksi teragih. 分布式事务了。
如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价;如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
多库结果集合并(group by,order by)
类似于group by,order by
Berbilang set hasil pangkalan data digabungkan (kumpulan mengikut, susunan mengikut)
🎜Serupa denganKumpulkan mengikut, tertib mengikutPernyataan pengelompokan dan pengisihan sedemikian tidak boleh digunakan🎜🎜Cross-database join🎜🎜Selepas pangkalan data dibahagikan kepada jadual, operasi perkaitan antara jadual akan dihadkan, dan kami tidak boleh menyertai jadual di lokasi yang berbeza Jadual dalam sub-pangkalan data tidak boleh digabungkan dengan jadual dengan butiran sub-jadual yang berbeza Akibatnya, perniagaan yang boleh diselesaikan dengan satu pertanyaan mungkin memerlukan beberapa pertanyaan untuk diselesaikan. Penyelesaian kasar: jadual global: data asas, semua perpustakaan mempunyai salinan. Lebihan medan: Dengan cara ini, sesetengah medan tidak perlu disoal dengan menyertai. Pemasangan lapisan sistem: Tanya semuanya secara berasingan dan kemudian pasangkannya, yang lebih rumit. 🎜Produk penyelesaian sub-pangkalan data dan sub-jadual
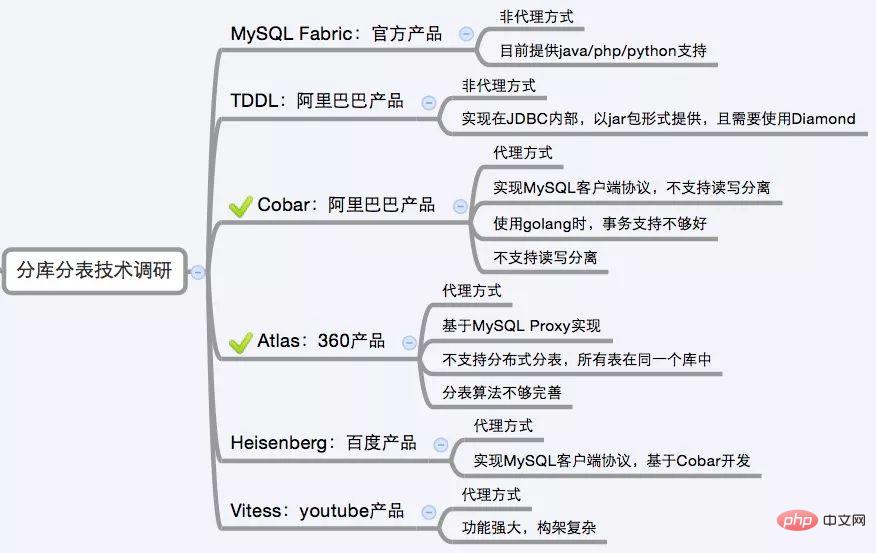
Terdapat banyak sub-pangkalan data dan perisian tengah sub-jadual di pasaran, antaranya yang berdasarkan proksi termasuk MySQL Proxy dan Amoeba, berdasarkan rangka kerja Hibernate ialah Hibernate Shard, berdasarkan jdbc Dangdangsharding-jdbc, pemalam Maven berdasarkan mybatis serupa dengan Mogujie TSharding, dengan menulis semula kelas templat ibatis spring Klien Cobar. MySQL Proxy和Amoeba, 基于Hibernate框架的是Hibernate Shards,基于jdbc的有当当sharding-jdbc, 基于mybatis的类似maven插件式的有蘑菇街的蘑菇街TSharding, 通过重写spring的ibatis template类的Cobar Client。
还有一些大公司的开源产品:
我是程序员青戈,一个爱生活、爱分享的90后程序员。
本期关于Mysql分库分表的介绍和解决方案介绍到这里,希望能帮助到大家,后续更多Java面试类的文章请持续关注公众号Java学习指南Terdapat juga produk sumber terbuka daripada beberapa syarikat besar:
 🎜Saya
🎜SayaProgrammer Qingge, seorang pengaturcara pasca 90-an yang sukakan kehidupan dan perkongsian. 🎜
Isu ini memperkenalkan sub-pangkalan data dan sub-jadual Mysql Penyelesaiannya diperkenalkan di sini, saya harap ia dapat membantu semua orang Sila teruskan memberi perhatian kepada akaun rasmi untuk lebih banyak artikel temuduga Java pada masa hadapanPanduan Belajar Java🎜. 🎜🎜
Atas ialah kandungan terperinci Hari ini saya akhirnya mengetahui sub-pangkalan data MySQL dan sub-jadual, jadi saya boleh membual tentangnya dalam temu bual!. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Alat AI Hot

Undresser.AI Undress
Apl berkuasa AI untuk mencipta foto bogel yang realistik

AI Clothes Remover
Alat AI dalam talian untuk mengeluarkan pakaian daripada foto.

Undress AI Tool
Gambar buka pakaian secara percuma

Clothoff.io
Penyingkiran pakaian AI

AI Hentai Generator
Menjana ai hentai secara percuma.

