
 pangkalan data
SQL
Mengapakah spesifikasi kod memerlukan pernyataan SQL supaya tidak mempunyai terlalu banyak sambungan?
pangkalan data
SQL
Mengapakah spesifikasi kod memerlukan pernyataan SQL supaya tidak mempunyai terlalu banyak sambungan?
Mengapakah spesifikasi kod memerlukan pernyataan SQL supaya tidak mempunyai terlalu banyak sambungan?
Jul 26, 2023 pm 04:51 PMHantar sub-soalan
Penemuduga: Adakah anda pernah mengendalikan Linux?
Saya: Ya
Penemuduga:Apakah perintah yang perlu saya gunakan
percuma untuk menyemak
untuk menyemakPercuma atas
Penemuduga:Bolehkah anda beritahu saya maklumat yang anda boleh lihat menggunakan arahan percuma
- Saya:
Nah, seperti yang ditunjukkan dalam rajah di bawah, anda boleh melihat penggunaan memori dan cache
- jumlah keseluruhan memori
- memori terpakai terpakai
- memori percuma percuma
- buff/cache digunakan cache
memori yang tersedia 
🎜🎜 Penemuduga: 🎜Maka adakah anda tahu cara mengosongkan cache yang digunakan (buff/cache)🎜
Saya: em... Saya tidak tahu
Penemuduga: sync; echo 3 > /proc/sys/vm/drop_caches Kemudian kita boleh mengosongkan buff/cache Bolehkah anda memberitahu saya jika saya boleh melaksanakan arahan ini dalam talian