Artikel Panas
Alat panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas
 1378
1378
 52
52

 MySQL: Kemudahan Pengurusan Data untuk Pemula
Apr 09, 2025 am 12:07 AM
MySQL: Kemudahan Pengurusan Data untuk Pemula
Apr 09, 2025 am 12:07 AM
MySQL sesuai untuk pemula kerana mudah dipasang, kuat dan mudah untuk menguruskan data. 1. Pemasangan dan konfigurasi mudah, sesuai untuk pelbagai sistem operasi. 2. Menyokong operasi asas seperti membuat pangkalan data dan jadual, memasukkan, menanyakan, mengemas kini dan memadam data. 3. Menyediakan fungsi lanjutan seperti menyertai operasi dan subqueries. 4. Prestasi boleh ditingkatkan melalui pengindeksan, pengoptimuman pertanyaan dan pembahagian jadual. 5. Sokongan sokongan, pemulihan dan langkah keselamatan untuk memastikan keselamatan data dan konsistensi.
 Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Cara membuka phpmyadmin
Apr 10, 2025 pm 10:51 PM
Anda boleh membuka phpmyadmin melalui langkah -langkah berikut: 1. Log masuk ke panel kawalan laman web; 2. Cari dan klik ikon phpmyadmin; 3. Masukkan kelayakan MySQL; 4. Klik "Login".
 MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL: Kemahiran Penting untuk Pemaju
Apr 10, 2025 am 09:30 AM
MySQL dan SQL adalah kemahiran penting untuk pemaju. 1.MYSQL adalah sistem pengurusan pangkalan data sumber terbuka, dan SQL adalah bahasa standard yang digunakan untuk mengurus dan mengendalikan pangkalan data. 2.MYSQL menyokong pelbagai enjin penyimpanan melalui penyimpanan data yang cekap dan fungsi pengambilan semula, dan SQL melengkapkan operasi data yang kompleks melalui pernyataan mudah. 3. Contoh penggunaan termasuk pertanyaan asas dan pertanyaan lanjutan, seperti penapisan dan penyortiran mengikut keadaan. 4. Kesilapan umum termasuk kesilapan sintaks dan isu -isu prestasi, yang boleh dioptimumkan dengan memeriksa penyataan SQL dan menggunakan perintah menjelaskan. 5. Teknik pengoptimuman prestasi termasuk menggunakan indeks, mengelakkan pengimbasan jadual penuh, mengoptimumkan operasi menyertai dan meningkatkan kebolehbacaan kod.
 Cara Membuat Premium Navicat
Apr 09, 2025 am 07:09 AM
Cara Membuat Premium Navicat
Apr 09, 2025 am 07:09 AM
Buat pangkalan data menggunakan Navicat Premium: Sambungkan ke pelayan pangkalan data dan masukkan parameter sambungan. Klik kanan pada pelayan dan pilih Buat Pangkalan Data. Masukkan nama pangkalan data baru dan set aksara yang ditentukan dan pengumpulan. Sambung ke pangkalan data baru dan buat jadual dalam penyemak imbas objek. Klik kanan di atas meja dan pilih masukkan data untuk memasukkan data.
 Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
Mysql: Konsep mudah untuk pembelajaran mudah
Apr 10, 2025 am 09:29 AM
MySQL adalah sistem pengurusan pangkalan data sumber terbuka. 1) Buat Pangkalan Data dan Jadual: Gunakan perintah Createdatabase dan Createtable. 2) Operasi Asas: Masukkan, Kemas kini, Padam dan Pilih. 3) Operasi lanjutan: Sertai, subquery dan pemprosesan transaksi. 4) Kemahiran Debugging: Semak sintaks, jenis data dan keizinan. 5) Cadangan Pengoptimuman: Gunakan indeks, elakkan pilih* dan gunakan transaksi.
 Cara Membuat Sambungan Baru ke MySQL di Navicat
Apr 09, 2025 am 07:21 AM
Cara Membuat Sambungan Baru ke MySQL di Navicat
Apr 09, 2025 am 07:21 AM
Anda boleh membuat sambungan MySQL baru di Navicat dengan mengikuti langkah -langkah: Buka aplikasi dan pilih Sambungan Baru (Ctrl N). Pilih "MySQL" sebagai jenis sambungan. Masukkan nama host/alamat IP, port, nama pengguna, dan kata laluan. (Pilihan) Konfigurasikan pilihan lanjutan. Simpan sambungan dan masukkan nama sambungan.
 Cara Melaksanakan SQL di Navicat
Apr 08, 2025 pm 11:42 PM
Cara Melaksanakan SQL di Navicat
Apr 08, 2025 pm 11:42 PM
Langkah -langkah untuk melaksanakan SQL di Navicat: Sambungkan ke pangkalan data. Buat tetingkap editor SQL. Tulis pertanyaan SQL atau skrip. Klik butang Run untuk melaksanakan pertanyaan atau skrip. Lihat hasilnya (jika pertanyaan dilaksanakan).
 Navicat menyambung ke kod ralat dan penyelesaian pangkalan data
Apr 08, 2025 pm 11:06 PM
Navicat menyambung ke kod ralat dan penyelesaian pangkalan data
Apr 08, 2025 pm 11:06 PM
Kesilapan dan penyelesaian yang biasa apabila menyambung ke pangkalan data: Nama pengguna atau kata laluan (ralat 1045) Sambungan blok firewall (ralat 2003) Timeout sambungan (ralat 10060)