(Hantar Sub-topik, saya sangat gembira) Faedahnya adalah hebat Selepas membersihkan cache, kita akan mempunyai lebih banyak ruang memori yang tersedia Sama seperti roket kecil xx Guardian pada PC, banyak memori akan dikeluarkan satu klik
Penemuduga: em…., balik dan tunggu pemberitahuan
Jom bincang tentang SQL Join lagi
Penemuduga:Tukar topik dan bincangkan pemahaman anda tentang join
Okay (kalau silap jawab lagi dah habis) Rebutlah peluang)
Semak
Sertai dalam SQL boleh gabungkan jadual yang ditentukan mengikut syarat tertentu dan kembalikan data kepada klien
Ada cara untuk menyertainya
.penuh sertai
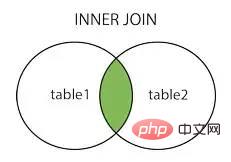
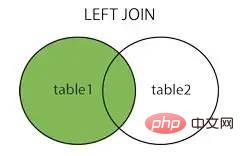
Sumber imej: https://www.cnblogs.com/reaptomorrow-flydream/p/8145610.html
Penemuduga: Jika anda perlu menggunakan penyata gabungan semasa pembangunan projek, bagaimana untuk mengoptimumkan dan meningkatkan prestasi?
Saya: Terdapat dua situasi, satu dengan saiz data yang kecil dan satu dengan saiz data yang besar.
Inderviewer: THEN?
ME: for
1.
, anda boleh meningkatkan indeks Optimumkan kelajuan pelaksanaan pernyataan gabunganAnda boleh menggunakan maklumat berlebihan untuk mengurangkan bilangan cantuman
Cuba kurangkan bilangan sambungan meja sambungan jadual untuk satu pernyataan SQL tidak boleh melebihi 5 kali ganda
-
Penemu bual: Boleh dirumuskan bahawa pernyataan gabungan itu agak memakan prestasi, bukan?
Ya
Penemuduga:Kenapa? me: Terdapat proses perbandingan apabila melaksanakan penyataan gabungan: ME: join_buffer_size seperti yang ditunjukkan dalam rajah Saiz akan mempengaruhi prestasi pelaksanaan kenyataan penyertaan kami Penemuduga: Premis utama Penemuduga: Saya: Ambil InnoDB enjin MySQL sebagai contoh InnoDB menggunakan halaman sebagai unit IO asas, dan saiz setiap halaman ialah 16KB storan data.InnoDB untuk setiap fail. Verifikasi me: Ini bermakna kita perlu membaca seberapa banyak fail yang ada jadual untuk disambungkan. cakera keras Penemuduga:Maksudnya, pergerakan kepala magnet yang kerap akan menjejaskan prestasi, bukan? Saya:Ya, bukankah rangka kerja sumber terbuka semasa suka mengatakan bahawa mereka sangat meningkatkan prestasi melalui pembacaan dan penulisan berurutan? , seperti hbase, kafka Pewawancara: Betul, adakah anda fikir Linux telah mengoptimumkan ini? cache diduduki Lebih daripada 1.2G buff/ disimpan dalam cache Apa adakah? Mengapa anda boleh menggunakan dua arahan untuk membersihkan memori yang diduduki oleh buff/cache, tetapi anda hanya boleh melepaskan digunakan dengan menamatkan proses? Pin, adakah anda berfikir dengan teliti Saya: Bolehkah? Saya memikirkan ayat dalam "CSAPP" (Pemahaman Mendalam Sistem Komputer) Intipati hierarki memori ialah setiap lapisan peranti storan adalah cache peranti lapisan bawah Dalam orang awam istilah, Maksudnya, Linux akan menganggap memori sebagai cache cakera keras Maklumat berkaitan: http://tldp.org/LDP/sag/html/buffer-cache.html Pewawancara: Sekarang saya tahu bahawa Bagaimana saya harus menjawab soalan mata Saya:Saya... Penemuduga:Beri anda peluang lagi jika anda bertanya untuk melaksanakan algoritma Sertai ? Saya: Jika tiada indeks, gelung bersarang akan selesai. Jika ada indeks, anda boleh menggunakan indeks untuk meningkatkan prestasi. Penemuduga: Kembali ke join_buffer, pada pendapat anda apa yang disimpan dalam join_buffer Saya: Semasa proses pengimbasan, pangkalan data akan memilih jadual dan meletakkan data yang ingin dipulangkan dan perlu dibandingkan dengan jadual lain . join_buffer Penemuduga: Bagaimana untuk mengendalikannya apabila terdapat indeks? Saya: Ini agak mudah cuma baca pepohon indeks kedua-dua jadual dan bandingkannya Izinkan saya memperkenalkan kaedah pemprosesan tanpa indeks Nested Loop Join . baca satu baris data dalam jadual pada satu masa Maksudnya, jika outerTable mempunyai 100,000 baris data dan innerTable mempunyai 100 baris data, ia perlu dibaca 10,000,000 kali (dengan mengandaikan bahawa fail kedua-dua jadual ini. belum dikendalikan) Sistem menyimpannya ke dalam memori, kami memanggilnya jadual data sejuk) Sudah tentu, tiada enjin pangkalan data menggunakan algoritma ini sekarang (terlalu perlahan) Sekat gelung bersarang Blok blok, iaitu Ia mengatakan bahawa sekeping data akan diambil ke dalam memori setiap kali untuk mengurangkan overhed I/O MySQL InnoDB akan menggunakan algoritma ini apabila tiada indeks boleh digunakan Pertimbangkan dua jadual berikut t_a dan t_b Apabila indeks tidak boleh digunakan untuk melakukan operasi gabungan, InnoDB akan menggunakan algoritma gelung bersarang Blok secara automatik Apabila saya berada di sekolah, guru pangkalan data suka mengambil paradigma pangkalan data yang paling banyak. , gunakannya Jika ia tidak boleh berlebihan, sertainya Jika bergabung benar-benar menjejaskan prestasi. Cuba tingkatkan join_buffer_size anda atau tukar kepada pemacu keadaan pepejal. "Pemahaman Mendalam Sistem Komputer" - Bab 6 Hierarki MemoriBuffer
show variables like '%buffer%'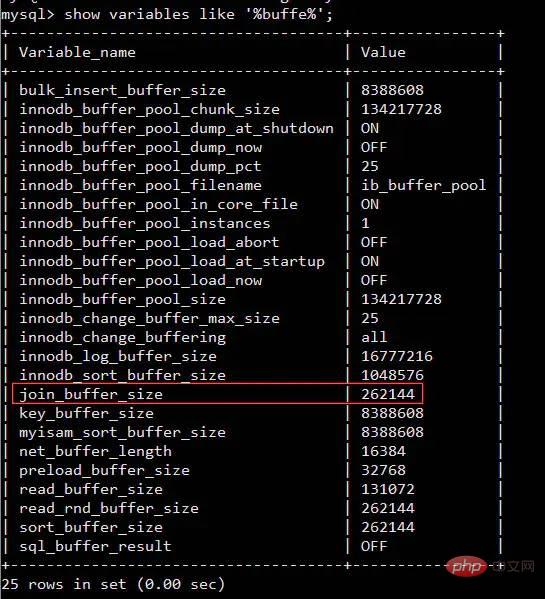
Saya:
Sebarang projek akhirnya akan masuk dalam talian, dan tidak dapat dielakkan untuk menjana data juga, data Skala tidak boleh kecil
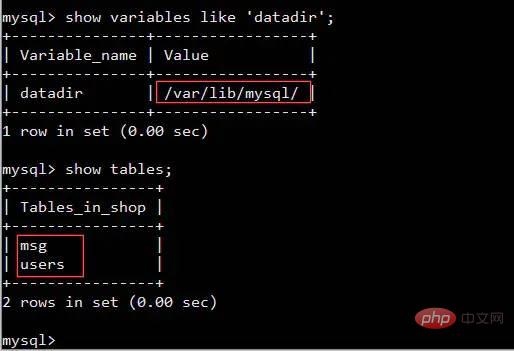

 Mengapa buff/cache mengambil begitu banyak memori, dan memori yang tersedia tersedia dan masih ada 1.1G?
Mengapa buff/cache mengambil begitu banyak memori, dan memori yang tersedia tersedia dan masih ada 1.1G? 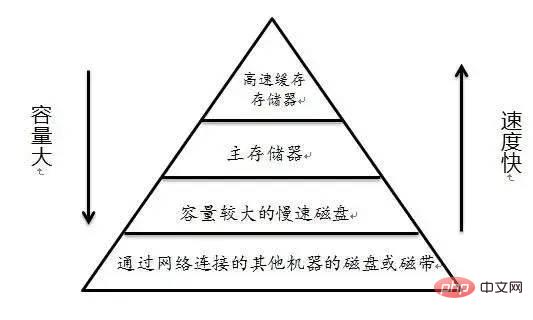

Sertai algoritma
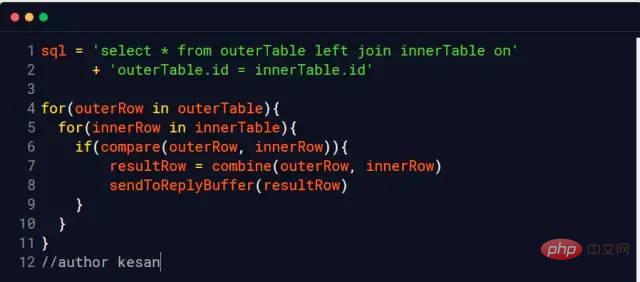 sahaja
sahaja 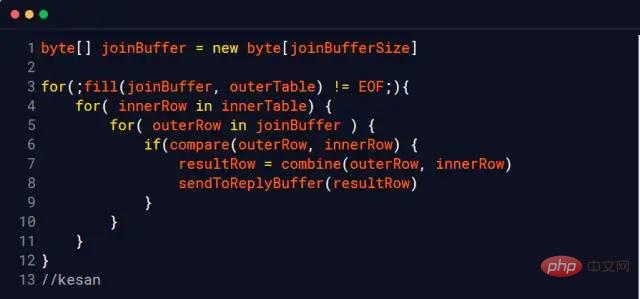

Summary
Rujukan
"Eksperimen dan keseronokan dengan cache cakera Linux" Penulis menggunakan beberapa contoh untuk menggambarkan kesan cache cakera keras terhadap prestasi pelaksanaan program
" Linux makan ram saya》Penjelasan Parameter Percuma
Cara mengosongkan penimbal/pagecache (cache cakera) di bawah Linux Penjelasan arahan sub-soalan pada permulaan artikel
Cara MySQL berjalan: Memahami MySQL dari akar
Sekat gelung terbaik daripada MariaDB Dokumen rasmi menerangkan pelaksanaan algoritma Block-Nested-Loop
Atas ialah kandungan terperinci Mengapakah spesifikasi kod memerlukan pernyataan SQL supaya tidak mempunyai terlalu banyak sambungan?. Untuk maklumat lanjut, sila ikut artikel berkaitan lain di laman web China PHP!

Artikel Panas

Alat panas Tag

Artikel Panas

Tag artikel panas

Notepad++7.3.1
Editor kod yang mudah digunakan dan percuma

SublimeText3 versi Cina
Versi Cina, sangat mudah digunakan

Hantar Studio 13.0.1
Persekitaran pembangunan bersepadu PHP yang berkuasa

Dreamweaver CS6
Alat pembangunan web visual

SublimeText3 versi Mac
Perisian penyuntingan kod peringkat Tuhan (SublimeText3)
Topik panas



 Apakah perbezaan antara HQL dan SQL dalam rangka kerja Hibernate?
Apr 17, 2024 pm 02:57 PM
Apakah perbezaan antara HQL dan SQL dalam rangka kerja Hibernate?
Apr 17, 2024 pm 02:57 PM
Apakah perbezaan antara HQL dan SQL dalam rangka kerja Hibernate?
 Penggunaan operasi bahagian dalam Oracle SQL
Mar 10, 2024 pm 03:06 PM
Penggunaan operasi bahagian dalam Oracle SQL
Mar 10, 2024 pm 03:06 PM
Penggunaan operasi bahagian dalam Oracle SQL
 Apakah yang dimaksudkan dengan atribut identiti dalam SQL?
Feb 19, 2024 am 11:24 AM
Apakah yang dimaksudkan dengan atribut identiti dalam SQL?
Feb 19, 2024 am 11:24 AM
Apakah yang dimaksudkan dengan atribut identiti dalam SQL?
 Perbandingan dan perbezaan sintaks SQL antara Oracle dan DB2
Mar 11, 2024 pm 12:09 PM
Perbandingan dan perbezaan sintaks SQL antara Oracle dan DB2
Mar 11, 2024 pm 12:09 PM
Perbandingan dan perbezaan sintaks SQL antara Oracle dan DB2
 Bagaimanakah java menggunakan pemintas pemacu MySQL untuk melaksanakan pengiraan sql yang memakan masa?
May 27, 2023 pm 01:10 PM
Bagaimanakah java menggunakan pemintas pemacu MySQL untuk melaksanakan pengiraan sql yang memakan masa?
May 27, 2023 pm 01:10 PM
Bagaimanakah java menggunakan pemintas pemacu MySQL untuk melaksanakan pengiraan sql yang memakan masa?
 Penjelasan terperinci tentang fungsi Set tag dalam teg SQL dinamik MyBatis
Feb 26, 2024 pm 07:48 PM
Penjelasan terperinci tentang fungsi Set tag dalam teg SQL dinamik MyBatis
Feb 26, 2024 pm 07:48 PM
Penjelasan terperinci tentang fungsi Set tag dalam teg SQL dinamik MyBatis
 Cara SpringBoot menyulitkan kata laluan akaun SQL bagi fail konfigurasi
May 22, 2023 pm 08:50 PM
Cara SpringBoot menyulitkan kata laluan akaun SQL bagi fail konfigurasi
May 22, 2023 pm 08:50 PM
Cara SpringBoot menyulitkan kata laluan akaun SQL bagi fail konfigurasi
 Bagaimana untuk menyelesaikan ralat 5120 dalam SQL
Mar 06, 2024 pm 04:33 PM
Bagaimana untuk menyelesaikan ralat 5120 dalam SQL
Mar 06, 2024 pm 04:33 PM
Bagaimana untuk menyelesaikan ralat 5120 dalam SQL
